서비스 요구사항이 커지면 하나의 DB 분류만으로 설명하기 어려운 선택지가 등장합니다. RDBMS, NoSQL, NewSQL은 정합성, 확장성, 운영 복잡도에서 서로 다른 타협을 합니다. 차이를 이해하면 팀 상황에 맞는 저장소 조합을 고를 수 있습니다.
세 가지 데이터베이스 패러다임을 비교 분석하고, 프로젝트의 요구사항에 맞는 올바른 선택을 할 수 있는 판단 기준을 갖춥니다.
- 1RDBMS의 강점과 수직 확장의 한계를 설명할 수 있다
- 2NoSQL 4가지 유형을 구분하고 각각의 사용 사례를 들 수 있다
- 3NewSQL의 등장 배경을 이해하고 대표 제품을 식별할 수 있다
- 4데이터베이스 유형들을 항목별로 비교할 수 있다
- 5프로젝트 요구사항에 맞춰 언제 무엇을 선택할지 판단할 수 있다
RDBMS vs NoSQL vs NewSQL — 언제 무엇을 선택하는가
"어떤 데이터베이스를 써야 하나요?" 이 질문은 모든 프로젝트에서 반복됩니다. 정답은 하나가 아닙니다. 데이터의 형태, 접근 패턴, 확장성 요구사항, 일관성 요구 수준에 따라 올바른 선택이 달라집니다. 이 모듈에서는 세 가지 주요 패러다임의 특성을 깊이 이해하고 실무에서의 선택 기준을 세웁니다.
RDBMS의 강점과 한계 — 구조화된 데이터의 왕
팀 내에서 새 서비스의 DB를 무엇으로 할지 논쟁이 벌어집니다. 누군가 "요즘은 NoSQL이 대세"라고 합니다. 다른 누군가는 "그냥 PostgreSQL 쓰자"고 합니다. 판단 기준 없이 선택하면 나중에 마이그레이션 비용이 생깁니다. RDBMS가 무엇을 잘하고 어디서 한계를 드러내는지 알면, 언제 다른 선택이 필요한지도 자연스럽게 판단할 수 있습니다.
 확대
확대
RDBMS란 무엇인가
스타트업에서 서비스를 처음 만들 때 대부분 PostgreSQL이나 MySQL을 선택합니다. 검증된 ACID 트랜잭션, 강력한 JOIN, SQL 표준 — 이 조합은 수십 년간 대부분의 비즈니스 요구사항을 충족해 왔습니다. 먼저 RDBMS가 잘하는 것과 못하는 것을 정확히 파악해야, 언제 다른 선택이 필요한지 판단할 수 있습니다.
관계형 데이터베이스 관리 시스템(Relational Database Management System)은 Edgar Codd의 관계형 모델을 구현한 데이터베이스입니다. 데이터는 행(Row)과 열(Column)로 구성된 테이블에 저장되며, 테이블 간의 관계는 외래키(Foreign Key)로 표현됩니다.
대표 제품: PostgreSQL, MySQL, MariaDB, Oracle, SQL Server, SQLite
RDBMS의 4가지 핵심 강점
1. 엄격한 스키마(Schema Enforcement): 컬럼 타입, 제약조건, 외래키 관계가 명시적으로 정의되어 잘못된 데이터가 저장되는 것을 DB 레벨에서 차단합니다.
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INT NOT NULL REFERENCES users(id),
total DECIMAL(12, 2) NOT NULL CHECK (total > 0),
status VARCHAR(20) CHECK (status IN ('pending','paid','shipped','cancelled')),
created_at TIMESTAMP DEFAULT NOW()
);
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 요구사항에서 일관성(C)과 가용성(A) 중 어느 쪽을 포기할 수 없는지 확인합니다. 금융·결제처럼 데이터 불일치가 절대 허용되지 않으면 RDBMS(CA)를, 글로벌 분산과 고가용성이 최우선이면 NoSQL(AP)을 선택합니다.
- 스키마 변경 빈도를 기준으로 판단합니다. 한 달에 1회 이상 컬럼 추가·변경이 예상되면 RDBMS의 ALTER TABLE 비용이 누적됩니다 — 이 경우 MongoDB처럼 스키마 유연성이 높은 DB가 초기 개발 속도를 높입니다.
- 두 시그널을 조합해 판단합니다: $lookup(MongoDB)이나 JOIN이 빈번하고 + 복잡한 집계가 필요하다면 → 선택한 NoSQL이 잘못된 도구일 수 있습니다. NoSQL은 단일 컬렉션에서 완결되는 접근 패턴에 최적화돼 있습니다.
