서비스가 느려졌다는 알림만으로는 원인을 찾을 수 없습니다. 커넥션, 락, 슬로우 쿼리, 버퍼 캐시 같은 신호를 함께 봐야 DB가 어디서 막혔는지 판단할 수 있습니다. 관측 지표를 읽을 줄 알면 장애 대응 시간이 크게 줄어듭니다.
슬로우 쿼리를 EXPLAIN ANALYZE로 분석하는 방법은 query-execution-plan 모듈에서 다뤘습니다. 이 모듈은 한 발 앞에 있습니다. 장애가 나기 전에 감지하고, 이미 느려진 상황을 데이터로 증명하고, 알람으로 선제 대응하는 것이 목표입니다. 분석 도구가 아니라 감시 체계를 구축합니다.
- 1pg_stat_statements로 슬로우 쿼리를 사후 분석할 수 있다
- 2MySQL slow_query_log를 설정하고 mysqldumpslow로 분석할 수 있다
- 3postgres_exporter로 QPS, 커넥션, 캐시 히트율 같은 핵심 메트릭을 수집할 수 있다
- 4Grafana 필수 패널 4개를 어떤 지표를 왜 보는지 이해하고 구성할 수 있다
- 5300ms와 1000ms 같은 알람 임계값을 근거를 들어 설정할 수 있다
- 6pg_locks와 InnoDB trx 뷰로 잠금 경합을 실시간으로 진단할 수 있다
운영 DB 모니터링 & 슬로우 쿼리 알람 설정
오전 11시 37분, 고객 센터에 첫 번째 민원이 들어왔습니다. "주문 조회가 너무 느려요." 처음엔 네트워크 문제인 줄 알았습니다. 11시 49분, 민원이 7건으로 늘었습니다. 백엔드 팀이 APM 대시보드를 열었을 때 주문 목록 API의 p99 레이턴시가 이미 12초를 넘긴 상태였습니다. DB 쿼리 로그를 뒤지기 시작했지만, 슬로우 쿼리 로그는 꺼져 있었고 pg_stat_statements도 비활성화 상태였습니다. 무엇이 느린지 알기 위해 수동으로 EXPLAIN ANALYZE를 하나씩 실행해보는 사이 12시 15분이 됐습니다. 장애 시작부터 원인 파악까지 38분이 걸렸습니다. 모니터링이 켜져 있었다면 3분 안에 끝날 일이었습니다.
학습 목표
이 모듈을 마치면 다음을 할 수 있습니다.
pg_stat_statements를 활성화하고 상위 슬로우 쿼리를 주기적으로 수집한다- MySQL
slow_query_log를 설정하고mysqldumpslow로 분석한다 - Prometheus
postgres_exporter의 핵심 메트릭을 이해하고 수집한다 - Grafana 대시보드에 필수 DB 패널 4개를 구성한다
- 슬로우 쿼리 알람 임계값의 근거를 설명하고 팀에 적합한 값을 결정한다
pg_locks와information_schema.innodb_trx로 잠금 경합을 실시간 진단한다
# postgres_exporter + Prometheus + Grafana 로컬 스택
cat > docker-compose.monitoring.yml << 'EOF'
version: "3.8"
services:
postgres:
image: postgres:15
environment:
POSTGRES_PASSWORD: secret
POSTGRES_DB: appdb
ports:
- "5432:5432"
postgres_exporter:
image: prometheuscommunity/postgres-exporter:latest
environment:
DATA_SOURCE_NAME: "postgresql://postgres:secret@postgres:5432/appdb?sslmode=disable"
ports:
- "9187:9187"
depends_on:
- postgres
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
grafana:
image: grafana/grafana:latest
environment:
GF_SECURITY_ADMIN_PASSWORD: admin
ports:
- "3000:3000"
EOF
# Prometheus 설정 파일 생성
cat > prometheus.yml << 'EOF'
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'postgres'
static_configs:
- targets: ['postgres_exporter:9187']
EOF
docker compose -f docker-compose.monitoring.yml up -d
실행 완료 또는 조회 결과가 표시됩니다.
- 슬로우 쿼리—응답 시간이 긴 쿼리의 SQL과 실행 빈도를 함께 확인합니다.
- 락 대기—대기 이벤트가 쿼리 실행인지 락 경합인지 구분합니다.
- 커넥션 상태—idle, active, waiting 연결 비율을 운영 기준과 비교합니다.
