PostgreSQL은 표준 SQL만 쓰는 DB가 아닙니다. JSONB, UPSERT, 부분 인덱스, 확장 기능을 알면 애플리케이션 코드를 크게 줄일 수 있습니다. PostgreSQL다운 기능을 이해하면 복잡한 요구사항을 더 단순한 쿼리로 해결할 수 있습니다.
PostgreSQL의 고급 데이터 타입을 활용하면 MongoDB 없이 JSONB로 반정형 데이터를 처리하고, Elasticsearch 없이 전문검색을 구현할 수 있습니다. 이 모듈에서는 실무에서 가장 자주 쓰이는 PostgreSQL 고유 기능들을 코드 예시와 함께 배웁니다.
- 1JSONB와 JSON의 저장 방식과 인덱스 차이를 이해하고 올바르게 선택할 수 있다
- 2JSONB 조회 연산자와 GIN 인덱스로 반정형 데이터를 빠르게 조회할 수 있다
- 3배열 타입과 배열 연산을 활용해 데이터를 다룰 수 있다
- 4tsvector, tsquery, GIN 인덱스로 전문검색을 구현할 수 있다
- 5ON CONFLICT DO UPDATE 패턴으로 UPSERT를 구현할 수 있다
PostgreSQL 실무 기능 — JSONB, 전문검색, 배열 타입
PostgreSQL은 단순한 관계형 데이터베이스를 넘어 반정형 데이터, 전문검색, 배열 타입, 지오데이터 등 다양한 기능을 기본으로 제공합니다. 이를 잘 활용하면 별도의 NoSQL 데이터베이스 없이도 복잡한 요구사항을 처리할 수 있습니다.
JSONB — PostgreSQL에서 반정형 데이터 다루기
API 응답을 그대로 DB에 저장해야 합니다. 외부 서비스 webhook인데 필드 구조가 버전마다 다릅니다. 정규화 테이블로 만들기에는 스키마가 너무 유동적입니다. 별도의 NoSQL 시스템을 추가하기에는 인프라가 부담됩니다. PostgreSQL의 JSONB는 관계형 DB 안에서 반정형 데이터를 처리할 수 있는 실용적인 선택지입니다. 언제 써야 하고 언제 쓰면 안 되는지를 알면 올바르게 활용할 수 있습니다.
 확대
확대
JSONB를 쓰면 안 되는 경우
JSONB는 강력하지만 남용하면 오히려 독이 됩니다. 다음 경우에는 JSONB 대신 일반 컬럼을 사용하세요.
- 필드가 고정적이고 모든 행에서 동일한 구조를 가질 때 — 정규화된 컬럼이 JOIN, 집계, 인덱스 모두 더 효율적입니다.
- 해당 필드로 자주 정렬하거나 범위 쿼리를 실행할 때 —
(metadata->>'price')::NUMERIC같은 캐스팅은 B-Tree 인덱스 활용을 어렵게 합니다. - FOREIGN KEY 제약이 필요할 때 — JSONB 내부 값에는 외래 키를 걸 수 없습니다.
- 행 수가 매우 많고 JSONB 필드를 WHERE 조건에 자주 쓸 때 — GIN 인덱스 없이는 Seq Scan이 발생합니다.
JSONB가 빛나는 상황은 행마다 구조가 다를 수 있는 반정형 데이터입니다. 사용자별 설정값, 외부 API 응답 캐싱, 제품 카탈로그의 카테고리별 속성 등이 대표적입니다.
