ORM은 생산성을 높여주지만 SQL을 몰라도 되게 해주는 도구는 아닙니다. 간단한 메서드 호출 뒤에서 어떤 SELECT와 JOIN이 실행되는지 모르면 N+1과 과한 조회가 숨어듭니다. ORM의 동작 방식을 알아야 편의성과 성능을 함께 챙길 수 있습니다.
ORM은 객체 지향 언어와 관계형 데이터베이스 사이의 패러다임 불일치를 해결합니다. 이 모듈에서는 ORM이 내부적으로 어떻게 동작하는지 이해하고, 주요 언어별 ORM 도구를 비교하여 올바른 도구를 선택하는 방법을 배웁니다.
- 1N+1과 의도치 않은 전체 업데이트 같은 ORM 공통 실패 패턴을 진단하고 예방할 수 있다
- 2ORM이 SQL을 추상화하는 동작 원리를 설명할 수 있다
- 3Active Record와 Data Mapper 설계 패턴을 구분하고 차이를 설명할 수 있다
- 4Prisma, SQLAlchemy, JPA/Hibernate, TypeORM을 비교할 수 있다
- 5실무 요구사항에 맞춰 ORM을 선택할 수 있다
ORM이란? — Prisma, SQLAlchemy, JPA, TypeORM 비교
데이터베이스와 애플리케이션 코드 사이의 다리 역할을 하는 ORM(Object-Relational Mapping)은 현대 서버 개발에서 거의 필수적인 도구입니다. SQL을 직접 작성하는 대신 프로그래밍 언어의 객체로 데이터베이스를 다룰 수 있게 해주지만, 그만큼 잘못 사용하면 심각한 성능 문제를 일으킵니다. ORM을 도입하기 전에 공통 실패 패턴을 먼저 이해하는 것이 중요합니다.
ORM 공통 실패 패턴 — 도구를 쓰기 전에 알아야 할 것
코드 리뷰에서 아무도 문제를 지적하지 않았습니다. 로컬 테스트도 정상이었습니다. 그런데 배포하고 나서 게시글 목록 API가 수백 밀리초씩 걸리기 시작합니다. APM을 보니 게시글 100개를 조회할 때 DB 쿼리가 101번 발생합니다. ORM이 편리한 만큼, ORM의 실패 패턴을 모르면 성능 문제는 반드시 터집니다. N+1부터 SELECT *까지, 도구를 쓰기 전에 알아야 할 패턴들입니다.
 확대
확대
N+1 문제 — 가장 흔한 ORM 실수
ORM을 처음 사용하는 개발자가 가장 많이 겪는 문제는 N+1 쿼리입니다. 부모 레코드 N개를 가져온 뒤 각각의 자식 레코드를 개별 쿼리로 로드하면, 총 N+1번의 쿼리가 데이터베이스에 발행됩니다. 10개 게시글의 댓글을 불러올 때는 11번, 100개라면 101번의 쿼리가 실행됩니다.
아래 Python 예시는 문제가 발생하는 코드와 올바른 해결 방법을 보여줍니다.
from sqlalchemy.orm import Session, joinedload
# N+1이 발생하는 코드
posts = session.query(Post).limit(10).all()
for post in posts:
print(post.comments)
# Eager Loading으로 해결 — JOIN으로 한 번에 로드
posts = (
session.query(Post)
.options(joinedload(Post.comments))
.limit(10)
.all()
)
첫 번째 방식은 post.comments에 접근할 때마다 Lazy Loading이 트리거되어 개별 쿼리가 실행됩니다. joinedload를 사용하면 단일 JOIN 쿼리 또는 2번의 쿼리(selectinload 사용 시)로 해결됩니다.
