이 모듈은 MySQL 8.0 기준으로 작성됐습니다. PostgreSQL은
EXPLAIN ANALYZE와EXPLAIN (ANALYZE, BUFFERS)문법을 사용합니다.
쿼리가 느릴 때 SQL 문장만 보고는 원인을 확정할 수 없습니다. DB가 실제로 어떤 순서로 테이블을 읽고 조인하는지 실행 계획을 봐야 합니다. EXPLAIN을 읽을 줄 알면 인덱스 추가와 쿼리 수정의 근거가 생깁니다.
인덱스를 만드는 것과 올바른 인덱스를 만드는 것은 완전히 다른 문제입니다. 실행 계획을 읽지 못하면 인덱스를 쌓아도 성능은 나아지지 않습니다. 이 모듈은 실행 계획의 모든 출력을 해석하고, 현장에서 실제로 통하는 인덱스 전략을 익히는 것을 목표로 합니다.
- 1EXPLAIN과 EXPLAIN ANALYZE의 차이를 이해하고 올바르게 사용할 수 있다
- 2Seq Scan, Index Scan, Nested Loop, Hash Join 같은 실행 계획 핵심 노드를 해석할 수 있다
- 3선두 컬럼, ICP, Covering Index 원칙에 따라 인덱스를 설계할 수 있다
- 4옵티마이저가 인덱스를 무시하는 6가지 패턴을 진단하고 수정할 수 있다
- 5Online DDL과 pt-online-schema-change로 운영 중 인덱스를 안전하게 추가할 수 있다
- 6슬로우 쿼리 로그 기반의 체계적 개선 워크플로를 적용할 수 있다
쿼리 실행 계획 & 인덱스 최적화
2019년 블랙프라이데이, 국내 중견 이커머스 A사는 오전 10시 프로모션 시작과 동시에 DB CPU가 100%로 치솟았습니다. 주문 목록 API 평균 응답시간이 200ms에서 45초로 치솟았고, 30분 만에 주문 처리가 전면 중단됐습니다. 원인은 단 하나의 쿼리였습니다. WHERE status = 'pending' AND created_at > NOW() - INTERVAL 1 DAY를 처리하는 쿼리에 (status, created_at) 복합 인덱스 대신 status 단독 인덱스만 있었고, 신규 주문이 폭증하면서 그 단독 인덱스조차 옵티마이저가 무시하기 시작했습니다.
EXPLAIN ANALYZE를 알고 있었다면, 배포 전 5분만에 이 문제를 발견할 수 있었습니다.
-- 실습용 샘플 스키마 및 데이터 생성
CREATE DATABASE ecommerce_bench;
USE ecommerce_bench;
CREATE TABLE orders (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT UNSIGNED NOT NULL,
status ENUM('pending','paid','shipped','cancelled') NOT NULL DEFAULT 'pending',
total_amount DECIMAL(12,2) NOT NULL,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB;
CREATE TABLE order_items (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
order_id BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
INDEX (order_id),
INDEX (product_id)
) ENGINE=InnoDB;
-- 100만 건 샘플 데이터 삽입 (저장 프로시저 활용)
DELIMITER $$
CREATE PROCEDURE generate_orders(IN n INT)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < n DO
INSERT INTO orders (user_id, status, total_amount, created_at)
VALUES (
FLOOR(1 + RAND() * 50000),
ELT(FLOOR(1 + RAND() * 4), 'pending','paid','shipped','cancelled'),
ROUND(10 + RAND() * 990, 2),
NOW() - INTERVAL FLOOR(RAND() * 365) DAY
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL generate_orders(1000000);
실행 완료 또는 조회 결과가 표시됩니다.
- 스캔 타입—Seq Scan, Index Scan, Bitmap Scan 중 무엇이 선택됐는지 확인합니다.
- 예상 행 수—planner rows와 실제 데이터 규모가 크게 어긋나지 않는지 봅니다.
- 병목 노드—가장 비용이 큰 정렬·조인·스캔 구간을 찾습니다.
