처음에는 한 테이블에 모든 정보를 넣는 편이 빨라 보입니다. 하지만 수정할 때마다 여러 행을 같이 바꿔야 하면 데이터 불일치가 생깁니다. 정규화는 이론 문제가 아니라 중복과 갱신 이상을 줄이는 실무 설계 도구입니다.
1NF, 2NF, 3NF를 단계적으로 적용하면 데이터 중복을 제거하고 구조적으로 일관된 스키마를 만들 수 있습니다. 단, 읽기 성능이 중요한 시스템에서는 의도적 역정규화를 고려합니다.
- 1나쁜 스키마가 만드는 3가지 이상 현상을 식별하고 설명할 수 있다
- 21NF를 적용해 원자값과 반복 그룹을 제거할 수 있다
- 32NF를 적용해 복합키 테이블의 부분 함수 종속을 제거할 수 있다
- 43NF를 적용해 이행 함수 종속을 제거할 수 있다
- 5읽기 성능을 위해 언제 역정규화로 정규화를 의도적으로 깰지 판단할 수 있다
정규화(Normalization) — 좋은 스키마 설계 원칙
스타트업 초기, 고객·주문·담당자 정보를 하나의 테이블에 몰아넣었습니다. 처음엔 편했지만 6개월 후 담당자 한 명의 전화번호가 바뀌었을 때 문제가 터졌습니다. 그 담당자가 연결된 주문 행이 32개였고, 모두 따로 UPDATE해야 했습니다. 3개를 빠뜨린 채 커밋했고, 이후 같은 담당자의 연락처가 두 가지 버전으로 데이터베이스에 공존했습니다. 어떤 게 맞는 번호인지 아무도 몰랐습니다.
데이터베이스 스키마를 잘못 설계하면 데이터를 추가하거나 수정하거나 삭제할 때 이런 의도치 않은 문제가 발생합니다. 이를 **이상 현상(Anomaly)**이라 부릅니다. 정규화(Normalization)는 이런 문제를 구조적으로 제거하는 스키마 설계 원칙입니다.
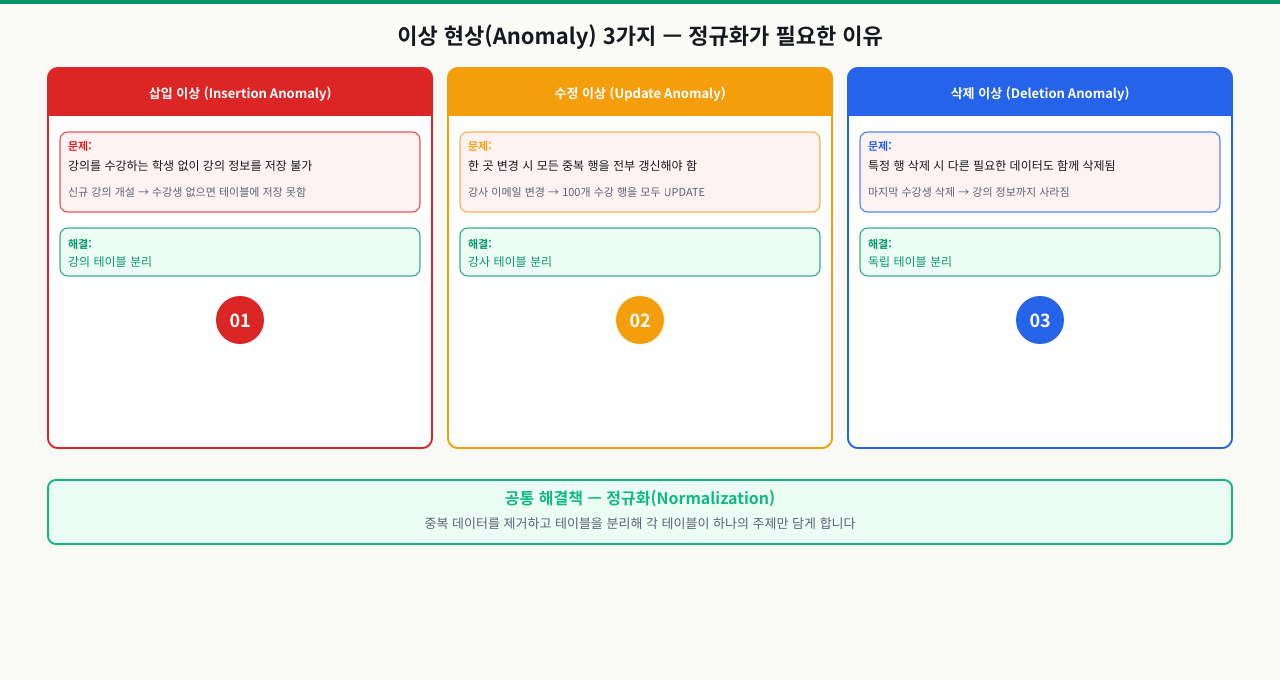
정규화가 필요한 이유 — 이상 현상(Anomaly) 3가지
강사 이름과 강의실 정보가 수강 테이블에 같이 있습니다. 강사가 이름을 바꾸면 그 강사가 담당하는 모든 수강 레코드를 하나씩 업데이트해야 합니다. 하나라도 빠지면 같은 강사인데 이름이 두 개가 됩니다. 이것이 수정 이상입니다. 정규화는 이런 이상 현상을 구조적으로 제거하는 설계 원칙입니다.
