복잡한 조회를 한 번에 작성하다 보면 WHERE 안의 SELECT와 WITH 절을 쓰게 됩니다. 하지만 상관 서브쿼리를 잘못 쓰면 같은 테이블을 수천 번 반복 조회합니다. 서브쿼리와 CTE의 실행 특성을 이해하면 읽기 쉬우면서도 느리지 않은 SQL을 만들 수 있습니다.
서브쿼리는 쿼리 안에 중첩된 또 다른 쿼리입니다. 위치에 따라 역할이 달라지며(스칼라값 반환, 인라인 테이블, 필터 조건), 상관 서브쿼리는 외부 쿼리의 행마다 재실행됩니다. CTE(WITH 절)는 서브쿼리를 이름 붙인 블록으로 분리해 가독성을 극적으로 높이며, RECURSIVE 옵션으로 계층형 데이터도 처리할 수 있습니다.
- 1SELECT, FROM, WHERE 절에서 서브쿼리를 위치에 맞게 사용할 수 있다
- 2상관 서브쿼리와 비상관 서브쿼리의 차이와 성능을 이해하고 구분할 수 있다
- 3대용량 데이터에서 EXISTS와 IN을 비교해 더 빠른 쪽을 선택할 수 있다
- 4CTE 문법과 다단계 CTE로 복잡한 쿼리를 구조화할 수 있다
- 5WITH RECURSIVE로 조직도 같은 계층형 데이터를 순회할 수 있다
- 6CTE, 서브쿼리, 임시 테이블, 뷰 중 상황에 맞는 것을 선택할 수 있다
서브쿼리와 CTE — 복잡한 쿼리 구조화하기
선배 개발자가 "이 API 느린 거 고쳐봐"라고 했다. 알고 보니 users 1만 건을 루프 돌면서 각각 orders를 SELECT하는 전형적인 N+1이었다. 파이썬 코드를 뜯어 고치려다가 — 사실 DB 쿼리 한 방으로 끝낼 수 있다는 걸 그때 처음 배웠다. 서브쿼리로 상관 조회를 하나로 합치고, CTE로 단계별로 쪼개자 쿼리 횟수가 10,001번에서 1번으로 줄었다. 이걸 모르면 애플리케이션 코드에서 루프로 해결하려 하게 되고, DB는 같은 작업을 수천 번 반복하게 된다. 서브쿼리와 CTE는 "쿼리를 예쁘게 쓰는 법"이 아니라, 불필요한 DB 왕복을 없애는 성능 도구다.
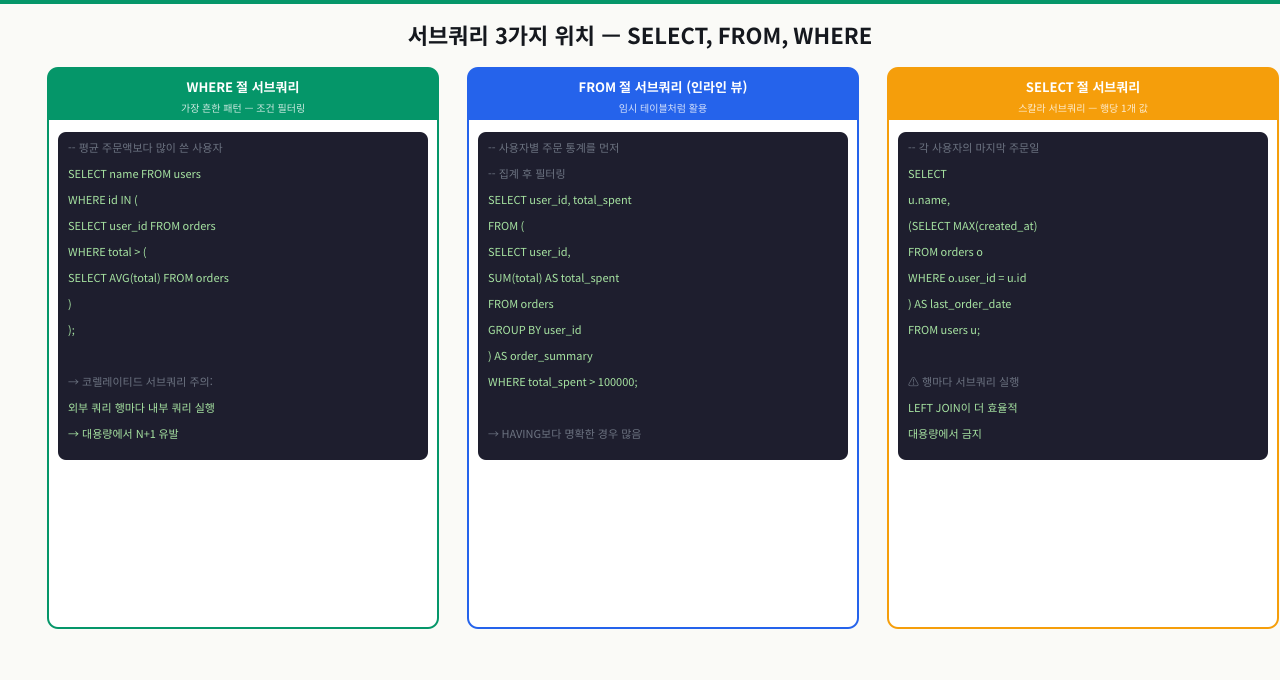
서브쿼리 3가지 위치 — SELECT, FROM, WHERE에서 쓰는 법
각 부서에서 가장 급여가 높은 직원을 조회해야 합니다. 단순 GROUP BY로는 급여 최대값은 구할 수 있지만 그 직원의 이름은 가져오지 못합니다. 서브쿼리를 어디에 어떻게 쓰느냐에 따라 이런 복합 조건 쿼리를 깔끔하게 작성할 수 있습니다.
 확대
확대
서브쿼리란?