-- pg_stat_statements 활성화 확인
SHOW shared_preload_libraries;
-- 결과에 'pg_stat_statements'가 없으면 postgresql.conf에 추가 필요
DB 상태가 대시보드에 뜨기까지 — 관측 파이프라인 5단계
Grafana를 열면 QPS·커넥션·캐시 히트율이 그려져 있습니다. 그런데 DB가 이 숫자들을 대시보드로 밀어 보내는 게 아닙니다. 지표는 파이프라인을 타고 흐릅니다 — DB가 내부 통계를 노출하면, exporter가 긁어 변환하고, Prometheus가 시계열로 저장하고, Grafana가 그리고 경보하고, 담당자가 원인 쿼리·락을 추적합니다. 이 다섯 홉을 알면 "패널이 왜 비어 있지"와 "DB가 실제로 멀쩡한지"를 구분해 진단할 수 있습니다.
[DB 내부] pg_stat_* 뷰가 연결수·커밋·락·버퍼 통계를 실시간 노출
│
① 노출 DB가 pg_stat_database·pg_stat_activity·pg_locks 등으로 지표 제공
│
② 수집 postgres_exporter가 그 뷰를 조회해 Prometheus 형식으로 변환(:9187)
│
③ 저장·집계 Prometheus가 scrape_interval마다 긁어 시계열로 저장(rate로 추세 계산)
│
④ 시각화·경보 Grafana가 PromQL로 패널을 그리고, 규칙이 임계 초과 시 알람 발사
│
⑤ 추적 경보를 받은 담당자가 pg_stat_statements·pg_locks로 범인 쿼리·락 확인
▼
[대응] 느린 쿼리 최적화 / 락을 쥔 세션 정리
각 홉이 하는 일과, 거기서 끊기면 나타나는 증상:
| 단계 | 하는 일 | 여기서 끊기면 증상 |
|---|---|---|
| ① 노출 | pg_stat_* 뷰로 내부 지표 제공 | pg_stat_statements 미로드 → 쿼리 통계 자체가 없음 |
| ② 수집 | exporter가 뷰 조회 후 메트릭 변환 | DSN·권한 오류 → :9187이 비거나 target down |
| ③ 저장·집계 | Prometheus가 주기적 scrape·시계열 저장 | scrape 설정 오타·방화벽 → 패널 데이터 공백 |
| ④ 시각화·경보 | PromQL 패널·알람 규칙 평가 | for 없이 짧은 스파이크 알람 → 알람 피로 |
| ⑤ 추적 | 슬로우 쿼리·락 대기 원인 규명 | 지표는 정상인데 특정 쿼리만 느림 → 통계 노후(plan regression) |
즉 비어 있거나 평평한 패널이 항상 "DB가 한가하다"는 뜻은 아닙니다. 패널이 비면 파이프라인을 거꾸로 짚습니다 — ④(패널 쿼리) → ③(scrape 설정) → ②(exporter target 상태) → ①(뷰·확장 로드) 순으로 어디서 끊겼는지 좁힙니다. 반대로 파이프라인은 멀쩡한데(자원 골든 시그널이 모두 정상) 특정 API만 느리면, ⑤에서 쿼리별 실행시간의 회귀를 봐야 합니다 — 자원 지표 밖에 숨은 지연입니다.
pg_stat_statements — 슬로우 쿼리를 사후에 잡는 뷰
pg_stat_statements는 PostgreSQL에서 실행된 모든 쿼리의 통계를 누적 집계합니다. EXPLAIN ANALYZE가 특정 쿼리 하나를 즉시 해부하는 것이라면, pg_stat_statements는 "지난 24시간 동안 어떤 쿼리가 DB를 가장 많이 갉아먹었는가"를 알려주는 전체 워크로드 X선 사진입니다.
 확대
확대
활성화 방법
# postgresql.conf 수정
# Docker 환경이면 postgres 컨테이너 셸 진입 후 또는 environment 변수로 설정
echo "shared_preload_libraries = 'pg_stat_statements'" >> /etc/postgresql/15/main/postgresql.conf
echo "pg_stat_statements.track = all" >> /etc/postgresql/15/main/postgresql.conf
# PostgreSQL 재시작
sudo systemctl restart postgresql
# 또는 Docker에서
docker run -e POSTGRES_PASSWORD=secret \
-e POSTGRES_INITDB_ARGS="--encoding=UTF8" \
postgres:15 \
-c shared_preload_libraries=pg_stat_statements \
-c pg_stat_statements.track=all
-- 데이터베이스에 확장 설치 (한 번만)
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- 설치 확인
SELECT * FROM pg_extension WHERE extname = 'pg_stat_statements';
상위 슬로우 쿼리 조회
추측 대신 데이터로 범인을 찾습니다. 평균 실행시간 순(avg_ms)과 총 소비시간 순(total_exec_time)으로 각각 정렬해, "느린 쿼리"와 "DB 자원을 가장 많이 먹는 쿼리"가 다를 수 있음을 확인합니다.