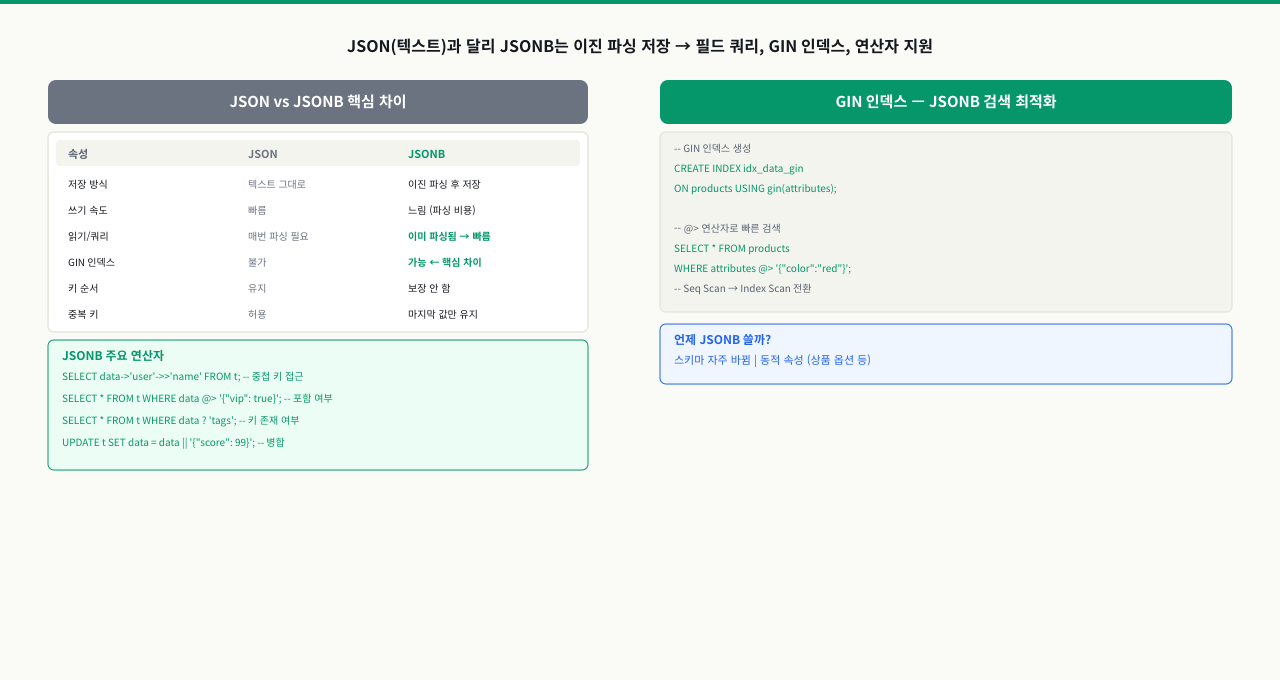
JSON vs JSONB 저장 방식 차이
JSON은 원본 텍스트를 그대로 저장해 입력 공백, 키 순서, 중복 키를 모두 보존합니다. JSONB는 이진 파싱 형식으로 저장해 공백을 제거하고, 키를 알파벳 순으로 정렬하며, 중복 키가 있으면 마지막 값만 남깁니다. 아래 예시에서 두 타입의 동작 차이를 확인하세요.
CREATE TABLE config_json (id SERIAL PRIMARY KEY, data JSON);
CREATE TABLE config_jsonb (id SERIAL PRIMARY KEY, data JSONB);
INSERT INTO config_json VALUES (1, '{"b": 1, "a": 2, "a": 3}');
INSERT INTO config_jsonb VALUES (1, '{"b": 1, "a": 2, "a": 3}');
SELECT data FROM config_json;
SELECT data FROM config_jsonb;
실행 완료 또는 조회 결과가 표시됩니다.
- 먼저 JSON vs JSONB 저장 결과를 비교합니다. JSON은 키 순서와 중복이 원본 그대로 보존되고, JSONB는 키가 알파벳 순으로 정렬되고 중복 키는 마지막 값만 남습니다 — 원본과 다르면 JSONB를 사용 중인 것입니다.
- EXPLAIN 출력에서 Seq Scan on products가 보이면 GIN 인덱스가 없거나 @> 이외의 연산자를 사용한 것입니다. Bitmap Index Scan 또는 Index Scan이 나타나야 인덱스가 활용되고 있습니다.
- EXPLAIN에서 cost 값을 확인합니다. Seq Scan cost가 1000 이상이고 GIN 인덱스 생성 후 100 미만으로 줄었다면 인덱스가 효과적으로 동작하는 것입니다 — cost가 줄어들지 않았다면 쿼리 연산자가 GIN과 호환되지 않는 경우입니다.
JSON 조회 결과는 {"b": 1, "a": 2, "a": 3}으로 원본 그대로 반환됩니다. JSONB 조회 결과는 {"a": 3, "b": 1}으로 키가 정렬되고 중복 키는 마지막 값만 남습니다.
JSON vs JSONB 비교
| 항목 | JSON | JSONB |
|---|---|---|
| 저장 방식 | 텍스트 원본 | 이진 파싱 |
| 키 순서 | 보존 | 알파벳 정렬 |
| 입력 속도 | 빠름 | 약간 느림 (파싱 비용) |
| 조회 속도 | 느림 (매번 파싱) | 빠름 |
| 인덱스 | 불가 | GIN 인덱스 가능 |
| 권장 상황 | 원본 보존 필요 | 거의 모든 경우 |
실무에서는 JSONB를 기본으로 선택하세요. 감사 로그나 외부 연동 원문 보존처럼 입력값을 그대로 유지해야 하는 경우에만 JSON을 사용합니다.
JSONB 조회 연산자
-> 연산자는 JSON 객체 또는 배열을 반환하고, ->> 연산자는 텍스트 값을 반환합니다. WHERE 조건에서 값을 문자열로 비교할 때는 ->> 를 씁니다. @> 연산자는 포함 여부를 확인하며, GIN 인덱스를 활용할 수 있어 대용량 테이블에서도 빠릅니다.
