검색, 리포트, 배치 작업에서는 문자열과 날짜를 가공하는 쿼리가 자주 등장합니다. 함수 사용 위치를 잘못 잡으면 인덱스를 못 타거나 타임존 버그가 생깁니다. 문자열·날짜 함수를 정확히 쓰면 애플리케이션 코드를 줄이면서도 결과를 안정적으로 만들 수 있습니다.
문자열과 날짜 함수는 데이터 정제, 리포트 생성, 검색 기능 구현의 핵심 도구입니다. PostgreSQL 기준으로 설명하며 MySQL 차이점도 함께 다룹니다.
- 1TRIM, UPPER/LOWER, SUBSTRING, REPLACE, CONCAT로 문자열을 가공할 수 있다
- 2SPLIT_PART, POSITION, LEFT/RIGHT로 원하는 패턴을 추출할 수 있다
- 3REGEXP_REPLACE, REGEXP_MATCH 정규식 함수로 복잡한 문자열을 처리할 수 있다
- 4NOW, CURRENT_DATE, DATE_TRUNC, EXTRACT로 날짜/시간을 다룰 수 있다
- 5AGE, INTERVAL 덧셈, DATEDIFF로 기간을 계산할 수 있다
- 6TO_CHAR, TO_DATE로 날짜 포맷을 변환할 수 있다
- 7AT TIME ZONE으로 타임존을 올바르게 처리할 수 있다
- 8PostgreSQL과 MySQL의 함수 차이를 구분해 적용할 수 있다
문자열/날짜 함수 — 실무에서 가장 자주 쓰는 것들
데이터베이스에는 애플리케이션 코드 없이 SQL만으로 처리할 수 있는 강력한 내장 함수들이 있습니다. 문자열 정제, 날짜 계산, 기간 집계 등을 DB 레벨에서 처리하면 네트워크 전송과 애플리케이션 처리 비용을 줄일 수 있습니다.
문자열 함수 실무 패턴 — 데이터 정제와 변환
외부 시스템에서 가져온 데이터에 공백이 섞여 있거나, 전화번호가 010-1234-5678과 01012345678 두 형식으로 혼재합니다. 이걸 애플리케이션에서 정제하면 모든 곳에서 처리 로직이 중복됩니다. SQL 문자열 함수로 DB 쿼리 단계에서 정제하면 한 곳에서 관리할 수 있습니다.
 확대
확대
기본 문자열 함수
TRIM은 문자열의 앞뒤 공백을 제거합니다. LTRIM은 왼쪽만, RTRIM은 오른쪽만 제거하며, TRIM(BOTH '0' FROM ...) 형식으로 특정 문자를 제거할 수도 있습니다. INITCAP은 PostgreSQL 전용으로 각 단어 첫 글자를 대문자로 변환합니다.
SELECT
TRIM(' 안녕하세요 ') AS trim_both,
LTRIM(' 안녕하세요 ') AS trim_left,
RTRIM(' 안녕하세요 ') AS trim_right,
TRIM(BOTH '0' FROM '00042000') AS trim_zeros;
SELECT
UPPER('hello World') AS upper_case,
LOWER('Hello WORLD') AS lower_case,
INITCAP('hello world') AS title_case;
SELECT
LENGTH('안녕하세요') AS byte_length,
CHAR_LENGTH('안녕하세요') AS char_length,
LENGTH('hello') AS ascii_length;
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 TRIM 결과의 LENGTH를 확인합니다. TRIM 전후 LENGTH 차이가 0이면 공백이 없었던 것입니다 — 차이가 있다면 입력 데이터에 앞뒤 공백이 있었다는 의미이고, DB 저장 전 정제 로직이 필요합니다.
- DATE_TRUNC 결과의 타임존을 확인합니다. TIMESTAMPTZ 컬럼을 DATE_TRUNC('month', ts)로 처리할 때 서버 timezone이 UTC이면 한국 기준 자정(00:00 KST = 전날 15:00 UTC) 경계가 밀립니다 — 8시간 이상 차이가 나는 데이터가 의심스러우면 AT TIME ZONE 'Asia/Seoul'을 추가하세요.
