JSON 형태의 데이터를 그대로 저장하고 싶을 때 Document DB가 매력적으로 보입니다. 하지만 유연한 스키마는 검증 책임이 애플리케이션으로 이동한다는 뜻이기도 합니다. 문서형 DB의 장단점을 알아야 빠른 개발과 데이터 품질 사이에서 균형을 잡을 수 있습니다.
MongoDB는 RDBMS의 테이블 대신 컬렉션(Collection)에 JSON 유사 문서(Document)를 저장합니다. 핵심 설계 결정은 임베딩(데이터를 문서 내에 포함)과 참조(ID를 저장하고 별도 컬렉션 조회) 중 선택입니다. 접근 패턴을 먼저 정의하고 거기에 맞게 스키마를 설계하는 것이 MongoDB 방식입니다.
- 1Collection, Document, BSON 같은 MongoDB 핵심 개념을 설명할 수 있다
- 2스키마리스의 진짜 의미를 이해하고 유연성과 책임의 트레이드오프를 판단할 수 있다
- 3임베딩과 참조를 선택 기준에 따라 구분해 설계할 수 있다
- 4기본 CRUD 연산과 쿼리 연산자로 문서를 조작할 수 있다
- 5$match, $group, $lookup으로 Aggregation Pipeline을 작성할 수 있다
- 6언제 MongoDB를 선택하고 언제 피해야 하는지 판단할 수 있다
Document DB (MongoDB) — 임베딩 vs 참조, 언제 선택하는가
쇼핑몰 상품 데이터를 PostgreSQL로 설계하다가 막혔다. 상품마다 속성이 달랐다 — 티셔츠는 색상·사이즈, 노트북은 CPU·RAM·SSD, 식품은 유통기한·알레르기. 테이블 하나로 못 담아서 결국 attributes 컬럼에 JSON 문자열을 때려박기 시작했다. 조회할 때마다 파싱하고, 인덱스도 못 걸고, 스키마 변경할 때마다 마이그레이션이 고통이었다. 그때 MongoDB를 써보고 처음으로 "이게 맞는 도구구나"라는 감각이 왔다. 문서마다 다른 구조를 자연스럽게 담고, 중첩 객체로 관련 데이터를 한 덩어리로 묶으니 상품 조회가 JOIN 없이 한 번에 끝났다. RDBMS가 나쁜 게 아니라 — 데이터 구조가 유연하고 함께 읽히는 데이터가 명확할 때는 Document DB가 훨씬 적합한 선택이다.
실행 결과를 확인할 수 있는 DB 콘솔 출력이 표시됩니다.
- 먼저 _id 필드를 확인합니다. ObjectId가 자동 생성됐는지, 삽입 시각이 ObjectId에 인코딩됐는지 확인합니다 — ObjectId 앞 4바이트가 Unix timestamp이므로 생성 순서 추적이 가능합니다.
- 도큐먼트 크기를 주시합니다. 임베딩 배열 길이가 100개를 초과하기 시작하면 16MB 제한에 근접하는 것입니다 — 이 시점에 참조(Reference) 방식으로 전환 여부를 검토하세요.
- find() 결과에 explain() 을 붙여 winningPlan을 확인합니다. COLLSCAN이면 인덱스 미사용 전체 컬렉션 스캔입니다 — IXSCAN이 나타나야 인덱스가 활용되고 있는 것입니다.
MongoDB 문서 모델 — RDBMS와 다른 설계 철학
상품 정보를 저장해야 하는데 상품마다 속성 개수가 다릅니다. 가전제품은 전압·용량이 필요하고, 의류는 사이즈·소재가 필요합니다. RDBMS에서는 공통 컬럼 외 나머지를 어떻게 저장할지 설계가 복잡해집니다. MongoDB는 문서마다 구조가 달라도 되는 유연한 모델을 제공합니다. 단, RDBMS와 설계 철학이 근본적으로 다르기 때문에 관계형 사고로 MongoDB를 쓰면 성능 문제가 생깁니다.
