트래픽이 갑자기 늘었는데 DB CPU보다 커넥션 수가 먼저 한계에 닿는 경우가 많습니다. 애플리케이션이 요청마다 새 연결을 만들면 DB는 쿼리보다 연결 관리에 시간을 씁니다. 커넥션 풀을 이해하면 API 서버와 DB 사이의 병목을 안정적으로 제어할 수 있습니다.
커넥션 풀을 설정하는 것과 운영하는 것은 다릅니다. 운영 단계에서는 풀 고갈, 누수(leak), 좀비 연결, 스케일아웃 시 연결 폭발 등 실제 장애 패턴을 다뤄야 합니다. 이 모듈은 모니터링 → 이상 감지 → 근본 원인 분석 → 설정 튜닝의 전체 사이클을 다룹니다.
- 1idle in transaction과 슬로우 쿼리로 인한 커넥션 풀 고갈 패턴을 진단할 수 있다
- 2PgBouncer 모드별 트레이드오프를 이해하고 운영 환경에 맞게 튜닝할 수 있다
- 3connectionTimeout, leakDetection, keepalive 등 HikariCP 고급 설정을 구성할 수 있다
- 4PgBouncer와 HikariCP를 결합한 2계층 풀링 아키텍처를 설계할 수 있다
- 5Prometheus로 풀 메트릭을 모니터링하고 알림을 설계할 수 있다
- 6RDS Proxy로 서버리스/컨테이너 환경의 관리형 풀링을 적용할 수 있다
Connection Pool 운영 & DB 성능 튜닝
2022년 여름, 서울 핀테크 스타트업 C사는 쿠버네티스 HPA가 트래픽 급증에 반응해 API 서버 파드를 5개에서 50개로 늘렸습니다. 10분 뒤 DB 알람이 울렸습니다. max_connections exceeded. 각 파드에는 HikariCP 풀이 20개 연결을 맺도록 설정되어 있었고, 50개 파드 × 20 = 1,000개 연결이 PostgreSQL(max_connections=200)로 몰려들었습니다.
개발팀은 급하게 max_connections=1000으로 올렸습니다. 그리고 10분 뒤 CPU 100%, 전체 처리량 이전의 30%로 추락. 연결 수가 늘수록 느려지는 역설이 발생했습니다.
PgBouncer를 이미 구성해 두었다면? 파드 50개가 PgBouncer로 연결하고, PgBouncer가 실제 DB 연결을 30개로 유지했을 것입니다. 장애 없이 끝났을 상황입니다.
# PgBouncer 설치
sudo apt install -y pgbouncer
# pgbench 초기화 (부하 테스트용 샘플 데이터)
pgbench -i -s 100 -U postgres mydb
# -s 100: scale factor 100 = pgbench_accounts 테이블에 1000만 건
# 기본 부하 테스트 (PgBouncer 없이)
pgbench -U postgres -c 50 -j 4 -T 30 mydb
# -c 50: 클라이언트 50개, -j 4: 스레드 4개, -T 30: 30초
# Prometheus + Grafana 로컬 실행
docker run -d -p 9090:9090 prom/prometheus
docker run -d -p 3000:3000 grafana/grafana
실행 완료 또는 조회 결과가 표시됩니다.
- 활성 연결 수—풀 크기 안에서 커넥션이 재사용되는지 확인합니다.
- 대기 시간—요청이 커넥션을 기다리느라 지연되지 않는지 봅니다.
- DB 한계—max_connections에 여유가 남는지 운영 기준으로 확인합니다.
# /etc/pgbouncer/pgbouncer.ini 기본 설정
[databases]
mydb = host=127.0.0.1 port=5432 dbname=mydb
[pgbouncer]
listen_port = 6432
listen_addr = 0.0.0.0
auth_type = scram-sha-256
auth_file = /etc/pgbouncer/userlist.txt
pool_mode = transaction
max_client_conn = 2000
default_pool_size = 25
min_pool_size = 5
reserve_pool_size = 5
reserve_pool_timeout = 3
# 타임아웃 설정 (장애 방지 핵심)
server_idle_timeout = 600
client_idle_timeout = 0
idle_transaction_timeout = 30 # 30초 이상 idle in transaction → 강제 해제
query_timeout = 0 # 0 = 무제한 (슬로우 쿼리 제어는 DB 측에서)
client_login_timeout = 60
# 연결 상태 모니터링
stats_period = 60
log_connections = 0
log_disconnections = 0
log_pooler_errors = 1
요청 하나가 커넥션을 빌리고 돌려주기까지 — 풀 대여·반납 생애 6단계
dataSource.getConnection()을 호출하면 대부분 즉시 커넥션이 돌아오는데, 이때 새 TCP 연결이 맺어지는 게 아닙니다 — 풀에 미리 만들어 둔 커넥션을 빌려오는 것입니다. 더 헷갈리는 건 close()인데, 이건 연결을 실제로 끊는 게 아니라 풀에 돌려주는 반납입니다. 이 대여-반납 생애를 단계로 알면 Connection is not available 타임아웃이나 커넥션 누수가 이 흐름의 어디서 깨진 것인지 짚어낼 수 있습니다.