- WHERE 절에 함수를 씌운 컬럼이 있다면 EXPLAIN으로 확인합니다. LOWER(email) = 'user@example.com' 패턴은 인덱스를 타지 못합니다(Seq Scan) — 함수 기반 인덱스(CREATE INDEX ON users (LOWER(email)))가 없으면 수십만 건 이상에서 성능 문제가 생깁니다.
문자열 자르기와 치환
SUBSTRING은 시작 위치와 길이로 부분 문자열을 추출합니다. SPLIT_PART는 PostgreSQL 전용으로 구분자 기준 N번째 토큰을 반환하며, 이메일 도메인 추출이나 날짜 파싱에 유용합니다.
SELECT
SUBSTRING('Hello, World!' FROM 1 FOR 5) AS first_5,
SUBSTRING('Hello, World!' FROM 8) AS from_8,
SUBSTR('Hello, World!', 8, 5) AS world;
SELECT
REPLACE('010-1234-5678', '-', '') AS no_dash,
REPLACE('홍길동 선생님', ' 선생님', '') AS name_only;
SELECT
SPLIT_PART('hong@gmail.com', '@', 1) AS username,
SPLIT_PART('hong@gmail.com', '@', 2) AS domain,
SPLIT_PART('2024-03-15', '-', 1) AS year,
SPLIT_PART('2024-03-15', '-', 2) AS month;
SELECT
LEFT('010-1234-5678', 3) AS area_code,
RIGHT('010-1234-5678', 4) AS last_4;
SELECT
POSITION('@' IN 'user@example.com') AS at_position,
STRPOS('user@example.com', '@') AS at_strpos;
문자열 연결과 포맷팅
CONCAT은 NULL을 빈 문자열로 처리하지만, || 연산자는 NULL이 하나라도 있으면 전체 결과가 NULL이 됩니다. CONCAT_WS는 NULL 항목을 건너뛰면서 구분자로 이어 붙일 때 유용합니다.
SELECT
'성: ' || '홍' || ' 이름: ' || '길동' AS 연결1,
CONCAT('홍', '길동') AS 연결2,
CONCAT_WS(', ', '서울', '강남구', NULL, '역삼동') AS 연결3;
SELECT
LPAD('42', 8, '0') AS zero_padded,
RPAD('hello', 10, '.') AS right_padded;
실무 데이터 정제
이메일에서 도메인을 추출하거나, 전화번호의 하이픈과 공백을 제거하고, 정규식으로 유효하지 않은 이메일을 찾는 쿼리는 데이터 정제 작업에서 반복적으로 사용됩니다. REGEXP_REPLACE의 네 번째 인자 'g'는 전체 치환(global)을 의미합니다.
SELECT
email,
LOWER(SPLIT_PART(email, '@', 2)) AS domain
FROM users
WHERE email IS NOT NULL;
UPDATE users
SET phone = REGEXP_REPLACE(phone, '[^0-9]', '', 'g')
WHERE phone IS NOT NULL;
SELECT
full_name,
SPLIT_PART(full_name, ' ', 1) AS first_name,
SPLIT_PART(full_name, ' ', 2) AS last_name
FROM users_import;
SELECT *
FROM users
WHERE email !~ '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$';
WHERE email LIKE '%@gmail.com'처럼 앞에 % 와일드카드를 붙이면 PostgreSQL은 인덱스를 사용하지 못하고 전체 테이블 스캔(Seq Scan)을 수행합니다. 수백만 건 테이블에서 쿼리가 수초 이상 걸리는 원인이 됩니다.
해결: 도메인 기준 검색이 자주 필요하다면 SPLIT_PART(email, '@', 2)로 도메인을 별도 컬럼에 저장하고 인덱스를 겁니다. 또는 REVERSE(email) LIKE REVERSE('%@gmail.com')처럼 뒤집어서 앞 와일드카드를 제거하는 트릭을 쓸 수 있습니다. 전문 검색이 필요하다면 pg_trgm 확장의 GIN 인덱스를 활용합니다.
날짜/시간 함수 — 기간 계산과 날짜 집계
가입일 기준으로 30일이 지난 사용자를 조회해야 합니다. 월별 신규 가입자를 집계해야 합니다. 두 날짜 사이의 일수를 계산해야 합니다. 날짜 함수가 PostgreSQL과 MySQL에서 다르게 생겼는데 어느 걸 써야 할지 모릅니다. 날짜 함수의 기본 패턴을 익혀두면 이런 요구사항을 쿼리 한 줄로 해결할 수 있습니다.