 확대
확대
RDBMS vs MongoDB 용어 비교
MongoDB는 RDBMS와 개념이 대응되지만 이름이 다릅니다. 가장 중요한 차이는 JOIN 대신 임베딩을 기본으로 사용하고, 스키마를 DB가 아닌 애플리케이션이 관리한다는 점입니다.
| RDBMS | MongoDB | 설명 |
|---|---|---|
| Database | Database | 동일 |
| Table | Collection | 행/문서의 집합 |
| Row | Document | 하나의 데이터 단위 |
| Column | Field | 데이터 속성 |
| Primary Key | _id | 자동 생성되는 ObjectId |
| JOIN | $lookup (또는 임베딩) | 관련 데이터 결합 |
| Index | Index | 동일한 목적 |
| View | View | 동일 (MongoDB 3.4+) |
BSON 문서 구조
MongoDB는 JSON의 이진 인코딩인 BSON(Binary JSON) 형식으로 데이터를 저장합니다. ObjectId는 12바이트 자동 생성 ID로, 생성 시각·머신 ID·프로세스 ID·카운터로 구성되어 분산 환경에서도 충돌이 없습니다. 배열, 중첩 문서, 날짜 타입 등을 네이티브로 지원합니다.
{
"_id": ObjectId("65a1b2c3d4e5f67890123456"),
"title": "MongoDB 설계 패턴",
"slug": "mongodb-design-patterns",
"author": {
"userId": ObjectId("..."),
"name": "김개발",
"avatar": "https://cdn.example.com/avatars/1.jpg"
},
"tags": ["mongodb", "database", "nosql"],
"status": "published",
"viewCount": 1523,
"publishedAt": ISODate("2024-03-15T09:00:00Z"),
"metadata": {
"readTime": 8,
"wordCount": 2400
}
}
스키마리스의 진짜 의미
MongoDB는 컬렉션에 문서를 추가할 때 스키마를 사전에 정의하지 않아도 됩니다. 같은 컬렉션 안의 문서들이 서로 다른 필드를 가져도 됩니다. 이는 유연하지만 책임이 따릅니다. 스키마 검증은 애플리케이션 코드나 MongoDB의 Schema Validation 기능이 담당합니다.
{ "_id": 1, "name": "노트북", "brand": "삼성", "ram_gb": 16 }
{ "_id": 2, "name": "셔츠", "brand": "유니클로", "size": "L", "color": "white" }
{ "_id": 3, "name": "책", "title": "MongoDB 완벽 가이드", "isbn": "978-..." }
MongoDB의 Schema Validation으로 최소한의 구조를 강제할 수 있습니다.
