백엔드 장애를 보면 코드보다 DB 경계가 흐릿해서 생기는 문제가 많습니다. 어떤 데이터는 트랜잭션이 필요하고, 어떤 데이터는 캐시나 검색엔진으로 분리해야 합니다. 아키텍처 안에서 DB의 역할을 이해해야 무리한 설계를 피할 수 있습니다.
아키텍처 패턴마다 DB를 다루는 방식이 다릅니다. 전통적인 3-Tier부터 현대적인 MSA와 CQRS까지, 각 패턴에서 DB의 역할을 이해하면 더 나은 설계 결정을 내릴 수 있습니다.
- 13-Tier 아키텍처에서 DB 계층의 역할과 위치를 설명할 수 있다
- 2MSA의 DB-per-Service 패턴과 공유 DB의 문제점을 비교해 판단할 수 있다
- 3CQRS 패턴으로 읽기와 쓰기를 분리하는 설계를 적용할 수 있다
- 4채용공고가 요구하는 DB 아키텍처 역량을 파악하고 자신의 학습에 연결할 수 있다
아키텍처에서의 DB 역할 — 3-Tier, MSA, CQRS 패턴
소프트웨어를 구축할 때 데이터베이스는 단순히 데이터를 저장하는 창고가 아닙니다. 어떤 아키텍처 패턴을 선택하느냐에 따라 DB가 놓이는 위치, 접근 방식, 그리고 서비스 간 관계가 근본적으로 달라집니다. 이 모듈에서는 3-Tier, MSA, CQRS라는 세 가지 핵심 아키텍처 패턴에서 DB가 어떤 역할을 하는지, 특히 DB 역할에 초점을 맞춰 살펴봅니다.