PostgreSQL vs MySQL 날짜 함수 차이
PostgreSQL과 MySQL은 날짜 함수 문법이 다릅니다. 팀이 두 DB를 혼용하거나 마이그레이션할 때 이 차이를 반드시 확인해야 합니다.
| 기능 | PostgreSQL | MySQL |
|---|---|---|
| 현재 날짜/시간 | NOW(), CURRENT_TIMESTAMP | NOW(), SYSDATE() |
| 날짜 자르기 | DATE_TRUNC('month', ts) | DATE_FORMAT(ts, '%Y-%m-01') |
| 부분 추출 | EXTRACT(YEAR FROM ts) | YEAR(ts), MONTH(ts) |
| 날짜 차이(일) | ts1 - ts2 (정수 반환) | DATEDIFF(ts1, ts2) |
| 날짜 덧셈 | ts + INTERVAL '7 days' | ts + INTERVAL 7 DAY |
| 포맷 변환 | TO_CHAR(ts, 'YYYY-MM-DD') | DATE_FORMAT(ts, '%Y-%m-%d') |
| 경과 기간 | AGE(ts1, ts2) | TIMESTAMPDIFF(MONTH, ts2, ts1) |
| 타임존 변환 | ts AT TIME ZONE 'Asia/Seoul' | CONVERT_TZ(ts, '+00:00', '+09:00') |
현재 날짜/시간 함수
NOW()는 트랜잭션이 시작된 시각을 반환합니다. 트랜잭션 내에서 여러 번 호출해도 동일한 값을 반환합니다. 트랜잭션 내 실제 호출 시각이 필요하다면 CLOCK_TIMESTAMP()를 사용합니다.
SELECT
NOW() AS now_with_tz,
CURRENT_TIMESTAMP AS current_ts,
CURRENT_DATE AS today,
CURRENT_TIME AS now_time,
CLOCK_TIMESTAMP() AS real_now;
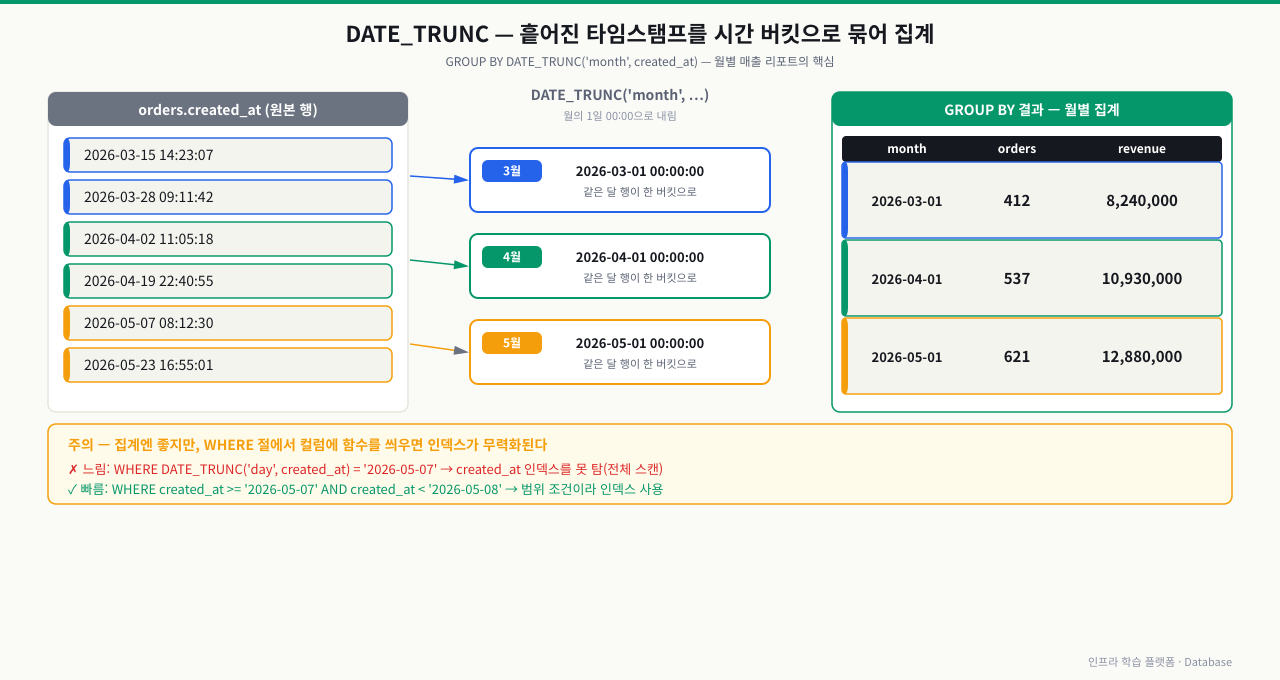
DATE_TRUNC — 시간 단위로 자르기
DATE_TRUNC는 타임스탬프를 지정한 단위의 시작점으로 내림합니다. 월별, 주별, 일별 집계 쿼리에서 GROUP BY와 함께 가장 많이 사용됩니다.