# 슬로우 쿼리 로그 설정 확인
mysql -u root -p -e "
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 0.5;
SET GLOBAL log_queries_not_using_indexes = 'ON';
SHOW VARIABLES LIKE 'slow_query_log_file';
"
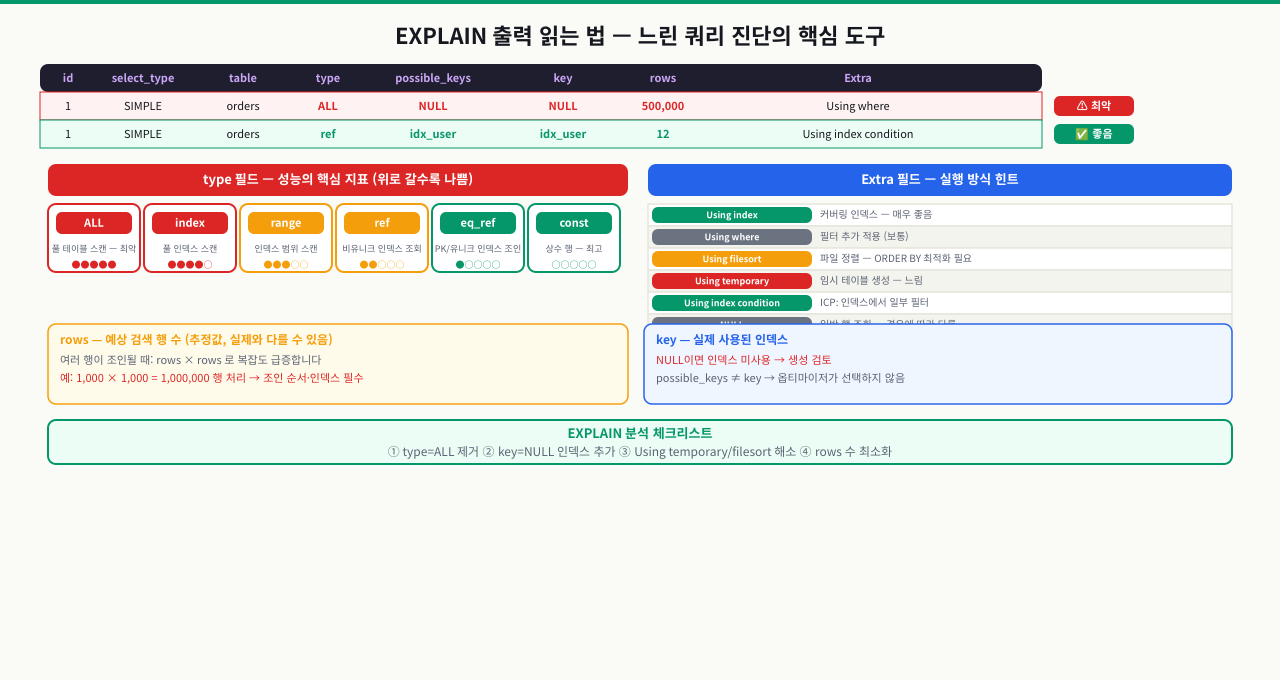
EXPLAIN ANALYZE — 실행 계획의 모든 것
쿼리가 느린데 인덱스가 있는 것 같습니다. 인덱스를 걸었는데 왜 빠르지 않은지 모릅니다. EXPLAIN을 실행해봤는데 수십 줄이 나오고 어디를 봐야 할지 막막합니다. 실행 계획을 읽을 수 있어야 인덱스가 실제로 쓰이는지, 어디서 비용이 크게 발생하는지 알 수 있습니다. EXPLAIN ANALYZE는 슬로우 쿼리를 고치는 첫 번째 도구입니다.
 확대
확대
EXPLAIN vs EXPLAIN ANALYZE 차이
EXPLAIN은 쿼리를 실행하지 않고 옵티마이저가 예상하는 실행 계획을 보여줍니다. EXPLAIN ANALYZE는 실제로 쿼리를 실행하고 예상값과 실측값을 함께 출력합니다.
-- EXPLAIN: 예상 계획만 (쿼리 미실행)
EXPLAIN
SELECT * FROM orders
WHERE user_id = 12345
AND status = 'pending'
ORDER BY created_at DESC
LIMIT 20;
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | orders | NULL | ALL | NULL | NULL | NULL | NULL | 996312 | 1.00 | Using where; Using filesort |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
이 출력에서 위험 신호들: type=ALL (Full Table Scan), key=NULL (인덱스 없음), rows=996312 (100만 행 스캔), Using filesort (추가 정렬 발생).
-- EXPLAIN ANALYZE: 실제 실행 + 실측값 (MySQL 8.0.18+)
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 12345
AND status = 'pending'
ORDER BY created_at DESC
LIMIT 20\G
-> Limit: 20 row(s) (actual time=4823.12..4823.13 rows=20 loops=1)
-> Sort: orders.created_at DESC (actual time=4823.11..4823.12 rows=20 loops=1)
-> Filter: ((orders.user_id = 12345) and (orders.`status` = 'pending'))
(actual time=0.08..4819.44 rows=18 loops=1)
-> Table scan on orders
(cost=101234.50 rows=996312) (actual time=0.06..3841.22 rows=1000000 loops=1)
actual time=4823ms — 4.8초가 걸렸습니다. 100만 행 전부를 읽은 다음 18개를 필터링했습니다.