2. ACID 트랜잭션: 복잡한 비즈니스 로직을 안전하게 처리합니다. 아래 예시에서 세 작업 중 하나라도 실패하면 전체가 롤백됩니다.
BEGIN;
UPDATE inventory SET stock = stock - 1 WHERE product_id = 101;
INSERT INTO orders (user_id, product_id, total) VALUES (5, 101, 29900);
INSERT INTO payments (order_id, amount, method) VALUES (LASTVAL(), 29900, 'card');
COMMIT;
3. 강력한 JOIN과 집계: RDBMS가 가장 빛을 발하는 영역은 여러 테이블을 연결한 복잡한 집계 분석입니다.
SELECT
DATE_TRUNC('month', o.created_at) AS month,
c.name AS category,
SUM(oi.price * oi.quantity) AS revenue,
COUNT(DISTINCT o.user_id) AS unique_buyers
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
JOIN categories c ON p.category_id = c.id
WHERE o.status = 'paid'
GROUP BY 1, 2
ORDER BY 1 DESC, 3 DESC;
4. SQL 표준: SQL은 ANSI 표준으로, 한번 배우면 PostgreSQL, MySQL, Oracle 등 어디서든 응용 가능합니다.
RDBMS의 한계: 수직 확장의 벽
RDBMS의 기본 확장 방식은 수직 확장(Scale Up)입니다. CPU와 RAM을 더 강력한 것으로 교체하는 방식인데, 비용이 기하급수적으로 증가합니다. 수평 확장(Scale Out, 서버를 여러 대로 늘리기)은 샤딩 복잡성, 분산 트랜잭션, 일관성 유지 문제 때문에 매우 어렵습니다.
트위터가 하루 5억 개의 트윗을 처리하거나 넷플릭스가 2억 명의 스트리밍 요청을 동시에 처리하는 규모에서 단일 RDBMS는 한계를 드러냅니다.
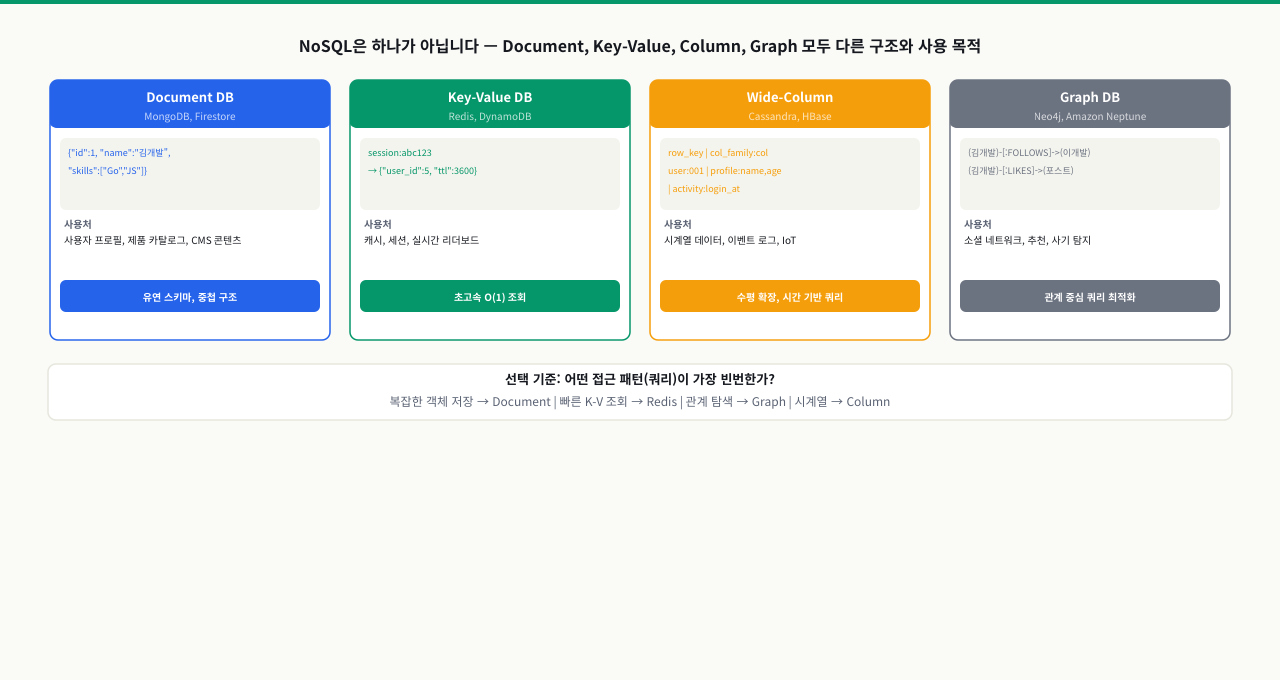
NoSQL 4가지 유형 — 각각 언제 쓰는가
"NoSQL 써봐요"라는 말을 들었는데, NoSQL이 무엇 하나가 아니라는 사실을 모르면 어디서부터 시작해야 할지 막막합니다. 문서 DB, 키-값 저장소, 컬럼 패밀리, 그래프 DB — 전부 NoSQL이지만 쓰임새가 완전히 다릅니다. 사용 사례와 패턴 없이 유형만 외우면 실제 선택에서 도움이 안 됩니다. 각 유형이 어떤 문제를 해결하기 위해 나왔는지를 알면 선택 기준이 생깁니다.
