같은 복잡한 조회가 여러 API에서 반복되면 쿼리 중복과 권한 관리가 어려워집니다. View와 Stored Procedure는 DB 안에 재사용 가능한 조회·로직 경계를 만드는 방법입니다. 언제 쓰고 언제 피해야 하는지 알아야 유지보수 비용을 줄일 수 있습니다.
View는 쿼리 추상화와 권한 제어에 효과적이고, Materialized View는 집계 성능 향상에 유용합니다. 저장 프로시저는 네트워크 왕복을 줄이지만 현대 개발에서는 유지보수 문제로 신중하게 사용해야 합니다.
- 1CREATE VIEW 문법으로 뷰를 만들고 그 특성을 설명할 수 있다
- 2View로 민감 데이터를 숨겨 권한을 제어할 수 있다
- 3Materialized View로 결과를 캐싱하고 갱신 전략을 적용할 수 있다
- 4언제 View를 쓰고 언제 피해야 하는지 판단할 수 있다
- 5저장 프로시저의 기본 문법으로 작성하고 실행할 수 있다
- 6현대 개발에서 저장 프로시저를 언제 써야 하는지 판단할 수 있다
- 7DB 함수와 저장 프로시저의 차이를 구분할 수 있다
뷰(View)와 저장 프로시저 — 언제 쓰고 언제 피하는가
View와 저장 프로시저는 데이터베이스에서 로직을 재사용하는 두 가지 방법입니다. View는 복잡한 쿼리를 단순하게 감추고, 저장 프로시저는 여러 SQL을 묶어 하나의 단위로 실행합니다. 하지만 둘 다 "항상 좋은 것"이 아니며, 잘못 사용하면 유지보수 악몽이 됩니다.
View vs Materialized View — 조회 추상화의 두 가지 방식
복잡한 JOIN 쿼리가 여러 화면에서 반복됩니다. 한 곳에서 수정하면 다른 곳도 바꿔야 합니다. View를 쓰면 쿼리를 한 곳에 정의하고 테이블처럼 참조할 수 있습니다. 그런데 View를 써도 매번 원본 쿼리가 실행되어 대시보드가 느립니다. Materialized View는 결과를 캐싱해서 이 문제를 해결하지만 데이터가 실시간이 아닙니다.
 확대
확대
일반 View — 쿼리의 별칭
일반 View는 SELECT 쿼리에 이름을 붙여 테이블처럼 사용할 수 있게 합니다. View를 조회할 때마다 정의된 쿼리가 실행되므로 항상 최신 데이터를 반환합니다. 데이터를 물리적으로 저장하지 않아 디스크 공간을 차지하지 않습니다.
주의사항: View 정의 안에 SELECT *를 쓰면 원본 테이블에 컬럼이 추가되어도 View는 생성 당시 컬럼만 반환합니다. 반드시 컬럼을 명시합니다.
CREATE VIEW v_order_summary AS
SELECT
o.id AS order_id,
o.status,
o.created_at,
u.id AS user_id,
u.name AS user_name,
u.email AS user_email,
COUNT(oi.id) AS item_count,
SUM(oi.quantity * oi.unit_price) AS total_amount
FROM orders o
JOIN users u ON o.user_id = u.id
LEFT JOIN order_items oi ON o.id = oi.order_id
WHERE o.deleted_at IS NULL
GROUP BY o.id, o.status, o.created_at, u.id, u.name, u.email;
SELECT * FROM v_order_summary
WHERE user_id = 42
ORDER BY created_at DESC;
CREATE OR REPLACE VIEW v_order_summary AS
SELECT
o.id AS order_id,
o.status,
o.created_at,
u.name AS user_name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.deleted_at IS NULL;
DROP VIEW IF EXISTS v_order_summary;
DROP VIEW IF EXISTS v_order_summary CASCADE;
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 EXPLAIN으로 View 조회의 실행 계획을 확인합니다. 일반 View는 정의된 쿼리를 그대로 실행하므로 기반 테이블에 인덱스가 없으면 Seq Scan이 발생합니다 — View가 느리면 기반 쿼리의 인덱스를 먼저 점검하세요.
- 원본 테이블에 행을 추가한 뒤 View를 즉시 조회합니다. 일반 View는 즉시 반영돼야 합니다. 반영되지 않는다면 Materialized View를 잘못 사용한 것이거나 캐시가 끼어 있는 것입니다.