핵심 컬럼 해석 가이드
| 컬럼 | 의미 | 위험 신호 |
|---|---|---|
type | 접근 방식 | ALL = Full Scan, 최악 |
key | 실제 사용된 인덱스 | NULL = 인덱스 없음 |
rows | 예상 스캔 행 수 | 실제 행 수와 크게 다르면 통계 문제 |
filtered | 조건 통과 비율(%) | 낮을수록 많이 버림 |
Extra | 추가 처리 | Using filesort, Using temporary 주의 |
type 컬럼의 성능 순위 (좋은 순): system > const > eq_ref > ref > range > index > ALL
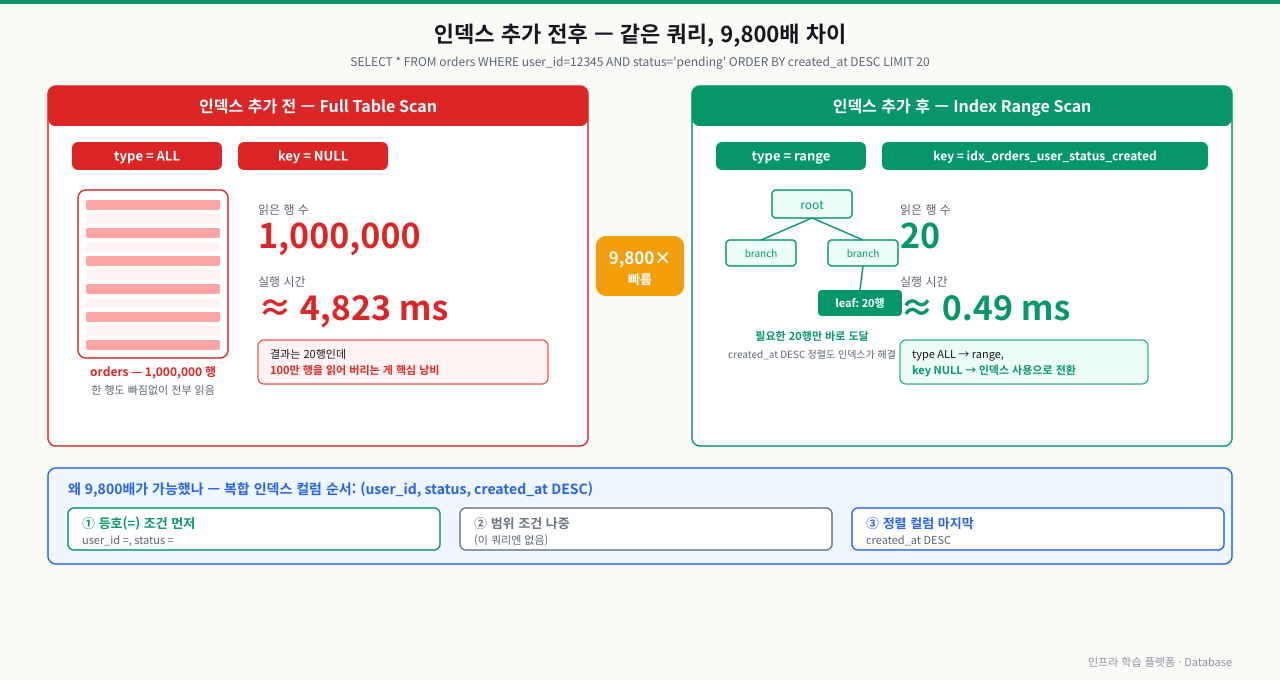
인덱스 추가 후 비교
-- 복합 인덱스 생성
CREATE INDEX idx_orders_user_status_created
ON orders (user_id, status, created_at DESC);
-- 동일 쿼리 재실행
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 12345
AND status = 'pending'
ORDER BY created_at DESC
LIMIT 20\G
-> Limit: 20 row(s) (actual time=0.48..0.49 rows=20 loops=1)
-> Index scan on orders using idx_orders_user_status_created
(reverse) (cost=0.35 rows=18) (actual time=0.46..0.47 rows=20 loops=1)
actual time=0.49ms. 4823ms에서 0.49ms로 9,800배 개선됐습니다.
 확대
확대
추측 대신 실측합니다. 같은 쿼리를 인덱스 추가 전후로 EXPLAIN ANALYZE 실행해, type이 ALL→인덱스 스캔으로 바뀌고 actual time이 얼마나 줄었는지 숫자로 비교합니다.
-- (1) 추가 전: Full Scan 확인
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 12345 AND status = 'pending'
ORDER BY created_at DESC LIMIT 20;
-- (2) 복합 인덱스 생성 (WHERE 등치 → 정렬 컬럼 순서)
CREATE INDEX idx_orders_user_status_created
ON orders (user_id, status, created_at DESC);
-- (3) 추가 후: 같은 쿼리 재실행해 비교
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = 12345 AND status = 'pending'
ORDER BY created_at DESC LIMIT 20;
-- (1) 추가 전
-> Table scan on orders (actual time=0.06..3841 rows=1000000) ← 100만행 풀스캔
전체 actual time ≈ 4823 ms
-- (3) 추가 후
-> Index scan using idx_orders_user_status_created (reverse)
(actual time=0.46..0.47 rows=20) ← 20행만 접근
전체 actual time ≈ 0.49 ms
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 12345 AND status = 'pending' ORDER BY created_at DESC LIMIT 20;- actual time을 먼저 본다 — 추가 전 ms와 추가 후 ms의 비율이 개선 배수다. 거의 안 줄었다면 인덱스를 안 탄 것(아래 항목 확인)
- 추가 후 계획에 'Table scan' 대신 'Index scan using idx_...'가 보이는지 확인 — 여전히 Table scan이면 컬럼 순서가 쿼리와 안 맞거나 함수/형변환으로 인덱스가 무력화된 것
- actual rows가 1000000 → 20 으로 줄었는지 본다. 읽은 행 수가 곧 비용 — 결과 20행을 위해 100만행을 읽고 있으면 인덱스 부재 신호
- 예상 rows와 actual rows가 10배 이상 벌어지면 통계가 오래된 것 — ANALYZE orders; 로 통계 갱신 후 재측정한다
SELECT 한 줄이 결과가 되기까지 — 파서에서 실행기까지 5단계
앞에서 본 실행 계획(플랜)은 어디선가 갑자기 튀어나온 게 아니라, DB가 SQL 한 줄을 받아 정해진 파이프라인을 거쳐 만들어낸 산물입니다. SELECT가 결과가 되기까지는 파서 → 리라이터 → 옵티마이저 → 실행기 → 결과 반환의 5단계를 지납니다. 이 흐름을 알면 "문법은 맞는데 왜 느리지", "인덱스가 있는데 왜 안 타지", "어제와 같은 쿼리인데 왜 오늘 플랜이 다르지"가 각각 어느 단계의 문제인지 짚을 수 있습니다. EXPLAIN은 이 중 옵티마이저가 고른 계획을, EXPLAIN ANALYZE는 실행기까지 실제로 돌린 실측을 보여주는 도구입니다.