서브쿼리(Subquery)는 다른 SQL 문 안에 중첩된 SELECT 문입니다. 괄호로 묶어 표현하며, 위치에 따라 스칼라 서브쿼리, 인라인 뷰, WHERE 절 서브쿼리 세 가지로 구분합니다.
SELECT 절 — 스칼라 서브쿼리
스칼라 서브쿼리는 SELECT 목록 안에 위치하며 행마다 단일 값 하나를 반환합니다. 2건 이상 반환하면 즉시 오류가 발생합니다. 아래 예시는 각 상품 행마다 해당 카테고리의 평균 가격과 차이를 함께 표시합니다. 이 방식은 외부 쿼리의 p.category_id를 참조하는 상관 서브쿼리이므로 상품 행 수만큼 서브쿼리가 반복 실행됩니다. 상품이 10,000건이면 서브쿼리도 10,000번 실행됩니다.
SELECT
p.product_name,
p.price,
(
SELECT AVG(p2.price)
FROM products p2
WHERE p2.category_id = p.category_id
) AS category_avg_price,
p.price - (
SELECT AVG(p2.price)
FROM products p2
WHERE p2.category_id = p.category_id
) AS diff_from_avg
FROM products p;
실행 완료 또는 조회 결과가 표시됩니다.
- EXPLAIN 먼저: 상관 서브쿼리의 경우 외부 테이블 행 수만큼 Loop가 발생하는지 확인 — "Rows Removed: N"이 외부 테이블 행 수에 비례하면 상관 서브쿼리가 반복 실행 중
- CTE vs 서브쿼리 성능 기준: PostgreSQL 12 이상에서 CTE는 기본적으로 인라인 최적화됨. EXPLAIN에 "Materialize" 또는 "CTE Scan"이 보이면 CTE 전체가 먼저 실행되는 것(최적화 장벽)
- EXISTS vs IN 선택 해석: 서브쿼리 결과가 수천 건 이상이면 IN은 결과 전체를 메모리에 올림 — EXISTS는 첫 행 발견 시 즉시 중단(Short-circuit). NOT IN 리스트에 NULL이 섞이면 결과 0건 → NOT EXISTS로 교체
성능이 중요한 상황이라면 AVG() OVER (PARTITION BY category_id) Window 함수로 대체하면 단일 패스로 처리됩니다.
FROM 절 — 인라인 뷰
FROM 절에 서브쿼리를 넣으면 그 결과를 가상의 테이블(인라인 뷰)처럼 사용합니다. 반드시 별칭을 붙여야 하며, 스칼라 서브쿼리와 달리 전체가 한 번만 실행되므로 성능이 훨씬 좋습니다.
