NULL은 빈 문자열이나 0이 아니라 “모름”을 의미합니다. 이 차이를 놓치면 조건문, 집계, JOIN 결과가 예상과 다르게 나옵니다. NULL 처리 규칙을 정확히 알아야 데이터 누락과 잘못된 통계를 피할 수 있습니다.
NULL의 3값 논리를 이해하면 WHERE 조건의 예상치 못한 결과, NOT IN 함정, 집계함수의 NULL 무시 등 흔한 SQL 버그를 예방할 수 있습니다.
- 1TRUE, FALSE, UNKNOWN의 3값 논리를 이해하고 쿼리 결과를 예측할 수 있다
- 2NULL과 비교 연산자의 함정을 피해 WHERE 조건을 올바르게 작성할 수 있다
- 3NOT IN 리스트에 NULL이 있을 때의 치명적 문제를 진단하고 예방할 수 있다
- 4COALESCE로 NULL을 기본값으로 안전하게 대체할 수 있다
- 5NULLIF로 특정 값을 NULL로 변환할 수 있다
- 6IS DISTINCT FROM으로 NULL 안전 비교를 작성할 수 있다
NULL 처리 — IS NULL, COALESCE, NULLIF 함정들
월별 활성 사용자 집계를 짜서 올렸더니, QA에서 숫자가 이상하다고 돌아왔다. 분명히 맞게 짠 것 같은데 총합이 실제보다 적었다. 한참 뒤에 발견했다 — phone 컬럼이 NULL인 사용자들이 WHERE 조건에서 통째로 빠지고 있었다. WHERE phone != '삭제됨' 이라고 썼는데, NULL != '삭제됨'은 TRUE가 아니라 UNKNOWN이 돼서 그 행들이 모두 제외된 거였다. 그날 처음 알았다, NULL은 빈 값이 아니라 "모른다"는 의미라서 일반 비교 연산자가 통하지 않는다는 걸. NULL 하나 때문에 집계 버그가 생기고, NOT IN에 NULL이 섞이면 결과가 0건이 되고, COUNT(*) 와 COUNT(column)이 다르게 나온다. 이 챕터를 지나면 NULL 관련 버그를 QA에서 잡히기 전에 먼저 잡을 수 있게 된다.
NULL의 3값 논리 — NULL = NULL이 FALSE인 이유
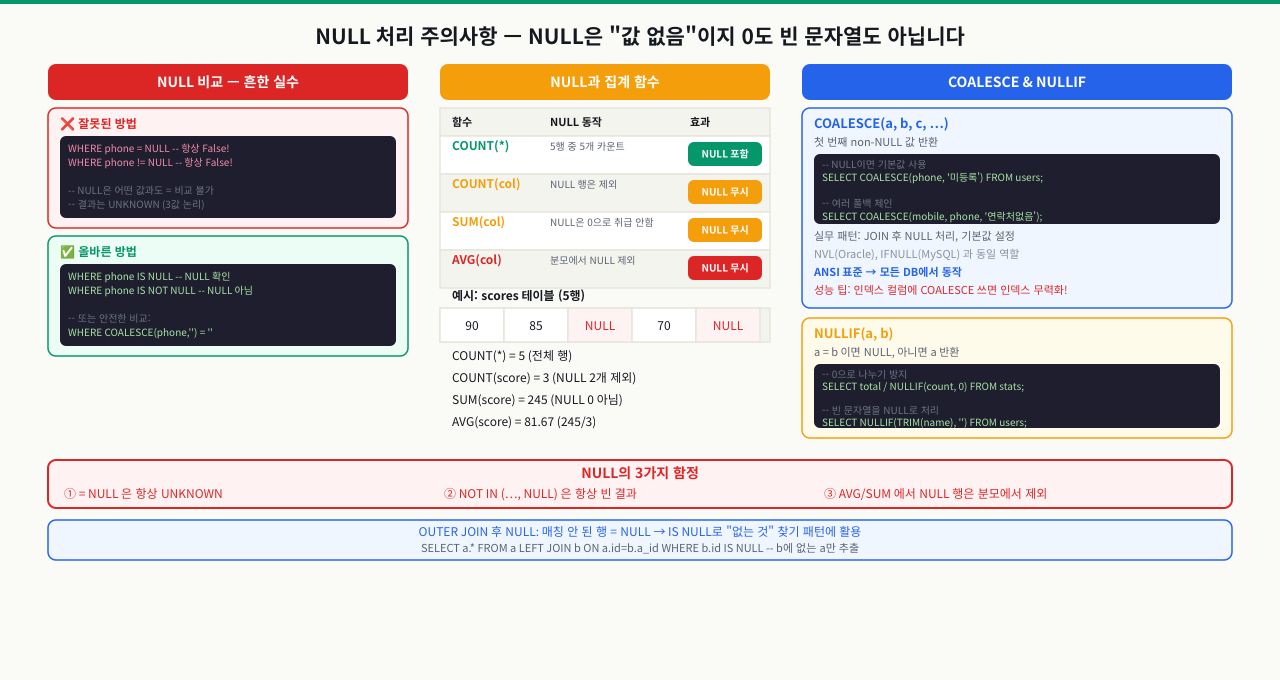
WHERE email = NULL로 쿼리를 짰는데 결과가 없습니다. 분명히 NULL인 데이터가 있는데 왜 조회가 안 되는지 모릅니다. NULL = NULL은 TRUE가 아니라 UNKNOWN입니다. 이 3값 논리를 이해하지 못하면 NULL 관련 쿼리에서 계속 예상과 다른 결과를 보게 됩니다.