SELECT
DATE_TRUNC('year', NOW()) AS this_year_start,
DATE_TRUNC('month', NOW()) AS this_month_start,
DATE_TRUNC('week', NOW()) AS this_week_start,
DATE_TRUNC('day', NOW()) AS today_start,
DATE_TRUNC('hour', NOW()) AS this_hour_start,
DATE_TRUNC('minute', NOW()) AS this_minute_start;
SELECT
DATE_TRUNC('month', created_at) AS month,
COUNT(*) AS orders,
SUM(amount) AS revenue
FROM orders
WHERE status = 'completed'
GROUP BY DATE_TRUNC('month', created_at)
ORDER BY 1;
 확대
확대
월별 리포트는 실무에서 가장 자주 쓰는 집계입니다. 위 쿼리를 실행해 created_at이 월의 1일 00:00으로 내림되어 같은 달 주문이 한 줄로 묶이는지 확인합니다.
SELECT
DATE_TRUNC('month', created_at) AS month,
COUNT(*) AS orders,
SUM(amount) AS revenue
FROM orders
WHERE status = 'completed'
GROUP BY 1
ORDER BY 1;
month | orders | revenue
---------------------+--------+----------
2026-03-01 00:00:00 | 412 | 8240000
2026-04-01 00:00:00 | 537 | 10930000
2026-05-01 00:00:00 | 621 | 12880000
SELECT DATE_TRUNC('month', created_at) AS month, COUNT(*) AS orders, SUM(amount) AS revenue FROM orders WHERE status = 'completed' GROUP BY 1 ORDER BY 1;- month 열의 값이 모두 '월-01 00:00:00'으로 떨어지는지 본다 — 일/시가 0이 아니면 DATE_TRUNC가 아니라 원본 created_at이 그대로 GROUP BY된 것(월 그룹핑 실패)
- 행 수가 '데이터가 존재하는 개월 수'와 같은지 확인한다. 같은 달이 두 줄로 나뉘면 타임존 차이로 월 경계가 어긋난 것 — created_at을 TIMESTAMPTZ로 두고 AT TIME ZONE을 검토
- orders 합이 WHERE status='completed' 적용 전 전체 건수보다 작아야 정상(필터가 먹은 것). 같으면 WHERE가 무시된 것
- revenue가 NULL로 나오면 amount에 NULL이 섞인 것 — SUM은 NULL을 건너뛰므로 COALESCE(amount,0) 여부를 판단한다
EXTRACT — 날짜/시간 부분 추출
EXTRACT는 타임스탬프에서 특정 필드(연, 월, 일, 시, 요일 등)를 숫자로 추출합니다. DOW는 요일(0=일요일, 6=토요일), EPOCH는 Unix timestamp(초)를 반환합니다.
SELECT
EXTRACT(YEAR FROM NOW()) AS year,
EXTRACT(MONTH FROM NOW()) AS month,
EXTRACT(DAY FROM NOW()) AS day,
EXTRACT(HOUR FROM NOW()) AS hour,
EXTRACT(DOW FROM NOW()) AS day_of_week,
EXTRACT(DOY FROM NOW()) AS day_of_year,
EXTRACT(EPOCH FROM NOW()) AS unix_timestamp;
SELECT
EXTRACT(DOW FROM created_at) AS day_of_week,
TO_CHAR(created_at, 'Day') AS day_name,
COUNT(*) AS order_count
FROM orders
GROUP BY 1, 2
ORDER BY 1;
날짜 계산과 INTERVAL
PostgreSQL에서 날짜 연산은 INTERVAL 타입을 사용합니다. AGE(ts1, ts2)는 두 타임스탬프 사이의 경과 기간을 interval 형식으로 반환하며, AGE(NOW())처럼 인자 하나만 전달하면 현재 시각 기준으로 계산합니다.