SELECT
p.product_name,
p.price,
cat_avg.avg_price
FROM products p
JOIN (
SELECT category_id, AVG(price) AS avg_price
FROM products
GROUP BY category_id
) AS cat_avg ON p.category_id = cat_avg.category_id
WHERE p.price > cat_avg.avg_price;
WHERE 절 — IN / EXISTS / ANY / ALL
WHERE 절의 서브쿼리는 필터 조건으로 사용됩니다. 가장 많이 쓰는 패턴은 IN, EXISTS, NOT IN, NOT EXISTS입니다.
SELECT customer_name, email
FROM customers
WHERE customer_id IN (
SELECT DISTINCT customer_id
FROM orders
WHERE order_date >= CURRENT_DATE - INTERVAL '30 days'
);
SELECT customer_name, email
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
AND o.order_date >= CURRENT_DATE - INTERVAL '30 days'
);
EXISTS vs IN — 성능 비교
| 항목 | IN | EXISTS |
|---|---|---|
| 동작 방식 | 서브쿼리 전체 실행 후 값 목록 메모리에 적재 | 조건 만족 첫 행 발견 시 즉시 중단(Short-circuit) |
| NULL 처리 | NOT IN에서 NULL 포함 시 예상치 못한 결과 | NULL에 안전 |
| 대용량 서브쿼리 | 메모리 부담 증가 | 조기 중단으로 유리한 경우 많음 |
| 소규모 서브쿼리 | 충분히 빠름 | 큰 차이 없음 |
| 가독성 | 직관적 | 상관 서브쿼리 구조 필요 |
NOT IN 리스트에 NULL이 포함되면 전체 결과가 0건이 될 수 있습니다. 서브쿼리 결과에 NULL이 섞일 가능성이 있다면 NOT EXISTS를 사용하세요.
SELECT * FROM orders o
WHERE NOT EXISTS (
SELECT 1 FROM blacklist b
WHERE b.customer_id = o.customer_id
);
비상관 서브쿼리 vs 상관 서브쿼리
비상관 서브쿼리는 외부 쿼리와 독립적으로 단 한 번 실행되고 결과가 재사용됩니다. 상관 서브쿼리는 외부 쿼리가 처리하는 각 행마다 재실행되어 행 수에 비례한 성능 비용이 발생합니다. 가능하면 JOIN이나 Window 함수로 대체를 검토하세요.
SELECT product_name, price
FROM products
WHERE price = (
SELECT MAX(price) FROM products
);
SELECT product_name, price, category_id
FROM products p
WHERE price = (
SELECT MAX(price)
FROM products p2
WHERE p2.category_id = p.category_id
);
상관 서브쿼리가 각 행마다 재실행된다는 사실을 모르고 작성한 쿼리가 개발 환경에서는 빠르다가 운영 데이터에서 타임아웃을 일으키는 경우가 흔합니다.
SELECT
employee_id,
salary,
(SELECT AVG(salary) FROM employees e2
WHERE e2.department_id = e.department_id) AS dept_avg
FROM employees e;
직원이 10만 명이면 서브쿼리가 10만 번 실행됩니다. 부서가 20개뿐이라도 동일 계산이 수천 번 반복됩니다.
해결 방법은 인라인 뷰나 CTE로 집계를 먼저 한 번만 계산하는 것입니다.
WITH dept_avg AS (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT e.employee_id, e.salary, d.avg_salary
FROM employees e
JOIN dept_avg d ON e.department_id = d.department_id;
또는 Window 함수 AVG(salary) OVER (PARTITION BY department_id)를 사용하면 단일 패스로 처리됩니다.
동작 원리 — 서브쿼리·CTE는 언제 몇 번 평가되나
서브쿼리·CTE 평가 모델 — 상관은 N번, 비상관·CTE는 한 번
같은 결과를 스칼라 서브쿼리로도, 조인으로도, CTE로도 쓸 수 있는데 어떤 건 순식간이고 어떤 건 운영 데이터에서 타임아웃이 납니다. 차이를 만드는 건 문법이 아니라 "DB가 그 서브쿼리를 언제, 몇 번 평가하느냐"입니다. 위치와 상관 여부에 따라 평가 시점·횟수가 어떻게 갈리는지 보면, 상관 서브쿼리가 왜 N번 돌고 CTE는 왜 한 번인지, 옵티마이저가 왜 IN과 EXISTS를 같게 취급하는지가 정리됩니다.
