월간 매출 리포트를 만들 때 단순 SELECT만으로는 답이 나오지 않습니다. 상품별·지역별로 묶어 합계를 내고, 비정상적으로 튀는 그룹을 빠르게 찾아야 합니다. GROUP BY와 HAVING을 정확히 이해하면 대시보드와 정산 쿼리를 훨씬 안전하게 작성할 수 있습니다.
GROUP BY는 데이터 분석의 핵심입니다. 실행 순서(WHERE → GROUP BY → HAVING → SELECT → ORDER BY)를 이해하면 어디에 조건을 넣어야 하는지 직관적으로 판단할 수 있습니다.
- 1COUNT, SUM, AVG, MAX, MIN의 동작과 NULL 처리를 구분하여 정확히 집계할 수 있다
- 2GROUP BY의 실행 순서를 이해하고 의도한 단위로 그룹을 묶을 수 있다
- 3HAVING과 WHERE를 구분해 그룹 필터와 행 필터를 올바른 위치에 작성할 수 있다
- 4월별 매출, 카테고리별 통계 같은 실전 분석 쿼리를 작성할 수 있다
- 5ROLLUP과 CUBE로 소계와 합계를 자동으로 생성할 수 있다
- 6FILTER(WHERE ...)로 조건부 집계를 한 쿼리에서 처리할 수 있다
GROUP BY와 집계함수 — 데이터 분석 기초
월별 매출 리포트를 만들어야 했는데, 처음엔 Python으로 짰다. DB에서 전체 주문을 끌어다가 딕셔너리로 월별로 묶고, 합계 계산하고 — 코드가 30줄쯤 됐다. 옆에 앉은 시니어가 보더니 쿼리 하나를 써줬다. SELECT DATE_TRUNC('month', created_at), SUM(amount) FROM orders GROUP BY 1 — 끝이었다. 그 순간 깨달았다, 내가 Python으로 하고 있던 루프와 딕셔너리 작업이 전부 GROUP BY 한 줄로 DB 안에서 처리될 수 있다는 걸. 집계를 애플리케이션 레이어에서 하면 전체 데이터를 네트워크로 옮겨야 하지만, DB 안에서 하면 결과만 나온다. GROUP BY와 집계함수를 모르면 불필요한 데이터를 수십만 건씩 끌어오는 코드를 계속 짜게 된다.
집계함수와 GROUP BY — 동작 원리 이해하기
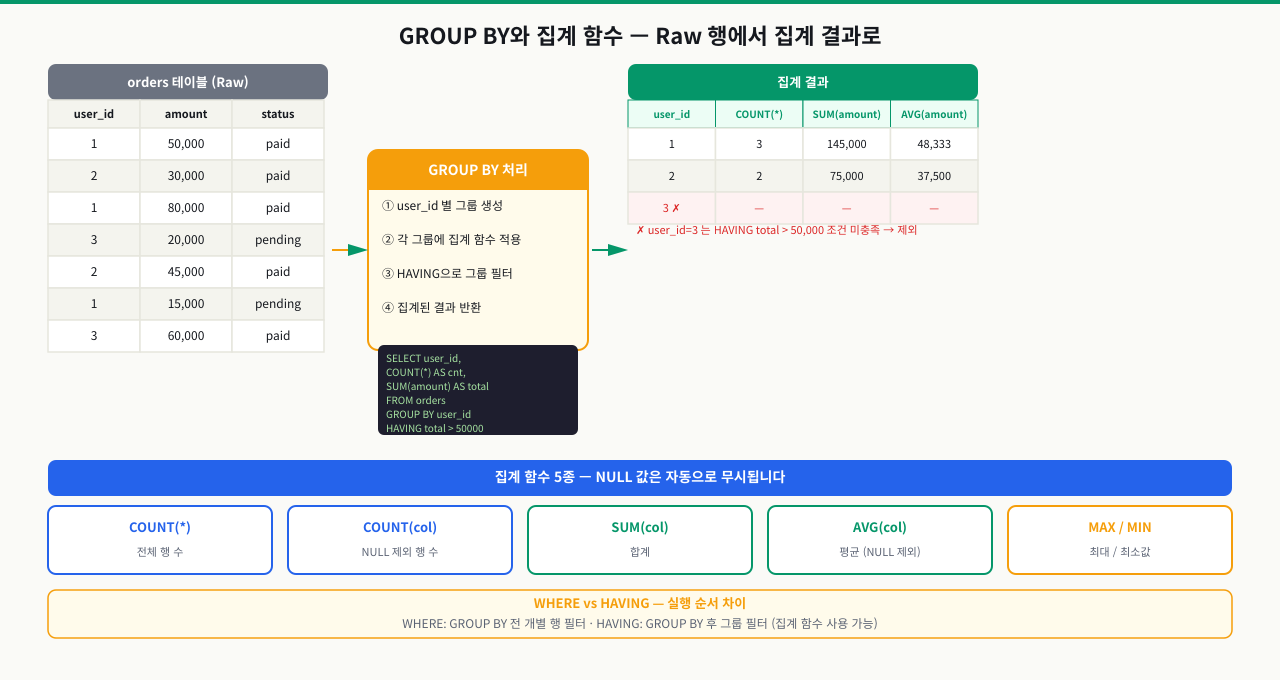
월별 매출 집계 쿼리를 짰는데 총합이 실제 데이터와 다릅니다. GROUP BY에 잘못된 컬럼을 포함시켜서 집계 단위가 달라진 것입니다. 또 NULL이 포함된 컬럼을 COUNT하면 NULL은 세지 않는데 이 동작을 모르면 집계 결과를 잘못 해석합니다. 집계함수와 GROUP BY의 동작 원리를 정확히 알아야 의도한 집계를 얻을 수 있습니다.
 확대
확대
집계함수 종류와 NULL 처리
