랭킹, 누적합, 전월 대비 같은 분석 쿼리는 GROUP BY만으로는 원본 행을 유지하기 어렵습니다. 윈도우 함수는 행을 접지 않고 주변 행과 비교하는 강력한 도구입니다. 리포트와 운영 대시보드 쿼리를 작성할 때 큰 차이를 만듭니다.
Window 함수는 OVER() 절로 정의된 '윈도우(창)'를 통해 관련 행들을 바라보며 집계나 분석을 수행합니다. GROUP BY와 달리 각 행이 원본 그대로 결과에 남아있으면서 집계값도 함께 표시됩니다. PARTITION BY로 그룹 경계를, ORDER BY로 행의 순서를, ROWS/RANGE로 프레임 범위를 정의합니다.
- 1OVER() 절의 PARTITION BY, ORDER BY, FRAME으로 Window 함수 구조를 작성할 수 있다
- 2ROW_NUMBER, RANK, DENSE_RANK, NTILE 순위 함수를 구분해 사용할 수 있다
- 3GROUP BY와 달리 왜 행이 줄어들지 않는지 설명할 수 있다
- 4LAG, LEAD로 이전/다음 행 값을 참조해 증감률을 계산할 수 있다
- 5SUM, AVG OVER 프레임으로 누적합과 이동평균을 계산할 수 있다
- 6FIRST_VALUE, LAST_VALUE로 윈도우 경계 값을 추출할 수 있다
Window 함수 — RANK, ROW_NUMBER, LAG, LEAD
영업팀 요청이 왔다. 각 직원의 월별 매출과 전체 순위를 함께 보고 싶다고. GROUP BY로 집계하면 개별 매출 행이 사라지고, 서브쿼리로 순위를 붙이려니 자기 JOIN이 두 겹 세 겹 쌓였다. 쿼리가 20줄이 넘었고 실행 계획을 보면 테이블을 세 번 스캔하고 있었다. 그때 누군가 RANK() OVER (ORDER BY sales DESC) 한 줄을 보여줬다. 원본 행은 그대로 두면서 각 행에 순위 컬럼만 추가됐다 — 테이블 스캔은 한 번. Window 함수를 모르면 서브쿼리 지옥이나 애플리케이션 레이어 정렬로 우회하게 되고, 쿼리는 점점 읽기 어려워진다. RANK, ROW_NUMBER, LAG — 이 세 가지만 제대로 알아도 분석 쿼리의 절반은 깔끔하게 해결된다.
Window 함수 기초 — OVER()가 GROUP BY와 다른 이유
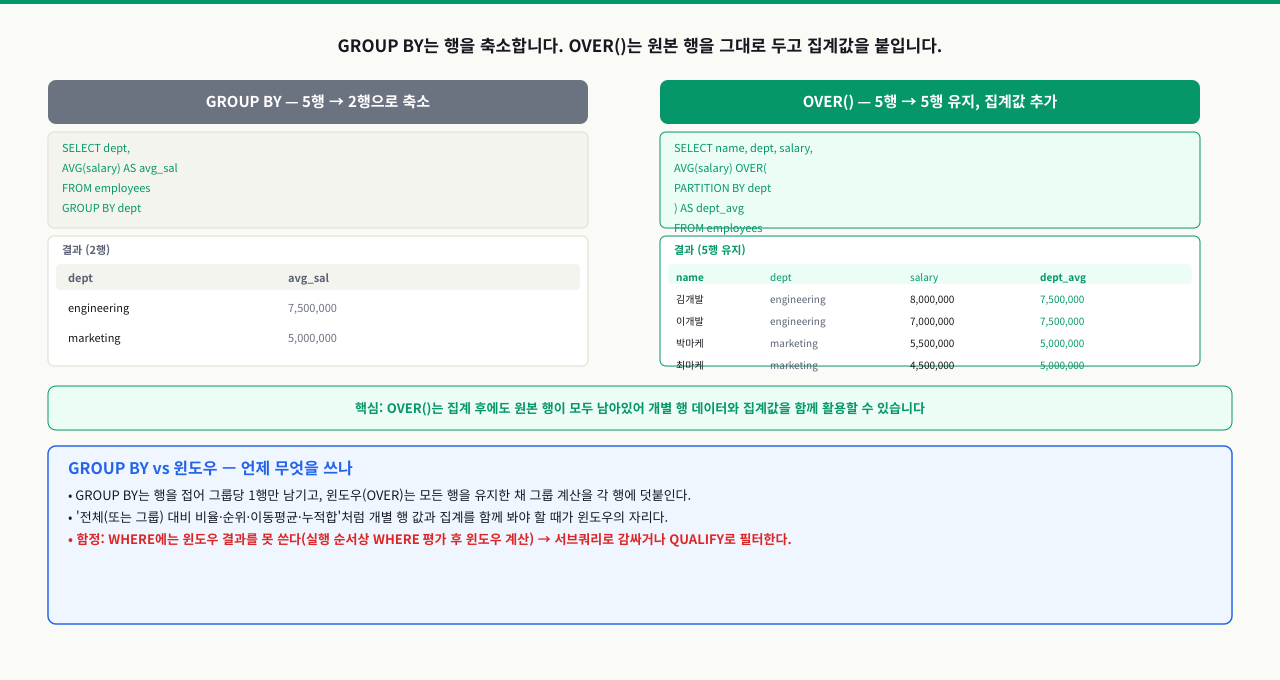
부서별 직원 급여를 조회하면서 부서 평균도 같이 보고 싶습니다. GROUP BY를 쓰면 개별 행이 사라지고, 서브쿼리를 쓰면 복잡해집니다. Window 함수는 행을 유지하면서 그룹 집계를 동시에 할 수 있습니다. GROUP BY와 무엇이 다른지 이해하지 못하면 이런 요구사항마다 복잡한 서브쿼리를 짜게 됩니다.