- 두 시그널을 조합합니다: View 조회 응답 시간이 3초 이상이고 + 데이터 실시간성이 1시간 지연을 허용한다면 → Materialized View로 전환하고 주기적 REFRESH로 결과를 캐싱하는 것이 적합합니다.
View를 통한 권한 제어
View는 민감한 컬럼을 숨기거나 특정 행만 노출하는 권한 제어 레이어로 활용할 수 있습니다. 분석팀에게 원본 테이블 접근은 차단하고 View만 허용하면, 개인정보를 노출하지 않고 분석에 필요한 데이터를 제공할 수 있습니다.
이메일 마스킹처럼 민감 정보를 일부 표시해야 하는 경우 View 정의 안에서 변환 함수를 적용합니다.
CREATE VIEW v_users_public AS
SELECT
id,
name,
created_at,
LEFT(email, 2) || '***@***' AS email_masked
FROM users
WHERE deleted_at IS NULL;
GRANT SELECT ON v_users_public TO analyst_role;
REVOKE SELECT ON users FROM analyst_role;
CREATE VIEW v_dept_employees AS
SELECT *
FROM employees
WHERE department_id = current_setting('app.current_department_id')::INT;
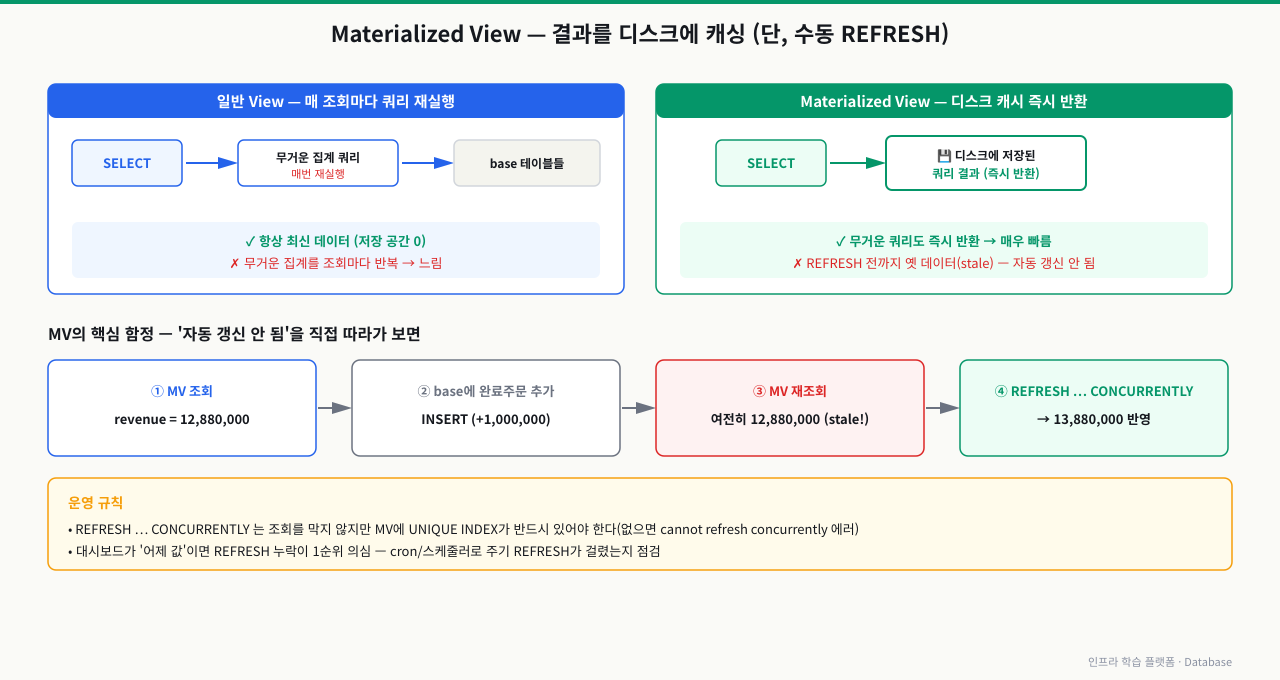
Materialized View — 결과를 디스크에 캐싱
Materialized View는 쿼리 결과를 물리적으로 디스크에 저장합니다. 조회 시 쿼리를 다시 실행하지 않으므로, 집계나 복잡한 JOIN을 포함한 무거운 쿼리도 빠르게 반환됩니다. 단점은 원본 데이터가 변경되어도 자동으로 반영되지 않고 REFRESH 명령을 수동으로 실행해야 한다는 것입니다.