 확대
확대
NULL은 '알 수 없음'이다
NULL은 "값이 없다"가 아니라 "값을 알 수 없다"를 의미합니다. 이 차이가 SQL에서 NULL이 특별하게 동작하는 근본 이유입니다. "알 수 없는 값"과 어떤 값을 비교하면 그 결과 역시 "알 수 없음(UNKNOWN)"입니다. NULL = NULL조차 "두 개의 알 수 없는 값이 같은지 알 수 없다"는 이유로 UNKNOWN을 반환합니다.
NULL을 확인하는 유일한 올바른 방법은 IS NULL과 IS NOT NULL입니다.
SELECT
NULL = NULL AS "NULL = NULL",
NULL != NULL AS "NULL != NULL",
NULL = 1 AS "NULL = 1",
NULL != 1 AS "NULL != 1",
NULL IS NULL AS "NULL IS NULL",
NULL IS NOT NULL AS "NULL IS NOT NULL";
실행 완료 또는 조회 결과가 표시됩니다.
- IS NULL vs = NULL 먼저: = NULL 결과가 항상 0행이면 정상(UNKNOWN 반환). IS NULL로 바꿔야 NULL 행이 조회됨 — 이 차이를 확인하지 않으면 집계 누락 버그의 원인을 못 찾음
- COUNT 차이로 NULL 수 계산: COUNT(*)가 COUNT(salary)보다 크면 그 차이가 NULL 행 수. 전체 4행에서 COUNT(salary)=3이면 NULL 1행이 집계에서 제외된 것
- NOT IN + NULL 조합 해석: NOT IN 리스트나 서브쿼리에 NULL이 하나라도 있으면 결과가 0건 → 반드시 NOT EXISTS나 LEFT JOIN + IS NULL 패턴으로 교체
결과: 처음 네 비교는 모두 NULL(UNKNOWN)이고, IS NULL만 TRUE, IS NOT NULL만 FALSE를 반환합니다.
3값 논리(3VL) — AND/OR 진리표
SQL은 TRUE/FALSE의 2값 논리가 아닌 TRUE/FALSE/UNKNOWN의 3값 논리를 사용합니다. UNKNOWN이 포함된 논리 연산 결과를 이해해야 WHERE 절의 동작을 예측할 수 있습니다.