COUNT(*) 는 NULL 여부와 무관하게 모든 행을 셉니다. COUNT(column)은 해당 컬럼 값이 NULL인 행을 제외합니다. SUM, AVG, MIN, MAX는 모두 NULL 값을 무시하고 계산합니다. NULL을 0으로 포함시키려면 COALESCE(column, 0)으로 감싸야 합니다.
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
category VARCHAR(50),
amount NUMERIC(12, 2),
status VARCHAR(20) NOT NULL DEFAULT 'pending',
created_at TIMESTAMP DEFAULT NOW()
);
실행 완료 또는 조회 결과가 표시됩니다.
- 행 수 먼저: GROUP BY 결과 행 수와 COUNT(DISTINCT 기준컬럼) 값을 비교 — 같으면 모든 그룹이 유일하게 묶인 것
- COUNT 차이 판단: COUNT(*)가 COUNT(amount)보다 크면 그 차이만큼 NULL 행이 존재. 5행 중 2행이 NULL이면 COUNT(*)=5, COUNT(amount)=3
- HAVING이 필요한 시점: WHERE에 COUNT(*) 같은 집계 조건을 쓰면 오류. 집계 결과로 필터해야 하면 반드시 HAVING — WHERE는 GROUP BY 이전, HAVING은 이후에 실행됨
SELECT
COUNT(*) AS 총행수,
COUNT(amount) AS 금액있는행수,
COUNT(DISTINCT user_id) AS 고유사용자수,
SUM(amount) AS 총금액,
AVG(amount) AS 평균금액,
MIN(amount) AS 최소금액,
MAX(amount) AS 최대금액,
SUM(COALESCE(amount, 0)) AS 널을0포함합계
FROM orders;
GROUP BY 실행 순서가 중요한 이유
SQL은 작성 순서와 실행 순서가 다릅니다. 이 차이를 모르면 "왜 WHERE에서 집계함수를 쓸 수 없는가?"나 "왜 SELECT에서 정의한 별칭을 HAVING에서 쓸 수 없는가?" 같은 오류가 발생합니다.
논리적 실행 순서는 다음과 같습니다.
| 순서 | 절 | 역할 |
|---|---|---|
| 1 | FROM | 대상 테이블 결정 |
| 2 | WHERE | 개별 행 필터링 |
| 3 | GROUP BY | 그룹화 |
| 4 | HAVING | 그룹 필터링 |
| 5 | SELECT | 출력 컬럼 선택 |
| 6 | ORDER BY | 정렬 |
| 7 | LIMIT / OFFSET | 페이지네이션 |
WHERE가 GROUP BY보다 먼저 실행되므로, WHERE 절에는 집계 결과가 아직 존재하지 않습니다. 집계 결과에 조건을 걸려면 반드시 HAVING을 사용해야 합니다.
