API 응답 하나를 만들기 위해 여러 테이블의 데이터를 합쳐야 하는 일이 많습니다. JOIN을 대충 쓰면 중복 행이 폭발하거나 필요한 데이터가 빠집니다. INNER, LEFT, 다대다 JOIN의 차이를 이해해야 정확한 조회 쿼리를 만들 수 있습니다.
JOIN은 관계형 데이터베이스의 핵심 기능입니다. 각 JOIN 타입이 어떤 행을 포함하고 제외하는지 명확히 이해하면 복잡한 데이터 요구사항도 자신 있게 처리할 수 있습니다.
- 1INNER, LEFT, RIGHT, FULL OUTER JOIN의 차이를 구분하고 상황에 맞게 선택할 수 있다
- 2벤다이어그램으로 각 JOIN이 포함하는 행을 시각화하여 설명할 수 있다
- 3SELF JOIN으로 계층 구조 데이터를 조회할 수 있다
- 4JOIN 성능과 인덱스의 관계를 이해하고 느린 JOIN을 개선할 수 있다
JOIN 완전 정복 — INNER, LEFT, RIGHT, FULL, SELF
단일 테이블 조회에서 벗어나 실제 비즈니스 데이터를 다루려면 JOIN이 필수입니다. 주문과 고객 정보를 함께 보거나, 상품과 카테고리를 연결하는 것 모두 JOIN 없이는 불가능합니다. 이 모듈에서는 JOIN의 모든 종류를 벤다이어그램으로 시각화하고 실제 SQL로 익힙니다.
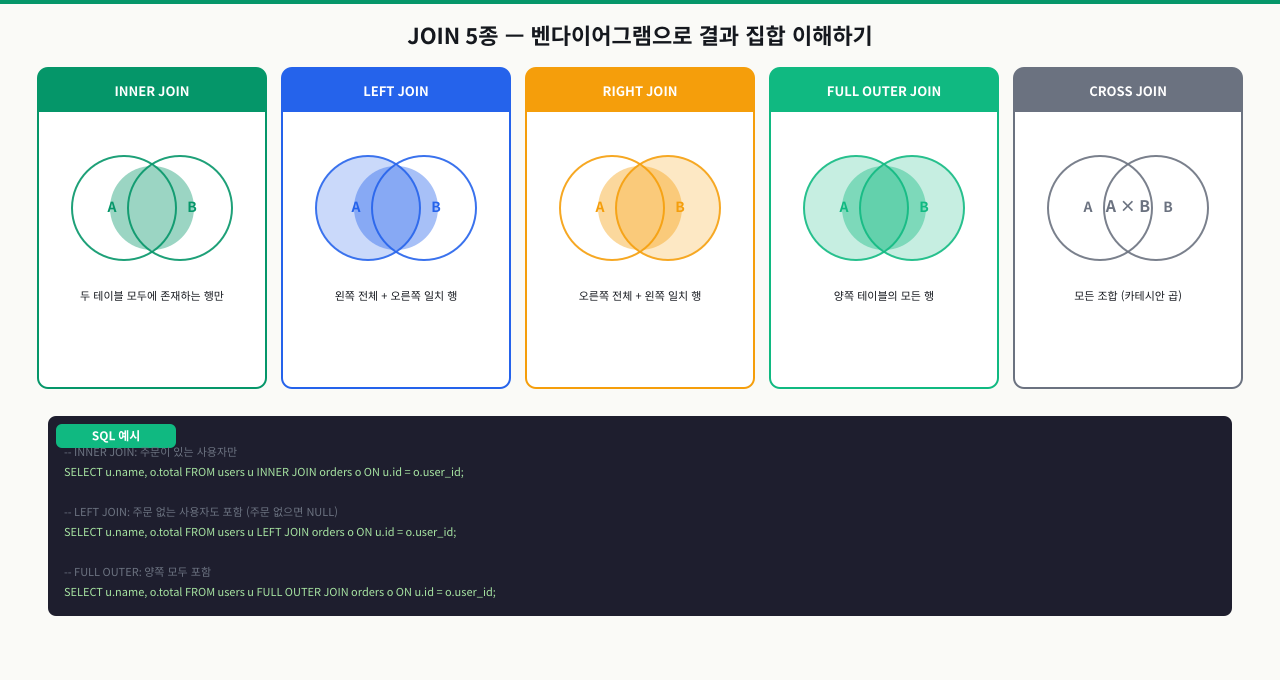
JOIN 5종 — 벤다이어그램으로 이해하기
주문이 있는 사용자만 조회해야 합니다. INNER JOIN을 썼더니 주문이 없는 신규 회원이 목록에서 사라집니다. LEFT JOIN으로 바꿨더니 주문이 없는 사용자도 나오는데 주문 정보 컬럼이 NULL입니다. JOIN 타입마다 어떤 데이터가 포함되고 빠지는지 벤다이어그램으로 이해해야 원하는 결과를 정확하게 뽑을 수 있습니다.
