새 프로젝트를 시작할 때 어떤 DB를 고를지 빨리 결정해야 하는 순간이 있습니다. 단순히 유명한 제품을 고르면 트랜잭션, 검색, 캐시, 분석 요구가 뒤늦게 충돌합니다. 선택 기준을 정리해두면 팀이 같은 근거로 의사결정할 수 있습니다.
DB 선택은 기술 성능 비교가 아닙니다. 도메인 특성, 쿼리 패턴, 팀의 운영 능력, 일관성 요구사항을 함께 고려해야 합니다. 이 모듈에서는 각 DB의 강점과 약점을 정리하고, 실무에서 반복되는 선택 패턴을 익힙니다.
- 1쿼리 패턴, 정합성 요구, 운영 비용을 기준으로 DB를 선택할 수 있다
- 2관계형, 문서형, 키-값 DB를 도메인 특성에 맞게 선택할 수 있다
- 3폴리글랏 퍼시스턴스로 여러 DB를 조합해 사용하는 설계를 할 수 있다
- 4CQRS로 쓰기와 읽기 저장소를 분리하는 전략을 적용할 수 있다
- 5실무 시나리오에 맞춰 DB 선택을 판단하고 근거를 제시할 수 있다
데이터베이스 선택 기준 — 프로젝트에 맞는 DB 고르기
스타트업 초기에 "빠르게 만들어야 한다"는 이유로 모든 걸 MySQL에 때려박았다. 6개월 뒤, 실시간 피드 조회가 느려지고, 검색 쿼리가 인덱스를 못 타고, 세션 테이블이 DB 부하의 30%를 잡아먹고 있었다. 결국 당시에 팀 전체가 2주를 들여서 Redis와 Elasticsearch로 마이그레이션했다 — 처음부터 올바른 도구를 선택했다면 없었을 작업이었다. DB 선택은 기술 취향의 문제가 아니라 쿼리 패턴과 데이터 특성에 따른 공학적 판단이다. JOIN이 많으면 PostgreSQL, 유연한 문서 구조면 MongoDB, 마이크로초 응답이 필요하면 Redis — 이 기준을 알면 처음부터 맞는 도구를 고를 수 있고, 나중에 갈아엎는 고통을 피할 수 있다.
DB 선택의 핵심 질문 3가지
아키텍처 회의에서 DB를 뭘 쓸지 논쟁이 붙었습니다. "PostgreSQL이 더 빠르다", "MongoDB가 유연하다", "Redis 쓰면 된다"는 말들이 오갑니다. 벤치마크 스펙만 보고 선택하면 나중에 데이터 접근 패턴이 맞지 않아 마이그레이션을 하게 됩니다. DB 선택은 스펙 비교가 아니라 올바른 질문에서 시작됩니다. 어떤 질문을 던지느냐가 선택의 방향을 결정합니다.
 확대
확대
스펙이 아닌 질문으로 선택한다
"어떤 DB가 더 빠른가?"는 잘못된 질문입니다. 올바른 질문은 다음 3가지입니다.
① 데이터 관계가 얼마나 복잡한가?
테이블 간 JOIN이 필수인 도메인과 단일 문서로 표현 가능한 도메인은 최적의 DB가 다릅니다.
| 관계 복잡도 | 적합한 DB | 이유 |
|---|---|---|
| 테이블 간 JOIN이 필수 | PostgreSQL, MySQL | 외래키, 트랜잭션, 인덱스 결합 |
| 단일 문서로 표현 가능 | MongoDB | 임베딩으로 JOIN 제거 |
| 키로만 조회 | Redis | 해시맵처럼 단순 K-V |
② 얼마나 강한 일관성이 필요한가?
비즈니스 도메인마다 허용되는 일관성 수준이 다릅니다. 계좌이체는 강한 일관성이 필수지만 좋아요 수는 잠깐 틀려도 됩니다.
강한 일관성 필요 → PostgreSQL (ACID 완전 지원)
예: 계좌이체, 재고 차감
최종 일관성으로 충분 → MongoDB, Cassandra
예: 좋아요 수, 조회수
일관성보다 속도가 중요 → Redis
예: 피드 목록, 세션, 랭킹
③ 쿼리 패턴이 고정인가, 유동적인가?
