Redis는 빠르다는 이유만으로 붙이면 금방 운영 문제가 됩니다. 캐시, 세션, 락, 카운터는 각각 만료 정책과 데이터 손실 허용 범위가 다릅니다. Key-Value 저장소의 특성을 이해해야 빠른 기능을 안전하게 운영할 수 있습니다.
Redis는 String, List, Hash, Set, ZSet 5가지 자료구조를 제공하며, 각각 다른 문제를 해결합니다. 실무에서 가장 많이 쓰는 패턴은 Cache-Aside(읽기 캐시)와 세션 저장입니다. 캐시 설계의 핵심은 TTL 전략과 캐시 무효화입니다. Cache Stampede 같은 분산 시스템 문제도 함께 이해해야 합니다.
- 1String, List, Hash, Set, ZSet 5가지 Redis 자료구조를 구분하고 설명할 수 있다
- 2각 자료구조의 실무 사용 사례에 맞는 명령어를 선택해 사용할 수 있다
- 3EXPIRE, TTL, PERSIST 명령으로 데이터 생명주기를 관리할 수 있다
- 4Cache-Aside 패턴으로 읽기/쓰기 순서와 캐시 무효화를 설계할 수 있다
- 5세션을 Redis에 저장하는 이유를 이해하고 직접 구현할 수 있다
- 6Cache Stampede 문제를 이해하고 대응 전략을 적용할 수 있다
Redis 실무 — 캐싱, 세션 관리, Pub/Sub 패턴
로그인 세션을 PostgreSQL에 저장했다. 사용자가 늘면서 매 요청마다 세션 테이블을 SELECT하는 게 DB 부하의 주범이 됐다. 배포할 때마다 세션이 초기화돼서 사용자들이 로그아웃됐다는 문의가 들어왔고, 새벽에 온 슬랙 알람에 서버 앞에 앉은 적이 있었다. 그때 팀장이 "Redis로 옮기면 된다"고 했다. TTL 설정 한 줄, 메모리에서 마이크로초 안에 읽고 — 세션 문제가 사라졌다. 처음엔 Redis가 그냥 "빠른 캐시 서버"인 줄 알았는데, 자료구조별로 완전히 다른 문제를 해결한다는 걸 나중에야 알았다. String으로 캐싱하고, ZSet으로 실시간 랭킹을 만들고, Pub/Sub으로 서비스 간 이벤트를 흘리는 — 이 패턴을 알면 DB 하나에 모든 걸 때려박던 설계에서 벗어날 수 있다.
실행 결과를 확인할 수 있는 DB 콘솔 출력이 표시됩니다.
- 읽기 순서—redis-cli INFO all 출력은 used_memory → 캐시 히트율(keyspace_hits/misses) → connected_clients → keyspace 섹션 순으로 확인합니다.
- used_memory 판단 기준—used_memory가 maxmemory의 80% 이상이면 eviction 시작 가능. 90% 이상이면 즉시 maxmemory 증설 또는 불필요한 키 TTL 점검 필요. used_memory_rss가 used_memory의 2배 이상이면 메모리 단편화 발생.
- 캐시 히트율 판단 기준—keyspace_hits ÷ (keyspace_hits + keyspace_misses) = 히트율. 90% 이상: 목표 / 70%~90%: 점검 필요(TTL이 너무 짧거나 캐시 대상 재검토) / 70% 미만: 캐시 전략 전면 재검토.
- connected_clients 판단 기준—평소 대비 갑작스러운 10배 이상 증가 → 커넥션 폭발. 애플리케이션 커넥션 풀 설정(maxmemory-clients 또는 maxclients) 확인. 기본 maxclients=10000.
- rdb_last_bgsave_status—ok가 아니면 RDB 스냅샷 실패. AOF 사용 중이라면 aof_last_write_status도 함께 확인. 백업 실패 상태에서 재시작 시 데이터 유실 가능.
- 조합 해석 — 키 낭비—used_memory 높음 + 히트율 낮음 → 키는 많은데 자주 쓰이지 않음. TTL 미설정 키 또는 너무 긴 TTL 키 정리 필요. redis-cli --scan --pattern '*' | xargs redis-cli OBJECT IDLETIME으로 유휴 키 확인.
- 조합 해석 — 커넥션 병목—latency 높음 + connected_clients 많음 → 커넥션 수가 성능 병목. 커넥션 풀링(redis-py의 ConnectionPool, ioredis의 maxRetriesPerRequest) 설정 검토.