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(200) NOT NULL,
metadata JSONB
);
INSERT INTO products (name, metadata) VALUES
('노트북', '{"brand": "Samsung", "specs": {"ram": 16, "ssd": 512}, "tags": ["laptop", "work"]}'),
('마우스', '{"brand": "Logitech", "specs": {"dpi": 1600}, "tags": ["peripheral"]}'),
('모니터', '{"brand": "LG", "specs": {"size": 27, "resolution": "4K"}, "tags": ["display", "work"]}');
SELECT metadata -> 'brand' FROM products;
SELECT name FROM products
WHERE metadata ->> 'brand' = 'Samsung';
SELECT metadata -> 'specs' ->> 'ram' AS ram_gb
FROM products
WHERE metadata -> 'specs' ? 'ram';
SELECT metadata #>> '{specs, ram}' AS ram FROM products;
SELECT name FROM products
WHERE metadata @> '{"brand": "LG"}';
SELECT name FROM products
WHERE metadata -> 'tags' @> '["work"]';
->/->>/@>는 비슷해 보여도 반환 타입과 용도가 다릅니다. 같은 데이터에 세 연산자를 실행해, 어떤 게 텍스트 비교용이고 어떤 게 인덱스 타는 포함 검색용인지 눈으로 구분합니다.
-- -> : JSON 값 반환(따옴표 포함) / ->> : 텍스트 반환(WHERE 비교용)
SELECT metadata -> 'brand' AS as_json,
metadata ->> 'brand' AS as_text
FROM products;
-- ->> 로 스칼라 동등 비교
SELECT name FROM products WHERE metadata ->> 'brand' = 'Samsung';
-- 중첩 경로 추출
SELECT name, metadata #>> '{specs, ram}' AS ram FROM products;
-- @> 포함 검색(배열 태그) — GIN 인덱스를 탈 수 있는 형태
SELECT name FROM products WHERE metadata -> 'tags' @> '["work"]';
as_json | as_text
-------------+----------
"Samsung" | Samsung ← -> 는 따옴표 포함, ->> 는 순수 텍스트
name
--------
노트북 ← brand = 'Samsung'
name
--------
노트북
모니터 ← tags 에 "work" 포함
SELECT name FROM products WHERE metadata ->> 'brand' = 'Samsung';- as_json 열은 "Samsung"처럼 따옴표가 붙고 as_text는 Samsung으로 나오는지 본다 — WHERE 비교에서 -> 를 쓰면 따옴표 때문에 매칭이 안 된다. 동등비교는 항상 ->>
- ->> 동등 검색 결과가 정확히 brand=Samsung 행만인지 확인. 0행이면 키 이름 오타이거나 값에 공백이 섞인 것
- @> 태그 검색이 'work'를 가진 2개 행을 반환하는지 본다 — @>는 부분집합 포함이라 다른 태그가 더 있어도 매칭된다
- @> 쿼리가 느리면 EXPLAIN으로 Seq Scan인지 확인 — GIN 인덱스(아래)가 있어야 @>가 인덱스를 탄다
JSONB GIN 인덱스 생성
GIN 인덱스는 JSONB 컬럼 전체에 걸거나, 특정 경로에만 제한해서 생성할 수 있습니다. jsonb_path_ops 옵션을 쓰면 @> 연산에만 최적화되지만 인덱스 크기가 더 작습니다. 특정 키를 자주 WHERE 조건에서 사용한다면 해당 키에만 B-Tree 인덱스를 거는 것이 가장 효율적입니다.
CREATE INDEX idx_products_metadata ON products USING GIN (metadata);
CREATE INDEX idx_products_brand ON products
USING BTREE ((metadata ->> 'brand'));
CREATE INDEX idx_products_metadata_path ON products
USING GIN (metadata jsonb_path_ops);
JSONB 컬럼에 @> 또는 ? 연산자를 쓰더라도 GIN 인덱스가 없으면 테이블 전체를 순차 스캔(Seq Scan)합니다. EXPLAIN (ANALYZE, BUFFERS) 로 실행 계획을 확인했을 때 Seq Scan on products가 보이면 인덱스 부재가 원인입니다.
해결책은 CREATE INDEX ... USING GIN (metadata)로 인덱스를 추가하는 것입니다. 인덱스 추가 후 EXPLAIN 결과에 Bitmap Index Scan 또는 Index Scan이 나타나면 인덱스가 활용되는 것입니다. 운영 중인 테이블이라면 CREATE INDEX CONCURRENTLY로 락 없이 생성하세요.
to_tsvector('english', '데이터베이스 관리') 처럼 언어를 english로 지정하면 한국어 어간 추출(stemming)과 불용어 처리가 적용되지 않아 검색 정확도가 떨어집니다. 특히 조사나 어미 변화가 있는 한국어 단어는 토큰화 결과가 의도와 다를 수 있습니다.
