도메인 요구사항은 비슷해 보여도 데이터 변경 방식은 크게 다릅니다. 소프트 삭제, 이력 테이블, 상태 전이 같은 패턴을 모르면 매번 임시 컬럼이 늘어납니다. 검증된 스키마 패턴을 알면 변경에 강한 테이블 구조를 만들 수 있습니다.
계층 구조는 parent_id 인접 목록으로 시작하되, 깊은 트리나 잦은 전체 조회가 있으면 경로 열거나 중첩 집합을 고려하세요. 태그는 중간 테이블로 다대다를 구현하고, 소프트 삭제는 deleted_at에 Partial Index를 추가합니다. Polymorphic Association은 유연하지만 무결성 관리를 코드에 위임한다는 트레이드오프가 있습니다.
- 1인접 목록, 경로 열거, 중첩 집합 3가지 계층 구조 모델을 구분해 설계할 수 있다
- 2각 계층 모델의 읽기/쓰기/이동 복잡도를 비교해 선택할 수 있다
- 33테이블 구조와 카운트 캐싱으로 태그 시스템 다대다 설계를 구현할 수 있다
- 4deleted_at와 Partial Index로 소프트 삭제를 구현할 수 있다
- 5Polymorphic Association으로 여러 엔티티를 하나의 댓글 테이블로 다룰 수 있다
- 6각 패턴의 장단점을 이해하고 상황별로 올바른 패턴을 선택할 수 있다
실전 스키마 패턴 — 계층구조, 태그 시스템, 소프트 삭제
"댓글에 대댓글을 달 수 있게 해주세요", "상품에 태그를 붙여주세요", "삭제해도 나중에 복구할 수 있게 해주세요" — 이런 요구사항들은 테이블을 어떻게 설계하느냐에 따라 쿼리 성능과 유지보수성이 크게 달라집니다. 이 모듈에서는 실무에서 반복해서 등장하는 스키마 설계 패턴을 구체적인 SQL과 함께 익힙니다.
스키마 설계 결정이 내려지는 흐름 — 요구 분석부터 검증까지
계층·태그·소프트 삭제 같은 패턴을 하나씩 배워도 "내 도메인에 무엇을, 언제 적용하나"라는 결정 자체는 여전히 막막합니다. 설계는 패턴 암기가 아니라 순서 있는 판단의 연속입니다 — 요구와 접근 패턴을 먼저 읽고, 정규화 수준을 정하고, 관계와 인덱스를 설계한 뒤, 성능이 정말 아플 때만 비정규화를 저울질하고, 마지막에 검증합니다. 이 흐름을 손에 쥐면 과정규화(조인 폭증)와 과비정규화(갱신 이상) 사이에서 근거 있게 멈출 지점을 찾습니다.
① 요구·접근 패턴 분석
무엇을 저장하나 · 어떻게 읽나(단건/목록/집계) · 읽기:쓰기 비율은?
│
▼
② 정규화 수준 결정 (기본은 3NF)
각 사실을 한 곳에만 → 갱신 이상 차단이 출발점
│
▼
③ 관계·인덱스 설계
1:N·N:M을 FK/중간 테이블로 · N쪽 FK 컬럼 인덱스 · 조회 패턴에 맞는 인덱스
│
▼
④ 비정규화 트레이드오프 판단 ← 측정된 병목이 있을 때만
조인 폭증(과정규화) vs 갱신 이상·동기화 책임(과비정규화)
│
▼
⑤ 검증
EXPLAIN으로 실제 실행계획 확인 · 이상 현상 재현 테스트 · 무결성 제약 점검
각 단계의 핵심 판단과, 한쪽으로 치우치면 생기는 일:
| 단계 | 핵심 판단 | 치우치면 |
|---|---|---|
| ① 요구·접근 패턴 | 읽기:쓰기 비율·조회 형태(단건/목록/집계) 파악 | 접근 패턴 무시 설계 → 나중에 전면 재설계 |
| ② 정규화 수준 | 기본 3NF로 각 사실을 1곳에 | 성급한 비정규화 → 갱신 이상을 자초 |
| ③ 관계·인덱스 | FK 위치·중간 테이블·자식 FK 인덱스 결정 | 인덱스 누락 → 부모 삭제·조인 지연 |
| ④ 비정규화 판단 | 측정된 병목에만 선택 적용 | 과정규화 → 조인 폭증 / 과비정규화 → 동기화 책임 폭증 |
| ⑤ 검증 | EXPLAIN·이상 재현·제약 확인 | 검증 생략 → 운영에서 성능·정합성 사고 |
즉 좋은 스키마는 "정규화냐 비정규화냐"를 처음부터 고르는 게 아니라, 3NF에서 출발해 측정된 병목이 있을 때만 한 걸음씩 비정규화로 물러서는 과정입니다. ④에서 균형점은 도메인이 결정합니다 — OLTP(주문·결제)는 무결성 쪽으로, 분석·대시보드는 읽기 최적화 쪽으로 기웁니다. 이 흐름을 건너뛰고 패턴부터 붙이면 과정규화로 조인이 폭발하거나 과비정규화로 갱신 이상이 되살아납니다. 이 모듈에서 다루는 계층·태그·소프트 삭제 패턴은 모두 이 흐름의 ③~④ 단계에서 꺼내 쓰는 도구입니다.