- 조합 해석 — eviction 연쇄—evicted_keys 증가 + 히트율 하락 → maxmemory에 의한 강제 삭제로 히트율 저하. maxmemory 증설 또는 eviction policy를 allkeys-lru에서 volatile-lru(TTL 있는 키만 삭제)로 변경 검토.
- TTL 설정—캐시나 세션 키에 만료 시간이 의도대로 걸렸는지 확인합니다.
- 영속성 요구—사라져도 되는 데이터인지 RDB/AOF가 필요한 데이터인지 구분합니다.
Redis 역할 분류 — 캐시·세션·큐·Pub-Sub
Redis를 "빠른 DB"라고 생각해서 중요한 비즈니스 데이터를 넣었는데, 서버 재시작 후 데이터가 사라집니다. Redis는 기본적으로 인메모리 저장소이고, 어떻게 설정하느냐에 따라 영속성이 달라집니다. 그리고 Redis는 캐시만 하는 도구가 아닙니다. 세션, 큐, Pub-Sub 등 역할마다 운용 방식이 완전히 다릅니다. 역할을 이해하고 써야 Redis를 올바르게 활용할 수 있습니다.
 확대
확대
Redis를 역할별로 이해하기
Redis를 "빠른 데이터베이스"로 생각하면 잘못 사용하게 됩니다. Redis는 역할에 따라 전혀 다른 방식으로 운용됩니다.
| 역할 | 사용 자료구조 | 핵심 특성 | 주의사항 |
|---|---|---|---|
| 캐시 | String, Hash | TTL 필수, 언제든 삭제 가능 | TTL 없으면 메모리 고갈 |
| 세션 저장소 | Hash, String | TTL로 자동 만료, 서버 무상태화 | 민감 데이터 암호화 |
| 분산 큐 | List | LPUSH/BRPOP으로 작업 처리 | 메시지 내구성 없음 |
| Pub/Sub | 채널 | 실시간 알림, Fire-and-Forget | 구독자 없으면 메시지 유실 |
| 랭킹/카운터 | ZSet, String | 원자적 증감 | 영구 저장 필요 시 DB와 병행 |
| Rate Limiting | String + INCR | 원자적 카운터로 요청 수 제한 | Lua 스크립트로 원자성 보장 |
Redis 5가지 자료구조 — String
String은 Redis의 가장 기본 자료구조입니다. 문자열, 숫자, 직렬화된 JSON 모두 저장 가능합니다. EX 옵션으로 TTL을 설정하면 자동 만료됩니다. INCR과 INCRBY는 원자적으로 동작하므로 여러 서버에서 동시에 호출해도 카운터 정확성이 보장됩니다.
SET product:123 '{"name":"노트북","price":1200000}' EX 300
GET product:123
TTL product:123
INCR page_view:article:42
INCRBY daily_login:2024-03-15 1
DECR stock:product:123
List — 큐와 최근 목록
List는 순서가 있는 문자열 목록으로, 양쪽 끝에서 O(1)으로 삽입/삭제가 가능합니다. LPUSH와 RPOP을 조합하면 FIFO 큐가 됩니다. LTRIM으로 목록 크기를 제한하면 최근 N개만 유지하는 슬라이딩 윈도우 패턴을 구현할 수 있습니다.
LPUSH job_queue '{"type":"email","to":"user@example.com"}'
RPOP job_queue
LPUSH recent:user:42 "product:100"
LTRIM recent:user:42 0 9
LRANGE recent:user:42 0 -1
LRANGE recent:user:42 0 4
BRPOP job_queue 0
Hash — 객체 필드별 저장
Hash는 필드-값 쌍의 맵입니다. 사용자 세션이나 객체를 String(JSON 직렬화)으로 저장하면 특정 필드 하나를 변경할 때도 전체를 역직렬화해야 합니다. Hash는 HSET으로 특정 필드만 직접 업데이트할 수 있어 불필요한 직렬화 비용이 없습니다.
HSET session:abc123 user_id 42
HSET session:abc123 username "kimdev"
HSET session:abc123 role "admin"
HSET session:abc123 last_active "2024-03-15T10:30:00"
HMSET user:42 name "김개발" email "kim@example.com" level 5
HGET session:abc123 user_id
HMGET user:42 name email
HGETALL session:abc123
HINCRBY user:42 login_count 1
HEXISTS session:abc123 role
EXPIRE session:abc123 1800
Set — 중복 없는 집합
Set은 중복을 허용하지 않는 집합으로, 교집합·합집합·차집합 연산을 지원합니다. 좋아요 기능에서 중복 클릭 방지, 온라인 사용자 추적, 공통 팔로워 찾기에 활용됩니다.