 확대
확대
NoSQL의 등장 배경
2000년대 웹 2.0 시대, 구글, 아마존, 페이스북은 기존 RDBMS로 감당할 수 없는 규모의 데이터와 트래픽을 처리해야 했습니다. 이 과정에서 CAP 정리가 주목받았습니다. CAP 정리는 분산 시스템에서 일관성(Consistency), 가용성(Availability), 파티션 내성(Partition Tolerance) 세 가지를 동시에 보장할 수 없다는 이론입니다. 전통적인 RDBMS는 일관성과 가용성을 선택(CA)하며 파티션 상황에 취약합니다. NoSQL은 대부분 가용성과 파티션 내성(AP)을 선택하고 최종 일관성(Eventual Consistency)을 허용합니다.
데이터베이스 유형 전체 비교표
| 유형 | 대표 제품 | 데이터 모델 | 강점 | 주요 사용 사례 |
|---|---|---|---|---|
| RDBMS | PostgreSQL, MySQL | 테이블/행/열 | ACID, JOIN, 집계 | 전자상거래, 금융, ERP |
| Document | MongoDB, Firestore | JSON/BSON 문서 | 유연한 스키마, 중첩 구조 | CMS, 카탈로그, 사용자 프로필 |
| Key-Value | Redis, DynamoDB | 키 → 값 | 초고속 읽기/쓰기 | 캐시, 세션, 실시간 순위표 |
| Column Family | Cassandra, HBase | 컬럼 패밀리 | 수평 확장, 쓰기 성능 | 시계열, 이벤트 로그, IoT |
| Graph | Neo4j, Amazon Neptune | 노드 + 엣지 | 관계 탐색 성능 | SNS 관계, 추천, 사기 탐지 |
| NewSQL | CockroachDB, Spanner | 테이블/행/열 | ACID + 수평 확장 | 글로벌 분산 서비스 |
유형 1: Document DB — MongoDB
MongoDB는 JSON과 유사한 BSON 형식의 문서를 컬렉션에 저장합니다. 상품마다 속성이 다른 이커머스 카탈로그처럼 스키마가 유연해야 하는 경우에 적합합니다. 그러나 여러 컬렉션을 참조하는 복잡한 JOIN이 필요한 경우에는 부적합합니다.
db.products.insertMany([
{
name: "노트북",
price: 1500000,
specs: { cpu: "M3", ram: 16, storage: 512 }
},
{
name: "티셔츠",
price: 29000,
sizes: ["S", "M", "L", "XL"],
colors: ["white", "black"]
}
])
유형 2: Key-Value — Redis
Redis는 메모리 기반으로 초당 수십만 건의 읽기/쓰기가 가능합니다. DB 캐시 레이어로 가장 많이 사용되며, TTL 기반 세션 관리와 Sorted Set을 이용한 실시간 순위표 구현에 특히 강합니다.
SET session:user:12345 '{"userId":12345,"role":"admin"}' EX 1800
ZADD leaderboard 9850 "player_kim"
ZADD leaderboard 9200 "player_lee"
ZREVRANGE leaderboard 0 9 WITHSCORES
유형 3: Column Family — Cassandra
Cassandra는 분산 아키텍처로 노드를 추가하는 방식으로 TB 단위까지 수평 확장이 가능합니다. 시계열 데이터와 이벤트 로그처럼 쓰기가 읽기보다 많은 워크로드에 최적화되어 있습니다.