 확대
확대
나쁜 스키마 예시 — 모든 것을 한 테이블에
아래는 학생, 수강 과목, 담당 교수를 하나의 테이블에 넣은 비정규화 구조입니다. student_id와 course_id를 복합 PK로 사용한다고 가정합니다.
CREATE TABLE student_courses (
student_id INT,
student_name VARCHAR(100),
course_id VARCHAR(10),
course_name VARCHAR(100),
professor_id INT,
professor_name VARCHAR(100),
professor_dept VARCHAR(100)
);
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 professor_name이나 professor_dept 같은 값이 몇 개 행에 반복되는지 세어봅니다. 같은 값이 2개 이상 행에 나타나면 수정 이상 가능성입니다 — 1개 사실은 1개 행에만 저장돼야 합니다.
- UPDATE 이상을 진단합니다: 교수 소속을 1곳만 바꿔도 영향받는 행이 N개라면 비정규화 상태입니다. 영향 행이 항상 1개이어야 정상입니다.
- 삭제 이상을 확인합니다: 특정 학생 행을 DELETE했을 때 관련 교수·과목 정보가 DB에서 사라지면 → 교수·과목 데이터가 학생 행에 묻혀 있다는 신호입니다. 정규화 후에는 학생 삭제가 교수·과목 테이블에 영향을 주지 않아야 합니다.
실제 데이터를 채워보면 문제가 명확해집니다. 이교수의 이름과 소속이 CS101을 수강한 학생 수만큼 중복 저장됩니다.
student_id | student_name | course_id | course_name | professor_id | professor_name | professor_dept
-----------|--------------|-----------|-------------|--------------|----------------|---------------
1001 | 김학생 | CS101 | 데이터베이스 | 201 | 이교수 | 컴퓨터공학과
1001 | 김학생 | CS102 | 알고리즘 | 202 | 박교수 | 컴퓨터공학과
1002 | 박학생 | CS101 | 데이터베이스 | 201 | 이교수 | 컴퓨터공학과
3가지 이상 현상
1. 삽입 이상(Insertion Anomaly)
(student_id, course_id)가 복합 PK이면, 담당 과목과 수강 학생이 없는 신규 교수는 레코드 자체를 삽입할 수 없습니다. PK 컬럼에 NULL을 넣을 수 없기 때문입니다.
INSERT INTO student_courses VALUES
(NULL, NULL, NULL, NULL, 203, '정교수', '수학과');
2. 수정 이상(Update Anomaly)
이교수의 소속 학과를 변경하려면, CS101을 수강하는 모든 학생 행을 빠짐없이 업데이트해야 합니다. 한 행이라도 누락되면 같은 교수에 대해 서로 다른 소속 정보가 공존하는 데이터 불일치가 발생합니다.
UPDATE student_courses
SET professor_dept = 'AI학과'
WHERE professor_id = 201;
3. 삭제 이상(Deletion Anomaly)
박학생(1002)이 CS101 수강을 취소해 유일한 수강자가 사라지면, 그 행을 삭제할 때 이교수와 CS101 과목에 대한 정보까지 데이터베이스에서 완전히 사라집니다.