SADD likes:post:42 "user:7"
SADD likes:post:42 "user:15"
SADD likes:post:42 "user:7"
SCARD likes:post:42
SISMEMBER likes:post:42 "user:7"
SREM likes:post:42 "user:15"
SINTERSTORE common_followers followers:alice followers:bob
SADD online_users "user:42"
SCARD online_users
SMEMBERS online_users
ZSet (Sorted Set) — 순위와 점수
ZSet은 각 멤버에 score를 부여해 자동 정렬합니다. ZINCRBY는 원자적으로 점수를 변경합니다. ZREVRANGE는 점수 내림차순으로 상위 N명을 조회합니다.
ZADD leaderboard 15000 "user:alice"
ZADD leaderboard 23000 "user:bob"
ZADD leaderboard 8500 "user:carol"
ZADD leaderboard 23000 "user:dave"
ZREVRANGE leaderboard 0 2 WITHSCORES
ZREVRANK leaderboard "user:bob"
ZSCORE leaderboard "user:alice"
ZRANGEBYSCORE leaderboard 10000 30000 WITHSCORES
ZINCRBY leaderboard 5000 "user:alice"
게임 랭킹·실시간 순위표는 ZSet의 대표 용례입니다. 점수를 넣고 상위권을 조회한 뒤, ZINCRBY로 점수를 올렸을 때 순위가 자동으로 재정렬되는지 redis-cli에서 확인합니다.
ZADD leaderboard 15000 user:alice 23000 user:bob 8500 user:carol
ZREVRANGE leaderboard 0 2 WITHSCORES # 상위 3명 + 점수
ZREVRANK leaderboard user:alice # alice의 0-based 순위
ZINCRBY leaderboard 10000 user:alice # alice +10000
ZREVRANGE leaderboard 0 2 WITHSCORES # 순위가 바뀌었는지 재확인
127.0.0.1:6379> ZREVRANGE leaderboard 0 2 WITHSCORES
1) "user:bob" 2) "23000"
3) "user:alice" 4) "15000"
5) "user:carol" 6) "8500"
127.0.0.1:6379> ZINCRBY leaderboard 10000 user:alice
"25000"
127.0.0.1:6379> ZREVRANGE leaderboard 0 2 WITHSCORES
1) "user:alice" 2) "25000" ← 1위로 상승
3) "user:bob" 4) "23000"
ZADD leaderboard 15000 user:alice 23000 user:bob 8500 user:carol- ZREVRANGE 결과가 점수 내림차순(높은 점수가 위)인지 먼저 본다 — 오름차순이면 ZRANGE를 쓴 것(REV가 빠짐)
- ZINCRBY 후 반환값이 '누적된 새 점수'인지 확인 — 증가분만 돌아오면 ZADD/ZINCRBY를 혼동한 것. ZINCRBY는 원자적으로 더하고 최종 점수를 준다
- ZINCRBY 직후 ZREVRANGE에서 해당 멤버의 순위가 실제로 올라갔는지 본다 — 안 바뀌면 같은 score 동점이거나 멤버 이름이 다른 것
- ZREVRANK는 0부터 시작한다 — 1위가 0으로 나오는지 확인(사람이 보는 '1위'로 쓰려면 +1)
TTL 관리 명령어
TTL은 Redis를 캐시로 사용할 때 가장 중요한 개념입니다. 모든 캐시 데이터에는 반드시 TTL을 설정하세요. PERSIST는 TTL을 제거해 영구 저장으로 전환합니다.
EXPIRE key 3600
EXPIREAT key 1711234567
PEXPIRE key 5000
TTL key
PTTL key
PERSIST key
SET product:123 '...' 처럼 EX 옵션 없이 저장하면 해당 키는 영구 저장됩니다. 상품, 사용자 프로필, API 응답 같은 캐시 데이터를 TTL 없이 저장하면 시간이 지나면서 Redis 메모리가 계속 증가합니다. maxmemory 제한에 도달하면 Redis는 maxmemory-policy 설정에 따라 기존 키를 삭제하거나(allkeys-lru) 새 쓰기를 거부합니다(noeviction).