-- (A) 평균이 느린 쿼리
SELECT query, calls, total_exec_time / calls AS avg_ms, rows
FROM pg_stat_statements
ORDER BY avg_ms DESC LIMIT 10;
-- (B) 총 소비시간이 큰 쿼리 = 최적화 효과가 큰 쿼리
SELECT LEFT(query, 60) AS q, calls, ROUND(total_exec_time) AS total_ms,
ROUND(100.0 * total_exec_time / SUM(total_exec_time) OVER (), 1) AS pct
FROM pg_stat_statements
WHERE calls > 100
ORDER BY total_exec_time DESC LIMIT 10;
-- (B) 총 소비시간 순
q | calls | total_ms | pct
--------------------------+--------+----------+------
SELECT * FROM orders ... | 184320 | 920400 | 41.2 ← 전체의 41%
SELECT * FROM users ... | 90211 | 210500 | 9.4
SELECT query, calls, total_exec_time/calls AS avg_ms, rows FROM pg_stat_statements ORDER BY avg_ms DESC LIMIT 10;- (A)와 (B)의 1순위가 다른지 본다 — avg_ms 1위(드물게 도는 무거운 배치)와 total 1위(자주 도는 보통 쿼리)는 보통 다르다. 시스템 체감 성능은 (B)가 좌우한다
- (B)의 pct 열을 본다. 한 쿼리가 40%를 차지하면 그 쿼리 하나 최적화가 전체를 바꾼다 — 여기를 1순위로 잡는다
- calls가 매우 큰데 avg_ms도 높으면 N+1이나 인덱스 부재 의심 — 해당 query를 EXPLAIN ANALYZE로 넘긴다
- 분석 사이클을 새로 시작할 땐 SELECT pg_stat_statements_reset(); 으로 통계를 초기화한 뒤 일정 시간 모아 다시 본다
이 쿼리 하나로 "어떤 쿼리가 평균 몇 ms가 걸렸는지"를 바로 확인할 수 있습니다. calls가 높고 avg_ms도 높은 쿼리가 1순위 최적화 대상입니다. calls가 낮더라도 avg_ms가 수천 ms인 쿼리는 배치 또는 리포트성일 가능성이 높습니다.
유용한 분석 쿼리
-- 총 실행 시간 기준 (DB 자원을 가장 많이 소비한 쿼리)
SELECT
LEFT(query, 80) AS query_snippet,
calls,
ROUND(total_exec_time) AS total_ms,
ROUND(total_exec_time / calls) AS avg_ms,
ROUND(rows::numeric / calls, 1) AS avg_rows,
ROUND(100.0 * total_exec_time /
SUM(total_exec_time) OVER (), 2) AS pct_total
FROM pg_stat_statements
WHERE calls > 100
ORDER BY total_exec_time DESC
LIMIT 15;
-- 통계 초기화 (분석 사이클을 새로 시작할 때)
SELECT pg_stat_statements_reset();
pct_total 컬럼이 핵심입니다. 어떤 쿼리 하나가 DB 전체 실행 시간의 40%를 차지하고 있다면, 그 쿼리 하나 최적화가 시스템 전체 성능을 바꿉니다.
실습: MySQL slow_query_log 설정
MySQL 환경에서는 slow_query_log가 파일 기반으로 슬로우 쿼리를 수집합니다. long_query_time을 초 단위로 설정하며, 이 시간을 초과한 쿼리가 로그 파일에 기록됩니다.
MySQL 전역 설정 런타임 변경
안전한 실행 조건: my.cnf에 동일하게 추가해야 영구 적용됩니다
실행 전 반드시 확인
- 로그 파일 저장 경로의 디스크 여유 공간 확인
- long_query_time 임계값을 운영 쿼리 특성에 맞게 설정
- 운영 피크 시간을 피해 설정 변경
SET GLOBAL slow_query_log = 'ON'위 항목을 모두 확인한 후 복사할 수 있습니다
-- MySQL에서 슬로우 쿼리 로그 활성화 (재시작 없이 적용)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 1초 이상인 쿼리 기록
SET GLOBAL log_queries_not_using_indexes = 'ON'; -- 인덱스 미사용 쿼리도 포함
-- 설정 확인
SHOW VARIABLES LIKE 'slow_query%';
SHOW VARIABLES LIKE 'long_query_time';
SHOW VARIABLES LIKE 'log_queries_not_using_indexes';
영구 적용을 위해 my.cnf에도 추가합니다.
