WHERE 조건을 붙였는데도 테이블 전체를 읽는 쿼리는 실무에서 자주 만납니다. 인덱스는 단순히 “빠르게 해주는 옵션”이 아니라 DB가 데이터를 찾는 경로입니다. 기본 원리를 알면 어떤 쿼리에 인덱스가 필요한지 스스로 판단할 수 있습니다.
인덱스는 조회를 빠르게 하지만 쓰기 성능을 낮추고 디스크를 사용합니다. 올바른 컬럼에 올바른 순서로 인덱스를 만드는 것이 쿼리 최적화의 출발점입니다.
- 1인덱스가 없을 때 Full Table Scan이 왜 느린지 설명할 수 있다
- 2B-Tree의 루트, 브랜치, 리프 노드 구조를 이해하고 검색이 빨라지는 원리를 설명할 수 있다
- 3Cardinality를 기준으로 인덱스가 효과적인 컬럼을 판단할 수 있다
- 4CREATE INDEX 문법으로 인덱스를 만들고 생성 여부를 확인할 수 있다
- 5복합 인덱스에서 컬럼 순서를 올바르게 설계할 수 있다
- 6인덱스를 만들지 말아야 할 상황을 구분하고 판단할 수 있다
인덱스 기초 — B-Tree 원리와 쿼리 속도
1억 개의 사용자 레코드에서 특정 이메일을 찾아야 한다면 어떻게 해야 할까요? 인덱스 없이는 1억 개를 전부 읽어야 하지만(Full Table Scan), B-Tree 인덱스가 있으면 약 27번의 비교만으로 찾을 수 있습니다. 인덱스는 데이터베이스 성능의 핵심입니다.
B-Tree 인덱스 — 왜 쿼리가 로그 시간으로 빨라지는가
사용자가 100만 명인 테이블에서 WHERE email = 'user@example.com'을 실행했더니 5초가 걸립니다. 인덱스를 걸었더니 즉시 반환됩니다. 왜 이렇게 빠른지 이해하지 못하면 인덱스를 아무 컬럼에나 걸거나, 반대로 필요한 곳에 안 걸어서 슬로우 쿼리가 반복됩니다.
 확대
확대
Full Table Scan vs 인덱스 검색
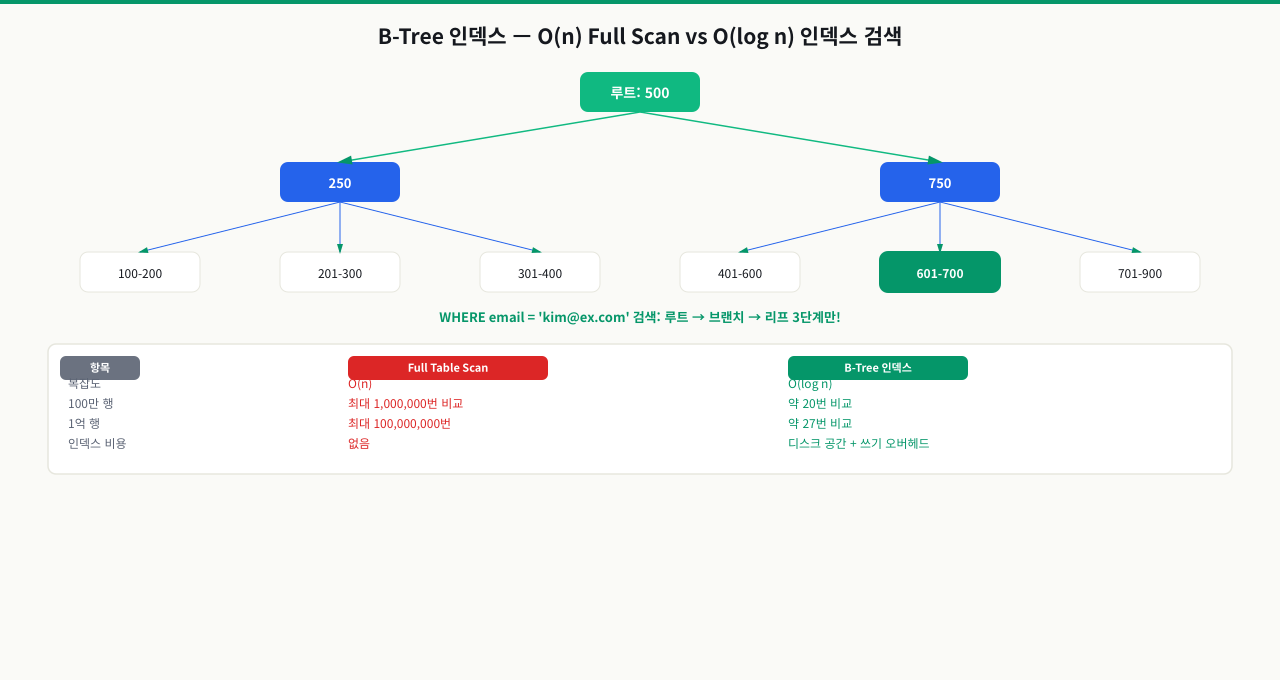
인덱스가 없는 테이블에서 특정 이메일을 검색하면 DB는 첫 번째 행부터 마지막 행까지 모든 행을 순서대로 비교합니다. 1억 행이 있으면 최악의 경우 1억 번 비교가 필요합니다. 이것이 Full Table Scan이고 시간 복잡도는 O(n)입니다.
B-Tree 인덱스가 있으면 루트 노드에서 시작해 각 단계마다 탐색 범위가 절반씩 줄어듭니다. 1억 행에서도 약 27번(log₂(1억) ≈ 27)의 비교만으로 원하는 행을 찾을 수 있습니다. 시간 복잡도는 O(log n)입니다.