WITH DATA로 생성하면 즉시 데이터가 채워지고, WITH NO DATA로 생성하면 구조만 만들어집니다. CONCURRENTLY 갱신을 위해서는 UNIQUE INDEX가 반드시 있어야 합니다.
 확대
확대
CREATE MATERIALIZED VIEW mv_monthly_revenue AS
SELECT
DATE_TRUNC('month', o.created_at) AS month,
p.category,
COUNT(DISTINCT o.id) AS order_count,
COUNT(DISTINCT o.user_id) AS customer_count,
SUM(oi.quantity * oi.unit_price) AS revenue
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
WHERE o.status = 'completed'
GROUP BY 1, 2
WITH DATA;
CREATE UNIQUE INDEX ON mv_monthly_revenue (month, category);
REFRESH MATERIALIZED VIEW mv_monthly_revenue;
REFRESH MATERIALIZED VIEW CONCURRENTLY mv_monthly_revenue;
MV의 핵심 함정은 "자동 갱신 안 됨"입니다. MV를 조회하고 → 원본에 주문을 추가하고 → 다시 조회해 값이 그대로인지(오래됨) 확인한 뒤, REFRESH 후 값이 바뀌는지 봅니다.
-- (1) 현재 MV 값
SELECT month, category, revenue FROM mv_monthly_revenue WHERE category = 'electronics';
-- (2) 원본에 완료 주문 추가 (revenue가 늘어야 정상)
INSERT INTO order_items (order_id, product_id, quantity, unit_price)
VALUES (99999, 1, 2, 500000);
-- (3) MV 재조회 — 아직 옛날 값 그대로다(자동 반영 안 됨)
SELECT month, category, revenue FROM mv_monthly_revenue WHERE category = 'electronics';
-- (4) REFRESH 후 다시 조회 — 이제 반영됨
REFRESH MATERIALIZED VIEW CONCURRENTLY mv_monthly_revenue;
SELECT month, category, revenue FROM mv_monthly_revenue WHERE category = 'electronics';
-- (1)/(3) 동일 (stale)
revenue
-----------
12880000
-- (4) REFRESH 후
revenue
-----------
13880000 ← +1,000,000 반영
SELECT revenue FROM mv_monthly_revenue WHERE category = 'electronics';- (3)의 값이 (1)과 같은지 본다 — 같아야 정상이다. MV는 원본 변경을 자동 반영하지 않는다는 걸 직접 확인하는 것(이게 stale의 정체)
- (4) REFRESH 후 값이 증가했는지 확인. 안 변하면 INSERT가 status='completed' 조건이나 JOIN 대상에서 빠진 것 — MV 정의의 WHERE를 다시 본다
- CONCURRENTLY가 'cannot refresh ... concurrently' 에러를 내면 UNIQUE INDEX가 없는 것 — MV에 CREATE UNIQUE INDEX가 선행돼야 한다
- 운영 판단: 대시보드 수치가 '어제 값'이면 REFRESH 누락이 1순위 의심 — cron/스케줄러로 주기 REFRESH가 걸려 있는지 점검한다
언제 View를 쓰고 언제 피하는가
| 기준 | 일반 View | Materialized View | View를 피해야 할 때 |
|---|---|---|---|
| 데이터 신선도 | 항상 최신 | 마지막 REFRESH 기준 | — |
| 조회 성능 | 쿼리 복잡도에 따라 다름 | 매우 빠름 (인덱스 가능) | — |
| 디스크 사용 | 없음 | 원본 데이터와 유사한 크기 | — |
| 갱신 방법 | 자동 (항상 최신) | REFRESH 명령 수동 실행 | — |
| 적합한 사례 | OLTP, 실시간 데이터, 권한 제어 | 대시보드, 주기적 집계 리포트 | — |
| 피해야 할 사례 | — | — | View 위에 View 중첩, 잦은 갱신이 필요한 집계 |
View를 피해야 하는 상황: 복잡한 View 위에 다시 View를 쌓으면(중첩 뷰) 옵티마이저가 전체 쿼리 계획을 최적화하기 어려워집니다. 또한 실시간 집계가 필요한 데이터에 Materialized View를 쓰면 오래된 데이터를 제공하게 됩니다.