계층 구조 모델링 — 카테고리와 댓글 트리
상품 카테고리가 3단계 이상 중첩됩니다. "전자제품 > 스마트폰 > 삼성"처럼 뎁스가 깊어질수록 쿼리도 복잡해집니다. parent_id 하나로 시작했는데 특정 카테고리 하위의 모든 상품을 조회하는 쿼리가 재귀 루프에서 타임아웃이 납니다. 계층 구조를 테이블에 저장하는 방법은 여러 가지이고, 각자 읽기와 쓰기 성능이 다릅니다. 어떤 패턴을 선택하느냐가 서비스 쿼리 복잡도를 결정합니다.
 확대
확대
1. 인접 목록 (Adjacency List)
가장 단순하고 직관적인 방법입니다. parent_id 컬럼으로 자기 참조(self-join)를 구현합니다. 구조 이해가 쉽고 노드 이동(parent_id만 변경)이 단순합니다. 단점은 특정 노드의 모든 자손을 한 번에 조회하려면 재귀 CTE가 필요하다는 것입니다.
CREATE TABLE categories (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
parent_id INT REFERENCES categories(id),
CONSTRAINT chk_not_self CHECK (id != parent_id)
);
INSERT INTO categories (id, name, parent_id) VALUES
(1, '전자기기', NULL),
(2, '컴퓨터', 1),
(3, '노트북', 2),
(4, '게이밍 노트북', 3),
(5, '스마트폰', 1);
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 WITH RECURSIVE 쿼리의 depth 값을 확인합니다. depth가 10 이상으로 커지면 재귀 횟수만큼 성능이 저하됩니다 — 트리 깊이가 5 이하면 인접 목록, 그 이상이면 경로 열거를 고려합니다.
- path 컬럼을 사용한 경우 EXPLAIN으로 인덱스 활용 여부를 확인합니다. LIKE '/1/2/%' 패턴에서 Seq Scan이 보이면 text_pattern_ops 인덱스가 없는 것입니다 — B-Tree 인덱스는 앞 와일드카드 LIKE를 타지 못합니다.
- 두 시그널을 조합합니다: 노드 이동(parent_id 변경)이 월 1회 이상이고 + 전체 트리 조회 빈도가 낮다면 → 인접 목록이 적합합니다. 반대로 이동이 거의 없고 조회가 잦다면 → 경로 열거가 조인 없이 빠릅니다.
직접 자식만 조회할 때는 단순 WHERE 조건으로 충분합니다.
SELECT id, name FROM categories WHERE parent_id = 1;
전체 트리를 한 번에 조회할 때는 WITH RECURSIVE를 사용합니다. depth와 path 배열을 추가하면 들여쓰기 출력과 순서 정렬이 가능합니다.
WITH RECURSIVE category_tree AS (
SELECT id, name, parent_id, 0 AS depth,
ARRAY[id] AS path
FROM categories
WHERE parent_id IS NULL
UNION ALL
SELECT c.id, c.name, c.parent_id, ct.depth + 1,
ct.path || c.id
FROM categories c
JOIN category_tree ct ON c.parent_id = ct.id
)
SELECT
REPEAT(' ', depth) || name AS indented_name,
depth,
path
FROM category_tree
ORDER BY path;
2. 경로 열거 (Path Enumeration)
각 노드에 루트부터의 전체 경로를 문자열로 저장합니다. /1/2/3/ 형태로 저장하면 LIKE 쿼리로 재귀 없이 모든 자손과 조상을 조회할 수 있습니다. 읽기가 빠르고 구현이 단순하지만, 노드를 이동할 때 해당 노드와 모든 하위 노드의 path 문자열을 일괄 업데이트해야 합니다.