| 방식 | 시간 복잡도 | 1억 행 검색 시 비교 횟수 |
|---|---|---|
| Full Table Scan | O(n) | 최대 1억 번 |
| B-Tree 인덱스 | O(log n) | 약 27번 |
| Hash 인덱스 | O(1) | 1번 (등호 검색 전용) |
B-Tree 구조 상세
B-Tree 인덱스는 루트 노드, 브랜치 노드, 리프 노드의 세 계층으로 구성됩니다. users.email 컬럼에 인덱스를 만들면 아래와 같은 트리가 내부적으로 생성됩니다.
[루트 노드]
[M | T]
/ | \
/ | \
[Branch] [Branch] [Branch]
[D | H] [N | R] [V | Z]
/ | \ ... ...
/ | \
[Leaf][Leaf][Leaf]
[A,B] [C,D] [E,F,G,H]
↓ ↓ ↓
실제 행 포인터 (heap page, offset)
각 노드의 역할은 다음과 같습니다. 루트 노드는 탐색의 시작점으로 전체 값 범위를 크게 나눕니다. 브랜치 노드는 중간 경로로 값 범위에 따라 탐색 방향을 결정합니다. 리프 노드는 실제 인덱스 키값과 해당 행의 물리적 위치(heap pointer)를 저장합니다. 리프 노드들은 서로 링크드 리스트로 연결되어 있어 BETWEEN, 부등호 같은 범위 검색에서 연속된 결과를 효율적으로 읽을 수 있습니다.
Cardinality — 인덱스 효과의 핵심 지표
Cardinality는 컬럼의 고유값 수를 의미합니다. 높을수록 인덱스 효과가 큽니다.
| 컬럼 | 고유값 수 | Cardinality | 인덱스 적합성 |
|---|---|---|---|
| users.email | ~전체 행 | 매우 높음 | 최적 |
| orders.id | 전체 행 | 최고 | (PK 자동 생성) |
| users.country | ~200개 | 보통 | 상황에 따라 |
| orders.status | 5개 | 낮음 | 비효율적 |
| users.is_active | 2개 | 매우 낮음 | Full Scan이 나음 |
is_active=true인 행이 전체의 90%라면, 인덱스를 통해 90%를 읽는 것보다 그냥 테이블 전체를 읽는 Full Scan이 오히려 빠릅니다. DB 옵티마이저가 이를 감지하고 인덱스를 자동으로 무시하기도 합니다.