월별 매출 보고서 API가 20줄 이상의 복잡한 JOIN 쿼리를 직접 포함하고 있었습니다. 같은 쿼리가 3개 API 엔드포인트에 중복 존재해, 쿼리 수정 시 모든 곳을 동기화해야 했습니다.
월별 집계 데이터는 1시간 지연이 허용되었기 때문에 Materialized View로 결과를 저장하고, pg_cron으로 매 시간 REFRESH MATERIALIZED VIEW CONCURRENTLY를 실행하도록 설정했습니다.
API 코드는 SELECT * FROM mv_monthly_revenue WHERE month = $1처럼 단순해졌고, 평균 응답 시간이 3.2초에서 12ms로 감소했습니다. 쿼리 변경이 필요할 때도 View 정의 한 곳만 수정하면 됩니다.
Materialized View를 생성한 후 REFRESH 스케줄을 설정하지 않으면, 처음 생성 시점의 데이터가 그대로 유지됩니다. 대시보드에서 "오늘 주문 건수 0건"처럼 이상한 데이터가 표시될 때 이 문제를 의심합니다.
확인 방법: 아래 쿼리로 각 Materialized View의 마지막 갱신 시간을 확인합니다.
SELECT schemaname, matviewname, last_refresh
FROM pg_matviews
ORDER BY last_refresh ASC NULLS FIRST;
해결 방법: pg_cron 또는 외부 스케줄러(cron, Airflow 등)로 주기적 REFRESH를 설정합니다. 운영 중에는 조회를 차단하지 않는 REFRESH MATERIALIZED VIEW CONCURRENTLY를 사용하고, 이를 위해 UNIQUE INDEX가 반드시 존재해야 합니다.
저장 프로시저(Stored Procedure) — 현대 개발에서의 위치
레거시 시스템에 수백 개의 저장 프로시저가 있습니다. 비즈니스 로직이 DB에 묻혀 있어서 어디서 무슨 일이 일어나는지 파악이 어렵습니다. 반면 새 시스템 설계에서는 "저장 프로시저 쓰지 마라"는 말이 나옵니다. 현대 개발에서 언제 쓰고 언제 피해야 하는지 알아야 기존 코드를 읽고, 새 설계에서 올바른 판단을 할 수 있습니다.
저장 프로시저 기본 문법
저장 프로시저(SP)는 여러 SQL 문을 하나의 이름으로 DB에 저장해두고 CALL 문으로 호출하는 기능입니다. DECLARE로 지역 변수를 선언하고, IF 분기, RAISE EXCEPTION으로 오류 처리, COMMIT/ROLLBACK으로 트랜잭션 제어가 가능합니다.
아래는 주문 취소 처리를 SP로 구현한 예시입니다. 상태 확인, 주문 취소 업데이트, 재고 복원, 이력 기록을 하나의 트랜잭션으로 묶어 처리합니다.
CREATE OR REPLACE PROCEDURE proc_cancel_order(
p_order_id BIGINT,
p_reason VARCHAR(500)
)
LANGUAGE plpgsql
AS $$
DECLARE
v_status VARCHAR(20);
BEGIN
SELECT status INTO v_status
FROM orders WHERE id = p_order_id;
IF v_status IS NULL THEN
RAISE EXCEPTION '주문을 찾을 수 없습니다: %', p_order_id;
END IF;
IF v_status = 'completed' THEN
RAISE EXCEPTION '완료된 주문은 취소할 수 없습니다';
END IF;
UPDATE orders
SET status = 'cancelled',
cancelled_at = NOW(),
cancel_reason = p_reason
WHERE id = p_order_id;
UPDATE inventory i
SET stock = i.stock + oi.quantity
FROM order_items oi
WHERE oi.order_id = p_order_id
AND i.product_id = oi.product_id;
INSERT INTO order_logs (order_id, action, note, created_at)
VALUES (p_order_id, 'CANCELLED', p_reason, NOW());
COMMIT;
END;
$$;
CALL proc_cancel_order(12345, '고객 요청으로 취소');
DB Function vs Stored Procedure
Function과 Procedure는 모두 DB에 로직을 저장하지만 용도가 다릅니다. Function은 반드시 값을 반환하고 SELECT 쿼리 안에서 사용할 수 있지만 트랜잭션 제어(COMMIT/ROLLBACK)는 불가능합니다. Procedure는 반환값이 없고 SELECT 안에서 호출할 수 없지만 트랜잭션을 직접 제어할 수 있습니다.