 확대
확대
예시 데이터 준비
JOIN을 설명하기 위한 간단한 예시 데이터입니다. customers(고객)와 orders(주문) 두 테이블을 사용합니다. 주문이 없는 고객(박민준, 최지은)과 고객 테이블에 존재하지 않는 customer_id=5의 주문을 의도적으로 포함시켜, 각 JOIN 타입이 이 불일치를 어떻게 처리하는지 확인합니다.
customers와 orders 테이블을 만들고 의도적으로 불일치 데이터를 포함시킵니다. 각 JOIN 타입이 이 불일치를 어떻게 처리하는지 다음 단계에서 확인합니다.
CREATE TABLE customers (
id INT PRIMARY KEY,
name VARCHAR(50)
);
INSERT INTO customers VALUES
(1, '김철수'), (2, '이영희'), (3, '박민준'), (4, '최지은');
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
amount INT
);
INSERT INTO orders VALUES
(101, 1, 50000),
(102, 1, 30000),
(103, 2, 75000),
(104, 5, 20000);
실행 완료 또는 조회 결과가 표시됩니다.
CREATE TABLE customers (id INT PRIMARY KEY, name VARCHAR(50));- 먼저 결과 행 수를 예상 행 수와 비교합니다. customers 4행 × orders 4행 = 16이 아닌, 테이블 삽입 후 총 5행이 나와야 정상입니다 — 갑자기 수십 배가 되면 ON 절 누락을 의심하세요.
- NULL 위치를 확인합니다. LEFT JOIN에서 오른쪽 컬럼만 NULL이면 정상입니다. 왼쪽 컬럼도 NULL이라면 ON 조건이 반전된 것입니다.
- A와 B가 조합되면 조인 타입을 진단합니다: LEFT JOIN 결과 행 수가 INNER JOIN과 같다면 → 오른쪽 테이블에 누락 없이 100% 매칭됐거나 WHERE에서 NULL 행이 필터됐다는 의미입니다.
JOIN 타입 한눈에 비교
어떤 JOIN을 써야 할지 막막할 때는 "왼쪽 테이블의 행을 전부 보고 싶은가, 아니면 양쪽이 일치하는 것만 보고 싶은가"를 먼저 판단합니다. 이 질문에 답하면 아래 표에서 선택이 명확해집니다.
| JOIN 종류 | 포함되는 행 | 대표 용도 |
|---|---|---|
| INNER JOIN | 양쪽 모두 매칭되는 행만 | 주문이 있는 고객만 조회 |
| LEFT JOIN | 왼쪽 전체 + 오른쪽 매칭 (없으면 NULL) | 주문 없는 고객도 포함 |
| RIGHT JOIN | 오른쪽 전체 + 왼쪽 매칭 (없으면 NULL) | LEFT JOIN과 방향만 반대 |
| FULL OUTER JOIN | 양쪽 모두 전체 (합집합) | 불일치 데이터 전수 감사 |
| CROSS JOIN | 양쪽 행의 모든 조합 (카테시안 곱) | 조합표 생성 |
INNER JOIN — 교집합
INNER JOIN은 두 테이블 모두에 매칭되는 행만 반환합니다. 위 예시 데이터에서 customer_id=5인 주문(104번)은 customers에 존재하지 않으므로 제외됩니다. 주문이 없는 박민준, 최지은도 orders에 매칭 행이 없으므로 제외됩니다.