Window 함수란?
Window 함수는 현재 행과 관련된 행들의 집합(윈도우)에 대해 계산을 수행하는 함수입니다. 핵심은 행을 줄이지 않는다는 점입니다. GROUP BY는 그룹 수만큼 행을 압축하지만, Window 함수는 원본 행을 그대로 유지하면서 집계값을 각 행에 추가합니다.
 확대
확대
SELECT category_id, AVG(price) AS avg_price
FROM products
GROUP BY category_id;
SELECT
product_name,
category_id,
price,
AVG(price) OVER (PARTITION BY category_id) AS category_avg
FROM products;
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 결과 행 수를 GROUP BY 쿼리와 비교합니다. GROUP BY는 카테고리 수(예: 5행)를 반환하고 Window 함수는 원본 상품 수(예: 50행)를 반환합니다 — 행 수가 줄었다면 WHERE나 HAVING이 개입한 것입니다.
- PARTITION BY 경계에서 값이 리셋되는지 확인합니다. category_id가 바뀌는 첫 행에서 RANK()가 1로 돌아가야 합니다. 전체를 관통해 순위가 이어진다면 PARTITION BY가 누락된 것입니다.
- 두 시그널을 조합합니다: ROW_NUMBER()가 같은 partition 내에서 중복 번호를 반환하고 + ORDER BY 기준 컬럼에 동점 행이 있다면 → 타이브레이커 컬럼(예: id)을 ORDER BY에 추가해야 결정적 결과를 보장합니다.
첫 번째 쿼리는 카테고리가 5개라면 5행을 반환합니다. 두 번째 쿼리는 상품 수만큼 행을 반환하며, 각 행에 해당 카테고리의 평균 가격이 함께 표시됩니다.
OVER() 절 구조
OVER() 절은 세 가지 구성 요소로 이루어집니다. PARTITION BY는 윈도우를 나누는 기준으로, 생략하면 전체가 하나의 파티션입니다. ORDER BY는 파티션 내에서 행의 순서를 정의하며, 순위 함수와 누적합에 필수입니다. ROWS/RANGE BETWEEN은 현재 행 기준으로 프레임(계산 범위)을 정의합니다.
함수명() OVER (
PARTITION BY 그룹기준컬럼
ORDER BY 정렬기준컬럼 [ASC|DESC]
ROWS BETWEEN 시작 AND 끝
)
순위 함수 비교 — ROW_NUMBER, RANK, DENSE_RANK, NTILE
네 가지 순위 함수는 동점 처리 방식에서 차이가 납니다. 어떤 함수를 선택하느냐에 따라 비즈니스 로직이 달라지므로 구분을 명확히 해야 합니다.