N+1은 로그를 켜야 보입니다. echo=True로 실행 SQL을 출력하고, Lazy 방식과 joinedload 방식의 쿼리 발행 횟수를 직접 세어 비교합니다.
from sqlalchemy import create_engine
engine = create_engine(DB_URL, echo=True) # 실행 SQL 콘솔 출력
# (N+1) 게시글 10개 + 각 댓글 조회 → 1 + 10 = 11번
posts = session.query(Post).limit(10).all()
for post in posts:
_ = post.comments
# (해결) joinedload → JOIN 1번
posts = (session.query(Post)
.options(joinedload(Post.comments))
.limit(10).all())
for post in posts:
_ = post.comments
# (N+1) — SELECT가 11줄 찍힘
SELECT * FROM posts LIMIT 10
SELECT * FROM comments WHERE post_id = 1
SELECT * FROM comments WHERE post_id = 2
... (10줄)
# (joinedload) — SELECT 1줄
SELECT posts.*, comments.* FROM posts
LEFT OUTER JOIN comments ON comments.post_id = posts.id
engine = create_engine(DB_URL, echo=True)- Lazy 방식 로그에서 SELECT 줄 수를 센다 — 게시글 N개에 N+1줄이면 N+1 문제가 재현된 것이다(10개 → 11줄)
- joinedload 방식이 SELECT 1~2줄로 줄었는지 확인 — 여전히 여러 줄이면 options()가 누락됐거나 다른 관계에서 또 Lazy가 터진 것
- 쿼리 수가 데이터 건수에 비례해 늘면(100개 → 101줄) 운영에서 응답시간이 선형 악화된다 — 목록 API는 항상 eager loading 명시
- echo 로그가 안 보이면 로깅이 안 켜진 것 — SQLAlchemy echo=True / Prisma DEBUG=prisma:query / Hibernate show-sql=true 를 개발환경에 켜둔다
의도치 않은 전체 테이블 업데이트
ORM이 생성하는 SQL을 확인하지 않으면 예상치 못한 전체 테이블 업데이트가 발생할 수 있습니다. 예를 들어 일부 ORM은 WHERE 조건 없이 모든 레코드를 업데이트하는 SQL을 조용히 실행하기도 합니다. 개발 중에는 반드시 ORM 로깅을 활성화하여 생성되는 SQL을 눈으로 확인해야 합니다.
SQLAlchemy에서는 echo=True 옵션으로 생성 SQL을 출력할 수 있고, Prisma에서는 환경변수 DEBUG="prisma:query"를 설정합니다. JPA/Hibernate에서는 spring.jpa.show-sql=true를 설정합니다.
게시글 목록 API에서 각 게시글의 작성자 정보를 post.author로 접근하면 게시글 수만큼 추가 쿼리가 발생합니다. 개발 환경에서는 데이터가 적어 눈치채지 못하다가 운영 환경에서 게시글이 수백 개가 되면 응답 시간이 급격히 증가합니다.
해결: 관계 데이터가 필요한 쿼리에는 항상 Eager Loading(joinedload, include, JOIN FETCH)을 명시적으로 지정합니다. ORM 로깅을 개발 환경에서 항상 켜두고, 쿼리 수가 예상과 다를 경우 즉시 확인합니다.
TypeORM에서 save() 메서드를 사용할 때 id가 없는 객체를 전달하면 INSERT가 아닌 조건 없는 UPDATE가 실행될 수 있습니다. 또한 일부 ORM은 영속성 컨텍스트의 변경 감지(dirty checking) 로직이 예상과 다르게 동작해 불필요한 컬럼까지 업데이트합니다.
해결: ORM 로깅을 활성화하여 실제 실행 SQL을 확인합니다. 민감한 업데이트 작업에서는 ORM 대신 Raw SQL이나 쿼리 빌더를 사용하는 것이 안전합니다.
ORM 동작 원리 — SQL을 코드로 추상화하는 방법
ORM 코드를 작성했는데 예상과 다른 결과가 나옵니다. 조건을 붙였는데 전체 테이블을 스캔하거나, 연관 객체를 접근했는데 추가 쿼리가 자동으로 발생합니다. ORM이 내부에서 무슨 SQL을 실행하는지 모르면 예상치 못한 동작을 만났을 때 원인을 찾기 어렵습니다. ORM이 객체 조작을 SQL로 변환하는 원리를 이해하면 실수도 줄고 디버깅도 빨라집니다.
