운영 데이터 보정 작업에서 수백만 건을 한 번에 처리해야 하는 순간이 옵니다. 단건 루프를 그대로 돌리면 DB I/O와 락이 치솟아 서비스 쿼리까지 느려집니다. 벌크 처리 패턴을 알면 빠르게 처리하면서도 장애 위험을 줄일 수 있습니다.
벌크 연산은 단순히 '많이 넣는 방법'이 아닙니다. 트랜잭션 범위, WAL 쓰기, 잠금 전략을 함께 설계해야 운영 중인 서비스에 영향을 주지 않으면서 대량 데이터를 처리할 수 있습니다.
- 1단건 INSERT와 벌크 INSERT의 커밋 오버헤드와 WAL 비용 차이를 설명할 수 있다
- 2Multi-row INSERT, PostgreSQL COPY, MySQL LOAD DATA INFILE로 대량 적재를 구현할 수 있다
- 3SQLAlchemy bulk_insert_mappings, Prisma createMany, JPA saveAll로 ORM 벌크 연산을 작성할 수 있다
- 4LIMIT과 ORDER BY 루프 패턴으로 대량 UPDATE/DELETE를 안전하게 배치 처리할 수 있다
- 5ON CONFLICT DO UPDATE와 INSERT ON DUPLICATE KEY UPDATE로 UPSERT를 구현할 수 있다
- 6벌크 연산 중 테이블 락을 방지하는 전략을 적용할 수 있다
대량 데이터 처리 패턴 — Bulk Insert·Update·Delete
신입 개발자가 처음으로 대용량 데이터 마이그레이션을 맡았습니다. 100만 건의 레거시 CSV 데이터를 새 테이블로 옮기는 작업이었습니다. Python 스크립트를 작성했고, for 루프 안에서 한 건씩 INSERT 쿼리를 날렸습니다. 로컬에서 1,000건 테스트할 때는 문제없었습니다. 그런데 운영 환경에서 스크립트를 돌리자 2시간이 지나도 10%밖에 처리되지 않았고, DB 서버 I/O가 치솟으며 함께 뜨던 서비스 쿼리들이 느려지기 시작했습니다. 결국 스크립트를 강제 종료했지만 절반쯤 올라간 데이터는 정합성을 알 수 없는 상태가 됐습니다. 단건 루프가 왜 이런 결과를 낳는지, 그리고 어떻게 해야 했는지를 이 모듈에서 배웁니다.
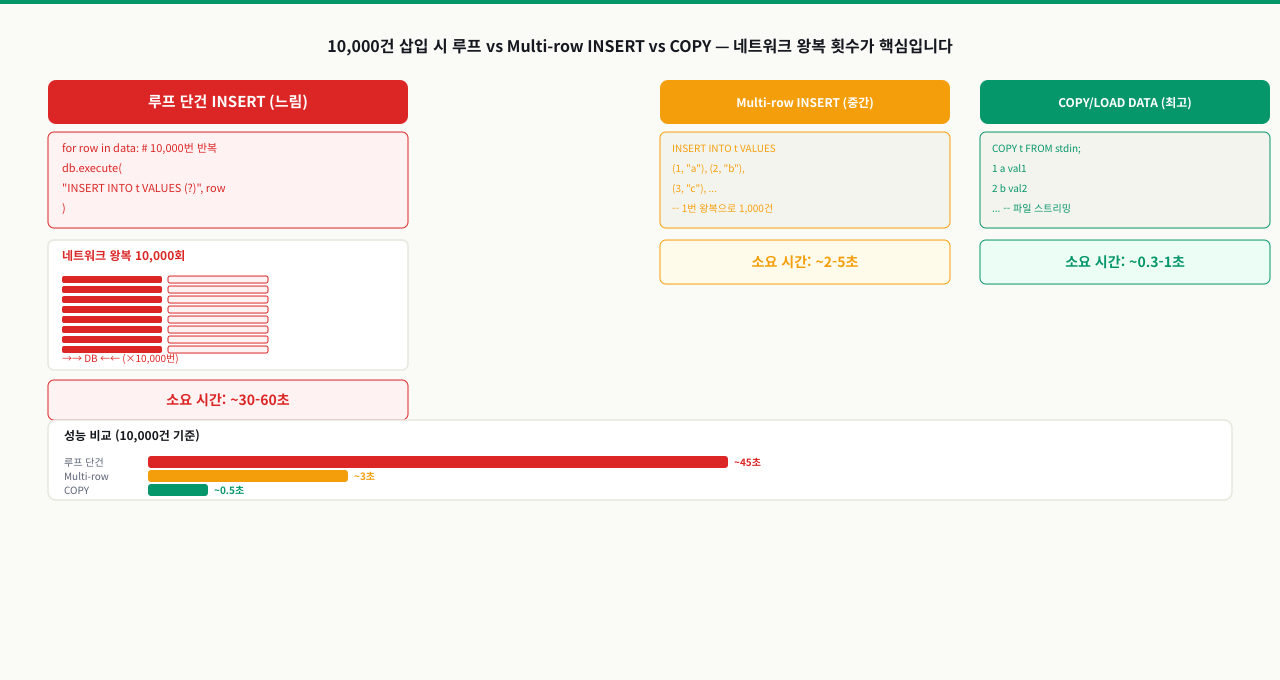
단건 INSERT vs 벌크 INSERT — 왜 이렇게 차이가 나는가
단건 INSERT 루프가 느린 이유는 SQL 문법의 문제가 아닙니다. 매 INSERT마다 발생하는 시스템 수준의 오버헤드가 누적되기 때문입니다. 100만 건을 넣는다면 이 오버헤드가 100만 번 반복됩니다.
