테이블을 만드는 일은 컬럼 이름을 나열하는 것보다 훨씬 중요합니다. 제약조건, 기본값, NULL 허용 여부를 어떻게 두느냐에 따라 애플리케이션 버그를 DB가 막아주기도 하고 방치하기도 합니다. 스키마 기본기를 알면 데이터 품질을 처음부터 지킬 수 있습니다.
데이터베이스 구조의 계층을 명확히 이해하고, DDL을 사용해 테이블을 설계하고 수정하는 실전 능력을 갖춥니다.
- 1Database, Schema, Table, Column, Row로 이어지는 계층 구조를 설명할 수 있다
- 2PostgreSQL과 MySQL의 Schema 개념 차이를 구분할 수 있다
- 3CREATE, ALTER, DROP 같은 DDL로 테이블을 만들고 수정할 수 있다
- 4NOT NULL, UNIQUE, DEFAULT, CHECK 컬럼 제약조건을 설계할 수 있다
- 5일관된 테이블 네이밍 컨벤션을 적용할 수 있다
테이블과 스키마 — 데이터베이스 구조 용어 완전 정리
스키마 설계 없이 기능부터 짜고 나중에 정리하면 된다고 생각했던 시절이 있다. users 테이블 하나에 컬럼을 계속 붙여가다 보니 어느 순간 user_extra_info, user_meta, user_data2 같은 컬럼이 수십 개 생겨났고, 어느 컬럼이 현재 쓰이는 건지 아무도 몰랐다. 거기다 분석팀이 같은 public 스키마에 stats 테이블을 잔뜩 쌓으면서, 특정 테이블 읽기 권한만 주려 해도 민감한 사용자 데이터까지 통째로 노출되는 구조가 돼버렸다. 처음부터 Database > Schema > Table > Column 계층을 이해하고 논리적으로 분리했다면 생기지 않았을 문제다. 이 모듈에서는 그 계층 구조의 의미와, DDL로 테이블을 안전하게 설계하고 수정하는 방법을 실무 관점에서 정리한다. "스키마가 뭐예요?"라는 질문에 MySQL 개발자와 PostgreSQL 개발자가 서로 다른 답을 하는 이유도 여기서 알게 된다.