CREATE TABLE sensor_readings (
device_id UUID,
timestamp TIMESTAMP,
temperature FLOAT,
humidity FLOAT,
PRIMARY KEY (device_id, timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);
유형 4: Graph DB — Neo4j
Neo4j는 노드와 엣지(관계)를 네이티브로 저장합니다. 친구의 친구 탐색처럼 관계를 따라가는 쿼리를 RDBMS의 자기 참조 JOIN 대비 압도적인 성능으로 처리합니다.
MATCH (user:Person {name: "김철수"})-[:FOLLOWS*2..3]->(recommended:Person)
WHERE NOT (user)-[:FOLLOWS]->(recommended)
RETURN recommended.name, COUNT(*) AS mutual_connections
ORDER BY mutual_connections DESC
LIMIT 10
NewSQL: 두 세계의 장점 통합
NewSQL은 RDBMS의 ACID와 SQL을 유지하면서 NoSQL 수준의 수평 확장을 달성합니다. 글로벌 분산 서비스에서 강력한 일관성이 필요할 때 선택합니다.
| 제품 | 특징 | 출신 |
|---|---|---|
| CockroachDB | PostgreSQL 호환 SQL, 자동 샤딩 | 오픈소스 |
| Google Spanner | 글로벌 분산 ACID, TrueTime | |
| TiDB | MySQL 호환, HTAP(분석+OLTP) | PingCAP |
| YugabyteDB | PostgreSQL + Cassandra 결합 | 오픈소스 |
이커머스 플랫폼을 MongoDB로 구축했는데, 주문-상품-재고-사용자 간의 관계가 복잡해질수록 애플리케이션 코드에서 여러 컬렉션을 수동으로 조인해야 하는 상황이 발생했습니다. MongoDB의 $lookup은 SQL JOIN보다 제한적이고 성능도 낮아, 결국 RDBMS로 마이그레이션하는 비용이 발생했습니다.
해결: 데이터 모델을 설계할 때 "관계가 얼마나 복잡한가?"를 먼저 평가합니다. 테이블 3개 이상이 서로 JOIN되는 구조라면 NoSQL보다 RDBMS가 더 적합합니다. NoSQL은 단일 컬렉션에서 완결되는 문서 중심 접근 패턴(조회 1번으로 필요한 데이터를 모두 가져오는 구조)에 최적화되어 있습니다.
언제 무엇을 선택하는가 — 의사결정 기준
서비스 초기에 Redis를 세션 캐시로 쓰다가, 어느 순간 주요 데이터까지 Redis에 넣기 시작합니다. 그러다 Redis가 재시작되면서 데이터가 날아갑니다. 반대로 RDBMS에 비정형 JSON을 억지로 컬럼에 넣으면서 스키마 변경이 배포마다 문제가 됩니다. 잘못된 DB 선택은 처음엔 문제없어 보이다가 규모가 커질수록 마이그레이션 비용으로 되돌아옵니다. 데이터 특성과 접근 패턴을 기준으로 선택하면 나중에 후회가 없습니다.
 확대
확대
데이터베이스 선택 흐름
올바른 데이터베이스 선택은 기술 트렌드가 아니라 데이터의 특성과 접근 패턴으로 결정됩니다. 다음 질문에 순서대로 답하면 선택지를 좁힐 수 있습니다.
첫 번째로 "데이터 간 관계가 복잡한가?"를 확인합니다. 여러 엔티티가 서로 참조하고, 이를 함께 집계하는 쿼리가 필요하다면 RDBMS가 기본 선택입니다. 스키마가 명확하고 팀이 SQL에 익숙하다면 PostgreSQL 또는 MySQL로 시작하는 것이 가장 안전합니다.
두 번째로 "어떤 종류의 특수 요구사항이 있는가?"를 확인합니다. 초당 수십만 건의 캐시나 세션을 처리해야 한다면 Redis, 속성이 다양한 문서를 유연하게 저장해야 한다면 MongoDB, TB 단위 시계열 이벤트를 수집해야 한다면 Cassandra, 관계 탐색이 핵심 기능이라면 Neo4j를 고려합니다.
세 번째로 "글로벌 분산과 ACID가 동시에 필요한가?"를 확인합니다. 여러 리전에 걸친 분산 배포에서 강한 일관성이 필요하다면 NewSQL(CockroachDB, Spanner)이 유일한 선택입니다.