한국어 환경에서는 두 가지 대안을 씁니다. 첫째, pg_trgm 확장으로 트라이그램 인덱스를 만들고 ILIKE 또는 유사도 검색을 사용합니다. 둘째, pg_bigm 확장을 설치해 2-gram 기반 한국어 전문검색을 구성합니다. 어느 방법도 완벽한 한국어 형태소 분석을 제공하지는 않으므로, 정밀한 검색이 필요하다면 Elasticsearch와 nori 플러그인 도입을 검토하세요.
실전 사용 패턴: 설정값과 메타데이터
jsonb_set 함수는 JSONB 내 특정 경로의 값만 변경합니다. || 연산자는 두 JSONB를 병합하며, 오른쪽 값이 우선합니다. - 연산자는 지정한 키를 삭제합니다. 이 세 연산을 조합하면 별도의 설정 테이블 없이 유연한 사용자별 설정을 관리할 수 있습니다.
CREATE TABLE user_settings (
user_id BIGINT PRIMARY KEY REFERENCES users(id),
settings JSONB NOT NULL DEFAULT '{}'
);
UPDATE user_settings
SET settings = jsonb_set(settings, '{theme}', '"dark"')
WHERE user_id = 1;
UPDATE user_settings
SET settings = settings || '{"language": "ko", "timezone": "Asia/Seoul"}'
WHERE user_id = 1;
UPDATE user_settings
SET settings = settings - 'old_key'
WHERE user_id = 1;
SELECT
metadata ->> 'brand' AS brand,
COUNT(*) AS product_count,
AVG((metadata -> 'specs' ->> 'ram')::INT) AS avg_ram
FROM products
WHERE metadata -> 'specs' ? 'ram'
GROUP BY metadata ->> 'brand';
전자상거래 플랫폼에서 상품 카탈로그를 구축할 때, 카테고리마다 속성이 다릅니다. 노트북은 RAM·SSD 용량이 있고, 의류는 사이즈·색상이 있으며, 식품은 유통기한·원산지가 있습니다. 이 모든 속성을 단일 테이블에 컬럼으로 만들면 수백 개의 NULL 컬럼이 생깁니다.
JSONB 컬럼 하나로 카테고리별 속성을 유연하게 수용하고, GIN 인덱스로 WHERE metadata @> '{"brand": "Samsung"}' 같은 검색을 빠르게 처리할 수 있습니다. 단, 모든 카테고리에 공통으로 존재하는 필드(가격, 재고, 등록일 등)는 여전히 정규화된 컬럼으로 관리해야 GROUP BY나 ORDER BY 성능을 보장할 수 있습니다.
배열 타입 활용
PostgreSQL 배열 타입은 GIN 인덱스와 @> 연산자를 조합해 태그 검색처럼 "포함 여부" 기반 쿼리에 효과적입니다. && 연산자는 두 배열 간 교집합이 존재하는지 확인합니다. unnest 함수는 배열을 행으로 펼쳐 집계 분석에 활용할 수 있습니다.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
tags TEXT[],
scores INT[]
);
INSERT INTO articles (title, tags, scores) VALUES
('PostgreSQL 가이드', ARRAY['database', 'postgresql', 'sql'], ARRAY[95, 87, 92]);
SELECT title FROM articles WHERE tags @> ARRAY['postgresql'];
SELECT title FROM articles WHERE tags && ARRAY['sql', 'nosql'];
SELECT title, unnest(tags) AS tag FROM articles;
CREATE INDEX idx_articles_tags ON articles USING GIN (tags);
UPSERT와 전문검색 — 실무 필수 PostgreSQL 기능
페이지 조회수를 기록하는 테이블이 있습니다. 첫 방문이면 INSERT, 재방문이면 UPDATE해야 합니다. 코드에서 SELECT → 분기 → INSERT/UPDATE로 구현했는데, 동시 요청이 몰리면 중복 INSERT가 발생하거나 레이스 컨디션이 생깁니다. 검색 기능은 LIKE 쿼리로 만들었는데 단어 조합 검색이 제대로 되지 않습니다. UPSERT와 전문검색은 이런 상황에서 PostgreSQL이 제공하는 원자적이고 효율적인 해결책입니다.