INNER JOIN을 실행하고, 주문이 없는 고객(박민준, 최지은)과 customer_id=5 주문이 결과에서 제외되는지 확인합니다.
SELECT c.name, o.id AS order_id, o.amount
FROM customers c
INNER JOIN orders o ON c.id = o.customer_id;
SELECT c.name, o.id AS order_id, o.amount FROM customers c INNER JOIN orders o ON c.id = o.customer_id;- 결과 행 수가 3행인지 먼저 확인합니다. 4행 이상이면 ON 절 조건이 잘못됐거나 1:N 관계를 놓친 것입니다.
- 박민준·최지은이 결과에 없는지 확인합니다. INNER JOIN에서 매칭 없는 왼쪽 행은 제외됩니다 — 이것이 LEFT JOIN과의 핵심 차이입니다.
- customer_id=5 주문(104번)도 결과에 없는지 확인합니다. 결과에 없는 행이 의도한 것인지, 데이터 누락인지를 먼저 판단 기준으로 삼으세요.
결과: 김철수(101, 50000), 김철수(102, 30000), 이영희(103, 75000) — 총 3행.
중복 행이 왜 생기는가 — 카디널리티 이해
위 결과에서 김철수가 두 번 나타납니다. 이것은 버그가 아니라 JOIN의 정상 동작입니다. 한 고객이 여러 주문을 가지면 1:N 관계에서 고객 행이 주문 수만큼 복제됩니다.
| 관계 유형 | 결과 행 수 | 주의점 |
|---|---|---|
| 1:1 | 양쪽 중 작은 쪽과 같음 | 중복 없음 |
| 1:N | N 쪽(많은 쪽)의 행 수 | 1쪽 행이 복제됨 |
| N:M | 교차 테이블 없이 JOIN 시 폭발적 증가 | 반드시 중간 테이블 사용 |
집계 쿼리를 작성할 때 중복 행을 인식하지 못하면 SUM()이나 COUNT()가 실제보다 과다 계산됩니다. JOIN 후 집계가 예상과 다르면 먼저 중복 행 여부를 확인하세요.
LEFT JOIN — 왼쪽 테이블 전체 보존
LEFT JOIN은 왼쪽 테이블(FROM 뒤)의 모든 행을 유지합니다. 오른쪽 테이블에 매칭되는 행이 없으면 오른쪽 컬럼 전체가 NULL로 채워집니다. "주문 없는 고객도 목록에 포함하고 싶다"는 요구사항이 LEFT JOIN의 전형적인 사용 사례입니다.
LEFT JOIN으로 주문이 없는 고객(박민준, 최지은)도 결과에 포함시킵니다. NULL 행만 골라 "미구매 고객" 목록도 추출해봅니다.
SELECT c.name, o.id AS order_id, o.amount
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id;
-- 한 번도 주문하지 않은 고객만 추출
SELECT c.name
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.id IS NULL;
SELECT c.name, o.id AS order_id, o.amount FROM customers c LEFT JOIN orders o ON c.id = o.customer_id;- 결과 총 행 수가 5행인지 확인합니다. INNER JOIN의 3행 + NULL 행 2행 = 5행이 기준입니다. INNER JOIN 결과(3행)보다 많을수록 LEFT JOIN이 왼쪽 행을 더 보존하고 있다는 의미입니다.
- 박민준·최지은의 order_id와 amount가 NULL인지 확인합니다. NULL이 아닌 다른 값이면 ON 조건이 예상과 다른 행을 매칭하고 있는 것입니다.
- WHERE o.id IS NULL 쿼리 결과가 정확히 2행인지 확인합니다. 2행 미만이면 NULL 행이 중간 어딘가에서 필터됐을 가능성이 있습니다.
결과: 김철수(101, 50000), 김철수(102, 30000), 이영희(103, 75000), 박민준(NULL, NULL), 최지은(NULL, NULL) — 총 5행. 박민준과 최지은은 order_id와 amount가 NULL입니다.