[바깥 쿼리가 서브쿼리를 만난다]
│
└─ 바깥 컬럼을 참조하나? (상관 여부)
│
├─▶ 예: 상관 서브쿼리
│ → 바깥 행 1건마다 다시 평가 (N행이면 N번)
│ 예) SELECT ..., (SELECT AVG(price) FROM p2 WHERE p2.cat=p.cat)
│ → 상품 수만큼 안쪽 SELECT 반복
│
└─▶ 아니오: 비상관 서브쿼리
→ 한 번 평가하고 결과를 재사용
├─ WHERE IN·EXISTS → 대개 세미조인으로 변환(첫 매칭에서 멈춤)
├─ FROM 인라인 뷰 → 결과 집합을 한 번 만들어 테이블처럼 조인
└─ WITH CTE → 한 번 평가 (PG12+는 대개 본문에 인라인)
위치·유형별 평가 방식과 함정:
| 위치·유형 | 언제·몇 번 평가되나 | 함정·증상 |
|---|---|---|
| SELECT 절 스칼라(상관) | 바깥 행마다 1번 → N행이면 N번. 반드시 0·1건만 반환 | 큰 테이블에서 N+1처럼 느려짐. 2건 이상 반환하면 more than one row returned by a subquery → 인라인 뷰·CTE·AVG() OVER(...)로 대체 |
| WHERE IN (비상관) | 서브쿼리를 한 번 평가한 뒤 세미조인. 옵티마이저가 대개 EXISTS와 같은 계획 | NOT IN 대상 컬럼이 nullable이면 NULL 3치 논리로 결과가 전건 0행 → 제외는 NOT EXISTS |
| WHERE EXISTS (상관) | 바깥 행별로 안쪽을 보되 첫 매칭에서 즉시 중단(short-circuit), 세미조인화 | 안쪽 상관 컬럼에 인덱스가 없으면 반복 조회가 비싸짐 → 상관 컬럼에 인덱스 |
| FROM 인라인 뷰 | 전체를 한 번 평가해 파생 테이블을 만든 뒤 바깥이 조인·필터 | 별칭 필수. 큰 중간 결과를 통째로 만들면 정렬·메모리 비용 |
| WITH CTE | 한 번 평가. PG12+는 참조 1회면 본문에 인라인, 여러 번·재귀면 물질화(Materialize) | PG11 이하·MATERIALIZED는 최적화 장벽 — 바깥 조건이 CTE 안으로 push-down 안 됨. EXPLAIN에 CTE Scan·Materialize |
그래서 서브쿼리 튜닝의 첫 질문은 늘 "이게 상관인가"입니다 — 바깥 컬럼을 참조하면 행마다 도니 N번, 아니면 한 번입니다. EXPLAIN에서 안쪽 노드가 바깥 행 수만큼 loops=N으로 찍히면 상관 반복이 확정이고, 인라인 뷰·CTE·윈도우 함수로 "한 번 평가"로 바꾸는 것이 정석입니다. 긍정형 IN·EXISTS는 대개 같은 세미조인으로 수렴하니 문법을 고르기보다 상관 컬럼의 인덱스를 확인하고, 제외형은 NULL에 안전한 NOT EXISTS를 기본으로 둡니다. 세미조인·안티조인으로 변환되는 더 깊은 이야기는 이 모듈 끝의 심화에서 이어집니다.
CTE(WITH 절) — 쿼리를 함수처럼 구조화하기
중첩 서브쿼리가 5단계로 쌓인 쿼리를 받았습니다. 어디서부터 읽어야 할지 모르겠고, 중간에 디버깅도 안 됩니다. CTE는 복잡한 쿼리를 이름 붙인 블록으로 나눠 위에서 아래로 읽을 수 있게 구조화합니다. 긴 쿼리를 관리하는 법을 모르면 코드 리뷰에서 "이 쿼리 무슨 의미야?"를 피하기 어렵습니다.
 확대
확대
CTE 기본 문법
CTE(Common Table Expression)는 WITH 키워드로 시작하며, 이름 붙은 임시 결과셋을 정의합니다. 마치 함수처럼 이름으로 참조할 수 있어 복잡한 쿼리를 논리적 단계로 분리합니다.
WITH cte_name AS (
SELECT ...