db.createCollection("users", {
validator: {
$jsonSchema: {
required: ["email", "name"],
properties: {
email: { type: "string", pattern: "^.+@.+$" },
age: { type: "int", minimum: 0, maximum: 150 }
}
}
}
});
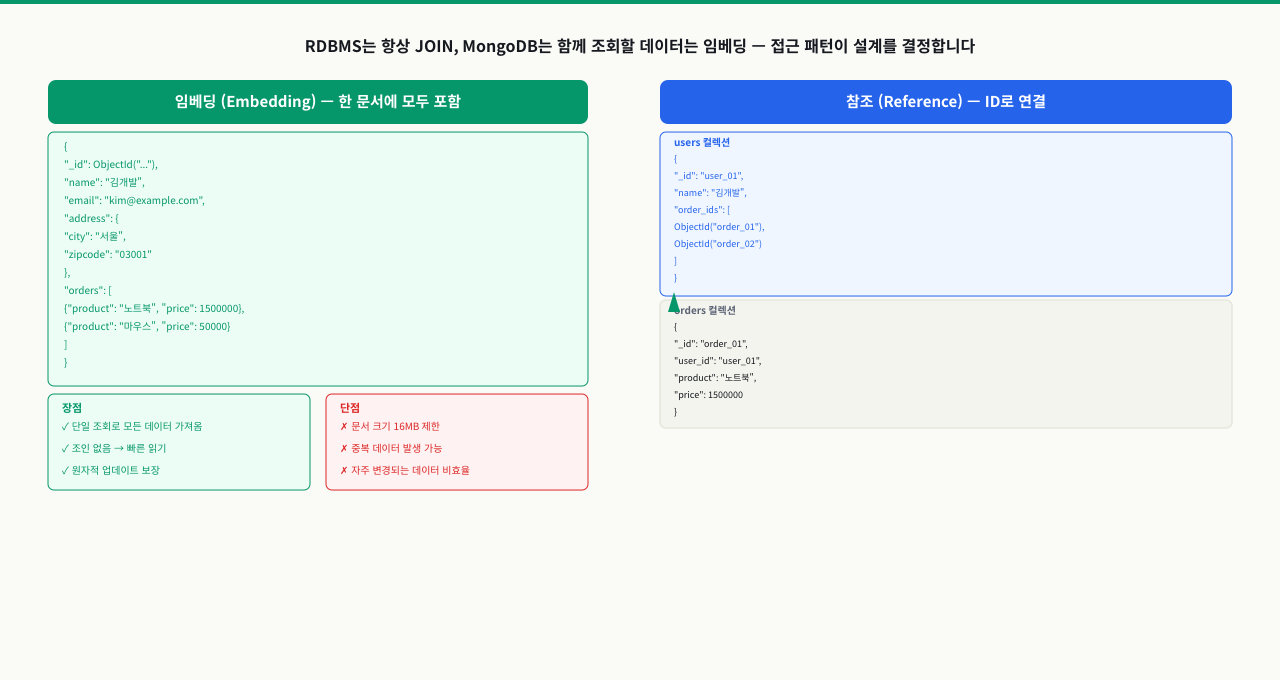
임베딩 vs 참조 — 의사결정 표
MongoDB 스키마 설계의 핵심 질문은 "관련 데이터를 같은 문서에 넣을 것인가(임베딩), 아니면 별도 컬렉션에 두고 ID로 참조할 것인가(참조)"입니다. 접근 패턴을 먼저 파악하고 그에 맞게 결정하세요.
| 기준 | 임베딩 선택 | 참조 선택 |
|---|---|---|
| 조회 패턴 | 항상 함께 조회 | 독립적으로 접근 필요 |
| 데이터 크기 | N이 작고 고정적 | N이 무한히 증가 가능 |
| 읽기/쓰기 비율 | 읽기 위주 | 자주 업데이트 필요 |
| 공유 여부 | 한 부모에만 속함 | 여러 문서에서 공유 |
| 관계 유형 | 1:1, 제한된 1:N | N:M, 대규모 1:N |
임베딩 예시로 주문 항목은 주문 문서와 항상 함께 조회되고, 항목 수가 현실적으로 제한되므로 임베딩이 적합합니다.
{
"_id": ObjectId("..."),
"orderId": "ORD-2024-001",
"customerId": ObjectId("..."),
"status": "delivered",
"orderItems": [
{ "productId": "P001", "name": "노트북", "qty": 1, "price": 1200000 },
{ "productId": "P002", "name": "마우스", "qty": 2, "price": 35000 }
],
"totalAmount": 1270000,
"createdAt": ISODate("2024-03-15")
}
참조 예시로 댓글은 무한히 증가할 수 있으므로 별도 컬렉션으로 분리합니다.