| 함수 | 동점 처리 | 다음 순위 | 주요 용도 |
|---|---|---|---|
| ROW_NUMBER() | 동점도 고유 번호 부여 | 연속 | 페이지네이션, 중복 제거 |
| RANK() | 동점은 동일 순위 | 건너뜀(1,2,2,4) | 스포츠 순위표 |
| DENSE_RANK() | 동점은 동일 순위 | 연속(1,2,2,3) | 등급/티어 계산 |
| NTILE(n) | n등분한 분위수 번호 | - | 사분위수, 상위 25% 추출 |
동점(같은 price) 상품이 있을 때 각 함수의 결과:
| product_name | price | ROW_NUMBER | RANK | DENSE_RANK | NTILE(4) |
|---|---|---|---|---|---|
| 상품A | 50000 | 1 | 1 | 1 | 1 |
| 상품B | 40000 | 2 | 2 | 2 | 1 |
| 상품C | 40000 | 3 | 2 | 2 | 2 |
| 상품D | 30000 | 4 | 4 | 3 | 2 |
| 상품E | 20000 | 5 | 5 | 4 | 3 |
SELECT
product_name,
category_id,
price,
ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY price DESC) AS row_num,
RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS dense_rank,
NTILE(4) OVER (PARTITION BY category_id ORDER BY price DESC) AS quartile
FROM products;
순위 함수는 OVER() 안에 ORDER BY가 없으면 어떤 행이 어떤 순위를 받을지 실행마다 달라집니다. 이 문제는 로컬에서는 항상 같아 보여도 운영 환경이나 병렬 실행 시 달라질 수 있습니다.
SELECT product_name, RANK() OVER () AS rnk FROM products;
이 쿼리에서 RANK()는 정렬 기준이 없으므로 모든 행에 1을 반환하거나, 실행 환경에 따라 임의 순서로 순위를 매깁니다. 의미 있는 순위 결과를 얻으려면 반드시 ORDER BY를 명시해야 합니다.
SELECT product_name, RANK() OVER (ORDER BY price DESC) AS rnk FROM products;
또한 ROW_NUMBER()에서 동점 행이 있을 때 ORDER BY 기준이 유니크하지 않으면 동점 행끼리의 번호 배정이 비결정적입니다. 결정적 결과가 필요하면 타이브레이커 컬럼(예: id)을 ORDER BY에 추가하세요.
카테고리별 상위 N개 추출 — ROW_NUMBER 활용
Window 함수 결과는 WHERE 절에서 직접 참조할 수 없으므로 CTE나 서브쿼리로 감싸야 합니다. 아래는 카테고리별 가장 비싼 상위 3개 상품을 추출하는 표준 패턴입니다.
WITH ranked_products AS (
SELECT
product_name,
category_id,
price,
ROW_NUMBER() OVER (
PARTITION BY category_id
ORDER BY price DESC
) AS rn
FROM products
)
SELECT product_name, category_id, price
FROM ranked_products
WHERE rn <= 3;
"정확히 3개"가 필요하면 ROW_NUMBER, "공동 순위 포함"이 필요하면 RANK나 DENSE_RANK를 선택하세요.
Window 함수의 핵심인 PARTITION BY(그룹별 독립 순위)를 직접 확인합니다. 카테고리마다 순위가 1부터 다시 시작하는지, 그리고 Window 결과를 WHERE에서 쓰려면 왜 CTE로 감싸야 하는지 봅니다.