3-Tier와 MSA에서의 DB 위치 — 어디에 어떻게 붙는가
프론트엔드에서 직접 DB에 쿼리를 날리는 코드를 발견했습니다. 또 다른 팀의 마이크로서비스가 우리 팀의 DB 테이블을 직접 읽고 있습니다. 아무도 스키마를 함부로 바꿀 수 없는 상황이 됩니다. DB가 아키텍처의 어디에 위치해야 하는지, 어느 계층만 접근해야 하는지 이해하지 못하면 이런 결합 문제가 시스템 전체로 퍼집니다.
 확대
확대
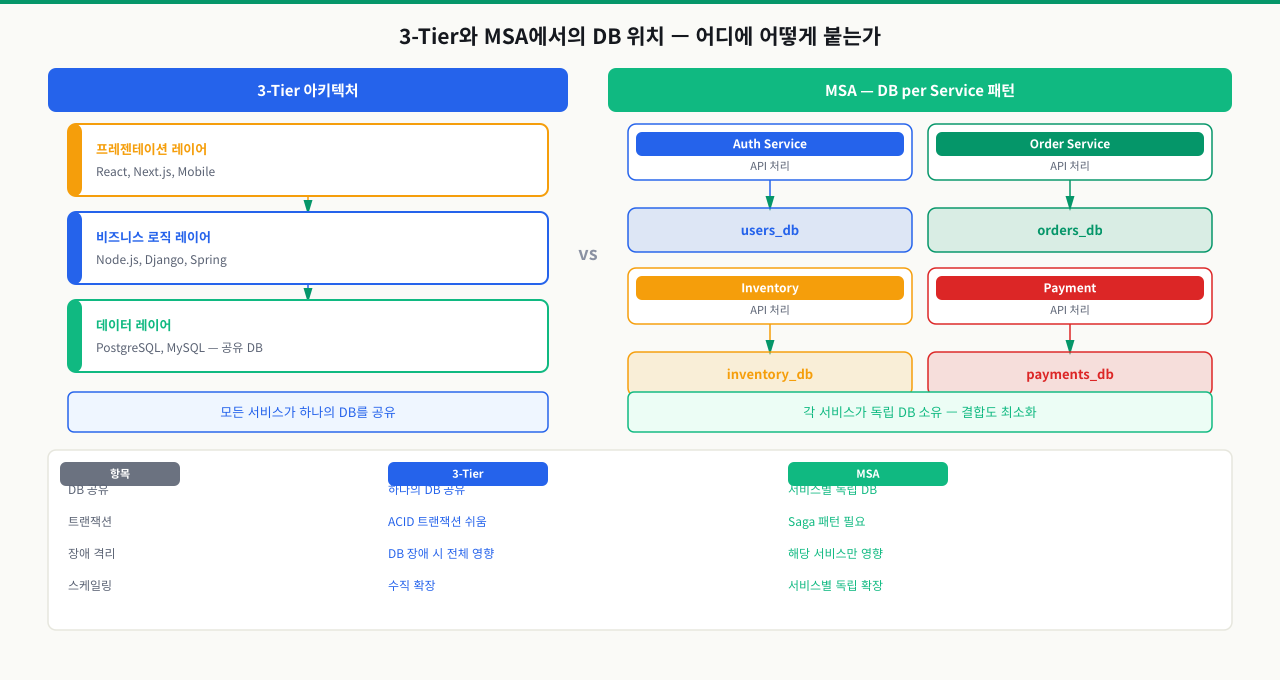
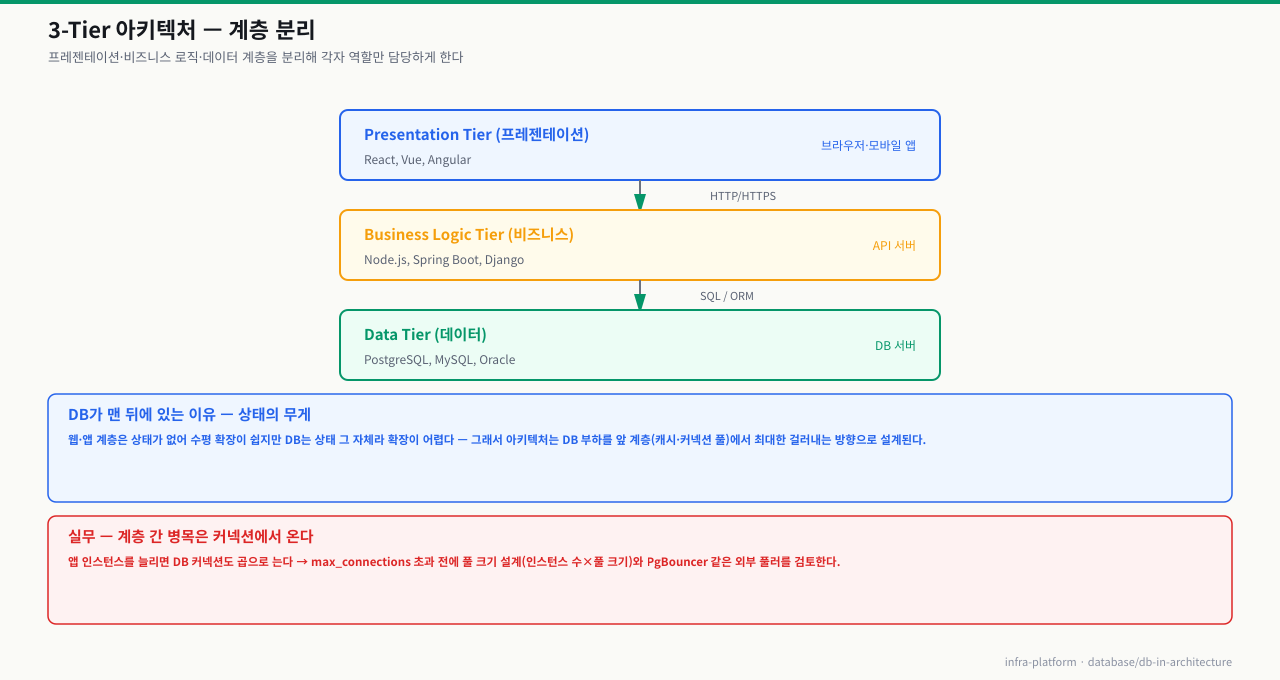
3-Tier 아키텍처: DB는 비즈니스 계층만 접근한다
3-Tier 아키텍처는 소프트웨어를 세 개의 독립적인 계층으로 나누는 가장 보편적인 패턴입니다. 프론트엔드 코드에서 SELECT * FROM users WHERE id = ?를 직접 날리거나, 반대로 DB가 UI 로직을 포함하면 보안 구멍이 생기고 코드 변경이 전체 스택에 파급됩니다. 3-Tier는 각 계층이 자신의 역할만 담당하도록 강제해 이 문제를 근본적으로 차단합니다.