{ "_id": ObjectId("article_001"), "title": "MongoDB 설계 패턴" }
{ "_id": ObjectId("..."), "articleId": ObjectId("article_001"), "body": "좋은 글이에요" }
{ "_id": ObjectId("..."), "articleId": ObjectId("article_001"), "body": "감사합니다" }
소셜 피드 서비스에서 게시글 문서에 댓글을 배열로 임베딩하면 초기에는 잘 동작합니다. 그러나 인기 게시글에 수천, 수만 개의 댓글이 쌓이면 단일 문서가 16MB 제한에 도달해 BSONObjectTooLarge 오류가 발생합니다. 문서가 커질수록 업데이트 성능도 저하됩니다.
해결책은 댓글을 별도 comments 컬렉션으로 분리하고 articleId로 참조하는 것입니다. 댓글 수가 많아도 문서 크기 문제가 없고, 페이지네이션도 자연스럽게 구현됩니다. 마이그레이션 시에는 기존 임베딩 댓글을 읽어 comments 컬렉션에 벌크 삽입하고, 게시글 문서에서 댓글 배열을 제거하면 됩니다.
소셜 피드 서비스를 설계할 때 댓글 처리 방식은 서비스 규모와 접근 패턴에 따라 다릅니다.
작은 커뮤니티 서비스에서 게시글당 댓글이 평균 10개 미만이고 "게시글과 최신 댓글 3개"를 항상 함께 보여주는 UI라면, 제한적 임베딩(최근 N개만 임베딩, 나머지는 참조)을 고려할 수 있습니다. 반면 트위터나 인스타그램처럼 인기 게시글에 댓글이 수만 개가 달릴 수 있는 서비스라면 처음부터 참조 방식으로 설계해야 합니다.
일반적인 권장 기준은 댓글 수가 현실적으로 100개를 초과할 가능성이 있다면 참조를 선택하는 것입니다. 나중에 임베딩에서 참조로 마이그레이션하는 것보다 처음부터 참조로 설계하는 편이 훨씬 안전합니다.
MongoDB 기본 CRUD와 Aggregation Pipeline
MongoDB CRUD를 처음 쓰는데 업데이트 후 문서 전체가 바뀌었습니다. $set을 빠뜨리고 업데이트하면 기존 필드가 모두 날아가는 MongoDB 고유 동작을 몰랐던 겁니다. 집계 쿼리는 SQL의 GROUP BY처럼 쓰려고 했는데 Aggregation Pipeline이라는 전혀 다른 개념이 등장합니다. MongoDB의 CRUD와 집계 문법은 처음엔 낯설지만 패턴을 익히면 강력한 데이터 처리가 가능합니다.
 확대
확대
기본 CRUD 연산
MongoDB CRUD의 핵심은 연산자 접두사입니다. 쿼리 연산자($gte, $in 등)는 조건을 표현하고, 업데이트 연산자($set, $inc, $push)는 변경 방식을 지정합니다. $set 없이 업데이트하면 문서 전체가 교체되므로 주의하세요.
db.products.insertOne({
name: "무선 키보드",
brand: "로지텍",
price: 89000,
stock: 150,
tags: ["keyboard", "wireless"],
createdAt: new Date()
});
db.products.insertMany([
{ name: "마우스", price: 45000, stock: 200 },
{ name: "헤드셋", price: 120000, stock: 80 }
]);
db.products.find({
price: { $gte: 50000, $lte: 200000 },
stock: { $gt: 0 },
tags: { $in: ["keyboard", "mouse"] }
});
db.products.find(
{ brand: "로지텍" },
{ name: 1, price: 1, _id: 0 }
);
db.products.find({ stock: { $gt: 0 } })
.sort({ price: -1 })
.skip(20)
.limit(10);
db.products.updateOne(
{ _id: ObjectId("...") },
{ $set: { price: 95000, updatedAt: new Date() } }
);
db.products.updateOne(
{ _id: ObjectId("...") },
{ $inc: { stock: 50 } }
);
db.articles.updateOne(
{ _id: ObjectId("...") },
{ $push: { tags: "performance" } }
);
db.products.updateMany(
{ brand: "로지텍" },
{ $set: { brand: "Logitech" } }
);
db.products.deleteOne({ _id: ObjectId("...") });
db.products.deleteMany({ stock: 0, discontinued: true });
MongoDB 초보가 가장 많이 내는 사고가 $set 누락입니다. 문서를 넣고 → $set으로 일부 필드만 바꾸고 → $set 없이 바꿔보며, 후자가 문서를 통째로 교체해 다른 필드가 사라지는지 mongosh에서 확인합니다.