CREATE INDEX 문법
기본 인덱스, UNIQUE 인덱스, 복합 인덱스, 부분 인덱스를 용도에 맞게 선택합니다. 운영 중인 대용량 테이블에 인덱스를 추가할 때는 CONCURRENTLY 옵션으로 테이블 락 없이 생성합니다. 시간이 더 걸리지만 서비스를 중단하지 않아도 됩니다.
email 컬럼에 인덱스를 생성합니다. 복합 인덱스와 부분 인덱스까지 순서대로 실행해봅니다.
CREATE INDEX idx_users_email ON users (email);
CREATE UNIQUE INDEX idx_users_email_unique ON users (email);
CREATE INDEX idx_orders_user_status ON orders (user_id, status);
CREATE INDEX idx_orders_pending ON orders (created_at)
WHERE status = 'pending';
CREATE INDEX idx_posts_created_desc ON posts (created_at DESC);
CREATE INDEX CONCURRENTLY idx_large_table_col ON large_table (column_name);
실행 완료 또는 조회 결과가 표시됩니다.
CREATE INDEX idx_users_email ON users (email);- 스캔 방식—EXPLAIN에서 Seq Scan인지 Index Scan인지 확인합니다.
- 조건 컬럼—WHERE와 ORDER BY 컬럼이 인덱스 설계와 맞는지 봅니다.
- 쓰기 비용—인덱스 추가 후 INSERT/UPDATE 비용 증가도 함께 고려합니다.
인덱스 확인 방법
psql에서 \d users로 테이블 구조와 인덱스를 함께 확인합니다. pg_stat_user_indexes의 idx_scan이 0인 인덱스는 생성 이후 한 번도 사용되지 않은 것으로, 삭제 대상 후보입니다.
인덱스 생성 전후로 EXPLAIN ANALYZE를 실행해 실행 계획이 Seq Scan에서 Index Scan으로 바뀌는지 확인합니다.
SELECT
indexname,
indexdef
FROM pg_indexes
WHERE tablename = 'users';
SELECT
schemaname,
tablename,
indexname,
idx_scan,
idx_tup_read
FROM pg_stat_user_indexes
WHERE tablename = 'users'
ORDER BY idx_scan DESC;
SHOW INDEX FROM users;
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'test@example.com';
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'test@example.com';- 읽기 순서—EXPLAIN 출력은 id → type → key → rows → Extra 순으로 읽습니다. key=NULL이 보이면 인덱스 미사용 — WHERE 컬럼에 인덱스 추가가 필요합니다.
- key 판단 기준—key=NULL: 인덱스 미사용(Full Scan) → 해당 WHERE 컬럼에 인덱스 필요. key에 인덱스명이 표시되면 인덱스를 사용 중입니다.
- Extra 필드 해석—Using index: 인덱스만으로 완료(최적) / Using where: 인덱스 후 추가 필터링 / Using filesort: 정렬에 임시 메모리 사용(ORDER BY 컬럼을 인덱스에 추가 고려) / Using temporary: 임시 테이블 생성(GROUP BY, DISTINCT 최적화 필요)
- 카디널리티 판단—SHOW INDEX의 Cardinality가 전체 rows의 10% 미만이면 인덱스 효과 낮음. 예: 1,000만 행 테이블에서 Cardinality=5이면 Full Scan이 더 빠를 수 있습니다.
- 조합 해석—type=range + Extra=Using filesort → 인덱스는 쓰지만 정렬이 비효율. 정렬 컬럼(ORDER BY 대상)을 복합 인덱스 마지막에 추가하는 것을 고려합니다.
- idx_scan 확인—pg_stat_user_indexes의 idx_scan 값이 증가하는지 확인합니다. 0이면 해당 인덱스는 한 번도 사용되지 않은 삭제 대상 후보입니다.