# /etc/mysql/my.cnf 또는 /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
log_queries_not_using_indexes = 1
min_examined_row_limit = 100 # 소량 행 쿼리는 제외 (노이즈 감소)
로그 파일이 쌓이면 mysqldumpslow로 요약합니다.
# 평균 실행 시간 기준 상위 10개 출력
mysqldumpslow -s at -t 10 /var/log/mysql/slow.log
# 총 시간 기준 (DB 자원을 가장 많이 소비한 쿼리)
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 특정 테이블이 포함된 쿼리만 필터
mysqldumpslow -s at -t 10 /var/log/mysql/slow.log | grep -A5 "orders"
임계값 선택 기준: OLTP 서비스(사용자가 직접 사용하는 API)라면
long_query_time = 0.3(300ms)부터 시작하는 것이 좋습니다. 배치 처리, 리포트 쿼리 위주 시스템이라면long_query_time = 1(1초)이 적당합니다. 임계값이 너무 낮으면 로그가 폭발해 정작 중요한 쿼리를 놓치고, 너무 높으면 사용자가 이미 고통받고 있는 쿼리를 감지하지 못합니다.
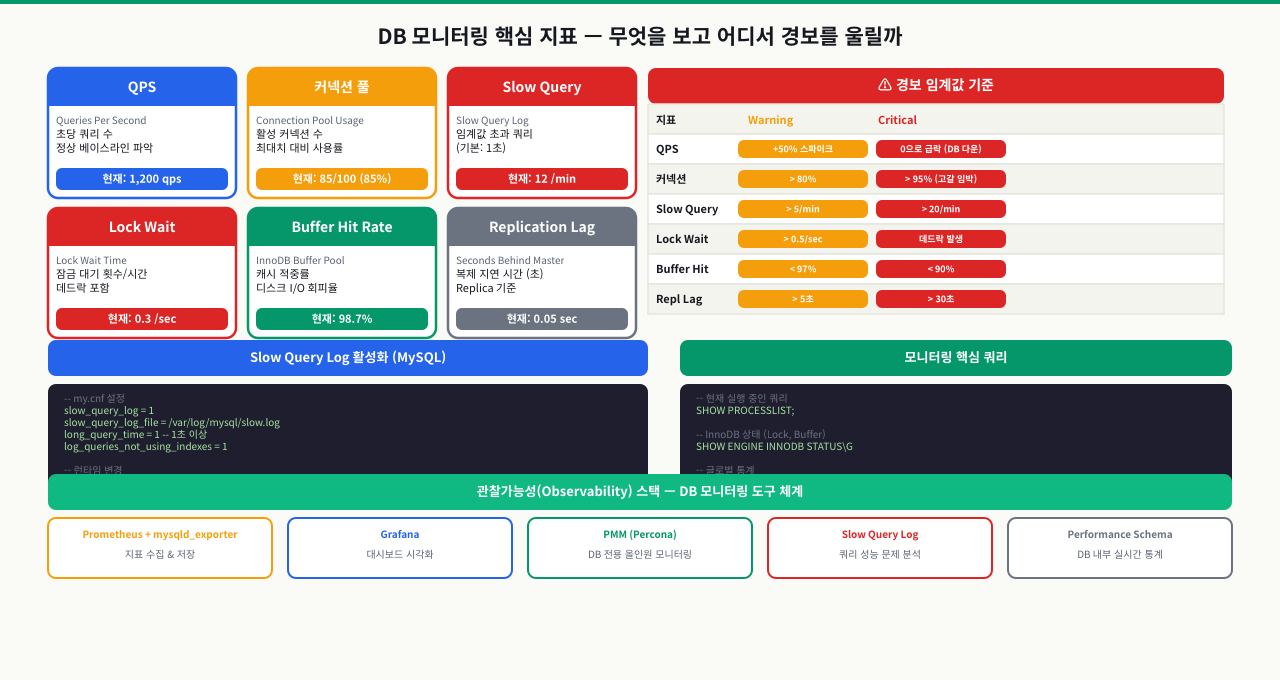
postgres_exporter 핵심 메트릭 — 무엇을 왜 보는가
prometheus/postgres_exporter는 PostgreSQL의 내부 통계 뷰(pg_stat_*)를 Prometheus가 수집할 수 있는 메트릭 형식으로 변환합니다. 수십 개의 메트릭 중 운영 현장에서 반드시 봐야 하는 3가지 범주가 있습니다.