RIGHT JOIN — 오른쪽 테이블 전체 보존
RIGHT JOIN은 LEFT JOIN과 방향만 반대입니다. 실무에서는 테이블 순서를 바꾸고 LEFT JOIN을 사용하는 것이 더 읽기 쉬워 RIGHT JOIN은 거의 사용하지 않습니다. 아래 두 쿼리는 동일한 결과를 반환합니다.
SELECT c.name, o.id FROM customers c RIGHT JOIN orders o ON c.id = o.customer_id;
SELECT c.name, o.id FROM orders o LEFT JOIN customers c ON o.customer_id = c.id;
FULL OUTER JOIN — 합집합
FULL OUTER JOIN은 양쪽 테이블의 모든 행을 반환합니다. 어느 쪽에도 매칭이 없으면 NULL로 채워집니다. 데이터 마이그레이션 후 불일치 감사, 두 시스템의 레코드 대조 등에 유용합니다.
SELECT c.name, o.id AS order_id
FROM customers c
FULL OUTER JOIN orders o ON c.id = o.customer_id;
결과: 매칭된 행 3개 + 주문 없는 고객 2개(order_id=NULL) + 고객 없는 주문 1개(name=NULL) — 총 6행.
CROSS JOIN — 모든 조합 (카테시안 곱)
CROSS JOIN은 ON 조건 없이 두 테이블의 모든 행 조합을 생성합니다. 의류 쇼핑몰에서 사이즈×색상 전체 SKU를 만들거나, 날짜 범위와 지역의 모든 조합을 생성할 때 의도적으로 사용합니다. 실수로 ON 절을 빠뜨린 INNER JOIN도 CROSS JOIN처럼 동작하므로 주의하세요.
SELECT s.size, c.color
FROM sizes s
CROSS JOIN colors c;
ON vs USING
두 테이블에서 조인 컬럼 이름이 동일할 때 USING으로 표현을 간결하게 줄일 수 있습니다.
SELECT * FROM customers c
JOIN orders o ON c.id = o.customer_id;
SELECT * FROM customers c
JOIN orders o USING (customer_id);
LEFT JOIN으로 왼쪽 테이블을 전체 보존했더니 WHERE 절을 추가하자 NULL 행이 사라지는 문제입니다.
-- 의도: 주문 없는 고객도 포함하면서, 최근 주문만 보고 싶다
SELECT c.name, o.id, o.order_date
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.order_date >= '2024-01-01';
이 쿼리는 INNER JOIN과 동일한 결과를 냅니다. 주문이 없는 고객의 경우 o.order_date가 NULL이고, NULL >= '2024-01-01'은 UNKNOWN이므로 WHERE에서 제거됩니다.
해결 방법은 날짜 조건을 WHERE가 아닌 ON 절로 옮기는 것입니다.
SELECT c.name, o.id, o.order_date
FROM customers c
LEFT JOIN orders o
ON c.id = o.customer_id
AND o.order_date >= '2024-01-01';
ON 절에 조건을 두면 날짜 조건이 만족하지 않을 때 오른쪽이 NULL로 채워지며 왼쪽 행은 유지됩니다.
마케팅팀이 "이번 달 전체 고객 목록에 구매 횟수와 금액을 보여달라"고 요청합니다. 이 요구사항의 핵심은 구매 이력이 없는 고객도 0건으로 표시해야 한다는 점입니다. INNER JOIN을 쓰면 구매 이력 있는 고객만 나와 보고서가 불완전해집니다.
SELECT
c.name,
COUNT(o.id) AS 주문횟수,
COALESCE(SUM(o.amount), 0) AS 총구매금액
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
GROUP BY c.id, c.name
ORDER BY 총구매금액 DESC;
COALESCE(SUM(...), 0)은 주문이 0건인 고객의 합계가 NULL이 되는 것을 방지합니다. LEFT JOIN과 COALESCE의 조합은 "있으면 실제 값, 없으면 0" 패턴의 표준입니다.