아래 쿼리는 실행 순서를 모두 포함한 예시입니다. status != 'cancelled' 조건이 WHERE에 있어 취소된 주문은 그룹화 전에 제거되고, SUM(amount) > 1000000 조건은 HAVING에서 그룹 집계 후 적용됩니다.
SELECT
category,
COUNT(*) AS 주문건수,
SUM(amount) AS 총매출,
AVG(amount) AS 평균주문금액,
MAX(amount) AS 최대주문금액
FROM orders
WHERE status != 'cancelled'
AND created_at >= '2024-01-01'
GROUP BY category
HAVING SUM(amount) > 1000000
ORDER BY 총매출 DESC
LIMIT 10;
HAVING vs WHERE
WHERE와 HAVING의 역할은 명확히 다릅니다.
- WHERE: 개별 행을 필터링합니다. 집계함수를 사용할 수 없습니다.
- HAVING: 그룹화된 결과를 필터링합니다. 집계함수를 조건으로 쓸 수 있습니다.
성능 관점에서도 차이가 납니다. WHERE로 먼저 행을 줄이면 GROUP BY가 처리해야 할 데이터가 적어지므로, 가능한 조건은 WHERE에 두는 것이 유리합니다.
SELECT
DATE_TRUNC('month', created_at) AS month,
category,
COUNT(*) AS order_count,
SUM(amount) AS revenue
FROM orders
WHERE created_at >= '2024-01-01'
GROUP BY 1, 2
HAVING SUM(amount) >= 500000
ORDER BY 1, 4 DESC;
집계함수(COUNT, SUM, AVG 등)를 WHERE 절에서 사용하면 이 오류가 발생합니다. WHERE는 GROUP BY 이전에 실행되므로 아직 집계 결과가 존재하지 않기 때문입니다.
-- 오류 발생
SELECT user_id, COUNT(*) AS order_count
FROM orders
WHERE COUNT(*) >= 5
GROUP BY user_id;
해결 방법: 집계 결과에 조건을 걸 때는 HAVING을 사용하세요. 개별 행 조건(예: status = 'completed')은 WHERE에, 집계 결과 조건(예: COUNT(*) >= 5)은 HAVING에 두면 됩니다.
SELECT user_id, COUNT(*) AS order_count
FROM orders
WHERE status = 'completed'
GROUP BY user_id
HAVING COUNT(*) >= 5;
실전 분석 쿼리
월별 매출 트렌드, 카테고리별 성과, 상위 구매 고객 조회는 가장 자주 쓰이는 분석 쿼리 패턴입니다. 아래 예시들은 그대로 복사해서 테이블 이름만 바꿔 활용할 수 있습니다.
월별 트렌드는 날짜를 월 단위로 잘라 GROUP BY 기준으로 사용합니다.
SELECT
TO_CHAR(created_at, 'YYYY-MM') AS 월,
COUNT(*) AS 주문건수,
SUM(amount) AS 총매출,
ROUND(AVG(amount), 0) AS 평균주문금액
FROM orders
WHERE status = 'completed'
AND created_at >= NOW() - INTERVAL '12 months'
GROUP BY TO_CHAR(created_at, 'YYYY-MM')
ORDER BY 1;
카테고리별 성과는 구매자 수와 건당 평균 매출을 함께 보면 단순 매출 크기와 고객 단가를 동시에 파악할 수 있습니다.
SELECT
category,
COUNT(*) AS 총주문,
COUNT(DISTINCT user_id) AS 구매자수,
SUM(amount) AS 매출,
ROUND(SUM(amount) / COUNT(*), 0) AS 건당평균매출
FROM orders
WHERE status != 'cancelled'
GROUP BY category
ORDER BY 매출 DESC;
상위 구매 고객 조회는 JOIN 이후에 GROUP BY를 적용하는 패턴입니다. HAVING으로 최소 주문 횟수 조건을 걸어 우량 고객만 추립니다.