)
SELECT * FROM cte_name;
다단계 CTE — 이전 CTE 참조
여러 CTE를 쉼표로 연결하고, 나중에 정의된 CTE가 앞서 정의된 CTE를 참조할 수 있습니다. 단계마다 이름을 붙이면 쿼리의 의도가 명확해지고, 코드 리뷰와 유지보수가 훨씬 쉬워집니다.
WITH active_customers AS (
SELECT DISTINCT customer_id
FROM orders
WHERE order_date >= CURRENT_DATE - INTERVAL '90 days'
),
customer_stats AS (
SELECT
o.customer_id,
COUNT(*) AS order_count,
SUM(o.total_amount) AS total_spent,
AVG(o.total_amount) AS avg_order_value
FROM orders o
WHERE o.customer_id IN (SELECT customer_id FROM active_customers)
GROUP BY o.customer_id
),
vip_customers AS (
SELECT
customer_id,
total_spent,
CASE
WHEN total_spent >= 1000000 THEN 'GOLD'
WHEN total_spent >= 500000 THEN 'SILVER'
ELSE 'BRONZE'
END AS vip_grade
FROM customer_stats
)
SELECT
c.customer_name,
c.email,
v.total_spent,
v.vip_grade
FROM customers c
JOIN vip_customers v ON c.customer_id = v.customer_id
ORDER BY v.total_spent DESC;
WITH RECURSIVE — 계층형 데이터 순회
WITH RECURSIVE는 CTE가 자기 자신을 참조할 수 있게 합니다. 앵커 멤버(초기값)와 재귀 멤버(자기 참조) 두 부분으로 구성됩니다. 순환 참조 데이터가 있다면 depth < 10 같은 깊이 제한을 추가해 무한 루프를 방지하세요.
WITH RECURSIVE org_tree AS (
SELECT
id,
name,
manager_id,
0 AS depth,
name::TEXT AS path
FROM employees
WHERE id = 1
UNION ALL
SELECT
e.id,
e.name,
e.manager_id,
ot.depth + 1,
ot.path || ' > ' || e.name
FROM employees e
JOIN org_tree ot ON e.manager_id = ot.id
)
SELECT
REPEAT(' ', depth) || name AS indented_name,
depth,
path
FROM org_tree
ORDER BY path;
재귀 CTE는 앵커(시작점)에서 출발해 재귀 멤버가 자식을 한 단계씩 끌어오는 구조입니다. 위 쿼리를 실행해 depth가 0부터 한 단계씩 늘며 조직도가 들여쓰기로 펼쳐지는지 확인합니다.
WITH RECURSIVE org_tree AS (
SELECT id, name, manager_id, 0 AS depth, name::TEXT AS path
FROM employees WHERE id = 1 -- 앵커: 최상위 1명
UNION ALL
SELECT e.id, e.name, e.manager_id, ot.depth + 1, ot.path || ' > ' || e.name
FROM employees e
JOIN org_tree ot ON e.manager_id = ot.id -- 재귀: 자식 끌어오기
)
SELECT REPEAT(' ', depth) || name AS indented_name, depth
FROM org_tree ORDER BY path;
indented_name | depth
---------------------+-------
김대표 | 0
이부장 | 1
박사원 | 2
최팀장 | 1
WITH RECURSIVE org_tree AS (...) SELECT REPEAT(' ', depth) || name, depth FROM org_tree ORDER BY path;- depth가 0인 행이 정확히 1개(앵커=최상위)인지 먼저 본다. 0이 여러 개면 WHERE 앵커 조건이 너무 넓은 것
- depth가 0,1,2…로 연속 증가하며 indented_name 들여쓰기가 깊어지는지 확인 — 한 단계도 안 늘면 JOIN 조건(e.manager_id = ot.id)이 안 맞아 재귀가 멈춘 것
- 쿼리가 끝나지 않고 멈춰 있으면(무한 루프) manager_id에 순환 참조가 있는 것 — 재귀 멤버에 AND ot.depth < 10 같은 깊이 제한을 추가한다
- 행 수가 employees 전체보다 적으면 앵커에서 도달 못 한 고아 노드가 있다는 신호다
CTE vs 서브쿼리 — 가독성 비교
같은 로직을 서브쿼리와 CTE로 각각 작성했을 때의 차이입니다. 서브쿼리 방식은 안쪽부터 읽어야 해서 의도 파악이 어렵고, CTE 방식은 위에서 아래로 단계별로 읽힙니다.