DELETE FROM student_courses
WHERE student_id = 1002 AND course_id = 'CS101';
정규화 전후 구조 비교
정규화 후에는 교수 정보가 professors 테이블 한 곳에만 존재합니다. 소속 학과를 변경할 때 단 1행만 수정하면 되고, 어떤 학생을 삭제해도 교수나 과목 정보는 영향받지 않습니다.
정규화 전 — 비정규화 테이블 student_courses (교수 정보가 행마다 중복)
| student_id | student_name | course_id | course_name | professor_id | professor_name | professor_dept |
|---|---|---|---|---|---|---|
| 1001 | 김학생 | CS101 | 데이터베이스 | 201 | 이교수 | 컴퓨터공학과 |
| 1001 | 김학생 | CS102 | 알고리즘 | 202 | 박교수 | 컴퓨터공학과 |
| 1002 | 박학생 | CS101 | 데이터베이스 | 201 | 이교수 | 컴퓨터공학과 |
정규화 후 — 4개 테이블로 분리
students
| id | name |
|---|---|
| 1001 | 김학생 |
| 1002 | 박학생 |
courses
| id | name | prof |
|---|---|---|
| CS101 | DB | 201 |
| CS102 | 알고 | 202 |
professors
| id | name | dept |
|---|---|---|
| 201 | 이교수 | 컴퓨터공학과 |
| 202 | 박교수 | 컴퓨터공학과 |
enrollments (연결 테이블)
| student_id | course_id |
|---|---|
| 1001 | CS101 |
| 1001 | CS102 |
| 1002 | CS101 |
비정규 테이블이 정규형으로 쪼개지는 순서 — 단계마다 사라지는 이상 현상
정규화는 "한 번에 좋은 스키마를 만드는 것"이 아니라, 비정규 테이블에서 종속을 하나씩 걷어내는 단계적 분해입니다. 1NF → 2NF → 3NF → BCNF는 각 단계가 특정 종속(반복 그룹·부분 종속·이행 종속)을 제거하고, 그 대가로 특정 이상 현상 하나가 사라지도록 짜여 있습니다. 이 순서를 알면 "내 테이블이 지금 몇 단계까지 와 있나", "다음에 무엇을 쪼개야 하나"를 진단할 수 있습니다.
[비정규형 UNF]
한 셀에 여러 값 · 반복 그룹 · 학생·과목·교수가 한 테이블에
│
│ ① 1NF — 원자값화: 반복 그룹·다중값을 별도 행으로 분리
▼
[1NF] 모든 컬럼이 원자값, 반복 그룹 없음
│
│ ② 2NF — 부분 함수 종속 제거: 복합 PK 일부에만 딸린 컬럼을 분리
▼
[2NF] 복합키 일부에만 종속된 컬럼 없음
│
│ ③ 3NF — 이행 함수 종속 제거: 비키 컬럼에 딸린 컬럼(A→B→C의 C)을 분리
▼
[3NF] 비키 컬럼 간 종속 없음 ← 대부분의 OLTP는 여기서 멈춤
│
│ ④ BCNF — 모든 결정자를 후보키로: 3NF가 못 잡는 결정자 이상 제거
▼
[BCNF] 각 사실이 정확히 한 곳에만 → 삽입·수정·삭제 이상 소멸
각 단계가 무엇을 쪼개고, 안 하면 어떤 이상이 남는가:
| 단계 | 무엇을 쪼개나 | 사라지는 이상 · 안 하면 남는 증상 |
|---|---|---|
| ① 1NF | 한 셀의 여러 값·반복 그룹을 별도 행으로 | 값 검색·부분 수정이 가능해짐 · 안 하면 LIKE '%사과%' 파싱·한 항목만 수정 불가 |
| ② 2NF | 복합 PK 일부에만 종속된 컬럼을 부모 테이블로 (예: product_name → products) | 부분종속발 중복 제거 · 안 하면 상품명 하나 바꿀 때 주문 행 전부 수정(수정 이상) |
| ③ 3NF | 비키 컬럼에 종속된 컬럼(zip_code → city의 city)을 분리 | 이행종속발 중복 제거 · 안 하면 우편번호당 도시명이 학생 수만큼 중복(수정 이상) |
| ④ BCNF | 후보키가 아닌 결정자를 키로 승격·분리 | 결정자 이상 제거 · 3NF인데도 남는 드문 갱신 이상 |
즉 정규화의 각 단계는 이상 현상 하나씩을 책임집니다. 삽입 이상은 "수강생 없는 새 과목"처럼 넣고 싶은 사실이 무관한 사실(학생)에 묶여 못 들어가던 것이, 사실을 각자 테이블로 분리하면서 풀립니다. 삭제 이상은 마지막 수강 행을 지울 때 함께 사라지던 과목 정보가 별도 테이블로 나가면서 보존됩니다. 진단은 역순으로 하면 빠릅니다 — 지금 테이블에서 "한 셀에 여러 값"이 보이면 1NF부터, "같은 값이 여러 행에 중복"이면 어떤 종속 때문인지(복합키 일부냐·비키 컬럼 경유냐)를 보고 2NF/3NF 중 어디가 덜 됐는지 좁힙니다. 대부분의 OLTP는 3NF에서 멈추고, BCNF는 결정자가 후보키가 아닌 드문 경우에만 갑니다.
