처음에는 VARCHAR 하나로 모든 값을 저장해도 동작하는 것처럼 보입니다. 하지만 금액, 시간, 상태값의 타입을 잘못 고르면 정렬·계산·인덱스에서 바로 문제가 납니다. 데이터 타입 선택은 저장 공간보다 서비스의 정확성과 유지보수성을 좌우합니다.
데이터 타입 선택이 성능, 정확성, 저장 공간에 어떤 영향을 미치는지 이해하고, 실무에서 자주 마주치는 타입 선택 실수를 피하는 방법을 익힙니다.
- 1SMALLINT부터 BIGINT까지 정수형 타입의 범위를 알고 적절히 선택할 수 있다
- 2DECIMAL과 FLOAT의 차이를 이해하고 금액 계산에 올바른 타입을 쓸 수 있다
- 3CHAR, VARCHAR, TEXT를 상황에 맞게 구분해 사용할 수 있다
- 4날짜/시간형을 다루고 타임존을 올바르게 처리할 수 있다
- 5BOOLEAN, JSON, UUID, ENUM 같은 특수 타입을 적재적소에 활용할 수 있다
데이터 타입 선택 기준 — 숫자, 문자, 날짜의 올바른 선택
입사 첫 달, 결제 금액 컬럼을 FLOAT으로 선언했다. 저장은 됐고, 조회도 됐고, 아무 문제 없어 보였다. 그런데 월말 정산 배치를 돌렸더니 합산 결과가 회계팀 숫자와 미묘하게 달랐다 — 1원, 2원씩. 원인을 찾는 데 이틀이 걸렸고, 결국 FLOAT의 부동소수점 오차가 수천 건에 걸쳐 누적된 것이었다. 컬럼 타입을 DECIMAL로 바꾸는 건 데이터 마이그레이션을 동반했고, 운영 시간 외에 작업해야 했다. 비슷한 일이 VARCHAR 쪽에서도 있었다 — 이름 컬럼을 TEXT로 선언해서 나중에 인덱스를 걸려니 길이 제한 오류가 났고, 글로벌 출시 후 TIMESTAMP 컬럼이 서울/뉴욕에서 9시간씩 틀어지는 사고도 겪었다. 타입 선택은 "저장만 되면 된다"의 문제가 아니라, 나중에 수정 비용이 얼마냐의 문제다. 이 모듈은 처음부터 올바른 타입을 고르는 판단 기준을 실수 사례와 함께 정리한다.
"어차피 다 저장되는 거 아닌가요?" 이런 생각으로 모든 컬럼을 VARCHAR(255)나 TEXT로 선언하는 경우가 있습니다. 하지만 잘못된 타입 선택은 저장 공간 낭비, 성능 저하, 심각한 경우 데이터 손실과 계산 오류로 이어집니다. 이 모듈에서는 각 타입의 내부 동작 원리와 선택 기준을 정확히 이해합니다.
값 하나가 타입을 만나 저장·연산·인덱스까지 — 동작 5단계
컬럼 타입은 단순한 "라벨"이 아닙니다. INSERT로 값 하나가 들어오는 순간, 선언된 타입은 그 값을 어떻게 검사하고, 어떤 형식으로 디스크에 눕히고, 나중에 어떻게 비교·계산하고, 인덱스에 어떻게 얹을지를 매 단계에서 지배합니다. 이 5단계를 알면 "왜 이 INSERT가 거부되지", "왜 합계가 1원 틀리지", "왜 인덱스를 안 타지"를 단계로 좁혀 진단할 수 있습니다. 타입 선택이 성능과 정확성을 가르는 지점이 바로 이 흐름 위에 있습니다.