SELECT
u.id AS user_id,
u.name AS 고객명,
COUNT(o.id) AS 주문횟수,
SUM(o.amount) AS 총구매금액,
MAX(o.created_at) AS 최근구매일
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.status = 'completed'
GROUP BY u.id, u.name
HAVING COUNT(o.id) >= 3
ORDER BY 총구매금액 DESC
LIMIT 10;
WHERE(그룹핑 전 행 필터)와 HAVING(그룹핑 후 집계값 필터)의 역할 차이를 한 쿼리에서 확인합니다. 위 쿼리를 실행해 "주문 3회 이상인 우량 고객 상위 10명"이 추려지는지 봅니다.
SELECT
u.name AS 고객명,
COUNT(o.id) AS 주문횟수,
SUM(o.amount) AS 총구매금액
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.status = 'completed' -- 행 필터(그룹핑 전)
GROUP BY u.id, u.name
HAVING COUNT(o.id) >= 3 -- 집계 필터(그룹핑 후)
ORDER BY 총구매금액 DESC
LIMIT 10;
고객명 | 주문횟수 | 총구매금액
----------+----------+------------
김우량 | 12 | 3840000
이단골 | 8 | 2210000
...
SELECT u.name, COUNT(o.id) AS 주문횟수, SUM(o.amount) AS 총구매 FROM users u JOIN orders o ON u.id=o.user_id WHERE o.status='completed' GROUP BY u.id, u.name HAVING COUNT(o.id) >= 3 ORDER BY 총구매 DESC LIMIT 10;- 결과의 주문횟수가 모두 3 이상인지 본다 — 3 미만 행이 보이면 HAVING이 아니라 WHERE에 잘못 넣었거나 누락된 것
- WHERE를 빼고 다시 실행해 행 수가 늘면, status 필터가 그룹핑 전에 정상 적용되고 있다는 의미(취소 주문이 섞였던 것)
- HAVING 조건을 WHERE COUNT(o.id) >= 3 으로 옮기면 'aggregate functions are not allowed in WHERE' 에러가 나는지 확인 — 집계값 필터는 반드시 HAVING이어야 한다
- LIMIT 10인데 10행 미만이면 조건을 만족하는 우량 고객 자체가 그만큼뿐이라는 뜻이다
실무에서 경영진이 요청하는 "카테고리별 월 매출, 전월 대비 성장률, 구매 고객 수" 같은 리포트는 거의 대부분 GROUP BY + 집계함수 조합으로 만듭니다.
WHERE vs HAVING 구분을 명확히 알아야 필터 조건을 올바른 위치에 배치할 수 있고, 조건을 WHERE에 먼저 걸면 GROUP BY가 처리할 데이터 양이 줄어 쿼리 성능도 개선됩니다. 수백만 건의 주문 테이블에서 이 차이는 실행 시간 수 초에 영향을 줍니다.