db.products.insertOne({ name: "무선 키보드", brand: "로지텍", price: 89000, stock: 150 });
// (정상) $set — price만 변경, 나머지 보존
db.products.updateOne({ name: "무선 키보드" }, { $set: { price: 95000 } });
db.products.findOne({ name: "무선 키보드" });
// (함정) $set 없이 — 문서 전체가 { price: 99000 } 로 교체됨!
db.products.updateOne({ name: "무선 키보드" }, { price: 99000 });
db.products.findOne({ price: 99000 });
// $set 사용 후 — 모든 필드 유지
{ _id: ObjectId("..."), name: '무선 키보드', brand: '로지텍', price: 95000, stock: 150 }
// $set 누락 후 — name·brand·stock 전부 사라짐
{ _id: ObjectId("..."), price: 99000 }
db.products.updateOne({ name: '무선 키보드' }, { $set: { price: 95000 } })- $set 사용 후 findOne 결과에 brand·stock 등 안 건드린 필드가 그대로 남아 있는지 본다 — 남아 있어야 정상(부분 업데이트)
- $set 없이 업데이트한 뒤 문서에 price만 남고 나머지가 사라졌는지 확인 — 사라졌다면 '문서 전체 교체'가 일어난 것(가장 흔한 데이터 유실 사고)
- updateOne 반환의 matchedCount/modifiedCount를 본다 — matched=1 인데 modified=0 이면 값이 이미 같아 변경이 없었던 것(필터는 맞았다는 뜻)
- find 조건의 $gte/$in 같은 연산자에 $가 빠지면 '필드명'으로 해석돼 0건이 나온다 — 결과가 비면 연산자 접두사부터 의심
Aggregation Pipeline
Aggregation Pipeline은 여러 단계를 순서대로 통과시키며 데이터를 변환·집계합니다. 각 단계의 출력이 다음 단계의 입력이 됩니다. $match는 항상 파이프라인 앞쪽에 두어 처리할 문서 수를 먼저 줄이세요.
db.products.aggregate([
{ $match: { stock: { $gt: 0 } } },
{ $group: {
_id: "$brand",
avgPrice: { $avg: "$price" },
totalStock: { $sum: "$stock" },
productCount: { $sum: 1 }
}},
{ $project: {
brand: "$_id",
avgPrice: { $round: ["$avgPrice", 0] },
totalStock: 1,
productCount: 1,
_id: 0
}},
{ $sort: { avgPrice: -1 } }
]);
$lookup은 다른 컬렉션과 조인을 수행합니다. RDBMS의 LEFT OUTER JOIN과 유사합니다. $lookup이 파이프라인에 자주 등장한다면 스키마 설계에 임베딩을 더 활용할 여지가 있는지 재검토하세요.
db.orders.aggregate([
{ $match: { status: "completed", createdAt: { $gte: new Date("2024-01-01") } } },
{
$lookup: {
from: "customers",
localField: "customerId",
foreignField: "_id",
as: "customer"
}
},
{ $unwind: "$customer" },
{ $project: {
orderId: 1,
totalAmount: 1,
"customer.name": 1,
"customer.email": 1
}}
]);
인덱스 생성
MongoDB 인덱스는 RDBMS와 동일한 원칙이 적용됩니다. 자주 쓰는 쿼리 조건과 정렬 필드에 복합 인덱스를 만드세요. TTL 인덱스는 세션, 임시 토큰처럼 자동으로 만료해야 하는 데이터에 유용합니다.