 확대
확대
단건 INSERT 1회당 발생하는 비용:
1. 네트워크 왕복 (애플리케이션 → DB → 애플리케이션)
2. SQL 파싱 및 실행 계획 수립
3. WAL(Write-Ahead Log) 레코드 기록 + fsync
4. 트랜잭션 커밋 (autocommit 환경에서 매 건마다 커밋)
5. 버퍼 풀 업데이트
벌크 INSERT는 이 비용을 N건에 대해 단 1회로 압축합니다. 아래 수치는 실제 테스트 환경 기준 참고치입니다.
| 방식 | 10만 건 소요 시간 | 비율 |
|---|---|---|
| 단건 INSERT 루프 (autocommit) | 120~180초 | 기준 |
| 단건 INSERT (하나의 트랜잭션) | 15~25초 | 8~10배 빠름 |
| Multi-row INSERT | 3~8초 | 25~50배 빠름 |
| COPY FROM (PostgreSQL) | 0.5~2초 | 80~200배 빠름 |
| LOAD DATA INFILE (MySQL) | 0.5~2초 | 80~200배 빠름 |
WAL 비용: PostgreSQL은 모든 변경을 WAL에 순서대로 기록합니다. 단건 커밋은 매 건마다 WAL을 디스크에 flush하는데, 이 fsync 호출 자체가 수ms 단위로 소요됩니다. 벌크 연산은 flush 횟수를 줄여 전체 I/O를 대폭 감소시킵니다.
-- 나쁜 예: autocommit 단건 루프 (Python pseudocode)
for row in data:
cursor.execute("INSERT INTO products (name, price) VALUES (%s, %s)", row)
# 매 건마다 커밋 발생 → 100만 번 fsync
-- 개선 1: 하나의 트랜잭션으로 묶기 (바로 효과)
conn.begin()
for row in data:
cursor.execute("INSERT INTO products (name, price) VALUES (%s, %s)", row)
conn.commit() # 딱 1번 커밋
실행 완료 또는 조회 결과가 표시됩니다.
- 처리 건수—INSERT/COPY 후 COUNT 결과가 입력 파일 또는 배치 크기와 일치하는지 확인합니다.
- 실행 시간—단건 루프보다 왕복과 커밋 횟수가 줄어든 효과를 봅니다.
- 잠금 영향—대량 작업 중 서비스 쿼리가 막히지 않도록 배치 크기를 조정합니다.
실습: Multi-row INSERT, COPY FROM, LOAD DATA INFILE
같은 1만 건을 단건 INSERT 루프와 Multi-row INSERT로 각각 넣어 시간을 비교합니다. \timing on(psql)으로 실행 시간을 켜고, 왜 벌크가 수십 배 빠른지 숫자로 확인합니다.
\timing on
-- (느림) 단건 INSERT 1만 회 — 매번 왕복 + 커밋 오버헤드
DO $$ BEGIN
FOR i IN 1..10000 LOOP
INSERT INTO products (name, price, stock) VALUES ('p'||i, 1000, 10);
END LOOP;
END $$;
-- (빠름) Multi-row INSERT — 한 문장에 여러 행
INSERT INTO products (name, price, stock)
VALUES
('상품A', 10000, 100),
('상품B', 20000, 50),
('상품C', 15000, 200),
('상품D', 8000, 300);
-- 실무: 1,000~5,000건 단위로 나눠 실행(메모리/오버헤드 균형점)
-- 단건 루프
Time: 4821.337 ms (00:04.821)
-- Multi-row (동일 건수 기준 환산)
Time: 142.880 ms
\timing on배치 크기 선택 기준: 단건보다 최소 10배 이상 빨라지는 지점이 1,000건 근처인 경우가 많습니다. 단, 행 크기(컬럼 수, TEXT 컬럼 등)에 따라 달라지므로 실제 데이터로 측정해야 합니다.
- 두 Time 값의 비율을 본다 — 단건 ms ÷ 벌크 ms 가 개선 배수다. 차이가 작으면 단건도 한 트랜잭션으로 묶인 것(BEGIN..COMMIT 범위 확인)
- 단건 루프가 유독 느리면 각 INSERT가 개별 자동커밋(fsync)된 것 — 벌크는 왕복·커밋 횟수를 줄여 빨라진다는 게 핵심
- Multi-row 한 문장에 행을 무한정 늘리면 어느 지점부터 다시 느려진다(파싱·메모리). 1,000건 근처에서 측정해 균형점을 찾는다
- 더 큰 적재라면 COPY FROM(아래)이 Multi-row INSERT보다 또 한 단계 빠른지 같은 방식으로 비교한다
PostgreSQL COPY FROM — 가장 빠른 로딩
# CSV 파일 준비 (헤더 없이)
# products.csv:
# 상품A,10000,100
# 상품B,20000,50
# psql에서 COPY 실행
psql -U postgres -d mydb -c "\COPY products (name, price, stock) FROM '/tmp/products.csv' CSV;"
-- SQL 콘솔에서 직접 실행 (슈퍼유저 권한)
COPY products (name, price, stock)
FROM '/tmp/products.csv'
WITH (FORMAT CSV, HEADER FALSE, DELIMITER ',');
-- 결과 확인
SELECT COUNT(*) FROM products;
-- 클라이언트 측 파일 (서버 파일 접근 불가 환경)
-- \COPY는 psql 메타커맨드로 클라이언트 파일을 읽어 서버로 전송
\COPY products (name, price, stock) FROM 'products.csv' CSV;
COPY가 INSERT보다 빠른 이유: WAL을 minimal 모드로 기록하고, 제약 체크를 배치 단위로 수행하며, 파싱 오버헤드가 없습니다. 단, FK 제약이 있으면 로딩 후 검사가 발생하므로 FK를 임시 비활성화하면 더 빨라집니다(단, 정합성 보장 책임은 직접).