 확대
확대
각 계층의 역할에서 핵심은 DB 접근 경로입니다. 프레젠테이션 계층은 DB와 직접 통신하지 않고, 비즈니스 로직 계층만이 SQL을 실행하고 결과를 가공합니다. 데이터 계층은 오직 비즈니스 계층만 접근합니다. 프론트엔드가 DB에 직접 쿼리를 날리는 구조는 보안과 유지보수 관점에서 심각한 문제를 만듭니다.
| 계층 | DB 역할 | DB와의 관계 |
|---|---|---|
| 프레젠테이션 | 데이터 표시 | 직접 접근 금지 |
| 비즈니스 로직 | 쿼리 실행, 결과 가공 | 유일한 접근 주체 |
| 데이터 | 영구 저장소 | 수동적 응답자 |
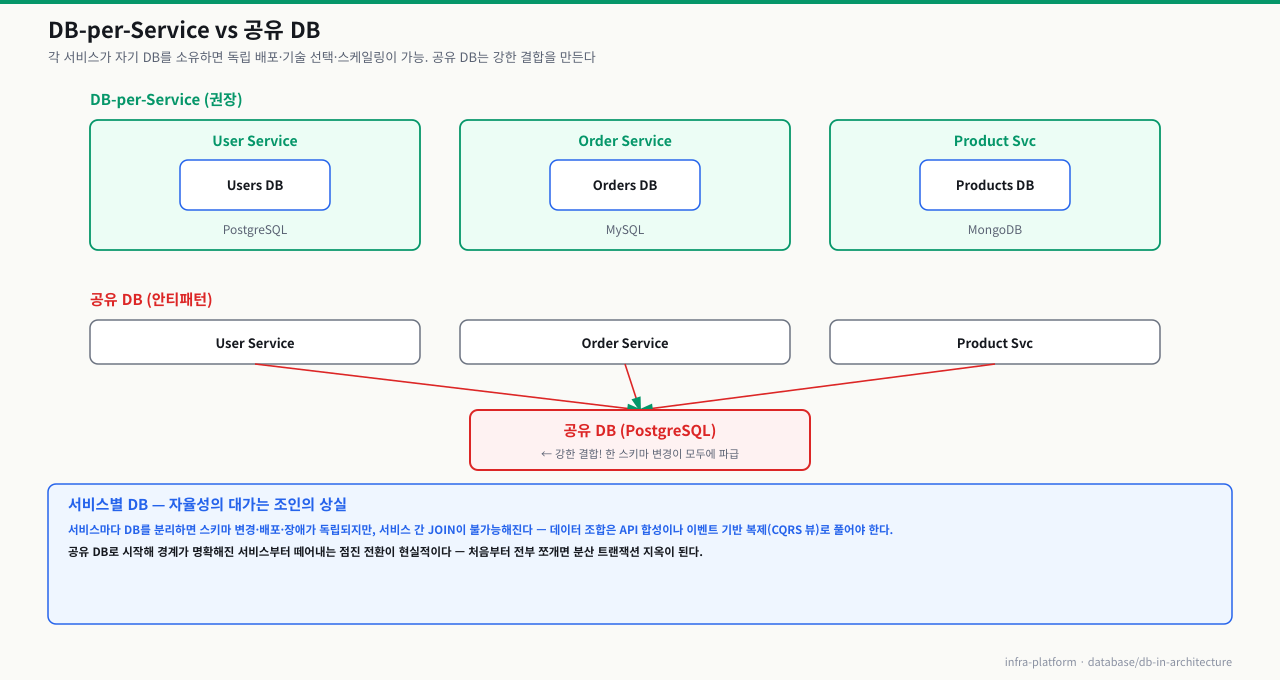
MSA에서의 DB-per-Service 패턴
마이크로서비스 아키텍처(MSA)에서는 각 서비스가 자신만의 데이터베이스를 소유합니다. DB가 서비스 내부에 캡슐화되는 것이 핵심입니다. User Service와 Order Service가 같은 PostgreSQL을 공유하면, users 테이블에 컬럼을 추가할 때 Order Service 코드도 함께 수정·배포해야 합니다. MSA가 약속하는 독립 배포가 불가능해지는 것입니다. DB-per-Service는 이 결합을 근본적으로 끊습니다.
