DB 서버 한 대에 모든 쓰기와 읽기를 맡기면 장애와 점검에 취약합니다. 복제와 고가용성 구성은 데이터를 여러 노드에 유지해 장애 영향을 줄이는 방법입니다. 다만 지연과 승격 절차를 이해하지 못하면 HA 구성이 오히려 혼란을 만듭니다.
복제를 직접 구축할 일은 거의 없지만, 원리를 알면 클라우드 RDS 옵션 선택과 복제 지연 버그를 이해할 수 있습니다.
- 1고가용성과 읽기 스케일아웃 관점에서 복제가 왜 필요한지 설명할 수 있다
- 2바이너리 로그와 IO/SQL 스레드로 복제 원리를 설명할 수 있다
- 3RDS Multi-AZ와 Read Replica를 비교해 상황에 맞게 선택할 수 있다
- 4복제 지연(Replication Lag) 패턴을 이해하고 개발 시 주의할 수 있다
- 5쓰기/읽기 분리 아키텍처를 설계 원칙에 따라 구성할 수 있다
DB 복제와 고가용성 — 개념 이해와 클라우드 활용
서비스가 커지면 두 가지 DB 문제가 생깁니다. 첫 번째: "DB 서버 하나가 죽으면 서비스 전체가 다운된다." 두 번째: "읽기 쿼리가 너무 많아서 DB가 버틸 수가 없다." 복제(Replication)는 읽기 확장에 도움을 주지만, 장애 시 자동 승격·펜싱·쿼럼 같은 HA 오케스트레이션이 없으면 첫 번째 문제를 자동으로 해결하지 않습니다. 이 구분을 먼저 이해해야 Multi-AZ·Read Replica를 목적에 맞게 선택할 수 있습니다.
실행 결과를 확인할 수 있는 DB 콘솔 출력이 표시됩니다.
- 읽기 순서—SHOW REPLICA STATUS 출력은 Seconds_Behind_Source → Replica_SQL_Running → Replica_IO_Running 순으로 읽습니다. 지연이 0이어도 두 Running이 Yes인지 반드시 확인합니다.
- Seconds_Behind_Source 판단 기준—0: 동기화됨(이상적) / 1~10s: 경미한 지연(모니터링) / 10~60s: 주의(Primary 쓰기 부하 감소 필요) / 60s 이상: 위험(복제 실패 임박) / NULL: 복제 중단(즉시 확인)
- 조합 해석 — IO 스레드 단절—Replica_IO_Running=No → Primary와 연결 끊김. 네트워크 장애 또는 Primary 다운 가능성. Last_IO_Error 필드로 구체적 원인 확인.
- 조합 해석 — SQL 스레드 에러—Replica_SQL_Running=No → SQL 스레드가 릴레이 로그 적용 중 에러. Last_SQL_Error 필드 확인 후 해당 이벤트를 SKIP하거나 데이터 불일치를 수동 복구해야 합니다.
- 조합 해석 — 지연 증가—Replica_IO_Running=Yes + Replica_SQL_Running=Yes인데 Seconds_Behind_Source가 지속 증가 → Primary 쓰기 속도가 Replica SQL 스레드 처리 속도 초과. slave_parallel_workers(병렬 복제) 활성화 또는 Primary 쓰기 부하 감소 필요.
- 읽기 라우팅—지연에 민감한 조회(쓰기 직후 읽기)가 Replica로 가지 않는지 봅니다.
- 장애 전환—Failover 후 애플리케이션 연결 문자열과 권한이 정상인지 점검합니다.