SELECT
NOW() + INTERVAL '7 days' AS next_week,
NOW() - INTERVAL '30 days' AS last_month,
NOW() + INTERVAL '1 year 3 months' AS next_period,
CURRENT_DATE + 7 AS also_next_week;
SELECT
AGE('2024-03-15', '2000-06-15') AS age_interval,
AGE(NOW(), created_at) AS account_age
FROM users WHERE id = 1;
SELECT
EXTRACT(DAY FROM AGE('2024-03-15', '2024-01-01')) AS days_diff,
('2024-03-15'::DATE - '2024-01-01'::DATE) AS date_subtraction;
SELECT id, name, created_at
FROM users
WHERE created_at >= NOW() - INTERVAL '30 days'
ORDER BY created_at DESC;
SELECT id, name, last_login
FROM users
WHERE last_login < NOW() - INTERVAL '90 days'
OR last_login IS NULL;
TO_CHAR — 날짜 포맷 변환
TO_CHAR는 숫자와 타임스탬프를 사람이 읽기 좋은 형식의 문자열로 변환합니다. 리포트 출력이나 레이블 생성에 사용합니다.
SELECT
TO_CHAR(NOW(), 'YYYY-MM-DD') AS iso_date,
TO_CHAR(NOW(), 'YYYY년 MM월 DD일') AS korean_date,
TO_CHAR(NOW(), 'HH24:MI:SS') AS time_24h,
TO_CHAR(NOW(), 'YYYY-MM-DD HH24:MI:SS') AS full_datetime,
TO_CHAR(1234567.89, '999,999,999.99') AS number_format;
SELECT
TO_CHAR(created_at, 'YYYY-MM') AS month_label,
COUNT(*) AS order_count,
TO_CHAR(SUM(amount), 'FM999,999,999') AS revenue_formatted
FROM orders
GROUP BY TO_CHAR(created_at, 'YYYY-MM')
ORDER BY 1;
타임존 처리 — TIMESTAMPTZ 사용 권장
TIMESTAMP 타입은 타임존 정보 없이 입력값을 그대로 저장합니다. TIMESTAMPTZ는 UTC로 저장하고 조회 시 세션 타임존으로 변환합니다. 운영 서비스에서는 항상 TIMESTAMPTZ를 사용해야 타임존 문제를 피할 수 있습니다.
SHOW timezone;
SELECT current_setting('TimeZone');
SELECT
NOW() AS utc_now,
NOW() AT TIME ZONE 'Asia/Seoul' AS seoul_time,
NOW() AT TIME ZONE 'America/New_York' AS ny_time;
CREATE TABLE events (
id BIGSERIAL PRIMARY KEY,
title VARCHAR(200) NOT NULL,
event_at TIMESTAMPTZ NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW()
);
INSERT INTO events (title, event_at)
VALUES ('서울 컨퍼런스', '2024-06-15 09:00:00 Asia/Seoul');
SELECT event_at FROM events;
SELECT event_at AT TIME ZONE 'Asia/Seoul' FROM events;
서버가 UTC로 설정된 환경에서 WHERE created_at::date = '2024-03-15'로 한국 시간 기준 3월 15일 데이터를 조회했는데, 한국 시간 자정(00:00~08:59 KST)에 생성된 데이터가 누락되었습니다. UTC 기준으로 이 시간대는 3월 14일이기 때문입니다.
해결: 날짜 비교 시 항상 타임존을 명시합니다. WHERE created_at AT TIME ZONE 'Asia/Seoul' >= '2024-03-15 00:00:00' AND created_at AT TIME ZONE 'Asia/Seoul' < '2024-03-16 00:00:00'처럼 작성하거나, DATE_TRUNC와 타임존 변환을 함께 사용합니다. 컬럼 타입은 항상 TIMESTAMPTZ를 사용하고 애플리케이션 서버의 타임존도 UTC로 통일하는 것이 장기적으로 가장 안전합니다.