CREATE OR REPLACE FUNCTION fn_calculate_discount(
p_amount NUMERIC,
p_user_tier VARCHAR(20)
)
RETURNS NUMERIC
LANGUAGE plpgsql
AS $$
BEGIN
RETURN CASE p_user_tier
WHEN 'gold' THEN p_amount * 0.85
WHEN 'silver' THEN p_amount * 0.90
ELSE p_amount * 0.95
END;
END;
$$;
SELECT
product_name,
price,
fn_calculate_discount(price, 'gold') AS gold_price
FROM products;
| 특성 | FUNCTION | STORED PROCEDURE |
|---|---|---|
| 반환값 | 반드시 있음 | OUT 파라미터 또는 없음 |
| SELECT 내 사용 | 가능 | 불가능 |
| COMMIT/ROLLBACK | 불가능 | 가능 |
| 호출 방법 | SELECT fn() 또는 쿼리 내 | CALL proc() |
| 용도 | 값 계산, 변환 | 복잡한 트랜잭션 처리 |
저장 프로시저의 장단점과 현대적 관점
현대 웹 서비스 개발에서 저장 프로시저는 사용이 점점 줄고 있습니다. 애플리케이션 레이어에서 비즈니스 로직을 관리하는 것이 테스트, 버전 관리, 배포 측면에서 유리하기 때문입니다.
| 구분 | 내용 |
|---|---|
| 장점 | 네트워크 왕복 감소 — 여러 SQL을 하나의 CALL로 처리 |
| 장점 | DB 내 로직 — 어떤 언어/프레임워크에서도 일관된 동작 |
| 장점 | 권한 분리 — EXECUTE 권한만 부여해 테이블 직접 접근 차단 |
| 장점 | 배치 처리 — 대용량 데이터 처리 시 효율적 |
| 단점 | 버전 관리 어려움 — SQL 파일을 Git으로 관리하기 어렵고 코드 리뷰가 불편함 |
| 단점 | 테스트 어려움 — 단위 테스트 작성이 복잡하고 CI/CD 통합이 어려움 |
| 단점 | 로직 분산 — 비즈니스 로직이 DB와 앱 양쪽에 나뉘어 일관성 유지 어려움 |
| 단점 | 이식성 없음 — PostgreSQL SP는 MySQL에서 동작하지 않음 |
SP가 여전히 유용한 경우
SP와 트리거가 실용적인 상황이 있습니다. 감사 로그(audit log)처럼 모든 테이블 변경에 자동으로 기록이 필요한 경우, 트리거를 통한 자동화가 애플리케이션 코드에서 누락될 위험 없이 일관성을 보장합니다.
아래는 모든 테이블 변경을 자동으로 감사 로그에 기록하는 트리거 함수입니다. TG_TABLE_NAME과 TG_OP로 어느 테이블에서 어떤 작업이 발생했는지 자동으로 기록합니다.
CREATE OR REPLACE FUNCTION fn_audit_log()
RETURNS TRIGGER
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO audit_logs (
table_name, operation, old_data, new_data, changed_at, changed_by
)
VALUES (
TG_TABLE_NAME,
TG_OP,
row_to_json(OLD),
row_to_json(NEW),
NOW(),
current_setting('app.current_user_id', true)
);
RETURN NEW;
END;
$$;
CREATE TRIGGER trg_users_audit
AFTER INSERT OR UPDATE OR DELETE ON users
FOR EACH ROW EXECUTE FUNCTION fn_audit_log();
대용량 데이터 배치 처리나 반복 사용되는 복잡한 집계 계산에도 SP와 Function이 유용합니다.