 확대
확대
1. QPS (Queries Per Second) — 부하 추세
# 초당 쿼리 수 (커밋+롤백 기준)
rate(pg_stat_database_xact_commit{datname="appdb"}[5m])
+ rate(pg_stat_database_xact_rollback{datname="appdb"}[5m])
QPS 자체보다 QPS의 갑작스러운 변화가 중요합니다. 평소 대비 3배 이상 급등하거나 갑자기 0에 가까워지면 모두 이상 신호입니다.
2. 활성 커넥션 수 — 풀 포화 감지
# 현재 활성 연결 수
pg_stat_activity_count{datname="appdb", state="active"}
# 최대 연결 수 대비 사용률 (%)
100 * pg_stat_activity_count{datname="appdb"}
/ pg_settings_max_connections
연결 수가 max_connections의 80%를 넘으면 새 연결이 실패하기 시작합니다. 70%에서 알람을 걸어야 대응 시간이 생깁니다.
3. 캐시 히트율 — 메모리 충분성 판단
# 캐시 히트율 (%) — 데이터를 디스크가 아닌 메모리에서 읽은 비율
100 * pg_stat_database_blks_hit{datname="appdb"}
/ (pg_stat_database_blks_hit{datname="appdb"}
+ pg_stat_database_blks_read{datname="appdb"})
90% 이상이 정상입니다. 90% 미만이면 데이터의 상당 부분이 shared_buffers 밖에 있어 디스크 I/O가 반복됩니다. shared_buffers를 늘리거나 (총 메모리의 25~40% 권장), Full Scan을 유발하는 쿼리를 최적화하는 것이 해결 방향입니다.
추가로 수집할 유용한 메트릭
| 메트릭 이름 | 의미 | 알람 조건 |
|---|---|---|
pg_replication_lag | 복제 지연(초) | 30초 이상 |
pg_stat_database_deadlocks | 데드락 발생 횟수 | 분당 1건 이상 |
pg_stat_database_temp_bytes | 임시 파일 사용량 | 지속 증가 추세 |
pg_stat_bgwriter_maxwritten_clean | checkpoint 강제 발생 | 0이 아닐 때 |
실습: Grafana 대시보드 필수 패널 4개
Grafana에서 새 대시보드를 만들고 아래 4개 패널을 구성합니다. 각 패널은 "무엇을 왜 보는가"가 명확해야 합니다.
패널 1 — QPS (초당 트랜잭션 수)
# Grafana PromQL 입력란에 붙여넣기
rate(pg_stat_database_xact_commit{datname="appdb"}[1m])
+ rate(pg_stat_database_xact_rollback{datname="appdb"}[1m])
- 패널 유형: Time series
- 목적: 트래픽 급증/급감을 가장 먼저 감지
- 임계 라인: 평소 최대값 × 2 (주석으로 표시)
패널 2 — 활성 커넥션 vs max_connections
# 활성 커넥션
pg_stat_activity_count{datname="appdb", state="active"}
# 위험 임계선 (max_connections의 70%)
0.7 * pg_settings_max_connections
- 패널 유형: Time series (2개 라인 겹치기)
- 목적: 커넥션 포화 직전 경보
패널 3 — 캐시 히트율
100 * pg_stat_database_blks_hit{datname="appdb"}
/ (pg_stat_database_blks_hit{datname="appdb"}
+ pg_stat_database_blks_read{datname="appdb"} + 1)
- 패널 유형: Gauge (0~100%)
- 색상 임계값: 90 이상 = 초록, 80~90 = 노랑, 80 미만 = 빨강
패널 4 — 슬로우 쿼리 상위 5개 (테이블)
Grafana에서 PostgreSQL 데이터소스를 추가 연결하면 SQL 패널 유형을 쓸 수 있습니다.
SELECT
LEFT(query, 100) AS "쿼리",
calls AS "호출 수",
ROUND(total_exec_time / calls) AS "평균(ms)",
ROUND(total_exec_time) AS "총 시간(ms)"
FROM pg_stat_statements
WHERE calls > 10
ORDER BY total_exec_time / calls DESC
LIMIT 5;
- 패널 유형: Table
- 목적: 대시보드를 열자마자 최우선 최적화 대상 쿼리가 눈에 들어오도록
팁: Grafana Labs에는 PostgreSQL용 공식 대시보드 ID 9628이 있습니다. Import 기능으로 즉시 불러올 수 있으며, 위 4개 패널 커스터마이징의 출발점으로 활용하세요.
알람 임계값 설정 기준 — 300ms vs 1000ms의 근거
알람 임계값은 "이 숫자를 넘으면 사용자가 영향을 받는가"를 기준으로 결정합니다. 보편적인 정답은 없지만, 판단 프레임워크가 있습니다.