[앱] Connection conn = dataSource.getConnection();
│
① 유휴(idle) 커넥션 탐색 → 풀에 놀고 있는 커넥션이 있으면 즉시 대여(재사용)
│
② 없으면 분기 → 현재 풀 크기가 max 미만: 새 물리 커넥션 생성해 대여
│ 현재 풀 크기가 max: 대기 큐에서 반납을 기다림
│ (connectionTimeout까지 못 받으면 예외)
│
③ (선택) 대여 전 검증 → keepalive·SELECT 1로 죽은 커넥션을 걸러냄
│
④ 쿼리 실행 → 이 커넥션은 'active(사용 중)'로 표시, 풀에서 빠져 있음
│
⑤ conn.close() → 물리 종료가 아니라 풀로 반납 → 다시 'idle'
│
⑥ 유지·정리 → 오래 놀면 idleTimeout으로 축소(minimumIdle까지),
│ maxLifetime 지나면 폐기 후 새로 생성
▼
[다음 요청] 다시 ①로 — 비싼 TCP·인증·세션 초기화를 건너뛰고 재사용
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 대여 | 유휴 커넥션이 있으면 바로 빌려줌(재사용) | 정상 경로 — 대여가 즉시면 풀이 건강한 것 |
| ② 신규/대기 | max 미만이면 생성, max면 반납을 대기 | max까지 다 active인데 반납이 없으면 대기 → Connection is not available, request timed out |
| ③ 검증 | 죽은 커넥션을 대여 전에 걸러냄 | 검증을 안 걸면 방화벽·DB가 끊은 좀비 커넥션을 빌려 Connection is closed |
| ④ 실행 | 커넥션이 active로 점유됨 | 슬로우 쿼리가 오래 점유하면 유휴가 마르고 ②의 대기가 쌓임(풀 고갈) |
| ⑤ 반납 | close()는 물리 종료가 아닌 풀 반납 | 코드가 close()를 빠뜨리면 영원히 active로 남음 → 커넥션 누수(leak) |
| ⑥ 정리 | idleTimeout 축소·maxLifetime 재생성 | maxLifetime이 DB의 유휴 타임아웃보다 길면 DB가 먼저 끊어 Connection reset |
핵심은 close()가 연결 종료가 아니라 반납이고, 동시에 열리는 실제 커넥션 수는 maximumPoolSize로 묶인다는 것입니다. 그래서 풀 문제는 늘 이 생애의 특정 단계로 환원됩니다 — SHOW POOLS의 cl_waiting이 쌓이면 ②(대여 대기), pg_stat_activity에 idle in transaction이 쌓이면 ⑤(트랜잭션을 연 채 반납), 간헐적 Connection is closed는 ③·⑥(검증·수명)입니다. 아래에서 다룰 '풀 고갈 3가지 패턴'은 모두 ④가 길어지거나 ⑤가 실패해 ②의 대기가 무한정 쌓이는 같은 뿌리에서 나옵니다.
풀 고갈의 3가지 패턴과 진단
트래픽이 갑자기 몰렸을 때 DB 연결이 부족해지면서 요청이 대기 상태에 들어갑니다. 서비스는 DB가 느린 게 아닌데 응답이 없습니다. 커넥션 풀이 고갈된 겁니다. 원인을 찾으려면 어디서 연결이 새고 있는지 진단할 수 있어야 합니다. 풀 고갈에는 반복되는 패턴이 있고, 패턴을 알면 빠르게 원인을 좁힐 수 있습니다.
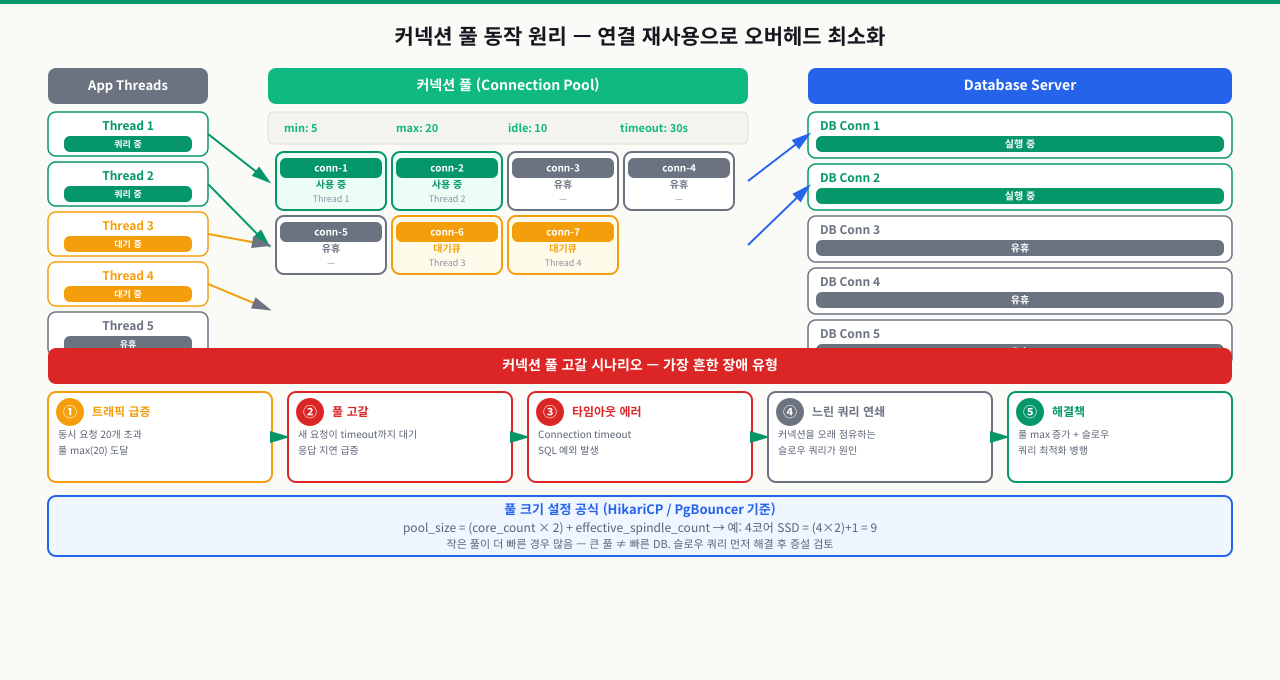 확대
확대
패턴 1: idle in transaction 누적
가장 흔한 풀 고갈 원인. 애플리케이션 코드에서 트랜잭션을 열고 예외 발생 시 COMMIT/ROLLBACK 없이 연결이 풀로 반환되면, DB 서버에는 해당 연결이 'idle in transaction' 상태로 남습니다. 이 연결은 PgBouncer가 회수할 수 없어 점진적으로 쌓입니다.