[값 입력] INSERT INTO t (price, code) VALUES (19.9, '00042')
│
① 타입 검사·변환 선언된 타입으로 파싱·캐스팅하고 범위를 확인
│ 범위 초과면 여기서 거부 (INT에 30억 → out of range)
│
② 저장 형식 결정 고정 길이(INT 4B·CHAR(n))냐 가변 길이(VARCHAR·NUMERIC)냐,
│ 정밀도·자릿수 확정 (DECIMAL=고정소수, FLOAT=이진 근사)
│
③ 연산 규칙 적용 비교·산술 시 타입 규칙 — 같은 타입끼리 비교,
│ 섞이면 암묵 형변환, FLOAT 합산은 오차가 누적
│
④ 인덱스 반영 키 타입의 크기·정렬성이 B-트리 모양을 결정,
│ 조건의 타입이 어긋나면 인덱스를 못 탄다
│
⑤ 용량·성능 행 크기 = 타입 크기의 합 → 페이지당 행 수·I/O를 좌우
▼
[디스크] 좁고 순차적인 타입일수록 더 작고 빠른 테이블·인덱스
각 단계에서 무슨 일이 일어나고, 타입을 잘못 고르면 어떤 증상인가:
| 단계 | 하는 일 | 타입을 잘못 고르면 |
|---|---|---|
| ① 타입 검사·변환 | 선언 타입으로 파싱·캐스팅·범위 확인 | 범위 초과 INSERT가 out of range로 실패 (INT 오버플로) |
| ② 저장 형식 | 고정·가변, 정밀도·자릿수 확정 | 금액을 FLOAT에 → 이진 근사로 정밀도 손실 (합계가 미세하게 틀림) |
| ③ 연산 규칙 | 비교·산술의 타입 규칙, 암묵 형변환 | 숫자를 VARCHAR에 → 정렬이 사전순(문자 '9'가 '10'보다 뒤)으로 틀어짐 |
| ④ 인덱스 반영 | 키 크기·정렬성이 B-트리를 좌우 | 조건 타입 불일치 → 암묵 형변환으로 인덱스 무력화(Seq Scan) |
| ⑤ 용량·성능 | 행 크기가 페이지당 행 수·I/O 결정 | 과대 타입 남발 → 테이블·인덱스 비대, 캐시 효율 저하 |
즉 "저장은 됐다"가 "타입이 맞다"는 뜻은 아닙니다. 문제가 생기면 이 5단계 중 어디서 어긋났는지로 좁힙니다 — INSERT 거부는 ①, 계산·정밀도 오차는 ②③, 느린 조회에서 Seq Scan이 보이면 ④(조건과 컬럼의 타입이 같은지 확인), 테이블·인덱스가 예상보다 크면 ⑤입니다. 뒤에서 다루는 정수 범위, DECIMAL vs FLOAT, CHAR/VARCHAR, 타임존 타입은 모두 이 흐름의 특정 단계를 깊이 파고드는 이야기입니다.
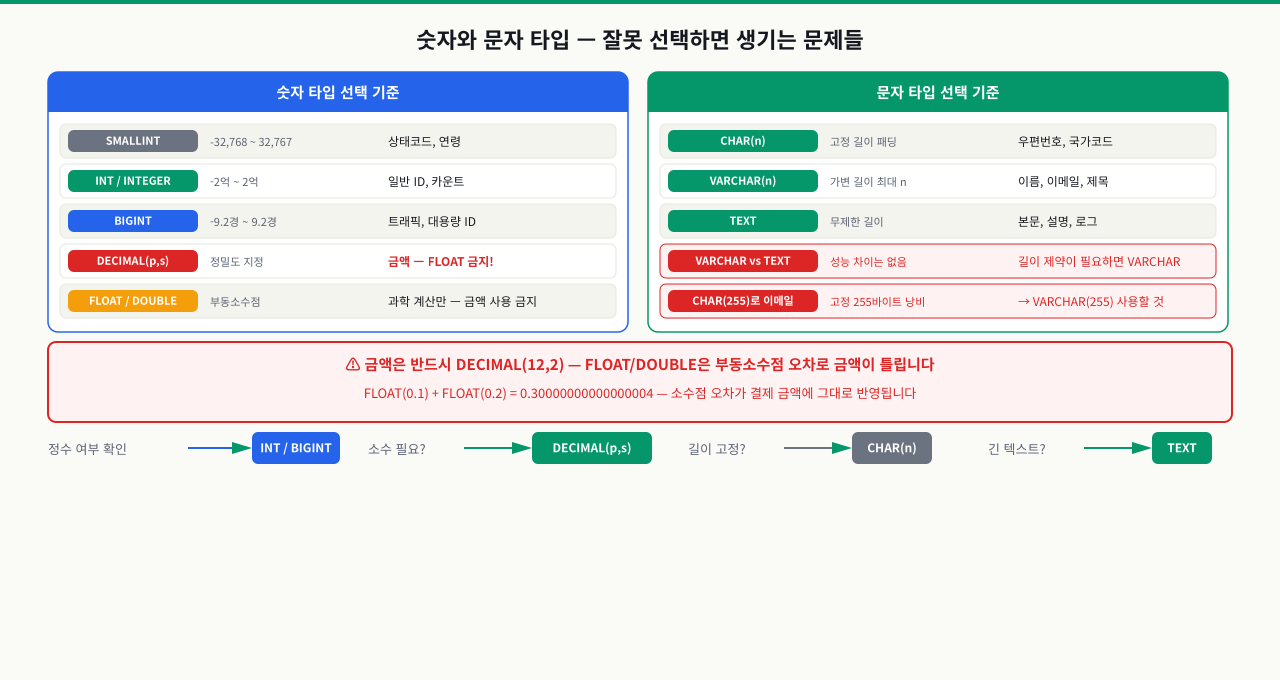
숫자와 문자 타입 — 잘못 선택하면 생기는 문제들