 확대
확대
DB-per-Service 패턴의 핵심 장점은 세 가지입니다. 첫째, 독립적 배포—User Service의 스키마를 변경해도 Order Service에 영향이 없습니다. 둘째, 기술 선택 자유—제품 카탈로그는 MongoDB, 주문은 PostgreSQL, 세션은 Redis를 선택할 수 있습니다. 셋째, 독립적 스케일링—주문 서비스의 DB만 따로 스케일 아웃할 수 있습니다.
공유 DB 패턴의 문제점
MSA에서 여러 서비스가 하나의 DB를 공유하면(위 그림 아래쪽) DB가 서비스 간 강한 결합의 원인이 됩니다.
Order Service가 users 테이블을 직접 JOIN하면, users 테이블의 컬럼 이름을 바꿀 때 Order Service도 함께 수정해야 합니다. 스키마 변경 시 모든 관련 서비스를 동시에 배포해야 하고, 공유 DB가 다운되면 모든 서비스가 동시에 장애를 겪습니다.
실무 팁: MSA 초기에는 공유 DB로 시작해서 서비스가 안정되면 분리하는 "Strangler Fig" 전략을 쓰는 경우도 많습니다. 처음부터 완벽한 분리를 강요하면 오히려 개발 속도가 느려질 수 있습니다.
API Gateway 패턴과 DB
MSA에서 클라이언트는 각 서비스에 직접 접근하지 않고 API Gateway를 거칩니다.
Client → API Gateway → User Service → Users DB
→ Order Service → Orders DB