CREATE TABLE categories_path (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
path VARCHAR(500) NOT NULL
);
INSERT INTO categories_path VALUES
(1, '전자기기', '/1/'),
(2, '컴퓨터', '/1/2/'),
(3, '노트북', '/1/2/3/'),
(4, '게이밍 노트북', '/1/2/3/4/');
모든 자손을 조회할 때는 해당 노드의 경로로 LIKE 접두사 매칭을 사용합니다. 모든 조상은 반대 방향으로 적용합니다.
SELECT * FROM categories_path WHERE path LIKE '/1/2/3/%';
SELECT * FROM categories_path
WHERE '/1/2/3/4/' LIKE path || '%';
CREATE INDEX idx_cat_path ON categories_path (path text_pattern_ops);
3. 중첩 집합 (Nested Set)
각 노드에 lft(왼쪽)와 rgt(오른쪽) 숫자를 부여해 트리 구조를 범위로 표현합니다. 어떤 노드의 자손은 해당 노드의 lft와 rgt 사이에 있는 모든 노드입니다. 재귀 없이 순수 범위 조건으로 조회할 수 있어 읽기 성능이 뛰어납니다. 단, 노드를 삽입하거나 이동할 때 영향받는 모든 노드의 lft/rgt 값을 재계산해야 하므로 쓰기 비용이 매우 높습니다.
CREATE TABLE categories_nested (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
lft INT NOT NULL,
rgt INT NOT NULL
);
lft와 rgt 값으로 트리 구조를 표현하면 다음과 같습니다. 전자기기(1,10) 아래 컴퓨터(2,7)가 있고, 컴퓨터 아래 노트북(3,6), 그 아래 게이밍(4,5)이 있는 구조입니다.
SELECT c.* FROM categories_nested AS c
WHERE c.lft BETWEEN 2 AND 7;
SELECT p.* FROM categories_nested AS p
WHERE p.lft < 3 AND p.rgt > 6;
방법별 비교표
세 가지 방법은 읽기/쓰기 패턴과 트리 변경 빈도에 따라 선택합니다.
| 항목 | 인접 목록 | 경로 열거 | 중첩 집합 |
|---|---|---|---|
| 구현 복잡도 | 낮음 | 낮음 | 높음 |
| 자손 전체 조회 | 재귀 CTE 필요 | LIKE — 빠름 | 범위 조건 — 빠름 |
| 직접 자식 조회 | 매우 빠름 | LIKE — 가능 | 계산 필요 |
| 노드 삽입 | 단순 | 경로 계산 필요 | lft/rgt 전체 재계산 |
| 노드 이동 | parent_id만 변경 | 경로 문자열 업데이트 | 전체 재계산 |
| 적합한 상황 | 읽기/쓰기 균형 | 읽기 위주, 이동 드묾 | 읽기 위주, 이동 없음 |
실무 선택 가이드: 카테고리 트리처럼 이동이 있는 경우에는 인접 목록 + 재귀 CTE가 적합합니다. 댓글 계층처럼 깊이가 4 이하로 제한된 경우에는 인접 목록으로도 재귀 없이 충분합니다. 조직도처럼 자주 변경되지 않고 읽기가 많은 경우에는 경로 열거를 고려합니다.
쇼핑몰의 상품 카테고리를 설계할 때 두 방식 중 하나를 선택해야 했습니다. 카테고리는 34단계 깊이이고, 시즌마다 카테고리가 재편성되어 노드 이동이 월 12회 발생했습니다.
경로 열거를 사용하면 읽기는 빠르지만 노드 이동 시 하위 카테고리 수백 개의 path를 일괄 UPDATE해야 했습니다. 인접 목록은 이동이 parent_id 값 하나만 바꾸면 되므로 운영 편의성이 훨씬 높았습니다.
전체 카테고리 트리 조회는 하루 수십 번뿐이고 Redis 캐싱이 있었기 때문에, 재귀 CTE의 약간의 오버헤드는 문제가 되지 않았습니다. 결국 인접 목록을 선택했고, 관리자 페이지의 카테고리 이동 기능이 단순해져 운영 실수가 줄었습니다.
태그 시스템, 소프트 삭제, Polymorphic Association 패턴
게시글을 삭제했는데 관련 댓글과 첨부파일이 함께 사라집니다. 관리자가 "삭제 취소" 요청을 합니다. 테이블에서 이미 DELETE됐으니 복구가 불가능합니다. 다음에는 소프트 삭제로 바꾸려는데, 모든 쿼리마다 WHERE deleted_at IS NULL을 붙여야 합니다. 태그, 소프트 삭제, Polymorphic Association은 자주 만나는 패턴이지만 잘못 설계하면 쿼리마다 수정해야 하는 부채가 생깁니다.