INT로 선언한 ID 컬럼이 21억을 넘었습니다. 더 이상 INSERT가 안 됩니다. 컬럼 타입을 BIGINT로 바꾸려면 수천만 건 테이블에서 ALTER가 몇 시간씩 걸리고, 그 사이 서비스는 멈춥니다. 처음부터 타입을 올바르게 선택하지 않으면 이 문제를 나중에 서비스 중단 없이 해결하기 어렵습니다.
 확대
확대
정수형 타입 범위
| 타입 | 크기 | 최솟값 | 최댓값 | 사용 예시 |
|---|---|---|---|---|
| SMALLINT | 2바이트 | -32,768 | 32,767 | 연령, 월, 소규모 카운터 |
| INT / INTEGER | 4바이트 | -2,147,483,648 | 2,147,483,647 | 일반 ID, 카운터 |
| BIGINT | 8바이트 | -9.2 × 10¹⁸ | 9.2 × 10¹⁸ | 대용량 ID, 타임스탬프(ms) |
| SERIAL | 4바이트 | 1 | 2,147,483,647 | 자동 증가 PK (INT + 시퀀스) |
| BIGSERIAL | 8바이트 | 1 | 9.2 × 10¹⁸ | 대용량 자동 증가 PK |
INT Overflow 실제 사례
2012년 Pinterest는 INT PK overflow 문제를 경험했습니다. 21억 개 이상의 레코드가 쌓이면 INT가 오버플로우하기 때문입니다. 아래는 잘못된 선택과 올바른 선택을 비교한 예시입니다. 미래가 불확실하다면 처음부터 BIGINT를 사용하는 것이 안전합니다.
CREATE TABLE posts (
id INT PRIMARY KEY
);
실행 완료 또는 조회 결과가 표시됩니다.
- INT PK 테이블에 SELECT max(id) FROM posts; 실행: 결과가 2,000,000,000(20억)에 근접하면 INT overflow 임박입니다. 이 시점에서 BIGINT로 ALTER는 테이블 재작성이 필요합니다. 신규 테이블은 처음부터 BIGSERIAL을 씁니다.
- DECIMAL과 FLOAT 오차 비교 확인: SELECT 0.1::FLOAT + 0.2::FLOAT = 0.3; 를 실행하면 false가 반환됩니다. 동일 계산을 DECIMAL로 바꾸면 true입니다. 금액 컬럼이 FLOAT으로 선언돼 있다면 이 쿼리 하나로 문제를 즉시 재현할 수 있습니다.
- 문자형 정렬 이상 감지: ORDER BY price를 실행했는데 '9', '10', '2' 순으로 정렬된다면 price 컬럼이 VARCHAR로 저장된 것입니다. 문자 정렬은 '1' < '2' < '9' < '10'이 아닌 사전순이어서 숫자 크기 비교가 틀어집니다.