풀이 마르는 가장 흔한 원인을 직접 관찰합니다. 먼저 상태별 연결 수를 집계해 'idle in transaction'이 쌓였는지 보고, 오래 묶인 세션을 추적한 뒤 (임시로) 종료합니다.
-- 1) 상태별 연결 수 — idle in transaction이 많으면 누수 신호
SELECT state, count(*) FROM pg_stat_activity GROUP BY state;
-- 2) 오래 idle in transaction인 세션 추적
SELECT pid, application_name,
now() - state_change AS idle_duration,
LEFT(query, 60) AS last_query
FROM pg_stat_activity
WHERE state = 'idle in transaction'
ORDER BY idle_duration DESC;
-- 3) 5분 이상 묶인 세션 강제 종료(임시 조치)
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE state = 'idle in transaction'
AND now() - state_change > INTERVAL '5 minutes';
state | count
----------------------+-------
active | 3
idle | 12
idle in transaction | 47 ← 비정상 누적(풀 고갈 임박)
SELECT state, count(*) FROM pg_stat_activity GROUP BY state;- 상태별 집계에서 'idle in transaction' 수를 먼저 본다 — active보다 훨씬 많거나 계속 증가하면 트랜잭션을 열고 COMMIT/ROLLBACK 없이 반환하는 코드가 있는 것
- idle_duration이 수 분~수십 분인 세션이 보이면 그 application_name/last_query가 범인 — 해당 코드 경로의 트랜잭션 종료 누락을 찾는다
- pg_terminate_backend는 임시 조치일 뿐 — 종료해도 같은 코드가 다시 쌓는다. 애플리케이션의 트랜잭션 관리(try/finally, 컨텍스트 매니저) 수정이 근본 해결
- idle in transaction은 PgBouncer가 회수하지 못한다 — DB의 idle_in_transaction_session_timeout 설정도 함께 거는지 점검한다
// 나쁜 예: 예외 발생 시 트랜잭션 미처리
public void processOrder(Long orderId) {
Connection conn = dataSource.getConnection();
conn.setAutoCommit(false);
// ... 쿼리 실행 ...
// 예외 발생 시 conn.rollback() 없이 메서드 종료
// → 연결이 풀에 반환되지만 DB에는 idle in transaction으로 남음
conn.commit();
}
// 좋은 예: try-finally 또는 try-with-resources로 반드시 처리
public void processOrder(Long orderId) {
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(false);
try {
// ... 쿼리 실행 ...
conn.commit();
} catch (Exception e) {
conn.rollback(); // 반드시 롤백
throw e;
}
} // 자동으로 conn.close() → 풀에 반환
}
패턴 2: 슬로우 쿼리의 연결 점유
쿼리 하나가 30초 걸리면, 그 연결은 30초 동안 풀에서 사라집니다. 풀 사이즈가 10이고 모두 느린 쿼리를 실행 중이면 풀은 고갈됩니다.
-- 현재 30초 이상 실행 중인 쿼리 확인
SELECT
pid,
now() - query_start AS duration,
state,
wait_event_type,
wait_event,
LEFT(query, 100) AS query_snippet
FROM pg_stat_activity
WHERE state = 'active'
AND now() - query_start > INTERVAL '30 seconds'
ORDER BY duration DESC;
-- HikariCP에서 연결 점유 시간 분포 확인 (Prometheus 쿼리)
-- histogram_quantile(0.99, hikaricp_connection_usage_nanos_bucket) / 1e9
-- → p99 연결 점유 시간 (초)
패턴 3: 연결 누수 (Connection Leak)
연결을 가져갔지만 반환하지 않는 코드 버그. 조용히 축적되다가 어느 날 풀이 고갈됩니다.