서비스 유형별 권장 임계값
| 서비스 유형 | 슬로우 쿼리 임계값 | 근거 |
|---|---|---|
| 사용자 직접 호출 API (OLTP) | 100~300ms | 사용자 체감 속도 기준. 200ms 이상은 "느리다"고 느낌 |
| 내부 API / 관리자 화면 | 500~1000ms | 내부 사용자는 상대적으로 허용 범위 넓음 |
| 배치 / 집계 쿼리 | 3000~10000ms | 사람이 직접 기다리지 않으므로 넓게 설정 |
| 실시간 검색 | 50~100ms | 검색은 빠르지 않으면 이탈률 증가 |
Prometheus 알람 규칙 예시
# prometheus/rules/postgres.yml
groups:
- name: postgres_alerts
rules:
# 커넥션 포화 경고
- alert: PostgresHighConnections
expr: |
pg_stat_activity_count{datname="appdb"}
/ pg_settings_max_connections > 0.7
for: 2m
labels:
severity: warning
annotations:
summary: "PostgreSQL 커넥션 사용률 70% 초과"
description: "현재 커넥션 수가 max_connections의 {{ $value | humanizePercentage }} 수준입니다."
# 캐시 히트율 저하
- alert: PostgresLowCacheHitRate
expr: |
100 * pg_stat_database_blks_hit{datname="appdb"}
/ (pg_stat_database_blks_hit{datname="appdb"}
+ pg_stat_database_blks_read{datname="appdb"} + 1) < 90
for: 5m
labels:
severity: warning
annotations:
summary: "PostgreSQL 캐시 히트율 90% 미만"
description: "캐시 히트율이 {{ $value | humanize }}%입니다. shared_buffers 증가 또는 쿼리 최적화가 필요합니다."
# 데드락 발생
- alert: PostgresDeadlockDetected
expr: |
rate(pg_stat_database_deadlocks{datname="appdb"}[5m]) > 0
for: 1m
labels:
severity: critical
annotations:
summary: "PostgreSQL 데드락 감지"
description: "분당 {{ $value | humanize }}건의 데드락이 발생하고 있습니다."
알람 피로(Alert Fatigue) 방지
알람이 너무 자주 울리면 팀이 무시하기 시작합니다. for: 2m 조건은 "2분 이상 지속될 때만 알람"을 의미합니다. 순간적 스파이크는 무시하고 지속적인 문제만 알람을 보내는 것이 핵심입니다.
실습: 잠금 경합 실시간 진단
슬로우 쿼리의 원인이 항상 쿼리 자체에 있는 것은 아닙니다. 다른 트랜잭션이 잠금을 쥐고 있어 대기하는 경우도 흔합니다.
PostgreSQL — pg_locks로 잠금 대기 확인
-- 현재 잠금 대기 중인 세션과 원인 세션을 함께 표시
SELECT
blocked.pid AS blocked_pid,
blocked.query AS blocked_query,
blocking.pid AS blocking_pid,
blocking.query AS blocking_query,
blocked.wait_event_type,
blocked.wait_event,
EXTRACT(EPOCH FROM NOW() - blocked.query_start)::int AS wait_seconds
FROM pg_stat_activity AS blocked
JOIN pg_stat_activity AS blocking
ON blocking.pid = ANY(pg_blocking_pids(blocked.pid))
WHERE blocked.cardinality(pg_blocking_pids(blocked.pid)) > 0
ORDER BY wait_seconds DESC;
wait_seconds가 수십 초를 넘는 세션이 있다면 blocking_pid를 찾아 원인 쿼리를 확인하고, 필요하면 SELECT pg_terminate_backend(blocking_pid)로 강제 종료합니다.
-- 잠금 타입별 현황 요약
SELECT
locktype,
relation::regclass AS table_name,
mode,
granted,
COUNT(*) AS count
FROM pg_locks
WHERE relation IS NOT NULL
GROUP BY locktype, relation, mode, granted
ORDER BY count DESC;
MySQL — InnoDB 트랜잭션 대기 확인
-- 현재 실행 중인 트랜잭션 목록
SELECT
trx_id,
trx_state,
trx_started,
TIMESTAMPDIFF(SECOND, trx_started, NOW()) AS duration_sec,
trx_rows_locked,
trx_rows_modified,
LEFT(trx_query, 120) AS current_query
FROM information_schema.innodb_trx
ORDER BY trx_started ASC;
duration_sec이 길고 trx_state = 'LOCK WAIT'인 트랜잭션이 있다면 잠금 경합이 진행 중입니다.