- 고정 패턴 (주문 조회, 사용자 조회): RDBMS의 정형화된 스키마가 유리
- 유동 패턴 (상품 속성, A/B 테스트 데이터): MongoDB의 유연한 스키마가 유리
- 집계/분석 쿼리: ClickHouse, BigQuery 같은 OLAP DB 고려
도메인별 DB 선택 패턴
이커머스, 소셜, IoT — 도메인마다 데이터 특성과 접근 패턴이 다릅니다. 그런데 "우리도 카카오처럼 하면 된다"는 식으로 남의 아키텍처를 그대로 복사하면 규모와 맥락이 달라 맞지 않습니다. 도메인별로 어떤 DB 조합이 반복적으로 나타나는지 알면, 새 서비스 설계 때 출발점이 생깁니다. 패턴을 아는 것과 모르는 것의 차이는 첫 설계의 품질에서 드러납니다.
 확대
확대
실무에서 반복되는 선택 패턴
도메인마다 데이터 접근 패턴이 다르기 때문에 최적의 DB 조합도 달라집니다. 아래 패턴들은 실무에서 가장 자주 등장하는 폴리글랏 구성입니다.
이커머스
주문·결제·재고는 ACID가 필수이므로 PostgreSQL이 핵심이고, 빠른 응답이 필요한 캐시와 검색은 각각 Redis와 Elasticsearch가 담당합니다.
PostgreSQL ← 주문, 결제, 재고 (ACID 필수)
Redis ← 장바구니, 세션, 상품 조회 캐시
Elasticsearch ← 상품 검색, 자동완성
MongoDB ← 상품 상세 (속성이 카테고리마다 다름)
SaaS B2B
조직·사용자·권한처럼 복잡한 관계형 데이터는 PostgreSQL이 담당하고, Rate Limit처럼 TTL이 필요한 임시 데이터는 Redis가 맡습니다.
PostgreSQL ← 조직, 사용자, 권한, 청구 (관계형 + 멀티테넌트)
Redis ← API Rate Limit, 실시간 알림 큐
S3 + PostgreSQL ← 첨부파일 메타데이터
소셜 피드
피드 타임라인은 최신 N개를 O(log N)으로 조회해야 하므로 Redis Sorted Set이 최적이고, 포스트 내용은 미디어·태그 등 구조가 다양해 MongoDB가 유연합니다.
PostgreSQL ← 사용자 계정, 팔로우 관계
Redis Sorted Set ← 타임라인 피드 (ZREVRANGE로 O(log N))
MongoDB ← 포스트 내용 (자유 형식, 미디어 임베딩)
실시간 분석 대시보드