→ Product Service → Products DB
API Gateway는 라우팅, 인증, 속도 제한을 담당하며 DB에는 직접 접근하지 않습니다. 여러 서비스의 데이터를 조합해야 할 때는 API Gateway가 각 서비스를 호출해 결과를 합칩니다(Backend for Frontend 패턴).
User Service와 Order Service가 같은 PostgreSQL 인스턴스의 테이블에 직접 SQL로 접근하면, 두 서비스는 스키마 수준에서 강하게 결합됩니다. users 테이블에 컬럼을 추가하거나 이름을 바꾸면 Order Service의 쿼리도 깨집니다. 독립 배포라는 MSA의 핵심 장점이 사라집니다.
해결책은 각 서비스가 자신의 DB만 소유하고, 다른 서비스의 데이터가 필요하면 반드시 해당 서비스의 API를 통해 요청하는 것입니다. 데이터 접근이 아닌 서비스 계약(API)을 통해 통신해야 MSA의 독립성이 유지됩니다.
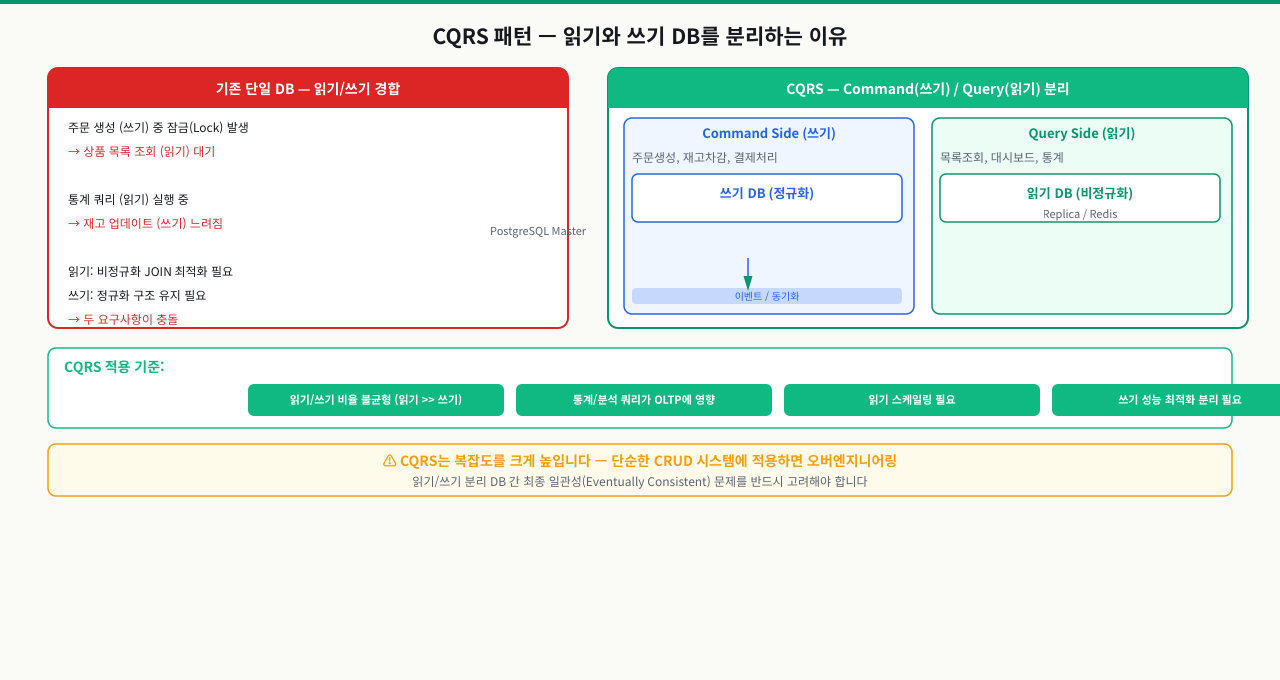
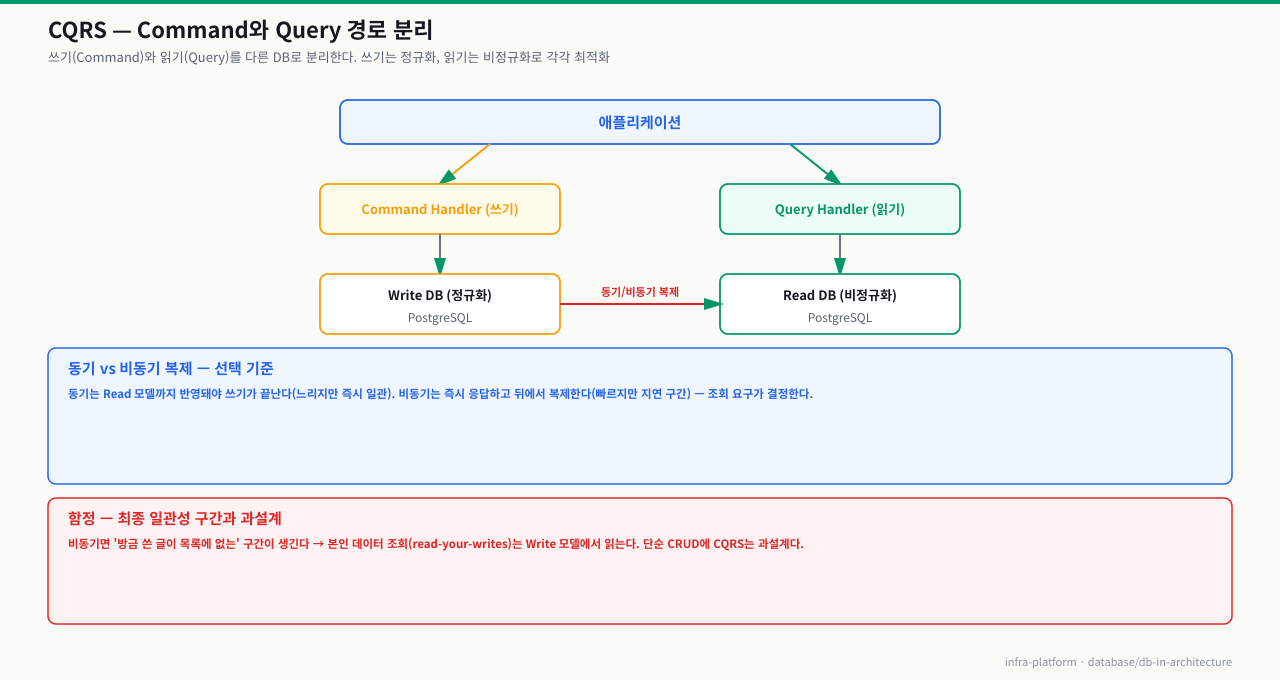
CQRS 패턴 — 읽기와 쓰기 DB를 분리하는 이유
대시보드용 집계 쿼리가 느려서 인덱스를 추가했는데, 오히려 주문 생성 API의 INSERT가 느려졌습니다. 읽기와 쓰기가 같은 DB에 있어서 최적화 방향이 서로 충돌합니다. CQRS는 이 문제를 쓰기 모델과 읽기 모델을 분리해서 각각 독립적으로 최적화하는 패턴으로 해결합니다.