 확대
확대
ORM이 생성하는 SQL
ORM의 핵심은 객체 조작 코드를 SQL로 변환하는 것입니다. 아래는 사용자의 최근 주문 목록을 가져오는 동일한 작업을 Raw SQL과 SQLAlchemy ORM으로 각각 표현한 것입니다.
SELECT u.id, u.name, o.id AS order_id, o.total_amount
FROM users u
INNER JOIN orders o ON o.user_id = u.id
WHERE u.email = 'alice@example.com'
ORDER BY o.created_at DESC
LIMIT 10;
실행 완료 또는 조회 결과가 표시됩니다.
- SELECT 로그 먼저: echo=True(SQLAlchemy) 또는 show-sql=true(JPA)로 출력된 로그에서 SELECT가 몇 번 찍히는지 센다. 조회한 게시글 수 + 1번이면 N+1 발생 중 — joinedload/include로 1~2번으로 줄일 것
- 쿼리 횟수 기준: 10개 게시글 조회 시 SELECT가 11번 이상이면 N+1. 2번 이하(1번 JOIN 또는 selectinload)면 정상. 50개 조회에서 51번이 뜬다면 즉시 Eager Loading 적용
- SELECT 많고 UPDATE가 예상보다 더 나옴: dirty checking이 불필요한 컬럼까지 업데이트하는 신호 — 변경한 필드가 1개인데 UPDATE SET이 전체 컬럼을 포함하면 @DynamicUpdate(JPA) 또는 개별 필드 지정 쿼리로 전환
from sqlalchemy.orm import Session
with Session(engine) as session:
results = (
session.query(User, Order)
.join(Order, Order.user_id == User.id)
.filter(User.email == 'alice@example.com')
.order_by(Order.created_at.desc())
.limit(10)
.all()
)
ORM은 이 Python 코드를 실행할 때 내부적으로 위의 SQL을 생성합니다. 개발자는 SQL 문법을 직접 작성하지 않아도 되며, 타입 시스템의 도움을 받아 컴파일 시점에 오류를 잡을 수 있습니다.
Active Record vs Data Mapper 패턴
ORM은 크게 두 가지 설계 패턴으로 구현됩니다.
Active Record 패턴은 모델 클래스 자체가 DB 접근 로직을 포함합니다. 모델 객체 스스로 save(), delete() 같은 DB 메서드를 가지며, Rails의 ActiveRecord가 대표적입니다. 단순 CRUD 중심의 소규모 애플리케이션에 적합합니다.
import { Entity, PrimaryGeneratedColumn, Column, BaseEntity } from "typeorm";
@Entity()
export class User extends BaseEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@Column({ unique: true })
email: string;
}
const user = new User();
user.name = "Alice";
user.email = "alice@example.com";
await user.save();
const found = await User.findOne({ where: { email: "alice@example.com" } });
await found.remove();
Data Mapper 패턴은 도메인 모델과 DB 접근 로직을 분리합니다. 모델은 순수한 데이터 구조이고, 별도의 Repository나 EntityManager가 DB 작업을 담당합니다. 복잡한 비즈니스 도메인과 테스트 용이성이 중요한 프로젝트에 적합합니다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(unique = true, nullable = false)
private String email;
}
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByEmail(String email);
List<User> findByNameContaining(String keyword);
}
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(String name, String email) {
User user = new User();
user.setName(name);
user.setEmail(email);
return userRepository.save(user);