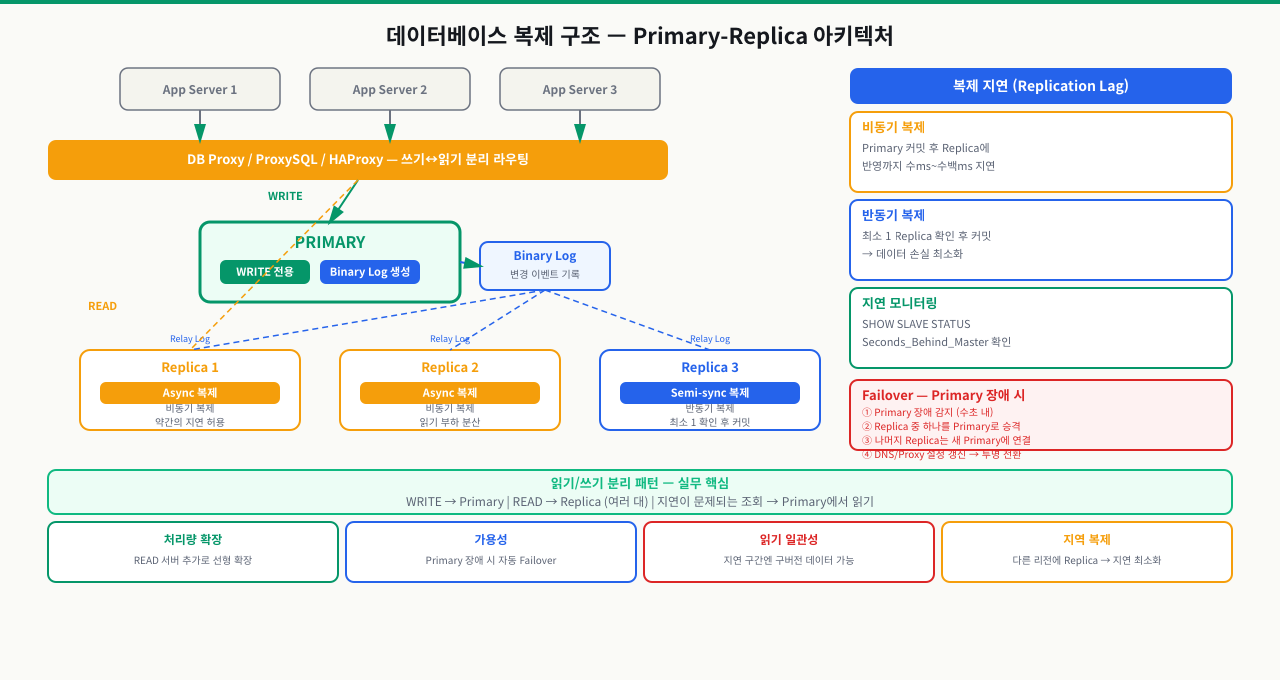
복제가 필요한 두 가지 이유
이유 1: 고가용성 (High Availability) — 단일 DB와 복제 구성의 장애 대응 차이입니다.
단일 DB:
[웹서버] → [DB 서버 (장애!)] → 서비스 전체 다운
복제 구성:
[웹서버] → [Primary DB] → 실시간 복제 → [Replica DB]
↓ 장애 발생
[Replica가 Primary로 승격] → 서비스 지속
이유 2: 읽기 스케일아웃 (Read Scale-out) — 읽기 트래픽을 Replica 여러 대로 분산합니다.
DAU 100만 서비스 — 쿼리 비율: 읽기 95%, 쓰기 5%
단일 DB: [모든 쿼리] → [DB 서버 1대] → 병목
Read Replica:
[쓰기 쿼리] → [Primary DB]
[읽기 쿼리] → [Replica 1]
→ [Replica 2]
→ [Replica 3] ← 읽기 부하를 N대로 분산
언제 복제가 필요한가:
- 일일 방문자 수만 명 이상의 서비스
- DB 다운 허용 시간이 수 분 이내인 서비스