1NF → 2NF → 3NF 단계별 변환
정규화가 필요하다는 건 알겠는데 실제로 어떻게 적용하는지 모릅니다. 1NF, 2NF, 3NF가 각각 어떤 기준인지 이론은 외울 수 있어도 실제 테이블에 어떻게 적용하는지는 다른 문제입니다. 단계별로 같은 예시 테이블을 변환하면서 따라가면 각 단계가 어떤 문제를 해결하는지 명확하게 보입니다.
 확대
확대
1NF — 원자값과 반복 그룹 제거
규칙: 모든 컬럼 값은 더 이상 분해될 수 없는 원자값(Atomic Value)이어야 합니다. 반복 그룹(Repeating Group)도 금지됩니다.
하나의 셀에 '사과,바나나,딸기'처럼 여러 값을 콤마로 저장하는 것이 대표적인 위반입니다. 이런 구조에서는 특정 상품의 포함 여부를 검색하거나 한 항목만 수정하는 것이 불가능합니다. 해결책은 반복되는 값을 별도 행으로 분리하는 것입니다.
| 구분 | 위반 예시 (orders_bad) | 준수 예시 (order_items) |
|---|---|---|
| products 컬럼 | '사과,바나나,딸기' (단일 셀) | 상품마다 별도 행으로 분리 |
| 검색 가능 여부 | LIKE '%사과%' 필요 (불안정) | WHERE product = '사과' |
| 수정 | 문자열 파싱 필요 | 해당 행만 UPDATE |
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer VARCHAR(100) NOT NULL
);
CREATE TABLE order_items (
order_id INT REFERENCES orders(order_id),
product VARCHAR(100) NOT NULL,
quantity INT NOT NULL DEFAULT 1,
PRIMARY KEY (order_id, product)
);
2NF — 부분 함수 종속 제거
규칙: 1NF를 만족하고, 복합 기본키의 일부에만 종속되는 컬럼이 없어야 합니다.
(order_id, product_id)가 복합 PK인 테이블에서, product_name과 unit_price는 order_id와 무관하게 product_id 하나만으로 결정됩니다. 이런 부분 함수 종속 컬럼은 별도 테이블로 분리해야 합니다.
| 컬럼 | 종속 대상 | 판정 |
|---|---|---|
quantity | order_id + product_id 전체 | 2NF 준수 |
product_name | product_id 만 | 2NF 위반 |
unit_price | product_id 만 | 2NF 위반 |
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
unit_price NUMERIC NOT NULL
);
CREATE TABLE order_items (
order_id INT REFERENCES orders(id),
product_id INT REFERENCES products(id),
quantity INT NOT NULL DEFAULT 1,
PRIMARY KEY (order_id, product_id)
);
3NF — 이행 함수 종속 제거
규칙: 2NF를 만족하고, PK가 아닌 컬럼이 다른 PK가 아닌 컬럼에 종속되면 안 됩니다.