EXPLAIN ANALYZE 결과에서 Index Scan using idx_users_email이 보이면 인덱스를 사용 중이고, Seq Scan이 보이면 Full Table Scan 중입니다.
인덱스로 한 행을 찾는 5단계 — 루트에서 리프, 그리고 실제 행까지
WHERE email = ? 한 줄이 인덱스를 타고 한 행에 도달하는 5단계
SELECT * FROM users WHERE email = 'a@b.com' 한 줄. 인덱스가 있으면 1억 행에서도 즉시 한 행이 나옵니다. 그런데 조건을 WHERE lower(email) = 'a@b.com'으로 살짝 바꾸거나 LIKE '%b.com'으로 쓰면, 같은 인덱스가 있는데도 풀스캔으로 되돌아갑니다. 인덱스가 한 행을 찾아 내려가는 과정을 단계로 알면, 어떤 조건이 인덱스를 타고 어떤 조건이 못 타는지를 규칙이 아니라 원리로 판단할 수 있습니다.
WHERE email = 'a@b.com'
│
① 옵티마이저: email 인덱스로 이 조건을 처리할 수 있는지 판단
│ (등호·범위·접두어 LIKE면 가능 / 좌변 변형·앞 %면 불가)
│
② 루트 노드 읽기: 찾는 키를 루트의 구분값과 비교 → 내려갈 브랜치 결정
│
③ 브랜치 하강: 레벨마다 범위 비교로 자식 포인터 하나 선택
│ 매 단계 탐색 범위가 크게 줄어 O(log n) (1억 행 ≈ 3~4레벨 = 3~4번 페이지 읽기)
│
④ 리프 도달: 찾는 키와 정확히 일치하는 항목 확인
│ 리프는 정렬 + 서로 링크 → 범위·정렬 조회는 여기서 옆으로 연속 스캔
│
⑤ 실제 행 접근: 리프에 담긴 포인터로 데이터에 도달
│ clustered(PK 인덱스): 리프에 행 자체가 있음 → 추가 접근 없음
│ secondary(보조 인덱스): 리프엔 PK/heap 위치만 → 테이블 룩업 1회 더
▼
결과 행 반환
각 단계가 하는 일과, 인덱스를 못 타게 되는 지점:
| 단계 | 하는 일 | 인덱스를 못 쓰는 경우 |
|---|---|---|
| ① 조건 판단 | 옵티마이저가 WHERE 조건을 인덱스 키 순서로 훑을 수 있는지 본다 | 좌변에 함수·연산(lower(email), col + 1)을 쓰면 인덱스는 원본값으로 정렬돼 있어 하강 기준이 사라짐 → 풀스캔 |
| ② 루트 | 트리 최상단에서 키 범위를 크게 가른다 | 복합 인덱스 (a, b, c)에서 선두 a 조건이 없으면 루트에서 내려갈 방향을 못 정함 → 선두 컬럼 규칙 |
| ③ 브랜치 하강 | 레벨마다 비교 한 번으로 후보를 크게 좁힌다(O(log n)) | 앞 와일드카드 LIKE '%b.com'은 시작값을 몰라 비교 기준이 없음 → 하강 불가 |
| ④ 리프 도달 | 정렬된 리프에서 일치 키를 찾고, 링크로 옆 항목까지 연속 read | 매칭 리프가 너무 많으면(저 카디널리티) 옵티마이저가 아예 풀스캔을 선택 |
| ⑤ 행 접근 | 리프의 포인터로 실제 행을 읽는다 | secondary 인덱스는 테이블 룩업이 1회 더 붙음 → 대량이면 커버링 인덱스로 이 단계 생략 |
즉 인덱스가 빠른 이유는 ②~③에서 "정렬된 트리를 위에서 아래로 범위 비교하며 내려간다"는 한 가지 원리 때문이고, 인덱스가 안 먹는 대부분의 사고도 같은 원리에서 나옵니다 — 좌변을 변형하거나(①), 선두 컬럼을 빼먹거나(②), 앞부분을 %로 가리면(③) 트리를 내려갈 기준 자체가 사라집니다. EXPLAIN에 Index Scan이 아니라 Seq Scan이 찍혔다면 이 세 지점 중 하나를 먼저 의심하고, secondary 인덱스인데 유독 느리면 ⑤의 테이블 룩업을 커버링 인덱스로 없앨 수 있는지 봅니다.