MySQL LOAD DATA INFILE
-- MySQL: CSV 파일 직접 로딩
LOAD DATA INFILE '/var/lib/mysql-files/products.csv'
INTO TABLE products
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(name, price, stock);
-- 로컬 클라이언트 파일 사용 (--local-infile 옵션 필요)
LOAD DATA LOCAL INFILE '/tmp/products.csv'
INTO TABLE products
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(name, price, stock);
-- MySQL 서버에서 local_infile 활성화 확인
SHOW VARIABLES LIKE 'local_infile';
-- OFF이면: SET GLOBAL local_infile = ON;
ORM 벌크 연산 — 편의성과 성능의 균형
ORM을 쓰면 개별 save() 호출이 단건 INSERT로 변환됩니다. 1,000건을 orm.save()로 루프 돌리면 1,000번 쿼리가 날아갑니다. ORM마다 벌크 연산 API가 따로 있습니다.
 확대
확대
SQLAlchemy (Python) — bulk_insert_mappings
from sqlalchemy.orm import Session
from sqlalchemy import text
# 나쁜 예: 단건 add 루프
with Session(engine) as session:
for row in data_list:
product = Product(name=row['name'], price=row['price'])
session.add(product) # 단건 INSERT 예약
session.commit() # 1,000건이면 1,000번 INSERT
# 좋은 예: bulk_insert_mappings
with Session(engine) as session:
session.bulk_insert_mappings(
Product,
[{'name': row['name'], 'price': row['price']} for row in data_list]
)
session.commit()
# 내부적으로 executemany → 훨씬 적은 왕복
# SQLAlchemy 2.0 이후 권장 방식
with Session(engine) as session:
session.execute(
insert(Product),
[{'name': row['name'], 'price': row['price']} for row in data_list]
)
session.commit()
Prisma (Node.js/TypeScript) — createMany
// 나쁜 예: create 루프
for (const row of dataList) {
await prisma.product.create({ data: row });
// 1,000건이면 1,000번 쿼리
}
// 좋은 예: createMany
await prisma.product.createMany({
data: dataList,
skipDuplicates: true, // 중복 키 무시 (선택)
});
// 주의: createMany는 nested create (relation 생성)를 지원하지 않음
// 관계 데이터가 있으면 createManyAndReturn 또는 트랜잭션 사용
JPA/Spring Boot (Java) — saveAll과 배치 설정
// application.properties — 배치 INSERT 활성화 필수
spring.jpa.properties.hibernate.jdbc.batch_size=1000
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
// Repository 사용
@Service
public class ProductService {
@Transactional
public void bulkInsert(List<Product> products) {
// saveAll은 batch_size 설정이 있어야 실제로 배치 동작
productRepository.saveAll(products);