AND 진리표 — FALSE가 하나라도 있으면 FALSE, 나머지는 UNKNOWN이 전파됩니다:
| AND | TRUE | FALSE | UNKNOWN |
|---|---|---|---|
| TRUE | TRUE | FALSE | UNKNOWN |
| FALSE | FALSE | FALSE | FALSE |
| UNKNOWN | UNKNOWN | FALSE | UNKNOWN |
OR 진리표 — TRUE가 하나라도 있으면 TRUE, 나머지는 UNKNOWN이 전파됩니다:
| OR | TRUE | FALSE | UNKNOWN |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE | UNKNOWN |
| UNKNOWN | TRUE | UNKNOWN | UNKNOWN |
WHERE 절은 결과가 TRUE인 행만 반환합니다. UNKNOWN은 FALSE와 같은 효과를 냅니다. 이것이 NULL 비교가 포함된 조건에서 예상치 못하게 행이 제외되는 이유입니다.
WHERE 절에서 NULL 함정
부서가 NULL인 직원이 "개발팀이 아닌 직원" 필터에서 누락되는 경우입니다. NULL != '개발팀'은 UNKNOWN이 되어 WHERE에서 제외됩니다.
CREATE TABLE employees (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
department VARCHAR(50),
salary NUMERIC(10, 2)
);
INSERT INTO employees (name, department, salary) VALUES
('김철수', '개발팀', 5000000),
('이영희', '마케팅', 4500000),
('박민준', NULL, 3800000),
('최수진', '개발팀', NULL);
SELECT * FROM employees WHERE department != '개발팀';
SELECT * FROM employees
WHERE department != '개발팀'
OR department IS NULL;
첫 번째 쿼리는 박민준(department=NULL)을 누락합니다. 두 번째 쿼리에서 OR department IS NULL을 추가하면 박민준도 포함됩니다.
NULL 값을 필터링하려고 = NULL을 사용하면 항상 결과가 비어 있습니다.
SELECT * FROM employees WHERE department = NULL;
SELECT * FROM employees WHERE salary != NULL;
department = NULL은 UNKNOWN을 반환하고, WHERE는 UNKNOWN을 FALSE로 취급하여 모든 행이 제외됩니다. 이 실수는 쿼리가 오류 없이 실행되고 단지 결과가 0건이기 때문에 발견하기 어렵습니다.
NULL 비교에는 반드시 IS NULL 또는 IS NOT NULL을 사용해야 합니다.
SELECT * FROM employees WHERE department IS NULL;
SELECT * FROM employees WHERE salary IS NOT NULL;
NOT IN 함정 — 가장 위험한 NULL 버그
NOT IN 리스트에 NULL이 포함되면 전체 쿼리 결과가 0건이 됩니다. 이유는 x NOT IN (1, 2, NULL)이 x != 1 AND x != 2 AND x != NULL로 전개되는데, x != NULL이 항상 UNKNOWN이 되어 AND 전체가 UNKNOWN이 되기 때문입니다.
SELECT * FROM products
WHERE category_id NOT IN (1, 2, NULL);
이 쿼리는 결과가 0건입니다. 리스트에 NULL이 포함되어 있으면 어떤 category_id 값도 UNKNOWN 비교를 피할 수 없습니다.
 확대
확대
서브쿼리가 반환하는 컬럼에 NULL이 단 하나라도 있으면 NOT IN 전체가 0건을 반환합니다. 문제는 서브쿼리 결과에 NULL이 있는지 직접 확인하지 않으면 원인을 찾기 어렵다는 점입니다.
SELECT * FROM orders
WHERE customer_id NOT IN (
SELECT customer_id FROM blacklist
);
blacklist.customer_id에 NULL 값이 하나라도 있으면 이 쿼리는 아무 행도 반환하지 않습니다.
안전한 대안은 NOT EXISTS 또는 LEFT JOIN + IS NULL 패턴입니다.