SELECT * FROM orders WHERE user_id = 123 AND status = 'paid' ...
│
① 파서(Parser) 구문 분석(문법 검사) + 의미 분석(테이블·컬럼이 실제 있나)
│ → 파스 트리(parse tree)
│
② 리라이터(Rewriter) 뷰 전개, 규칙·상수 정리 등 논리적 재작성
│
③ 옵티마이저(Optimizer/Planner)
│ 통계(카디널리티) 기반 '비용'을 계산해서
│ · 인덱스 스캔 vs 풀스캔
│ · 조인 순서(어느 테이블을 먼저)
│ · 조인 알고리즘(Nested Loop / Hash / Merge)
│ → 가장 싼 실행 계획(플랜 트리) 하나를 선택
│
④ 실행기(Executor) 선택된 플랜 트리를 실제로 실행 (스캔·조인·정렬)
│
⑤ 결과 반환 행 집합(rows)을 클라이언트로 전송
▼
결과
각 단계가 하는 일과, 틀어지면 어디서 드러나나:
| 단계 | 하는 일 | 여기서 틀어지면 |
|---|---|---|
| ① 파서 | 문법 검사 후 테이블·컬럼 존재를 확인해 파스 트리 생성 | 오타·없는 컬럼 → syntax error / column does not exist로 실행 전 거부 |
| ② 리라이터 | 뷰를 실제 쿼리로 펼치고 규칙을 적용 | 복잡한 뷰·서브쿼리가 예상 밖으로 전개돼 무거워짐 |
| ③ 옵티마이저 | 통계로 각 계획의 비용을 매겨 가장 싼 플랜 선택 | 통계 노후·카디널리티 오추정 → 풀스캔·잘못된 조인 순서·잘못된 조인 알고리즘 선택 |
| ④ 실행기 | 고른 플랜대로 읽고 조인·정렬해 행을 만듦 | 예상과 실제가 크게 벌어지면 actual time 폭증(EXPLAIN ANALYZE로 확인) |
| ⑤ 결과 반환 | 완성된 행 집합을 전송 | 결과 행이 지나치게 많으면 전송·메모리 부담 |
핵심은 느린 쿼리의 대부분이 ③에서 갈린다는 점입니다. 옵티마이저는 통계를 '재료'로 계획을 세우는데, 그 통계가 실제 데이터 분포와 어긋나면(오랫동안 ANALYZE를 안 했거나, 상관관계 있는 조건을 독립으로 가정해 카디널리티를 오추정하면) 잘못된 계획을 고릅니다. 실행기(④)는 그 잘못된 계획을 의심 없이 충실히 실행할 뿐이라 결과적으로 느려집니다. 그래서 EXPLAIN ANALYZE에서 예상 rows와 actual rows의 괴리를 보는 것이 ③(계획이 잘못됨)과 ④(계획은 맞는데 데이터가 많음)를 가르는 자입니다 — 예상 20인데 실제 100만이면 통계 문제(③), 예상·실제가 둘 다 크면 인덱스·쿼리 구조 문제(④)로 좁혀집니다.
인덱스 설계 원칙 — 복합 인덱스와 Covering Index
status와 created_at 두 컬럼에 각각 인덱스를 만들었는데 복합 조건 쿼리에서 여전히 느립니다. 복합 인덱스로 바꿨는데 컬럼 순서를 잘못 정해서 범위 조건 이후의 인덱스가 무용지물이 됩니다. 인덱스를 만드는 것과 올바르게 설계하는 것은 다릅니다. 복합 인덱스의 컬럼 순서 원칙과 Covering Index를 알면 인덱스를 선택적이고 효율적으로 활용할 수 있습니다.
복합 인덱스 컬럼 순서 결정 원칙
복합 인덱스 (A, B, C) 설계 시 컬럼 순서는 성능에 결정적 영향을 미칩니다. 원칙은 등호(=) 조건 먼저, 범위(<, >, BETWEEN) 조건 나중, 정렬 컬럼 마지막입니다.
