서비스 초기엔 인스턴스에 직접 PostgreSQL을 깔아 썼습니다. 그런데 어느 날 그 인스턴스의 디스크가 고장 나 데이터가 통째로 날아갔고, 백업은 없었습니다. 복구에 사흘, 신뢰는 영영. 그 뒤로 팀은 DB를 관리형으로 옮겼습니다 — 패치·백업·이중화를 사람이 잊지 않도록. DB는 '죽으면 가장 아픈' 자원이라, 운영을 위임할 가치가 가장 큽니다.
- 1관리형 DB가 대신 해주는 것과, 여전히 내 책임인 것을 구분할 수 있다
- 2멀티AZ가 '가용성'을 위한 것임을 설명할 수 있다
- 3읽기 복제본이 '읽기 확장'을 위한 것임을 구분할 수 있다
- 4자동 백업·시점 복구로 사고에 대비하는 법을 안다
- 5DB를 프라이빗 서브넷에 두는 보안 원칙을 적용할 수 있다
운영을 위임하되, 설계는 내 몫
관리형 DB가 맡는 것 / 안 맡는 것
관리형 DB(RDS 등)는 운영을 대신합니다: OS·엔진 패치, 자동 백업, 장애 복구, 멀티AZ 이중화, 기본 모니터링. DBA가 없어도 안정 운영이 가능합니다.
하지만 설계는 그대로 내 책임입니다: 데이터 모델링, 인덱스, 느린 쿼리 튜닝, 커넥션 관리. 관리형이라고 나쁜 스키마·쿼리가 빨라지지 않습니다. Database 트랙의 지식이 클라우드에서도 그대로 필요합니다.
 확대
확대
위 그림처럼 관리형 DB라도 스키마 설계·인덱스·슬로우쿼리 튜닝·보안그룹 설정은 여전히 고객 책임입니다.
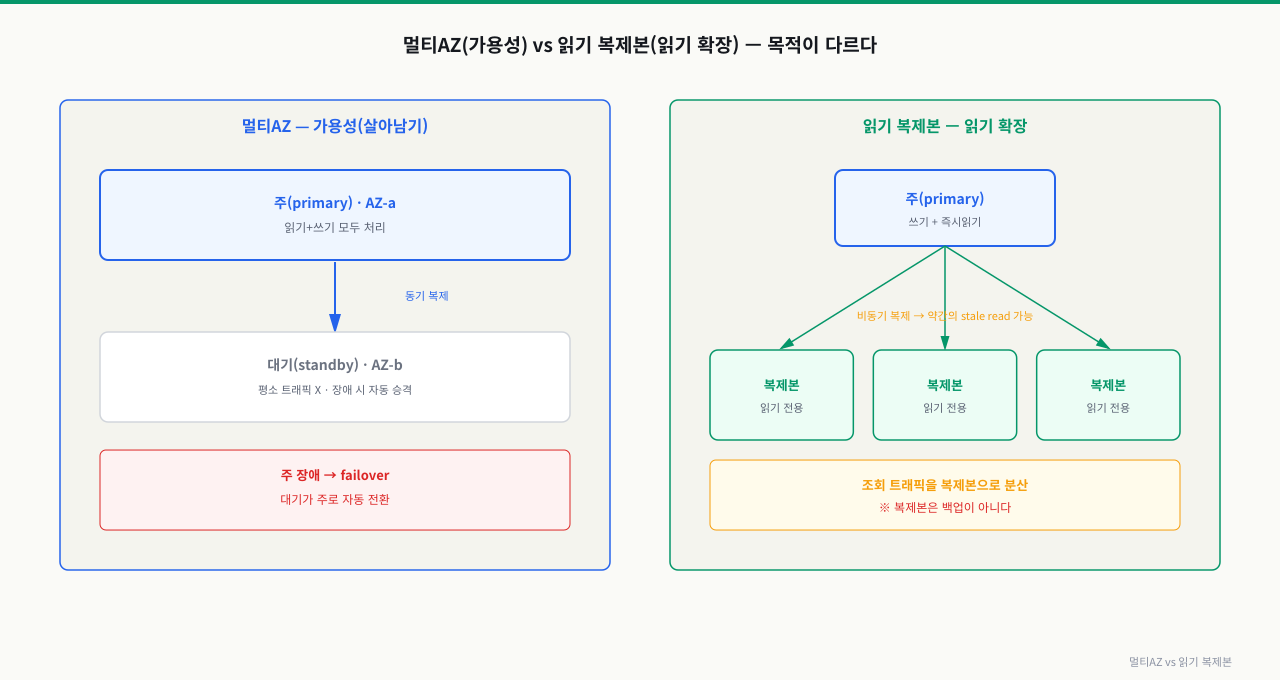
멀티AZ vs 읽기 복제본 — 자주 헷갈리는 둘
이름이 비슷해 헷갈리지만 목적이 정반대입니다.