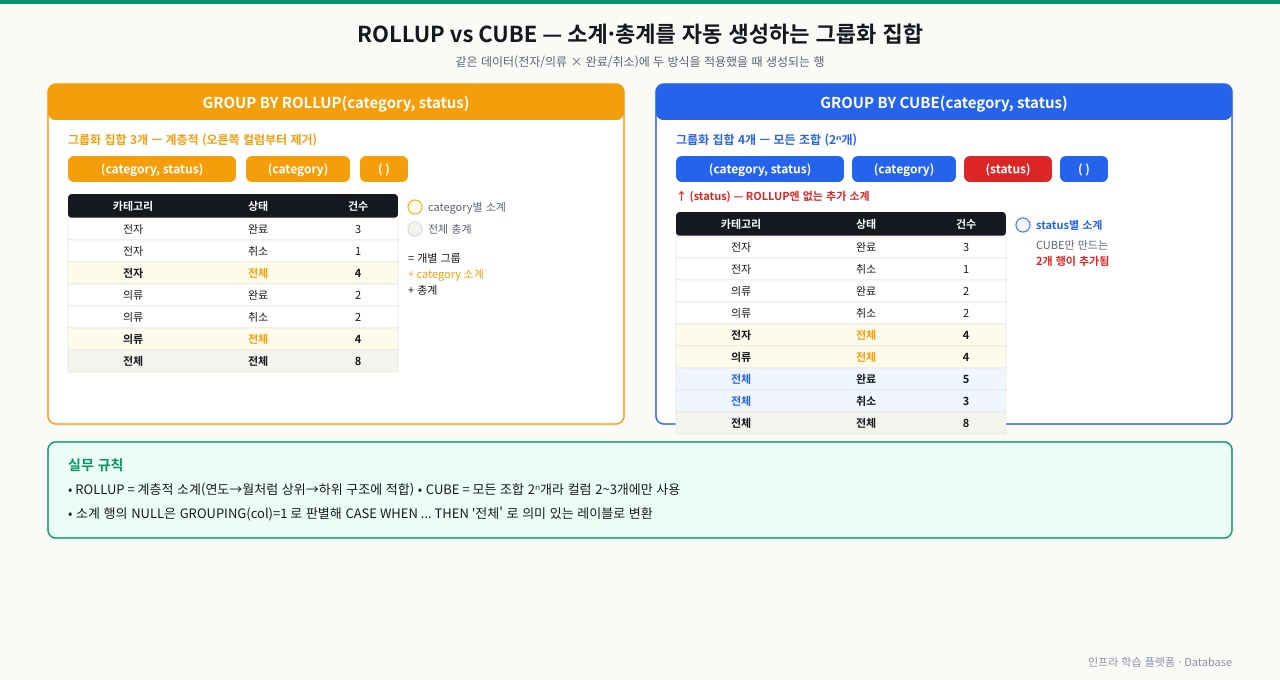
ROLLUP과 CUBE — 소계/합계 자동 생성
지역별-카테고리별 매출 보고서를 만들어야 합니다. 각 지역 소계, 각 카테고리 소계, 전체 합계가 모두 필요합니다. 여러 쿼리를 UNION으로 합치거나 애플리케이션에서 계산하는 방법은 복잡합니다. ROLLUP 하나로 계층적 소계를 자동으로 생성할 수 있습니다.
 확대
확대
ROLLUP — 계층적 소계와 총계
GROUP BY ROLLUP(col1, col2)는 일반 그룹별 집계 외에 col1 단위 소계와 전체 총계를 추가로 생성합니다. 소계 행에서 하위 컬럼은 NULL로 표시되므로 GROUPING() 함수로 소계 행임을 구분할 수 있습니다.
아래 쿼리는 연도-월 계층 구조로 소계를 생성합니다. 결과에서 월이 NULL인 행은 해당 연도의 소계이고, 연도와 월이 모두 NULL인 행이 전체 총계입니다.
SELECT
EXTRACT(YEAR FROM created_at) AS 연도,
EXTRACT(MONTH FROM created_at) AS 월,
SUM(amount) AS 매출
FROM orders
WHERE status = 'completed'
GROUP BY ROLLUP(
EXTRACT(YEAR FROM created_at),
EXTRACT(MONTH FROM created_at)
)
ORDER BY 1 NULLS LAST, 2 NULLS LAST;
GROUPING() 함수를 사용하면 소계 행의 NULL을 "전체"처럼 의미 있는 레이블로 바꿀 수 있습니다.
SELECT
CASE WHEN GROUPING(category) = 1 THEN '전체' ELSE category END AS 카테고리,
CASE WHEN GROUPING(status) = 1 THEN '전체' ELSE status END AS 상태,
COUNT(*) AS 건수,
SUM(amount) AS 금액
FROM orders
GROUP BY ROLLUP(category, status)
ORDER BY 1, 2;
CUBE — 모든 조합의 소계
CUBE(a, b)는 (a, b) 개별 그룹, a별 소계, b별 소계, 전체 총계 — 이렇게 네 가지 조합을 모두 생성합니다. 컬럼이 많아질수록 생성되는 조합이 기하급수적으로 늘어나므로 2~3개 컬럼에만 사용하는 것이 일반적입니다.
SELECT
category,
status,
COUNT(*) AS order_count
FROM orders
GROUP BY CUBE(category, status)
ORDER BY category NULLS LAST, status NULLS LAST;
FILTER — 조건부 집계
FILTER (WHERE ...) 절을 집계함수에 붙이면 한 번의 GROUP BY 스캔으로 여러 조건의 집계를 동시에 계산할 수 있습니다. 상태별로 별도의 서브쿼리를 작성하거나 CASE WHEN으로 분기하는 것보다 가독성이 좋고 성능도 유리합니다.