CALL proc_archive_old_orders(cutoff_date := '2023-01-01');
비즈니스 대시보드에 오늘 매출이 0원으로 표시되는 버그 신고가 들어왔습니다. Materialized View가 전날 생성된 후 한 번도 REFRESH되지 않은 것이 원인이었습니다.
REFRESH 스케줄이 없거나 스케줄러 작업이 실패한 경우 이런 문제가 발생합니다. 모니터링이 없으면 얼마나 오래된 데이터인지도 알 수 없습니다.
해결 방법: Materialized View마다 마지막 갱신 시간을 Grafana나 슬랙 알림으로 모니터링합니다. REFRESH 실패 시 알림이 오도록 설정하고, 수동 복구 절차를 문서화합니다.
뷰·프로시저를 호출하면 DB가 실제로 실행하는 순서 — 재작성부터 계획 재사용까지
앞에서 뷰·Materialized View·프로시저가 무엇이고 언제 쓰는지를 봤습니다. 그런데 "왜 어떤 뷰는 인덱스를 타고 어떤 뷰는 전체를 훑는지", "왜 프로시저는 두 번째 호출부터 빨라지는지"는, DB가 이들을 실행하는 순서를 알아야 보입니다. 뷰 참조와 프로시저 호출이 각각 파싱 → 재작성 → 계획 → 실행을 어떻게 지나는지 따라가 봅니다.
[뷰를 조회할 때] SELECT * FROM v_order_summary WHERE user_id = 42
│
① 파싱 — 구문 검사, 구문 트리 생성
│
② 재작성(rewrite) — 뷰 정의를 바깥 쿼리에 병합(inline)
│ Materialized View면 재작성 없이 디스크에 저장된 결과를 읽음
│
③ 계획 수립 — 옵티마이저가 인덱스·조인 방법 결정
│ 단순 뷰: 바깥 WHERE(user_id=42)를 base 테이블로 밀어넣어 인덱스 사용
│ 윈도우·DISTINCT 낀 뷰: 못 밀어넣어 base 전체 계산(아래 심화 참고)
│
④ 실행 — 기반 테이블에서 행 읽기 (일반 뷰는 조회마다 재실행)
▼
결과
[프로시저를 호출할 때] CALL proc_cancel_order(42, '고객 요청')
│
① 파싱 — 본문의 여러 SQL을 구문 트리로
│
② 컴파일 — 최초 호출에서 본문 문장별 실행 계획을 준비
│
③ 계획 캐시 — 세션에 계획을 저장(첫 파라미터 기준 generic plan)
│
④ 재사용 — 다음 CALL부터 캐시된 계획을 그대로 사용
▼
결과 (매 호출마다 파싱·계획을 다시 하지 않아 빠름)
각 단계가 하는 일과, 여기서 생기는 성능 이슈:
| 단계 | 뷰·프로시저가 하는 일 | 여기서 생기는 성능 이슈 |
|---|---|---|
| ① 파싱 | 구문 검사·구문 트리 생성 | 거의 문제 없음 |
| ② 재작성 / 컴파일 | 뷰는 정의를 바깥 쿼리에 inline · 프로시저는 본문을 계획 | 윈도우·DISTINCT·중첩 뷰는 조건을 못 밀어넣어 base 전체 계산 · MV는 재작성 없이 stale한 저장 결과 반환 |
| ③ 계획 수립·캐시 | 옵티마이저가 인덱스·조인 결정 · 프로시저·PREPARE는 계획을 캐시 | 첫 호출 파라미터로 만든 generic plan이 값 분포가 크게 다른 다음 인자에 안 맞으면 느려짐(파라미터 스니핑류) |
| ④ 실행·재사용 | base 테이블에서 실제 행 읽기 | 일반 뷰는 조회마다 무거운 정의 쿼리를 재실행(느리면 MV로) · 프로시저는 계획 재사용으로 절약 |
정리하면, 뷰의 속도는 ②~③에서 결정됩니다 — 바깥 WHERE가 base까지 내려가면(밀어넣기 성공) 인덱스를 타고, 윈도우·DISTINCT에 막히면 전체를 훑습니다(자세한 내막은 아래 심화). Materialized View는 최신성을 내주고 ②~④를 건너뛰어 저장된 결과만 읽기에 빠른 대신 stale합니다. 프로시저는 ①~③을 캐시하기에 두 번째 호출부터 빠르지만, 바로 그 캐시 때문에 어떤 인자에선 빠르고 어떤 인자에선 느릴 수 있습니다(generic plan). 여기에 권한 매핑을 얹으면 경계가 완성됩니다 — base 테이블 권한을 회수하고 뷰에는 SELECT, 프로시저에는 EXECUTE 권한만 부여하면, 어느 단계에서 무엇에 접근하는지를 뷰·프로시저 경계로 통제할 수 있습니다. 진단은 EXPLAIN으로 뷰 재작성 후의 계획을 확인하고, 프로시저가 특정 인자에서만 느리면 계획 캐시(generic plan)를 의심하는 순서로 좁힙니다.