# HikariCP 연결 누수 감지 설정 (application.yml)
spring:
datasource:
hikari:
leak-detection-threshold: 5000 # 5초 이상 반환 안 된 연결 경고
# 로그 출력 예:
# Connection leak detection triggered for com.zaxxer.hikari.pool.ProxyConnection
# Stack trace of leaked connection:
# at com.example.service.OrderService.processOrder(OrderService.java:47)
# PgBouncer에서 풀 상태 실시간 확인
# PgBouncer 관리 DB 접속 (포트 6432, 데이터베이스명 'pgbouncer')
psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer
SHOW POOLS;
-- database | user | cl_active | cl_waiting | sv_active | sv_idle | sv_used | sv_tested | sv_login | maxwait
-- mydb | app | 23 | 7 | 20 | 5 | 0 | 0 | 0 | 2
-- cl_waiting=7: 대기 중인 클라이언트 (풀 부족 신호)
-- maxwait=2: 최대 대기 시간(초)
SHOW STATS;
-- total_query_count, total_query_time, avg_query_time 등
SHOW CLIENTS;
-- 연결된 클라이언트 목록과 상태
HikariCP 고급 설정 — 프로덕션 튜닝
앱 인스턴스를 늘렸는데 DB에서 too many connections 오류가 납니다. 인스턴스별로 커넥션 풀을 독립적으로 설정하다 보니 전체 DB 연결 수가 max_connections를 초과했습니다. 풀 사이즈를 무조건 크게 잡으면 DB가 연결 관리 오버헤드로 느려집니다. HikariCP 설정은 CPU 코어 수, 인스턴스 수, DB 설정을 함께 고려해야 합니다. 계산 공식과 주요 파라미터를 알면 환경에 맞는 값을 산출할 수 있습니다.
풀 사이즈 계산과 멀티 인스턴스 설계
단일 인스턴스 기준 공식: connections = (CPU 코어 수 × 2) + 유효 디스크 수
멀티 인스턴스 환경: 총 DB 연결 = 인스턴스 수 × 풀 사이즈 ≤ max_connections × 0.8
# Spring Boot application.yml — 프로덕션 권장 설정
spring:
datasource:
url: jdbc:postgresql://pgbouncer-host:6432/mydb?ApplicationName=order-service
username: ${DB_USER}
password: ${DB_PASSWORD}
hikari:
# 풀 크기: (4코어 × 2) + 1 SSD = 9. 여유분 포함해 10
maximum-pool-size: 10
minimum-idle: 3 # 최소 유지 유휴 연결
# 타임아웃 설정 (ms 단위)
connection-timeout: 3000 # 3초: 풀에서 연결 못 받으면 즉시 실패 (기본 30초는 너무 김)
idle-timeout: 600000 # 10분: 유휴 연결 제거 (PgBouncer server_idle_timeout보다 짧게)
max-lifetime: 1800000 # 30분: 연결 최대 수명 (DB의 wait_timeout - 30초)
keepalive-time: 60000 # 1분: 유휴 연결 유효성 확인 (방화벽 끊김 방지)
# 연결 유효성 검사
connection-test-query: SELECT 1
validation-timeout: 2000 # 유효성 검사 타임아웃
# 누수 감지 (개발/스테이징)
leak-detection-threshold: 10000 # 10초 이상 반환 안 된 연결 경고
pool-name: OrderService-HikariPool
# Prometheus 메트릭 노출
register-mbeans: true
connection-timeout 설정의 중요성
기본값 30초는 대부분의 상황에서 너무 깁니다. 풀이 고갈됐을 때 30초 동안 기다리는 요청들이 쌓이면 HTTP 타임아웃, 상위 서비스 연쇄 장애로 이어집니다.
// connection-timeout = 3000 (3초) 설정 시 동작
// 풀에 연결이 없으면 3초 후 즉시 SQLException
// → 빠른 실패(fail-fast)로 상위 서비스에 즉시 에러 전파
// → Circuit Breaker가 빠르게 발동해 연쇄 장애 방지
// 응용: Circuit Breaker와 함께 사용
@CircuitBreaker(name = "database", fallbackMethod = "fallbackGetOrder")
public Order getOrder(Long orderId) {
return orderRepository.findById(orderId).orElseThrow();
}
public Order fallbackGetOrder(Long orderId, Exception ex) {
log.error("DB 연결 실패, 캐시에서 조회: {}", orderId);
return orderCache.get(orderId);
}
max-lifetime과 DB wait_timeout 정합성
DB 서버의 wait_timeout(MySQL) 또는 tcp_keepalives_idle(PostgreSQL)보다 HikariCP의 max-lifetime이 길면, DB가 연결을 먼저 끊어버려 "Connection is closed" 에러가 발생합니다.