- 읽기 쿼리가 쓰기의 10배 이상인 경우
- 분석/리포트 쿼리가 운영 DB에 부하를 주는 경우
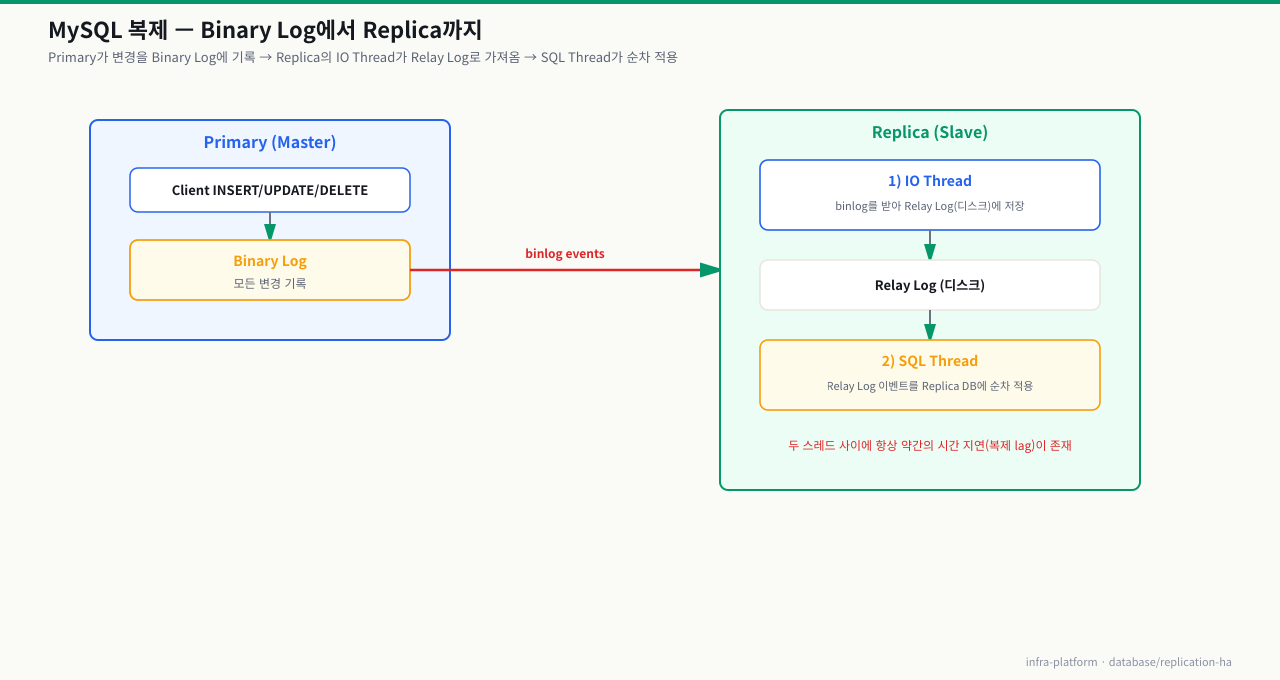
복제 원리 — 바이너리 로그와 두 개의 스레드
MySQL 복제가 어떻게 동작하는지 알면, 복제 지연이 왜 생기는지 이해할 수 있습니다.
 확대
확대
핵심 포인트:
- Primary는 모든 변경(INSERT/UPDATE/DELETE)을 Binary Log에 기록
- Replica의 IO Thread가 이 로그를 가져와 Relay Log에 저장
- SQL Thread가 Relay Log를 순차로 실행해서 Replica DB에 반영
- IO Thread와 SQL Thread 사이에 항상 약간의 시간 지연이 존재
복제가 "살아 있는지"와 "얼마나 뒤처졌는지"는 다른 문제입니다. Replica에서 상태를 조회해 두 스레드가 모두 Yes인지, 그리고 Seconds_Behind_Source가 0에 가까운지 확인합니다(PostgreSQL은 pg_stat_replication).