SELECT
category,
COUNT(*) AS 총주문수,
COUNT(*) FILTER (WHERE status = 'completed') AS 완료수,
COUNT(*) FILTER (WHERE status = 'cancelled') AS 취소수,
COUNT(*) FILTER (WHERE status = 'pending') AS 대기수,
SUM(amount) FILTER (WHERE status = 'completed') AS 완료매출,
ROUND(
100.0 * COUNT(*) FILTER (WHERE status = 'completed') / COUNT(*),
1
) AS 완료율
FROM orders
GROUP BY category
ORDER BY 총주문수 DESC;
복잡한 분석 쿼리 예시
사용자 코호트 분석은 가입 시점별로 그룹을 나누고, 각 코호트의 첫 구매 전환율을 측정하는 패턴입니다. CTE로 코호트와 첫 주문을 각각 계산한 뒤 LEFT JOIN으로 연결하면 전환 여부가 없는 사용자도 포함해 집계할 수 있습니다.
WITH user_cohorts AS (
SELECT
user_id,
DATE_TRUNC('month', created_at) AS cohort_month
FROM users
WHERE created_at >= '2024-01-01'
),
first_orders AS (
SELECT
user_id,
MIN(DATE_TRUNC('month', created_at)) AS first_order_month
FROM orders
WHERE status = 'completed'
GROUP BY user_id
)
SELECT
uc.cohort_month,
COUNT(DISTINCT uc.user_id) AS 가입자수,
COUNT(DISTINCT fo.user_id) AS 구매전환자수,
ROUND(
100.0 * COUNT(DISTINCT fo.user_id) / COUNT(DISTINCT uc.user_id),
1
) AS 전환율
FROM user_cohorts uc
LEFT JOIN first_orders fo
ON uc.user_id = fo.user_id
AND uc.cohort_month = fo.first_order_month
GROUP BY uc.cohort_month
ORDER BY uc.cohort_month;
동작 원리 — GROUP BY가 행을 그룹으로 접는 과정
GROUP BY 한 줄이 그룹을 만드는 5단계 — 행이 버킷으로 접힌다
SELECT category, name, SUM(amount) FROM orders GROUP BY category 를 실행하면 "name은 GROUP BY에 없다"는 에러가 나는데, 정작 SUM(amount)는 아무 문제가 없습니다. 왜 어떤 컬럼은 되고 어떤 컬럼은 안 될까요. GROUP BY가 여러 행을 하나의 그룹으로 "접는" 과정을 단계로 따라가 보면, 이 에러도, HAVING을 WHERE와 따로 두는 이유도, NULL이 어떻게 묶이는지도 한 번에 설명됩니다.
[orders 테이블의 행들]
│
① FROM·WHERE: 대상 행 확보 (status·기간 등으로 행 필터 — 아직 그룹 아님)
│
② 그룹 키 계산 → 버킷 분할 (GROUP BY 컬럼 값이 같은 행끼리 한 버킷)
│ category='전자' → [행, 행, 행]
│ category='도서' → [행, 행]
│ category=NULL → [행, 행] (NULL끼리도 하나의 버킷)
│
③ 버킷마다 집계함수로 fold (COUNT·SUM·AVG를 버킷 안 행들에 적용)
│ [행, 행, 행] → COUNT=3, SUM=1200
│
④ HAVING: 집계 결과로 버킷 필터 (SUM(amount) > 1000000 같은 그룹 조건)
│
⑤ 버킷당 1행 출력 (그룹 키 + 집계값 — 개별 행은 사라짐)
▼
[category별로 한 행씩 남은 결과]
각 단계가 하는 일과, 그 단계라서 생기는 규칙:
| 단계 | 하는 일 | 그래서 생기는 규칙·증상 |
|---|---|---|