 확대
확대
태그 시스템 — 다대다 3테이블 구조
태그는 전형적인 다대다(M:N) 관계입니다. 하나의 게시글에 여러 태그가 붙고, 하나의 태그도 여러 게시글에 붙습니다. RDBMS에서는 중간 연결 테이블(Junction Table)로 구현합니다.
 확대
확대
article_tags의 (article_id, tag_id) 복합 PK는 중복 태그를 자동으로 방지합니다. 역방향 조회(태그로 게시글 찾기)를 위해 tag_id 단독 인덱스를 추가합니다.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT,
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE TABLE tags (
id SERIAL PRIMARY KEY,
name VARCHAR(50) UNIQUE NOT NULL,
slug VARCHAR(50) UNIQUE NOT NULL,
tag_count INT DEFAULT 0
);
CREATE TABLE article_tags (
article_id INT NOT NULL REFERENCES articles(id) ON DELETE CASCADE,
tag_id INT NOT NULL REFERENCES tags(id) ON DELETE CASCADE,
created_at TIMESTAMPTZ DEFAULT NOW(),
PRIMARY KEY (article_id, tag_id)
);
CREATE INDEX idx_article_tags_tag_id ON article_tags (tag_id);
게시글의 태그를 조회할 때는 article_tags를 경유해 tags를 JOIN합니다. 여러 태그를 모두 가진 게시글을 찾을 때는 GROUP BY + HAVING으로 각 게시글이 가진 해당 태그 수를 세어 필터링합니다.
SELECT t.name, t.slug
FROM tags t
JOIN article_tags at ON t.id = at.tag_id
WHERE at.article_id = 42;
SELECT a.id, a.title, a.created_at
FROM articles a
JOIN article_tags at ON a.id = at.article_id
JOIN tags t ON at.tag_id = t.id
WHERE t.slug = 'postgresql'
ORDER BY a.created_at DESC
LIMIT 20;
SELECT a.id, a.title
FROM articles a
JOIN article_tags at ON a.id = at.article_id
JOIN tags t ON at.tag_id = t.id
WHERE t.slug IN ('postgresql', 'performance', 'indexing')
GROUP BY a.id, a.title
HAVING COUNT(DISTINCT t.slug) = 3;
태그 카운트는 매번 COUNT 집계를 실행하거나, tags 테이블에 캐싱 컬럼을 두고 추가/삭제 시 함께 업데이트하는 방식을 선택합니다. 카운트 정확도가 중요하고 태그 수가 많지 않다면 매번 COUNT, 태그 클라우드처럼 빠른 조회가 중요하다면 캐싱 컬럼이 적합합니다.
SELECT t.name, COUNT(at.article_id) AS cnt
FROM tags t
LEFT JOIN article_tags at ON t.id = at.tag_id
GROUP BY t.id, t.name
ORDER BY cnt DESC;
UPDATE tags SET tag_count = tag_count + 1 WHERE id = :tag_id;
SELECT name, slug, tag_count FROM tags
WHERE tag_count > 0
ORDER BY tag_count DESC
LIMIT 30;
다대다의 핵심은 연결 테이블과 복합 PK입니다. 태그를 연결하고(중복 자동 차단), "여러 태그를 모두 가진 글"을 GROUP BY + HAVING으로 찾는 표준 패턴을 실행합니다.