- 멀티AZ: 다른 AZ에 동기 복제된 대기(standby). 주가 죽으면 자동 전환(failover). 목적은 가용성(살아남기). 대기는 평소 트래픽을 안 받음.
- 읽기 복제본(read replica): 비동기 복제된 읽기 전용 사본(여러 개 가능, 다른 리전도). 읽기 트래픽 분산. 목적은 읽기 확장. 복제 지연으로 stale read 가능.
"고가용성"이 필요하면 멀티AZ, "읽기가 많아 버겁다"면 읽기 복제본입니다.
 확대
확대
위 그림처럼 멀티AZ는 장애 시 자동 페일오버를 위한 것이고, 읽기 복제본은 조회 트래픽을 분산하기 위한 것입니다. 목적이 다르므로 둘을 혼동하지 않아야 합니다.
백업과 복구 — 복제본은 백업이 아니다
관리형 DB는 자동 스냅샷+트랜잭션 로그로 시점 복구(PITR) 를 제공합니다. 실수로 데이터를 지워도 그 직전으로 새 인스턴스를 복원할 수 있습니다.
주의: 읽기 복제본은 백업이 아닙니다. 주에서 잘못된 DELETE가 일어나면 복제본에도 그대로 복제됩니다. 백업(되돌릴 수 있는 시점 사본)과 복제(실시간 사본)는 다른 안전장치입니다. 둘 다 필요합니다.
 확대
확대
위 그림처럼 자동 백업·수동 스냅샷·PITR 세 가지가 서로 다른 복구 목표를 위해 존재합니다. 복제본은 실시간 사본일 뿐, 실수 쿼리는 스냅샷이나 PITR로만 복구할 수 있습니다.
프라이머리가 죽으면 어떻게 자동으로 넘어가나 — 쓰기부터 페일오버까지 6단계
"장애 시 자동 전환"이라는 한 문장 안에는 여러 단계가 숨어 있습니다. 평소 쓰기가 어떻게 스탠바이까지 도달하고, 장애가 나면 무엇이 승격되고 앱은 어떻게 새 프라이머리를 찾는지를 단계로 보면 "왜 페일오버에 몇 분이 걸리는지", "왜 접속 문자열은 그대로 두는지"가 이해됩니다. 관리형 DB의 가용성은 아래 흐름이 맞물린 결과입니다.
[앱] 엔드포인트(prod-db.xxxx.rds.amazonaws.com)로 연결
│
① 라우팅 → 엔드포인트 DNS 이름이 '현재 프라이머리'를 가리킴
│
② 쓰기+동기 복제 → 프라이머리에 쓰기 → 커밋 전 다른 AZ 스탠바이에 복제
│ 양쪽에 기록돼야 커밋 확정(그래서 스탠바이는 항상 최신)
│
③ 헬스체크 → 관리 시스템이 프라이머리 생사를 지속 감시
│
══════════ 프라이머리 AZ 장애 발생 ══════════
│
④ 승격 → 스탠바이를 새 프라이머리로 승격
│
⑤ 엔드포인트 전환 → 같은 DNS 이름을 새 프라이머리 주소로 갱신
│ (앱은 재연결만 하면 됨 — 접속 문자열 불변)
▼
[앱] 재연결 → 새 프라이머리로 계속 서비스
(병행) ⑥ 자동 스냅샷 + 트랜잭션 로그 → 임의 시점 복구(PITR)로 '논리적 사고' 대비
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면·주의 |
|---|---|---|
| ① 엔드포인트 라우팅 | 앱은 IP가 아니라 엔드포인트 DNS 이름으로 접속 → 프라이머리가 바뀌어도 접속 문자열은 그대로 | 앱이 IP를 직접 박아두면 페일오버 후 옛 노드로 감 |
| ② 동기 복제 | 프라이머리 쓰기를 다른 AZ 스탠바이에 동기 복제, 양쪽 기록 후 커밋 → 스탠바이 데이터 손실 없음 | 두 곳 확정을 기다리므로 쓰기 지연이 약간 늘어남 |
| ③ 헬스체크 | 관리형 시스템이 프라이머리 생사를 감시 | 감지 자체에 시간이 들어 전환이 즉시가 아님 |
| ④ 승격 | 장애 감지 시 스탠바이를 새 프라이머리로 승격 | 승격 순간 진행 중이던 트랜잭션은 끊김 → 재시도 필요 |
| ⑤ 엔드포인트 전환 | 같은 DNS를 새 주소로 갱신 → 반영에 보통 1~2분 | 클라가 DNS를 오래 캐시하거나 커넥션 풀이 끊긴 연결을 안 버리면 옛 주소로 계속 접속 |
| ⑥ 백업·PITR(병행) | 스냅샷+트랜잭션 로그로 임의 시점 복구 | 복제는 실수를 못 되돌림 — 논리적 사고(잘못된 DELETE)는 PITR의 몫 |