-- MySQL: wait_timeout 확인
SHOW VARIABLES LIKE 'wait_timeout'; -- 기본 28800초 (8시간)
-- PostgreSQL: 연결 유지 설정 확인
SHOW tcp_keepalives_idle;
SHOW tcp_keepalives_interval;
# 규칙: max-lifetime < DB wait_timeout - 30초
# MySQL wait_timeout = 28800초(8시간)이면
# max-lifetime = 28770000ms (8시간 - 30초)
# 실무 권장: 30분으로 설정 (대부분의 DB 설정보다 짧음)
max-lifetime: 1800000 # 30분
2계층 풀링 아키텍처 & 모니터링
앱 인스턴스가 10개로 늘어났고 각 인스턴스 HikariCP 풀 크기가 10입니다. 이론상 DB에 최대 100개의 연결이 동시에 열릴 수 있습니다. PostgreSQL의 max_connections가 100이라면 가끔 연결 거부가 발생합니다. PgBouncer를 앞에 두면 실제 DB 연결을 25개로 제한하면서 앱 단의 100개 연결 요청을 다중화할 수 있습니다. 2계층 풀링은 대규모 앱 배포에서 DB 연결 수를 통제하는 표준 패턴입니다.
PgBouncer + HikariCP 2계층 아키텍처
앱 인스턴스 1 [HikariCP: 10개]
앱 인스턴스 2 [HikariCP: 10개] → PgBouncer [실제 DB 연결: 25개] → PostgreSQL
앱 인스턴스 3 [HikariCP: 10개]
...
앱 인스턴스 N [HikariCP: 10개]
클라이언트 연결: N × 10개 → DB 실제 연결: 25개 (고정)
HikariCP는 각 JVM 인스턴스 내에서 빠른 연결 재사용을 처리하고, PgBouncer는 여러 인스턴스 전체의 DB 연결 총량을 통제합니다. 쿠버네티스에서 파드가 100개로 늘어나도 DB 연결은 25개로 유지됩니다.
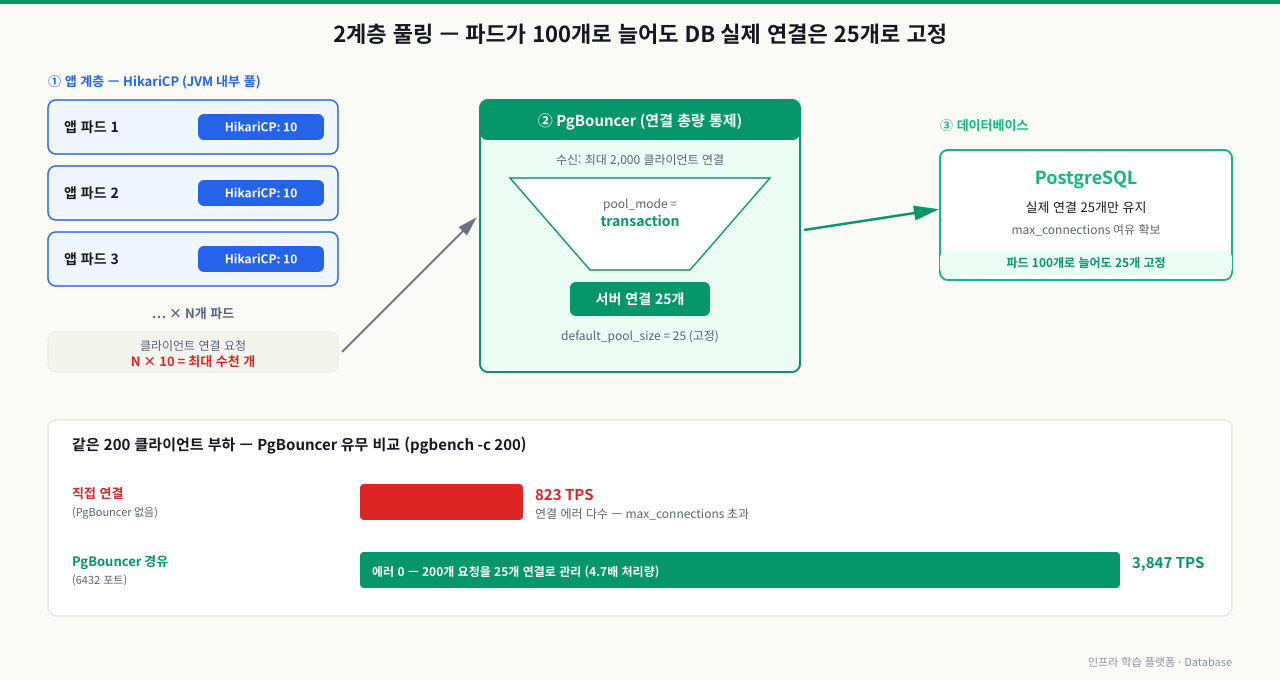 확대
확대
# PgBouncer 부하 테스트 비교
# PgBouncer 없이 (PostgreSQL 직접 연결)
pgbench -U postgres -h postgres-host -p 5432 \
-c 200 -j 8 -T 60 mydb
# 결과: TPS=823, 연결 에러 다수 (max_connections 초과)
# PgBouncer를 통한 연결
pgbench -U postgres -h pgbouncer-host -p 6432 \
-c 200 -j 8 -T 60 mydb
# 결과: TPS=3847, 에러 0 (PgBouncer가 200개를 25개로 관리)
Prometheus 기반 모니터링 설정
# docker-compose.yml — PgBouncer exporter 포함
version: '3.8'
services:
pgbouncer-exporter:
image: prometheuscommunity/pgbouncer-exporter:latest
environment:
PGBOUNCER_EXPORTER_HOST: pgbouncer
PGBOUNCER_EXPORTER_PORT: 6432
PGBOUNCER_EXPORTER_USER: pgbouncer
PGBOUNCER_EXPORTER_PASSWORD: ${PGBOUNCER_ADMIN_PASS}
ports:
- "9127:9127"
# Prometheus 알림 규칙 (alert.rules.yml)
groups:
- name: connection_pool
rules:
- alert: HikariPoolPendingHigh
expr: hikaricp_connections_pending > 3
for: 1m
labels:
severity: warning
annotations:
summary: "HikariCP 풀 대기 세션 증가"
description: "{{ $labels.pool }} 풀에서 {{ $value }}개 요청이 연결 대기 중"
- alert: PgBouncerClientWaiting
expr: pgbouncer_stats_clients_waiting > 10
for: 30s
labels:
severity: critical
annotations:
summary: "PgBouncer 클라이언트 대기 급증"
- alert: IdleInTransactionSpike
expr: |
pg_stat_activity_count{state="idle in transaction"} > 20
for: 2m
labels:
severity: warning
annotations:
summary: "idle in transaction 세션 급증 — 연결 누수 가능성"
-- 핵심 모니터링 쿼리 (정기 실행 권장)
-- 1. 연결 상태 분포
SELECT state, count(*) AS cnt
FROM pg_stat_activity
WHERE datname = 'mydb'
GROUP BY state
ORDER BY cnt DESC;
-- 2. 애플리케이션별 연결 수