SELECT customer_name
FROM customers
WHERE customer_id IN (
SELECT customer_id
FROM orders
WHERE order_id IN (
SELECT order_id
FROM order_items
WHERE product_id IN (
SELECT product_id
FROM products
WHERE category = 'ELECTRONICS'
)
)
);
WITH electronics AS (
SELECT product_id FROM products WHERE category = 'ELECTRONICS'
),
electronics_orders AS (
SELECT DISTINCT order_id FROM order_items
WHERE product_id IN (SELECT product_id FROM electronics)
),
qualified_customers AS (
SELECT DISTINCT customer_id FROM orders
WHERE order_id IN (SELECT order_id FROM electronics_orders)
)
SELECT customer_name
FROM customers
WHERE customer_id IN (SELECT customer_id FROM qualified_customers);
CTE vs 임시 테이블 vs 뷰 — 선택 기준
| 구분 | CTE | 임시 테이블 | 뷰(View) |
|---|---|---|---|
| 범위 | 단일 쿼리 내에서만 유효 | 세션 전체 | 영구 저장 |
| 재사용 | 동일 쿼리 내에서만 | 세션 내 여러 쿼리 | 여러 세션/쿼리 |
| 인덱스 | 불가 | 가능 | 불가(일반 뷰) |
| 성능 | 쿼리 플래너가 최적화 | 명시적 통계 활용 | 쿼리 플래너 최적화 |
| 적합 상황 | 복잡한 쿼리 가독성 | 대용량 중간 결과 재사용 | 비즈니스 로직 공유 |
PostgreSQL 12 이전에서 CTE는 optimization fence(최적화 장벽)로 동작했습니다. CTE는 항상 완전히 실행되고 그 결과가 materialized되어, 플래너가 CTE 내부와 외부를 함께 최적화할 수 없었습니다. PostgreSQL 12부터는 CTE를 인라인하는 최적화가 기본으로 활성화되었으며, 명시적으로 제어하려면 MATERIALIZED 또는 NOT MATERIALIZED 키워드를 사용합니다.
WITH recent_orders AS NOT MATERIALIZED (
SELECT * FROM orders WHERE order_date > '2024-01-01'
)
SELECT * FROM recent_orders WHERE customer_id = 42;
CTE가 가독성이 좋다는 이유로 모든 상황에서 성능도 우수하다고 착각하면 안 됩니다.
PostgreSQL 11 이하에서는 CTE가 optimization fence로 동작합니다. 외부 WHERE 조건이 CTE 내부로 push-down되지 않아 CTE 전체를 먼저 완전히 실행한 뒤 필터링합니다.
WITH all_orders AS (
SELECT * FROM orders
)
SELECT * FROM all_orders WHERE customer_id = 42;
PostgreSQL 11에서 위 쿼리는 orders 테이블 전체를 CTE로 materialize한 다음 필터링합니다. 반면 서브쿼리나 직접 쿼리는 인덱스를 타서 customer_id=42인 행만 읽습니다.
진단: EXPLAIN ANALYZE로 CTE 노드에 Materialize 또는 CTE Scan이 보이면 해당 CTE가 전체 실행됨을 의미합니다.
해결 방법은 PostgreSQL 버전 확인 후 12 이상이면 NOT MATERIALIZED로 인라인 최적화를 허용하거나, 조건을 CTE 내부로 직접 이동시키는 것입니다.
분석팀이 "지난 분기 활성 고객 중 VIP 등급별 평균 주문 금액과 재구매율을 한 번에 보여달라"고 요청합니다. 하나의 거대한 서브쿼리 중첩으로 작성하면 개발자 본인도 나중에 읽기 어렵고, 부분 결과를 디버깅하기도 힘듭니다.
CTE로 분해하면 각 단계를 독립적으로 실행하며 중간 결과를 확인할 수 있습니다.