-- 연결 추가 — 복합 PK라 같은 (article,tag) 재삽입은 자동 무시
INSERT INTO article_tags (article_id, tag_id)
VALUES (42, 1), (42, 2), (42, 3)
ON CONFLICT (article_id, tag_id) DO NOTHING;
-- 3개 태그를 '모두' 가진 글 찾기 (AND 검색)
SELECT a.id, a.title
FROM articles a
JOIN article_tags at ON a.id = at.article_id
JOIN tags t ON at.tag_id = t.id
WHERE t.slug IN ('postgresql', 'performance', 'indexing')
GROUP BY a.id, a.title
HAVING COUNT(DISTINCT t.slug) = 3; -- 3개 = IN 목록 개수
id | title
----+------------------------------
42 | PostgreSQL 인덱스 성능 튜닝
INSERT INTO article_tags (article_id, tag_id) VALUES (42, 1) ON CONFLICT DO NOTHING;- 같은 (article_id, tag_id)를 두 번 넣어도 에러 없이 무시되는지 본다 — ON CONFLICT가 동작하면 복합 PK가 중복 태그를 막고 있는 것. 에러가 나면 PRIMARY KEY (article_id, tag_id) 선언이 빠진 것
- AND 검색에서 HAVING COUNT(DISTINCT t.slug) = 3 의 3이 IN 목록 개수와 일치하는지 확인 — 숫자가 다르면 'OR 검색'이 돼버린다(하나만 가진 글도 걸림)
- DISTINCT를 빼면 같은 태그 중복 연결 시 카운트가 부풀어 오답이 나올 수 있다 — DISTINCT 유무로 결과가 달라지는지 본다
- 태그로 글 찾기가 느리면 idx_article_tags_tag_id(역방향 인덱스)가 있는지 EXPLAIN으로 확인한다
소프트 삭제 (Soft Delete)
소프트 삭제는 데이터를 실제로 삭제하는 대신 deleted_at 타임스탬프로 삭제 여부를 표시하는 패턴입니다. NULL이면 살아있는 데이터, NOT NULL이면 삭제된 데이터입니다. 삭제된 데이터를 일정 기간 후 감사 기록으로 보존하거나 복구할 수 있다는 장점이 있습니다.
주의사항: 삭제된 데이터도 테이블에 계속 남기 때문에 모든 일반 조회 쿼리에 WHERE deleted_at IS NULL 조건을 반드시 포함해야 합니다. ORM을 사용한다면 기본 스코프(default scope)로 설정해 실수를 방지합니다.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT,
author_id INT NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW(),
deleted_at TIMESTAMPTZ NULL
);
UPDATE articles SET deleted_at = NOW() WHERE id = 42;
UPDATE articles SET deleted_at = NULL WHERE id = 42;
DELETE FROM articles WHERE deleted_at < NOW() - INTERVAL '90 days';
일반 조회에는 반드시 deleted_at IS NULL 조건을 포함합니다. 관리자 페이지에서 삭제된 항목을 보려면 deleted_at IS NOT NULL으로 조회합니다.
SELECT * FROM articles WHERE deleted_at IS NULL ORDER BY created_at DESC;
SELECT * FROM articles WHERE deleted_at IS NOT NULL;
Partial Index를 사용하면 살아있는 데이터에만 인덱스가 생성되어 인덱스 크기가 최소화되고 유지 비용도 줄어듭니다. 이 인덱스는 WHERE deleted_at IS NULL 조건이 포함된 쿼리에만 사용됩니다.
CREATE INDEX idx_articles_active ON articles (author_id, created_at DESC)
WHERE deleted_at IS NULL;
SELECT * FROM articles
WHERE author_id = 42 AND deleted_at IS NULL
ORDER BY created_at DESC;
deleted_at 컬럼을 추가하고 소프트 삭제를 구현했지만, 기존 인덱스를 재검토하지 않은 경우 문제가 발생합니다.
예를 들어 CREATE INDEX idx_articles_author ON articles (author_id)처럼 일반 인덱스만 있으면, WHERE author_id = 42 AND deleted_at IS NULL 쿼리에서 인덱스를 사용하더라도 삭제된 행을 포함한 모든 행을 읽고 필터링합니다. 삭제된 데이터가 쌓일수록 불필요하게 읽는 행이 늘어납니다.
해결 방법: 소프트 삭제 테이블의 인덱스는 모두 WHERE deleted_at IS NULL Partial Index로 재생성합니다. 기존 일반 인덱스는 DROP하고 Partial Index로 교체합니다. EXPLAIN ANALYZE로 Index Cond에 deleted_at IS NULL이 포함되는지 확인합니다.