SELECT application_name, count(*) AS connections
FROM pg_stat_activity
WHERE datname = 'mydb'
GROUP BY application_name
ORDER BY connections DESC;
-- 3. 가장 오래 실행 중인 쿼리 TOP 5
SELECT
pid,
ROUND(EXTRACT(EPOCH FROM (now() - query_start))::NUMERIC, 1) AS seconds,
state,
LEFT(query, 100) AS query
FROM pg_stat_activity
WHERE state IN ('active', 'idle in transaction')
ORDER BY query_start ASC
LIMIT 5;
실습 — 풀 고갈 재현 및 복구
# Step 1: 인위적으로 풀 고갈 상황 재현
# PgBouncer default_pool_size = 5로 임시 축소
psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer -c "
SET default_pool_size = 5;
RELOAD;
"
# Step 2: 동시 접속 50개로 부하 생성
pgbench -h 127.0.0.1 -p 6432 -U app -c 50 -j 4 -T 30 mydb &
# Step 3: 실시간 상태 모니터링 (다른 터미널)
watch -n 1 'psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer -c "SHOW POOLS;"'
-- SHOW POOLS 출력 (풀 고갈 상태)
database | user | cl_active | cl_waiting | sv_active | sv_idle | maxwait
mydb | app | 5 | 45 | 5 | 0 | 8
-- cl_waiting=45: 45개 클라이언트가 연결 대기
-- maxwait=8: 최대 8초 대기 중
# Step 4: 풀 사이즈 복구
psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer -c "
SET default_pool_size = 25;
RELOAD;
"
# 복구 후 SHOW POOLS
# cl_waiting=0, sv_active=25, maxwait=0
# Step 5: idle in transaction 시뮬레이션
psql -h 127.0.0.1 -p 6432 -U app mydb -c "BEGIN;"
# 위 세션을 그대로 두고 다른 터미널에서 30초 후 확인
psql -U postgres -c "
SELECT pid, state, now() - state_change AS idle_time
FROM pg_stat_activity
WHERE state = 'idle in transaction';
"
# PgBouncer의 idle_transaction_timeout=30 설정으로 자동 해제됨
상황: 갑자기 API 서버 전체에서 이 에러가 터지기 시작합니다. 풀 크기는 충분해 보이는데 모든 연결이 고갈됩니다.
원인 분석: 트랜잭션을 열어둔 채 반환하지 않은 연결이 풀을 고갈시킵니다.
-- 1. 현재 DB 연결 상태 확인
SELECT state, count(*)
FROM pg_stat_activity
WHERE datname = 'mydb'
GROUP BY state;
-- 결과:
-- idle in transaction | 47 ← 범인 발견
-- active | 2
-- idle | 1
47개의 'idle in transaction' 세션이 모든 풀 연결을 점유하고 있었습니다. 배포된 코드에서 특정 API 핸들러가 트랜잭션을 열고 외부 HTTP API를 호출한 뒤 타임아웃이 나도 롤백 없이 반환되는 버그가 있었습니다.
// 버그 있는 코드
@Transactional
public void checkout(Long userId) {
Order order = orderRepo.save(new Order(userId)); // 트랜잭션 시작
paymentApi.charge(order.getId()); // 외부 API — 타임아웃 발생
// @Transactional이 예외를 잡아 롤백하려 하지만
// 외부 API 호출에서 RuntimeException이 아닌 checked exception이면
// 기본 설정에서 롤백이 일어나지 않음
}
// 수정된 코드
@Transactional(rollbackFor = Exception.class)
public void checkout(Long userId) {
Order order = orderRepo.save(new Order(userId));
try {
paymentApi.charge(order.getId());
} catch (Exception e) {
throw new RuntimeException("결제 실패", e); // 롤백 트리거
}
}
즉시 복구: 장시간 열려있는 트랜잭션을 강제 종료해 풀을 되살립니다.