-- MySQL: Replica에서
SHOW REPLICA STATUS\G
-- PostgreSQL: Primary에서 각 replica의 지연(바이트) 확인
SELECT client_addr, state,
pg_wal_lsn_diff(sent_lsn, replay_lsn) AS replay_lag_bytes
FROM pg_stat_replication;
-- MySQL SHOW REPLICA STATUS\G (발췌)
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
Seconds_Behind_Source: 0
-- PostgreSQL pg_stat_replication
client_addr | state | replay_lag_bytes
-------------+-----------+------------------
10.0.1.21 | streaming | 0
SHOW REPLICA STATUS\G- IO/SQL 두 스레드가 모두 Yes인지 먼저 본다 — 하나라도 No면 복제가 멈춘 것(Last_Error 컬럼에서 원인 확인). Yes인데 지연만 큰 것과 구분해야 한다
- Seconds_Behind_Source(또는 replay_lag_bytes)가 0~수 초인지 확인 — 계속 증가하면 Replica가 쓰기를 따라잡지 못하는 것(Replica 사양·디스크 I/O 병목 의심)
- 지연이 크면 그 Replica로 읽기를 보내는 서비스는 '오래된 데이터'를 보게 된다 — 읽기 분산 시 일관성 요구가 높은 조회는 Primary로 보내는지 점검
- Seconds_Behind_Source가 NULL이면 IO 스레드가 끊겨 측정 불가 상태 — 연결/권한/네트워크부터 확인한다
커밋 한 건이 복제본까지 도달하는 5단계 — WAL과 복제
COMMIT 한 건이 WAL을 거쳐 복제본에 반영되고 읽히기까지 5단계
앞에서 binlog와 IO/SQL 두 스레드로 복제의 뼈대를 봤습니다. 한 단계 더 들어가면, "결제가 커밋됐다"는 응답이 돌아온 순간 데이터가 정확히 어디까지 안전해졌는지, 그리고 그게 복제본에서 언제 읽히는지가 갈립니다. 커밋이 WAL에 적히고 복제본까지 도달해 읽히는 경로를 단계로 보면, 복제 지연·데이터 유실·스플릿 브레인이 각각 이 경로의 어느 지점에서 생기는지 한눈에 들어옵니다.
COMMIT (Primary)
│
① WAL(redo/binlog)에 변경을 먼저 기록하고 fsync → "커밋 성공" 응답
│ durability: 이 시점 이후엔 크래시가 나도 WAL에서 복구된다
│
② WAL 레코드를 복제본으로 전송 (스트리밍)
│ ─[비동기] ②를 기다리지 않고 이미 커밋 완료 → 빠름 / 유실 위험
│ ─[반동기] 복제본이 "받았다" 확인까지 기다린 뒤 커밋 응답
│ ─[동기] 설정한 동기 복제본의 내구성 있는 기록·확인을 기다림 → 구성된 장애 범위에서 RPO를 크게 줄임 / 가장 느림
│
③ 복제본: 받은 WAL을 relay/redo 로그에 저장 (IO 스레드)
│
④ 복제본: WAL을 재생(apply)해 자기 데이터에 반영 (SQL 스레드)
│ ③과 ④ 사이의 시차 = 복제 지연(replication lag)
│
⑤ 읽기 라우팅: 지연 허용 조회 → 복제본 / 방금 쓴 것 읽기 → Primary
▼
복제본에서도 같은 데이터가 읽힘 (지연만큼 늦게)
각 단계가 하는 일과, 여기서 어긋나면 생기는 문제:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① WAL 기록 | 변경을 로그에 먼저 쓰고 fsync해야 커밋 확정(durability) | WAL을 안전히 못 남기면 크래시 시 "커밋됐다던" 트랜잭션이 사라짐 |
| ② 전송(동기성 선택) | Primary가 복제본을 얼마나 기다리고 커밋을 확정할지 결정 | 비동기는 장애 시 아직 못 보낸 마지막 트랜잭션 유실(RPO = 지연) / 동기는 매 쓰기가 네트워크 왕복만큼 느려짐 |
| ③ 수신 | 복제본 IO 스레드가 WAL을 relay에 적재 | IO 스레드가 끊기면 복제 중단 — Seconds_Behind_Source가 NULL |
| ④ 재생 | 단일 SQL 스레드가 WAL을 순차 apply | 대량 쓰기를 못 따라가면 지연이 계속 증가 → 복제본이 오래된 데이터를 보여줌(stale read) |
| ⑤ 읽기 분산 | 일관성 요구에 따라 Primary/복제본으로 라우팅 | 방금 쓴 것을 복제본에서 읽으면 "저장했는데 없다" 버그(Read-Your-Writes 위반) |
즉 복제의 안전성과 지연은 ①(언제 커밋을 확정하나)과 ②(얼마나 기다렸다 보내나)에서 결정되고, 개발자가 흔히 만나는 "방금 쓴 게 없다"는 ④~⑤의 지연 문제입니다. 페일오버 시 ④까지 재생되지 못한 WAL은 그대로 유실되므로(RPO), 승격 전에 "정확히 하나의 Primary만 ①을 수행"하도록 옛 Primary를 격리(펜싱)하지 않으면 두 노드가 각자 WAL을 쌓는 스플릿 브레인이 됩니다 — 이 위험은 아래 심화에서 자세히 다룹니다.