WITH ranked AS (
SELECT
product_name, category_id, price,
ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY price DESC) AS rn
FROM products
)
SELECT product_name, category_id, price, rn
FROM ranked
WHERE rn <= 3
ORDER BY category_id, rn;
product_name | category_id | price | rn
--------------+-------------+---------+----
노트북 Pro | 1 | 2400000 | 1
노트북 Air | 1 | 1500000 | 2
태블릿 X | 1 | 990000 | 3
의자 A | 2 | 320000 | 1
책상 B | 2 | 210000 | 2
WITH ranked AS (SELECT product_name, category_id, price, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY price DESC) AS rn FROM products) SELECT * FROM ranked WHERE rn <= 3;- rn이 각 category_id 안에서 1,2,3으로 다시 시작하는지 본다 — 1이 카테고리마다 한 번씩 나와야 PARTITION BY가 먹은 것. 전체에서 1이 한 번뿐이면 PARTITION BY가 빠진 것
- 같은 카테고리에서 price 내림차순으로 rn이 매겨졌는지 확인 — 순서가 뒤죽박죽이면 OVER 안의 ORDER BY가 누락된 것
- WHERE rn <= 3 을 바깥 SELECT가 아니라 CTE 안에 넣으면 에러가 난다 — Window 결과는 같은 SELECT의 WHERE에서 참조 불가, 반드시 CTE/서브쿼리로 감싼 뒤 필터해야 함
- 동점 가격이 있을 때 ROW_NUMBER는 임의로 끊어 정확히 3개를 주고, RANK는 공동 3위가 여럿이면 3개를 넘길 수 있다 — 요구사항에 맞는 함수인지 판단
집계 Window 함수
SELECT
order_id,
customer_id,
total_amount,
AVG(total_amount) OVER () AS overall_avg,
SUM(total_amount) OVER (PARTITION BY customer_id) AS customer_total,
total_amount / SUM(total_amount) OVER () * 100 AS pct_of_total
FROM orders;
동작 원리 — 윈도우 함수가 한 행을 계산하는 순서
윈도우 함수가 값을 만드는 5단계 — 나누고·정렬하고·범위 잡고·붙인다
SUM(amount) OVER (ORDER BY d)는 누적합이 되는데 SUM(amount) OVER (PARTITION BY cat)는 그룹 합계가 각 행에 붙습니다 — 같은 SUM인데 결과가 왜 다를까요. 게다가 LAST_VALUE는 분명 "마지막 값"인데 자꾸 현재 행 값을 돌려줍니다. 윈도우 함수가 한 행의 값을 만드는 순서를 단계로 보면, OVER 괄호 안의 PARTITION BY·ORDER BY·프레임이 각각 어느 단계에서 무슨 일을 하는지, 프레임 기본값 함정이 왜 생기는지가 정리됩니다.
[FROM·WHERE·GROUP BY·HAVING까지 끝난 행 집합] (윈도우는 그 다음 단계)
│
① 대상 행 집합 확정 (WHERE·HAVING 다 지난 뒤의 행들)
│
② PARTITION BY로 분할 (cat별로 창을 나눔 / 없으면 전체가 한 창)
│
③ ORDER BY로 창 안 정렬 (순위·누적·LAG의 '순서'가 여기서 정해짐)
│
④ 프레임 확정 (ROWS·RANGE) (행마다 계산에 포함할 '범위'를 정함)
│ ORDER BY만 있으면 기본 = 창 시작 ~ 현재 행
│
⑤ 각 행에 함수 적용 (행은 유지) (그 행의 프레임을 보고 값 하나 산출)
▼
[입력과 같은 행 수 + 윈도우 컬럼이 붙은 결과]
각 단계가 하는 일과 함정:
| 단계 | 하는 일 | 이 단계의 함정·증상 |
|---|---|---|
| ① 행 집합 | 윈도우는 SELECT 단계에서, 즉 WHERE·GROUP BY·HAVING이 끝난 뒤 계산된다 | 그래서 윈도우 결과를 같은 쿼리 WHERE에서 못 쓴다 → CTE·서브쿼리로 감싼 뒤 WHERE rn <= 3 |
| ② PARTITION BY | 같은 값끼리 창(윈도우)을 나눈다. 생략하면 전체가 한 창 | 순위가 창마다 1로 리셋. 전체를 관통해 이어지면 PARTITION BY 누락. OVER()(빈 괄호)는 전체 총합·전체 평균이 모든 행에 |
| ③ ORDER BY | 창 안에서 행 순서를 정한다. 순위·LAG·누적합이 이 순서 기준 | OVER 안에 ORDER BY가 없으면 순위가 비결정적. 동점이면 타이브레이커(id)를 ORDER BY에 추가 |
| ④ 프레임 | 이 행의 계산에 넣을 범위를 행마다 정한다. ROWS=물리적 행 수, RANGE=같은 정렬값 묶음 | ORDER BY만 쓰면 기본이 RANGE 시작~현재라 LAST_VALUE가 현재 행까지만 봐서 '마지막'이 안 나온다 → ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 명시. 이동평균엔 예측 가능한 ROWS |
| ⑤ 함수 적용 | 각 행이 자기 프레임을 보고 값 하나를 낸다. 행은 접히지 않음 | GROUP BY와 정반대로 입력 행 수 = 출력 행 수. 행이 줄었다면 WHERE·GROUP BY·JOIN이 개입한 것 |
핵심은 순서입니다 — 윈도우 함수는 '창을 나누고(②) → 줄 세우고(③) → 범위를 정하고(④) → 그 범위로 값 하나를 붙인다(⑤)'. 그래서 "왜 순위가 리셋이 안 되지"는 ②를, "왜 순서가 뒤죽박죽이지"는 ③을, "왜 마지막 값이 현재 행으로 나오지"는 ④의 프레임 기본값을 보면 됩니다. 그리고 이 네 단계 어디서도 행을 합치지 않으므로 결과 행 수는 입력과 같습니다 — 개별 행과 집계를 나란히 보는 것이 윈도우 함수의 존재 이유입니다. 이 정렬(②·③)이 실제로 만드는 성능 비용은 이 모듈 끝의 심화에서 다룹니다.