월별 매출 리포트는 DATE_TRUNC('month', created_at)으로 월 단위로 집계하고, 신규 가입자 코호트 분석은 가입월과 활동월을 각각 DATE_TRUNC로 잘라서 조인합니다. 예를 들어 "2024년 1월에 가입한 사용자가 각 월에 얼마나 재방문했는가"를 분석하는 코호트 리텐션 쿼리는 DATE_TRUNC('month', signup_at) AS cohort_month와 DATE_TRUNC('month', last_active_at) AS activity_month를 GROUP BY로 집계하는 구조입니다. EXTRACT(EPOCH FROM AGE(activity_month, cohort_month)) / 2592000으로 코호트 이후 몇 달이 지났는지 계산해 피벗 테이블을 만들 수 있습니다.
함수가 값을 바꾸는 순간, 인덱스가 죽는 순간 — WHERE에 함수를 씌우면 벌어지는 4단계
지금까지 TRIM·LOWER·DATE_TRUNC·EXTRACT로 값을 변환해 봤습니다. 그런데 똑같은 함수를 WHERE 절에서 컬럼에 씌우면, 인덱스가 조용히 무력화되어 같은 쿼리가 수십 배 느려집니다. 결과는 맞는데 느리기 때문에 원인을 찾기 어렵습니다. 왜 그런지는, 함수가 컬럼 값을 건드리는 순간부터 옵티마이저가 인덱스를 포기하기까지의 4단계를 따라가면 분명해집니다.
WHERE LOWER(email) = 'a@x.com' (email 컬럼에 B-Tree 인덱스 있음)
│
① 입력 값 — 컬럼 email 의 원본 문자열('A@X.com', 'A@X.COM' …)
│
② 함수 적용 — LOWER()가 값을 변환(대소문자·포맷·형변환·부분추출)
│ 인덱스에 저장된 키는 '원본값'인데, 비교 대상은 '변환된 값'
│
③ 옵티마이저 판단 — 인덱스 키(email)와 LOWER(email)이 서로 다름
│ 원본으로 정렬된 인덱스로는 변환값을 찾아갈 수 없다 → 인덱스 포기
│
④ 실행 — 전체 행을 읽어 행마다 LOWER()를 적용한 뒤 비교(Seq Scan)
▼ 수십만~수백만 행에서 급격히 느려짐
결과 (정답이지만 느림)
대조: WHERE email = 'a@x.com' → ②③ 없이 인덱스로 바로 탐색(Index Scan)
각 단계에서 무슨 일이 일어나고, 인덱스에 무슨 일이 생기나:
| 단계 | 하는 일 | 인덱스에 생기는 일 |
|---|---|---|
| ① 입력 값 | 컬럼의 원본값이 조건에 들어옴 | 아직 문제 없음 — 인덱스는 이 원본값으로 정렬돼 있음 |
| ② 함수 적용 | 값 변환 — LOWER/UPPER(대소문자), DATE(col)·DATE_TRUNC(날짜 절단), AT TIME ZONE(타임존), ::타입·암묵 형변환, SUBSTRING(추출) | 비교 대상이 더는 '원본값'이 아니게 됨 |
| ③ 옵티마이저 판단 | 인덱스 키(원본)와 함수 결과가 불일치함을 확인 | 인덱스로 탐색 불가 → Seq Scan 선택(인덱스 무력화) |
| ④ 실행 | 전체 행을 읽어 각 행에 함수 적용 후 필터 | I/O·CPU가 행 수에 비례해 폭증 |
즉 인덱스가 죽는 곳은 ③이고, 원인은 언제나 ② — 컬럼에 함수·형변환이 씌워지는 순간입니다. 진단은 EXPLAIN으로 합니다: 인덱스가 있는 컬럼을 필터했는데 Seq Scan이 찍히면, 그 컬럼에 함수나 형변환이 씌워졌는지 의심합니다. 실무에서 가장 잦은 세 형태는 WHERE DATE(created_at) = '2024-03-15'(날짜 함수), WHERE LOWER(email) = …(대소문자 정규화), WHERE phone = 01012345678(문자열 컬럼에 숫자 리터럴 → 암묵 형변환)입니다. 해결은 방향을 뒤집는 것입니다 — 함수를 상수 쪽으로 옮겨 범위 조건으로 바꾸거나(created_at >= '2024-03-15' AND created_at < '2024-03-16'), 리터럴 타입을 컬럼에 맞추거나(phone = '01012345678'), 꼭 함수가 필요하면 표현식 인덱스(CREATE INDEX ON users (LOWER(email)))를 만들어 '변환된 값'을 인덱스로 저장합니다. 타임존·포맷 불일치로 생기는 느린 쿼리도 결국 이 "컬럼에 함수를 씌운" 형태로 나타납니다.