즉 "자동 페일오버"는 ③감지·④승격·⑤전환이 순서대로 끝나야 완료됩니다. 그래서 앱 에러가 전환 때 몇 분 이어진다면 ⑤(DNS 캐시·커넥션 풀 재수립)를, 페일오버와 무관하게 방금 쓴 데이터가 안 보인다면 이 동기 경로가 아니라 읽기 복제본의 비동기 복제 지연(stale read)을, 실수로 지운 데이터를 못 되돌린다면 ⑥(PITR 비활성)을 의심합니다. '자동'과 '무중단'은 다른 약속이라, 앱에는 짧은 백오프 재시도와 커넥션 재수립이 설계돼 있어야 이 몇 분이 대량 에러가 아니라 짧은 흔들림으로 끝납니다.
멀티AZ·백업 보존·공개 접근 여부를 한 번에 점검합니다.
aws rds describe-db-instances \
--query "DBInstances[].{Id:DBInstanceIdentifier,MultiAZ:MultiAZ,Backup:BackupRetentionPeriod,Public:PubliclyAccessible}" --output table
+-------------+---------+--------+--------+
| prod-db | True | 7 | False |
| legacy-db | False | 0 | True | ← 위험: 단일AZ·백업없음·공개
+-------------+---------+--------+--------+
aws rds describe-db-instances자동 백업이 실제로 보관하는 가장 이른 시점과 가장 최근 시점을 함께 확인합니다.
aws rds describe-db-instance-automated-backups --db-instance-identifier prod-db \
--query "DBInstanceAutomatedBackups[0].{Earliest:RestoreWindow.EarliestTime,Latest:RestoreWindow.LatestTime,Retention:BackupRetentionPeriod}"
{ "Earliest": "2026-06-15T13:20:00Z", "Latest": "2026-06-22T13:15:00Z", "Retention": 7 }
Earliest부터 Latest 사이가 현재 복구 가능한 범위입니다. 값이 비어 있으면 자동 백업 보존 기간과 첫 백업 생성 상태부터 확인합니다.
aws rds describe-db-instance-automated-backups- PubliclyAccessible=True인 DB — DB는 프라이빗 서브넷·비공개가 원칙(VPC와 서브넷). 공개면 즉시 차단 검토
- BackupRetentionPeriod=0 — 자동 백업 꺼짐. 사고 시 복구 불가. 최소 7일 이상 권장
- 운영 핵심인데 MultiAZ=False — 단일 AZ 장애로 다운. 가용성 요구에 따라 멀티AZ 활성화
- 읽기 복제본의 복제 지연(ReplicaLag) — 지연이 크면 stale read 심화. 쓰고 바로 읽는 요청은 주로 라우팅
상황: 쓰기 직후 읽기 복제본에서 조회하면 데이터가 없거나 옛 값.
원인: 읽기 복제본은 비동기 복제라 주→복제본 반영에 지연(ReplicaLag)이 있음. '쓰고 즉시 읽는' 요청이 복제본으로 가면 아직 복제 전이라 안 보임(stale read).
진단: 복제본의 ReplicaLag 지표 확인 → 해당 요청이 어느 엔드포인트로 가는지 확인(쓰기/읽기 분리 라우팅).
해결: '쓰고 바로 보여줘야 하는' 흐름(주문 직후 확인 등)은 주 인스턴스에서 읽기. 분석·목록처럼 약간의 지연이 허용되는 읽기만 복제본으로. 복제 지연을 모니터링하고 임계 초과 시 알림(관측과 거버넌스).
심화 — '자동'의 디테일은 장애 당일에 드러난다
심화: 멀티AZ 페일오버의 실제 — 자동이지, 무중단이 아니다
"장애 시 자동 전환"이라는 말에서 설계를 멈추면, 정작 페일오버 당일에 놀라게 됩니다. 전환이 실제로 어떻게 일어나는지 알아야 앱을 그에 맞게 준비할 수 있습니다.