조인은 물리적으로 어떻게 실행되나 — 세 알고리즘의 단계별 동작
같은 JOIN을 옵티마이저가 실행하는 3가지 방식 — Nested Loop·Hash·Sort-Merge
INNER JOIN은 "무엇을 반환하는가"를 정하지, "어떻게 두 테이블을 맞물리는가"는 정하지 않습니다. 실제 실행은 옵티마이저가 양쪽 행 수와 인덱스를 보고 세 가지 물리 알고리즘 중 하나를 고릅니다. 그래서 SQL은 그대로인데 데이터가 쌓이면 EXPLAIN의 조인 노드가 Nested Loop에서 Hash Join으로 바뀌고, 잘못 고르면 같은 쿼리가 수십 배 느려집니다. 세 방식이 각각 어떤 단계로 도는지 알면 EXPLAIN을 읽고 "이 조인이 왜 느린가"를 짚을 수 있습니다.
SELECT ... FROM A JOIN B ON A.k = B.k
│
① 옵티마이저: A·B의 (추정)행 수 + 조인 키 인덱스 유무로 알고리즘 결정
│
├─▶ [Nested Loop] 바깥 A 한 행마다 안쪽 B에서 매칭 탐색
│ for a in A:
│ for b in lookup(B, a.k): ← B.k 인덱스면 몇 번 만에
│ emit(a, b)
│ 비용 ≈ A행 수 × (B 한 번 탐색)
│
├─▶ [Hash Join] 작은 쪽으로 해시테이블 빌드 → 큰 쪽으로 프로브
│ build: for b in B: ht[hash(b.k)] = b (메모리에)
│ probe: for a in A: ht에서 a.k 매칭 찾기
│ 비용 ≈ A행 수 + B행 수 (인덱스 불필요)
│
└─▶ [Sort-Merge] 양쪽을 조인 키로 정렬 후 지퍼처럼 병합
sort(A by k); sort(B by k)
두 커서를 나란히 전진시키며 같은 키를 매칭
비용 ≈ 정렬 + (A행 수 + B행 수)
각 알고리즘이 언제 유리하고 EXPLAIN에 어떻게 찍히는가:
| 알고리즘 | 단계 요약 | 적합 상황 | 함정 | EXPLAIN 표기 |
|---|---|---|---|---|
| Nested Loop | 바깥 행마다 안쪽을 인덱스로 조회 | 바깥이 작고(좁게 필터됨) 안쪽 조인 키에 인덱스 | 바깥이 커지면 loops가 폭발 → 안쪽 탐색을 바깥 행 수만큼 반복 | Nested Loop + 안쪽 Index Scan |
| Hash Join | 작은 쪽 해시 빌드 → 큰 쪽 프로브 | 대량 대 대량 등가(=) 조인, 인덱스 없어도 됨 | 해시가 work_mem 초과 시 디스크로 흘러(spill) 느려짐 | Hash Join + Hash(빌드) 노드 |
| Sort-Merge | 양쪽 정렬 후 병합 스캔 | 이미 정렬됨 / 범위·정렬을 겸함 | 정렬 비용이 크면 손해 | Merge Join (필요 시 Sort) |
즉 "조인이 느리다"의 절반은 잘못 고른 알고리즘이고, 그 선택은 ①의 행 수 추정에 달려 있습니다. EXPLAIN ANALYZE에서 조인 노드의 종류를 먼저 보고, Nested Loop이면 그 노드의 loops 값과 estimated rows 대 actual rows의 괴리를 확인하세요 — 바깥을 몇 건으로 과소추정해 Nested Loop을 골랐는데 실제로는 수십만 건이면, 안쪽 탐색을 수십만 번 반복하는 재앙이 됩니다. 이때 우선 조치는 ANALYZE로 통계를 갱신해 옵티마이저가 대량 조인에 맞는 Hash Join을 고르게 하는 것입니다.