- TIMESTAMPTZ vs TIMESTAMP 차이 확인: SET timezone = 'America/New_York'; 후 SELECT created_at FROM events LIMIT 1;을 실행해 TIMESTAMPTZ는 시간이 바뀌고 TIMESTAMP는 그대로면 타임존 변환이 올바르게 동작 중입니다.
CREATE TABLE posts (
id BIGSERIAL PRIMARY KEY
);
실수형: DECIMAL vs FLOAT
FLOAT과 DOUBLE은 IEEE 754 부동소수점 방식으로 소수를 이진 근사값으로 표현합니다. 이 때문에 SELECT 1.1 + 2.2를 실행하면 3.3000000000000003처럼 정밀도 오류가 발생합니다. 금액 컬럼에는 절대 FLOAT을 사용하면 안 됩니다. DECIMAL(NUMERIC)은 정확한 십진수 연산을 보장합니다.
DECIMAL(precision, scale)에서 precision은 전체 유효 숫자 개수이고, scale은 소수점 이하 자릿수입니다. 예를 들어 DECIMAL(12, 2)는 최대 9999999999.99까지 저장할 수 있습니다.
FLOAT/DOUBLE은 과학적 계산이나 통계 분석처럼 근사값이 허용되는 경우에만 사용합니다.
CREATE TABLE payments (
amount DECIMAL(15, 2) NOT NULL,
tax_rate DECIMAL(5, 4),
exchange_rate DECIMAL(10, 6)
);
CREATE TABLE sensor_readings (
temperature DOUBLE PRECISION,
humidity FLOAT
);
FLOAT 또는 DOUBLE 타입으로 금액 컬럼을 선언하면 IEEE 754 부동소수점 연산의 특성상 미세한 정밀도 오류가 누적됩니다. 수천~수만 건의 합산에서 오차가 커져 회계 불일치로 이어집니다.
해결 방법: 금액 컬럼은 항상 DECIMAL 또는 NUMERIC 타입을 사용하세요. 소수점 이하 2자리가 필요하면 DECIMAL(15, 2)가 표준적인 선택입니다.
문자형 타입 선택
세 가지 문자형 타입의 저장 방식은 다음과 같습니다.
CHAR(n): 고정 길이. 항상 n바이트를 사용합니다. 데이터가 n보다 짧으면 나머지를 공백으로 채웁니다.VARCHAR(n): 가변 길이. 최대 n글자까지 저장하며, 실제 문자열 길이 + 1~2바이트(길이 정보)만 사용합니다.TEXT: 가변 길이. 길이 제한이 없습니다.
길이가 항상 고정된 데이터(국가 코드, 통화 코드 등)에는 CHAR를, 최대 길이가 정해진 가변 데이터에는 VARCHAR를, 길이 제한 없는 긴 텍스트에는 TEXT를 사용합니다.
TEXT 컬럼에는 인덱스 크기 제한이 있으므로 전체 텍스트 검색이 필요하다면 전문 검색 기능을 사용해야 합니다.
CREATE TABLE products (
country_code CHAR(2) NOT NULL,
currency CHAR(3) NOT NULL,
name VARCHAR(100) NOT NULL,
email VARCHAR(255) NOT NULL,
title VARCHAR(500) NOT NULL,
description TEXT,
content TEXT
);
VARCHAR 길이 선택 가이드
아래는 실무에서 각 필드 유형에 권장되는 VARCHAR 크기입니다. RFC 표준이나 알고리즘 출력 길이가 고정된 경우는 그 값을 그대로 따릅니다.