데이터베이스를 처음 배울 때 가장 혼란스러운 것 중 하나가 용어입니다. "스키마가 데이터베이스야, 테이블이야?" "MySQL과 PostgreSQL에서 스키마의 의미가 다르다던데?" 이 모듈에서는 데이터베이스 구조의 계층과 각 용어의 정확한 의미를 정리하고, DDL로 테이블을 생성하고 수정하는 방법을 익힙니다.
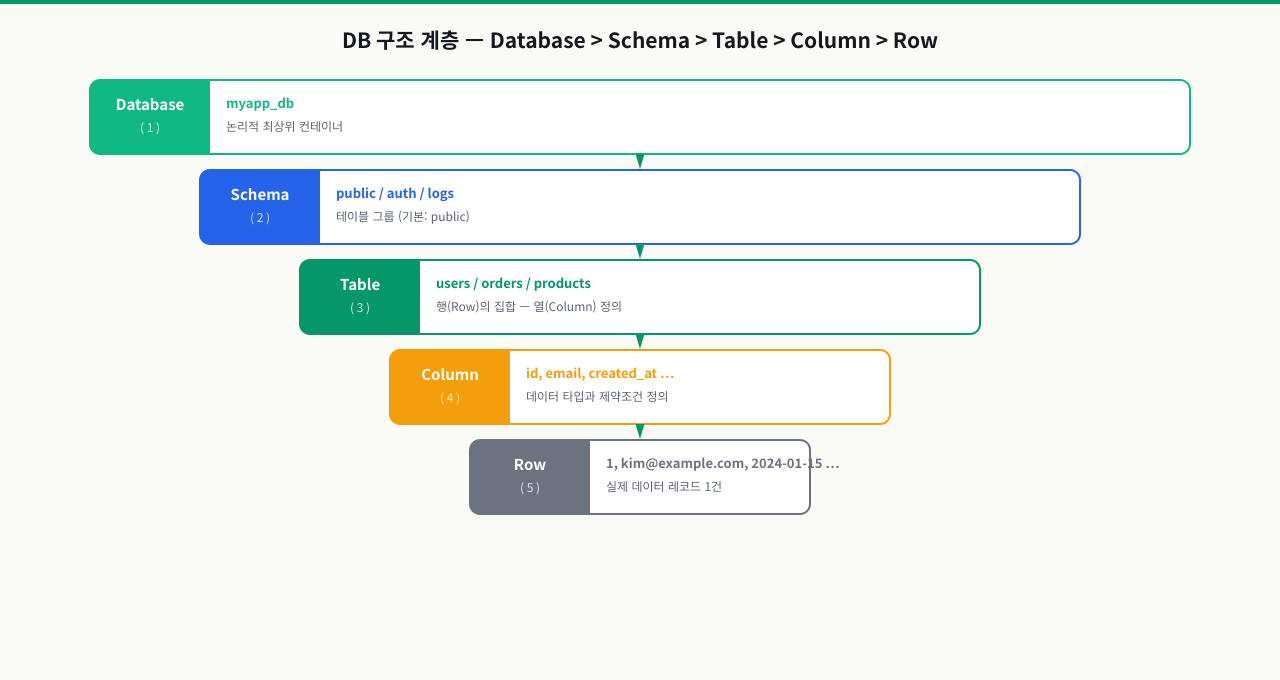
DB 구조 계층 — Database > Schema > Table > Column > Row
DBA가 보낸 접속 정보에 database, schema, table이 따로 있습니다. MySQL에서 쓰던 방식으로 PostgreSQL에 접속했더니 "schema not found"가 납니다. 계층 구조를 이해하지 못하면 "database가 없다"와 "table이 없다"를 같은 오류로 혼동하고, 어디를 어떻게 만들어야 하는지 알 수 없습니다.
 확대
확대
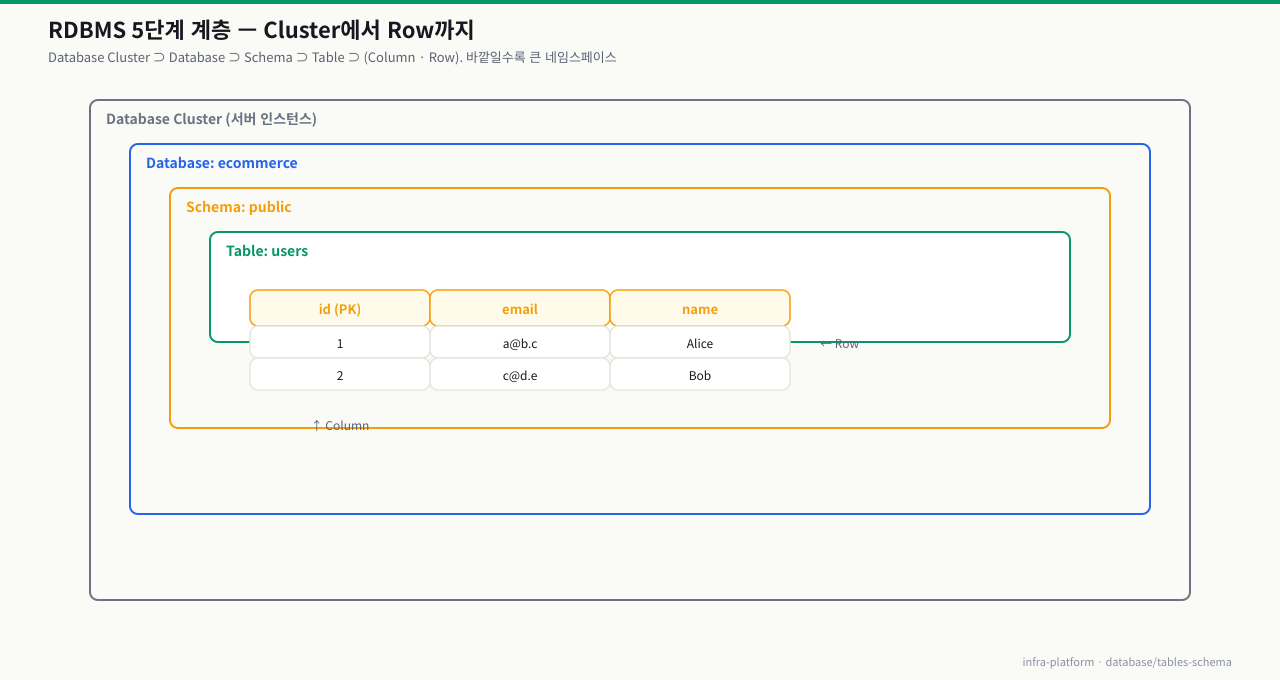
5단계 계층 구조
관계형 데이터베이스는 아래 다이어그램과 같이 5단계 계층으로 구성됩니다. 가장 바깥쪽 Database Cluster는 PostgreSQL 서버 인스턴스 자체이고, 그 안에 여러 Database가 존재합니다. 각 Database 안에 Schema(네임스페이스)가 있고, Schema 안에 Table이 있습니다. Table은 열(Column)과 행(Row)으로 이루어진 2차원 구조입니다.