모든 캐시 데이터에는 SET key value EX 300 처럼 TTL을 필수로 설정하세요. 세션 데이터는 EXPIRE session:abc 1800으로 마지막 접근 시 TTL을 갱신해 활성 세션이 만료되지 않도록 합니다. 영구 저장이 필요한 데이터는 Redis가 아닌 데이터베이스에 저장하세요.
SET/GET 한 줄이 Redis 안에서 처리되는 법 — 수신부터 만료·영속화까지 5단계
Redis가 왜 마이크로초 만에 응답하는지, 그런데 왜 가끔 CPU도 메모리도 멀쩡한데 전체가 순간 멈추는지 — 둘 다 Redis가 명령 하나를 처리하는 방식에서 나옵니다. Redis는 메모리 위 자료구조를 단일 스레드로 순차 처리하고, 만료·영속화를 뒤에서 챙깁니다. 이 5단계를 알면 빠른 이유와 느려지는 이유를 같은 그림으로 설명할 수 있습니다.
[클라이언트] SET session:abc "..." EX 1800 또는 GET session:abc
│
① 명령 수신·파싱 (소켓으로 도착 → RESP 프로토콜 파싱 후 실행 큐에 적재)
│
② 단일 스레드 이벤트 루프 (명령을 '한 번에 하나씩' 순차 실행 → 그래서 원자적, 락 불필요)
│
③ 인메모리 자료구조 접근 (전역 해시테이블에서 키 조회 → String/Hash/ZSet 값 읽기·쓰기, 대개 O(1))
│
④ TTL 관리 (EX/EXPIRE로 만료시각 기록 → lazy(접근 시 검사)+active(주기 샘플링) 삭제)
│
⑤ 필요 시 영속화 (쓰기를 AOF 버퍼에 기록 / 주기적 RDB 스냅샷 — 재시작 복구용)
▼
[응답] OK 또는 값 반환 (② 이벤트 루프가 다음 명령으로 넘어감)
각 단계에서 무슨 일이 일어나고, 어디서 문제가 되나:
| 단계 | 하는 일 | 여기서 문제가 되면(증상) |
|---|---|---|
| ① 명령 수신 | 소켓으로 온 명령을 RESP로 파싱해 실행 큐에 넣음 | connected_clients 폭증·커넥션 누수면 이 앞단이 병목 → 커넥션 풀로 재사용 |
| ② 단일 스레드 실행 | 모든 명령을 한 스레드에서 순차 처리 → 명령 하나하나가 원자적(INCR 등 락 불필요) | O(N) 명령(KEYS·큰 키 HGETALL·동기 DEL) 하나가 루프를 오래 점유 → 뒤의 모든 요청이 대기(순간 멈춤) |
| ③ 자료구조 접근 | 전역 해시테이블에서 키를 찾고 값 자료구조를 읽고 씀 — 대부분 O(1) | 큰 키(원소 수백만)의 한 방 조회가 O(N)이 되어 ②를 막음 → 키 분할·HSCAN으로 나눠 읽기 |
| ④ TTL 만료 | 만료시각을 저장하고 lazy(접근 시)+active(백그라운드 샘플링)로 삭제 | TTL 없이 저장하면 안 지워져 메모리 증가 · 대량 동시 만료는 순간 삭제 부하 → TTL에 지터 |
| ⑤ 영속화·축출 | AOF/RDB로 디스크 보존, maxmemory 초과 시 maxmemory-policy로 키 축출 | 한도 도달 시 allkeys-lru면 캐시 삭제·noeviction이면 쓰기 거부 → 캐시와 영속 데이터를 한 인스턴스에 섞지 말 것 |
즉 Redis가 마이크로초로 응답하는 것은 ③이 디스크가 아니라 메모리 해시테이블을 O(1)로 건드리기 때문이고, 반대로 "CPU도 메모리도 멀쩡한데 전체가 순간 멈추는" 장애는 거의 항상 ②의 단일 스레드를 오래 잡는 O(N) 명령입니다. SLOWLOG GET·redis-cli --bigkeys로 그 명령과 큰 키를 찾고, KEYS는 SCAN으로 DEL은 UNLINK로 바꾸면 됩니다.