db.products.createIndex({ price: 1 });
db.orders.createIndex({ customerId: 1, createdAt: -1 });
db.articles.createIndex({ title: "text", content: "text" });
db.articles.find({ $text: { $search: "MongoDB 성능" } });
db.sessions.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 });
db.orders.getIndexes();
언제 MongoDB를 선택하는가
MongoDB가 유리한 상황과 RDBMS가 더 적합한 상황을 명확히 구분해야 합니다. 기술 선택은 팀의 익숙함보다 데이터 특성과 접근 패턴이 우선입니다.
| MongoDB가 유리 | RDBMS가 유리 |
|---|---|
| 스키마가 자주 바뀌는 MVP | 복잡한 비즈니스 트랜잭션 (결제, 재고) |
| 계층적/중첩 구조 데이터 | 강한 데이터 일관성과 FK 무결성 필수 |
| 지리 위치 데이터 | 복잡한 다중 테이블 조인이 빈번한 경우 |
| 로그, 이벤트, 실시간 분석 | 집계 및 리포팅 중심 워크로드 (OLAP) |
| 수평 샤딩이 필요한 대용량 | 트랜잭션 롤백이 빈번한 경우 |
문서를 넣고 꺼내면 실제로 무슨 일이 — 삽입부터 조회까지 5단계
insertOne 한 줄로 아무 구조나 넣고 find 한 줄로 꺼내지지만, 그 사이 MongoDB는 정해진 경로를 거칩니다. 이 경로를 모르면 "왜 이 쿼리는 느리지", "인덱스를 만들었는데 왜 안 빠르지"를 설명하지 못합니다. 문서 저장·조회는 문서(JSON) 삽입 → BSON으로 컬렉션 저장 → 인덱스 반영 → 쿼리 플래너 판단 → IXSCAN 또는 COLLSCAN이라는 단계의 결과입니다.
[삽입] db.products.insertOne({ ... })
│
① 문서 삽입 — 스키마 검사 없이 받는다(스키마리스) (_id 없으면 ObjectId 자동 생성)
│
② 컬렉션 저장 — JSON을 BSON(이진)으로 인코딩해 저장 (중첩·배열·날짜를 네이티브로)
│
③ 인덱스 반영 — 인덱스 걸린 필드는 B-tree에도 함께 기록 (없으면 데이터만 쌓임)
│
──[조회] db.products.find({ ... }).sort({ ... })
│
④ 플래너 판단 — 쿼리 조건에 쓸 인덱스가 있는지 후보 평가
│
⑤ 실행 — 인덱스 있으면 IXSCAN(좁게), 없으면 COLLSCAN(전수)
│ → 프로젝션으로 필요한 필드만 추려 반환
▼
[결과] IXSCAN=빠름 / COLLSCAN=데이터 늘수록 선형으로 느려짐
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 삽입 | DB가 구조를 강제하지 않고 문서를 그대로 받는다. _id가 없으면 ObjectId 자동 부여 | 스키마 책임이 앱으로 이동 → 필드명을 코드에서 바꾸면 옛 문서와 불일치(마이그레이션 필요) |
| ② 저장 | JSON을 BSON으로 인코딩해 컬렉션에 저장. 임베딩 배열도 한 문서 안에 통째로 | 임베딩 배열이 무한정 커지면 16MB 한도 초과(BSONObjectTooLarge) → 참조로 분리 |
| ③ 인덱스 반영 | createIndex한 필드는 쓰기마다 B-tree에도 반영된다 | 인덱스가 없으면 조회가 뒤에서 전수 스캔(COLLSCAN)으로 떨어짐 |
| ④ 플래너 판단 | 쿼리 필터·정렬을 보고 쓸 인덱스 후보를 평가·선택 | 조건 필드에 인덱스가 없거나 연산자 접두사 $를 빠뜨리면 인덱스를 못 씀 |
| ⑤ 실행 | 인덱스가 맞으면 IXSCAN으로 좁게, 아니면 COLLSCAN으로 전수 스캔 후 프로젝션 | 정렬이 인덱스 순서와 안 맞으면 메모리 SORT → 데이터 늘면 Sort exceeded memory limit |
즉 "느린 쿼리"의 정체는 대부분 ③·④·⑤에 있습니다 — 인덱스가 없어 COLLSCAN으로 떨어지거나, 인덱스는 있어도 정렬 순서가 안 맞아 메모리에서 정렬이 터지는 것입니다. find(...).explain("executionStats")의 winningPlan에서 COLLSCAN인지 IXSCAN인지, IXSCAN 위에 SORT 스테이지가 얹혔는지를 보면 어느 단계에서 어긋났는지 바로 드러납니다. 복합 인덱스의 컬럼 순서(등호·정렬·범위)를 맞추는 ESR 규칙은 바로 아래 심화에서 다룹니다.