| 필드 | 타입 | 근거 |
|---|---|---|
| VARCHAR(255) | RFC 5321 표준 최대 길이 | |
| username | VARCHAR(50) | 일반적인 서비스 제한 |
| password_hash | CHAR(60) | bcrypt 해시는 항상 60자 |
| phone | VARCHAR(20) | 국제 전화번호 포함 |
| url | VARCHAR(2048) | URL 최대 길이 고려 |
| ip_address | VARCHAR(45) | IPv6 포함 최대 45자 |
| country_code | CHAR(2) | ISO 3166-1 |
| currency_code | CHAR(3) | ISO 4217 |
| zip_code | VARCHAR(10) | 국가별 우편번호 최대 길이 |
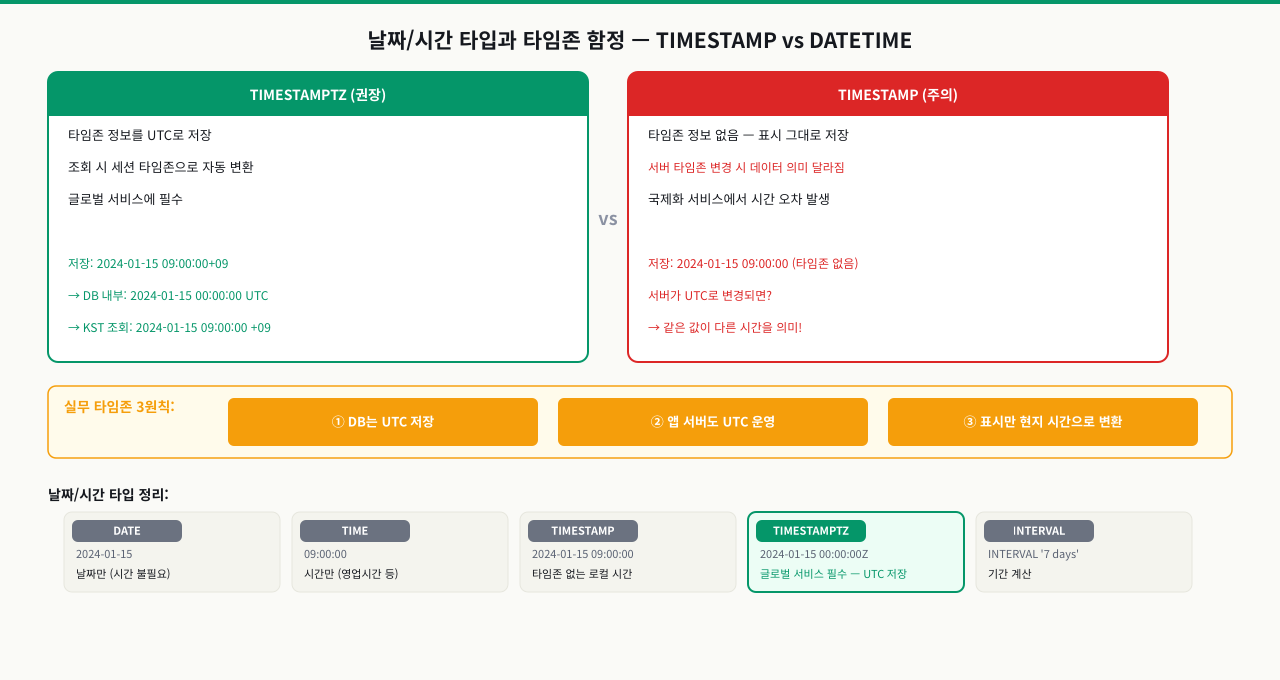
날짜/시간 타입과 타임존 함정 — TIMESTAMP vs DATETIME
한국 서버에서 정상적으로 저장된 시간이 미국 서버로 마이그레이션하자 9시간이 틀어졌습니다. DATETIME을 쓴 것이 원인이었습니다. TIMESTAMP와 DATETIME 중 어느 것을 쓰느냐에 따라 타임존 변환 동작이 완전히 다릅니다. 잘못 선택하면 글로벌 서비스에서 반드시 시간 버그가 발생합니다.
 확대
확대
날짜/시간 타입 비교
| 타입 | 크기 | 범위 | 타임존 |
|---|---|---|---|
| DATE | 4바이트 | 4713 BC ~ 5874897 AD | 없음 |
| TIME | 8바이트 | 00:00:00 ~ 24:00:00 | 없음 |
| TIMESTAMP | 8바이트 | 4713 BC ~ 294276 AD | 없음 |
| TIMESTAMPTZ | 8바이트 | 4713 BC ~ 294276 AD | UTC 변환 저장 |
| INTERVAL | 16바이트 | ±178,000,000년 | 해당없음 |
TIMESTAMP vs TIMESTAMPTZ 차이
TIMESTAMP는 타임존 정보가 없어 입력값을 그대로 저장합니다. 서울(UTC+9) 세션에서 15:00:00을 저장하면 그냥 15:00:00이 저장되고, 이 값이 어느 타임존의 15시인지 DB는 알 수 없습니다.