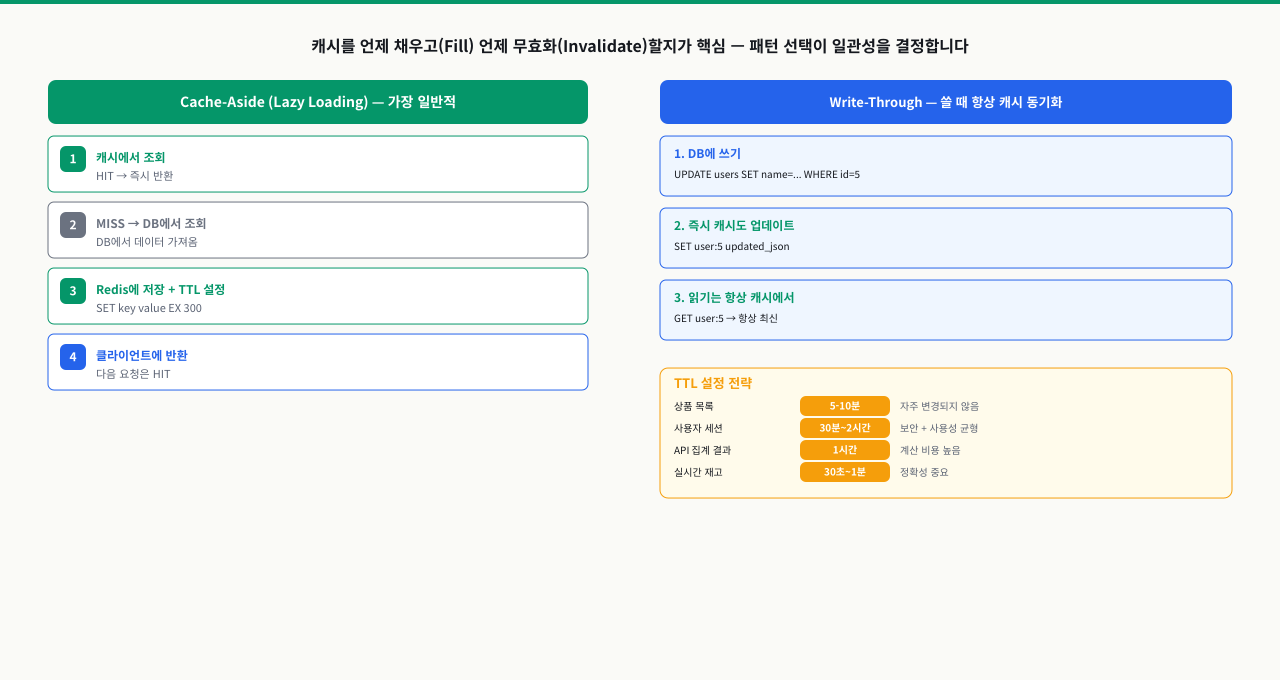
캐싱 패턴과 세션 관리 — Cache-Aside와 TTL 전략
DB 캐싱을 Redis로 구현했는데, DB를 업데이트한 직후에도 캐시에서 이전 데이터를 돌려줍니다. 캐시 무효화를 빠뜨린 겁니다. TTL을 길게 잡으면 오래된 데이터가 노출되고, 너무 짧게 잡으면 캐시 히트율이 떨어져 DB 부하가 줄지 않습니다. 세션을 Redis에 넣었는데 TTL이 지나도 로그인이 유지되는 경우도 있습니다. 캐싱은 패턴 없이 구현하면 일관성 문제와 메모리 낭비가 동시에 발생합니다.
 확대
확대
Cache-Aside 패턴 (Lazy Loading)
Cache-Aside는 읽기 시에만 캐시를 채우는 가장 일반적인 캐싱 패턴입니다. 쓰기 시에는 캐시를 업데이트하지 않고 삭제합니다. 캐시를 업데이트하면 DB 쓰기와 캐시 쓰기를 원자적으로 처리할 수 없어 불일치가 발생할 수 있기 때문입니다.
import redis
import json
r = redis.Redis(host='localhost', port=6379, db=0)
def get_product(product_id: int):
cache_key = f"product:{product_id}"
cached = r.get(cache_key)
if cached:
return json.loads(cached)
product = db.query("SELECT * FROM products WHERE id = %s", product_id)
if not product:
return None
r.setex(cache_key, 300, json.dumps(product))
return product
def update_product(product_id: int, data: dict):
db.execute("UPDATE products SET price=%s WHERE id=%s",
data['price'], product_id)
r.delete(f"product:{product_id}")
Write-Through vs Cache-Aside 비교
쓰기 패턴에 따라 캐시 전략을 선택합니다. 읽기가 훨씬 많은 서비스에는 Cache-Aside가, 읽기와 쓰기가 균형 잡힌 서비스에는 Write-Through가 적합합니다.