SELECT * FROM orders o
WHERE NOT EXISTS (
SELECT 1 FROM blacklist b
WHERE b.customer_id = o.customer_id
);
SELECT o.* FROM orders o
LEFT JOIN blacklist b ON o.customer_id = b.customer_id
WHERE b.customer_id IS NULL;
NOT EXISTS는 NULL에 안전합니다. 서브쿼리 내에서 NULL = o.customer_id가 UNKNOWN이 되어도 EXISTS 자체는 FALSE로 처리되어 NOT EXISTS는 TRUE가 됩니다.
머리로 아는 것과 직접 0행을 보는 것은 다릅니다. blacklist에 NULL을 한 건 넣어 NOT IN이 통째로 0건이 되는 걸 재현하고, 같은 의도를 NOT EXISTS로 바꿔 정상 동작을 확인합니다.
-- blacklist에 NULL이 섞이도록 한 건 삽입
INSERT INTO blacklist (customer_id) VALUES (NULL);
-- (버그) NOT IN — 리스트에 NULL이 있어 결과가 0건
SELECT count(*) AS not_in_result
FROM orders
WHERE customer_id NOT IN (SELECT customer_id FROM blacklist);
-- (정답) NOT EXISTS — NULL에 안전
SELECT count(*) AS not_exists_result
FROM orders o
WHERE NOT EXISTS (
SELECT 1 FROM blacklist b WHERE b.customer_id = o.customer_id
);
not_in_result
---------------
0 -- 주문이 있어도 0건 (NULL 때문에 전부 UNKNOWN)
not_exists_result
-------------------
1280 -- 실제 블랙리스트 제외 주문 수
SELECT count(*) FROM orders WHERE customer_id NOT IN (SELECT customer_id FROM blacklist);- not_in_result 가 0인지 먼저 본다 — 주문 데이터가 분명히 있는데 0이면 NULL이 NOT IN을 통째로 무력화한 것이다(버그 재현 성공)
- not_exists_result 는 0이 아닌 실제 건수가 나와야 한다. 두 값이 다르다는 사실 자체가 'NOT IN을 NOT EXISTS로 바꿔야 하는 이유'다
- 원인 확인: SELECT count(*) FROM blacklist WHERE customer_id IS NULL 로 NULL이 실제로 섞였는지 본다. 1건 이상이면 NOT IN은 항상 위험
- 운영 규칙: 서브쿼리 기반 제외는 NOT IN 대신 NOT EXISTS 또는 LEFT JOIN ... IS NULL을 기본으로 쓴다
"직원 수와 평균 급여를 계산했는데 숫자가 맞지 않는다"는 보고서 버그가 발생합니다. 이 문제의 원인은 집계 함수가 NULL을 처리하는 방식에 있습니다.
COUNT(*)는 모든 행을 셉니다. 반면 COUNT(salary)는 salary가 NULL인 행을 제외합니다. AVG(salary) 역시 NULL을 제외한 행의 평균만 계산합니다.
SELECT
COUNT(*) AS 전체직원수,
COUNT(department) AS 부서있는직원수,
COUNT(salary) AS 급여확정직원수,
AVG(salary) AS 평균급여_null제외,
AVG(COALESCE(salary, 0)) AS 평균급여_null을0으로
FROM employees;
결과: 전체직원수=4, 부서있는직원수=3(박민준 NULL 제외), 급여확정직원수=3(최수진 NULL 제외), 평균급여_null제외는 3명 기준 평균, 평균급여_null을0으로는 4명 기준 평균입니다.
어느 쪽이 비즈니스적으로 올바른지는 맥락에 따라 다릅니다. "급여가 아직 확정되지 않은 직원은 평균 계산에서 제외"라면 AVG(salary)가 맞고, "미확정 급여를 0으로 간주"라면 COALESCE 처리가 맞습니다. 중요한 것은 의도를 명시적으로 코드에 표현하는 것입니다.