실무 선택 기준 요약
스키마가 명확하고 관계가 복잡하다면 RDBMS(PostgreSQL)를 선택합니다. 수천만 건 이하이고 팀이 SQL에 익숙하다면 역시 RDBMS가 기본입니다. 캐싱, 세션 관리, 실시간 순위가 필요하다면 Redis를 추가합니다. 문서 구조가 유연하고 스키마가 자주 바뀐다면 MongoDB를 고려합니다. TB 단위 시계열 및 이벤트 로그라면 Cassandra, 관계 탐색이 핵심 기능이라면 Neo4j, 전 세계 분산과 ACID가 동시에 필요하다면 CockroachDB 또는 Spanner를 선택합니다.
하나의 서비스에 여러 DB를 혼용하는 것은 매우 흔한 패턴입니다. 예를 들어 PostgreSQL(주 데이터) + Redis(캐시) + Elasticsearch(검색) 조합이 중규모 이커머스에서 표준적으로 사용됩니다.
초기 스타트업에서는 팀 규모와 운영 복잡도를 고려해 PostgreSQL 단일 DB로 시작하는 것이 합리적입니다. 사용자가 늘어나면서 특정 병목이 생기는 시점에 목적에 맞는 DB를 추가합니다. 일반적인 진화 경로는 다음과 같습니다. 세션과 API 캐싱 문제가 생기면 Redis를 추가하고, 전문 검색 기능이 필요해지면 Elasticsearch를 붙이고, 사용자 행동 이벤트 로그가 폭증하면 Cassandra나 ClickHouse를 도입합니다. 처음부터 모든 DB를 도입하는 것은 운영 복잡도와 팀 학습 비용을 불필요하게 높입니다. 병목이 실제로 측정된 뒤에 전문 DB를 도입하는 점진적 전략이 현장에서 가장 많이 쓰입니다.
심화 — '수평 확장'이라는 말이 감추는 조건
심화: 분산 SQL이 저절로 확장되지 않는 이유 — 쓰기 핫스팟
NewSQL을 "ACID + 수평 확장"으로 소개하면, 노드만 늘리면 쓰기가 알아서 빨라질 것 같습니다. 하지만 분산 SQL이 노드에 데이터를 나누는 방식을 모르면, 옮긴 뒤에 "왜 안 빨라지지"라는 벽을 만납니다.
CockroachDB·Spanner 같은 분산 SQL은 대부분 키 범위(range) 기반 샤딩을 씁니다. 키 공간을 여러 구간으로 쪼개 각 구간(range)을 노드에 분산하고, 각 range의 리더(리스홀더) 노드가 그 구간의 쓰기를 담당합니다. 여기서 함정이 생깁니다.
- 단조 증가 키 = 단일 range 핫스팟: 기본키가
SERIAL/auto-increment거나 삽입 시각 순이면, 새 행은 언제나 현재 최대 키를 가집니다. 그래서 모든 신규 삽입이 마지막 range 한 곳으로 몰리고, 그 range를 맡은 노드 한 대만 일합니다. 나머지 노드는 놀아도 쓰기 TPS는 노드 한 대분에서 멈춥니다. - 노드 추가로 안 풀리는 이유: 확장의 전제는 "데이터와 부하가 여러 range로 흩어진다"입니다. 키가 한쪽으로만 자라면 range가 안 쪼개져(정확히는 계속 뒤쪽만 쪼개져) 부하가 퍼지지 않습니다.
- 해결은 키를 흩뿌리는 것: 해시 샤딩 인덱스(CockroachDB
USING HASH)나 UUID·랜덤 접두사 키를 쓰면 삽입이 여러 range에 분산돼 여러 노드가 동시에 쓰기를 받습니다. 대가로 그 키의 범위 스캔이 흩어져(scatter-gather) 정렬·구간 조회 성능을 일부 내줍니다 — 순서가 중요한 접근 패턴과 저울질해야 합니다.
핵심은, 앞의 비교표에서 NewSQL 칸에 적힌 "수평 확장"이 무조건이 아니라 스키마 설계(키 분포) 위에서만 성립한다는 점입니다. 도구를 바꿔도 데이터 모델링 책임은 사라지지 않습니다.
상황: 단일 PostgreSQL의 쓰기 한계 때문에 분산 SQL로 이전했습니다. 노드를 3배로 늘렸는데 삽입 TPS가 늘지 않고, 대시보드를 보면 유독 한 노드의 CPU만 100%, 나머지는 20% 언저리로 놀고 있습니다.