심화 — 리포트가 거짓말하는 법: 없는 '월'은 표시되지 않는다
심화: DATE_TRUNC 집계의 빈 구간 함정과 gap filling
앞에서 GROUP BY DATE_TRUNC('month', created_at)로 월별 리포트를 만들었습니다. 이 쿼리는 대부분 잘 동작하지만, 한 가지 조용한 함정이 있습니다 — 데이터가 없는 달은 결과에 아예 나타나지 않습니다. 그리고 이 '없음'이 리포트를 미묘하게 거짓말하게 만듭니다.
GROUP BY는 '매칭되는 행이 하나라도 있는' 그룹에 대해서만 결과 행을 만듭니다. 완료 주문이 0건인 달은 그 버킷에 속한 행이 없으니 그룹 자체가 생기지 않아, 3월과 5월만 있고 4월은 통째로 빠진 결과가 나옵니다. 여기서 두 가지 왜곡이 생깁니다.
- 그래프가 나쁜 달을 감춘다: 선 그래프는 3월 점과 5월 점을 바로 이어, 매출이 0이던 4월을 없던 일처럼 매끄러운 상승선으로 그립니다. 추세가 실제보다 좋아 보입니다.
- 평균이 부풀려진다: '월 평균 매출'을 결과 행으로 AVG 하면, 실제 기간 수(예: 6개월)가 아니라 '결과에 나온 달 수'(예: 5개월)로 나눠 평균이 커집니다. '없음(missing)'과 '0'은 리포트에서 전혀 다른 값입니다.
- 알림이 침묵한다: "이번 달 주문 수"를 조회했는데 0건이면, 0이 아니라 행 없음이 반환돼 "값이 없다"와 "0이다"를 구분 못 하는 코드가 오작동합니다.
해결은 모든 버킷을 먼저 만들어 두고(scaffold) 집계를 붙이는 것입니다. generate_series로 기간의 모든 달을 생성한 뒤, 실제 집계를 LEFT JOIN하고 COALESCE로 없는 달을 0으로 채웁니다.
SELECT g.month,
COALESCE(o.orders, 0) AS orders,
COALESCE(o.revenue, 0) AS revenue
FROM generate_series(
date_trunc('month', DATE '2026-01-01'),
date_trunc('month', DATE '2026-06-01'),
interval '1 month'
) AS g(month)
LEFT JOIN (
SELECT date_trunc('month', created_at) AS month,
count(*) AS orders,
sum(amount) AS revenue
FROM orders
WHERE status = 'completed'
GROUP BY 1
) o ON o.month = g.month
ORDER BY g.month;
덧붙여, 집계함수의 NULL 처리도 함께 알아 둡니다 — SUM/AVG/COUNT(col)은 NULL을 건너뜁니다. 그래서 amount에 NULL이 섞이면 SUM은 무시하지만 AVG(amount)는 NULL이 아닌 행 수로만 나눠 값이 달라집니다. '행 없음 vs 0 vs NULL' 세 가지를 리포트마다 COALESCE로 명시적으로 정해 두는 것이 집계 정확성의 핵심입니다.
상황: 월별 리포트 쿼리는 문제없이 돌고 값도 맞아 보입니다. 그런데 마케팅 중단으로 매출이 0이던 한 달이 표에서 아예 사라졌고, 그래프는 그 앞뒤 달을 바로 이어 부드러운 우상향으로 보입니다. 경영진에 보고한 '월 평균 매출'도 재무팀 수치보다 높게 나옵니다.
원인: GROUP BY DATE_TRUNC('month', created_at)는 그 달에 완료 주문이 하나라도 있어야 행을 만듭니다. 0건인 달은 행 자체가 없어(0도 NULL도 아님) 타임라인에 보이지 않는 구멍이 생깁니다. 선 그래프는 그 구멍을 그냥 이어 붙여 나쁜 달을 감추고, 평균은 '결과에 나온 달 수'로만 나눠 부풀려집니다.