NULL 하나가 쿼리를 통과하는 5단계 — 미지값이 사라지고 왜곡되는 지점
앞에서 3값 논리를 진리표·WHERE·NOT IN·집계로 나눠서 봤습니다. 이 조각들을 하나로 잇는 가장 좋은 방법은, salary가 NULL인 행 한 개가 쿼리를 위에서 아래로 통과하는 과정을 따라가 보는 것입니다. 그러면 그 행이 정확히 어느 단계에서 조용히 사라지고, 어느 단계에서 숫자를 왜곡하는지가 한눈에 보입니다. NULL 버그는 대부분 "값이 왜 빠졌지"와 "합계가 왜 안 맞지" 두 가지인데, 둘 다 이 흐름의 특정 지점에서 생깁니다.
salary = NULL 인 행 하나가 아래 쿼리를 통과한다
SELECT department, AVG(salary) FROM employees WHERE salary > 3000000 GROUP BY department
│
① 값의 정체 — NULL = '값이 없음 / 알 수 없음'(미지)
│ 빈 문자열('')도 0도 아니다. "모른다"는 표식일 뿐
│
② 산술·비교에 NULL 전파 — salary > 3000000 을 평가
│ NULL > 3000000 = UNKNOWN (TRUE도 FALSE도 아님)
│ NULL + 1, NULL = NULL, NULL != '개발팀' 도 전부 NULL/UNKNOWN
│
③ WHERE는 TRUE만 통과 — UNKNOWN 행은 탈락
│ 이 행은 UNKNOWN이라 결과에서 조용히 사라진다(에러 없음)
│ = NULL·!= 값 필터에서 NULL 행이 빠지는 바로 그 지점
│
④ 집계는 NULL을 무시 — 살아남아도 COUNT/AVG에서 제외
│ COUNT(salary)·AVG(salary)는 NULL 행을 세지 않는다
│ COUNT(*)와 값이 갈리고, 평균의 분모가 달라진다
│
⑤ 명시적 처리 — IS NULL / COALESCE 로 의도를 못박음
▼
여기서 손대지 않으면 ②~④가 결과를 말없이 바꾼다
각 단계에서 무슨 일이 일어나고, 어떤 함정이 생기나:
| 단계 | 하는 일 | 여기서 생기는 함정 |
|---|---|---|
| ① 값의 정체 | NULL은 '미지값' 표식 — 빈 문자열·0과 다르다 | ''이나 0으로 착각해 = ''·= 0으로 거르면 NULL 행이 안 잡힘 |
| ② NULL 전파 | 산술·비교 결과가 NULL 또는 UNKNOWN | WHERE col = NULL은 항상 0행 — 등호로는 영영 못 잡음(→ IS NULL) |
| ③ WHERE 필터 | TRUE인 행만 통과, UNKNOWN은 탈락 | != '개발팀'이 NULL 부서를 누락, NOT IN (1, 2, NULL)은 전건 UNKNOWN → 0건 |
| ④ 집계 | COUNT(col)·AVG·SUM이 NULL을 건너뜀 | COUNT(*)와 COUNT(col)이 불일치, 평균이 'NULL 아닌 행 수'로만 나뉘어 왜곡 |
| ⑤ 명시 처리 | IS NULL·COALESCE·IS DISTINCT FROM으로 의도 표현 | 생략하면 ②~④가 에러 없이 조용히 결과를 바꿈 |
즉 "NULL 행이 사라졌다"는 ② 전파 → ③ 탈락에서, "숫자가 안 맞다"는 ④ 집계 무시에서 옵니다. 그래서 진단은 두 단계를 나눠 봅니다 — 먼저 COUNT(*)와 COUNT(col)의 차이로 컬럼별 NULL 행 수를 세고(④ 확인), = NULL을 IS NULL로 바꿔 실제로 NULL 행이 있는지 봅니다(②③ 확인). 미지값이 필터·집계·NOT IN 중 어느 단계에 개입했는지를 짚으면, 원인을 한 곳으로 좁힐 수 있습니다.