RDS Multi-AZ vs Read Replica — 클라우드가 대신 해주는 것
온프레미스에서는 MHA, ProxySQL, 3대의 서버, SSH 키 설정 등 복잡한 구축이 필요합니다. AWS RDS는 이것들을 클릭 몇 번으로 제공합니다.
 확대
확대
| 구분 | Multi-AZ | Read Replica |
|---|---|---|
| 목적 | 고가용성 (HA) | 읽기 분산 |
| 복제 방식 | 동기식(구성된 장애 범위에서 RPO를 줄임) | 비동기(지연·최근 변경 유실 가능성) |
| Standby 읽기 | 불가 (대기만 함) | 가능 (읽기 전용) |
| 자동 페일오버 | 있음 (시간은 엔진·구성·장애에 따라 다름) | 없음 (수동 승격) |
| 추가 비용 | 인스턴스 2배 | Replica 수만큼 |
| 언제 쓰나 | 운영 DB 필수 | 읽기 많은 서비스 |
# 이런 코드가 문제를 만듭니다
def register_user(data):
db_write.execute("INSERT INTO users ...", data) # Primary에 쓰기
user = db_read.query("SELECT * FROM users WHERE email = ?", data["email"])
# ↑ Replica에서 읽기 → 복제 지연으로 방금 쓴 데이터가 아직 없을 수 있음!
send_welcome_email(user) # user가 None이면 에러
원인: 쓰기는 Primary, 읽기는 Replica — 복제 지연 때 문제 발생.
해결 패턴 1: 쓰기 직후 읽기는 Primary에서 — 복제 지연을 우회하는 가장 단순한 방법입니다.
def register_user(data):
db_write.execute("INSERT INTO users ...", data)
# 방금 쓴 데이터는 Primary에서 읽기
user = db_write.query("SELECT * FROM users WHERE email = ?", data["email"])
send_welcome_email(user)
해결 패턴 2: 방금 INSERT한 ID 활용 (DB 왕복 없이) — Replica 조회 없이 INSERT 결과를 바로 씁니다.
def register_user(data):
result = db_write.execute("INSERT INTO users ...", data)
user_id = result.lastrowid # INSERT한 ID를 바로 활용
# Replica에서 조회하지 않고 ID로 직접 처리
send_welcome_email(user_id=user_id, email=data["email"])
설계 원칙: Read-Your-Writes 패턴 — 어떤 요청을 Primary, Replica로 보낼지 기준입니다.
Primary (쓰기 + 즉시 읽기 필요한 경우):
- 회원가입 후 프로필 조회
- 결제 후 주문 확인
- 설정 변경 후 확인 화면
Replica (복제 지연 허용 가능한 조회):
- 상품 목록/검색
- 통계/대시보드
- 다른 사용자의 게시물 조회
심화 — '자동 페일오버'가 데이터를 둘로 쪼갤 때
심화: 페일오버의 진짜 난제는 승격이 아니라 '펜싱'이다
앞에서 페일오버를 "Primary가 죽으면 Replica를 승격해 서비스가 이어진다"로 설명했습니다. 그런데 현장에서 가장 무서운 사고는 승격이 실패해서가 아니라, 승격은 됐는데 옛 Primary가 안 죽어서 벌어집니다.
- 스플릿 브레인: 페일오버 컨트롤러와 Primary 사이 네트워크가 잠깐 끊기면, 컨트롤러는 "Primary 다운"으로 판단해 Replica를 승격합니다. 하지만 옛 Primary는 실제로는 살아 있고(그저 컨트롤러에서 안 보였을 뿐), DNS/VIP가 완전히 넘어가기 전까지 일부 앱 서버는 여전히 옛 Primary에 씁니다. 이제 두 Primary가 각자 다른 쓰기를 받아 데이터가 갈라집니다.