// 설정 없으면 내부적으로 단건 루프와 동일
}
}
// 더 빠른 방법: JdbcTemplate batchUpdate
@Autowired
JdbcTemplate jdbcTemplate;
public void bulkInsertWithJdbc(List<Product> products) {
jdbcTemplate.batchUpdate(
"INSERT INTO products (name, price, stock) VALUES (?, ?, ?)",
products,
1000, // 배치 크기
(ps, product) -> {
ps.setString(1, product.getName());
ps.setInt(2, product.getPrice());
ps.setInt(3, product.getStock());
}
);
}
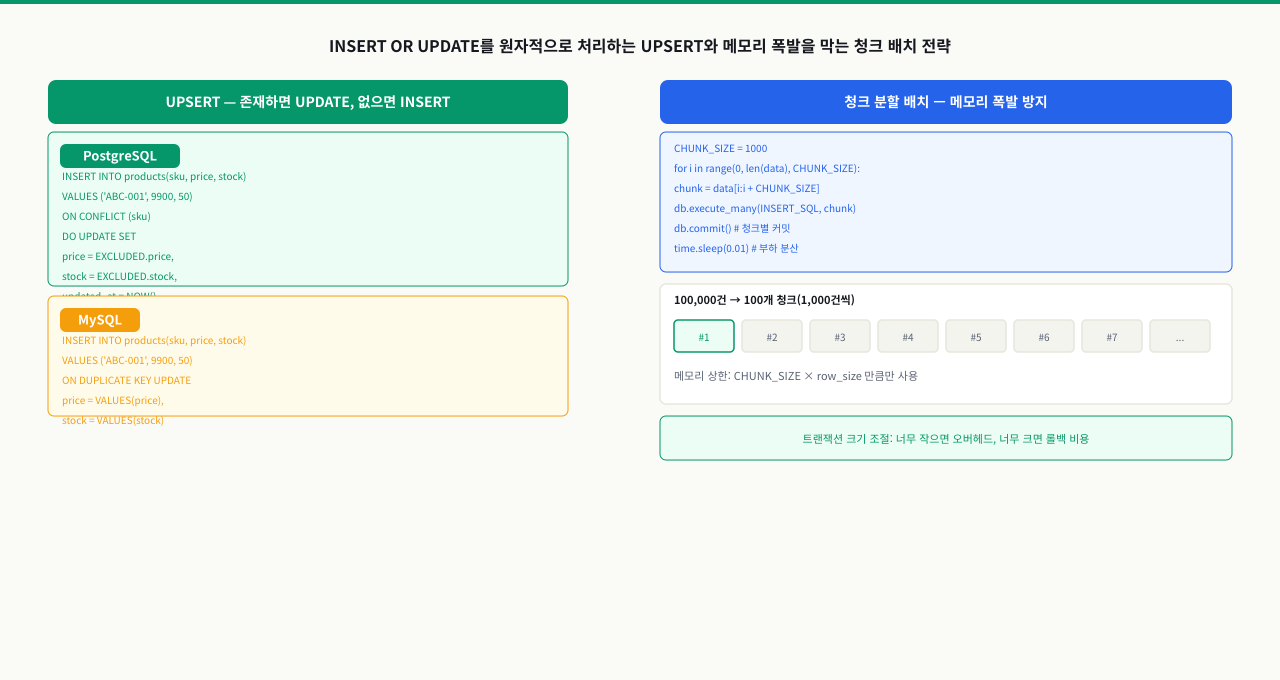
대량 UPDATE 한 배치가 커밋되기까지 — 배치를 키울수록 커지는 5가지 비용
"한 번에 다 UPDATE하면 되지, 왜 굳이 나눠서?"라는 의문이 듭니다. 답은 배치 하나가 커밋되기까지 거치는 관문들에 있습니다. 대량 변경은 대상 행을 잠그고, 변경하고, 제약을 검사하고, WAL에 기록한 뒤 커밋하는데 — 배치를 키울수록 이 관문마다 치르는 비용(락 유지 시간·WAL 양·롤백 비용)이 함께 커집니다. 이 흐름을 알면 청크 분할이 왜 '너무 크지도 작지도 않은' 크기를 노리는지 이해할 수 있습니다.
[한 배치] UPDATE products SET ... WHERE ... (예: 100만 행을 한 문장으로)
│
① 대상 행 수집·잠금 → 조건에 맞는 행을 찾아 잠금(lock) 획득
│ 배치가 클수록 더 많은 행을 동시에 잠금 = 다른 쿼리 대기
│
② 변경(MVCC) → 각 행을 고쳐쓰지 않고 새 버전을 만들고 옛 버전은
│ 죽은 튜플로 남김 (인덱스 컬럼이면 인덱스 엔트리도 추가)
│
③ 제약·인덱스 검사 → NOT NULL·UNIQUE·FK·CHECK 확인, 인덱스마다 엔트리 갱신
│
④ WAL 기록 → 모든 변경을 로그에 append → 배치가 클수록 WAL 폭증
│
⑤ COMMIT → 여기서 한 번에 확정·fsync하고 잠금 해제
│ (행별 커밋이면 ④⑤가 행마다 반복 = fsync 폭증)
▼
[결과] 커밋 단위로 한꺼번에 반영 — 실패하면 배치 전체 롤백(되돌릴 양도 배치 크기만큼)
각 단계가 하는 일과, 배치를 키울 때 커지는 비용:
| 단계 | 하는 일 | 배치를 키우면 |
|---|---|---|
| ① 수집·잠금 | 대상 행에 잠금을 걸고 유지 | 락 범위·유지 시간 늘어남 → 서비스 쿼리 대기·데드락 위험 |
| ② 변경(MVCC) | 새 행 버전 생성, 옛 버전은 죽은 튜플로 | 죽은 튜플 폭증 → 커밋 후 테이블 부풀기(bloat) |
| ③ 제약·인덱스 | 제약 검사 + 인덱스마다 엔트리 갱신 | 인덱스가 많을수록 갱신 비용 증가 |
| ④ WAL 기록 | 변경 전부를 WAL에 append | WAL 폭증 → 디스크 압박·복제 지연 |
| ⑤ 커밋 | 배치 단위 fsync + 잠금 해제 | 롤백 비용이 배치 크기만큼 커짐. 반대로 행별 커밋은 fsync가 N번 반복돼 느림 |
그래서 성능의 두 극단이 모두 나쁩니다 — 행별 커밋은 ④·⑤의 fsync를 행마다 반복해 느리고(단건 루프가 수십 배 느린 이유), 단일 초대형 배치는 ①의 락과 ④의 WAL, ⑤의 롤백 비용을 한꺼번에 키웁니다. 최적은 그 사이의 **청크(보통 1천~1만 건)**입니다 — fsync는 배치로 묶어 줄이고, 락·WAL·롤백은 청크 경계에서 끊어 짧게 유지합니다. 바로 다음 절의 LIMIT + ORDER BY 루프가 이 청크 경계를 만드는 구체적 방법이고, 배치가 끝난 뒤 ②의 죽은 튜플을 회수하는 VACUUM이 왜 필요한지도 이 흐름에서 나옵니다.
실습: 대량 UPDATE/DELETE — LIMIT + ORDER BY 루프 패턴
운영 중인 테이블에서 단일 UPDATE로 수백만 건을 한 번에 처리하면 그 시간 동안 해당 행에 잠금이 걸립니다. 서비스 쿼리가 같은 행을 건드리면 대기하게 됩니다. 청크 단위로 나눠서 각각 커밋하면 잠금 범위를 최소화할 수 있습니다.