COALESCE, NULLIF, NULLS FIRST/LAST — NULL 다루는 함수들
NULL을 포함한 컬럼을 화면에 표시하면 "null"이라는 문자열이 보입니다. 정렬하면 NULL이 맨 앞에 올지 맨 뒤에 올지 DB마다 다릅니다. 나눗셈 분모에 NULL이 들어오면 오류가 납니다. 이런 상황에서 COALESCE, NULLIF, NULLS FIRST/LAST를 쓰면 애플리케이션 코드 없이 SQL에서 바로 처리할 수 있습니다.
COALESCE — NULL을 기본값으로 대체
COALESCE는 인자를 왼쪽부터 평가해 NULL이 아닌 첫 번째 값을 반환합니다. 모든 인자가 NULL이면 NULL을 반환합니다. 연락처 우선순위 폴백, 집계의 NULL을 0으로 처리, 디스플레이용 기본값 설정에 광범위하게 사용됩니다.
SELECT
name,
COALESCE(nickname, name) AS 표시이름,
COALESCE(phone, '연락처 없음') AS 연락처,
COALESCE(salary, 0) AS 급여
FROM employees;
SELECT
COALESCE(mobile_phone, office_phone, home_phone, '연락 불가') AS 대표연락처
FROM contacts;
SELECT
SUM(COALESCE(bonus, 0)) AS 총보너스,
AVG(COALESCE(score, 50)) AS 평균점수
FROM employees;
NULLIF — 특정 값을 NULL로 변환
NULLIF(a, b)는 a = b이면 NULL을 반환하고, 다르면 a를 반환합니다. 가장 일반적인 사용 패턴은 0으로 나누기 방지입니다.
SELECT
NULLIF(status, 'unknown') AS clean_status,
NULLIF(score, -1) AS valid_score,
NULLIF(phone, '') AS phone_or_null
FROM users;
SELECT
total_sales,
total_orders,
total_sales / NULLIF(total_orders, 0) AS avg_order_value
FROM monthly_stats;
SELECT
completed_tasks,
total_tasks,
ROUND(completed_tasks * 100.0 / NULLIF(total_tasks, 0), 1) AS completion_rate
FROM projects;
total_orders가 0일 때 NULLIF(total_orders, 0)이 NULL을 반환하고, 나누기 결과도 NULL이 되어 Division by zero 오류를 방지합니다.
IS DISTINCT FROM — NULL 안전 비교
일반 != 연산자는 NULL이 포함되면 UNKNOWN을 반환합니다. IS DISTINCT FROM은 NULL을 하나의 구체적인 값처럼 비교해 항상 TRUE 또는 FALSE를 반환합니다. NULL IS DISTINCT FROM NULL은 FALSE (두 NULL은 같다)이고, 1 IS DISTINCT FROM NULL은 TRUE입니다.
| a | b | a != b (일반) | a IS DISTINCT FROM b |
|---|---|---|---|
| 1 | 1 | FALSE | FALSE |
| 1 | 2 | TRUE | TRUE |
| 1 | NULL | NULL (UNKNOWN) | TRUE |
| NULL | NULL | NULL (UNKNOWN) | FALSE |
SELECT
a,
b,
a != b AS 일반비교,
a IS DISTINCT FROM b AS NULL안전비교
FROM (VALUES
(1, 1),
(1, 2),
(1, NULL),
(NULL, NULL)
) AS t(a, b);
변경 감지 로직에서 IS DISTINCT FROM은 특히 유용합니다. 이전/신규 값 모두 NULL일 수 있는 컬럼을 비교할 때 일반 !=를 쓰면 NULL 컬럼의 변경이 감지되지 않습니다.