- 그래서 핵심은 펜싱(fencing): 승격 전에 옛 Primary가 더는 쓰기를 못 받도록 확실히 격리해야 합니다 — VIP 회수, 노드 강제 종료(STONITH), 쿼럼(과반)으로 한쪽만 승자가 되게 하기. RDS Multi-AZ가 "자동 페일오버"라고 말할 때 실제로 어려운 일이 이 펜싱이고, 관리형이 이를 대신 해 줍니다.
- 비동기 승격은 데이터를 잃는다: 스플릿 브레인이 아니어도, N초 뒤처진 비동기 Replica를 승격하면 그 N초 동안 옛 Primary가 커밋한 트랜잭션은 사라집니다(RPO = 페일오버 시점의 지연). 준동기(semi-sync)로 이 손실을 제한할 수 있지만 쓰기 지연이 늘어납니다.
- 옛 Primary를 함부로 되붙이면 안 된다: 스플릿 브레인 동안 옛 Primary가 커밋했지만 새 Primary엔 없는 트랜잭션은 errant(고아) 트랜잭션입니다. GTID 집합이 갈라져, 그냥 복제로 되붙이면 붙지 않거나 데이터가 오염됩니다.
정리하면, HA는 "Replica를 하나 더 두는 것"이 아니라 "언제나 정확히 하나의 Primary만 쓰기를 받게 만드는 규율"입니다. 자동 페일오버를 켜기 전에 "옛 Primary는 어떻게 확실히 멈추나"를 먼저 설계해야 합니다.
상황: 짧은 네트워크 순단으로 페일오버 컨트롤러가 Replica를 새 Primary로 승격했습니다. 하지만 옛 Primary는 실제로 죽지 않았고, VIP가 완전히 넘어가기까지 약 30초 동안 일부 앱 서버가 계속 옛 Primary에 주문을 썼습니다. 사고 후 보니 새 Primary에 없는 주문이 옛 Primary에 있고, 반대로 옛 Primary에 없는 주문이 새 Primary에 있습니다.
원인: 펜싱이 없었습니다. 페일오버가 "승격"만 했을 뿐 옛 Primary가 쓰기를 멈추는 것을 보장하지 못해 스플릿 브레인이 생겼습니다. 게다가 비동기 복제라 승격 시점에 새 Primary는 옛 Primary의 마지막 트랜잭션 일부를 아직 못 받은 상태였습니다.
진단: 두 노드의 GTID 집합(또는 타임라인)을 비교해 어느 쪽에만 있는 트랜잭션이 무엇인지 찾습니다.
-- 두 노드에서 각각 실행해 gtid_executed를 비교
SELECT @@GLOBAL.gtid_executed;
-- 새 Primary에는 없고 옛 Primary에만 있는 GTID = errant(고아) 트랜잭션
-- 애플리케이션 쓰기 로그에서 페일오버 시작 이후 옛 엔드포인트로 간 쓰기를 대조
한쪽에만 있는 트랜잭션(errant)이 확인되고, 앱 로그상 페일오버 개시 후에도 옛 엔드포인트로 쓰기가 들어갔다면 스플릿 브레인 확정입니다.
해결: 새 Primary를 단일 진실 원본으로 확정합니다. 옛 Primary에만 있던 주문은 수동으로 추출·검토해 새 Primary에 반영할지 결정하고(비즈니스 판단), 옛 Primary 자체는 CHANGE MASTER로 되붙이지 말고 새 Primary의 최신 백업/스냅샷으로 처음부터 다시 만들어(rebuild) 복제에 붙입니다 — errant GTID가 남은 노드를 그대로 붙이면 복제가 깨집니다. 재발 방지로는 (1) 펜싱(VIP 회수·STONITH·쿼럼) 도입, (2) 준동기 복제로 RPO 제한, (3) 앱이 "진짜 Primary인지" 확인 못 하면 쓰기를 막는(fail-closed) 설계, (4) 가능하면 펜싱을 대신 해 주는 관리형 페일오버(RDS Multi-AZ) 사용을 적용합니다.