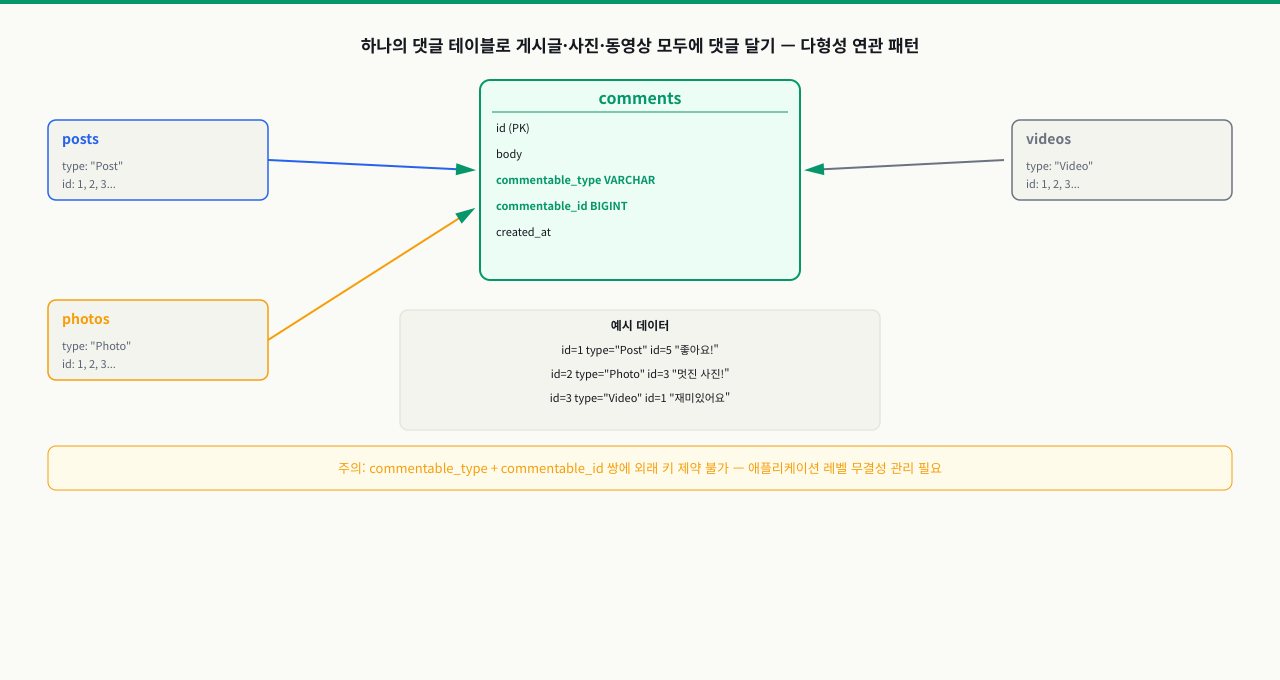
Polymorphic Association — 다형성 연관
하나의 댓글 테이블이 게시글, 상품, 동영상 등 여러 타입의 엔티티에 달릴 수 있는 패턴입니다. commentable_type으로 어느 테이블을 참조하는지 저장하고, commentable_id로 해당 테이블의 PK를 저장합니다.
유연성은 높지만 중요한 단점이 있습니다. commentable_id가 어느 테이블의 행을 가리키는지 DB가 알 수 없기 때문에 FK 제약조건을 설정할 수 없습니다. 참조 무결성(존재하지 않는 게시글에 댓글이 달리는 문제)은 애플리케이션 코드가 직접 보장해야 합니다.
CREATE TABLE comments (
id SERIAL PRIMARY KEY,
body TEXT NOT NULL,
author_id INT NOT NULL REFERENCES users(id),
commentable_type VARCHAR(50) NOT NULL,
commentable_id INT NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW(),
deleted_at TIMESTAMPTZ NULL
);
CREATE INDEX idx_comments_polymorphic
ON comments (commentable_type, commentable_id)
WHERE deleted_at IS NULL;
특정 엔티티의 댓글은 commentable_type과 commentable_id로 조회합니다.
SELECT * FROM comments
WHERE commentable_type = 'Article'
AND commentable_id = 42
AND deleted_at IS NULL;
SELECT c.*, c.commentable_type, c.commentable_id
FROM comments c
WHERE c.author_id = 7 AND c.deleted_at IS NULL;
FK 무결성이 중요하다면 타입별로 별도 댓글 테이블을 만드는 방식을 사용합니다. 이 방식은 FK를 통한 참조 무결성이 보장되지만, "사용자가 쓴 모든 댓글"을 조회하려면 UNION이 필요합니다.
CREATE TABLE article_comments (
id SERIAL PRIMARY KEY,
article_id INT NOT NULL REFERENCES articles(id) ON DELETE CASCADE,
body TEXT NOT NULL,
author_id INT NOT NULL REFERENCES users(id)
);
CREATE TABLE product_comments (
id SERIAL PRIMARY KEY,
product_id INT NOT NULL REFERENCES products(id) ON DELETE CASCADE,
body TEXT NOT NULL,
author_id INT NOT NULL REFERENCES users(id)
);
Polymorphic Association 장단점 비교
두 방식은 구현 유연성과 참조 무결성 사이의 트레이드오프입니다.