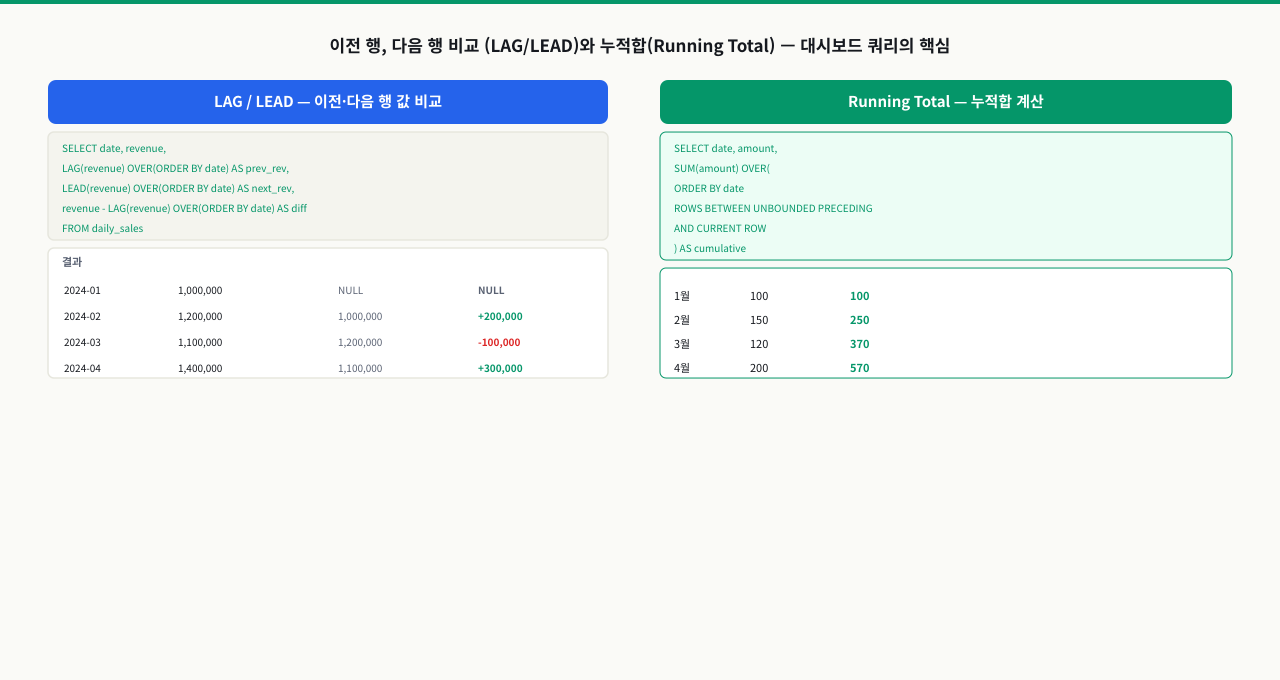
LAG/LEAD와 누적합 — 실무 분석 쿼리 패턴
전월 대비 매출 증감을 계산해야 합니다. 이걸 SQL로 어떻게 하는지 모르겠습니다. 또 일별 주문 건수의 누적합을 보여주는 그래프가 필요합니다. LAG/LEAD와 누적합 패턴을 알면 전월비교, 이동평균, 누계 같은 분석 쿼리를 애플리케이션 코드 없이 SQL에서 바로 계산할 수 있습니다.
 확대
확대
![]() 확대
확대
LAG와 LEAD — 이전/다음 행 값 가져오기
LAG(컬럼, offset, 기본값)은 현재 행보다 offset만큼 앞선 행의 값을 반환하고, LEAD는 뒤따르는 행의 값을 반환합니다. 기본값을 생략하면 파티션 경계에서 NULL이 반환됩니다. 월별 매출 증감률 계산이 대표적인 사용 패턴입니다.