개발자가 DB 복제 관련 알아야 하는 것
RTO/RPO — 장애 대응 기준 수립: 팀원과 공통 언어로 장애 허용 범위를 정의하는 방법입니다.
팀장: "우리 DB 죽으면 얼마나 버틸 수 있어요?"
RTO (Recovery Time Objective) — 복구 목표 시간
- "서비스가 최대 X분 다운돼도 된다"
- RDS Multi-AZ: ~60초 자동 페일오버
RPO (Recovery Point Objective) — 데이터 유실 허용 범위
- "최대 X분치 데이터가 사라져도 된다"
- RDS Multi-AZ (동기 복제): 일반적으로 RPO 0을 목표로 하지만 장애 유형·서비스 보장 범위와 설정을 확인해야 함
- Read Replica (비동기 복제): RPO = 복제 지연만큼
ORM에서 읽기/쓰기 분리: Django, SQLAlchemy 등 ORM에서 읽기/쓰기 DB를 구분하는 설정 예시입니다.
# Django
DATABASES = {
'default': { # 쓰기용 Primary
'HOST': 'rds-primary.xxxxx.rds.amazonaws.com'
},
'replica': { # 읽기용 Replica
'HOST': 'rds-replica.xxxxx.rds.amazonaws.com'
}
}
# 쓰기 직후 읽어야 하는 경우 using('default')로 강제
user = User.objects.using('default').get(id=user_id)
# 일반 조회는 replica 사용 (Router 설정 시 자동)
users = User.objects.all() # → Replica로 자동 라우팅
복제 지연 모니터링 (CloudWatch): ReplicaLag 수치로 복제 상태를 판단하는 기준입니다.
RDS 메트릭: ReplicaLag (초 단위)
- 0~1초: 정상
- 1~10초: 주의 (쓰기 집중 작업 있는지 확인)
- 10초 이상: 위험 (배치 작업, 대용량 마이그레이션 확인)
알람 설정: ReplicaLag > 30초 → SNS 알림
복제 원리를 알면 "왜 방금 저장한 데이터가 조회가 안 되지?"라는 버그의 원인을 즉시 파악하고, RDS 구성 시 Multi-AZ vs Read Replica 선택을 제대로 할 수 있습니다. 클라우드 관리형 DB에서 이 둘(가용성용 멀티AZ vs 읽기 확장용 읽기 복제본)을 구분해 설계하는 법은 관리형 데이터베이스(RDS)(Cloud Engineering 트랙)에서 다룹니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 복제 상태 점검·운영 명령을 모았습니다(MySQL·PostgreSQL·RDS).
| 구문/명령 | 용도 | 예 |
|---|---|---|
SHOW REPLICA STATUS\G | MySQL 복제 상태·지연 확인 | Replica_IO_Running / Replica_SQL_Running = Yes 확인 |
Seconds_Behind_Source | MySQL 복제 지연(초) | 0 정상 / 60s↑ 위험 / NULL 복제 중단 |
pg_stat_replication | PostgreSQL 복제 지연 | SELECT client_addr, state, replay_lag FROM pg_stat_replication |
pg_wal_lsn_diff | 복제 지연을 바이트로 계산 | pg_wal_lsn_diff(sent_lsn, replay_lsn) AS lag_bytes |
@@GLOBAL.gtid_executed | 노드별 GTID 비교(errant 탐지) | SELECT @@GLOBAL.gtid_executed (두 노드 대조) |
CHANGE REPLICATION SOURCE | Replica가 볼 Primary 지정 | 스플릿 브레인 후 errant 노드엔 되붙이지 말고 rebuild |
slave_parallel_workers | 병렬 복제로 지연 완화 | Primary 쓰기 폭주로 SQL 스레드가 못 따라갈 때 |
| 읽기 라우팅 강제(ORM) | 쓰기 직후 읽기는 Primary | Django User.objects.using('default').get(…) |
CloudWatch ReplicaLag | RDS 복제 지연 알람 | ReplicaLag > 30s → SNS 알림 |
다음 모듈에서는 실시간 DB 모니터링 체계 구축과 슬로우 쿼리 슬랙 알림 설정 방법을 다룹니다.