| 항목 | Polymorphic (단일 테이블) | 타입별 분리 테이블 |
|---|---|---|
| 구현 유연성 | 높음 — 새 타입 추가 시 스키마 변경 불필요 | 낮음 — 타입마다 테이블 추가 필요 |
| FK 무결성 | 보장 불가 — 앱 코드에 위임 | 보장 — DB 수준 제약조건 |
| 통합 조회 | 단순 — 단일 테이블 WHERE | 복잡 — UNION 필요 |
| 고아 데이터 위험 | 있음 | 없음 (CASCADE로 자동 삭제) |
| 적합한 상황 | 무결성보다 유연성 우선 | 무결성이 중요한 도메인 |
무결성 요구도가 높다면 타입별 분리 테이블을, 새로운 타입이 자주 추가되고 통합 조회가 중요하다면 Polymorphic 방식을 선택합니다.
심화 — 캐싱 카운터는 '유지'가 진짜 일이다
심화: tag_count 같은 비정규화 카운터가 틀어지는 세 가지 이유
앞에서 태그 클라우드를 빠르게 그리려고 tags 테이블에 tag_count 캐싱 컬럼을 두는 방법을 소개했습니다. 이건 "읽기 속도"를 사는 대신 대부분이 과소평가하는 "유지 비용"을 지불하는 결정입니다. 그 비용의 정체를 알아야 카운터를 언제 두고 어떻게 지킬지 판단할 수 있습니다.
- 경쟁(lost update): 카운터를 애플리케이션에서 "값을 읽고 +1 해서 쓰는" 방식으로 갱신하면, 동시에 두 요청이 같은 값을 읽고 각자 덮어써 증가 하나가 사라집니다. 반드시 DB 안에서
UPDATE tags SET tag_count = tag_count + 1로 원자적으로 올리고, 연결(article_tags) 삽입과 같은 트랜잭션에 둬야 합니다. 그래야 삽입이 롤백될 때 카운터만 앞서가지 않습니다. - 표류(drift): 원자적 증가로 동시성을 잡아도, 카운터는 원본의 사본이라 어느 쓰기 경로가 갱신을 빠뜨리면 곧장 어긋납니다. 대량 임포트가 article_tags에 직접 넣거나, 게시글 삭제가 CASCADE로 연결을 지우면서 카운터를 안 줄이면 값이 틀어집니다. 캐싱 집계는 "언젠가는 틀린다"를 전제로, **원본에서 다시 세어 맞추는 정합성 작업(reconciliation)**을 주기적으로 돌려야 합니다.
- 핫 로우 경합: 'javascript' 같은 초인기 태그는 글이 달릴 때마다 tags의 같은 한 행이 갱신됩니다. 동시성이 높으면 그 행의 락을 두고 요청들이 줄을 서(직렬화) 처리량 병목이 되고, 글 행과 태그 행을 서로 다른 순서로 잠그는 두 트랜잭션이 만나면 데드락도 납니다. 극단적 핫 태그는 카운터를 여러 하위 행으로 쪼갠 뒤 합산하는 샤딩 카운터나 근사 카운트를 고려합니다.
정리하면, 비정규화 카운터는 "만들 때"가 아니라 "유지할 때" 비용이 드는 구조입니다. 읽기가 압도적이고 약간의 오차·지연을 허용할 때만 두고, 갱신은 원자적·트랜잭션 내부로, 정합성은 스케줄러로 지키는 것이 원칙입니다.
상황: tags.tag_count로 태그 클라우드를 그리는데, 시간이 지날수록 숫자가 실제와 맞지 않습니다. 어떤 태그는 부풀어 있고 어떤 태그는 실제보다 작습니다. 태그를 붙이고 뗄 때 카운트를 함께 갱신하는 코드는 분명히 있습니다.
원인: 카운터가 원본(article_tags)의 사본인데, 그 사본을 갱신하지 않는 쓰기 경로가 여럿 있었습니다. (1) 애플리케이션이 값을 읽고 +1 하는 read-modify-write라 동시 태깅에서 lost update가 났고, (2) 카운터 UPDATE가 삽입과 다른 트랜잭션이라 삽입이 실패해도 카운터는 이미 올라가 있었으며, (3) 게시글을 지울 때 article_tags는 CASCADE로 삭제됐지만 tag_count를 줄이는 코드가 그 경로엔 없었고, (4) 운영자가 대량 임포트로 article_tags에 직접 넣었습니다. 각 경로가 조금씩 카운터를 어긋나게 해 누적된 것입니다.
진단: 캐시된 값과 원본에서 다시 센 값을 나란히 비교해 어긋난 태그를 뽑습니다.