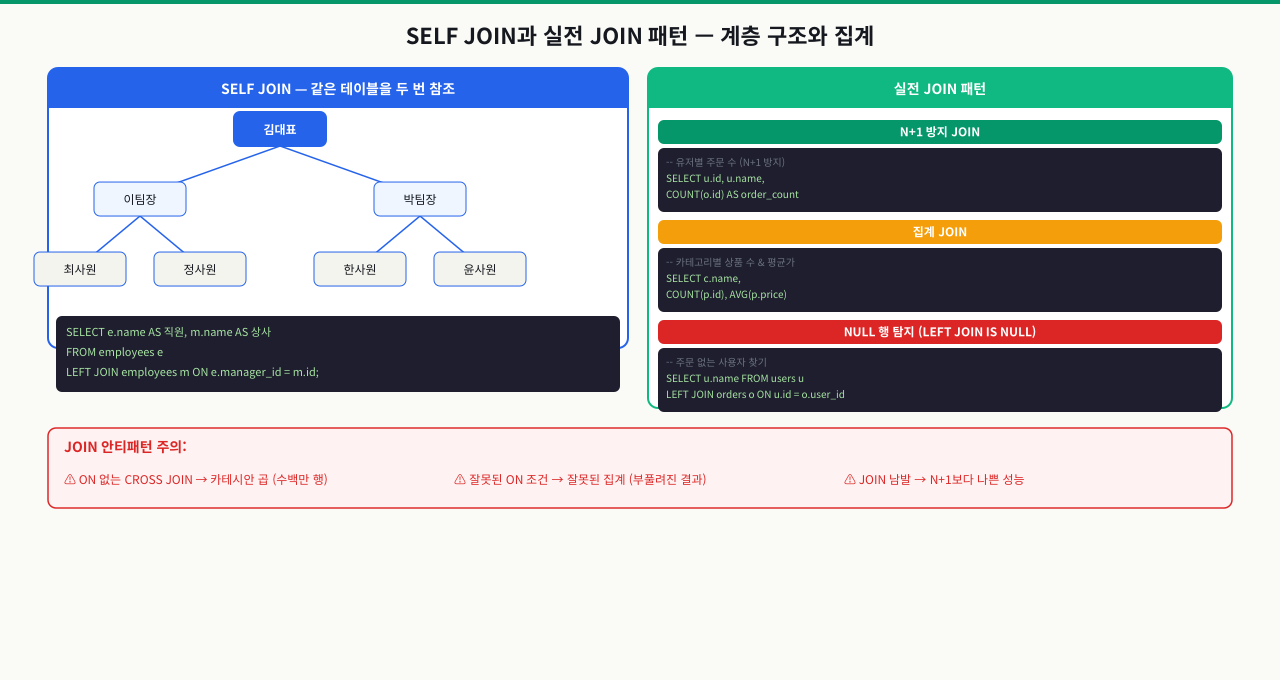
SELF JOIN과 실전 JOIN 패턴 — 계층 구조와 통계
카테고리 테이블에 parent_id 컬럼이 있습니다. 대분류-중분류-소분류 계층을 쿼리로 가져와야 하는데 어떻게 해야 하는지 모릅니다. 같은 테이블을 자기 자신과 JOIN하면 계층 관계를 한 번에 조회할 수 있습니다. 이 패턴을 알면 댓글 트리, 조직도, 카테고리 같은 재귀 구조를 처리하는 쿼리를 작성할 수 있습니다.
 확대
확대
SELF JOIN — 같은 테이블끼리 조인
SELF JOIN은 테이블이 자기 자신을 참조하는 구조에서 사용합니다. 대표적인 예가 직원-관리자 관계입니다. 같은 테이블을 두 번 쓰기 때문에 반드시 서로 다른 별칭을 붙여야 어느 인스턴스를 참조하는지 구분됩니다.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
manager_id INT REFERENCES employees(id)
);
INSERT INTO employees VALUES
(1, '박대표', NULL),
(2, '김팀장', 1),
(3, '이팀장', 1),
(4, '박사원', 2),
(5, '최사원', 2),
(6, '정사원', 3);
SELECT
e.name AS 직원,
m.name AS 관리자
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.id;
결과: 박대표(관리자=NULL), 김팀장/이팀장(관리자=박대표), 박사원/최사원(관리자=김팀장), 정사원(관리자=이팀장).
최상위 직원(박대표)처럼 manager_id가 NULL인 경우도 보존하려면 INNER JOIN이 아닌 LEFT JOIN을 사용해야 합니다.
다중 JOIN 체이닝
실무에서는 3개 이상의 테이블을 JOIN하는 경우가 많습니다. 각 JOIN에 명확한 ON 조건을 붙이고, 불필요한 JOIN은 과감히 제거해야 성능을 지킬 수 있습니다.