TIMESTAMPTZ(TIMESTAMP WITH TIME ZONE)는 입력값을 UTC로 변환해 저장하고, 조회 시 세션 타임존에 맞게 자동으로 변환해 돌려줍니다. 같은 15:00:00 KST 값이 내부적으로 06:00:00 UTC로 저장되고, 뉴욕 타임존으로 조회하면 02:00:00 EDT로 변환됩니다.
INSERT INTO events (created_at_tz)
VALUES ('2026-04-07 15:00:00');
SELECT created_at_tz FROM events;
타임존 함정은 말로 들으면 헷갈립니다. 한 테이블에 두 타입을 같이 두고, 세션 타임존을 서울→뉴욕으로 바꿔 조회하면 차이가 한눈에 드러납니다.
CREATE TABLE tz_demo (ts TIMESTAMP, tstz TIMESTAMPTZ);
SET TIME ZONE 'Asia/Seoul';
INSERT INTO tz_demo VALUES ('2026-04-07 15:00:00', '2026-04-07 15:00:00');
-- 같은 세션(서울)에서 조회
SELECT * FROM tz_demo;
-- 뉴욕 타임존으로 바꿔 다시 조회
SET TIME ZONE 'America/New_York';
SELECT * FROM tz_demo;
-- 서울 세션
ts | tstz
---------------------+------------------------
2026-04-07 15:00:00 | 2026-04-07 15:00:00+09
-- 뉴욕 세션 (ts는 그대로, tstz만 변환됨)
ts | tstz
---------------------+------------------------
2026-04-07 15:00:00 | 2026-04-07 02:00:00-04
SET TIME ZONE 'Asia/Seoul';- 두 번째(뉴욕) 조회에서 ts 열이 여전히 15:00:00 인지 본다 — TIMESTAMP는 타임존을 모르므로 글자 그대로 보존된다(= 위험 신호: 어느 지역 15시인지 알 수 없음)
- 같은 행에서 tstz 열이 02:00:00-04 로 바뀌었는지 확인한다 — TIMESTAMPTZ는 UTC로 저장 후 세션 타임존(-04)으로 자동 변환한다. 이게 정상
- tstz 값 끝의 +09 / -04 오프셋 표기가 보이면 타임존 인식 타입이 맞다. ts에는 오프셋이 없다
- 결론 판단: 생성·수정 시각이면 tstz처럼 오프셋이 붙고 지역따라 변환되는 컬럼이어야 한다. ts처럼 고정돼 보이면 글로벌 서비스에서 버그다
TIMESTAMP 타입을 사용하면 저장된 값에 타임존 정보가 없습니다. 서버 타임존을 변경하거나 글로벌 사용자가 늘어나면 동일한 데이터가 지역마다 다르게 해석됩니다.
해결 방법: 레코드 생성/수정 시간은 항상 TIMESTAMPTZ를 사용하고 UTC로 저장하세요. 생년월일처럼 순수한 날짜 데이터는 DATE를 사용합니다. 글로벌 서비스라면 TIMESTAMP는 사용하지 않는 것이 원칙입니다.
날짜 타입 실무 패턴
생년월일이나 이벤트 날짜처럼 특정 날짜만 필요한 경우에는 DATE를 사용합니다. 레코드의 생성/수정 시각에는 TIMESTAMPTZ가 맞습니다. updated_at은 UPDATE가 발생할 때마다 자동으로 갱신되도록 트리거를 걸어 두는 것이 일반적입니다.
CREATE TABLE users (
birthdate DATE,
joined_on DATE NOT NULL DEFAULT CURRENT_DATE
);
CREATE TABLE products (
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
날짜 연산에는 EXTRACT와 INTERVAL을 활용합니다. 기간별 집계에는 DATE_TRUNC로 날짜를 월/주 단위로 잘라 GROUP BY에 사용합니다.