WITH monthly_sales AS (
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(total_amount) AS revenue
FROM orders
GROUP BY 1
)
SELECT
month,
revenue,
LAG(revenue, 1, 0) OVER (ORDER BY month) AS prev_month_revenue,
revenue - LAG(revenue, 1, 0) OVER (ORDER BY month) AS mom_change,
ROUND(
(revenue - LAG(revenue, 1) OVER (ORDER BY month))
/ NULLIF(LAG(revenue, 1) OVER (ORDER BY month), 0) * 100,
2
) AS mom_growth_pct
FROM monthly_sales
ORDER BY month;
누적합(Running Total) — SUM OVER ORDER BY
ORDER BY를 지정하면 기본 프레임이 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW로 설정되어, 파티션 시작부터 현재 행까지의 누적합이 계산됩니다.
SELECT
order_date,
daily_revenue,
SUM(daily_revenue) OVER (ORDER BY order_date) AS cumulative_revenue,
SUM(daily_revenue) OVER (
PARTITION BY DATE_TRUNC('year', order_date)
ORDER BY order_date
) AS ytd_revenue
FROM daily_sales;
이동평균 — ROWS BETWEEN으로 프레임 지정
ROWS BETWEEN은 물리적 행 수 기준으로 프레임을 지정합니다. RANGE BETWEEN은 논리적 값 범위 기준으로, 동일한 ORDER BY 값을 가진 행을 같은 그룹으로 묶습니다. 이동평균에는 예측 가능한 ROWS BETWEEN이 일반적으로 더 적합합니다.
SELECT
sale_date,
daily_revenue,
AVG(daily_revenue) OVER (
ORDER BY sale_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS moving_avg_7d,
AVG(daily_revenue) OVER (
ORDER BY sale_date
ROWS BETWEEN 29 PRECEDING AND CURRENT ROW
) AS moving_avg_30d
FROM daily_sales
ORDER BY sale_date;
FIRST_VALUE와 LAST_VALUE
LAST_VALUE는 기본 프레임이 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW이므로, 파티션의 마지막 값을 올바르게 가져오려면 프레임을 UNBOUNDED FOLLOWING까지 명시적으로 확장해야 합니다.
SELECT
product_name,
category_id,
price,
FIRST_VALUE(product_name) OVER (
PARTITION BY category_id
ORDER BY price DESC
) AS most_expensive_in_category,
LAST_VALUE(product_name) OVER (
PARTITION BY category_id
ORDER BY price DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS least_expensive_in_category
FROM products;
실무 대시보드 쿼리 패턴
SELECT
rep_name,
region,
monthly_sales,
RANK() OVER (ORDER BY monthly_sales DESC) AS national_rank,
RANK() OVER (PARTITION BY region ORDER BY monthly_sales DESC) AS regional_rank,
ROUND(PERCENT_RANK() OVER (ORDER BY monthly_sales) * 100, 1) AS percentile,
ROUND(
monthly_sales / AVG(monthly_sales) OVER (PARTITION BY region) * 100,
1
) AS vs_region_avg_pct,
monthly_sales - LAG(monthly_sales) OVER (
PARTITION BY rep_name ORDER BY month
) AS mom_change
FROM sales_summary
WHERE month = '2024-03-01';
Window 함수 성능 팁
PARTITION BY와 ORDER BY에 사용되는 컬럼에 복합 인덱스를 만들면 정렬 비용을 줄일 수 있습니다. Window 함수 결과를 WHERE로 필터링할 때는 반드시 서브쿼리나 CTE를 사용해야 합니다. Window 함수는 WHERE 절에서 직접 사용할 수 없으며, EXPLAIN ANALYZE 결과에서 WindowAgg 또는 Sort 노드로 나타납니다.
WITH ranked AS (
SELECT *, RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS rnk
FROM products
)
SELECT * FROM ranked WHERE rnk = 1;
데이터 분석팀이 매월 경영진에게 보고하는 실적 대시보드를 자동화하려 합니다. 요구사항은 다음과 같습니다: (1) 연간 누적 매출 추이, (2) 부서 내 담당자 순위, (3) 전월 대비 증감액.