SELECT
o.id AS 주문번호,
c.name AS 고객명,
p.name AS 상품명,
oi.quantity AS 수량,
oi.unit_price AS 단가,
oi.quantity * oi.unit_price AS 소계
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
WHERE o.created_at >= NOW() - INTERVAL '30 days'
ORDER BY o.id, p.name;
집계와 JOIN 결합
JOIN과 GROUP BY를 결합해 통계 쿼리를 작성합니다. LEFT JOIN을 사용하면 주문 건수가 0인 고객도 결과에 포함됩니다.
SELECT
c.name,
COUNT(o.id) AS 주문횟수,
COALESCE(SUM(o.amount), 0) AS 총구매금액
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
GROUP BY c.id, c.name
ORDER BY 총구매금액 DESC;
JOIN 성능과 인덱스
JOIN 성능의 첫 번째 점검 항목은 항상 인덱스입니다. 외래키(FK) 컬럼에 인덱스가 없으면 매칭을 위해 테이블 전체를 스캔하게 됩니다(O(N×M)). 인덱스가 있으면 Index Scan으로 O(log N)에 처리됩니다.
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
EXPLAIN ANALYZE
SELECT c.name, o.amount
FROM customers c
JOIN orders o ON c.id = o.customer_id
WHERE c.id = 1;
불필요한 JOIN은 쿼리를 느리게 만듭니다. 실제로 SELECT에서 사용하지 않는 테이블이 JOIN에 포함되어 있다면 제거하세요.
SELECT c.name, COUNT(*)
FROM orders o
JOIN customers c ON o.customer_id = c.id
GROUP BY c.name;
심화 — JOIN은 어떻게 '실행'되는가: Nested Loop·Hash·Merge
심화: 같은 JOIN도 알고리즘에 따라 100배 갈린다
지금까지는 JOIN이 무엇을 반환하는지(INNER·LEFT 등)를 다뤘습니다. 성능을 이해하려면 어떻게 조인되는지를 봐야 합니다. 옵티마이저는 상황에 따라 세 가지 물리 알고리즘 중 하나를 고릅니다.
- Nested Loop Join: 바깥 테이블 한 행마다 안쪽 테이블에서 매칭을 찾습니다. 안쪽에 인덱스가 있고 바깥이 작으면 최고입니다 — WHERE로 좁혀 몇 건만 조인할 때 그렇습니다. 하지만 바깥이 커지면 안쪽 탐색 곱하기 바깥 행 수라 비용이 급격히 폭발합니다.
- Hash Join: 한쪽(작은 쪽)으로 메모리에 해시 테이블을 만들고, 다른 쪽을 훑으며 해시로 매칭합니다. 인덱스가 없어도 대량 대 대량 조인을 효율적으로 처리하는 큰 조인의 기본기입니다. 대신 해시 테이블이 work_mem을 넘으면 디스크로 흘러(spill) 느려집니다.
- Merge Join: 양쪽을 조인 키로 정렬한 뒤 지퍼처럼 맞물려 병합합니다. 이미 정렬돼 있거나 정렬 비용이 쌀 때, 특히 범위·정렬을 겸할 때 유리합니다.
- 선택은 옵티마이저가 행 수 추정으로 합니다: 그래서 통계가 틀리면 알고리즘 선택도 틀립니다. 바깥 행 수를 몇 건으로 과소추정하면 Nested Loop을 골랐다가 실제로는 수십만 건이라 재앙이 됩니다(쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화). 조인이 느리다의 절반은 잘못 고른 조인 알고리즘입니다.
핵심은, 인덱스만이 아니라 어떤 조인 알고리즘이 선택됐는가가 성능을 가른다는 점입니다. EXPLAIN에서 조인 노드의 종류와 loops·행 수를 읽는 습관이 큰 조인을 살립니다.
상황: 최근 N일 주문과 사용자·상품을 조인하는 집계 쿼리가 데이터가 쌓이면서 갑자기 수십 초로 늘어났습니다. 인덱스는 다 있는데도 그렇습니다.