-- 잠금 대기 그래프 (MySQL 8.0 — performance_schema 활용)
SELECT
r.trx_id AS waiting_trx_id,
r.trx_query AS waiting_query,
b.trx_id AS blocking_trx_id,
b.trx_query AS blocking_query,
b.trx_mysql_thread_id AS blocking_thread
FROM information_schema.innodb_lock_waits w
JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id
JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id;
예방 패턴: 트랜잭션은 짧게 유지하고, 같은 순서로 잠금을 획득하도록 코드를 설계하면 데드락과 잠금 경합을 구조적으로 줄일 수 있습니다.
이 에러는 PostgreSQL의 max_connections 한도에 도달했을 때 발생합니다. PostgreSQL은 마지막 몇 개의 연결 슬롯을 슈퍼유저와 복제 연결을 위해 예약(superuser_reserved_connections, 기본값 3)하며, 일반 사용자 연결이 이 예약분까지 채우면 신규 연결이 즉시 거부됩니다.
즉각 대응 (운영 중 연결 정리):
-- 현재 연결 상태 확인
SELECT state, COUNT(*) FROM pg_stat_activity GROUP BY state;
-- 유휴 연결 강제 종료 (idle 상태 5분 이상)
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE state = 'idle'
AND query_start < NOW() - INTERVAL '5 minutes'
AND pid <> pg_backend_pid();
중기 해결책 (설정 조정):
-- 현재 max_connections 확인
SHOW max_connections;
-- 현재 연결 수 확인
SELECT COUNT(*) FROM pg_stat_activity;
# postgresql.conf
max_connections = 200 # 기본값(100)보다 크게
superuser_reserved_connections = 5 # 슈퍼유저 예약 슬롯
근본 해결책 (커넥션 풀 도입):
애플리케이션이 직접 DB에 연결하는 구조라면 PgBouncer를 앞에 두는 것이 장기 해결책입니다. max_connections를 늘리는 것만으로는 언젠가 다시 같은 에러가 발생합니다. 스케일아웃 환경(컨테이너 오토스케일 등)에서는 파드 수 × 풀 크기가 max_connections를 초과하는 것은 시간문제입니다.
connection-pooling 모듈에서 PgBouncer + HikariCP 2계층 아키텍처를 다룹니다.
심화 — 지표는 정상인데 느리다: 실행계획 회귀를 관측하기
심화: 골든 시그널이 못 잡는 지연 — 통계 노후와 plan regression
QPS·커넥션·캐시 히트율이 모두 정상인데 특정 API만 갑자기 느려질 때가 있습니다. 자원 지표만 보면 '문제가 없어 보이는' 이 유형의 흔한 범인은 통계 노후로 인한 실행계획 회귀(plan regression) 입니다.
- 옵티마이저는
pg_statistic(ANALYZE가 채움)의 행 수·분포 추정으로 계획을 고릅니다. 대량 적재/삭제 뒤 통계가 낡으면 추정이 실제와 크게 어긋나, 그 쿼리만 인덱스 스캔 대신 Seq Scan이나 잘못된 조인(Nested Loop)을 골라 수십 배 느려집니다. - 이건 자원 지표가 아니라 '쿼리별 시간'을 봐야 잡힙니다:
pg_stat_statements에서 그 쿼리의mean_exec_time만 급등,auto_explain으로 실제 계획을 로깅, PostgreSQL 16+는 계획 식별로 회귀를 추적합니다. - 그래서 성숙한 모니터링은 자원 골든 시그널뿐 아니라 쿼리별 평균/총 실행시간의 회귀와 추정 행 수 대 실제 행 수의 괴리까지 관측 대상에 넣습니다.
핵심은 '서버는 한가한데 특정 쿼리만 느리다'는 신호를 자원 지표 밖에서 잡을 수 있어야 한다는 것입니다.
상황: 야간 대량 적재 배치 뒤 아침에 특정 목록 API만 급격히 느려졌습니다. 대시보드의 QPS·커넥션·캐시 히트율은 모두 정상 범위라, 자원 지표만 봐서는 어디가 문제인지 보이지 않습니다.
원인: 적재로 테이블 내용이 크게 바뀌었는데 통계(ANALYZE)가 아직 갱신되지 않아 옵티마이저의 행 수 추정이 실제와 크게 어긋났습니다. 그 결과 그 쿼리만 인덱스 스캔 대신 Seq Scan/비효율 조인 계획으로 회귀해 느려졌습니다 — 서버 자원은 남으니 골든 시그널에는 흔적이 안 남습니다.
진단: pg_stat_statements에서 그 쿼리의 mean_exec_time·total_exec_time이 특정 시점부터 급등했는지 확인합니다. EXPLAIN (ANALYZE)로 예상 rows와 실제 rows의 큰 괴리·Seq Scan 여부를 보고, auto_explain 로그로 계획 변화를 대조합니다.