 확대
확대
CQRS란 무엇인가
CQRS(Command Query Responsibility Segregation)는 데이터를 **변경하는 Command(명령)**와 데이터를 **조회하는 Query(질의)**의 처리 경로를 완전히 분리하는 패턴입니다. 2010년 Greg Young이 체계화했으며, 현재는 대형 서비스에서 보편적으로 사용됩니다. 주문 목록 API가 매번 users, orders, order_items, products를 JOIN하는 무거운 쿼리를 실행하는데 쓰기는 드물고 읽기가 폭발적으로 많은 상황을 생각해보세요. 정규화된 단일 DB 하나로는 한계가 옵니다. CQRS는 읽기와 쓰기 경로를 아예 다른 DB로 분리해 이 문제를 해결합니다.
 확대
확대
Command 모델: 쓰기에 최적화
Write DB는 데이터 무결성에 집중합니다. 정규화된 구조로 외래키와 제약조건을 엄격하게 적용합니다. Command는 CreateOrder, UpdateOrderStatus, CancelOrder처럼 의도를 명확히 표현하는 이름을 사용합니다.
CREATE TABLE orders (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users(id),
status VARCHAR(20) NOT NULL DEFAULT 'pending',
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE order_items (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
order_id UUID NOT NULL REFERENCES orders(id),
product_id UUID NOT NULL REFERENCES products(id),
quantity INT NOT NULL CHECK (quantity > 0),
unit_price NUMERIC(10, 2) NOT NULL
);
실행 완료 또는 조회 결과가 표시됩니다.
- 레이턴시 먼저: Write DB INSERT와 Read DB SELECT의 응답 시간을 각각 확인 — P99 기준 100ms 이하면 정상, 1s 이상이면 커넥션 풀 포화나 락 경합 의심
- Connection Pool 사용률 판단: Pool 사용률 80% 이상이면 요청 대기가 발생. 100% 포화 시 새 요청이 거부되어 전체 API 마비로 이어짐
- Write·Read 지연 조합 해석: Write는 빠르고(5ms) Read가 느리면(500ms) → Read DB 동기화 지연 또는 비정규화 테이블 갱신 누락 의심
Query 모델: 읽기에 최적화
Read DB는 조회 성능에 집중합니다. 정규화를 포기하고 조회에 필요한 데이터를 미리 합쳐 놓습니다. 이 구조에서는 복잡한 JOIN 없이 단순 SELECT 한 번으로 주문 목록 화면을 구성할 수 있습니다.
CREATE TABLE order_summary_view (
order_id UUID PRIMARY KEY,
user_name VARCHAR(100),
user_email VARCHAR(255),
status VARCHAR(20),
total_amount NUMERIC(10, 2),
item_count INT,
product_names TEXT[],
created_at TIMESTAMPTZ
);
Write DB에서 Read DB로 데이터 동기화
두 DB를 동기화하는 방식은 크게 세 가지입니다.
이벤트 기반 동기화는 Write DB에서 변경이 발생하면 이벤트를 발행하고 Event Bus를 거쳐 Read DB를 업데이트합니다. 가장 유연하고 권장되는 방식입니다.
PostgreSQL Logical Replication은 DB 수준에서 변경 내용을 스트리밍합니다. Publisher(Write DB)와 Subscriber(Read DB)를 아래와 같이 설정합니다.