 확대
확대
각 계층의 역할
| 계층 | 설명 | PostgreSQL 예시 |
|---|---|---|
| Database | 독립적인 데이터 컨테이너. 별도 DB 간 쿼리 불가 | ecommerce, warehouse |
| Schema | DB 내 논리적 네임스페이스. 테이블 그룹화 | public, analytics, audit |
| Table | 실제 데이터가 저장되는 2차원 구조 | users, products, orders |
| Column | 테이블의 세로축. 이름과 타입 정의 | id, email, created_at |
| Row | 테이블의 가로축. 실제 데이터 레코드 | 특정 사용자 1명의 데이터 |
PostgreSQL vs MySQL — Schema 개념 차이
PostgreSQL과 MySQL은 Schema 개념이 완전히 다릅니다. PostgreSQL은 Database와 Schema를 명확히 구분합니다. 하나의 Database 안에 여러 Schema가 공존할 수 있고, 각 Schema는 독립된 네임스페이스로 테이블을 격리합니다. 반면 MySQL/MariaDB에서는 DATABASE와 SCHEMA가 완전히 같은 의미입니다. MySQL에는 PostgreSQL 방식의 중간 Schema 계층이 존재하지 않습니다.
\c ecommerce
CREATE SCHEMA analytics;
CREATE TABLE analytics.daily_stats (
date DATE PRIMARY KEY,
visits INT
);
SELECT * FROM public.users;
SELECT * FROM users;
실행 완료 또는 조회 결과가 표시됩니다.
- search_path 먼저 확인: SHOW search_path; 결과에 public만 있으면 analytics.users와 public.users 중 후자만 단축명으로 접근됩니다. 스키마를 여러 개 쓴다면 search_path 설정을 먼저 확인하세요.
- CREATE SCHEMA 성공 여부: \dn 명령 결과에 새로 만든 스키마 이름이 나타나는지 확인합니다. 없으면 권한 부족(CREATE 권한 필요) 또는 이미 동명 스키마가 존재하는 경우입니다.
- 테이블이 올바른 스키마에 생성됐는지: \dt analytics.* 실행 시 테이블이 나와야 합니다. \dt 만 치면 public 스키마만 조회되므로 스키마 이름을 접두사로 반드시 붙이세요.
- 스키마 접두사 없이 조회 가능한지: SET search_path = analytics; 후 SELECT * FROM users;가 analytics.users를 가리키는지 확인합니다. 다른 스키마 테이블이 나오면 search_path 우선순위를 재점검하세요.
CREATE DATABASE ecommerce;
CREATE SCHEMA ecommerce;
USE ecommerce;
Schema 활용 예시 — 멀티 테넌트 구조
SaaS 서비스에서 고객사별로 Schema를 분리하면, 동일한 Database에서 고객 데이터를 논리적으로 격리할 수 있습니다. search_path를 설정하면 쿼리에서 스키마 이름을 생략할 수 있어 코드 변경 없이 테넌트를 전환할 수 있습니다.