| ① FROM·WHERE | 그룹으로 묶기 전에 개별 행을 먼저 거른다 | 이 단계엔 아직 집계값이 없다 → WHERE에 COUNT(*) 같은 집계 조건을 쓰면 aggregate functions are not allowed in WHERE |
| ② 버킷 분할 | GROUP BY에 적은 컬럼 값이 같은 행을 한 버킷에 모은다 | 버킷을 가르는 그 컬럼만 그룹당 값이 하나로 확정된다. NULL 값끼리도 한 버킷으로 묶인다 |
| ③ 집계 fold | 버킷 안 여러 행을 집계함수가 값 하나로 접는다. COUNT(*)는 행 수, COUNT(col)·SUM·AVG는 NULL을 뺀다 | SELECT에 올 수 있는 건 '그룹 키' 아니면 '집계로 접은 값'뿐. GROUP BY에 없는 raw 컬럼(name 등)은 버킷 안 값이 여러 개라 하나로 못 정해 에러 |
| ④ HAVING | 집계가 끝난 버킷을 집계 결과로 거른다 | 집계값 조건은 HAVING(HAVING SUM(amount) > 1000000), 개별 행 조건은 ①의 WHERE |
| ⑤ 1행 출력 | 버킷 하나가 결과 한 행이 된다 | 원본 행 수가 그룹 수로 줄어든다(윈도우 함수와 정반대). NULL 버킷도 한 행으로 출력 |
즉 "GROUP BY에 없는 컬럼을 SELECT 못 한다"는 제약은 외우는 문법이 아니라 ③의 결과입니다 — 버킷 안엔 그 컬럼 값이 여러 개인데 출력은 버킷당 한 줄이라, DB는 "그 중 무엇을 보여줄지" 정할 수 없습니다. 그 컬럼도 함께 보고 싶으면 GROUP BY에 넣어(버킷을 더 잘게 쪼개) 값을 하나로 확정하거나, MAX()·STRING_AGG() 같은 집계로 접으면 됩니다. WHERE와 HAVING이 헷갈릴 때도 이 순서로 돌아오면 됩니다 — 행을 줄이는 조건은 ①(WHERE), 접힌 값을 거르는 조건은 ④(HAVING). 이 버킷을 DB가 실제로 해시로 만드는지 정렬로 만드는지는 이 모듈 끝의 심화에서 다룹니다.
심화 — 집계는 정렬과 해시 위에서 돌아간다
심화: GROUP BY의 실행 전략 — HashAggregate vs GroupAggregate와 work_mem
WHERE와 HAVING의 위치를 익혔다면 다음 질문은 이것입니다 — GROUP BY는 실제로 그룹을 어떻게 묶을까요. 옵티마이저는 보통 두 전략 중 하나를 고르고, 어느 쪽이 걸리느냐에 따라 같은 쿼리의 속도가 크게 갈립니다.
- HashAggregate: 그룹 키로 메모리에 해시 테이블을 만들어 한 번의 스캔으로 집계합니다. 정렬이 필요 없어 대개 빠르지만, 해시 테이블이
work_mem을 넘으면 디스크 임시 파일로 스필(spill)합니다. - GroupAggregate: 입력이 그룹 키 순으로 정렬돼 있을 때, 이웃한 같은 키를 순서대로 접어 집계합니다. 그룹 키에 정렬된 인덱스가 있으면 정렬 비용 없이 바로 흘려보낼 수 있고 메모리도 거의 쓰지 않습니다.
EXPLAIN에서 HashAggregate가 보이면 그룹 카디널리티(고유 그룹 수)와 work_mem을 함께 의심하고, GroupAggregate 위에 Sort가 얹혀 있으면 그 정렬을 인덱스로 없앨 수 있는지 봅니다. 핵심은 집계도 스캔·정렬·메모리라는 물리 자원 위에서 돌아간다는 것입니다 — WHERE로 대상을 먼저 줄이는 것이 성능에 유리한 이유도 결국 해시 테이블과 정렬 입력이 작아지기 때문입니다.
EXPLAIN (ANALYZE, BUFFERS)
SELECT category, SUM(amount)
FROM orders
GROUP BY category;
HashAggregate (cost=... rows=8 ...) (actual time=...)
Group Key: category
Batches: 5 Memory Usage: 4096kB Disk Usage: 24960kB ← 스필 발생
-> Seq Scan on orders ...
상황: 카테고리·월별 매출 집계 대시보드 쿼리가 초기에는 수십 ms였는데, 주문이 쌓이자 갑자기 몇 초로 뛰었습니다. 쿼리 문장도 인덱스도 바꾸지 않았는데 특정 시점부터 계단식으로 느려집니다.