인덱스 설계 원칙 — 언제 만들고 언제 안 만드는가
인덱스를 많이 걸수록 좋을 것 같아서 모든 컬럼에 인덱스를 걸었습니다. INSERT/UPDATE가 갑자기 느려졌습니다. 인덱스는 읽기를 빠르게 하지만 쓰기를 느리게 합니다. 어느 컬럼에 걸어야 하고 어느 컬럼에 걸면 안 되는지 — 이 판단 기준을 모르면 인덱스가 오히려 독이 됩니다.
 확대
확대
인덱스를 만들어야 하는 컬럼
WHERE 조건에 자주 사용되는 컬럼, JOIN ON 조건 컬럼, ORDER BY 컬럼, Cardinality가 높은 컬럼이 인덱스 대상입니다. 특히 JOIN에서 외래키 컬럼(orders.user_id)에 인덱스가 없으면 조인 시 Full Scan이 발생합니다.
왜 빠른가 — 수치로: 1,000만 건 테이블에서 Full Scan은 최대 10,000,000번 비교지만, B-Tree 인덱스는 log₂(10,000,000) ≈ 23번 비교면 찾습니다. 이 차이가 "수십 초 → 수 밀리초"를 만듭니다.
외래키, 이메일, 날짜, 고유 식별자 컬럼에 상황별 인덱스를 만들어봅니다.
CREATE INDEX idx_orders_user_id ON orders (user_id);
CREATE UNIQUE INDEX idx_users_email ON users (email);
CREATE INDEX idx_posts_created_at ON posts (created_at DESC);
CREATE INDEX idx_products_sku ON products (sku);
CREATE INDEX idx_orders_user_id ON orders (user_id);- 외래키 컬럼(user_id) 인덱스 생성 후 JOIN 쿼리 EXPLAIN에서 Hash Join → Index Scan 변화를 확인합니다.
- UNIQUE 인덱스는 중복 삽입 시 'duplicate key' 오류가 발생하는지 확인합니다.
- 내림차순 인덱스(DESC)는 ORDER BY created_at DESC 정렬 쿼리에서 효과를 봅니다.
Composite Index 컬럼 순서 설계
복합 인덱스의 컬럼 순서는 어떤 WHERE 조건으로 사용할 수 있는지를 결정합니다. 선두 컬럼부터 순서대로만 사용할 수 있습니다. 컬럼 순서 설계 원칙은 등호(=) 조건 컬럼을 앞에, Cardinality가 높은 컬럼을 앞에, 범위 조건(>, <, BETWEEN)은 뒤에, ORDER BY 컬럼은 마지막에 배치합니다.
복합 인덱스를 만들고, 선두 컬럼이 있는 쿼리와 없는 쿼리의 EXPLAIN 결과를 비교합니다.
CREATE INDEX idx_orders_user_status_created
ON orders (user_id, status, created_at DESC);
-- 인덱스 사용됨 (선두 컬럼 user_id 포함)
EXPLAIN SELECT * FROM orders WHERE user_id = 1 AND status = 'pending';
-- 인덱스 미사용 (선두 컬럼 user_id 없음)
EXPLAIN SELECT * FROM orders WHERE status = 'pending';
CREATE INDEX idx_orders_user_status_created ON orders (user_id, status, created_at DESC);- user_id = 1 조건 쿼리에서 'Index Scan using idx_orders_user_status_created'가 보이는지 확인합니다.
- status = 'pending' 만으로 조회 시 Seq Scan이 발생하는지 확인합니다.
- 선두 컬럼이 없는 조건은 인덱스를 사용하지 못한다는 '선두 컬럼 규칙'을 직접 확인합니다.