WITH active_window AS (
SELECT customer_id, COUNT(*) AS order_count, SUM(amount) AS total_spent
FROM orders
WHERE order_date >= CURRENT_DATE - INTERVAL '90 days'
GROUP BY customer_id
),
graded AS (
SELECT customer_id, order_count, total_spent,
CASE
WHEN total_spent >= 1000000 THEN 'GOLD'
WHEN total_spent >= 300000 THEN 'SILVER'
ELSE 'BRONZE'
END AS grade
FROM active_window
),
repeat_buyers AS (
SELECT customer_id
FROM orders
GROUP BY customer_id
HAVING COUNT(DISTINCT DATE_TRUNC('month', order_date)) >= 2
)
SELECT
g.grade,
COUNT(*) AS 고객수,
ROUND(AVG(g.total_spent), 0) AS 평균구매금액,
COUNT(rb.customer_id) * 100.0
/ NULLIF(COUNT(*), 0) AS 재구매율
FROM graded g
LEFT JOIN repeat_buyers rb ON g.customer_id = rb.customer_id
GROUP BY g.grade
ORDER BY 평균구매금액 DESC;
디버깅 시에는 WITH active_window AS (...) SELECT * FROM active_window 처럼 최종 SELECT만 바꿔 각 단계 결과를 확인합니다.
심화 — 'EXISTS가 IN보다 빠르다'의 진짜 이야기
심화: 옵티마이저는 IN/EXISTS를 세미조인으로 바꾼다 — 진짜 함정은 NOT IN
앞의 비교표는 "IN은 전체를 메모리에 올리고 EXISTS는 첫 행에서 멈춘다"는 교과서적 요약을 줬습니다. 실무 감각으로는 맞지만, 실제 플래너가 하는 일을 알면 'IN이냐 EXISTS냐'에 시간을 덜 쓰고 진짜 중요한 곳을 보게 됩니다.
PostgreSQL 플래너는 상관 없는 IN (서브쿼리)와 EXISTS를 대개 같은 세미조인(semi-join)으로 변환합니다. 세미조인은 "매칭이 하나라도 있으면 통과, 없으면 탈락"을 첫 매칭에서 멈추며 처리하는 조인입니다. 그래서 EXPLAIN을 보면 두 문법이 똑같이 Hash Semi Join으로 나오는 경우가 많습니다 — 문법 선택이 계획을 안 바꿉니다. 성능을 실제로 가르는 건 안쪽 상관 컬럼의 인덱스와 세미조인 방식(hash/nested-loop/merge)입니다. 그러니 긍정형(IN/EXISTS)에서는 문법을 고민하기보다 상관 컬럼에 인덱스가 있는지 확인하고 EXPLAIN을 읽는 편이 낫습니다.
비대칭은 부정형에서 드러납니다.
- **
NOT EXISTS는 깔끔한 안티조인(anti-join)**이 됩니다 — "매칭이 없는 행만 남기기"를 효율적으로 처리합니다. NOT IN (서브쿼리)는 서브쿼리 컬럼이 nullable이면 안티조인으로 못 바꿉니다. 3치 논리 때문입니다: 목록에 NULL이 하나라도 있으면 어떤 x에 대해서도x NOT IN (…)이 참으로 확정되지 않아(UNKNOWN) 결과가 전건 0행이 됩니다. 이 의미를 보존하려고 플래너는 안티조인 대신 NULL까지 확인하는 느린 계획을 씁니다. 즉 NOT IN + nullable 컬럼은 **정확성 지뢰(갑자기 0건)이자 성능 지뢰(안티조인 불가)**입니다.
그래서 규칙은 단순합니다 — 긍정형은 인덱스와 EXPLAIN으로 판단하고(대개 세미조인으로 수렴), 제외 조건은 NOT EXISTS(또는 LEFT JOIN … IS NULL 안티조인)를 기본으로 씁니다. NOT IN은 서브쿼리 컬럼이 NOT NULL임이 보장될 때만 쓰세요.
상황: "탈퇴 이력이 없는 고객"을 뽑는 WHERE customer_id NOT IN (SELECT customer_id FROM withdrawals)가 오래 잘 돌다가, 어느 날부터 결과가 0건입니다. withdrawals에는 여전히 소수 고객만 들어 있고, 데이터가 통째로 바뀐 것도 아닙니다. 게다가 EXPLAIN을 보면 예전보다 무거운 계획입니다.
원인: withdrawals.customer_id가 nullable로 바뀌었고, customer_id 없이 들어온 탈퇴 기록 한 건이 NULL로 존재합니다. NOT IN의 목록에 NULL이 섞이면 3치 논리로 모든 행에서 customer_id NOT IN (…)이 UNKNOWN이 되어 WHERE가 전건을 걸러 0행이 됩니다. 데이터 개수 문제가 아니라 NULL 의미론 문제입니다. 또한 컬럼이 nullable이라 플래너가 NOT IN을 효율적 안티조인으로 바꾸지 못해 계획도 무거워졌습니다.