 확대
확대
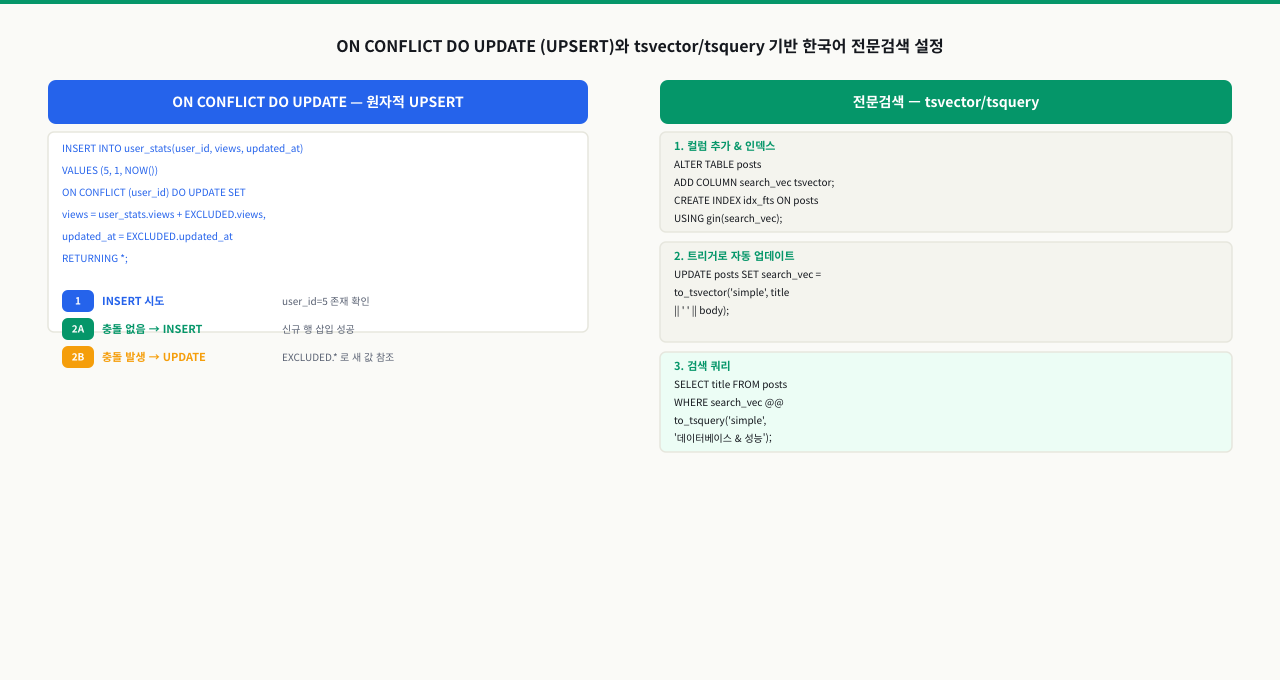
UPSERT — ON CONFLICT DO UPDATE
UPSERT는 INSERT를 시도했을 때 충돌이 발생하면 UPDATE로 전환하는 패턴입니다. PostgreSQL은 ON CONFLICT 절로 이를 원자적으로 처리합니다. EXCLUDED는 삽입에 실패한 새 행의 값을 참조하는 특수 테이블 별칭이고, 테이블 이름(예: page_views)은 기존에 저장된 행을 가리킵니다.
CREATE TABLE page_views (
page_url VARCHAR(500) PRIMARY KEY,
view_count BIGINT NOT NULL DEFAULT 0,
last_viewed_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
INSERT INTO page_views (page_url, view_count, last_viewed_at)
VALUES ('/home', 1, NOW())
ON CONFLICT (page_url)
DO UPDATE SET
view_count = page_views.view_count + EXCLUDED.view_count,
last_viewed_at = EXCLUDED.last_viewed_at;
INSERT INTO users (email, name) VALUES ('alice@example.com', 'Alice')
ON CONFLICT (email) DO NOTHING;
아래는 외부 시스템에서 받은 재고 데이터를 CTE와 UPSERT로 일괄 동기화하는 패턴입니다. WHERE inventory.quantity != EXCLUDED.quantity 조건을 추가하면 실제로 변경된 행만 UPDATE해 불필요한 쓰기를 줄입니다.
WITH incoming AS (
SELECT * FROM (VALUES
('SKU001', 100),
('SKU002', 0),
('SKU003', 50)
) AS t(sku, quantity)
)
INSERT INTO inventory (sku, quantity, updated_at)
SELECT sku, quantity, NOW() FROM incoming
ON CONFLICT (sku)
DO UPDATE SET
quantity = EXCLUDED.quantity,
updated_at = EXCLUDED.updated_at
WHERE inventory.quantity != EXCLUDED.quantity;
전문검색 — tsvector와 tsquery
tsvector는 문서 텍스트에서 어간 추출(stemming)과 불용어 제거를 거쳐 정규화된 단어 집합을 만듭니다. tsquery는 &(AND), |(OR), !(NOT) 연산자로 검색 조건을 표현합니다. @@ 연산자로 tsvector가 tsquery를 만족하는지 확인합니다. plainto_tsquery는 자연어 입력을 받아 자동으로 AND로 연결하고, websearch_to_tsquery는 구글 스타일 검색 문법을 지원합니다.