-- PostgreSQL: 청크 분할 UPDATE (1만 건씩 처리)
DO $$
DECLARE
updated_count INT;
BEGIN
LOOP
UPDATE products
SET updated_at = NOW()
WHERE id IN (
SELECT id FROM products
WHERE updated_at < '2024-01-01'
ORDER BY id
LIMIT 10000
);
GET DIAGNOSTICS updated_count = ROW_COUNT;
EXIT WHEN updated_count = 0; -- 더 이상 업데이트할 행이 없으면 종료
-- 선택: 잠시 대기해 다른 쿼리에 CPU/I/O 양보
PERFORM pg_sleep(0.1);
END LOOP;
END $$;
-- MySQL: 청크 분할 UPDATE
SET @batch_size = 10000;
SET @last_id = 0;
REPEAT
UPDATE products
SET updated_at = NOW()
WHERE id > @last_id
AND updated_at < '2024-01-01'
ORDER BY id
LIMIT 10000;
SET @affected = ROW_COUNT();
SELECT MAX(id) INTO @last_id
FROM (
SELECT id FROM products
WHERE updated_at >= NOW() - INTERVAL 1 SECOND
ORDER BY id DESC
LIMIT 10000
) AS sub;
UNTIL @affected = 0
END REPEAT;
# Python에서 청크 분할 DELETE (대량 삭제 패턴)
import time
import psycopg2
conn = psycopg2.connect(dsn)
cursor = conn.cursor()
batch_size = 10000
deleted_total = 0
while True:
cursor.execute("""
DELETE FROM logs
WHERE id IN (
SELECT id FROM logs
WHERE created_at < NOW() - INTERVAL '90 days'
ORDER BY id
LIMIT %s
)
""", (batch_size,))
deleted = cursor.rowcount
conn.commit()
deleted_total += deleted
print(f"삭제 완료: {deleted_total}건")
if deleted < batch_size:
break # 마지막 배치
time.sleep(0.05) # 50ms 대기로 I/O 분산
print(f"전체 삭제 완료: {deleted_total}건")
ORDER BY + LIMIT 조합의 중요성: LIMIT만 쓰면 DB가 매 배치마다 같은 행을 반복해서 선택할 수 있습니다. ORDER BY id를 함께 쓰면 이미 처리된 범위를 건너뜁니다. id 기반 범위 쿼리(WHERE id > @last_id)로 변환하면 인덱스를 효율적으로 사용할 수 있습니다.
UPSERT 패턴 — 존재하면 UPDATE, 없으면 INSERT
애플리케이션에서 SELECT 후 INSERT or UPDATE를 결정하는 패턴은 동시 요청이 생기면 경쟁 조건이 발생합니다. 두 요청이 동시에 SELECT를 실행하면 둘 다 "행이 없다"고 판단하여 INSERT를 시도하고, 두 번째 INSERT가 중복 키 에러를 냅니다. UPSERT는 이를 DB 레벨에서 원자적으로 처리합니다.
 확대
확대
실무 사용 사례:
- 일별/시간별 통계 집계 테이블 (
UPDATE count = count + 1, 없으면 INSERT) - 외부 시스템 데이터 동기화 (ID 기준으로 있으면 업데이트, 없으면 삽입)
- 사용자 설정/프로필 저장 (처음이면 생성, 이후엔 업데이트)
-- PostgreSQL: ON CONFLICT DO UPDATE
-- conflict_target: 중복을 판단할 컬럼 (UNIQUE 제약이나 PK여야 함)
INSERT INTO daily_stats (date, product_id, view_count)
VALUES ('2024-01-15', 42, 1)
ON CONFLICT (date, product_id)
DO UPDATE SET
view_count = daily_stats.view_count + EXCLUDED.view_count,
updated_at = NOW();
-- EXCLUDED: INSERT하려고 했던 값 (충돌로 무시된 행)
-- daily_stats.view_count: 현재 테이블에 있는 값
-- 충돌 시 아무것도 하지 않기 (중복 무시)
INSERT INTO products (id, name, price)
VALUES (1, '상품A', 10000)
ON CONFLICT (id) DO NOTHING;
-- 벌크 UPSERT: 여러 행 한 번에
INSERT INTO daily_stats (date, product_id, view_count)
VALUES
('2024-01-15', 42, 10),
('2024-01-15', 43, 5),
('2024-01-15', 44, 20)
ON CONFLICT (date, product_id)
DO UPDATE SET
view_count = daily_stats.view_count + EXCLUDED.view_count;
-- MySQL: INSERT ... ON DUPLICATE KEY UPDATE
INSERT INTO daily_stats (date, product_id, view_count)
VALUES ('2024-01-15', 42, 1)
ON DUPLICATE KEY UPDATE
view_count = view_count + VALUES(view_count),
updated_at = NOW();
-- MySQL 8.0.20 이후: VALUES() 대신 별칭 사용 (권장)
INSERT INTO daily_stats (date, product_id, view_count) AS new_row
VALUES ('2024-01-15', 42, 1)
ON DUPLICATE KEY UPDATE
view_count = view_count + new_row.view_count,
updated_at = NOW();
-- 벌크 UPSERT
INSERT INTO daily_stats (date, product_id, view_count) AS new_row
VALUES
('2024-01-15', 42, 10),
('2024-01-15', 43, 5),
('2024-01-15', 44, 20)
ON DUPLICATE KEY UPDATE
view_count = view_count + new_row.view_count;
주의: ON DUPLICATE KEY UPDATE는 UNIQUE 제약이 걸린 컬럼이 2개 이상일 때 어느 것과 충돌했는지 예측이 어렵습니다. 가능하면 단일 UNIQUE 컬럼 또는 복합 UNIQUE 인덱스를 명확히 지정하세요.