| 항목 | Cache-Aside | Write-Through |
|---|---|---|
| 쓰기 방식 | DB 쓰기 → 캐시 삭제 | DB 쓰기 + 캐시 쓰기 동시 |
| 캐시 일관성 | 잠깐의 stale 가능 | 항상 최신 |
| 쓰기 지연 | 낮음 | 높음 (캐시+DB 모두 대기) |
| 사용 패턴 | 읽기 위주 | 읽기/쓰기 균형 |
| 복잡성 | 낮음 | 높음 |
세션을 Redis에 저장하는 이유
서버 메모리에 세션을 저장하면 특정 서버에서만 세션이 유효하므로 수평 확장이 불가합니다. Redis에 세션을 저장하면 어느 서버에서도 같은 세션을 읽을 수 있고, TTL로 자동 만료되며, 인메모리라 조회가 빠릅니다.
import session from 'express-session';
import RedisStore from 'connect-redis';
import { createClient } from 'redis';
const redisClient = createClient({ url: 'redis://localhost:6379' });
await redisClient.connect();
app.use(session({
store: new RedisStore({ client: redisClient }),
secret: process.env.SESSION_SECRET,
resave: false,
saveUninitialized: false,
cookie: {
secure: process.env.NODE_ENV === 'production',
httpOnly: true,
maxAge: 30 * 60 * 1000
}
}));
Redis에 저장된 세션을 직접 확인하는 명령어입니다.
KEYS sess:*
TTL sess:abc123
HGETALL sess:abc123
Redis는 각 역할마다 선택 기준이 다릅니다.
세션 토큰 저장은 Redis의 핵심 용도입니다. JWT를 사용하면 Redis가 불필요하지만, 강제 로그아웃이나 세션 무효화가 필요한 서비스(금융, 관리자 대시보드)라면 세션을 Redis에 저장하고 로그아웃 시 삭제하는 방식이 필요합니다.
API 응답 캐싱은 DB 쿼리가 느리거나 외부 API 호출이 빈번한 경우 효과적입니다. TTL은 데이터 신선도 요구사항에 따라 설정하세요. 실시간성이 중요한 재고 수량은 TTL을 10초, 변경이 드문 상품 설명은 1시간으로 설정할 수 있습니다.
Rate Limiting은 INCR과 EXPIRE를 조합해 구현합니다. SET ratelimit:user:42:2024-03-15T10 0 EX 60으로 1분 단위 카운터를 만들고 INCR로 증가시켜 임계값을 초과하면 요청을 거부합니다. 원자성이 중요한 경우 Lua 스크립트나 Redis 모듈인 RedisBloom을 활용하세요.
Cache Stampede 문제와 대응
인기 있는 캐시 항목의 TTL이 만료되는 순간, 동시에 수천 개 요청이 캐시 미스를 경험하고 모두 DB로 몰립니다. DB가 과부하되어 응답이 느려지고 연쇄 장애로 이어질 수 있습니다.
인기 상품 페이지의 캐시 TTL이 오전 9시 정각에 만료될 때, 수천 명의 사용자 요청이 동시에 캐시 미스를 경험합니다. 모든 요청이 DB 조회를 시작하고 DB는 순간적인 과부하로 응답 시간이 급증합니다. 캐시가 채워지기 전에 타임아웃이 발생하면 더 많은 재시도가 몰려 상황이 악화됩니다.
두 가지 대응 전략이 있습니다. Mutex Lock은 첫 번째 요청만 DB에 접근해 캐시를 채우고, 나머지는 락이 해제될 때까지 대기했다가 캐시에서 읽도록 합니다. Probabilistic Early Expiration은 TTL 만료 전에 확률적으로 일부 요청이 미리 캐시를 갱신해 만료 순간의 폭발적 동시 접근을 방지합니다. 트래픽이 매우 높은 서비스라면 두 전략을 함께 사용하세요.