트랜잭션 원본은 PostgreSQL에 두고, 수억 건 집계 쿼리는 OLAP에 특화된 ClickHouse가 초 단위로 처리합니다.
PostgreSQL ← 원본 트랜잭션 데이터
ClickHouse ← OLAP 집계 쿼리 (수억 건도 초 단위)
Redis ← 최근 1시간 지표 캐시
폴리글랏 퍼시스턴스와 CQRS
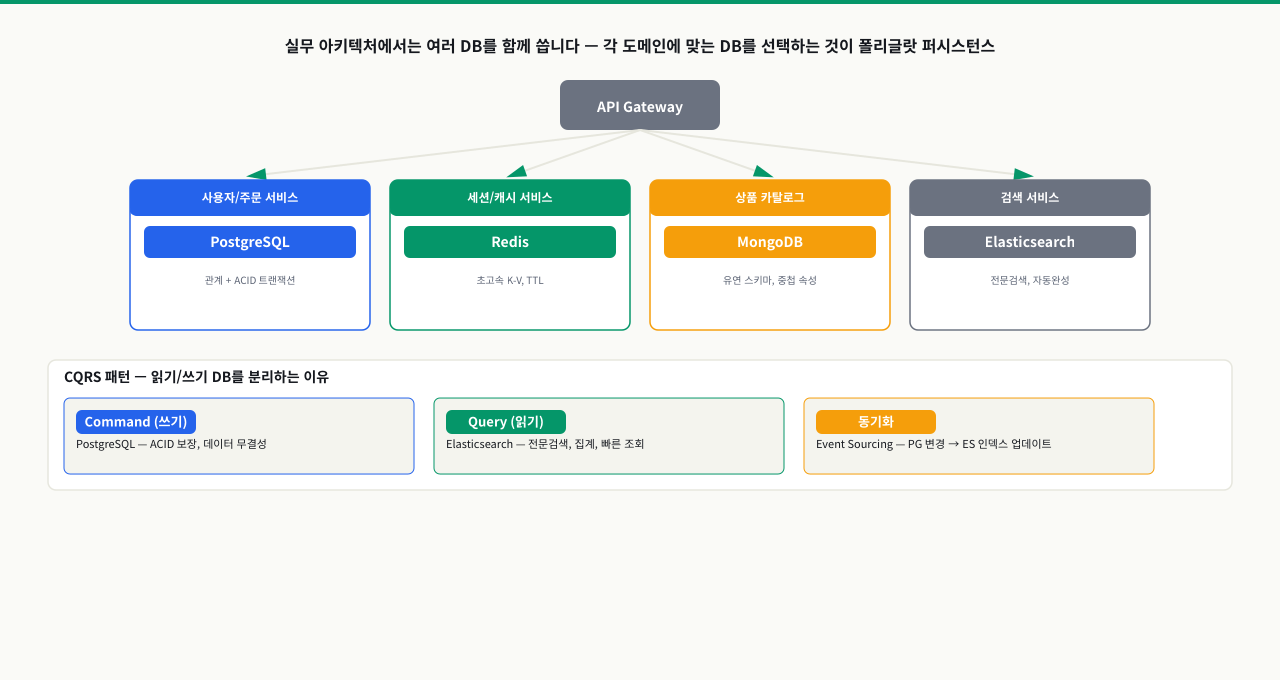
쓰기는 PostgreSQL에서 하고 읽기는 Redis 캐시에서 합니다. 그런데 캐시 갱신이 늦어 읽기 요청에서 오래된 데이터가 노출됩니다. 검색은 Elasticsearch로 따로 인덱싱하는데 DB와 ES 사이 데이터가 맞지 않을 때가 있습니다. 여러 DB를 함께 쓰면 일관성 유지와 동기화가 새로운 과제가 됩니다. 폴리글랏 퍼시스턴스와 CQRS는 이런 복잡도를 관리하는 설계 패턴입니다.
여러 DB를 함께 쓰는 설계 패턴
폴리글랏 퍼시스턴스 (Polyglot Persistence)
한 서비스 안에서 목적에 맞는 DB를 혼용하는 전략
하나의 Application이 목적별로 여러 DB를 함께 씁니다.
| DB | 용도 |
|---|---|
| PostgreSQL | 주문/결제 (ACID) |
| Redis | 캐시/세션 |
| MongoDB | 상품 상세/로그 |
장점: 각 도메인에 최적화된 DB 사용 단점: 운영 복잡성 증가 (장애 포인트 증가, 팀 숙련도 분산)
결정 기준: 단일 DB로 해결할 수 없는 명확한 이유가 있을 때만 추가
CQRS (Command Query Responsibility Segregation)
쓰기(Command)와 읽기(Query) 저장소를 분리합니다.
사용자 요청을 쓰기/읽기로 분리합니다.
- 쓰기 (POST /order) → PostgreSQL (ACID, 정규화) → 이벤트 발행 → Redis/Elasticsearch (읽기 뷰 갱신)
- 읽기 (GET /orders) → Redis (캐시) 또는 Elasticsearch (검색 최적화 뷰)
읽기 트래픽이 쓰기보다 10배 이상 많은 서비스에서 효과적입니다.
실습: 시나리오별 DB 선택 판단
다음 시나리오에서 어떤 DB를 고를지 직접 판단해보세요.
시나리오 1: 의료 기록 시스템 — 환자별 진료 기록을 저장하고, 의사가 과거 기록을 시간순으로 조회합니다. 진료 기록 삭제는 절대 불가입니다.