}
}
| 비교 항목 | Active Record | Data Mapper |
|---|---|---|
| 모델 복잡도 | 낮음 (단순) | 높음 (분리된 계층) |
| 테스트 용이성 | 낮음 (DB 의존) | 높음 (Mock 가능) |
| 도메인 복잡성 | 단순 CRUD에 적합 | 복잡한 비즈니스 로직에 적합 |
| 대표 ORM | Ruby ActiveRecord, Eloquent | JPA/Hibernate, SQLAlchemy |
ORM의 장점과 단점
장점:
- 타입 안전성: 컴파일 시점에 컬럼명 오타 등을 잡을 수 있습니다
- 마이그레이션 통합: 모델 변경 시 마이그레이션 파일을 자동 생성할 수 있습니다
- DBMS 추상화: PostgreSQL에서 MySQL로 전환 시 코드 변경이 최소화됩니다
- 개발 속도: 반복적인 CRUD 코드 작성 시간이 줄어듭니다
단점:
- 복잡한 쿼리 한계: 복잡한 GROUP BY, 윈도우 함수, CTE 등은 ORM으로 표현이 어렵습니다
- N+1 문제: 관계 데이터를 Lazy Loading으로 접근 시 쿼리가 폭증합니다
- 성능 예측 어려움: 생성되는 SQL을 파악하지 않으면 의도치 않은 Full Table Scan이 발생합니다
- 학습 곡선: ORM 자체 개념(세션, 영속성 컨텍스트 등)을 따로 학습해야 합니다
user.setName() 한 줄이 UPDATE가 되기까지 — 영속성 컨텍스트 5단계
user.setName("Alice") 한 줄만 썼는데, save()도 안 불렀는데 트랜잭션이 끝나자 UPDATE users ...가 나갑니다. 반대로 분명히 값을 바꿨는데 커밋 전에는 DB에 안 보이기도 합니다. ORM은 객체를 바꾸는 즉시 SQL을 내는 게 아니라, 변경을 모아뒀다가 정해진 시점(flush)에 한꺼번에 SQL로 바꿉니다. 이 5단계를 알면 "언제 SQL이 나가는지"와 N+1이 어디서 터지는지를 단계로 좁힐 수 있습니다.
[앱 코드] user = repo.findById(1) → user.setName("Alice")
│
① 로드·영속화 (SELECT 또는 persist → 1차 캐시(영속성 컨텍스트)에 올리고 로드 값 스냅샷 보관)
│
② 객체 조작 (user.setName(...) — 순수 메모리 변경, 아직 DB 미접촉·SQL 없음)
│
③ 변경 감지(dirty checking) (flush 시 현재 값 ↔ ①의 스냅샷 비교 → 바뀐 엔터티·컬럼 탐지)
│
④ SQL 생성·플러시(flush) (변경분에 INSERT/UPDATE/DELETE 생성 → DB로 전송, 아직 커밋 아님)
│ ↑ 트리거: 커밋 직전 · JPQL/쿼리 실행 직전 · 수동 flush() 호출
│
⑤ 커밋(commit) (트랜잭션 확정 → 반영. 영속성 컨텍스트(1차 캐시) 종료)
▼
[DB] UPDATE users SET name='Alice' WHERE id=1
각 단계에서 무슨 일이 일어나고, 어디서 문제가 새어 나오나:
| 단계 | 하는 일 | 여기서 새어 나오는 문제(증상) |
|---|---|---|
| ① 로드·영속화 | SELECT/persist로 엔터티를 1차 캐시에 올리고 로드 시점 값을 스냅샷으로 보관 | 목록을 로드한 뒤 루프에서 post.comments 같은 연관을 건드리면 지연 로딩이 매번 SELECT → N+1 폭발 |
| ② 객체 조작 | setName() 등으로 필드만 변경 — 메모리 작업, 아직 DB 미접촉 | save()를 안 불러도 영속 상태 엔터티면 변경이 추적됨 → 의도치 않은 UPDATE |
| ③ 변경 감지 | flush 시점에 현재 필드값과 ①의 스냅샷을 비교해 바뀐 엔터티·컬럼을 추림 | 스냅샷 비교라 필드 1개만 바꿔도 전체 컬럼 UPDATE가 나갈 수 있음 → @DynamicUpdate로 제한 |
| ④ SQL 생성·플러시 | 변경분에 SQL을 만들어 DB로 전송(커밋 아님) | 플러시는 커밋 직전·쿼리 실행 직전에도 자동 발생 → "안 지운 것 같은데 왜 반영됐지" 타이밍 혼란 |
| ⑤ 커밋 | 트랜잭션을 확정하고 1차 캐시를 종료 | 커밋(=컨텍스트 종료) 후 지연 로딩 접근 → LazyInitializationException |
즉 setName() 한 줄이 UPDATE가 되는 것은 ③변경 감지와 ④플러시의 결과이지, 그 줄이 곧바로 SQL을 내는 게 아닙니다. 무슨 SQL이 언제 몇 번 나가는지는 쿼리 로깅(echo=True·show-sql)으로 flush 지점을 눈으로 확인하고, 목록에서 N+1이 보이면 ①의 지연 로딩을 fetch join(JOIN FETCH·joinedload·include)으로 한 번에 당겨오면 됩니다.