SELECT to_tsvector('english', 'The quick brown fox jumps over the lazy dog');
SELECT to_tsquery('english', 'quick & fox');
SELECT to_tsquery('english', 'cat | dog');
SELECT to_tsquery('english', 'quick & !lazy');
SELECT to_tsvector('english', 'quick brown fox') @@ to_tsquery('english', 'fox');
SELECT plainto_tsquery('english', 'quick brown fox');
SELECT websearch_to_tsquery('english', '"quick fox" OR cat -lazy');
전문검색 인덱스 설정 (실전)
미리 계산된 tsvector 컬럼을 별도로 두고 트리거로 자동 갱신하는 방식이 실무 표준입니다. setweight로 제목(가중치 A)과 본문(가중치 B)에 다른 중요도를 부여하면 ts_rank 결과에 반영됩니다. GIN 인덱스를 search_vector 컬럼에 생성해야 @@ 연산에서 인덱스가 활용됩니다.
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title VARCHAR(500) NOT NULL,
content TEXT,
search_vector TSVECTOR
);
CREATE OR REPLACE FUNCTION articles_search_vector_update()
RETURNS TRIGGER AS $$
BEGIN
NEW.search_vector :=
setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(NEW.content, '')), 'B');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trig_articles_search_vector
BEFORE INSERT OR UPDATE ON articles
FOR EACH ROW EXECUTE FUNCTION articles_search_vector_update();
CREATE INDEX idx_articles_search ON articles USING GIN (search_vector);
SELECT id, title,
ts_rank(search_vector, query) AS rank,
ts_headline('english', content, query, 'MaxWords=50, MinWords=20') AS snippet
FROM articles, to_tsquery('english', 'postgresql & index') query
WHERE search_vector @@ query
ORDER BY rank DESC
LIMIT 10;
한국어 전문검색 — pg_trgm 활용
PostgreSQL의 기본 텍스트 파서는 한국어 형태소 분석을 지원하지 않습니다. pg_trgm 확장은 3글자 단위(트라이그램) 인덱스를 만들어 LIKE/ILIKE 쿼리가 인덱스를 타도록 합니다. 완전한 형태소 분석은 아니지만 부분 문자열 매칭과 유사도 검색은 충분히 지원합니다.
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX idx_articles_title_trgm ON articles
USING GIN (title gin_trgm_ops);
SELECT * FROM articles WHERE title ILIKE '%데이터베이스%';
SELECT title, similarity(title, '데이터베이스 관리')
FROM articles
WHERE title % '데이터베이스'
ORDER BY similarity DESC;
UUID와 ENUM 타입
UUID는 분산 시스템에서 여러 서버가 독립적으로 ID를 생성해도 충돌하지 않는다는 장점이 있습니다. PostgreSQL 13부터는 확장 없이 gen_random_uuid()를 기본 함수로 제공합니다. ENUM은 컬럼 값을 제한된 집합으로 강제하며, CHECK 제약보다 타입 수준에서 안전합니다. 단, ENUM 값 삭제는 지원하지 않으므로 마이그레이션 시 신중하게 설계해야 합니다.
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE sessions (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
user_id BIGINT NOT NULL REFERENCES users(id),
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE TABLE sessions_v2 (
id UUID PRIMARY KEY DEFAULT gen_random_uuid()
);
CREATE TYPE order_status AS ENUM (
'pending', 'confirmed', 'shipped', 'delivered', 'cancelled'
);
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
status order_status NOT NULL DEFAULT 'pending'
);
ALTER TYPE order_status ADD VALUE 'refunded' AFTER 'delivered';
SELECT * FROM orders WHERE status = 'pending';
초기 스타트업이나 중소규모 서비스에서 Elasticsearch 클러스터를 운용하는 것은 인프라 복잡도와 비용 측면에서 부담이 큽니다. PostgreSQL의 tsvector + GIN 인덱스 조합은 별도 검색 엔진 없이 수백만 건 수준의 전문검색을 처리할 수 있습니다.
상품명과 설명에 search_vector 컬럼을 만들고, 제목에 가중치 A, 설명에 가중치 B를 부여하면 ts_rank가 자동으로 관련도 순 정렬을 처리합니다. 한국어 검색은 pg_trgm의 ILIKE 인덱스로 커버하고, 검색 트래픽이 수천 QPS를 초과하는 시점에 Elasticsearch 마이그레이션을 고려하면 됩니다.