판단 포인트:
- 시간순 조회 → created_at 인덱스
- 삭제 불가 → soft delete + audit log
- 규정 준수 → ACID 필수
→ PostgreSQL (+ 감사 로그용 append-only 테이블)
시나리오 2: 라이브 스트리밍 플랫폼 — 시청자 수를 1초마다 업데이트하고 스트리머 대시보드에 표시합니다.
판단 포인트:
- 초당 업데이트 → 높은 쓰기 빈도
- 정확한 수치보다 빠른 응답이 중요
- 데이터 소실 허용 (±0.1% 오차 무방)
→ Redis INCR (RDBMS에 매초 UPDATE하면 커넥션 병목)
시나리오 3: B2B SaaS 리포트 — 월별 매출, 고객사별 사용량을 집계해서 PDF로 내보냅니다.
판단 포인트:
- 집계 쿼리 (GROUP BY, SUM, 날짜 범위)
- 실시간보다 배치 처리
- 데이터 크기: 수천만 건
→ PostgreSQL (규모 작으면 충분) or ClickHouse (억 단위 이상)
스키마가 자주 바뀐다는 이유로 MongoDB 선택 → 관계형 쿼리 필요해짐
// 처음에는 단순해 보였던 구조
{ user_id: 1, orders: [...] } // 사용자 안에 주문 임베딩
// 6개월 후: "이번 달 특정 상품을 구매한 모든 사용자 목록 뽑아줘"
// → 전체 컬렉션 스캔, 집계 파이프라인으로 복잡한 $unwind + $match 필요
왜 이렇게 됐는가: 초기 요구사항만 보고 DB를 선택했습니다. 비즈니스가 성장하면 분석 쿼리가 반드시 생깁니다.
교훈:
- "스키마가 유연해서 MongoDB" → 잘못된 이유. 스키마 변경은 RDBMS에서 마이그레이션으로 관리 가능
- 예상 쿼리 패턴을 먼저 작성해보고 DB를 선택
- 도메인의 핵심 데이터는 관계형이 거의 항상 유리
이미 MongoDB에 있다면: $lookup(JOIN에 해당)으로 임시 대응하고, 장기적으로 핵심 데이터는 PostgreSQL로 마이그레이션을 계획합니다.
# Redis 재시작 후
redis-cli keys "*"
# (empty array)
# 모든 캐시, 세션, 그리고 잘못 저장한 주문 데이터까지 소멸
실행 완료 또는 조회 결과가 표시됩니다.
- CAP 판단 먼저: 결제·재고처럼 강한 일관성(C)이 필요하면 PostgreSQL — 좋아요 수·조회수처럼 최종 일관성(A)으로 충분하면 MongoDB/Redis 선택
- TPS 기준 판단: 관계형(PostgreSQL/MySQL)은 초당 수천 건 트랜잭션에 적합, Redis·Cassandra는 초당 수만 건 이상 키-값 조회에 적합
- JOIN 빈도와 DB 조합 해석: JOIN이 3개 테이블 이상 필요하고 빈번하면 → PostgreSQL. 단일 문서 조회이고 속성 구조가 다양하면 → MongoDB. 두 패턴이 동시에 필요하면 → 폴리글랏 퍼시스턴스 적용 시점
원인: Redis의 기본 설정은 인메모리만 사용합니다. RDB 스냅샷이나 AOF(Append Only File)를 설정하지 않으면 재시작 시 데이터가 사라집니다.
해결: Redis는 캐시·세션·임시 데이터에만 사용하고, 영구 보존이 필요한 데이터는 반드시 RDBMS나 MongoDB에 저장합니다.
# redis.conf에서 영속성 활성화 (캐시 용도가 아닐 때만)
appendonly yes
appendfsync everysec
심화 — 폴리글랏의 청구서는 '정합성'으로 날아온다
심화: 두 저장소에 걸친 쓰기는 원자적이지 않다 — dual write와 outbox
폴리글랏·CQRS는 읽기와 쓰기를 각자 잘하는 DB에 맡긴다는 매력적인 그림입니다. 그런데 한 번의 사용자 요청이 PostgreSQL에 쓰고 Elasticsearch에도 색인해야 한다면, 그 순간 분산 시스템의 가장 어려운 문제가 조용히 들어옵니다.