CREATE SCHEMA tenant_acme;
CREATE SCHEMA tenant_bigcorp;
CREATE TABLE tenant_acme.users (id SERIAL PRIMARY KEY, name VARCHAR(100));
CREATE TABLE tenant_bigcorp.users (id SERIAL PRIMARY KEY, name VARCHAR(100));
SET search_path = tenant_acme;
SELECT * FROM users;
개발 초기에 편의상 모든 테이블을 public 스키마에 집어넣었습니다. 서비스가 커지면서 분석팀, 백엔드팀, 감사(audit) 목적의 테이블이 public에 수백 개 섞이게 되었습니다. 분석팀에게 읽기 권한만 주려 해도 public에 있는 모든 테이블이 노출되는 문제가 발생했습니다. 민감한 users 테이블을 분석 쿼리에서 실수로 조회하는 사고도 발생했습니다.
원인: public 스키마는 기본적으로 모든 사용자에게 접근이 허용됩니다. 역할 분리 없이 테이블을 모두 public에 쌓으면 권한 제어가 불가능해집니다.
해결 방법: 초기 설계 단계에서 app, analytics, audit, internal 등의 스키마로 분리합니다. GRANT USAGE ON SCHEMA analytics TO analyst_role;처럼 스키마 단위로 권한을 부여하면 세밀한 접근 제어가 가능합니다. PostgreSQL 15+에서는 public 스키마의 기본 권한이 강화되었으므로 버전도 확인하세요.
DDL로 테이블 만들기 — CREATE, ALTER, DROP
운영 서버에서 컬럼 하나를 추가하려는데 ALTER TABLE이 수백만 건 테이블에서 수 분간 락을 잡습니다. 더 나쁜 경우, DROP COLUMN을 잘못 치면 롤백이 안 됩니다. DDL은 DML과 달리 대부분 즉시 커밋되고, 실수의 복구 비용이 매우 높습니다. 각 DDL 명령어가 어떻게 동작하는지 정확히 알아야 스키마 변경을 안전하게 할 수 있습니다.
 확대
확대
CREATE TABLE — 실전 예시
아래는 이커머스 상품 테이블의 완성도 높은 설계 예시입니다. 기본키에는 자동 증가 정수(SERIAL)를 사용하고, 외래키에는 삭제 정책을 명시합니다. 가격과 재고에는 CHECK 제약으로 음수를 방지하고, status 컬럼은 허용된 값 목록을 CHECK로 제한합니다. 자주 검색되는 category_id와 status 컬럼에는 별도 인덱스를 생성합니다.
CREATE TABLE products (
id SERIAL PRIMARY KEY,
category_id INT NOT NULL
REFERENCES categories(id)
ON DELETE RESTRICT,
name VARCHAR(255) NOT NULL,
slug VARCHAR(255) UNIQUE NOT NULL,
description TEXT,
price DECIMAL(12, 2) NOT NULL
CHECK (price >= 0),
stock INT NOT NULL DEFAULT 0
CHECK (stock >= 0),
status VARCHAR(20) NOT NULL DEFAULT 'active'
CHECK (status IN ('active', 'inactive', 'discontinued')),
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
CREATE INDEX idx_products_category ON products(category_id);
CREATE INDEX idx_products_status ON products(status);
위 CREATE TABLE products 문을 실제 DB에 실행한 뒤, 테이블이 의도대로 만들어졌는지 구조를 조회해 확인합니다. 정의한 컬럼·타입·기본값·CHECK 제약·인덱스가 모두 반영됐는지 한눈에 보는 단계입니다. PostgreSQL은 \d, MySQL은 DESCRIBE/SHOW INDEX를 씁니다.