위 인덱스는 WHERE user_id = 1, WHERE user_id = 1 AND status = 'pending', WHERE user_id = 1 AND status = 'pending' ORDER BY created_at 조건에서 사용됩니다. 반면 WHERE status = 'pending'이나 WHERE created_at > '2024-01-01'처럼 선두 컬럼(user_id)이 없는 조건에서는 사용되지 않습니다.
인덱스를 만들지 말아야 할 상황
인덱스는 조회를 빠르게 하지만 쓰기(INSERT, UPDATE, DELETE)를 느리게 합니다. 데이터 변경마다 인덱스도 함께 갱신해야 하기 때문입니다.
소규모 테이블(1000행 미만)은 Full Scan이 인덱스 조회보다 빠를 수 있습니다. 인덱스를 통해 행 위치를 찾고 다시 힙에 접근하는 오버헤드가 더 크기 때문입니다.
Cardinality가 낮은 컬럼(gender, is_active)은 인덱스 효율이 없습니다. 초당 수만 건 INSERT가 발생하는 로그 테이블이나 사용자 활동마다 갱신되는 last_activity_at 컬럼은 인덱스가 쓰기 성능을 떨어뜨립니다.
인덱스 유지보수
시간이 지나면 인덱스가 단편화됩니다. REINDEX로 인덱스를 재구성할 수 있고, 운영 중에는 CONCURRENTLY 옵션을 사용합니다. 분기별로 idx_scan = 0인 미사용 인덱스를 점검하고 삭제합니다.
인덱스 삭제
안전한 실행 조건: EXPLAIN으로 해당 인덱스를 사용하는 쿼리가 없음을 확인 후 삭제
실행 전 반드시 확인
- pg_stat_user_indexes에서 idx_scan 값이 0인지 확인
- 삭제 대상 인덱스 이름이 정확한지 이중 확인
- 롤백 계획 수립 (DROP 후 CREATE INDEX CONCURRENTLY)
DROP INDEX idx_old_unused_index위 항목을 모두 확인한 후 복사할 수 있습니다
REINDEX INDEX CONCURRENTLY idx_users_email;
REINDEX TABLE users;
DROP INDEX idx_old_unused_index;
SELECT
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size,
indexrelname,
idx_scan AS times_used
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND indexrelname NOT LIKE 'pk_%'
ORDER BY pg_relation_size(indexrelid) DESC;
"인덱스가 검색을 빠르게 한다"는 사실만 알고 중요해 보이는 컬럼마다 인덱스를 추가하다 보면, 테이블에 인덱스가 10개 이상 쌓이기도 합니다. 문제는 INSERT 한 건이 실행될 때마다 모든 인덱스를 동시에 갱신해야 한다는 점입니다. 인덱스가 10개라면 INSERT 한 번에 인덱스 10번 갱신이 발생합니다. 주문, 로그 같은 쓰기가 빈번한 테이블에서는 이것이 병목이 됩니다.
해결책은 EXPLAIN ANALYZE로 실제로 사용되는 인덱스만 남기는 것입니다. pg_stat_user_indexes에서 idx_scan = 0인 인덱스를 찾아 삭제합니다. 인덱스는 테이블당 5-6개 이하를 권장합니다. 새 인덱스를 추가하기 전에 항상 "이 인덱스가 사용하는 쿼리가 얼마나 자주 실행되는가", "삭제 대신 기존 복합 인덱스를 확장할 수 있는가"를 먼저 확인하세요.
WHERE name LIKE '%apple'처럼 앞에 와일드카드가 붙는 패턴은 B-Tree 인덱스를 사용할 수 없습니다. B-Tree는 값의 시작 부분을 기준으로 정렬되어 있기 때문에, 앞부분을 알 수 없으면 트리를 탐색할 기준이 없습니다. LIKE 'apple%'(앞에 와일드카드 없음)는 인덱스를 사용할 수 있지만 LIKE '%apple%'나 LIKE '%apple'은 불가능합니다.
전방 와일드카드 검색이 꼭 필요하다면 Full Text Search(tsvector, tsquery)나 Trigram 인덱스(pg_trgm 확장의 GIN 인덱스)를 사용합니다. CREATE INDEX idx_name_trgm ON products USING gin(name gin_trgm_ops);로 만든 인덱스는 LIKE '%apple%' 패턴에도 동작합니다.