- 전환은 DNS로 일어납니다: 페일오버 시 엔드포인트의 DNS가 standby의 주소로 바뀝니다. 장애 감지→승격→DNS 반영까지 보통 1~2분이 걸리고, 그동안 연결은 실패합니다. "자동"과 "무중단"은 다른 약속입니다.
- 클라이언트가 DNS를 캐시하면 더 길어집니다: 특히 JVM 계열은 설정에 따라 DNS 결과를 매우 오래 캐시해, 전환이 끝난 뒤에도 옛 주소로 계속 접속을 시도할 수 있습니다. DNS 캐시 TTL을 짧게 잡고, 커넥션 풀이 끊긴 연결을 버리고 재수립하도록 설정해야 페일오버가 '몇 분'으로 끝납니다.
- 앱에는 재시도가 필요합니다: 전환 순간 진행 중이던 쿼리·트랜잭션은 끊깁니다. 짧은 백오프 재시도와 트랜잭션 재실행 설계가 없으면, 1~2분의 전환이 사용자에겐 대량 에러로 보입니다.
- 멀티AZ가 못 막는 것: 동기 복제는 잘못된 DELETE도 즉시 standby에 복제합니다. 논리적 사고는 페일오버가 아니라 PITR의 영역이고, 리전 전체 장애도 멀티AZ 범위 밖입니다.
그래서 성숙한 팀은 페일오버를 믿는 대신 연습합니다 — 점검 시간에 reboot with failover로 실제 전환을 일으켜, 앱이 몇 분 만에 스스로 회복하는지 측정해 둡니다.
상황: 배포도 없고 트래픽도 평소 수준인데 DB 응답이 일제히 느려짐. 슬로우쿼리를 의심해 쿼리를 뒤졌지만 특별히 달라진 것이 없습니다.
원인: 인스턴스가 버스터블(db.t3/t4g) 클래스였습니다. 이 클래스는 기준선(baseline) 이하로 쓸 때 CPU 크레딧을 모으고, 넘을 때 소모합니다. 며칠에 걸쳐 조금씩 늘어난 부하가 크레딧을 전부 소진하자, CPU가 기준선(예: 20%)으로 강제 제한돼 같은 쿼리도 몇 배씩 걸리게 된 것입니다.
진단: CloudWatch에서 CPUCreditBalance가 0으로 떨어졌는지, CPUUtilization이 기준선 비율에 못 박힌 듯 고정돼 있는지 확인합니다. 크레딧 고갈 시점과 지연 시작 시점이 일치하면 확정입니다.
해결: 상시 부하가 기준선을 넘는 워크로드라면 버스터블이 아니라 m/r 클래스로 바꿉니다(버스터블은 개발·간헐 부하용). 임시로는 unlimited 모드로 급한 불을 끌 수 있지만 초과 크레딧이 추가 과금됩니다. 재발 방지로 CPUCreditBalance에 알람을 걸어 고갈 전에 감지합니다(관측과 거버넌스). '작은 인스턴스로 시작'은 좋은 전략이지만, 어떤 클래스로 작게 시작했는지는 알고 있어야 합니다.
면접 단골: "DB 가용성을 어떻게 확보하나요?" → "운영 DB는 멀티AZ로 자동 failover, 읽기 부하는 읽기 복제본으로 분산, 자동 백업+PITR로 사고 대비, DB는 프라이빗 서브넷에 둬 외부 노출 차단"이면 탄탄합니다.
실무 함정: 관리형 DB로 옮겼다고 안심하다가 복구를 한 번도 연습 안 해 정작 사고 때 우왕좌왕하는 경우가 많습니다. 백업이 '있는 것'과 '복구되는 것'은 다릅니다 — 정기적으로 스냅샷에서 복원해 보는 DR 훈련이 진짜 안전장치입니다. 커넥션 풀·느린 쿼리 같은 성능 이슈는 클라우드여도 Database 트랙의 튜닝이 그대로 필요합니다.
관련 모듈로 더 깊이:
- 오브젝트·블록·파일 스토리지 — 관리형 DB가 데이터를 올려두는 블록 스토리지와 백업 대상 오브젝트 스토리지
- 백업과 재해복구 — RDS의 멀티AZ·스냅샷을 넘어선 백업·재해복구 설계
- VPC와 서브넷 — DB를 외부에 노출하지 않도록 프라이빗 서브넷에 배치하는 법
다음 모듈에서는 서버를 아예 띄우지 않고 코드만 실행하는 서버리스(Lambda) — 이벤트 기반 실행과 콜드스타트, 과금 모델을 다룹니다.