원인: 옵티마이저가 바깥 입력(기간 조건을 통과한 주문)의 행 수를 실제보다 훨씬 적게 추정해 Nested Loop을 선택했습니다. 바깥이 몇 건뿐이니 안쪽을 그만큼만 조회하면 된다는 계산이었지만, 실제로는 바깥이 수십만 건이라 안쪽 인덱스 탐색을 수십만 번 반복하게 됐습니다. 대량 대 대량에는 Hash Join이 맞는데 잘못된 추정이 Nested Loop을 부른 것입니다.
진단: EXPLAIN ANALYZE에서 조인 노드가 Nested Loop인지 보고, 그 노드의 loops 값과 estimated rows 대 actual rows의 괴리를 확인합니다. 추정과 실제가 크게 벌어져 있으면 통계 문제로 인한 알고리즘 오선택입니다. Hash Join 노드가 나온 경우엔 Batches가 1보다 큰지 봐 work_mem spill 여부도 함께 점검합니다.
해결: 먼저 관련 테이블에 ANALYZE로 통계를 갱신해 옵티마이저가 올바른 행 수로 Hash Join을 고르게 유도합니다. 대량 조인이 반복된다면 조인·필터 컬럼 통계나 인덱스를 보강하고, Hash Join이 디스크로 흘렀다면 세션 work_mem을 조정합니다. 조인 자체를 줄이도록 필요한 컬럼만 남기고 불필요한 테이블을 빼는 것도 함께 검토합니다(DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기).
명령어·구문 빠른 참조
이 모듈에서 다룬 JOIN 구문과 성능 관련 명령을 실전 예와 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
INNER JOIN ... ON | 양쪽 매칭되는 행만(교집합) | FROM customers c INNER JOIN orders o ON c.id = o.customer_id |
LEFT JOIN ... ON | 왼쪽 전체 보존, 없으면 NULL | 주문 없는 고객도 목록에 포함 |
RIGHT JOIN / FULL OUTER JOIN | 오른쪽 전체 / 양쪽 전체(합집합) | FULL은 마이그레이션 불일치 감사에 유용 |
CROSS JOIN | 모든 행 조합(카테시안 곱) | FROM sizes s CROSS JOIN colors c (SKU 조합표) |
| SELF JOIN(별칭 2개) | 같은 테이블로 계층 관계 조회 | FROM employees e LEFT JOIN employees m ON e.manager_id = m.id |
USING (컬럼) | 조인 컬럼명이 같을 때 ON 간결화 | JOIN orders o USING (customer_id) — 컬럼 1번만 출력 |
필터를 ON에 두기 | LEFT JOIN에서 NULL 행 보존 | LEFT JOIN orders o ON c.id = o.customer_id AND o.order_date >= '2024-01-01' |
WHERE 오른쪽.id IS NULL | 안티 조인 — 매칭 없는 행만 추출 | 한 번도 주문 안 한 고객 뽑기 |
COALESCE(SUM(...), 0) + GROUP BY | LEFT JOIN 집계에서 NULL을 0으로 | COALESCE(SUM(o.amount), 0) 총구매금액 |
| 다중 JOIN 체이닝 | 3개 이상 테이블 결합 | orders → customers → order_items → products 순 JOIN |
| FK 컬럼 인덱스 | JOIN을 O(log N)으로 가속 | CREATE INDEX idx_orders_customer_id ON orders(customer_id); |
EXPLAIN ANALYZE | 조인 알고리즘·loops 확인 | Nested Loop / Hash / Merge 판별 |
관련 모듈로 더 깊이:
- PK, FK 제약조건과 Cascade 설정이 주는 영향 — JOIN의 조건이 되는 PK/FK 관계를 설계하는 법
- B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건 — FK 컬럼 인덱스로 JOIN 성능을 O(log N)으로 끌어올리는 원리
- 서브쿼리와 CTE(WITH 문)를 활용한 쿼리 구조화 — JOIN으로 풀기 어려운 복잡한 쿼리를 분리하는 대안
다음 모듈에서는 서브쿼리와 CTE(WITH 문)를 활용해 복잡한 쿼리를 읽기 쉬운 구조로 분리하는 방법을 다룹니다.