심화 — 있는 인덱스가 정렬을 못 살릴 때
심화: 복합 인덱스 순서와 ESR 규칙 — 인덱스가 있어도 정렬은 메모리에서 터진다
COLLSCAN을 없앴다고 끝이 아닙니다. find()가 인덱스를 타는데도 정렬이 포함되면 갑자기 느려지거나 오류가 나기도 합니다. 문제는 인덱스가 있느냐가 아니라, 인덱스 컬럼 순서가 쿼리의 등호·정렬·범위와 맞느냐입니다.
MongoDB 복합 인덱스 설계의 실무 원칙이 ESR(Equality, Sort, Range)입니다 — 인덱스 앞쪽부터 등호(Equality) 필드 → 정렬(Sort) 필드 → 범위(Range) 필드 순으로 배치합니다.
- 등호가 앞:
status같은 등호 조건이 인덱스 앞쪽에 있어야 스캔 구간이 한 점으로 좁혀집니다. - 정렬이 가운데: 정렬 필드가 등호 바로 뒤에 오면 인덱스가 이미 그 순서로 정렬돼 있어, 추가 정렬 단계(in-memory SORT) 없이 인덱스를 그대로 훑어 반환합니다.
- 범위가 뒤:
createdAt범위 조건은 맨 뒤에 둡니다. 범위 필드 뒤에 오는 인덱스 컬럼은 정렬에 활용되지 못하기 때문입니다 — 범위가 정렬보다 앞서면 정렬이 다시 메모리로 넘어갑니다.
정렬이 인덱스로 처리되지 못하면 MongoDB는 결과를 메모리에 모아 정렬하는데, 이 in-memory 정렬은 기본 상한(32MB, 최신 버전 100MB)을 넘으면 아예 실패합니다. 인덱스 컬럼 순서 하나가 빠른 인덱스 정렬과 정렬 실패 오류를 가르는 셈입니다.
// status(등호) → createdAt(정렬) 순 — SORT 스테이지 없이 인덱스가 정렬까지 제공
db.orders.createIndex({ status: 1, createdAt: -1 });
db.orders.find({ status: "active", createdAt: { $gt: ISODate("2024-01-01") } })
.sort({ createdAt: -1 })
.explain("executionStats");
explain()의 winningPlan에서 IXSCAN 위에 SORT 스테이지가 얹혀 있다면, 정렬이 인덱스를 못 타고 메모리에서 처리되고 있다는 신호입니다.
상황: 상태와 기간으로 거른 뒤 최신순으로 정렬하는 목록 API가, 데이터가 쌓이자 느려지더니 어느 시점부터 정렬 관련 오류로 실패하기 시작했습니다. 인덱스는 분명히 걸려 있습니다.