PostgreSQL이 UPDATE 하나를 처리하는 법 — MVCC 튜플과 VACUUM 5단계
큰 JSONB를 자주 갱신하면 논리적 행 수는 그대로인데 디스크가 부풀고 조회가 느려집니다. 이 현상의 뿌리는 PostgreSQL이 UPDATE를 처리하는 방식 자체에 있습니다. PostgreSQL은 행을 제자리에서 덮어쓰지 않고 새 버전을 쌓는 MVCC(다중 버전 동시성 제어)로 동시성을 처리합니다 — 덕분에 읽기와 쓰기가 서로를 막지 않지만, 그 대가로 '죽은 튜플'이 생기고 VACUUM이 이를 치웁니다. 아래 5단계를 알면 왜 부풀고 왜 느려지는지가 한 줄로 이어집니다.
[트랜잭션 A] BEGIN → UPDATE orders SET status='paid' WHERE id=1
│
① 스냅샷 획득 (트랜잭션 시작 시 '지금 보이는 xid 범위'를 스냅샷으로 고정)
│
② 가시성 판정 (행마다 xmin(생성 xid)·xmax(삭제 xid)를 스냅샷과 대조 → 내게 보이는 버전만 읽음)
│ → 읽는 쪽과 쓰는 쪽이 서로를 막지 않음
│
③ UPDATE = 새 튜플 삽입 (기존 행을 덮어쓰지 않음! 새 버전을 추가하고 옛 버전 xmax에 내 xid 기록)
│ → 옛 버전은 '죽은 튜플' 예약
│
④ 커밋 (COMMIT → 새 버전이 이후 트랜잭션에 보임. 롤백하면 새 버전이 죽은 튜플이 됨)
│
⑤ VACUUM 정리 (아무도 더 안 보는 죽은 튜플 공간을 autovacuum이 회수·재사용)
▼
[결과] 동시 읽기는 옛 버전을, 새 읽기는 새 버전을 — 락 없이 일관되게
각 단계에서 무슨 일이 일어나고, 어디서 문제가 되나:
| 단계 | 하는 일 | 여기서 문제가 되면(증상) |
|---|---|---|
| ① 스냅샷 획득 | 트랜잭션 시작 시 보이는 xid 범위를 고정 | 롱 트랜잭션이 오래된 스냅샷을 붙잡으면 xmin horizon이 묶여 이후 죽은 튜플을 아무도 못 지움 |
| ② 가시성 판정 | 행의 xmin·xmax를 스냅샷과 비교해 보이는 버전만 선택 | 죽은 튜플이 쌓이면 스캔이 안 보이는 버전까지 훑어 조회가 느려짐 |
| ③ UPDATE=새 튜플 | 기존 버전 유지 + 새 버전 삽입(제자리 수정 아님) | 한 방에 수천만 행 UPDATE = 수천만 죽은 튜플 + 대량 WAL이 한꺼번에 → 테이블 급팽창 |
| ④ 커밋 | 새 버전을 확정해 이후 트랜잭션에 노출 | JSONB 필드 하나만 jsonb_set으로 바꿔도 행 전체가 새로 쓰임 → bloat 가속 |
| ⑤ VACUUM 정리 | 더 이상 안 보이는 죽은 튜플 공간을 autovacuum이 회수 | autovacuum이 갱신 속도를 못 따라가면 bloat 누적 → VACUUM FULL·REINDEX로 회수 |
즉 PostgreSQL이 락 없이 동시성을 처리하는 비결은 ③의 "덮어쓰지 않고 새 버전을 쌓는" 방식이고, 그 청구서가 ⑤ VACUUM이 치우는 죽은 튜플입니다. 그래서 "행 수는 그대로인데 디스크가 부풀고 느려지는" 증상은 거의 항상 잦은 UPDATE가 만든 bloat이며, pg_stat_user_tables의 n_dead_tup으로 확인하고 대량 백필은 배치로 나눠 커밋해 autovacuum이 사이사이 회수하게 하면 됩니다.
심화 — JSONB의 물리적 비용
심화: TOAST와 MVCC — 잦게 갱신하는 큰 JSONB가 부르는 부하
JSONB로 반정형 데이터를 우아하게 담고 GIN 인덱스로 검색까지 빠르게 만들었습니다. 그런데 그 JSONB를 자주 갱신하기 시작하면, 논리적 행 수는 그대로인데 디스크가 부풀고 쓰기가 느려지는 현상을 만납니다. 원인은 SQL이 아니라 PostgreSQL의 물리 저장 방식에 있습니다.