SELECT t.id, t.name,
t.tag_count AS cached,
COUNT(at.article_id) AS actual
FROM tags t
LEFT JOIN article_tags at ON at.tag_id = t.id
GROUP BY t.id, t.name, t.tag_count
HAVING t.tag_count <> COUNT(at.article_id)
ORDER BY ABS(t.tag_count - COUNT(at.article_id)) DESC;
결과 행이 곧 표류한 태그입니다. cached가 대체로 크면 롤백·감소 누락 경로가, 작으면 카운터 없이 연결만 추가하는 경로가 범인입니다.
해결: 카운터를 단일 경로로 묶고 정기적으로 맞춥니다.
-- 1) 모든 연결 변경이 카운터를 함께 바꾸도록 트리거로 일원화
CREATE OR REPLACE FUNCTION sync_tag_count() RETURNS trigger AS $$
BEGIN
IF TG_OP = 'INSERT' THEN
UPDATE tags SET tag_count = tag_count + 1 WHERE id = NEW.tag_id;
ELSIF TG_OP = 'DELETE' THEN
UPDATE tags SET tag_count = tag_count - 1 WHERE id = OLD.tag_id;
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_sync_tag_count
AFTER INSERT OR DELETE ON article_tags
FOR EACH ROW EXECUTE FUNCTION sync_tag_count();
-- 2) 그래도 남는 오차를 위한 주기적 정합성 작업(reconciliation)
UPDATE tags t
SET tag_count = sub.cnt
FROM (
SELECT tag_id, COUNT(*) AS cnt FROM article_tags GROUP BY tag_id
) sub
WHERE t.id = sub.tag_id AND t.tag_count <> sub.cnt;
트리거로 삽입·삭제·CASCADE·대량 임포트까지 모두 같은 갱신을 타게 하면 표류의 원천이 사라지고, 야간 reconciliation이 남은 오차를 정리합니다. 애플리케이션 코드에서 카운터를 직접 만지던 로직은 제거해 갱신 경로를 하나로 유지합니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 계층·태그·소프트삭제 패턴의 핵심 구문을 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
| 인접 목록(자기참조 FK) | 계층을 parent_id로 표현 | parent_id INT REFERENCES categories(id) |
WITH RECURSIVE | 트리 전체 순회(자손 조회) | WITH RECURSIVE t AS (앵커 UNION ALL 자식 JOIN t) SELECT … |
경로 열거 + LIKE | 재귀 없이 자손 조회 | WHERE path LIKE '/1/2/%' (+ text_pattern_ops 인덱스) |
| 중첩 집합(lft/rgt) | 범위로 자손 조회 | WHERE lft BETWEEN 2 AND 7 |
| 연결 테이블 복합 PK | M:N·중복 자동 차단 | PRIMARY KEY (article_id, tag_id) |
ON CONFLICT DO NOTHING | 중복 연결 무시 삽입 | INSERT INTO article_tags VALUES (42, 1) ON CONFLICT DO NOTHING |
GROUP BY + HAVING COUNT(DISTINCT) | 'AND 태그'를 모두 가진 글 | … WHERE t.slug IN (…) GROUP BY a.id HAVING COUNT(DISTINCT t.slug) = 3 |
소프트 삭제 UPDATE | 물리삭제 대신 표시 | UPDATE articles SET deleted_at = NOW() WHERE id = 42 |
WHERE deleted_at IS NULL | 삭제 행 제외 조회 | SELECT * FROM articles WHERE deleted_at IS NULL |
| 부분 인덱스 | 살아있는 행만 인덱싱 | CREATE INDEX … ON articles (author_id, created_at DESC) WHERE deleted_at IS NULL |
| 원자적 카운터 증가 | lost update 방지 | UPDATE tags SET tag_count = tag_count + 1 WHERE id = ? |
CREATE TRIGGER | 카운터 갱신 경로 일원화 | CREATE TRIGGER trg AFTER INSERT OR DELETE ON article_tags … |
관련 모듈로 더 깊이:
- 제1·2·3정규화와 역정규화(De-normalization) 실전 적용 기준 — 스키마를 정규화/비정규화 어디까지 할지의 기준
- PK, FK 제약조건과 Cascade 설정이 주는 영향 — 패턴의 핵심인 FK 무결성과 참조 관계 설계
- 요구사항 분석부터 정규화 및 ERD 작성 전략 — 패턴을 적용하기 전 엔티티 관계를 모델링하는 법
다음 모듈에서는 RANK, ROW_NUMBER, LAG, LEAD 등 윈도우 함수를 활용한 실무 분석 쿼리 패턴을 다룹니다.