실습: 벌크 연산 중 테이블 락 방지 전략
대용량 INSERT/UPDATE는 테이블 레벨 또는 행 레벨 잠금을 오래 유지합니다. 서비스 중인 테이블이라면 다음 전략을 조합합니다.
운영 데이터에 적용하면 되돌리기 어려운 변경입니다. 실행 전 대상 테이블, WHERE 조건, 백업 또는 롤백 경로를 반드시 확인하세요.
-- 전략 1: 스테이징 테이블을 거쳐 교체
-- 직접 운영 테이블에 INSERT하는 대신:
-- (1) 임시 테이블에 벌크 INSERT (서비스에 영향 없음)
CREATE TABLE products_staging (LIKE products INCLUDING ALL);
COPY products_staging (name, price, stock)
FROM '/tmp/new_products.csv' CSV;
-- (2) 검증 후 운영 테이블에 병합
BEGIN;
INSERT INTO products SELECT * FROM products_staging
ON CONFLICT (id) DO UPDATE
SET name = EXCLUDED.name,
price = EXCLUDED.price;
COMMIT;
DROP TABLE products_staging;
-- 전략 2: 인덱스 비활성화 후 COPY, 재활성화 (PostgreSQL)
-- 대량 초기 로딩 시에만 적합 (운영 중 비활성화는 위험)
ALTER INDEX idx_products_name RENAME TO idx_products_name_disabled;
-- ... COPY 실행 ...
ALTER INDEX idx_products_name_disabled RENAME TO idx_products_name;
-- 더 안전한 방법: 인덱스 삭제 후 COPY 후 재생성
DROP INDEX CONCURRENTLY idx_products_name; -- 잠금 없이 삭제
-- COPY 실행
CREATE INDEX CONCURRENTLY idx_products_name ON products(name); -- 잠금 없이 생성
운영 데이터에 적용하면 되돌리기 어려운 변경입니다. 실행 전 대상 테이블, WHERE 조건, 백업 또는 롤백 경로를 반드시 확인하세요.
-- 전략 3: 파티셔닝으로 배치 대상 파티션만 처리 (고급)
-- 월별 파티션이 있을 때 오래된 파티션만 교체
-- DETACH PARTITION → 수정 → ATTACH PARTITION 패턴
ALTER TABLE logs DETACH PARTITION logs_2023_01;
-- logs_2023_01에 수정 작업 (서비스 logs 테이블에 영향 없음)
ALTER TABLE logs ATTACH PARTITION logs_2023_01
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
-- 전략 4: lock_timeout으로 오래 기다리는 쿼리 실패 처리 (PostgreSQL)
-- 운영 환경에서 배치 실행 전 설정
SET lock_timeout = '5s'; -- 5초 이상 락 대기 시 에러 발생
SET statement_timeout = '60s'; -- 단일 쿼리 60초 초과 시 종료
-- 이렇게 하면 배치 중 잠금 충돌이 서비스 전체를 멈추지 않고
-- 배치 쿼리 자체가 타임아웃으로 실패함 → 재시도 가능
벌크 연산 중 데드락 / 잠금 대기 타임아웃
# PostgreSQL 데드락 에러
ERROR: deadlock detected
DETAIL: Process 12345 waits for ShareLock on transaction 6789;
blocked by process 9876.
Process 9876 waits for ShareLock on transaction 12345;
blocked by process 12345.
HINT: See server log for query details.
# MySQL 잠금 대기 타임아웃
ERROR 1205 (HY000): Lock wait timeout exceeded;
try restarting transaction
원인 1 — 배치 처리 순서 불일치: 두 배치 프로세스가 서로 다른 순서로 같은 행 집합을 처리하면 데드락이 발생합니다. 예를 들어 프로세스 A가 id=1 → id=2 순서로 잠금을 걸고, 프로세스 B가 id=2 → id=1 순서로 잠금을 걸면 서로 기다리게 됩니다.
-- 해결: 모든 배치 프로세스에서 동일한 ORDER BY로 정렬 후 처리
-- A, B 프로세스 모두 ORDER BY id ASC 사용
UPDATE products
SET price = price * 1.1
WHERE id IN (
SELECT id FROM products
WHERE category = 'electronics'
ORDER BY id -- 항상 같은 순서 보장
LIMIT 1000
);
원인 2 — 배치 크기가 너무 큼: 하나의 트랜잭션이 너무 많은 행에 잠금을 걸면 다른 쿼리와 충돌 확률이 높아집니다.
# 해결: 배치 크기를 줄이고, 실패 시 재시도 로직 추가
import time
def batch_update_with_retry(conn, batch_size=1000, max_retries=3):
last_id = 0
while True:
for attempt in range(max_retries):
try:
cursor = conn.cursor()
cursor.execute("""
UPDATE products SET price = price * 1.1
WHERE id > %s AND id <= %s + %s
AND category = 'electronics'
""", (last_id, last_id, batch_size))
affected = cursor.rowcount
conn.commit()
last_id += batch_size
break # 성공 시 재시도 루프 탈출
except Exception as e:
conn.rollback()
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # 지수 백오프
if affected == 0:
break
원인 3 — MySQL InnoDB 갭 락: REPEATABLE READ 격리 수준에서 범위 쿼리는 갭 락(Gap Lock)을 걸어 해당 범위에 INSERT를 차단합니다. 벌크 INSERT와 범위 UPDATE가 겹치면 데드락이 발생합니다.