심화 — View는 공짜 추상화가 아니다
심화: 옵티마이저가 조건을 밀어넣지 못하는 View
앞에서 "중첩 뷰는 옵티마이저가 최적화하기 어렵다"고 짧게 언급했습니다. 왜 그런지 한 단계 들어가면, View의 성능은 '무엇을 감쌌느냐'에 따라 완전히 갈립니다. 바깥에서 건 WHERE가 View 안으로 내려가느냐(predicate pushdown)가 핵심입니다.
- 잘 되는 경우 — inlining과 predicate pushdown: 단순 View는 옵티마이저가 정의 쿼리를 바깥 쿼리에 합쳐(inlining) 하나의 쿼리처럼 다룹니다. 그래서
SELECT * FROM v WHERE user_id = 42의 조건이 base 테이블까지 내려가 user_id 인덱스를 씁니다 — View를 써도 base를 직접 조회하는 것과 같은 속도가 나옵니다. - 막히는 경우 — 옵티마이저 울타리(fence): 그런데 View 안에 윈도우 함수(OVER), DISTINCT, 일부 집계처럼 '어떤 행이 포함되는지가 결과를 바꾸는' 연산이 있으면 이야기가 달라집니다. 바깥 조건을 그 연산 아래로 내리면 순번·집계 값이 달라지므로, 옵티마이저는 의미 보존을 위해 밀어넣기를 포기합니다. 결국 base 전체를 계산한 뒤 마지막에 조건을 적용해, 인덱스가 있어도 전체 스캔이 납니다.
- View는 파라미터를 못 받는다: View는 함수가 아니라 '이름 붙은 쿼리'라 인자를 받지 못합니다. 바깥에서 WHERE를 아무리 걸어도, 그게 안으로 안 내려가면 필터를 '연산 다음'에서만 할 수 있습니다. 이 한계가 무거운 집계·윈도우 View에서 성능 함정으로 나타납니다.
- 진단은 EXPLAIN으로:
EXPLAIN (ANALYZE, BUFFERS)에서 WindowAgg·Unique·Aggregate 노드가 Filter보다 아래에 있고, 그 밑 Seq Scan이 수백만 행을 훑는데 상위 Filter의 Rows Removed by Filter가 크면 '조건이 안 밀린' 것입니다.
그래서 필터가 성능을 좌우하는 조회는 파라미터를 받는 함수(set-returning function)로 만들어 필터를 base 쿼리 안으로 밀어 넣거나, 무거운 연산을 이미 좁혀진 집합 위에서만 수행하도록 재구성합니다. View의 편리함 뒤에는 '옵티마이저가 그 안을 들여다볼 수 있느냐'라는 조건이 숨어 있습니다.
상황: 사용자별로 최근 주문에 순번을 매기는 뷰 v_user_order_rank(정의에 ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at DESC) 포함)를 만들고, SELECT * FROM v_user_order_rank WHERE user_id = 42 AND rn <= 5로 조회합니다. base orders 테이블엔 user_id 인덱스가 분명히 있는데도, 이 조회가 수백만 건 전체를 훑어 수 초씩 걸립니다.
원인: 뷰에 윈도우 함수가 들어 있습니다. 옵티마이저가 바깥의 user_id = 42 조건을 윈도우 계산 아래로 밀어넣으면, 파티션 구성과 ROW_NUMBER 값이 달라져 결과가 바뀝니다. 그래서 밀어넣기를 포기하고, 먼저 orders 전체에 대해 윈도우(사용자별 순번)를 계산한 다음 마지막에 user_id = 42로 거릅니다. 결과적으로 user_id 인덱스는 쓰이지 못하고 전체 스캔이 발생합니다.