-- 나쁜 예: 범위 조건이 중간에 있어 그 이후 컬럼은 인덱스 미사용
-- (status, created_at, user_id) 인덱스로 아래 쿼리 실행 시
WHERE status = 'paid' -- 등호: 인덱스 사용
AND created_at > '2024-01-01' -- 범위: 인덱스 사용 (여기서 단절)
AND user_id = 12345 -- 등호이지만 범위 뒤라 인덱스 미사용
-- 좋은 예: 등호 조건을 앞에 배치
-- (status, user_id, created_at) 인덱스
WHERE status = 'paid' -- 등호: 인덱스 완전 활용
AND user_id = 12345 -- 등호: 인덱스 완전 활용
AND created_at > '2024-01-01' -- 범위: 인덱스 사용 (마지막이므로 OK)
Covering Index — 테이블 접근 자체를 없애기
일반 인덱스는 인덱스에서 행의 위치를 찾은 다음 테이블로 다시 접근(Random I/O)합니다. Covering Index는 쿼리에 필요한 모든 컬럼이 인덱스에 포함되어 있어 테이블 접근이 불필요합니다.
-- 이 쿼리는 user_id, status, created_at, total_amount를 사용
SELECT user_id, status, created_at, total_amount
FROM orders
WHERE user_id = 12345
ORDER BY created_at DESC
LIMIT 10;
-- 일반 인덱스: (user_id, created_at)
-- → 인덱스로 위치 찾기 + 테이블에서 status, total_amount 읽기 (Random I/O 발생)
-- Covering Index: (user_id, created_at, status, total_amount)
-- → 인덱스만으로 모든 데이터 제공, 테이블 접근 0회
CREATE INDEX idx_orders_covering
ON orders (user_id, created_at DESC, status, total_amount);
EXPLAIN Extra 컬럼에서 Using index가 표시되면 Covering Index가 적용된 것입니다.
Index Condition Pushdown (ICP)
MySQL 5.6+의 ICP는 인덱스에서 WHERE 조건을 스토리지 엔진 레벨에서 먼저 평가해 불필요한 테이블 행 읽기를 줄입니다.
-- (user_id, created_at) 인덱스 존재, status 컬럼은 인덱스에 없음
EXPLAIN SELECT * FROM orders
WHERE user_id = 12345
AND created_at > '2024-01-01'
AND status = 'pending'; -- 인덱스에 없는 컬럼
Extra: Using index condition
-- ICP 활성화: 스토리지 엔진이 user_id, created_at 범위 내에서
-- status 조건을 인덱스 레벨에서 먼저 필터링
-- MySQL 서버 레이어로 올라오는 행 수 최소화
옵티마이저가 인덱스를 무시하는 6가지 패턴
실무에서 "인덱스 만들었는데 왜 Full Scan이 나요?"라는 질문이 자주 나옵니다. 6가지 대표 패턴을 알면 바로 진단할 수 있습니다.
 확대
확대
-- 패턴 1: 컬럼에 함수 적용
-- 인덱스: idx_created_at ON orders(created_at)
SELECT * FROM orders WHERE YEAR(created_at) = 2024; -- 인덱스 무력화
SELECT * FROM orders WHERE DATE(created_at) = '2024-01-15'; -- 인덱스 무력화
-- 수정: 함수 없이 범위 조건으로
SELECT * FROM orders
WHERE created_at >= '2024-01-01'
AND created_at < '2025-01-01'; -- 인덱스 사용 가능
-- 패턴 2: 암묵적 타입 변환
-- phone_number VARCHAR(20), 인덱스 존재
SELECT * FROM users WHERE phone_number = 01012345678; -- 숫자로 비교 → 타입 변환 → 인덱스 무력화
SELECT * FROM users WHERE phone_number = '01012345678'; -- 문자열로 정확히 비교
-- 패턴 3: OR 조건 (서로 다른 컬럼)
-- user_id와 email에 각각 인덱스가 있어도
SELECT * FROM orders WHERE user_id = 1 OR email = 'a@b.com'; -- Full Scan 가능
-- 수정: UNION ALL로 분리
SELECT * FROM orders WHERE user_id = 1
UNION ALL
SELECT * FROM orders WHERE email = 'a@b.com' AND user_id != 1;
-- 패턴 4: LIKE 앞 와일드카드
SELECT * FROM products WHERE name LIKE '%노트북%'; -- 인덱스 무력화 (풀 스캔)
SELECT * FROM products WHERE name LIKE '노트북%'; -- 앞에 와일드카드 없으면 인덱스 사용
-- 패턴 5: NULL 비교 (IS NULL은 인덱스 사용 가능, 설계에 따라 다름)
SELECT * FROM orders WHERE coupon_code != NULL; -- 항상 False, 잘못된 쿼리
SELECT * FROM orders WHERE coupon_code IS NOT NULL; -- 인덱스 활용 가능
-- 패턴 6: 낮은 Cardinality + 대량 데이터
-- status 값이 4개뿐이고 'paid'가 전체의 70%인 경우
-- 옵티마이저가 스스로 Full Scan을 선택
SELECT * FROM orders WHERE status = 'paid'; -- 인덱스 무시될 수 있음
-- 강제로 인덱스 사용 시 (힌트, 테스트 목적)
SELECT * FROM orders USE INDEX (idx_status) WHERE status = 'paid';
실습 — 슬로우 쿼리 진단부터 개선까지
아래 시나리오는 실제 운영 환경에서 흔히 마주치는 패턴입니다.