-- 해결: MySQL에서 격리 수준을 READ COMMITTED로 낮추면 갭 락 비활성화
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- READ COMMITTED는 갭 락을 사용하지 않아 삽입 충돌이 줄어듦
-- 단, 팬텀 리드 가능성은 허용해야 함
심화 — 대량 변경 뒤에 남는 것: 죽은 튜플과 부풀기
심화: MVCC가 남기는 dead tuple — 대량 UPDATE/DELETE가 테이블을 부풀리는 이유
데드락과 잠금을 청크 분할로 피했다면, 그다음 함정은 배치가 끝난 뒤에 조용히 드러납니다. PostgreSQL은 MVCC로 동시성을 처리하므로, UPDATE는 기존 행을 덮어쓰지 않고 옛 버전을 죽은 튜플(dead tuple) 로 남긴 채 새 버전을 추가합니다. DELETE도 즉시 지우지 않고 죽은 것으로 표시만 합니다.
- 죽은 튜플이 차지한 공간은
VACUUM(주로 autovacuum)이 회수해 재사용 가능 공간으로 돌려놓기 전까지 테이블에 그대로 남습니다. 그래서 테이블과 인덱스가 물리적으로 부풀고(bloat), 살아있는 행 수는 그대로여도 스캔할 페이지가 늘어 조회가 느려집니다. - 대량 배치는 autovacuum이 따라잡기도 전에 죽은 튜플을 폭증시켜 부풀기를 키웁니다. 인덱스된 컬럼을 바꾸면 HOT update가 깨져 인덱스에도 새 엔트리가 쌓이므로 인덱스 부풀기가 특히 심해집니다.
- 그래서 청크 분할은 락만 줄이는 게 아니라, 배치 사이에 autovacuum이 죽은 튜플을 회수할 틈을 준다는 의미도 큽니다.
부풀기가 이미 심해 물리 공간까지 줄여야 한다면 VACUUM FULL(독점 락, 서비스 시간 회피)이나 온라인으로 재구성하는 pg_repack을 씁니다. 갱신이 잦은 테이블은 fillfactor를 낮춰 페이지에 HOT update 여지를 미리 확보하는 것도 방법입니다.
상황: 수백만 건 UPDATE를 락이 걸리지 않게 1만 건씩 청크로 나눠 돌렸고 배치 자체는 성공했습니다. 그런데 배치 후 그 테이블을 읽는 조회들이 전반적으로 느려졌고 디스크 사용량도 눈에 띄게 늘었습니다.
원인: UPDATE가 만든 옛 버전(dead tuple)이 대량으로 쌓였는데 autovacuum이 아직 회수하지 못해 테이블과 인덱스가 부풀었습니다. 살아있는 행은 그대로인데 스캔해야 할 페이지 수가 늘어, 같은 쿼리가 더 많은 페이지를 읽으며 I/O가 커진 것입니다.
진단: pg_stat_user_tables에서 해당 테이블의 n_dead_tup과 last_autovacuum을 확인합니다(죽은 튜플이 크고 회수가 늦었는지). pgstattuple 확장으로 dead_tuple_percent와 여유 공간을 측정하고, pg_relation_size로 인덱스가 테이블 대비 과도하게 커졌는지 봅니다.
해결: VACUUM (ANALYZE) 테이블명으로 죽은 튜플을 회수하고 통계도 갱신합니다(공간이 재사용 가능해지고 실행계획도 최신화). 부풀기가 심해 물리적으로 줄여야 하면 VACUUM FULL(독점 락 주의)이나 pg_repack을 씁니다. 재발 방지로 배치 사이에 autovacuum이 돌 여유를 주거나 청크마다 명시적 VACUUM을 넣고, 갱신이 잦은 테이블은 fillfactor를 낮춰 HOT update 여지를 확보합니다(B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건).
실무에서 이 패턴이 쓰이는 곳
정산 배치 — 월말 대용량 집계 UPDATE
정산 시스템은 보통 월말에 수백만 건의 거래를 집계해 정산 테이블을 업데이트합니다. 전체를 하나의 트랜잭션으로 처리하면 수십 분간 잠금이 걸려 서비스가 멈춥니다. 실무에서는 판매자 ID 기준으로 청크를 나눠 1,000~5,000건씩 처리하고, 각 배치가 완료되면 중간 상태를 별도 테이블에 기록합니다. 중간에 실패해도 처리된 청크는 재처리하지 않고 미처리 청크만 재시작합니다.