student_id → zip_code → city라는 종속 체인이 그 예입니다. city는 PK인 student_id가 직접 결정하는 값이 아니라 zip_code를 거쳐 간접적으로 결정됩니다. 같은 우편번호를 가진 학생이 100명이면 city 값도 100번 중복 저장됩니다.
| 구분 | 위반 (students_bad) | 준수 (분리 후) |
|---|---|---|
| city 저장 위치 | students 테이블에 중복 | zip_codes 테이블에 1회 |
| 도시명 변경 시 | zip_code 사용자 수만큼 UPDATE | zip_codes 1행만 UPDATE |
CREATE TABLE zip_codes (
zip_code VARCHAR(10) PRIMARY KEY,
city VARCHAR(100) NOT NULL,
district VARCHAR(100)
);
CREATE TABLE students (
student_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
zip_code VARCHAR(10) REFERENCES zip_codes(zip_code)
);
3NF 위반이 실제로 어떤 데이터 사고를 만드는지 직접 확인합니다. 정규화 전 테이블(students_bad)에서 같은 우편번호가 서로 다른 도시명을 갖는지 — 즉 중복 저장된 city가 일관성을 잃었는지 찾아냅니다.
-- 같은 zip_code인데 city가 2개 이상 = 갱신 이상이 이미 발생한 증거
SELECT zip_code, COUNT(DISTINCT city) AS city_variants
FROM students_bad
GROUP BY zip_code
HAVING COUNT(DISTINCT city) > 1;
-- zip_code당 city 중복 저장 횟수(낭비 규모)
SELECT zip_code, city, COUNT(*) AS dup_rows
FROM students_bad
GROUP BY zip_code, city
ORDER BY dup_rows DESC;
zip_code | city_variants
----------+---------------
06236 | 2 -- '서울특별시' / '서울시' 혼재 → 갱신 이상
zip_code | city | dup_rows
----------+------------+----------
06236 | 서울특별시 | 84
SELECT zip_code, COUNT(DISTINCT city) FROM students_bad GROUP BY zip_code HAVING COUNT(DISTINCT city) > 1;- 첫 쿼리가 한 행이라도 반환하면(city_variants > 1) 이미 갱신 이상이 발생한 것 — 같은 우편번호에 도시명이 갈렸다는 뜻이다. 0행이면 아직 운 좋게 일관성이 유지된 상태
- 두 번째 쿼리의 dup_rows가 클수록 같은 city를 그만큼 반복 저장 중이라는 의미 — 3NF 분리(zip_codes 테이블)로 1행으로 줄일 수 있는 낭비 규모다
- 분리 후 students에는 zip_code만 남고 city는 zip_codes 1행에서 JOIN으로 가져오므로, 도시명 변경이 UPDATE 1건으로 끝나는지 확인한다
역정규화(Denormalization) — 성능을 위해 의도적으로 중복 허용
정규화가 항상 정답은 아닙니다. 읽기 집중(Read-Heavy) 환경에서는 잦은 JOIN이 성능 병목이 됩니다.
아래 예시는 주문 목록 조회 시 매번 users 테이블과 JOIN하는 비용을 피하기 위해 orders 테이블에 고객 이름과 이메일을 직접 복사해 두는 역정규화 패턴입니다. 단, 사용자가 이메일을 변경하면 orders 테이블도 별도로 업데이트해야 하므로 애플리케이션 레벨에서 일관성 유지 전략을 수립해야 합니다.
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL REFERENCES users(id),
customer_name VARCHAR(100) NOT NULL,
customer_email VARCHAR(255) NOT NULL,
total_amount NUMERIC(12, 2) NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
);
정규화 단계 요약표
각 정규형이 무엇을 추가로 요구하는지 단계별로 정리하면, 내가 설계한 테이블이 어느 단계까지 만족하는지 진단하는 기준이 됩니다.
| 단계 | 요구사항 |
|---|---|
| 1NF | 모든 컬럼 값이 원자값, 반복 그룹 없음 |
| 2NF | 1NF + 부분 함수 종속 제거 (복합 PK 테이블에만 해당) |
| 3NF | 2NF + 이행 함수 종속 제거 (비주요 속성 간 종속 제거) |
| BCNF | 3NF + 모든 결정자가 후보키 (실무에서 3NF로 충분한 경우 많음) |
실전 가이드: 대부분의 OLTP(트랜잭션 처리) 시스템은 3NF까지 적용합니다. 성능 문제가 실제로 측정된 경우에만 역정규화를 선택하고, 애플리케이션 레벨에서 데이터 일관성을 유지하는 전략을 수립하세요.