Mutex Lock 구현입니다. NX=없을 때만 옵션으로 첫 번째 요청만 락을 획득하고 DB를 조회해 캐시를 채웁니다. 락 획득에 실패한 요청은 잠시 대기 후 캐시에서 읽습니다.
import redis
import time
def get_product_with_lock(product_id: int):
cache_key = f"product:{product_id}"
lock_key = f"lock:product:{product_id}"
cached = r.get(cache_key)
if cached:
return json.loads(cached)
acquired = r.set(lock_key, "1", nx=True, ex=5)
if acquired:
try:
product = db.get_product(product_id)
r.setex(cache_key, 300, json.dumps(product))
return product
finally:
r.delete(lock_key)
else:
time.sleep(0.1)
cached = r.get(cache_key)
return json.loads(cached) if cached else None
Probabilistic Early Expiration 구현입니다. 남은 TTL이 적을수록 갱신 확률이 높아져 만료 직전에 일부 요청이 미리 캐시를 갱신합니다.
import math
import random
def get_with_early_refresh(key: str, ttl: int, fetch_fn):
result = r.get(key)
remaining_ttl = r.ttl(key)
if result is None or should_refresh(remaining_ttl, ttl):
fresh_data = fetch_fn()
r.setex(key, ttl, json.dumps(fresh_data))
return fresh_data
return json.loads(result)
def should_refresh(remaining: int, total: int) -> bool:
if remaining <= 0:
return True
probability = math.exp(-remaining / (total * 0.1))
return random.random() < probability
Redis Pub/Sub — 실시간 알림
Pub/Sub은 발행자가 채널에 메시지를 보내면 구독자가 실시간으로 수신하는 패턴입니다. 구독자가 연결되어 있지 않으면 메시지가 유실됩니다(Fire-and-Forget). 메시지 내구성이 필요하면 Redis Streams 또는 Kafka 사용을 검토하세요.
SUBSCRIBE notifications:user:42
PUBLISH notifications:user:42 '{"type":"comment","message":"새 댓글이 달렸습니다"}'
def subscribe_notifications(user_id: int):
pubsub = r.pubsub()
pubsub.subscribe(f"notifications:user:{user_id}")
for message in pubsub.listen():
if message['type'] == 'message':
data = json.loads(message['data'])
send_websocket(user_id, data)
def publish_notification(user_id: int, notification: dict):
r.publish(f"notifications:user:{user_id}", json.dumps(notification))
심화 — 단일 스레드가 만드는 지연의 진짜 원인
심화: 단일 스레드 Redis — 느린 명령 하나가 전체를 멈춘다
캐시 히트율도 좋고 메모리도 여유로운데, 몇 초에 한 번씩 모든 요청이 순간적으로 멈추는 일이 있습니다. TTL이나 eviction으로는 설명이 안 됩니다. 원인은 대개 Redis의 가장 근본적인 특성 — 명령을 단일 스레드에서 순차 처리한다는 점에 있습니다.
Redis는 한 번에 하나의 명령만 실행합니다. 그래서 O(1) 명령(SET/GET/INCR)은 마이크로초 단위로 끝나 문제가 없지만, O(N) 명령은 N이 커질수록 그 명령이 끝날 때까지 이벤트 루프를 붙잡고, 뒤에 도착한 모든 클라이언트의 명령이 줄을 서서 기다립니다.
KEYS */KEYS prefix:*— 전체 키스페이스를 훑습니다. 키가 수백만 개면 수백 밀리초씩 전체를 멈춥니다. 운영에서는 커서 기반SCAN으로 대체합니다(조금씩 나눠 훑어 블로킹을 피함).- 큰 키(big key)의
HGETALL·SMEMBERS·LRANGE 0 -1·ZRANGE— 원소가 수백만 개인 컬렉션을 한 번에 직렬화해 반환하면 그동안 다른 요청이 멈춥니다.HSCAN·SSCAN·페이지네이션으로 나눠 읽습니다. - 큰 키의
DEL— 동기 삭제는 메모리 해제까지 스레드를 붙잡습니다.UNLINK는 삭제를 백그라운드 스레드로 넘겨 이벤트 루프를 막지 않습니다. 대량 만료(TTL 동시 만료)도 같은 방식으로 순간 부하를 만듭니다.
핵심은 느린 명령을 쓰는 한 클라이언트가 모두를 느리게 만든다는 점입니다. 그래서 컬렉션이 무한정 커지지 않도록 설계하고(파티셔닝·상한), 진단 도구로 느린 명령을 상시 감시합니다.