SELECT
EXTRACT(YEAR FROM age(birthdate)) AS age,
birthdate + INTERVAL '18 years' AS adult_date
FROM users;
SELECT
DATE_TRUNC('month', created_at) AS month,
COUNT(*) AS orders_count
FROM orders
GROUP BY 1
ORDER BY 1;
특수 타입 정리
BOOLEAN은 TRUE, FALSE, NULL 세 가지 값을 가집니다. 기본값을 반드시 명시하는 것이 좋습니다.
UUID는 분산 환경에서 충돌 없이 전역 고유 ID가 필요할 때 사용합니다. 16바이트(INT의 4배)이므로 내부 PK는 BIGINT, 외부 노출용으로 UUID를 별도 컬럼에 두는 패턴을 권장합니다.
JSONB는 JSON을 바이너리로 저장해 인덱스를 지원하고 조회 속도가 빠릅니다. JSON은 텍스트로 저장하며 입력 순서를 보존하지만 인덱스를 사용할 수 없어 일반적으로 JSONB를 권장합니다.
ENUM은 컬럼 값을 특정 문자열 집합으로 제한합니다. 단, 값 추가/변경이 번거롭기 때문에 CHECK 제약이 더 유연한 대안이 될 수 있습니다.
CREATE TABLE users (
is_active BOOLEAN NOT NULL DEFAULT TRUE,
is_verified BOOLEAN NOT NULL DEFAULT FALSE,
metadata JSONB DEFAULT '{}'
);
CREATE TYPE order_status AS ENUM ('pending', 'paid', 'shipped', 'delivered', 'cancelled');
CREATE TABLE orders (
status order_status NOT NULL DEFAULT 'pending'
);
결제 서비스를 개발할 때 amount 컬럼을 FLOAT으로 선언하면 수천 건의 정산 합산에서 1~2원의 오차가 발생해 회계 불일치 문제가 생깁니다. 실무에서는 DECIMAL(15, 2)를 표준으로 사용합니다.
마찬가지로 created_at을 TIMESTAMP로 선언한 서비스가 글로벌로 확장될 때 기존 데이터 마이그레이션 비용이 발생합니다. 처음부터 TIMESTAMPTZ를 사용하면 DB가 타임존 변환을 자동으로 처리하므로 애플리케이션 레이어에서 별도 변환 로직이 필요 없습니다.
이 두 가지 타입 선택만 올바르게 해도 나중에 발생하는 대규모 데이터 마이그레이션을 예방할 수 있습니다.
심화 — 타입은 디스크와 인덱스 위에 산다
심화: 타입 크기와 순서가 B-트리 인덱스를 좌우한다
타입 선택은 '정확성' 이야기로 끝나지 않습니다. 컬럼 타입의 물리 크기와 값의 순서(정렬성)는 B-트리 인덱스의 모양과 삽입 패턴을 직접 좌우합니다. 특히 PK/인덱스 키에서 이 차이가 성능으로 드러납니다.
- 크기: 좁은 타입일수록 한 페이지에 더 많은 키가 들어가 fanout이 커지고 트리 레벨이 낮아져, 조회 시 읽는 페이지가 줄어듭니다. INT(4B) PK 인덱스가 UUID(16B) 인덱스보다 작고 빠른 근본 이유입니다.
- 순서: 크기보다 삽입 순서가 더 중요할 때가 많습니다. 증가하는 키(
BIGSERIAL,UUID v7)는 항상 B-트리의 오른쪽 끝에 추가돼 페이지가 순차로 차고 분할이 드뭅니다. 무작위 키(UUID v4)는 트리 곳곳에 삽입돼 페이지 분할(page split)이 잦고, 매번 다른 페이지를 건드려 캐시 지역성이 나빠지며, 변경 페이지가 WAL에 통째로 기록돼(full page write) 쓰기가 증폭됩니다. - 부가 효과: 큰 값은 TOAST로 별도 저장·압축되고, 타입마다 정렬(alignment) 패딩이 붙어 실제 저장 크기가 달라집니다.
그래서 '분산 환경 대비 UUID'처럼 타입을 고를 때도, 그 타입이 인덱스 위에서 어떻게 삽입되는지를 함께 따져야 합니다.