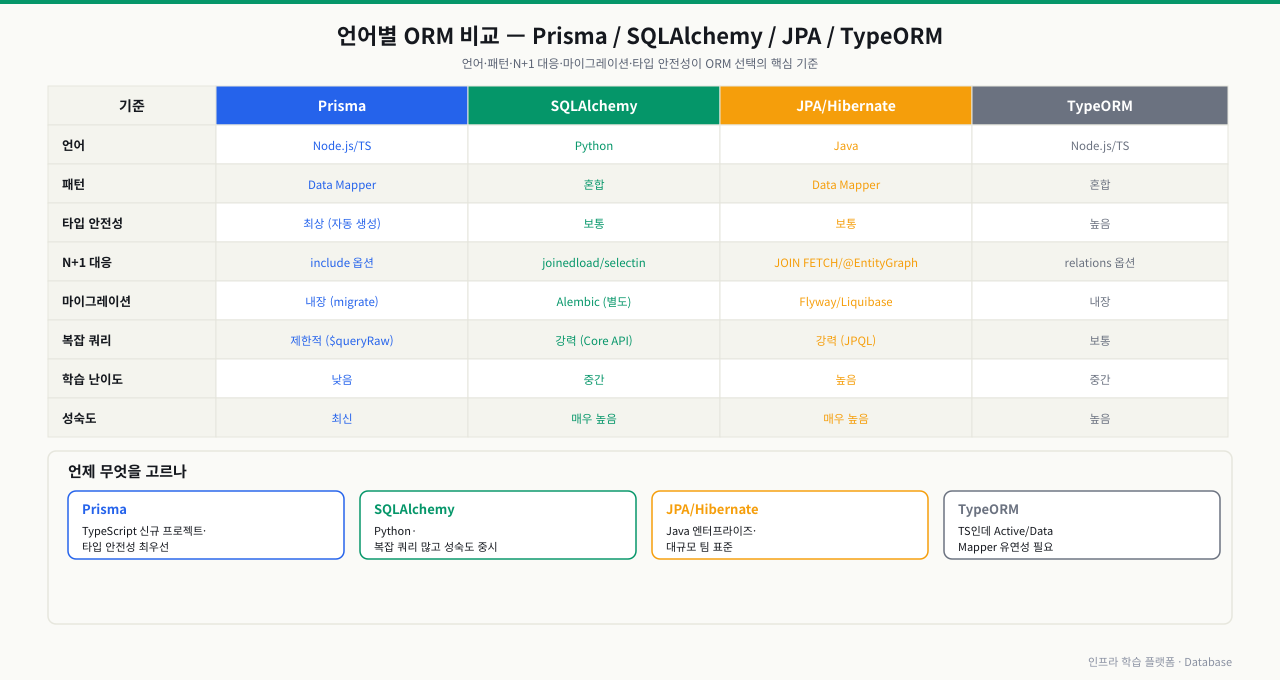
언어별 ORM 비교 — Prisma vs SQLAlchemy vs JPA vs TypeORM
새 프로젝트를 시작하는데 팀에서 ORM을 고릅니다. 누군가는 Prisma를 쓰자고 하고, 백엔드 시니어는 JPA를 주장합니다. 각각 뭐가 다른지, 어떤 상황에서 어떤 도구가 적합한지 기준이 없으면 결정이 어렵습니다. 도구마다 N+1 처리 방식, 타입 안전성, 마이그레이션 전략이 다릅니다. 비교 기준을 알면 팀과 프로젝트에 맞는 선택이 가능합니다.