해결: 해당 테이블에 ANALYZE(또는 VACUUM ANALYZE)를 실행해 통계를 갱신하면 대개 계획이 정상으로 돌아옵니다. 대량 적재 배치의 마지막 단계에 ANALYZE를 넣고, 편차가 큰 컬럼은 통계 타깃을 올립니다(ALTER TABLE ... ALTER COLUMN ... SET STATISTICS). 모니터링에는 자원 지표만이 아니라 '쿼리별 평균 실행시간 회귀' 알람을 추가해, 자원이 멀쩡한데 느려지는 이 유형을 선제적으로 잡습니다(쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화).
"DBA 없는 팀에서 백엔드 개발자가 직접 셋업하는 모니터링 스택"
스타트업이나 중소 서비스팀에는 DBA가 없는 경우가 대부분입니다. DB 모니터링이 없어도 평소에는 아무 문제가 없어 보입니다. 그러다 트래픽이 몰리거나 대형 배치 작업이 실행되는 순간, 아무도 원인을 모르는 장애가 발생합니다.
이 모듈에서 다룬 스택(pg_stat_statements + postgres_exporter + Prometheus + Grafana)은 오픈소스로 라이선스 비용이 없으며, Docker Compose 하나로 로컬에서도 돌아갑니다. 설정에 걸리는 시간은 반나절입니다. 그 반나절 투자가 다음 장애의 원인 파악 시간을 38분에서 3분으로 줄입니다.
현업에서 이 스택을 처음 셋업할 때 가장 중요한 순서는 다음과 같습니다:
pg_stat_statements활성화 → 즉시 슬로우 쿼리 누적 시작- Grafana 대시보드 4개 패널 → 팀 모두가 같은 화면을 볼 수 있는 기반
- 커넥션 포화 알람 → 가장 빈번한 운영 장애를 사전 감지
- 슬로우 쿼리 알람 → SLA 기반 임계값 설정으로 품질 기준 명문화
"모니터링은 나중에"는 항상 장애 다음에 후회하는 말입니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 슬로우 쿼리 분석·잠금 진단 쿼리와 CLI 도구를 실전 옵션과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
SHOW shared_preload_libraries | pg_stat_statements 로드 확인 | 없으면 postgresql.conf에 추가 후 재시작 |
CREATE EXTENSION IF NOT EXISTS pg_stat_statements | 쿼리 통계 확장 설치 | DB당 1회 |
SELECT ... FROM pg_stat_statements ORDER BY total_exec_time DESC | 자원 최다 소비 쿼리 | pct_total 40%면 그 쿼리 1순위 최적화 |
SELECT pg_stat_statements_reset() | 분석 사이클 통계 초기화 | 일정 시간 다시 수집 후 재분석 |
SET GLOBAL slow_query_log='ON' (MySQL) | 슬로우 쿼리 로그 활성화 | SET GLOBAL long_query_time = 1(초) |
SHOW VARIABLES LIKE 'slow_query%' (MySQL) | 슬로우 로그 설정 확인 | long_query_time·로그 파일 경로 |
mysqldumpslow -s at -t 10 | 슬로우 로그 요약 | -s at(평균)·-s t(총시간) 정렬 |
pg_blocking_pids(pid) + pg_stat_activity | 잠금 대기·원인 세션 추적 | blocked/blocking 쿼리 함께 조회 |
pg_terminate_backend(pid) | 원인 세션 강제 종료 | wait_seconds 큰 blocking_pid 종료 |
SELECT ... FROM pg_locks WHERE relation IS NOT NULL | 잠금 타입별 현황 | mode·granted별 집계 |
information_schema.innodb_trx (MySQL) | InnoDB 트랜잭션·락 대기 | trx_state = 'LOCK WAIT' 확인 |
SHOW max_connections / SELECT COUNT(*) FROM pg_stat_activity | 연결 한도·현재 수 | 슬롯 소진(FATAL) 대응 |
관련 모듈로 더 깊이:
- DB 연결 지연을 없애는 HikariCP 설정과 대기 성능 튜닝 — 모니터링이 가장 먼저 잡아내는 커넥션 포화의 원인과 PgBouncer 설계
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — pg_stat_statements로 찾은 슬로우 쿼리를 실제로 개선하는 법
- 쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화 — 느린 쿼리를 EXPLAIN 출력으로 노드 단위 진단하는 법
다음 모듈에서는 DB 연결 지연을 없애는 HikariCP 설정과 커넥션 풀 대기 성능 튜닝 방법을 다룹니다.