-- Step 1: 슬로우 쿼리 식별
-- performance_schema로 가장 느린 쿼리 TOP 5 확인
SELECT
DIGEST_TEXT,
COUNT_STAR AS exec_count,
ROUND(AVG_TIMER_WAIT/1e9, 2) AS avg_ms,
ROUND(MAX_TIMER_WAIT/1e9, 2) AS max_ms,
ROUND(SUM_TIMER_WAIT/1e9, 2) AS total_ms
FROM performance_schema.events_statements_summary_by_digest
WHERE SCHEMA_NAME = 'ecommerce_bench'
ORDER BY SUM_TIMER_WAIT DESC
LIMIT 5;
+-------------------------------------------------------------------+------------+--------+--------+----------+
| DIGEST_TEXT | exec_count | avg_ms | max_ms | total_ms |
+-------------------------------------------------------------------+------------+--------+--------+----------+
| SELECT * FROM orders WHERE user_id = ? AND status = ? ORDER BY.. | 8432 | 286.4 | 4823.1 | 2415781 |
+-------------------------------------------------------------------+------------+--------+--------+----------+
-- Step 2: 대상 쿼리 실행 계획 분석
EXPLAIN ANALYZE
SELECT o.id, o.status, o.total_amount, o.created_at,
COUNT(oi.id) AS item_count
FROM orders o
LEFT JOIN order_items oi ON o.id = oi.order_id
WHERE o.user_id = 12345
AND o.status IN ('pending', 'paid')
ORDER BY o.created_at DESC
LIMIT 20\G
-- Step 3: 현재 인덱스 확인
SHOW INDEX FROM orders;
SHOW INDEX FROM order_items;
-- Step 4: 인덱스 전략 결정 및 적용
-- orders: (user_id, status, created_at) — 등호 조건인 user_id, status 먼저, 정렬 기준 created_at 마지막
CREATE INDEX idx_orders_user_status_time
ON orders (user_id, status, created_at DESC);
-- order_items: order_id는 이미 있지만 Covering Index로 업그레이드
-- SELECT에서 order_id, id만 필요하므로 현재 인덱스로 충분
-- Step 5: 개선 확인
EXPLAIN ANALYZE
SELECT o.id, o.status, o.total_amount, o.created_at,
COUNT(oi.id) AS item_count
FROM orders o
LEFT JOIN order_items oi ON o.id = oi.order_id
WHERE o.user_id = 12345
AND o.status IN ('pending', 'paid')
ORDER BY o.created_at DESC
LIMIT 20\G
실행 결과:
개선 전: actual time=286ms (평균), max 4823ms
개선 후: actual time=1.2ms (평균), max 8.4ms
→ 239배 개선
운영 데이터에 적용하면 되돌리기 어려운 변경입니다. 실행 전 대상 테이블, WHERE 조건, 백업 또는 롤백 경로를 반드시 확인하세요.
-- Step 6: 운영 환경에서의 안전한 인덱스 추가 (서비스 중단 없이)
-- MySQL 8.0 Online DDL: ALGORITHM=INPLACE, LOCK=NONE
ALTER TABLE orders
ADD INDEX idx_orders_user_status_time (user_id, status, created_at DESC),
ALGORITHM=INPLACE,
LOCK=NONE;
-- 인덱스 생성 진행 상황 모니터링
SELECT
STAGE,
EVENT_NAME,
WORK_COMPLETED,
WORK_ESTIMATED,
ROUND(WORK_COMPLETED/WORK_ESTIMATED*100, 1) AS pct_done
FROM performance_schema.events_stages_current
WHERE EVENT_NAME LIKE '%alter%';
상황: 운영 중인 1억 건 테이블에 ALTER TABLE ... ADD INDEX를 실행했더니 잠시 후 The total number of locks exceeds the lock table size 에러가 발생하며 DDL이 실패했습니다.
원인: innodb_buffer_pool_size의 12.5%만큼 할당되는 innodb_lock_table이 가득 찼습니다. 대규모 ALTER 중 변경된 행마다 잠금 정보가 버퍼에 쌓이는데, 기본 설정으로는 행 수가 많을수록 금방 한계에 도달합니다.
-- 현재 lock table 크기 확인
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
-- lock table은 buffer_pool의 약 12.5%
-- 임시 해결: 세션 수준 innodb_lock_table 크기 조정은 불가
-- 서버 수준 설정 변경 필요 (재시작 불필요, 동적 변경 가능)
SET GLOBAL innodb_buffer_pool_size = 4 * 1024 * 1024 * 1024; -- 4GB로 증가
-- 근본 해결: pt-online-schema-change 사용
-- 내부적으로 트리거를 사용해 변경사항을 작은 배치로 처리
pt-online-schema-change \
--alter "ADD INDEX idx_orders_user_status_time (user_id, status, created_at DESC)" \
--chunk-size=5000 \
--max-load="Threads_running=50" \
--critical-load="Threads_running=100" \
--execute \
D=ecommerce_bench,t=orders
교훈: 1억 건 이상 테이블의 DDL은 반드시 pt-osc 또는 gh-ost를 사용합니다. --chunk-size와 --max-load 옵션으로 운영 영향도를 직접 제어할 수 있습니다.