 확대
확대
ORM 도구 비교표
언어, 패턴, N+1 대응 방식, 마이그레이션 전략, 타입 안전성은 ORM 선택에서 가장 중요한 기준입니다.
| 항목 | Prisma | SQLAlchemy | JPA/Hibernate | TypeORM |
|---|---|---|---|---|
| 언어 | Node.js/TS | Python | Java | Node.js/TS |
| 패턴 | Data Mapper | 혼합 | Data Mapper | 혼합 |
| 타입 안전성 | 최상 (자동 생성 타입) | 보통 | 보통 | 높음 |
| N+1 대응 | include 옵션 | joinedload / selectinload | JOIN FETCH / @EntityGraph | relations 옵션 |
| 마이그레이션 | 내장 (prisma migrate) | Alembic (별도) | Flyway / Liquibase | 내장 |
| 복잡 쿼리 | 제한적 ($queryRaw 사용) | 강력 (Core API) | 강력 (JPQL/NativeQuery) | 보통 |
| 학습 난이도 | 낮음 | 중간 | 높음 | 중간 |
| 성숙도 | 최신 | 매우 높음 | 매우 높음 | 높음 |
Prisma (Node.js/TypeScript)
Prisma는 스키마 파일로부터 타입 안전한 클라이언트를 자동 생성하는 최신 ORM입니다. Data Mapper 패턴을 따르며, TypeScript 환경에서 최고의 개발 경험을 제공합니다. npx prisma migrate dev 명령으로 마이그레이션을 생성하고 적용하며, schema.prisma의 변경 사항을 감지해 SQL 파일을 자동으로 만듭니다.
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String
posts Post[]
createdAt DateTime @default(now())
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
author User @relation(fields: [authorId], references: [id])
authorId Int
}
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
const user = await prisma.user.create({
data: { email: 'alice@example.com', name: 'Alice' }
});
const usersWithPosts = await prisma.user.findMany({
include: { posts: true }
});
await prisma.user.update({
where: { id: user.id },
data: { name: 'Alice Updated' }
});
await prisma.user.delete({ where: { id: user.id } });
SQLAlchemy (Python)
SQLAlchemy는 Python 생태계에서 가장 강력한 ORM으로, 저수준 Core API와 고수준 ORM 레이어를 모두 제공합니다. 마이그레이션은 Alembic을 별도로 사용합니다(alembic revision --autogenerate, alembic upgrade head).
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, select
from sqlalchemy.orm import DeclarativeBase, relationship, Session
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, autoincrement=True)
email = Column(String(255), unique=True, nullable=False)
name = Column(String(100), nullable=False)
posts = relationship("Post", back_populates="author", lazy="select")
class Post(Base):
__tablename__ = "posts"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(255), nullable=False)
author_id = Column(Integer, ForeignKey("users.id"), nullable=False)
author = relationship("User", back_populates="posts")
engine = create_engine("postgresql+psycopg2://user:pass@localhost/db")
with Session(engine) as session:
user = User(email="bob@example.com", name="Bob")
session.add(user)
session.commit()
stmt = select(User).where(User.email == "bob@example.com")
result = session.execute(stmt).scalar_one()
JPA/Hibernate (Java)
JPA(Java Persistence API)는 Java 표준 ORM 명세이고, Hibernate는 가장 널리 쓰이는 구현체입니다. Spring Boot와 함께 사용할 때 생산성이 극대화됩니다. @Query로 JPQL 커스텀 쿼리를 작성하고, N+1 해결에는 JOIN FETCH를 사용합니다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true, nullable = false)
private String email;
@OneToMany(mappedBy = "author", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private List<Post> posts = new ArrayList<>();
}
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByEmail(String email);
@Query("SELECT u FROM User u JOIN FETCH u.posts WHERE u.id = :id")
Optional<User> findByIdWithPosts(@Param("id") Long id);
}
TypeORM (Node.js/TypeScript)
TypeORM은 Active Record와 Data Mapper 패턴을 모두 지원하며, TypeScript 데코레이터 기반으로 작동합니다. relations 옵션으로 Eager Loading을 명시적으로 지정합니다.