-- 5분 이상 idle in transaction 강제 종료
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE state = 'idle in transaction'
AND now() - state_change > INTERVAL '5 minutes';
재발 방지: PgBouncer idle_transaction_timeout = 30 설정으로 30초 이상 idle in transaction은 자동 해제. HikariCP leak-detection-threshold = 10000 (10초)으로 누수 즉시 로그 출력.
상황: 애플리케이션 재배포 후 DB 연결이 전혀 되지 않습니다. PgBouncer 로그에 인증 실패가 반복됩니다. PostgreSQL에 직접 접속은 성공합니다.
원인: PgBouncer는 auth_file(userlist.txt)에 저장된 자체 사용자 목록으로 먼저 인증합니다. PostgreSQL 비밀번호를 변경했는데 PgBouncer의 userlist.txt를 업데이트하지 않은 경우, 또는 auth_type = scram-sha-256으로 변경했는데 userlist.txt가 md5 해시만 가진 경우에 발생합니다.
# PgBouncer userlist.txt 형식 확인
cat /etc/pgbouncer/userlist.txt
# "app" "md5해시값" ← md5 방식
# "app" "SCRAM-SHA-256$......" ← scram 방식
# PostgreSQL에서 SCRAM 해시 추출
psql -U postgres -c "
SELECT usename, passwd
FROM pg_shadow
WHERE usename = 'app';
"
# passwd 값을 userlist.txt에 그대로 복사
# 또는 auth_query 방식으로 PgBouncer가 PostgreSQL에 직접 인증을 위임
# pgbouncer.ini에 추가:
# auth_query = SELECT usename, passwd FROM pg_shadow WHERE usename=$1
# auth_user = pgbouncer_auth # pg_shadow 읽기 권한을 가진 전용 계정
# 설정 재로드
sudo systemctl reload pgbouncer
# 또는
psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer -c "RELOAD;"
교훈: 비밀번호 순환(rotation) 정책이 있는 환경에서는 PgBouncer auth_query 방식이 안전합니다. userlist.txt를 수동으로 관리하면 비밀번호 변경 때마다 PgBouncer도 업데이트해야 합니다.
심화 — 풀링 효율과 세션 상태는 맞바꿔진다
심화: PgBouncer pool_mode의 트레이드오프 — transaction 모드가 조용히 깨뜨리는 것
스케일아웃 환경에서 실제 DB 연결을 낮게 유지하려면 PgBouncer를 대개 transaction 모드로 씁니다. 그런데 이 모드는 공짜가 아닙니다. pool_mode마다 무엇이 보존되고 무엇이 깨지는지를 알아야 이상한 간헐 오류를 예방할 수 있습니다.
- session 모드: 클라이언트 연결이 하나의 서버 연결을 세션 내내 독점합니다. 세션 상태(서버 사이드 prepared statement,
SETGUC, 임시 테이블, advisory lock,LISTEN/NOTIFY)가 모두 보존되지만, 서버 연결이 클라이언트만큼 필요해 풀링 효율이 낮습니다. - transaction 모드: 서버 연결을 트랜잭션 단위로 반납·재배정합니다. 적은 서버 연결로 많은 클라이언트를 다중화하는 핵심 모드지만, 트랜잭션 경계를 넘어 유지돼야 하는 세션 상태는 다음 트랜잭션에서 다른 서버 연결을 만나 유실·충돌합니다.
- statement 모드: 문장 단위로 반납하므로 여러 문장을 묶는 트랜잭션 자체를 쓸 수 없습니다.
핵심은 '적은 서버 연결(풀링 효율)'과 '세션 상태 보존'이 맞바꿔진다는 것입니다. transaction 모드를 택했다면 애플리케이션과 드라이버가 트랜잭션 밖 세션 상태에 의존하지 않도록 맞춰야 합니다 — 서버 사이드 prepared statement 끄기, 세션 GUC 대신 트랜잭션 로컬 설정 사용 등.
상황: 직접 연결에서는 멀쩡하던 앱을 PgBouncer transaction 모드 뒤에 붙였더니 간헐적으로 이 오류가 납니다. 재시도하면 통과되기도 하고, 트래픽이 오를수록 빈도가 올라갑니다.
원인: 드라이버(예: pgjdbc)가 같은 쿼리를 반복 실행하면서 서버 사이드 prepared statement로 PREPARE 후 재사용하고 있었습니다. 그런데 transaction 모드는 트랜잭션이 끝날 때마다 서버 연결을 풀로 반납하고 다음 트랜잭션엔 다른 서버 연결을 배정합니다. 이전 연결에서 PREPARE된 구문이 새로 배정된 연결에는 존재하지 않아 EXECUTE가 실패합니다. 연결 재배정이 잦아지는 트래픽 피크에 더 자주 터집니다.
진단: PgBouncer pool_mode = transaction인지, 드라이버가 서버 사이드 prepared statement를 쓰는지 확인합니다(pgjdbc는 prepareThreshold 기본 5회 이후 서버 prepared 사용). PgBouncer 로그와 애플리케이션 예외의 구문 이름이 일치하는지 대조합니다.