원인: 옮긴 테이블의 기본키가 기존 스키마 그대로 자동 증가 정수(또는 created_at 순)였습니다. 범위 기반 샤딩에서 새 행은 항상 최대 키라 마지막 range로만 들어가고, 그 range의 리스홀더 노드 한 대가 모든 신규 쓰기를 처리합니다. 전형적인 단조 증가 키 쓰기 핫스팟으로, 노드를 늘려도 쓰기가 한 range에 묶여 확장이 되지 않습니다.
진단: 노드별·range별 쓰기 분포를 확인합니다. 한 range(또는 hot range)가 거의 모든 쓰기 QPS를 받고, 그 리스홀더 노드의 CPU만 포화 상태인지 봅니다. 다른 노드가 놀고 있는데 처리량이 안 오르면 분산이 아니라 집중이 문제입니다.
-- 개념 예시: 단조 증가 키(문제) vs 해시 샤딩 키(해결)
-- 문제: 새 행이 항상 마지막 range로 몰림
CREATE TABLE events (
id BIGSERIAL PRIMARY KEY, -- 단조 증가 → 단일 range 핫스팟
body STRING
);
-- 해결: 기본키에 해시 샤딩을 적용해 range를 여러 개로 분산
CREATE TABLE events (
id BIGSERIAL,
body STRING,
PRIMARY KEY (id) USING HASH WITH (bucket_count = 16)
);
해결: 기본키를 값이 고루 흩어지는 형태로 바꿉니다 — 해시 샤딩 인덱스(USING HASH)나 UUID·랜덤 접두사 키. 그러면 삽입이 여러 range에 퍼져 여러 노드가 동시에 쓰기를 받고, 노드를 늘린 만큼 쓰기 TPS가 실제로 올라갑니다. 단, 그 키로 하던 범위 조회·정렬은 scatter-gather가 되어 느려질 수 있으니, 순서가 필요한 조회는 별도 인덱스나 접근 패턴으로 보완합니다. Spanner 역시 같은 이유로 "단조 증가 키를 기본키로 쓰지 말라"고 안내합니다 — 분산 SQL의 확장은 키 설계에 달려 있습니다.
명령어·구문 빠른 참조
이 모듈에서 비교한 각 패러다임의 대표 질의를 한눈에 모았습니다(SQL 외 질의 언어 포함).
| 구문/명령 | 용도 | 예 |
|---|---|---|
CREATE TABLE + 제약 (RDBMS) | 엄격한 스키마·무결성 | CREATE TABLE orders (… status VARCHAR CHECK (status IN ('pending','paid',…))) |
BEGIN … COMMIT (RDBMS) | ACID 트랜잭션 | BEGIN; UPDATE inventory …; INSERT INTO orders …; COMMIT; |
다중 JOIN + 집계 (RDBMS) | 복잡한 관계 분석 | … FROM orders o JOIN order_items oi … GROUP BY 1, 2 |
insertMany (MongoDB 문서) | 유연한 JSON 문서 저장 | db.products.insertMany([{ name:'노트북', specs:{ cpu:'M3' } }]) |
SET … EX / ZADD (Redis KV) | 캐시·세션·실시간 순위표 | SET session:1 '…' EX 1800, ZREVRANGE leaderboard 0 9 WITHSCORES |
PRIMARY KEY (a, b) (Cassandra CQL) | 넓은 행·시계열 쓰기 | PRIMARY KEY (device_id, timestamp) WITH CLUSTERING ORDER BY (timestamp DESC) |
MATCH … RETURN (Neo4j Cypher) | 관계 탐색 | MATCH (u)-[:FOLLOWS*2..3]->(r) RETURN r.name |
PRIMARY KEY … USING HASH (NewSQL) | 쓰기 핫스팟 분산 | PRIMARY KEY (id) USING HASH WITH (bucket_count = 16) |
관련 모듈로 더 깊이:
- 파일 시스템의 한계와 데이터베이스 관리 시스템(DBMS)의 탄생 — 관계형/문서/키-값 등 데이터 모델 패러다임의 근본 차이
- 우리 서비스에 맞는 최적의 RDBMS vs NoSQL 고르기 — 요구사항별로 어떤 DB를 고를지의 의사결정 흐름
- Document DB (MongoDB) 임베딩 vs 참조 설계 기준 — RDBMS의 대안으로 가장 먼저 검토하는 문서형 DB의 설계 원리
다음 모듈에서는 Document DB(MongoDB)의 임베딩 vs 참조 설계 기준과 스키마 유연성의 실무적 의미를 다룹니다.