CREATE PUBLICATION orders_pub FOR TABLE orders, order_items;
CREATE SUBSCRIPTION orders_sub
CONNECTION 'host=write-db ...'
PUBLICATION orders_pub;
Materialized View는 단일 DB 내에서 조회용 스냅샷을 주기적으로 갱신합니다. 별도 인프라 없이 시작하기 좋은 방식입니다.
CREATE MATERIALIZED VIEW order_summary AS
SELECT
o.id AS order_id,
u.name AS user_name,
u.email AS user_email,
o.status,
SUM(oi.quantity * oi.unit_price) AS total_amount,
COUNT(oi.id) AS item_count,
o.created_at
FROM orders o
JOIN users u ON o.user_id = u.id
LEFT JOIN order_items oi ON o.id = oi.order_id
GROUP BY o.id, u.name, u.email, o.status, o.created_at;
REFRESH MATERIALIZED VIEW CONCURRENTLY order_summary;
CQRS를 언제 적용해야 하는가
CQRS는 강력하지만 복잡성을 크게 높입니다. 다음 기준으로 적용 여부를 판단하세요.
| 조건 | CQRS 도입 고려 |
|---|---|
| 읽기/쓰기 비율이 100:1 이상 | O |
| 쓰기는 적지만 조회 쿼리가 매우 복잡 | O |
| 읽기와 쓰기의 스케일링 요구가 다름 | O |
| 팀 규모가 작고 트래픽이 낮음 | X |
| 데이터 일관성이 최우선 | X (Eventual Consistency 수용해야 함) |
채용공고에서 "CQRS/Event Sourcing 경험 우대", "Read Replica 운영 경험", "MSA 환경에서 데이터 정합성 관리 경험" 같은 표현이 보이면 이 패턴들을 이해하고 있음을 보여줄 수 있어야 합니다.
주문 목록 조회 API에서 orders, users, order_items, products 테이블을 매번 JOIN하는 쿼리가 100ms 이상 걸렸습니다. 주문 생성(쓰기)은 하루 수천 건이지만 주문 조회(읽기)는 초당 수백 건으로 비율 차이가 컸습니다.
CQRS를 적용해 Write DB는 정규화 구조를 유지하고, 주문 생성/변경 이벤트가 발생할 때마다 Read DB의 order_summary_view 테이블을 비동기로 업데이트했습니다. 조회 쿼리는 단순 SELECT * WHERE user_id = $1로 단순화됐고 응답 시간이 100ms에서 5ms로 줄었습니다. 작은 팀에서 전체 CQRS 인프라를 구축하기 어렵다면, PostgreSQL의 Materialized View와 REFRESH CONCURRENTLY로 시작하는 것도 좋은 선택입니다.
심화 — 분리의 대가는 '시간차'다
심화: 읽기 분리가 만드는 결과적 일관성 — 복제 지연을 설계로 다루기
CQRS와 Read Replica는 읽기 부하를 떼어내 독립 스케일링을 가능하게 하지만, 함께 딸려오는 것이 있습니다 — 시간차입니다. 쓰기는 Write DB/Primary에, 읽기는 Read DB/Replica에 도착하는데, 그 둘을 잇는 동기화(복제)는 대개 비동기라 지연(replication lag)이 존재합니다.
- 동기 복제는 지연을 없애지만 쓰기 응답이 느려지고 가용성 비용이 큽니다. 그래서 실무 대부분은 비동기를 쓰고, 그 결과 방금 커밋한 데이터가 Read 쪽엔 아직 없을 수 있습니다(stale read).
- 이로 인한 두 함정: read-your-writes(내가 쓴 걸 바로 못 읽음), monotonic reads(새로고침마다 값이 앞뒤로 튐).
- 설계로 다루기: '쓰고 바로 읽어야 하는' 요청은 Primary로 라우팅, 복제 지연을 모니터링해 임계 초과 시 Read 라우팅을 일시 차단, 어디까지 오래된 데이터를 허용할지(staleness 경계)를 요구사항으로 명시.
즉 CQRS·복제 분리는 '강한 일관성'을 결과적 일관성으로 바꾸는 대신 성능을 얻는 거래입니다. 그 거래 조건을 모른 채 도입하면, 성능은 좋아졌는데 '가끔 데이터가 안 보인다'는 버그 리포트에 시달리게 됩니다.