원인: 그룹 집계가 HashAggregate로 실행되는데, 집계 대상 행이 늘면서 그룹 해시 테이블이 세션의 work_mem을 초과했습니다. PostgreSQL은 넘치는 만큼을 디스크 임시 파일로 스필하고, 이때부터 메모리 내 집계가 디스크 왕복이 섞인 집계로 바뀌어 급격히 느려집니다. 데이터가 임계선을 넘는 순간 튀는 계단식 저하가 이 현상의 특징입니다.
진단: EXPLAIN (ANALYZE, BUFFERS)로 실행하면 HashAggregate 노드에 Batches가 2 이상이고 Disk Usage가 찍힙니다(스필 확정). 서버에 log_temp_files = 0을 켜면 임시 파일이 로그에 남고, pg_stat_statements의 temp_blks_written이 그 쿼리에서 커집니다.
해결: 먼저 WHERE로 집계 대상을 좁혀(예: 최근 N개월) 해시 테이블을 작게 만듭니다. 리포트성 쿼리라면 세션에서 SET work_mem = '128MB'처럼 한시적으로 올려 스필을 없앨 수 있습니다(전역 상향은 동시성 곱만큼 메모리를 먹으니 주의). 반복되는 집계는 그룹 키에 정렬된 인덱스로 GroupAggregate를 유도하거나, 사전 집계(롤업·요약 테이블·머티리얼라이즈드 뷰)로 그룹 카디널리티 자체를 낮춥니다(쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화).
명령어·구문 빠른 참조
이 모듈에서 다룬 집계·GROUP BY 관련 SQL 구문을 실전 조합과 함께 모았습니다. "예" 열을 그대로 응용해도 됩니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
COUNT(*) / COUNT(col) | 전체 행 수 / NULL 제외 행 수 | 5행 중 2행이 NULL이면 COUNT(*)=5, COUNT(amount)=3 |
COUNT(DISTINCT col) | 고유값 개수 | COUNT(DISTINCT user_id) (고유 구매자 수) |
SUM/AVG/MIN/MAX | 합계·평균·최소·최대(NULL 무시) | SUM(amount), ROUND(AVG(amount), 0) |
COALESCE(col, 0) | NULL을 0으로 바꿔 집계 | SUM(COALESCE(amount, 0)) |
GROUP BY | 지정 컬럼 단위로 묶기 | GROUP BY category / GROUP BY 1, 2(위치 참조) |
HAVING | 집계 결과로 그룹 필터 | HAVING SUM(amount) > 1000000 |
WHERE | 그룹핑 전 개별 행 필터 | WHERE status != 'cancelled'(집계함수 사용 불가) |
DATE_TRUNC / TO_CHAR / EXTRACT | 날짜를 집계 단위로 자르기 | DATE_TRUNC('month', created_at), TO_CHAR(created_at, 'YYYY-MM') |
GROUP BY ROLLUP(...) | 소계+총계 자동 생성 | GROUP BY ROLLUP(category, status) |
GROUP BY CUBE(...) | 모든 조합 소계 생성 | GROUP BY CUBE(category, status) |
GROUPING(col) | 소계 행(NULL) 구분·라벨링 | CASE WHEN GROUPING(category)=1 THEN '전체' ELSE category END |
FILTER (WHERE ...) | 조건부 집계를 한 스캔에 | COUNT(*) FILTER (WHERE status='completed') |
EXPLAIN (ANALYZE, BUFFERS) | 집계 실행계획·스필 확인 | HashAggregate의 Batches≥2·Disk Usage 확인 |
SET work_mem | 해시 집계 디스크 스필 방지 | SET work_mem = '128MB'(리포트 세션 한시 상향) |
관련 모듈로 더 깊이:
- INNER, LEFT, RIGHT, FULL JOIN의 최적화 실행 조건 — 집계 전에 여러 테이블을 올바르게 연결하는 JOIN 동작 원리
- 서브쿼리와 CTE(WITH 문)를 활용한 쿼리 구조화 — 코호트 분석처럼 단계적 집계를 CTE로 구조화하는 법
- RANK, ROW_NUMBER, LAG, LEAD 윈도우 함수 실무 — GROUP BY로 행을 합쳐버리지 않고 순위·누적을 계산하는 법
다음 모듈에서는 NULL 값이 만들어내는 함정과 COALESCE, NULLIF로 안전하게 처리하는 방법을 다룹니다.