상황: 배치 리포트 생성 쿼리가 정상적으로 실행되다가 어느 순간부터 이 에러로 중단됩니다.
원인: MySQL 8.0에서 max_execution_time (밀리초 단위)이 초과됐습니다. DBA가 최근 max_execution_time = 30000 (30초)을 글로벌 설정으로 추가했고, 데이터가 증가하면서 배치 쿼리가 30초를 넘기기 시작했습니다.
-- 현재 설정 확인
SHOW VARIABLES LIKE 'max_execution_time';
-- 해당 쿼리만 제한 해제 (쿼리 힌트 사용)
SELECT /*+ MAX_EXECUTION_TIME(0) */
DATE(created_at) AS order_date,
COUNT(*) AS total_orders,
SUM(total_amount) AS revenue
FROM orders
WHERE created_at >= '2024-01-01'
GROUP BY DATE(created_at)
ORDER BY order_date;
-- 더 나은 해결: 인덱스 + 쿼리 최적화로 30초 안에 끝내기
-- created_at 인덱스 추가 및 GROUP BY 커버링 인덱스
CREATE INDEX idx_orders_created_amount
ON orders (created_at, total_amount);
-- 이후 쿼리가 0.8초로 단축되어 제한 시간 내 완료
교훈: max_execution_time은 글로벌 설정보다 애플리케이션별로 세션 수준에서 관리하는 것이 안전합니다. 배치 쿼리용 DB 계정은 별도로 만들고 타임아웃을 다르게 설정하세요.
심화 — 옵티마이저의 행 추정과 조인 선택
심화: 카디널리티 추정과 조인 알고리즘 — 통계가 틀리면 계획이 무너진다
지금까지는 인덱스를 잘 걸면 빨라진다였습니다. 그런데 인덱스를 그대로 둔 채로, 어느 날 갑자기 같은 쿼리가 수십 배 느려지는 일이 있습니다. 범인은 인덱스가 아니라 옵티마이저가 계획을 고르는 재료 — 카디널리티(행 수) 추정 — 입니다.
옵티마이저는 통계로 각 계획의 비용을 매겨 가장 싼 것을 고릅니다. 조인에서 이 선택이 특히 극적입니다.
- Nested Loop vs Hash Join. 안쪽(inner) 결과가 적을 것으로 추정되면 매 행마다 인덱스로 반복 조회하는 Nested Loop이 싸 보입니다. 많을 것으로 추정되면 한 번에 해시 테이블을 만드는 Hash Join이 싸 보입니다. 추정이 맞으면 최적이지만, 추정이 틀리면 정반대의 재앙이 됩니다 — 안쪽을 적다고 오판해 Nested Loop을 골랐는데 실제로는 수백만 번 반복하면, 인덱스가 있어도 쿼리가 폭발합니다.
- 독립성 가정이 과소추정을 만듭니다. 옵티마이저는 여러 WHERE 조건을 기본적으로 서로 독립이라 가정해 선택도를 곱합니다. 그런데 상관관계 있는 컬럼(예:
city와country,status와created_at)에서는 이 곱셈이 실제보다 훨씬 작은 행 수를 내놓습니다. 과소추정된 행 수가 그대로 조인 입력으로 들어가 잘못된 조인 알고리즘을 부릅니다. - 데이터가 자라면 임계를 넘습니다. 처음엔 추정 오차가 있어도 데이터가 적어 티가 안 나다가, 데이터가 늘면서 과소추정된 Nested Loop이 어느 순간 임계를 넘어 급격히 느려집니다 — 인덱스는 그대로인데 계획만 바뀌어 느려지는 전형적 패턴입니다.
그래서 EXPLAIN ANALYZE를 볼 때는 실행 시간만이 아니라 노드별 예상 rows와 실제 rows의 차이를 봅니다. 둘이 크게 벌어진 노드가 조인 아래 있으면 그게 원인 후보입니다. 해결은 ANALYZE로 통계를 최신화하고, 상관 컬럼에는 확장 통계(PostgreSQL의 CREATE STATISTICS, MySQL 8의 히스토그램)를 만들어 결합 선택도를 제대로 추정하게 하는 것입니다.
상황: 인덱스도 그대로고 쿼리도 안 바꿨는데, 데이터가 쌓이면서 특정 조인 쿼리만 어느 날부터 수십 초로 느려졌습니다. EXPLAIN을 떠 보니 예전과 조인 방식이 달라져 있습니다.
원인: 상관관계 있는 조건(예: status = paid이면서 created_at이 최근인 주문) 때문에 옵티마이저가 결과 행 수를 크게 과소추정했습니다. 안쪽 입력이 작다고 오판해 Nested Loop을 골랐는데, 실제로는 그 안쪽이 수십만에서 수백만 행이라 반복 조회가 폭발한 것입니다. 데이터가 적을 땐 오차가 티가 안 나다가, 규모가 커지자 임계를 넘었습니다.