import { Entity, PrimaryGeneratedColumn, Column,
OneToMany, Repository } from 'typeorm';
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column({ unique: true })
email: string;
@OneToMany(() => Post, (post) => post.author, { lazy: true })
posts: Promise<Post[]>;
}
const userRepo: Repository<User> = dataSource.getRepository(User);
const user = userRepo.create({ email: 'carol@example.com' });
await userRepo.save(user);
const found = await userRepo.findOne({
where: { email: 'carol@example.com' },
relations: { posts: true }
});
TypeScript 기반 신규 프로젝트에서 Prisma를 선택하는 기준은 팀의 SQL 숙련도가 낮고 빠른 프로토타이핑이 필요할 때입니다. Prisma는 schema.prisma 파일 하나로 타입 생성과 마이그레이션을 통합 관리하므로 온보딩이 빠릅니다. 반면 기존 레거시 DB 스키마를 그대로 사용해야 하거나, 복잡한 동적 쿼리 빌딩이 많다면 TypeORM의 QueryBuilder가 더 유연합니다. Prisma는 Raw SQL 탈출구($queryRaw)를 제공하므로 복잡한 집계 쿼리는 그쪽으로 처리하고, 일반 CRUD는 Prisma를 사용하는 하이브리드 전략이 현장에서 가장 많이 쓰입니다.
실무에서는 언어와 팀의 기술 스택에 따라 선택하되, 복잡한 리포팅 쿼리나 대용량 배치 작업은 ORM이 아닌 Raw SQL을 사용하는 것이 합리적입니다. 좋은 ORM 활용 전략은 "단순 CRUD는 ORM, 복잡한 집계는 SQL"입니다.
심화 — ORM이 커넥션을 쥐고 있는 시간
심화: 영속성 컨텍스트와 OSIV — 쿼리는 빠른데 커넥션이 마르는 이유
N+1을 잡고 인덱스를 붙여 모든 쿼리가 밀리초 단위로 빨라졌는데도, 트래픽이 몰리면 요청들이 커넥션을 못 얻어 무더기로 실패하는 일이 있습니다. 이건 쿼리 속도의 문제가 아니라, ORM이 커넥션을 언제부터 언제까지 쥐고 있느냐의 문제입니다.
JPA 같은 ORM은 트랜잭션 동안 영속성 컨텍스트(persistence context) — 1차 캐시이자 변경 감지(dirty checking)의 저장소 — 를 유지하고, 그에 DB 커넥션을 묶어 둡니다. 여기서 Spring의 기본 설정인 OSIV(Open Session In View)가 함정을 만듭니다.
- OSIV는 커넥션을 요청 전 구간 동안 붙잡습니다. 뷰(응답 렌더링) 단계에서도 지연 로딩이 되도록, 영속성 컨텍스트와 커넥션을 HTTP 요청 시작부터 끝까지 유지합니다. 편해 보이지만, 컨트롤러가 응답을 만들며 외부 API 호출이나 느린 직렬화로 시간을 끌면 그동안 커넥션이 반납되지 않습니다.
- DB를 안 쓰는 시간에도 커넥션이 점유됩니다. 요청 중간에 결제 API를 부르는 300ms 동안 실제 DB 작업은 없어도 커넥션은 잡혀 있습니다. 동시 요청이 늘면 커넥션이 전부 점유돼 풀이 고갈되고, 뒤 요청은 획득 타임아웃으로 실패합니다.
그래서 성숙한 팀은 OSIV를 끄고(spring.jpa.open-in-view=false), 필요한 데이터를 서비스의 트랜잭션 경계 안에서 fetch join이나 DTO 프로젝션으로 미리 로딩합니다. 이렇게 하면 커넥션 점유 시간이 실제 DB 작업 구간으로 좁혀져, 같은 풀 크기로 훨씬 많은 요청을 소화합니다.
상황: 슬로우 쿼리 로그를 봐도 느린 SQL이 없고 각 쿼리는 밀리초 단위인데, 피크 시간에 요청들이 커넥션을 얻지 못해 대량으로 실패합니다. 커넥션 풀 크기를 늘리면 잠깐 나아지다 다시 같은 증상이 반복됩니다.