상황: Redis 지표상 used_memory도 maxmemory에 여유가 있고 CPU도 낮은데, 주기적으로 애플리케이션 전체에서 Redis 응답이 순간 멈추고 타임아웃이 발생합니다. 특정 API가 아니라 그 시점의 모든 요청이 함께 느려집니다.
원인: 단일 스레드를 오래 점유하는 O(N) 명령이 주기적으로 실행되고 있었습니다. 흔한 범인은 (1) 모니터링·정리 스크립트가 도는 KEYS *, (2) 세션·목록을 통째로 읽는 큰 키의 HGETALL/SMEMBERS, (3) 커진 키를 지우는 동기 DEL입니다. 이 명령이 도는 수백 밀리초 동안 다른 모든 명령이 대기하다 한꺼번에 처리되며 지연이 튑니다.
진단: SLOWLOG GET 20으로 최근 느린 명령을 확인하고, LATENCY LATEST·LATENCY DOCTOR로 지연 원인을 봅니다. redis-cli --bigkeys로 비정상적으로 큰 키가 있는지 찾습니다. 느린 명령의 실행 주기와 지연 스파이크 시각이 맞으면 확정입니다.
해결: KEYS를 SCAN으로, 대량 컬렉션 조회를 HSCAN·SSCAN 등 커서 방식으로, DEL을 비동기 UNLINK로 바꿉니다. 근본적으로는 하나의 키에 원소를 무한정 쌓지 않도록 키를 분할하고 상한을 둡니다. TTL 동시 만료가 원인이면 만료 시각에 지터(랜덤 오프셋)를 줍니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 Redis 자료구조별 명령을 실전 용례와 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
SET key val EX 초 / GET | 문자열 저장(TTL 포함)·조회 | SET product:123 '{...}' EX 300 |
INCR / INCRBY / DECR | 원자적 카운터(조회수·레이트리밋) | INCR page_view:article:42 |
EXPIRE / TTL / PERSIST | 만료 설정·확인·해제 | EXPIRE session:abc 1800, TTL key |
LPUSH / RPOP / BRPOP | List 큐(FIFO·블로킹 소비) | LPUSH job_queue '{...}' 후 BRPOP job_queue 0 |
LTRIM / LRANGE | 최근 N개 유지·범위 조회 | LTRIM recent:user:42 0 9 |
HSET / HGET / HGETALL | Hash 필드 단위 저장·조회 | HSET session:abc user_id 42, HGETALL session:abc |
HINCRBY | Hash 필드 원자적 증감 | HINCRBY user:42 login_count 1 |
SADD / SISMEMBER / SCARD | Set 중복 없는 집합·존재·개수 | SADD likes:post:42 user:7 |
SINTERSTORE | 집합 교집합(공통 팔로워 등) | SINTERSTORE common_followers followers:alice followers:bob |
ZADD / ZREVRANGE / ZINCRBY | Sorted Set 랭킹·상위 N·점수 증감 | ZREVRANGE leaderboard 0 2 WITHSCORES |
SET key val NX EX 초 | 분산 락(첫 요청만 획득) | r.set(lock, "1", nx=True, ex=5) (Cache Stampede 방지) |
SUBSCRIBE / PUBLISH | Pub/Sub 실시간 메시지 전파 | PUBLISH notifications:user:42 '{...}' |
SCAN / HSCAN (KEYS 대신) | 커서 방식 비블로킹 순회 | 운영에선 KEYS * 금지 → SCAN 0 MATCH prefix:* |
UNLINK (DEL 대신) | 큰 키 비동기 삭제 | 동기 DEL의 이벤트 루프 블로킹 회피 |
SLOWLOG GET / --bigkeys | 느린 명령·큰 키 진단 | SLOWLOG GET 20, redis-cli --bigkeys |
관련 모듈로 더 깊이:
- Document DB (MongoDB) 임베딩 vs 참조 설계 기준 — 같은 NoSQL 계열인 문서 DB와의 데이터 모델 차이
- RDBMS, NoSQL, 그리고 분산 확장 가능한 NewSQL 전격 비교 — Key-Value 스토어가 전체 DB 지형에서 차지하는 위치
- 우리 서비스에 맞는 최적의 RDBMS vs NoSQL 고르기 — 캐시·세션 용도에 Redis가 적합한지 판단하는 기준
다음 모듈에서는 서비스 요구사항에 맞는 RDBMS vs NoSQL 선택 기준과 판단 프레임워크를 다룹니다.