진단: EXPLAIN ANALYZE로 노드별 예상 rows와 실제 rows를 비교합니다. 조인 입력이 되는 노드에서 예상 rows가 1 수준인데 actual rows가 수십만이고, 그 위에서 Nested Loop과 큰 loops 값이 보이면 카디널리티 과소추정에 의한 잘못된 조인입니다.
해결: 먼저 ANALYZE로 통계를 최신화합니다. 그래도 상관 컬럼 때문에 추정이 틀리면 확장 통계를 만듭니다 — PostgreSQL은 CREATE STATISTICS ... (dependencies, ndistinct) ON (status, created_at) FROM orders, MySQL 8은 해당 컬럼에 히스토그램을 생성합니다. 통계가 결합 선택도를 반영하면 옵티마이저가 Nested Loop 대신 Hash Join을 골라 정상화됩니다. 급할 때는 옵티마이저 힌트로 조인 방식을 고정할 수 있지만, 이는 통계를 고치는 근본 해결이 아니라 임시방편입니다.
실무 시나리오: 신규 기능 출시 전 DB 성능 리뷰
시니어 엔지니어라면 새 기능의 코드 리뷰 시 쿼리 성능을 함께 검토합니다. PR이 올라왔을 때 아래 체크리스트를 사용합니다.
- 새로 추가된 쿼리에 EXPLAIN 실행 —
type=ALL,key=NULL이 없는지 확인 - WHERE, JOIN ON, ORDER BY 컬럼에 적절한 인덱스가 있는지 확인
- N+1 패턴 확인 — ORM이 루프 내에서 쿼리를 반복 실행하지 않는지
- 기존 테이블에 컬럼/인덱스 추가 시 Online DDL 가능 여부 확인
- 데이터 규모 예측 — 현재는 10만 건이지만 1년 후 1000만 건이 되면?
인터뷰 단골 질문: "슬로우 쿼리가 발생했을 때 어떻게 접근하시나요?" 모범 답변: slow_query_log 확인 → 대상 쿼리 EXPLAIN ANALYZE → 실행 계획에서 Full Scan / filesort / temporary 확인 → 인덱스 추가 또는 쿼리 재작성 → 개선 전후 성능 비교 및 문서화.
명령어·구문 빠른 참조
이 모듈에서 다룬 실행 계획·인덱스 최적화 구문을 모았습니다(MySQL 8.0 기준, PostgreSQL 표기 병기).
| 구문/명령 | 용도 | 예 |
|---|---|---|
EXPLAIN | 실행 없이 예상 계획 확인 | type=ALL·key=NULL이면 Full Table Scan |
EXPLAIN ANALYZE | 실제 실행 + 예상/실측 비교 | EXPLAIN ANALYZE SELECT ... \G |
| 복합 인덱스(등호→정렬 순) | 컬럼 순서로 Full Scan·filesort 제거 | CREATE INDEX ix ON orders (user_id, status, created_at DESC) |
Covering Index (Using index) | 테이블 접근 없이 인덱스만으로 응답 | 조회에 필요한 모든 컬럼을 인덱스에 포함 |
ANALYZE 테이블 | 통계 갱신(예상 vs 실제 rows 괴리 해소) | 통계가 오래되면 잘못된 계획 선택 |
SHOW INDEX FROM t | 현재 인덱스 확인 | SHOW INDEX FROM orders |
USE INDEX (...) | 옵티마이저에 인덱스 힌트(테스트용) | 낮은 카디널리티로 인덱스 무시될 때 |
ALGORITHM=INPLACE, LOCK=NONE | 무중단 온라인 DDL 인덱스 추가 | ALTER TABLE orders ADD INDEX ... ALGORITHM=INPLACE, LOCK=NONE |
pt-online-schema-change / gh-ost | 초대형 테이블 안전 DDL | --chunk-size·--max-load로 부하 제어 |
slow_query_log / long_query_time | 느린 쿼리 수집 | SET GLOBAL long_query_time = 0.5 |
events_statements_summary_by_digest | 누적 기준 슬로우 쿼리 TOP N | ORDER BY SUM_TIMER_WAIT DESC |
/*+ MAX_EXECUTION_TIME(0) */ | 쿼리별 타임아웃 힌트 | 배치 쿼리 제한 해제 |
CREATE STATISTICS / 히스토그램 | 상관 컬럼 카디널리티 보정 | 잘못된 Nested Loop → Hash Join 유도 |
관련 모듈로 더 깊이:
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — 실행 계획에서 찾은 병목을 인덱스·재작성으로 제거하는 법
- B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건 —
type=ALL,key=NULL을 없애는 인덱스 설계의 근본 원리 - N+1 문제, SELECT *, 인덱스 무력화 안티패턴 방지 — Full Scan·filesort를 유발하는 쿼리 패턴 피하기
다음 모듈에서는 Master-Slave 복제 구축과 DB 고가용성(HA) 아키텍처를 다룹니다.