원인: OSIV가 켜져 있어 커넥션이 HTTP 요청 전 구간 동안 점유됩니다. 요청 중간에 외부 결제·알림 API 호출이나 무거운 응답 직렬화가 있으면, DB를 쓰지 않는 그 시간에도 커넥션이 반납되지 않습니다. 개별 쿼리는 빨라도 커넥션 1개가 잡혀 있는 시간이 실제 쿼리 시간보다 훨씬 길어, 동시성이 조금만 올라도 풀이 고갈됩니다.
진단: 커넥션 풀(HikariCP 등) 지표에서 active connections와 획득 대기 시간을 봅니다. 활성 커넥션 점유 시간이 실제 쿼리 합계보다 크게 길고, 외부 API 호출이 요청 경로에 있으면 OSIV 점유가 원인입니다. spring.jpa.open-in-view 값을 확인합니다(기본 true).
해결: OSIV를 끄고(spring.jpa.open-in-view=false), 뷰에서 필요한 연관 데이터는 서비스 트랜잭션 안에서 fetch join·@EntityGraph·DTO 프로젝션으로 미리 로딩합니다. 외부 API 호출은 트랜잭션(그리고 커넥션 점유) 바깥으로 빼서, 커넥션이 실제 DB 작업에만 잡히도록 경계를 좁힙니다. 풀 크기 확대는 임시방편일 뿐 점유 시간을 줄이는 것이 근본 해결입니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 ORM별 N+1 해결·로깅·마이그레이션 구문을 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
joinedload / selectinload (SQLAlchemy) | N+1 해결 eager loading | session.query(Post).options(joinedload(Post.comments)) |
include (Prisma) | 연관 데이터 eager loading | prisma.user.findMany({ include: { posts: true } }) |
JOIN FETCH / @EntityGraph (JPA) | N+1 해결 fetch join | @Query("SELECT u FROM User u JOIN FETCH u.posts") |
relations (TypeORM) | 연관 데이터 eager loading | findOne({ where: {...}, relations: { posts: true } }) |
echo=True / show-sql / DEBUG | 생성 SQL 로깅(N+1 진단) | create_engine(url, echo=True), spring.jpa.show-sql=true, DEBUG="prisma:query" |
FetchType.LAZY (JPA) | 지연 로딩으로 불필요 JOIN 제거 | @OneToMany(fetch = FetchType.LAZY) |
select(User).where(...) (SQLAlchemy 2.0) | 2.0 스타일 조회 | session.execute(select(User).where(User.email == "a@b.com")) |
prisma migrate dev 후 prisma generate | 마이그레이션 적용 후 클라이언트 재생성 | 순서 반대면 타입-DB 스키마 불일치 |
alembic revision --autogenerate / upgrade head | SQLAlchemy 마이그레이션(Alembic) | 모델 변경분 자동 감지·적용 |
$queryRaw (Prisma) / NativeQuery (JPA) | ORM으로 어려운 복잡 쿼리 탈출구 | 복잡 집계·윈도우 함수는 Raw SQL |
@DynamicUpdate (JPA) | 변경된 필드만 UPDATE | dirty checking의 전체 컬럼 UPDATE 방지 |
spring.jpa.open-in-view=false | OSIV 끄기(커넥션 점유 축소) | 커넥션 획득 타임아웃 방지 |
관련 모듈로 더 깊이:
- Flyway와 Liquibase를 이용한 DB 마이그레이션 버전 관리 — ORM이 생성하는 마이그레이션을 운영에서 안전하게 적용하는 법
- N+1 문제, SELECT *, 인덱스 무력화 안티패턴 방지 — ORM이 흔히 만드는 N+1 쿼리 등 안티패턴 피하기
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — ORM 대신 Raw SQL이 필요한 복잡한 쿼리를 튜닝하는 법
다음 모듈에서는 Flyway와 Liquibase를 활용한 DB 마이그레이션 버전 관리와 운영 환경 안전 배포 전략을 다룹니다.