- 트랜잭션은 한 DB 안에서만 원자적입니다: PostgreSQL의 COMMIT은 PostgreSQL만 보장합니다. 이어지는 ES 색인은 별개의 네트워크 호출이라 둘을 하나의 트랜잭션으로 묶을 수 없습니다. 앱이 PG 커밋과 ES 색인 사이에서 죽으면 주문은 DB엔 있는데 검색엔 없는 영구 불일치가 남습니다(dual write 문제).
- 순서를 바꿔도 해결되지 않습니다: ES 먼저 쓰고 PG를 나중에 써도, PG가 실패하면 이번엔 검색엔 있는데 DB엔 없는 유령 데이터가 됩니다. 두 저장소를 앱에서 순차 호출하는 한 중간 실패의 창은 사라지지 않습니다.
- 2단계 커밋(2PC)은 대개 답이 아닙니다: 이론상 분산 트랜잭션으로 묶을 수 있지만, ES·Redis 같은 저장소는 완전한 2PC를 지원하지 않거나 운영·성능 비용이 큽니다. 실무는 강한 원자성 대신 결국 맞춰지는(eventually consistent) 설계를 택합니다.
- 정석은 transactional outbox입니다: 주문을 저장하는 바로 그 PG 트랜잭션 안에서 outbox 테이블에 이 주문을 색인하라는 이벤트도 함께 커밋합니다. 그러면 주문과 이벤트는 원자적으로 같이 저장됩니다. 별도 프로세스나 CDC가 outbox를 읽어 ES에 반영하고, 실패하면 재시도합니다. 반영은 at-least-once라 같은 이벤트가 두 번 올 수 있으므로 색인은 멱등(같은 id면 덮어쓰기)해야 합니다.
핵심은, 폴리글랏의 진짜 비용은 DB를 하나 더 배우는 게 아니라 두 저장소를 어떻게 일관되게 유지할 것인가라는 점입니다. DB를 나눈다는 결정에는 항상 어떻게 동기화할 것인가라는 설계가 딸려 옵니다(Master-Slave 복제(Replication) 구축과 DB 고가용성(HA) 아키텍처).
상황: 주문은 PostgreSQL에, 검색은 Elasticsearch에 두는 CQRS 구조입니다. 대부분 잘 되는데 특정 주문들이 상세 페이지에는 있지만 검색·목록에는 없습니다. 밤마다 전체 재색인 배치를 돌리면 사라졌던 주문이 채워집니다.
원인: 앱이 PG에 저장 후 커밋하고 그다음 ES에 색인하는 순서로 두 저장소에 따로 씁니다. 배포·타임아웃·인스턴스 종료 등으로 커밋 직후 ES 색인 전에 실패하면, 그 주문은 DB에만 남고 검색엔 영영 반영되지 않습니다. 평소엔 드물지만 트래픽·배포가 몰릴 때 집중적으로 발생합니다.
진단: 특정 시간대(배포·스케일인 시점)에 불일치가 몰리는지 봅니다. PG의 주문 집합과 ES의 문서 집합을 대사해 DB엔 있고 ES엔 없는 id를 뽑으면 dual write 실패가 확정됩니다. 애플리케이션 로그에서 PG 커밋 성공 후 ES 호출 예외가 조용히 삼켜졌는지도 확인합니다.
해결: 앱에서의 순차 이중 쓰기를 걷어내고 transactional outbox로 바꿉니다. 주문과 함께 outbox 이벤트를 같은 PG 트랜잭션에서 커밋하고, 별도 워커나 CDC가 outbox를 ES로 흘려보내며 실패 시 재시도합니다. 색인은 주문 id 기준 멱등 upsert로 만들어 중복 이벤트에도 안전하게 합니다. 야간 전체 재색인은 최후의 보정일 뿐 상시 정합성의 근거가 되어서는 안 됩니다.
실무에서 DB 선택 결정이 일어나는 순간
시나리오: 신규 기능 개발 전 아키텍처 리뷰
팀장: "이번에 상품 리뷰 기능 추가하는데, 어디에 저장할까요?"