해결: 세 갈래입니다. (1) 드라이버에서 서버 사이드 prepared를 끕니다(pgjdbc prepareThreshold=0). (2) PgBouncer 1.21+라면 max_prepared_statements를 켜 프로토콜 레벨에서 prepared statement를 지원하게 합니다. (3) 서버 사이드 prepared나 세션 상태가 꼭 필요한 워크로드는 session 모드(또는 별도 풀)로 분리합니다. 근본 원칙은 transaction 모드에선 트랜잭션 밖 세션 상태에 의존하지 않는 것입니다(트랜잭션 격리 수준(Isolation Level)과 이상 현상 제어).
실무 시나리오: 쿠버네티스 스케일아웃 대응 DB 연결 설계
쿠버네티스 HPA가 부하에 따라 파드 수를 3~50개로 조정하는 환경에서 DB 연결 설계.
잘못된 설계 (흔한 실수):
- 각 파드 HikariCP
maximum-pool-size: 20 - 50파드 × 20 = 1,000 연결 → PostgreSQL
max_connections: 200초과 → 장애
올바른 설계:
- PgBouncer를 DB 앞에 배치 (Deployment로 2개 레플리카, 각각
max_client_conn: 2000,default_pool_size: 15) - 파드는 PgBouncer에 연결, HikariCP
maximum-pool-size: 5(파드 내 빠른 재사용만) - 50파드 × 5 = 250개 → PgBouncer 실제 DB 연결: 30개 (고정)
- PostgreSQL
max_connections: 100— 여유분 충분
모니터링 체계:
hikaricp_connections_pending> 2이면 PgBouncer pool_size 검토pg_stat_activity idle in transaction> 10이면 코드 버그 의심- 매주
pg_stat_statements로 슬로우 쿼리 TOP 10 리뷰
면접 포인트: "max_connections를 늘리면 되지 않나요?"에 대한 답: CPU 코어 수 이상의 연결은 컨텍스트 스위칭 비용으로 성능 역전이 발생합니다. 올바른 접근은 PgBouncer로 실제 DB 연결을 최소로 유지하면서 애플리케이션 쪽 동시 요청은 무제한에 가깝게 처리하는 것입니다.
관련 모듈로 더 깊이:
- 실시간 DB 모니터링 및 슬로우 쿼리 슬랙 알림 설정 —
hikaricp_connections_pending,pg_stat_activity등 풀 상태를 관측하는 법 - 트랜잭션 격리 수준(Isolation Level)과 이상 현상 제어 —
idle in transaction이 쌓이는 트랜잭션 관리 문제의 근본 배경 - 3-Tier, MSA, CQRS 아키텍처에서의 최적의 DB 역할 분담 — HPA로 파드가 늘어나는 환경에서 DB 연결을 설계하는 아키텍처 관점
명령어·구문 빠른 참조
이 모듈에서 다룬 커넥션 풀 진단 쿼리와 PgBouncer 관리 명령을 실전 옵션과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
SELECT state, count(*) FROM pg_stat_activity GROUP BY state | 연결 상태 분포(풀 고갈 진단) | idle in transaction이 쌓였는지 확인 |
... WHERE state='idle in transaction' ORDER BY idle_duration | 오래 묶인 세션 추적 | now() - state_change AS idle_duration |
pg_terminate_backend(pid) | 문제 세션 강제 종료(임시 조치) | 5분 이상 idle in transaction 세션 정리 |
SHOW max_connections | DB 최대 연결 수 확인 | 총 풀 크기 ≤ max_connections × 0.8 |
| PgBouncer 관리 접속 | 풀러 상태 조회용 접속 | psql -h 127.0.0.1 -p 6432 -U pgbouncer pgbouncer |
SHOW POOLS (PgBouncer) | 클라이언트·서버 연결·대기 확인 | cl_waiting·maxwait로 풀 부족 판단 |
SHOW STATS / SHOW CLIENTS (PgBouncer) | 쿼리 통계·클라이언트 목록 | total_query_time, avg_query_time |
SET default_pool_size=...; RELOAD; (PgBouncer) | 풀 크기 조정·설정 재적용 | 고갈 시 25로 복구 후 RELOAD |
SHOW VARIABLES LIKE 'wait_timeout' (MySQL) | DB 연결 수명 확인 | max-lifetime을 이 값보다 짧게(-30초) |
SHOW tcp_keepalives_idle (PostgreSQL) | keepalive 설정 확인 | 방화벽 끊김·좀비 연결 점검 |
pgbench -c N -j M -T S | 커넥션 풀 부하 테스트 | pgbench -c 200 -j 8 -T 60 mydb(직접 vs PgBouncer TPS) |
SELECT usename, passwd FROM pg_shadow WHERE usename='app' | SCRAM 해시 추출(userlist 갱신) | PgBouncer 인증 실패 복구 |
여기까지 Database 트랙의 모든 모듈을 완료했습니다. SQL 기초부터 트랜잭션, 인덱스, 쿼리 최적화, NoSQL, 고가용성, 커넥션 풀까지 — 실무 백엔드 개발자가 DB와 직접 마주치는 거의 모든 상황을 다뤘습니다.