진단: 서브쿼리 컬럼에 NULL이 있는지부터 봅니다.
-- 서브쿼리 컬럼에 NULL이 하나라도 있나
SELECT count(*) AS null_rows
FROM withdrawals
WHERE customer_id IS NULL;
null_rows가 1 이상이면 NOT IN이 전건 0행이 되는 원인이 확정입니다. EXPLAIN에는 안티조인 대신 NULL을 확인하는 서브플랜/필터가 보입니다.
해결: 제외 조건을 NOT EXISTS나 안티조인으로 바꿔 NULL에 안전하게 만들고, 데이터 모델도 바로잡습니다.
-- NULL에 안전하고 안티조인으로 최적화되는 형태
SELECT c.*
FROM customers c
WHERE NOT EXISTS (
SELECT 1 FROM withdrawals w
WHERE w.customer_id = c.customer_id
);
-- 또는 LEFT JOIN 안티조인
SELECT c.*
FROM customers c
LEFT JOIN withdrawals w ON w.customer_id = c.customer_id
WHERE w.customer_id IS NULL;
두 형태 모두 목록의 NULL에 흔들리지 않고 결과가 올바르며, 플래너가 안티조인을 씁니다. 아울러 withdrawals.customer_id를 NOT NULL로 바로잡고(항상 있어야 하는 값이라면) 인덱스를 두면 안티조인이 더 빨라집니다. 교훈은 하나 — 제외에는 NOT EXISTS를 기본으로, NOT IN은 서브쿼리 컬럼이 NOT NULL일 때만.
명령어·구문 빠른 참조
이 모듈에서 다룬 서브쿼리·CTE 구문을 위치·용도별로 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
스칼라 서브쿼리(SELECT절) | 행마다 값 하나 계산 | SELECT name, (SELECT COUNT(*) FROM orders o WHERE o.user_id = u.id) FROM users u |
인라인 뷰(FROM절) | 서브쿼리 결과를 테이블처럼 | FROM (SELECT category_id, AVG(price) FROM products GROUP BY 1) t |
IN (서브쿼리) | 목록 포함 필터 | WHERE customer_id IN (SELECT customer_id FROM orders WHERE …) |
EXISTS | 존재 여부(첫 행에서 중단) | WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id) |
NOT EXISTS | 제외(NULL 안전·안티조인) | WHERE NOT EXISTS (SELECT 1 FROM blacklist b WHERE b.customer_id = o.customer_id) |
NOT IN | 제외(서브쿼리 NULL 주의) | WHERE id NOT IN (SELECT id FROM …) — 컬럼이 NOT NULL일 때만 |
WITH name AS (…) | CTE로 단계 분리·이름 부여 | WITH active AS (SELECT …) SELECT * FROM active |
| 다단계 CTE(쉼표 연결) | 앞 CTE를 뒤 CTE가 참조 | WITH a AS (…), b AS (SELECT … FROM a) SELECT … |
WITH RECURSIVE | 계층형(조직도·트리) 순회 | WITH RECURSIVE t AS (앵커 UNION ALL 재귀 JOIN t) SELECT … |
NOT MATERIALIZED | CTE 인라인 최적화 허용(PG12+) | WITH r AS NOT MATERIALIZED (…) SELECT … WHERE … |
LEFT JOIN … IS NULL | 안티조인(제외) | LEFT JOIN w ON w.cid = c.cid WHERE w.cid IS NULL |
AVG(…) OVER (PARTITION BY …) | 상관 서브쿼리 대체(단일 패스) | AVG(salary) OVER (PARTITION BY department_id) |
관련 모듈로 더 깊이:
- INNER, LEFT, RIGHT, FULL JOIN의 최적화 실행 조건 — 서브쿼리 대신 JOIN으로 풀 수 있는 경우의 판단 기준
- GROUP BY와 집계함수의 효율적인 인덱스 활용 — CTE 안에서 자주 쓰는 집계와 GROUP BY 심화
- RANK, ROW_NUMBER, LAG, LEAD 윈도우 함수 실무 — 서브쿼리로 구현하던 순위/누적을 한 번에 푸는 윈도우 함수
다음 모듈에서는 N+1 문제, SELECT *, 인덱스 무력화 등 실무에서 자주 만나는 SQL 안티패턴과 방지법을 다룹니다.