진단: 결과에 나온 달 수와 기간 내 실제 달 수를 비교합니다.
-- 2026년 상반기(6개월)인데 몇 개 달이 나오나
SELECT count(*) AS returned_months
FROM (
SELECT date_trunc('month', created_at) AS m
FROM orders
WHERE status = 'completed'
AND created_at >= '2026-01-01'
AND created_at < '2026-07-01'
GROUP BY 1
) x;
6이 나와야 하는데 5가 나오면 한 달이 통째로 빠진 것입니다. 알고 있는 '매출 0인 달'이 결과에 있는지 직접 확인해도 됩니다.
해결: generate_series로 기간의 모든 달을 만들어 두고 집계를 LEFT JOIN + COALESCE로 붙입니다(위 심화의 쿼리). 그러면 0인 달이 revenue = 0 행으로 나타나 그래프에 제대로 찍히고, 평균도 실제 기간 수(6)로 나뉘어 정확해집니다. 지표마다 '없는 구간을 0으로 볼지 제외할지'를 먼저 정하고, 그 결정을 COALESCE로 쿼리에 명시하세요 — 리포트의 신뢰도는 "있는 데이터"만큼이나 "없는 데이터를 어떻게 표현하는가"에 달려 있습니다.
명령어·구문 빠른 참조
이 모듈에서 다룬 문자열·날짜 함수를 실전 예시와 함께 모았습니다(PostgreSQL 기준).
| 구문/명령 | 용도 | 예 |
|---|---|---|
TRIM / LTRIM / RTRIM | 앞뒤(또는 지정 문자) 제거 | TRIM(' hi '), TRIM(BOTH '0' FROM '00420') |
UPPER / LOWER / INITCAP | 대소문자 정규화 | LOWER(email) (대소문자 무시 비교·유니크) |
SUBSTRING / SUBSTR | 부분 문자열 추출 | SUBSTRING('Hello' FROM 1 FOR 3) |
SPLIT_PART | 구분자 기준 N번째 토큰 | SPLIT_PART(email, '@', 2) (도메인 추출) |
REPLACE | 문자열 치환 | REPLACE(phone, '-', '') |
CONCAT / CONCAT_WS / || | 문자열 연결(NULL 처리 주의) | CONCAT_WS(', ', 시, 구, 동) (NULL 건너뜀) |
REGEXP_REPLACE | 정규식 치환('g'=전체) | REGEXP_REPLACE(phone, '[^0-9]', '', 'g') |
NOW / CURRENT_DATE | 현재 시각/날짜 | WHERE created_at >= NOW() - INTERVAL '30 days' |
DATE_TRUNC | 시간 단위 내림(월·일 집계) | GROUP BY DATE_TRUNC('month', created_at) |
EXTRACT | 연·월·요일·epoch 추출 | EXTRACT(EPOCH FROM (expires_at - NOW())) |
AGE / INTERVAL | 경과 기간·날짜 연산 | AGE(NOW(), created_at), ts + INTERVAL '7 days' |
TO_CHAR | 날짜·숫자 포맷 문자열 | TO_CHAR(created_at, 'YYYY-MM') |
… AT TIME ZONE | 타임존 변환 | created_at AT TIME ZONE 'Asia/Seoul' |
generate_series + COALESCE | 빈 구간 채우기(gap filling) | generate_series(…, interval '1 month') LEFT JOIN … COALESCE(revenue, 0) |
관련 모듈로 더 깊이:
- 정밀한 데이터 타입(숫자·문자·날짜) 선택 기준 — TIMESTAMPTZ 등 날짜/시간 타입 선택이 함수 동작을 좌우하는 이유
- GROUP BY와 집계함수의 효율적인 인덱스 활용 — DATE_TRUNC로 자른 값을 월별로 집계하는 법
- N+1 문제, SELECT *, 인덱스 무력화 안티패턴 방지 — WHERE에서 날짜 컬럼을 함수로 감싸 인덱스를 죽이는 함정
다음 모듈에서는 뷰(View)와 Stored Procedure의 운영 관점 장단점과 언제 사용할지 판단 기준을 다룹니다.