상황: 분산 환경 대비로 PK를 UUID v4로 잡았습니다. 초기엔 문제가 없다가 수천만 건이 되자 INSERT 처리량이 점점 떨어지고, PK 인덱스가 비정상적으로 커졌습니다(테이블 데이터보다 큰 경우도).
원인: UUID v4는 무작위 값이라 새 행이 PK B-트리의 예측 불가한 위치에 삽입됩니다. 이 무작위 삽입이 페이지 분할을 자주 일으키고, 매번 다른 페이지를 건드려 캐시 적중률이 떨어지며(랜덤 I/O), 변경된 페이지 전체가 WAL에 기록돼 쓰기가 증폭됩니다. 증가형 키였다면 항상 끝에 순차로 쌓여 이런 비용이 거의 없습니다.
진단: PK 컬럼 타입이 UUID(v4)인지 확인하고, pg_relation_size로 인덱스와 테이블 크기를 비교합니다(인덱스가 과도하게 크면 부풀기 신호). 삽입 시 랜덤 I/O·WAL 증가 추세, 시간에 따른 INSERT throughput 저하를 함께 봅니다.
해결: 시간순으로 정렬되는 UUID v7(또는 ULID)로 바꾸면 무작위 삽입 문제가 대부분 사라집니다. 또는 내부 PK는 BIGSERIAL로 두고 외부 노출용 UUID는 별도 컬럼(+유니크 인덱스)에 둡니다. 이미 v4가 쌓였다면 REINDEX로 부풀기를 일시적으로 줄일 수 있지만, 삽입 패턴 자체를 바꾸는 것이 근본 해결입니다(B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건).
명령어·구문 빠른 참조
이 모듈에서 다룬 데이터 타입과 그 선언·연산 구문을 실전 조합과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
INT vs BIGINT | 정수 범위 선택(오버플로 예방) | 대량 PK·카운터는 BIGINT(약 ±922경) |
SERIAL / BIGSERIAL | 자동 증가 PK | id BIGSERIAL PRIMARY KEY |
DECIMAL(p, s) / NUMERIC | 금액 등 정확한 십진 계산 | amount DECIMAL(15, 2)(금액에 FLOAT 금지) |
FLOAT / DOUBLE PRECISION | 근사값 허용 과학·통계값 | temperature DOUBLE PRECISION |
CHAR(n) / VARCHAR(n) / TEXT | 고정·가변·무제한 문자열 | country_code CHAR(2), name VARCHAR(100), description TEXT |
DATE / TIMESTAMP / TIMESTAMPTZ | 날짜·시간·타임존 인식 시각 | 생성시각은 TIMESTAMPTZ(UTC 저장·세션 변환) |
SET TIME ZONE | 세션 타임존 변경(변환 확인) | SET TIME ZONE 'America/New_York' |
EXTRACT / INTERVAL / age() | 날짜 연산 | birthdate + INTERVAL '18 years', age(birthdate) |
DATE_TRUNC('month', ...) | 기간 단위 절삭 후 GROUP BY | DATE_TRUNC('month', created_at) |
BOOLEAN / JSONB | 참·거짓 / 인덱스 가능한 JSON | is_active BOOLEAN DEFAULT TRUE, metadata JSONB |
CREATE TYPE ... AS ENUM | 값을 특정 문자열 집합으로 제한 | CREATE TYPE order_status AS ENUM ('pending', ...) |
UUID (v4 vs v7) | 전역 고유 ID(삽입 패턴 주의) | 순차형 UUID v7/ULID로 무작위 삽입 회피 |
관련 모듈로 더 깊이:
- 테이블, 스키마, 로우(Row), 컬럼(Column) 용어 완벽 가이드 — 타입을 부여할 컬럼이 속하는 테이블·스키마 구조의 기초
- JSONB 비정형 데이터 다루기와 전문 검색(Full-text Search) — JSONB, ENUM, TIMESTAMPTZ 등 PostgreSQL 고유 타입을 더 깊이
- IS NULL, COALESCE, NULLIF 함수의 함정과 안전한 처리 방법 — 컬럼 타입과 함께 결정해야 하는 NULL 허용 여부의 함정
다음 모듈에서는 PK, FK 제약조건과 CASCADE 삭제 설정이 데이터 정합성에 미치는 영향을 다룹니다.