프로덕션에서 APM 도구나 CloudWatch에서 특정 API의 응답 시간이 2초 이상으로 치솟는 알림이 왔습니다. 먼저 psql로 프로덕션 읽기 전용 계정에 접속해 pg_stat_activity로 현재 실행 중인 쿼리를 확인합니다. 문제 쿼리를 식별했으면 EXPLAIN ANALYZE를 실행해 실행 계획을 확인합니다.
Seq Scan on orders (cost=0.00..45231.00 rows=982340 width=...) 같은 출력이 보이면 Full Table Scan이 원인입니다. WHERE 조건 컬럼에 인덱스가 없거나 복합 인덱스의 컬럼 순서가 맞지 않는 경우입니다. CREATE INDEX CONCURRENTLY idx_orders_user_created ON orders (user_id, created_at DESC);로 인덱스를 추가한 뒤 다시 EXPLAIN ANALYZE를 실행해 Index Scan으로 바뀌었는지 확인합니다. 적용 전후 실행 시간을 비교해 개선량을 측정하고 변경 이력에 기록합니다.
심화 — 인덱스도 늙는다: B-Tree가 부풀어 느려질 때
심화: 잘 만든 인덱스가 시간이 지나 느려지는 이유 — 페이지 분할과 인덱스 bloat
지금까지는 올바른 컬럼에 인덱스를 만들면 빠르다를 다뤘습니다. 한 단계 더 들어가면, 같은 인덱스가 몇 달 뒤 느려지는 현상을 만납니다. 인덱스는 정적인 정렬표가 아니라 쓰기가 계속 흔드는 살아 있는 B-Tree이기 때문입니다.
- 무작위 삽입은 페이지를 쪼갭니다: B-Tree 리프는 정렬 순서를 유지해야 합니다. UUID처럼 무작위 키가 중간에 끼어들면 꽉 찬 리프 페이지를 둘로 나누는 page split이 일어납니다. 분할이 잦으면 페이지들이 절반만 찬 채 흩어져, 같은 데이터를 담는 데 더 많은 페이지·더 많은 I/O가 듭니다.
- MVCC는 인덱스에도 죽은 항목을 남깁니다: 행을 UPDATE·DELETE하면 인덱스에도 옛 버전을 가리키던 항목이 죽은 채 남습니다. VACUUM이 정리하지만 갱신이 폭주하면 회수가 못 따라가 dead 항목이 쌓입니다. 그 결과 인덱스가 데이터에 비해 비정상적으로 커집니다(index bloat).
- 부푼 인덱스는 Index Scan이어도 느립니다: EXPLAIN에는 여전히 Index Scan이 찍히니 인덱스는 타는데 왜 느리지로 헷갈립니다. 진짜 원인은 인덱스가 캐시에 다 안 올라오고 더 많은 페이지를 훑어야 한다는 것입니다 — 논리는 옳은데 물리가 무너진 상태입니다.
- 정리는 REINDEX, 예방은 설계입니다: REINDEX INDEX CONCURRENTLY로 인덱스를 다시 조밀하게 재구축하면 크기와 속도가 회복됩니다. 예방은 가능하면 단조 증가 키(BIGSERIAL 등)를 PK로 써 append-only에 가깝게 만들고, 갱신이 잦은 테이블은 fillfactor를 낮춰 페이지에 갱신 여유를 두는 것입니다.
핵심은, 인덱스 성능은 만들 때가 아니라 운영하는 내내 관리하는 대상이라는 점입니다. 크기 추이를 관측하지 않으면 느려짐이 인덱스 노화 때문임을 놓치기 쉽습니다(쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화).
상황: 상태를 자주 바꾸는 orders 테이블의 인덱스로 조회하는 API가 시간이 갈수록 느려집니다. 인덱스는 분명히 살아 있고 EXPLAIN에도 Index Scan이 찍히는데 응답만 계속 나빠집니다.