상황: 주문 조회를 Read Replica/비정규화 Read DB로 옮겨 조회 성능은 좋아졌는데, '주문 직후 목록에 안 보임'이 간헐적으로 발생합니다. 잠시 뒤 새로고침하면 정상적으로 보입니다.
원인: 쓰기는 Primary에, 조회는 Read 쪽에 갔는데 둘 사이 복제가 비동기라 지연이 있습니다. 주문 커밋 직후 아주 짧은 창 동안 Read 쪽엔 그 행이 아직 복제되지 않아 안 보이는 stale read입니다. 트래픽 피크나 대량 쓰기로 복제 지연이 커질 때 더 잦아집니다.
진단: 복제 지연 지표를 확인합니다(예: pg_replication_lag, 복제 슬롯의 지연). 문제 요청이 실제로 Read 쪽으로 라우팅되는지, 그리고 커밋 시각과 조회 시각의 간격이 복제 지연보다 짧은지 대조합니다.
해결: 주문 직후 확인처럼 '쓰고 바로 보여줘야 하는' 흐름은 Primary(Write DB)에서 읽도록 라우팅합니다. 또는 방금 쓴 사용자만 잠시 Primary로 붙이는 read-your-writes 처리를 더하고, 복제 지연 모니터링·알람으로 임계 초과 시 Read 라우팅을 일시 차단합니다. CQRS·복제 분리는 결과적 일관성을 받아들이는 대가로 성능을 얻는 것이므로, 어디까지 stale을 허용할지를 요구사항으로 못박아 둬야 합니다(Master-Slave 복제(Replication) 구축과 DB 고가용성(HA) 아키텍처).
명령어·구문 빠른 참조
이 모듈에서 CQRS의 Write/Read 모델과 동기화를 구현할 때 쓴 SQL 구문을 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
UUID PRIMARY KEY DEFAULT gen_random_uuid() | Write 모델 분산 친화 PK | id UUID PRIMARY KEY DEFAULT gen_random_uuid() |
REFERENCES (FK) + CHECK | 정규화된 Write DB 무결성 | order_id UUID REFERENCES orders(id), CHECK (quantity > 0) |
TEXT[] 배열 컬럼 | 비정규화 Read 모델에 미리 합침 | product_names TEXT[](JOIN 없이 조회) |
CREATE MATERIALIZED VIEW | 조회용 스냅샷 사전 집계 | CREATE MATERIALIZED VIEW order_summary AS SELECT ... |
REFRESH MATERIALIZED VIEW CONCURRENTLY | 잠금 최소로 뷰 갱신 | 소규모 팀 CQRS 시작점 |
CREATE PUBLICATION ... FOR TABLE | 논리 복제 발행자(Write DB) | CREATE PUBLICATION orders_pub FOR TABLE orders, order_items |
CREATE SUBSCRIPTION ... PUBLICATION | 논리 복제 구독자(Read DB) | CREATE SUBSCRIPTION orders_sub CONNECTION '...' PUBLICATION orders_pub |
JOIN / LEFT JOIN + GROUP BY | Read 뷰 구성용 집계 | JOIN users ... LEFT JOIN order_items ... GROUP BY ... |
pg_replication_lag | 복제 지연(stale read) 감시 | 지연 임계 초과 시 Read 라우팅 차단 |
관련 모듈로 더 깊이:
- Master-Slave 복제(Replication) 구축과 DB 고가용성(HA) 아키텍처 — Read Replica로 읽기 부하를 분산하는 고가용성 구성
- DB 슬로우 쿼리 실전 진단: EXPLAIN ANALYZE로 병목 찾고 인덱스 설계하기 — CQRS로 분리하기 전, 느린 조회 쿼리 자체를 개선하는 법
- 우리 서비스에 맞는 최적의 RDBMS vs NoSQL 고르기 — 서비스 아키텍처에 어떤 DB를 배치할지 선택하는 기준
다음 모듈에서는 DBeaver, TablePlus, psql 등 실무에서 자주 쓰는 DB 클라이언트 도구 활용법을 다룹니다.