이 세 가지를 과거에는 별도 쿼리 3개와 애플리케이션 조합으로 처리했지만, Window 함수를 사용하면 단일 쿼리로 해결됩니다.
WITH monthly_by_rep AS (
SELECT
rep_id,
rep_name,
department,
DATE_TRUNC('month', sale_date) AS month,
SUM(amount) AS monthly_sales
FROM sales
WHERE sale_date >= DATE_TRUNC('year', CURRENT_DATE)
GROUP BY rep_id, rep_name, department, DATE_TRUNC('month', sale_date)
)
SELECT
month,
rep_name,
department,
monthly_sales,
SUM(monthly_sales) OVER (
PARTITION BY rep_id
ORDER BY month
) AS ytd_cumulative,
RANK() OVER (
PARTITION BY department, month
ORDER BY monthly_sales DESC
) AS dept_rank,
monthly_sales - LAG(monthly_sales) OVER (
PARTITION BY rep_id ORDER BY month
) AS mom_delta
FROM monthly_by_rep
ORDER BY month, department, dept_rank;
추가 JOIN이나 애플리케이션 코드 없이 단일 SQL 쿼리가 대시보드에 필요한 모든 수치를 계산합니다.
심화 — 윈도우 함수의 숨은 비용은 '정렬'이다
심화: WindowAgg 앞의 Sort — work_mem과 인덱스로 다스리기
윈도우 함수는 문법이 깔끔해 공짜처럼 보이지만, 실행 계획에는 거의 항상 정렬(Sort)이 숨어 있습니다. 앞의 '성능 팁'을 한 단계 더 파면, 윈도우 쿼리의 속도는 대부분 '정렬을 얼마나, 어디서 하느냐'로 결정됩니다.
- 윈도우는 정렬된 입력을 요구한다: 각 행에 '그 행이 속한 윈도우'의 값을 붙이려면, DB는 입력을 PARTITION BY 다음 ORDER BY 순으로 정렬해야 합니다. 그래서 실행 계획에는 WindowAgg 노드 아래에 Sort 노드가 붙습니다. 그 정렬 순서를 그대로 내주는 인덱스가 없으면 매번 정렬합니다.
- 서로 다른 윈도우 = 정렬 여러 번: 한 쿼리에 정렬 기준이 다른 윈도우가 여러 개면(전국 순위, 지역별 순위, 담당자별 전월비) 호환되지 않는 정렬마다 다시 정렬합니다. 플래너는 가능하면 정렬을 재사용하도록 윈도우 순서를 잡지만, 기준이 제각각이면 데이터를 여러 번 sort하게 됩니다.
- 정렬이 work_mem을 넘으면 디스크로 샌다: 정렬 대상이 work_mem 한도를 넘으면 인메모리 정렬 대신 임시 파일로 넘치는 '외부 병합 정렬(external merge Disk)'이 됩니다. 이게 윈도우 리포트가 어느 규모부터 갑자기 느려지는 흔한 이유입니다.
EXPLAIN (ANALYZE)의 Sort 노드에Sort Method: external merge Disk: ...kB로 드러납니다. - 인덱스로 정렬을 아예 없앨 수 있다: PARTITION BY·ORDER BY 컬럼 순서에 맞춘 복합 btree 인덱스를 만들면, 플래너가 이미 정렬된 순서로 인덱스를 읽어 Sort 노드를 통째로 건너뜁니다. 정렬을 피할 수 없는 경우엔 해당 세션의 work_mem을 그 정렬이 담길 만큼만 올려 디스크 spill을 막습니다 — 단 work_mem은 정렬 노드마다 곱으로 잡히므로 전역으로 크게 올리는 건 위험합니다.
정리하면, 윈도우 함수의 진짜 비용은 함수 자체가 아니라 그 앞의 정렬입니다. EXPLAIN (ANALYZE, BUFFERS)로 Sort가 몇 번인지, 메모리인지 디스크인지 확인하고, 인덱스 정렬 정합과 work_mem으로 다스리는 것이 윈도우 튜닝의 핵심입니다.
상황: 담당자별 순위·지역별 순위·전월 대비 증감을 한 번에 뽑는 실적 리포트가, 데이터가 수백만 행으로 늘면서 갑자기 느려졌습니다(테스트 데이터에선 빨랐습니다). CPU는 여유가 있는데 쿼리가 30초 넘게 걸립니다.