원인: 잦은 UPDATE로 인덱스에 죽은 항목이 쌓이고 무작위 갱신으로 페이지 분할이 누적돼 인덱스가 실제 데이터에 비해 크게 부풀었습니다(index bloat). 스캔 자체는 인덱스를 타지만 절반만 찬 페이지가 흩어져 있어 훨씬 많은 페이지를 읽어야 하고, 인덱스가 버퍼 캐시에 다 올라오지 못해 디스크 I/O가 늘었습니다.
진단: pg_relation_size로 그 인덱스의 물리 크기를 데이터 규모·행 수와 비교합니다. 행 수 증가에 비해 인덱스가 과도하게 크면 bloat 신호입니다. pgstattuple 확장이 있으면 leaf 적재율이 낮은지 직접 확인합니다. idx_scan은 높은데 성능만 나쁜 조합이 전형적입니다.
해결: REINDEX INDEX CONCURRENTLY로 인덱스를 재구축해 크기와 속도를 회복시킵니다. 재발 방지로 갱신이 잦은 테이블은 fillfactor를 낮춰 페이지 여유를 두고, 무작위 UUID를 PK로 쓰고 있었다면 단조 증가 키로의 전환을 검토합니다. 인덱스 크기 추이를 정기 점검 지표에 넣어 노화를 조기에 잡습니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 인덱스 생성·확인·유지보수 구문을 실전 예와 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
CREATE INDEX | 기본 B-Tree 인덱스 생성 | CREATE INDEX idx_users_email ON users (email); |
CREATE UNIQUE INDEX | 중복 방지 + 조회 가속 동시 확보 | CREATE UNIQUE INDEX idx_users_email ON users (email); |
복합 인덱스 (a, b, c) | 선두 컬럼 규칙 — 앞 컬럼부터 사용 | CREATE INDEX ... ON orders (user_id, status, created_at DESC); |
부분 인덱스 ... WHERE | 특정 조건 행만 인덱싱 | CREATE INDEX ... ON orders (created_at) WHERE status = 'pending'; |
... (col DESC) | 내림차순 정렬 쿼리 가속 | CREATE INDEX ... ON posts (created_at DESC); |
CREATE INDEX CONCURRENTLY | 운영 중 테이블 락 없이 생성 | 대용량 테이블 무중단 인덱스 추가 |
USING gin(... gin_trgm_ops) | 전방 와일드카드(%키워드) 검색용 | CREATE INDEX idx_name_trgm ON products USING gin(name gin_trgm_ops); |
EXPLAIN ANALYZE | Seq Scan → Index Scan 전환 확인 | EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'a@b.c'; |
\d 테이블 / pg_indexes | 테이블의 인덱스 목록·정의 확인 | SELECT indexname, indexdef FROM pg_indexes WHERE tablename = 'users'; |
pg_stat_user_indexes(idx_scan) | 미사용 인덱스(삭제 후보) 탐지 | ... WHERE idx_scan = 0 |
REINDEX INDEX CONCURRENTLY | bloat 인덱스 온라인 재구축 | REINDEX INDEX CONCURRENTLY idx_users_email; |
DROP INDEX | 미사용 인덱스 제거 | DROP INDEX idx_old_unused_index; |
fillfactor | 갱신 잦은 테이블 페이지 여유 확보 | 페이지 분할·index bloat 예방 |
관련 모듈로 더 깊이:
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — 인덱스를 무기로 슬로우 쿼리를 실제로 개선하는 전체 루틴
- 쿼리 실행 계획(Execution Plan) 읽는 법과 인덱스 최적화 —
Seq ScanvsIndex Scan을 EXPLAIN 출력에서 판별하는 법 - N+1 문제, SELECT *, 인덱스 무력화 안티패턴 방지 —
LIKE '%키워드'처럼 인덱스를 못 타게 만드는 패턴 회피
다음 모듈에서는 3-Tier, MSA, CQRS 아키텍처에서 데이터베이스가 담당하는 역할 분담 패턴을 다룹니다.