-- PostgreSQL: 컬럼 + 인덱스 + 제약을 한 번에
\d products
-- MySQL: 컬럼 정의와 인덱스 확인
DESCRIBE products;
SHOW INDEX FROM products;
Table "public.products"
Column | Type | Nullable | Default
-------------+--------------------------+----------+--------------------------------------
id | integer | not null | nextval('products_id_seq'::regclass)
category_id | integer | not null |
price | numeric(12,2) | not null |
status | character varying(20) | not null | 'active'::character varying
Indexes:
"products_pkey" PRIMARY KEY, btree (id)
"idx_products_category" btree (category_id)
"idx_products_status" btree (status)
Check constraints:
"products_price_check" CHECK (price >= 0)
"products_status_check" CHECK (status::text = ANY (ARRAY['active','inactive','discontinued']))
\d products- 먼저 Indexes 섹션을 본다 — products_pkey(PK) + idx_products_category + idx_products_status 3개가 모두 있으면 인덱스 생성까지 성공한 것이다
- Check constraints에 price >= 0 과 status IN (...) 두 제약이 보이는지 확인한다. 없으면 CHECK 절이 누락된 것이다
- Default 열에서 id가 nextval(...)이면 SERIAL이 정상 동작(자동 증가)하는 것이고, status 기본값이 'active'로 잡혔는지 본다
- category_id가 not null인데 REFERENCES가 안 보이면 categories 테이블이 먼저 없어 FK가 빠진 것 — 참조 테이블 생성 순서를 확인한다
주요 컬럼 제약조건
각 제약조건의 역할을 이해하고 적절히 조합하는 것이 중요합니다. NOT NULL은 필수 입력 필드를 보장하고, UNIQUE는 이메일처럼 중복 불가한 값을 관리합니다. DEFAULT는 생략 가능한 값에 자동으로 초기값을 넣어줍니다. CHECK는 비즈니스 규칙을 DB 레벨에서 강제합니다. NOT NULL + DEFAULT 조합이 가장 흔한 실전 패턴입니다.
email VARCHAR(255) NOT NULL
email VARCHAR(255) UNIQUE
created_at TIMESTAMP DEFAULT NOW()
is_active BOOLEAN DEFAULT TRUE
age INT CHECK (age >= 0 AND age <= 150)
price DECIMAL CHECK (price > 0)
status VARCHAR(20) CHECK (status IN ('active','inactive'))
stock INT NOT NULL DEFAULT 0
ALTER TABLE — 테이블 구조 변경
운영 중인 테이블의 구조를 변경할 때는 작업 유형마다 위험도가 다릅니다. 새 컬럼 추가(ADD COLUMN)는 기존 데이터에 영향이 없어 안전합니다. 반면 컬럼 타입 변경이나 대용량 테이블에 NOT NULL 추가는 전체 테이블 재작성(Table Rewrite)을 유발해 서비스 중단을 일으킬 수 있습니다. NOT NULL 추가는 반드시 2단계(DEFAULT 설정 → NULL 제거)로 나눠 진행합니다.
운영 데이터에 적용하면 되돌리기 어려운 변경입니다. 실행 전 대상 테이블, WHERE 조건, 백업 또는 롤백 경로를 반드시 확인하세요.
ALTER TABLE products
ADD COLUMN weight_kg DECIMAL(8, 3);
ALTER TABLE products
ADD COLUMN is_featured BOOLEAN NOT NULL DEFAULT FALSE;
ALTER TABLE products
RENAME COLUMN description TO product_description;
ALTER TABLE products
ALTER COLUMN price TYPE DECIMAL(15, 2);
ALTER TABLE products ALTER COLUMN weight_kg SET DEFAULT 0;
UPDATE products SET weight_kg = 0 WHERE weight_kg IS NULL;
ALTER TABLE products ALTER COLUMN weight_kg SET NOT NULL;
ALTER TABLE products DROP COLUMN weight_kg;
ALTER TABLE products ADD CONSTRAINT chk_price CHECK (price >= 0);
ALTER TABLE products DROP CONSTRAINT chk_price;
DROP 명령어 주의사항
DROP TABLE은 테이블과 모든 데이터를 복구 불가능하게 삭제합니다. CASCADE 옵션은 이 테이블을 FK로 참조하는 다른 테이블의 제약조건까지 함께 삭제하므로 특히 주의가 필요합니다. TRUNCATE는 구조는 유지하면서 데이터만 전체 삭제하며, DELETE보다 훨씬 빠릅니다.
운영 데이터에 적용하면 되돌리기 어려운 변경입니다. 실행 전 대상 테이블, WHERE 조건, 백업 또는 롤백 경로를 반드시 확인하세요.
DROP TABLE products;
DROP TABLE products CASCADE;
DROP TABLE IF EXISTS products;
TRUNCATE TABLE products;
TRUNCATE TABLE products RESTART IDENTITY;
네이밍 컨벤션
일관된 네이밍 컨벤션은 팀 전체의 코드 가독성과 유지보수성을 높입니다. SQL 예약어(order, user, select)를 테이블명으로 사용하면 쿼리마다 따옴표로 감싸야 하므로 반드시 피합니다.