UPDATE users
SET
profile_updated_at = NOW(),
version = version + 1
WHERE
old_email IS DISTINCT FROM new_email
OR old_name IS DISTINCT FROM new_name;
ORDER BY에서 NULL 위치 지정
NULL을 포함한 컬럼을 정렬할 때 NULL이 어디 위치할지는 DBMS마다 다릅니다. PostgreSQL은 ASC 정렬에서 NULL이 마지막, DESC 정렬에서 NULL이 처음에 옵니다. NULLS FIRST와 NULLS LAST로 명시적으로 지정하면 DBMS 간 차이 없이 일관된 동작을 보장합니다.
SELECT name, last_login FROM users
ORDER BY last_login DESC NULLS LAST;
SELECT name, salary FROM employees
ORDER BY salary ASC NULLS FIRST;
SELECT name, salary FROM employees
ORDER BY COALESCE(salary, 999999999) ASC;
실전 NULL 처리 패턴 모음
SELECT * FROM contacts
WHERE NULLIF(TRIM(phone), '') IS NOT NULL;
SELECT * FROM products
WHERE (category IS NULL OR category = '미분류')
AND is_active = true;
SELECT
data->>'phone' AS json_phone,
(data->>'phone') IS NULL AS is_missing
FROM user_profiles;
SELECT
COUNT(*) AS total_rows,
COUNT(department) AS has_dept,
COUNT(DISTINCT department) AS unique_dept,
COUNT(DISTINCT COALESCE(department, '미배정')) AS with_null_dept
FROM employees;
NULLIF(TRIM(phone), '')는 공백만 있는 문자열도 NULL로 처리해 "진짜 빈 연락처"를 제외합니다. COUNT(department)는 NULL을 제외하고, COUNT(*)는 포함하므로 두 값의 차이가 NULL 행 수입니다.
심화 — 제약조건 속의 3값 논리
심화: 제약조건과 NULL — CHECK는 UNKNOWN을 통과시키고 UNIQUE는 NULL을 중복 허용한다
지금까지 NULL의 3값 논리가 WHERE·NOT IN·집계에서 어떻게 함정을 만드는지 봤습니다. 그런데 같은 논리가 제약조건(constraint)에서도 그대로 작동합니다 — 그래서 제약을 걸어 두고도 막았다고 믿은 데이터가 새어 나갑니다.
- CHECK는 UNKNOWN을 통과시킵니다. CHECK 제약은 조건이 명시적으로 FALSE인 행만 거부합니다.
CHECK (price > 0)가 걸려 있어도 price가 NULL이면price > 0이 UNKNOWN이 되어 거부되지 않고 저장됩니다. 값의 범위를 강제해도 NULL은 예외가 되는 셈입니다. NULL까지 막으려면 NOT NULL을 함께 걸거나CHECK (price > 0 AND price IS NOT NULL)로 명시합니다. - UNIQUE는 NULL을 서로 다른 값으로 봅니다. 표준 SQL에서 UNIQUE 제약은 두 NULL을 같지 않다고 판단하므로, UNIQUE 컬럼이라도 NULL인 행은 여러 개 존재할 수 있습니다.
email에 UNIQUE를 걸어도 email이 비어(NULL) 있는 계정은 중복으로 생성됩니다. - FOREIGN KEY는 NULL을 검사하지 않습니다. FK 컬럼이 NULL이면 참조 무결성 검사를 건너뜁니다(참조 대상이 없어도 통과). 선택적 관계에서는 유용하지만, 반드시 부모가 있어야 한다면 FK만으로는 부족하고 NOT NULL이 필요합니다.
정리하면, 제약조건은 값이 있을 때의 규칙이고 NULL은 그 규칙의 사각지대입니다. 필수 값에는 NOT NULL을 1순위로 두고, 그 위에 CHECK·UNIQUE·FK를 얹어야 의도한 무결성이 완성됩니다.