주문 목록 한 페이지를 보여주기 위해 7개 테이블을 JOIN해야 하는 상황이 발생했습니다. 정규화 원칙을 엄격하게 지키다 보니 도시 정보, 우편번호, 배송지 주소가 모두 별도 테이블로 분리되었고, 주문 1건 조회에 수십 ms가 걸리는 성능 문제가 나타났습니다.
원인: 정규화는 쓰기(INSERT/UPDATE) 이상 현상 방지에 최적화됩니다. 읽기 집중 화면에서 지나치게 많은 JOIN은 오히려 역효과를 냅니다.
해결 방법: 성능 병목을 먼저 측정(EXPLAIN ANALYZE)한 뒤, 자주 함께 조회되는 컬럼을 선택적으로 역정규화합니다. 또는 읽기 전용 Materialized View를 만들어 미리 JOIN된 결과를 캐싱합니다. 역정규화 없이 해결하려면 적절한 인덱스와 커버링 인덱스(Covering Index)를 먼저 시도하세요.
신규 이커머스 서비스 초기에 orders 테이블 하나에 사용자 이름, 배송지 주소(도시, 도로명, 우편번호), 결제 수단 이름까지 모두 넣었습니다. 서비스가 성장하면서 문제가 생겼습니다. 사용자가 주소를 변경하면 과거 주문 기록의 주소도 바뀌고, 동일 도시를 수만 건의 주문에서 중복 저장하는 비효율이 드러났습니다.
3NF 기준으로 재설계하면서 users, addresses, zip_codes, orders로 테이블을 분리했습니다. 주문 생성 시점의 배송지는 order_snapshots 테이블에 비정규화된 형태로 별도 보존해, 이후 주소 변경이 주문 이력에 영향을 주지 않도록 했습니다. 정규화와 역정규화를 목적에 맞게 혼합하는 것이 실전 설계의 핵심입니다.
심화 — 역정규화의 청구서: 되살아난 갱신 이상
심화: 중복을 허용한 대가는 '동기화 책임'으로 돌아온다
정규화는 중복을 없애 갱신 이상을 막습니다. 역정규화는 읽기 성능을 위해 그 중복을 의도적으로 되살립니다 — 그런데 그 순간, 정규화가 없애 줬던 갱신 이상도 함께 돌아옵니다. 이것을 DB가 대신 막아 주지 않는다는 게 핵심입니다.
- 복사한 값은 원본과 따로 늙습니다: 조회를 빠르게 하려고 orders에 customer_email을 복사해 두면, 사용자가 users에서 이메일을 바꿔도 orders의 사본은 그대로입니다. 앱이 두 곳을 함께 갱신하지 않으면 같은 사람의 이메일이 두 값으로 갈립니다 — 정규화 단원에서 봤던 바로 그 수정 이상입니다.
- DB는 이 중복을 지켜 주지 않습니다: FK는 참조 무결성은 지키지만 복사본을 원본과 같게 유지하라는 규칙은 없습니다. 그 일관성은 전적으로 애플리케이션의 책임이 됩니다 — 트리거, CDC, 또는 주기적 대사(reconciliation) 중 무엇으로 맞출지 설계해야 합니다.
- 스냅샷과 캐시는 다릅니다: 주문 시점의 배송지·가격처럼 그때 값을 일부러 얼려 두는 스냅샷은 원본이 바뀌어도 갱신하면 안 됩니다 — 이건 역정규화가 아니라 의도된 이력입니다. 반대로 최신을 빠르게 보여주려는 캐시성 복제는 원본이 바뀌면 반드시 따라 갱신돼야 합니다. 이 둘을 구분하지 않으면 왜 옛날 값이 남지와 왜 과거 주문 금액이 바뀌지가 동시에 터집니다.
- 넓은 행은 갱신 비용도 큽니다: 여러 사본을 한 테이블에 몰아 넓어진 행은, 그중 한 컬럼만 바꿔도 MVCC 상 행 전체가 새 버전으로 복사됩니다. dead tuple과 인덱스 갱신이 늘어, 역정규화가 읽기를 아낀 만큼 쓰기·vacuum 비용을 지불하게 됩니다.