권장 규칙:
테이블명: 복수형 스네이크케이스 → users, order_items, product_categories
컬럼명: 단수형 스네이크케이스 → user_id, created_at, is_active
PK: id (또는 테이블명_id) → id
FK: 참조테이블_id → user_id, category_id
인덱스: idx_테이블_컬럼 → idx_products_category_id
제약조건: chk_테이블_컬럼 → chk_products_price
피해야 할 것:
✗ 예약어 사용: order, user, select (따옴표로 감싸야 해서 불편)
✗ 대소문자 혼용: UserId, ProductName (DB마다 대소문자 처리 다름)
✗ 너무 짧은 이름: u, p, dt (가독성 저하)
B2B SaaS 서비스를 설계할 때 고객사 데이터 격리 방법으로 세 가지 선택지가 있습니다. 첫째, 테이블에 tenant_id 컬럼을 추가하는 방식(Row-level isolation)은 구현이 단순하지만 쿼리마다 WHERE tenant_id = ? 조건을 빠뜨리면 데이터 유출 사고로 이어집니다. 둘째, schema per tenant 패턴은 고객사마다 독립된 스키마를 만들어 완전히 격리하는 방식입니다. SET search_path = tenant_acme만 설정하면 기존 쿼리 코드를 수정하지 않아도 됩니다. 셋째, database per tenant는 격리 수준이 가장 높지만 DB 연결 수와 운영 비용이 급증합니다.
중소 규모 SaaS에서는 schema per tenant가 보안과 운영 비용의 균형이 좋습니다. PostgreSQL의 search_path 기능과 연결 풀러(PgBouncer)를 함께 사용하면 수백 개 테넌트도 효율적으로 관리할 수 있습니다.
CREATE TABLE 한 줄이 저장 구조가 되기까지 — 동작 4단계
CREATE TABLE은 컬럼 이름을 나열하는 선언처럼 보이지만, 실행되는 순간 DB는 그 정의를 파싱해 시스템 카탈로그에 기록하고, 저장 엔진은 이를 물리적인 행 포맷과 페이지 배치로 바꾸며, PK·제약은 인덱스와 삽입 규칙으로 반영됩니다. 이 4단계를 알면 "왜 나중에 타입 하나 바꾸는 게 그렇게 비싼지", "왜 이 INSERT가 제약 위반으로 거부되는지"를 구조적으로 이해할 수 있습니다.
[정의] CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
... )
│
① 파싱·검증 문법·타입·참조 대상(FK 테이블)이 유효한지 확인
│
② 카탈로그 등록 정의를 시스템 카탈로그(pg_class·pg_attribute)에 기록
│ = "이 테이블은 이런 컬럼·타입·기본값을 갖는다"
│
③ 물리 구조 확정 저장 엔진이 행 포맷(컬럼 순서·NULL 비트맵)과
│ 8KB 페이지 배치를 정하고 빈 테이블 파일을 만든다
│
④ 제약·인덱스 반영 PK·UNIQUE → 자동 인덱스 생성,
│ NOT NULL·CHECK·DEFAULT → 이후 INSERT마다 강제될 규칙 등록
▼
[INSERT 시] 각 행이 ③의 포맷으로 페이지에 담기고, ④의 규칙을 통과해야 저장된다
각 단계에서 무슨 일이 일어나고, 여기서 어긋나면 무엇이 문제인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 파싱·검증 | 문법·타입·FK 참조 대상 확인 | 참조할 테이블이 아직 없으면 FK 생성 실패 (생성 순서 문제) |
| ② 카탈로그 등록 | 컬럼·타입·기본값을 카탈로그에 기록 | 나중의 타입 변경은 이 정의를 다시 쓰는 일 → 대형 테이블 ALTER가 테이블 재작성·락 유발 |
| ③ 물리 구조 확정 | 행 포맷·페이지 배치 결정 | 컬럼 순서·NULL 허용이 행 크기·정렬 패딩에 영향 (같은 컬럼도 배치 따라 용량 차이) |
| ④ 제약·인덱스 반영 | PK·UNIQUE=인덱스, NOT NULL·CHECK=삽입 규칙 | 기본값·NULL 허용을 잘못 두면 값 없는 행이 제약 위반으로 거부 |
즉 "테이블을 만든다"는 이름을 적는 게 아니라 저장 포맷과 규칙을 확정하는 일입니다. 스키마 변경이 비싼 이유가 ②③에 있고(정의와 물리 구조를 다시 써야 하므로), 제약 위반·기본값·NULL 관련 오류는 ④에서 납니다. 그래서 컬럼 타입·제약·기본값은 실행 후 고치는 것보다 CREATE TABLE 시점에 신중히 정하는 편이 훨씬 쌉니다.