# 정산 배치 — 청크 분할 + 체크포인트 패턴
def run_settlement_batch(settlement_date: str):
# 처리할 판매자 목록 조회
sellers = get_sellers_for_settlement(settlement_date)
for i in range(0, len(sellers), CHUNK_SIZE):
chunk = sellers[i:i + CHUNK_SIZE]
seller_ids = [s['id'] for s in chunk]
# 이미 처리된 청크는 건너뜀 (체크포인트)
if is_chunk_processed(settlement_date, seller_ids):
continue
with db.transaction():
# 청크 내 거래 집계 및 정산 테이블 UPSERT
db.execute("""
INSERT INTO settlements (date, seller_id, amount)
SELECT %s, seller_id, SUM(amount)
FROM transactions
WHERE date = %s AND seller_id = ANY(%s)
GROUP BY seller_id
ON CONFLICT (date, seller_id) DO UPDATE
SET amount = EXCLUDED.amount,
updated_at = NOW()
""", (settlement_date, settlement_date, seller_ids))
# 체크포인트 기록
mark_chunk_processed(settlement_date, seller_ids)
데이터 마이그레이션 — 스키마 변경 후 데이터 백필
컬럼을 추가하거나 데이터 포맷을 변환할 때, 기존 수천만 건 데이터를 새 포맷으로 채워야 합니다. 한 번에 전체를 UPDATE하면 테이블 락이 수십 분 지속됩니다. 실무에서는 WHERE new_column IS NULL ORDER BY id LIMIT 10000 루프로 야간에 조금씩 처리하고, 새 코드는 old_column과 new_column을 모두 읽을 수 있게 배포합니다. 백필이 완료된 후 old_column을 제거합니다. 이것이 Expand-Contract 패턴의 데이터 마이그레이션 응용입니다.
이벤트 로그 아카이빙 — 오래된 데이터 대량 삭제
90일 지난 로그를 주기적으로 삭제하는 배치는 DELETE를 한 번에 실행하면 안 됩니다. 수천만 건 DELETE는 언두 로그(MySQL) 또는 dead tuple(PostgreSQL)을 급격히 늘려 이후 VACUUM/OPTIMIZE TABLE 비용을 높입니다. 청크 단위 삭제 후 VACUUM ANALYZE를 주기적으로 실행하는 방식이 표준입니다.
정리
| 상황 | 권장 방법 |
|---|---|
| 수천~수만 건 INSERT | Multi-row INSERT (배치 크기 1,000~5,000) |
| 수십만~수백만 건 초기 로딩 | PostgreSQL COPY, MySQL LOAD DATA INFILE |
| ORM 환경 벌크 INSERT | bulk_insert_mappings, createMany, JdbcTemplate.batchUpdate |
| 운영 중 대량 UPDATE/DELETE | LIMIT + ORDER BY 청크 루프 + 중간 커밋 |
| 존재하면 UPDATE, 없으면 INSERT | ON CONFLICT DO UPDATE (PG), ON DUPLICATE KEY UPDATE (MySQL) |
| 테이블 락 방지 | 스테이징 테이블 → 병합, CONCURRENTLY 인덱스, lock_timeout 설정 |
| 데드락 방지 | 일관된 ORDER BY, 배치 크기 축소, 재시도 로직 |
명령어·구문 빠른 참조
이 모듈에서 다룬 벌크 적재·배치 UPDATE/DELETE·UPSERT 구문을 실전 조합과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
Multi-row INSERT ... VALUES | 여러 행을 한 문장에 적재 | INSERT INTO products(...) VALUES (...),(...),(...) (1,000~5,000건 단위) |
\COPY / COPY ... FROM | CSV 대량 적재(가장 빠름) | \COPY products(name,price,stock) FROM 'p.csv' CSV |
LOAD DATA INFILE (MySQL) | CSV 파일 직접 적재 | LOAD DATA INFILE '...' INTO TABLE products FIELDS TERMINATED BY ',' |
\timing on (psql) | 단건 vs 벌크 실행 시간 측정 | 개선 배수 = 단건 ms ÷ 벌크 ms |
ORDER BY id LIMIT N 루프 | 대량 UPDATE/DELETE 청크 분할 | WHERE ... ORDER BY id LIMIT 10000 반복 + 중간 커밋 |
GET DIAGNOSTICS ... = ROW_COUNT | 배치 처리 건수로 종료 판단 | EXIT WHEN updated_count = 0 |
ON CONFLICT (col) DO UPDATE | UPSERT(있으면 갱신) | ... DO UPDATE SET view_count = daily_stats.view_count + EXCLUDED.view_count |
ON CONFLICT ... DO NOTHING | 중복 무시 삽입 | INSERT ... ON CONFLICT (id) DO NOTHING |
ON DUPLICATE KEY UPDATE (MySQL) | MySQL UPSERT | ... ON DUPLICATE KEY UPDATE view_count = view_count + new_row.view_count |
CREATE/DROP INDEX CONCURRENTLY | 잠금 없이 인덱스 재생성 | 대량 적재 전 DROP → 적재 → CREATE |
SET lock_timeout / statement_timeout | 배치가 서비스를 막지 않게 | SET lock_timeout='5s'(락 대기 시 실패 → 재시도) |
SET SESSION ... ISOLATION LEVEL READ COMMITTED | MySQL 갭 락 회피 | 벌크 INSERT·범위 UPDATE 데드락 완화 |
VACUUM (ANALYZE) | 대량 변경 후 죽은 튜플 회수 | VACUUM (ANALYZE) products(부풀기·통계 갱신) |
관련 모듈로 더 깊이:
- 트랜잭션의 4대 속성(ACID)과 복구 원리 — 청크 단위 중간 커밋이 트랜잭션 경계와 어떻게 맞물리는지
- B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건 — 대량 INSERT 시 인덱스 갱신이 병목이 되는 이유와
CONCURRENTLY - Flyway와 Liquibase를 이용한 DB 마이그레이션 버전 관리 — Expand-Contract 백필이 스키마 마이그레이션 흐름의 일부인 이유
다음 모듈에서는 Prisma, JPA, TypeORM, SQLAlchemy 등 ORM의 성능 차이와 올바른 사용 패턴을 다룹니다.