원인: 인덱스가 범위·정렬 필드를 앞에, 등호 필드를 뒤에 둔 순서(예: createdAt 먼저, status 나중)였습니다. 인덱스로 후보 문서를 찾을 수는 있지만 등호 조건이 뒤라 스캔 범위가 넓고, 정렬 순서도 인덱스가 보장하지 못해 결과를 메모리에 모아 다시 정렬합니다. 문서가 늘자 이 in-memory 정렬이 상한을 초과해 실패한 것입니다.
진단: find(...).sort(...).explain("executionStats")로 winningPlan을 봅니다. IXSCAN 위에 SORT 스테이지가 있고 totalKeysExamined가 반환 문서 수보다 훨씬 크면, 인덱스가 정렬을 못 살리고 넓게 스캔한 뒤 메모리 정렬한 것입니다.
해결: ESR 순서로 인덱스를 다시 만듭니다 — 등호 status를 맨 앞, 정렬 createdAt을 그 뒤에 둡니다. 이러면 status로 구간을 좁히고 createdAt 순서를 인덱스가 그대로 제공해 SORT 스테이지가 사라집니다. 정렬 방향까지 인덱스에 맞추면 역방향 스캔도 인덱스로 처리됩니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 MongoDB 쿼리·집계·인덱스 명령을 실전 조합과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
insertOne / insertMany | 문서 삽입(단건/다건) | db.products.insertMany([{ name: "마우스", price: 45000 }, ...]) |
find(query, projection) | 조건 조회 + 반환 필드 선택 | db.products.find({ price: { $gte: 50000 } }, { name: 1, _id: 0 }) |
$gte·$lte·$gt·$in | 비교·포함 쿼리 연산자 | { stock: { $gt: 0 }, tags: { $in: ["keyboard"] } } |
.sort().skip().limit() | 정렬·페이지네이션 | .find().sort({ price: -1 }).skip(20).limit(10) |
updateOne + $set | 부분 필드 수정(문서 통째 교체 방지) | updateOne({ _id }, { $set: { price: 95000 } }) |
$inc / $push | 값 증감 / 배열에 추가 | { $inc: { stock: 50 } }, { $push: { tags: "perf" } } |
deleteOne / deleteMany | 문서 삭제 | db.products.deleteMany({ stock: 0 }) |
aggregate([$match, $group]) | 집계 파이프라인(SQL GROUP BY) | [{ $match: { stock: { $gt: 0 } } }, { $group: { _id: "$brand", avg: { $avg: "$price" } } }] |
$lookup + $unwind | 컬렉션 조인(LEFT OUTER JOIN) | { $lookup: { from: "customers", localField: "customerId", foreignField: "_id", as: "customer" } } |
createIndex({ f: 1 }) | 인덱스·복합 인덱스 생성 | createIndex({ customerId: 1, createdAt: -1 }) (ESR 순서) |
createIndex(..., { expireAfterSeconds }) | TTL 인덱스(자동 만료) | db.sessions.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 }) |
{ f: "text" } + $text | 전문 검색 인덱스·검색 | find({ $text: { $search: "MongoDB 성능" } }) |
explain("executionStats") | 실행계획 확인(IXSCAN/COLLSCAN/SORT) | find(...).sort(...).explain("executionStats") |
createCollection(validator) | 스키마 검증 강제 | $jsonSchema: { required: ["email", "name"] } |
관련 모듈로 더 깊이:
- RDBMS, NoSQL, 그리고 분산 확장 가능한 NewSQL 전격 비교 — 문서 DB가 RDBMS·NewSQL 대비 어디에 적합한지
- 캐시(Cache) 전략, 세션 스토어, Pub/Sub 실무 패턴 — 같은 NoSQL 계열인 Key-Value 스토어와의 모델 차이
- 우리 서비스에 맞는 최적의 RDBMS vs NoSQL 고르기 — MongoDB vs RDBMS 선택을 데이터 특성으로 판단하는 프레임워크
다음 모듈에서는 캐시 전략, 세션 스토어, Pub/Sub 등 Redis의 실무 활용 패턴을 다룹니다.