심화 — 빠른 DDL이 서비스를 멈추는 순간
심화: ALTER TABLE의 진짜 위험은 '작업 시간'이 아니라 '락 큐'다
앞의 DecisionTable은 각 DDL이 "얼마나 오래 락을 잡는가"를 다뤘습니다. 그런데 현업에서 DDL로 장애가 나는 대부분은 무거운 테이블 재작성이 아니라, 밀리초면 끝날 빠른 DDL이 정작 락을 얻지 못해 대기하는 동안 벌어집니다. 한 단계 더 들어가 락의 종류와 큐가 어떻게 맞물리는지 봐야 이 함정을 피할 수 있습니다.
- AccessExclusiveLock의 파급력: ALTER TABLE은 대부분 가장 강한 락인 AccessExclusiveLock을 요구합니다. 이 락은 심지어 SELECT가 쓰는 가장 약한 락(AccessShareLock)과도 충돌합니다. 즉 DDL이 이 락을 쥐거나, 쥐려고 대기만 해도 단순 조회조차 통과하지 못합니다.
- 락 큐는 FIFO다: PostgreSQL은 락 요청을 대체로 도착 순서대로 부여합니다. 문제는 DDL이 앞선 롱 트랜잭션 때문에 락을 못 얻고 큐 맨 앞에서 기다릴 때입니다. 그 뒤로 도착한 평범한 SELECT는 "앞사람(DDL)이 원하는 락과 충돌"하므로 함께 줄을 섭니다. 롱 트랜잭션 하나 + 빠른 DDL 하나 = 테이블 전체 정지.
- 원흉은 대개 '느린 조회'나 'idle in transaction': 커밋을 깜빡한 세션, 리포트용 초장시간 SELECT, 커넥션 풀이 잡고 놓지 않은 트랜잭션이 흔한 범인입니다. DDL 자체는 죄가 없고, 앞에서 락을 놓지 않는 세션이 진짜 문제입니다.
- 안전장치는 lock_timeout: DDL을 실행하기 직전
SET lock_timeout = '3s'처럼 걸어 두면, 락을 그 시간 안에 못 얻은 DDL이 큐를 오래 막는 대신 스스로 실패합니다. 애플리케이션은 그 실패를 받아 한적한 시점에 재시도하면 됩니다. "무중단 마이그레이션"의 핵심은CONCURRENTLY만이 아니라 이 짧은 lock_timeout + 재시도 조합입니다.
그래서 성숙한 팀은 마이그레이션 스크립트 맨 앞에 lock_timeout과 statement_timeout을 항상 심어 둡니다 — 마이그레이션이 실패해도 서비스는 살아 있어야 하니까요.
상황: 마이그레이션에서 nullable 컬럼 하나를 추가하는, DecisionTable에서 '안전'으로 분류된 DDL을 실행했습니다. 그런데 배포 직후 그 테이블을 조회하는 모든 요청이 동시에 멈췄고, 대시보드의 활성 커넥션 수가 급등하며 커넥션 풀이 고갈됐습니다.
원인: ADD COLUMN 작업 자체는 메타데이터만 바꿔 밀리초면 끝납니다. 문제는 그 순간 리포트용 SELECT 하나가 몇 분째 그 테이블을 읽고 있었다는 점입니다. DDL은 AccessExclusiveLock이 필요한데 그 SELECT의 락과 충돌해 큐 맨 앞에서 대기했고, PostgreSQL 락 큐는 FIFO라 뒤이어 들어온 평범한 조회까지 DDL 뒤에 줄줄이 막혔습니다. 빠른 DDL이 느린 조회 하나 때문에 테이블 전체를 세운 것입니다.