주니어: "MongoDB요. 리뷰마다 구조가 다를 수 있으니까요."
시니어: "잠깐, 리뷰 조회 패턴이 어떻게 되나요?
- 상품별 리뷰 목록 (product_id로 조회)
- 사용자가 쓴 리뷰 목록 (user_id로 조회)
- 리뷰에 대댓글 기능 예정?
- 구조가 '다를 수 있다'는 게 구체적으로 어떤 부분인가요?"
주니어: "rating이 별점인 상품도 있고 점수인 것도 있어서요..."
시니어: "그건 컬럼 두 개면 해결됩니다. PostgreSQL로 가는 게 낫겠어요.
나중에 '이번 달 평점 4점 이상 리뷰 남긴 사용자에게 쿠폰 발송' 같은
마케팅 쿼리가 반드시 생기거든요. MongoDB에서 그런 집계는 고통스럽습니다."
핵심: DB 선택 전에 "6개월 후 어떤 쿼리가 필요할까?"를 미리 물어보는 것이 중요합니다. 현재 요구사항만으로 결정하면 결국 마이그레이션 비용이 생깁니다.
정리: DB 선택 체크리스트
✅ 데이터 간 관계가 복잡하다 (JOIN 필요) → PostgreSQL/MySQL
✅ ACID 트랜잭션이 필수다 (결제, 재고) → PostgreSQL
✅ 초당 수만 번 읽기, 정확성보다 속도 → Redis
✅ 문서 구조가 진짜로 다양하다 (e-commerce 상품 속성) → MongoDB
✅ 전문 검색, 자동완성이 필요하다 → Elasticsearch
✅ 집계 분석, 수억 건 이상 → ClickHouse, BigQuery
⚠️ "스키마가 유연해서" MongoDB → 잘못된 이유
⚠️ "빠를 것 같아서" Redis를 메인 DB로 → 잘못된 용도
⚠️ 팀이 한 번도 안 써본 DB → 운영 비용 과소평가
명령어·구문 빠른 참조
SQL 문법 학습 모듈이 아니라 DB 선택 판단 모듈이므로, 각 저장소의 적합성을 가르는 데 등장한 대표 명령·구문만 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
psql / mongo / redis-cli | 워크로드별로 다른 DB 접속 클라이언트 | 관계형은 psql, 문서는 mongo, 캐시는 redis-cli |
Redis ZREVRANGE ... WITHSCORES | Sorted Set으로 최신 피드 O(log N) 조회 | ZREVRANGE user:42:feed 0 99 WITHSCORES |
Redis INCR | 조회수·시청자 수 같은 고빈도 카운터 | INCR live:1234:viewers (매초 RDBMS UPDATE 대신) |
Redis keys "*" | 저장된 키 확인(운영 남용 주의) | redis-cli keys "*" — 재시작 후 비면 영속성 미설정 |
redis.conf appendonly / appendfsync | Redis AOF 영속성 활성화 | appendonly yes / appendfsync everysec |
MongoDB $lookup | 문서 DB에서 JOIN 대응(임시 대응책) | 임베딩 후 관계형 쿼리가 필요해질 때 |
MongoDB $unwind + $match | 임베딩 배열을 펼쳐 집계·조건 조회 | 컬렉션 전체 스캔 비용 주의 |
GROUP BY / SUM() 집계 | 분석 쿼리 규모로 DB 선택 판단 | 억 단위 집계면 ClickHouse·BigQuery 고려 |
관련 모듈로 더 깊이:
- RDBMS, NoSQL, 그리고 분산 확장 가능한 NewSQL 전격 비교 — RDBMS/NoSQL/NewSQL의 근본 차이를 선택 기준으로 연결
- Document DB (MongoDB) 임베딩 vs 참조 설계 기준 — MongoDB를 "스키마가 유연해서"가 아니라 올바른 이유로 고르는 법
- 캐시(Cache) 전략, 세션 스토어, Pub/Sub 실무 패턴 — Redis를 메인 DB가 아닌 적절한 용도로 쓰는 기준
다음 모듈에서는 SQL Injection 예방, 최소 권한 접근 제어, 데이터 암호화 등 DB 보안 기초를 다룹니다.