핵심은, 역정규화가 무료 성능이 아니라 일관성 유지 책임을 앱으로 옮겨 온 거래라는 점입니다. 그 책임을 설계하지 않은 역정규화는 반드시 데이터 불일치로 돌아옵니다.
상황: 조회 성능을 위해 orders 테이블에 customer_email을 역정규화해 두고 목록·알림을 그 컬럼으로 처리했습니다. 그런데 일부 고객에게 이전 이메일로 알림이 발송돼 컴플레인이 들어왔습니다.
원인: 사용자가 users의 이메일을 변경할 때 orders에 복사돼 있던 사본은 갱신되지 않았습니다. 원본은 바뀌고 사본은 그대로라 같은 사람의 이메일이 두 값으로 공존했고, 알림이 낡은 사본을 읽은 것입니다. 정규화로 없앴던 수정 이상이 역정규화된 복제 컬럼을 통해 그대로 되살아난 사례입니다.
진단: 먼저 이 컬럼이 캐시성 복제인지 주문 시점 스냅샷인지 정의를 확인합니다. 캐시성인데 안 맞았다면 users와 orders를 조인해 customer_email이 원본과 다른 주문을 뽑아 불일치 규모를 셉니다. 이메일 변경 이벤트 처리 경로에 orders 갱신이 빠져 있는지도 코드에서 확인합니다.
해결: 이 값이 최신을 따라가야 하는 캐시성 복제라면, 원본 변경 시 사본을 함께 갱신하도록 트리거나 이벤트(CDC) 기반 동기화를 넣고 주기적 대사로 표류(drift)를 잡습니다. 반대로 보낸 시점의 주소를 남기려는 의도였다면 스냅샷임을 명시하고 알림은 원본(users)에서 읽도록 바꿉니다. 무엇을 복제하든 언제 어떻게 동기화할지를 함께 설계해야 합니다(계층형 댓글 구조, 다대다 태그 시스템, Soft Delete 구현).
명령어·구문 빠른 참조
이 모듈에서 정규화·역정규화를 다루며 사용한 테이블 정의·진단 구문을 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
CREATE TABLE ... PRIMARY KEY | 정규화로 분리한 테이블 정의 | CREATE TABLE professors (id INT PRIMARY KEY, ...); |
복합 PK PRIMARY KEY (a, b) | 연결(교차) 테이블의 키 | PRIMARY KEY (order_id, product_id) (enrollments) |
REFERENCES 부모(컬럼) | 분리한 테이블을 FK로 연결 | zip_code VARCHAR(10) REFERENCES zip_codes(zip_code) |
COUNT(DISTINCT 컬럼) + HAVING | 이행 종속 중복 진단(한 키에 값 2개) | GROUP BY zip_code HAVING COUNT(DISTINCT city) > 1 |
COUNT(*) + GROUP BY + ORDER BY | 중복 저장 규모(낭비) 측정 | GROUP BY zip_code, city ORDER BY dup_rows DESC |
| 역정규화 복제 컬럼 | 읽기용 JOIN 제거(중복 의도 허용) | orders에 customer_name·customer_email 복사 |
| Materialized View | 미리 JOIN한 결과를 캐싱 | 과도한 JOIN의 읽기 전용 대안 |
EXPLAIN ANALYZE | 역정규화 전 병목 먼저 측정 | JOIN 병목 확인 후 선택적 역정규화 |
관련 모듈로 더 깊이:
- PK, FK 제약조건과 Cascade 설정이 주는 영향 — 정규화로 분리한 테이블을 PK/FK로 다시 연결하는 법
- 계층형 댓글 구조, 다대다 태그 시스템, Soft Delete 구현 — 정규화 원칙을 실전 스키마 설계로 확장하는 패턴
- INNER, LEFT, RIGHT, FULL JOIN의 최적화 실행 조건 — 정규화로 쪼갠 테이블을 JOIN으로 다시 합쳐 조회하는 법
다음 모듈에서는 SELECT, INSERT, UPDATE, DELETE의 정확한 동작 방식과 실수를 방지하는 안전한 쿼리 패턴을 다룹니다.