원인: 이 쿼리에는 정렬 기준이 서로 다른 윈도우가 여러 개 있어 데이터를 여러 번 정렬합니다. 게다가 각 정렬 대상이 work_mem 한도를 넘겨 임시 파일로 spill되는 '외부 병합 정렬'이 발생했습니다. 즉 느림의 정체는 윈도우 함수 계산이 아니라, 그 앞에서 반복되는 디스크 정렬이었습니다.
진단: EXPLAIN (ANALYZE, BUFFERS)로 실행 계획을 봅니다. WindowAgg 노드 아래 Sort 노드가 몇 개인지, 각 Sort의 Sort Method가 quicksort Memory인지 external merge Disk: NNNkB인지 확인합니다. Disk가 찍혀 있고 그 정렬 시간이 총 실행 시간의 대부분이면 확정입니다. temp 파일 I/O(BUFFERS의 temp read·written)도 함께 큽니다.
해결: 두 갈래로 접근합니다. (1) 가장 자주 쓰는 윈도우의 PARTITION BY·ORDER BY 순서에 맞춘 복합 인덱스를 만들어 그 정렬을 인덱스 순서로 대체합니다 — Sort 노드가 사라지면 spill도 사라집니다. (2) 정렬을 완전히 없앨 수 없으면 해당 리포트 세션에서만 work_mem을 정렬이 인메모리로 끝날 만큼 올립니다(전역이 아니라 SET LOCAL로 그 트랜잭션에만). 또 화면에 필요 없는 윈도우까지 계산하고 있지 않은지, 정렬 기준을 통일해 정렬 횟수를 줄일 수 있는지 함께 봅니다. 윈도우 리포트 튜닝은 곧 '정렬 다스리기'입니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 윈도우 함수 구문을 실전 조합과 함께 모았습니다. "예" 열의 조합을 그대로 써도 됩니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
OVER (PARTITION BY ... ORDER BY ...) | 윈도우(그룹·순서) 정의 | AVG(price) OVER (PARTITION BY category_id) — 행 유지하며 그룹 평균 |
ROW_NUMBER() | 동점도 고유 번호(페이지네이션) | ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY price DESC) |
RANK() | 동점 동일 순위, 다음 건너뜀(1,2,2,4) | RANK() OVER (ORDER BY sales DESC) — 스포츠 순위표 |
DENSE_RANK() | 동점 동일 순위, 연속(1,2,2,3) | DENSE_RANK() OVER (ORDER BY price DESC) — 등급/티어 |
NTILE(n) | n등분 분위수 번호 | NTILE(4) OVER (ORDER BY price DESC) — 상위 25% 추출 |
LAG(col, offset, default) | 이전 행 값(전월 대비) | LAG(revenue, 1, 0) OVER (ORDER BY month) → revenue - LAG(...) |
LEAD(...) | 다음 행 값 | LEAD(revenue) OVER (ORDER BY month) |
SUM() OVER (ORDER BY ...) | 누적합(Running Total) | SUM(daily_revenue) OVER (ORDER BY order_date) |
ROWS BETWEEN N PRECEDING AND CURRENT ROW | 이동평균 프레임 | AVG(...) OVER (ORDER BY sale_date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) — 7일 이동평균 |
FIRST_VALUE / LAST_VALUE | 윈도우 경계 값 | LAST_VALUE(name) OVER (... ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) |
WITH ranked AS (...) (CTE) | 윈도우 결과를 WHERE로 필터 | 윈도우는 WHERE 직접 참조 불가 → CTE로 감싼 뒤 WHERE rn <= 3 |
EXPLAIN (ANALYZE, BUFFERS) | Sort 비용·디스크 spill 진단 | Sort Method: external merge Disk면 복합 인덱스/work_mem 조정 |
관련 모듈로 더 깊이:
- GROUP BY와 집계함수의 효율적인 인덱스 활용 — GROUP BY 집계와 윈도우 함수의 차이와 보완 관계
- 서브쿼리와 CTE(WITH 문)를 활용한 쿼리 구조화 — 윈도우 쿼리를 단계별 CTE로 가독성 있게 구성하는 법
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — PARTITION BY/ORDER BY가 만드는 정렬 비용을 튜닝하는 법
다음 모듈에서는 대량 데이터를 고성능으로 처리하는 Bulk Insert·Update·Delete 패턴과 데드락 방지 전략을 다룹니다.