진단: EXPLAIN (ANALYZE, BUFFERS)로 실행 계획을 봅니다. WindowAgg 노드가 Filter보다 아래에 있고, 그 밑에 Seq Scan on orders가 수백만 행을 처리하며, 상위 Filter의 Rows Removed by Filter가 대부분을 차지하면 확정입니다 — 조건이 윈도우 아래로 내려가지 못한 것입니다.
해결: 파라미터를 못 받는 View 대신, user_id를 인자로 받는 함수(set-returning function)로 바꿉니다. 함수 안에서 먼저 user_id 인덱스로 해당 사용자의 주문만 좁힌 뒤, 그 좁혀진 집합 위에서만 ROW_NUMBER를 계산하면 스캔량이 몇 건으로 줄어듭니다. 즉 필터를 '윈도우 다음'이 아니라 '윈도우 이전(base)'으로 옮기는 것이 핵심입니다. 윈도우·DISTINCT·중첩 뷰는 옵티마이저 울타리가 될 수 있음을 기억하고, 필터가 중요한 경로에는 이런 뷰를 그대로 두지 않습니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 뷰·프로시저·함수 DDL을 실전 조합과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
CREATE VIEW | 복잡한 쿼리에 이름 붙이기 | CREATE VIEW v_order_summary AS SELECT ...; (컬럼 명시, SELECT * 지양) |
CREATE OR REPLACE VIEW | 기존 뷰 정의 교체 | CREATE OR REPLACE VIEW v_order_summary AS SELECT ...; |
DROP VIEW | 뷰 삭제 | DROP VIEW IF EXISTS v_order_summary; / 의존 객체까지 ... CASCADE; |
GRANT / REVOKE SELECT | 뷰로 권한 제어 | GRANT SELECT ON v_users_public TO analyst_role; + REVOKE SELECT ON users FROM analyst_role; |
CREATE MATERIALIZED VIEW | 결과를 디스크에 캐싱 | CREATE MATERIALIZED VIEW mv_monthly_revenue AS SELECT ... WITH DATA; |
CREATE UNIQUE INDEX (MV) | CONCURRENTLY 갱신의 전제 조건 | CREATE UNIQUE INDEX ON mv_monthly_revenue (month, category); |
REFRESH MATERIALIZED VIEW | MV 최신화(stale 해소) | 무중단: REFRESH MATERIALIZED VIEW CONCURRENTLY mv_monthly_revenue; |
pg_matviews | MV 마지막 갱신 시각 확인 | SELECT matviewname, last_refresh FROM pg_matviews; |
CREATE PROCEDURE | 여러 SQL을 트랜잭션 단위로 | CREATE OR REPLACE PROCEDURE proc_cancel_order(...) LANGUAGE plpgsql AS $$ ... $$; |
CALL | 프로시저 실행 | CALL proc_cancel_order(12345, '고객 요청으로 취소'); |
CREATE FUNCTION | 값 반환·SELECT 내 사용 | CREATE OR REPLACE FUNCTION fn_calculate_discount(...) RETURNS NUMERIC ...; → SELECT fn_calculate_discount(price,'gold') |
RAISE EXCEPTION | 프로시저 내 오류 처리 | RAISE EXCEPTION '완료된 주문은 취소할 수 없습니다'; |
CREATE TRIGGER | 이벤트 발생 시 자동 실행 | CREATE TRIGGER trg_users_audit AFTER INSERT OR UPDATE OR DELETE ON users FOR EACH ROW EXECUTE FUNCTION fn_audit_log(); |
관련 모듈로 더 깊이:
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — Materialized View로 무거운 집계를 미리 계산해 튜닝하는 법
- GROUP BY와 집계함수의 효율적인 인덱스 활용 — 뷰가 감싸는 복잡한 집계 쿼리의 기초
- 실시간 DB 모니터링 및 슬로우 쿼리 슬랙 알림 설정 — Materialized View 갱신 지연을 모니터링하는 운영 관점
다음 모듈에서는 EXPLAIN 명령어로 쿼리 실행 계획을 분석하고 데이터 검색 범위를 최소화하는 최적화 기법을 다룹니다.