진단: pg_stat_activity에서 state와 query_start를 보고 오래 떠 있는 세션(장시간 SELECT, idle in transaction)을 찾습니다. pg_locks를 대상 테이블 relation으로 조인하면 누가 락을 granted로 쥐고 누가 DDL 때문에 waiting인지 한눈에 보입니다. 대기 세션의 맨 앞이 ALTER면 확정입니다.
해결: 급한 불은 락을 쥔 롱 트랜잭션을 정리(정당하면 완료를 기다리고, 안전하면 종료)해 끄고 DDL을 다시 실행합니다. 진짜 대책은 재발 방지입니다 — 모든 마이그레이션 앞에 SET lock_timeout = '3s';를 걸어 락을 못 얻은 DDL이 큐를 막는 대신 스스로 실패·재시도하게 하고, 애초에 그 테이블을 오래 읽는 리포트 쿼리는 읽기 복제본으로 보냅니다. '작업이 빠른 DDL'과 '안전한 DDL'은 다릅니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 DDL 구문을 실전 옵션과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
CREATE SCHEMA | DB 안에 네임스페이스 생성 | CREATE SCHEMA analytics; → analytics.users로 이름 충돌 격리 |
CREATE TABLE | 테이블 정의(컬럼·제약) | CREATE TABLE products (id SERIAL PRIMARY KEY, price DECIMAL(12,2) CHECK (price >= 0)); |
SERIAL PRIMARY KEY | 자동 증가 기본키 | id SERIAL PRIMARY KEY (nextval로 자동 채움) |
REFERENCES ... ON DELETE | 외래키 + 삭제 정책 | category_id INT REFERENCES categories(id) ON DELETE RESTRICT |
NOT NULL / UNIQUE / DEFAULT / CHECK | 컬럼 제약 | status VARCHAR(20) NOT NULL DEFAULT 'active' CHECK (status IN ('active','inactive')) |
CREATE INDEX | 조회 컬럼 인덱스 | CREATE INDEX idx_products_status ON products(status); (대형 테이블은 CREATE INDEX CONCURRENTLY) |
\d / DESCRIBE | 테이블 구조 확인 | PostgreSQL \d products / MySQL DESCRIBE products; |
ALTER TABLE ... ADD COLUMN | 컬럼 추가 | ALTER TABLE products ADD COLUMN weight_kg DECIMAL(8,3); (nullable은 거의 즉시) |
ALTER TABLE ... RENAME COLUMN | 컬럼 이름 변경 | ALTER TABLE products RENAME COLUMN description TO product_description; |
ALTER TABLE ... ALTER COLUMN | 타입·기본값·NOT NULL 변경 | 안전 3단계: SET DEFAULT 0 → UPDATE ... WHERE col IS NULL → SET NOT NULL |
ALTER TABLE ... ADD/DROP CONSTRAINT | 제약 추가·삭제 | ALTER TABLE products ADD CONSTRAINT chk_price CHECK (price >= 0); |
DROP TABLE | 테이블·데이터 삭제 | DROP TABLE IF EXISTS products; / FK 참조까지 DROP TABLE products CASCADE; |
TRUNCATE TABLE | 구조 유지, 데이터 전체 삭제 | TRUNCATE TABLE products RESTART IDENTITY; (DELETE보다 빠름) |
SET lock_timeout | DDL 락 대기 상한(무중단 마이그레이션) | 마이그레이션 앞에 SET lock_timeout = '3s'; |
관련 모듈로 더 깊이:
- 정밀한 데이터 타입(숫자·문자·날짜) 선택 기준 — 각 컬럼에 어떤 타입을 줄지의 선택 기준
- PK, FK 제약조건과 Cascade 설정이 주는 영향 — 테이블 간 관계를 정의하는 기본키/외래키 설계
- 제1·2·3정규화와 역정규화(De-normalization) 실전 적용 기준 — 테이블을 어떻게 쪼개고 합칠지의 정규화 원리
다음 모듈에서는 숫자, 문자, 날짜 등 정밀한 데이터 타입 선택 기준과 잘못된 타입 선택이 가져오는 실무 문제를 다룹니다.