상황: users(email)에 UNIQUE 제약을 걸었는데도, 소셜 로그인 등으로 email을 받지 못한 계정이 같은 사용자에 대해 여러 개 만들어졌습니다. 이메일이 채워진 계정은 정상적으로 중복이 막힙니다.
원인: 표준 SQL에서 UNIQUE는 두 NULL을 서로 다른 값으로 취급합니다. 그래서 email이 NULL인 행은 UNIQUE 컬럼이라도 개수 제한 없이 저장됩니다. 이메일이 없으면 하나만 있어야 한다는 기대와 DB의 실제 동작이 어긋난 것입니다.
진단: SELECT count(*) FROM users WHERE email IS NULL로 NULL 행 수를 셉니다. UNIQUE 제약이 있는데도 이 값이 2 이상이면 이 현상입니다. \d users로 제약이 표준 UNIQUE인지 확인합니다.
해결: 실제 값에만 유일성을 강제하려면 부분 유니크 인덱스를 씁니다 — CREATE UNIQUE INDEX ... ON users (email) WHERE email IS NOT NULL. NULL도 하나만 허용하고 싶다면 PostgreSQL 15+의 UNIQUE NULLS NOT DISTINCT를 선언합니다. 근본적으로 email이 필수라면 NOT NULL을 걸고 미입력을 애플리케이션에서 막는 것이 가장 확실합니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 NULL 처리 구문을 안전한 사용 패턴과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
IS NULL / IS NOT NULL | NULL 여부 검사(= NULL 금지) | WHERE deleted_at IS NULL |
COALESCE(a, b, ...) | NULL 아닌 첫 값 반환(기본값·폴백) | COALESCE(mobile_phone, office_phone, '연락 불가') |
NULLIF(a, b) | a=b이면 NULL(0으로 나누기 방지) | total_sales / NULLIF(total_orders, 0) |
IS DISTINCT FROM | NULL 안전 비교(항상 TRUE/FALSE) | old_email IS DISTINCT FROM new_email |
NOT EXISTS (NOT IN 대신) | NULL에 안전한 제외 조건 | WHERE NOT EXISTS (SELECT 1 FROM blacklist b WHERE b.customer_id = o.customer_id) |
LEFT JOIN ... IS NULL | 반조인 패턴(NOT IN 대체) | LEFT JOIN blacklist b ON o.customer_id = b.customer_id WHERE b.customer_id IS NULL |
COUNT(*) vs COUNT(col) | 전체 vs NULL 제외 집계 | 두 값의 차이 = 해당 컬럼 NULL 행 수 |
AVG(COALESCE(col, 0)) | NULL을 0으로 간주해 집계 | AVG(salary)는 NULL 제외 평균 |
ORDER BY ... NULLS FIRST/LAST | 정렬 시 NULL 위치 명시 | ORDER BY last_login DESC NULLS LAST |
... != v OR col IS NULL | != 필터에서 NULL 행 포함 | WHERE department != '개발팀' OR department IS NULL |
CHECK (... AND col IS NOT NULL) | CHECK가 UNKNOWN 통과하는 것 방지 | CHECK (price > 0 AND price IS NOT NULL) |
| 부분 유니크 인덱스 | UNIQUE의 NULL 중복 허용 차단 | CREATE UNIQUE INDEX ... ON users(email) WHERE email IS NOT NULL |
관련 모듈로 더 깊이:
- 실무에서 가장 많이 쓰는 날짜 및 문자열 함수 활용법 — NULLIF·TRIM과 함께 쓰는 문자열 정제 함수들
- GROUP BY와 집계함수의 효율적인 인덱스 활용 — COUNT(컬럼)이 NULL을 제외하는 등 집계에서의 NULL 동작
- N+1 문제, SELECT *, 인덱스 무력화 안티패턴 방지 —
= NULL같은 NULL 관련 흔한 실수 패턴 피하기
다음 모듈에서는 실무에서 가장 자주 쓰이는 날짜 및 문자열 함수와 코호트 분석 활용 패턴을 다룹니다.