- 큰 값은 TOAST로 행 밖에 저장됩니다. 한 행 크기가 임계(약 2KB)를 넘으면 PostgreSQL은 큰 컬럼을 별도 TOAST 테이블에 압축해 행 밖으로 밀어냅니다. 그래서 JSONB 안의 키 하나(
metadata->>'user_id')만 읽어도 값 전체를 읽어 압축을 풀어야 합니다 — 필터링은 GIN 인덱스가 도와도, 값을 꺼내는(projection) 비용은 값 크기에 비례합니다. - MVCC 때문에 부분 수정이 곧 전체 재작성입니다. PostgreSQL의 UPDATE는 제자리 수정이 아니라 새 튜플 삽입과 옛 튜플을 죽은 튜플로 표시하는 방식입니다.
jsonb_set으로 필드 하나만 바꿔도 행 전체(그리고 TOAST 청크)가 새로 쓰이고, 죽은 튜플·WAL·GIN 인덱스 갱신 비용이 함께 발생합니다. - 죽은 튜플이 쌓이면 bloat입니다. autovacuum이 죽은 튜플 회수를 따라가지 못하면 테이블·TOAST·인덱스가 계속 커지고, 캐시 효율이 떨어져 읽기까지 느려집니다.
그래서 실무 기준은 자주 바뀌는 값은 JSONB 안에 두지 않는다입니다. 상태·카운터·최종 수정시각처럼 갱신이 잦은 필드는 일반 컬럼으로 빼고, JSONB에는 거의 안 바뀌는 반정형 속성만 남깁니다. GIN 인덱스는 조회를 돕지만 쓰기 비용을 늘리므로, 갱신이 잦은 컬럼에는 인덱스 대상 범위도 신중히 정합니다.
상황: 사용자 설정이나 세션처럼 행 수는 많지 않은 JSONB 테이블인데, 디스크 사용량이 비정상적으로 크고 시간이 갈수록 조회·갱신이 느려집니다. 데이터를 세어 보면 행은 몇천 건뿐입니다.
원인: 그 JSONB를 매 요청·이벤트마다 jsonb_set 등으로 갱신하고 있었습니다. MVCC 때문에 필드 하나를 바꿔도 행 전체가 새로 쓰이며 죽은 튜플이 쌓이고, 값이 커 TOAST에 저장되니 TOAST 테이블과 GIN 인덱스까지 함께 부풉니다(bloat). autovacuum이 갱신 속도를 못 따라가면 공간이 회수되지 않고 계속 커집니다.
진단: pg_stat_user_tables에서 해당 테이블의 n_dead_tup(죽은 튜플)과 n_tup_upd(업데이트 수)를 봅니다. pg_total_relation_size로 테이블·TOAST·인덱스 크기를 나눠 확인하고, pgstattuple로 dead tuple 비율을 봅니다. 행 수 대비 크기·죽은 튜플이 과도하면 확정입니다.
해결: 자주 바뀌는 값을 JSONB 밖 일반 컬럼으로 분리해 갱신이 큰 값 전체를 다시 쓰지 않게 합니다. 갱신 빈도 자체를 줄이고(모아서 쓰기), 이 테이블만 autovacuum을 더 공격적으로(스케일 팩터 하향) 설정합니다. 이미 부푼 공간은 VACUUM FULL이나 REINDEX로 회수합니다(락 주의, 운영 중이면 pg_repack 검토).
명령어·구문 빠른 참조
이 모듈에서 다룬 PostgreSQL 고유 기능 구문을 실전 조합과 함께 모았습니다.
| 구문/명령 | 용도 | 예 |
|---|---|---|
-> vs ->> | jsonb 반환 vs 텍스트 반환(WHERE 비교) | WHERE metadata ->> 'brand' = 'Samsung' |
#>> '{a,b}' | 중첩 경로 텍스트 추출 | metadata #>> '{specs, ram}' |
@> (JSONB/배열 포함) | 포함 검색(GIN 인덱스 활용) | WHERE metadata @> '{"brand": "LG"}' |
? / && | 키 존재 여부 / 배열 교집합 | metadata -> 'specs' ? 'ram', tags && ARRAY['sql'] |
jsonb_set / || / - | JSONB 부분 수정·병합·키 삭제 | settings || '{"language":"ko"}' |
CREATE INDEX ... USING GIN (col) | JSONB·배열·tsvector 인덱스 | USING GIN (metadata jsonb_path_ops) |
ON CONFLICT ... DO UPDATE | UPSERT(EXCLUDED=삽입 시도한 새 행) | DO UPDATE SET view_count = page_views.view_count + EXCLUDED.view_count |
ON CONFLICT ... DO NOTHING | 중복 충돌 시 무시 | INSERT ... ON CONFLICT (email) DO NOTHING |
to_tsvector @@ to_tsquery | 전문검색 매칭 | to_tsvector('english', body) @@ to_tsquery('english', 'a & b') |
setweight / ts_rank | 필드 가중치 부여·관련도 정렬 | setweight(to_tsvector(...), 'A') |
pg_trgm + gin_trgm_ops | 한국어 ILIKE·유사도 검색 | WHERE title ILIKE '%데이터베이스%' |
gen_random_uuid() / CREATE TYPE ... AS ENUM | UUID PK·ENUM 타입 | id UUID DEFAULT gen_random_uuid() |
CREATE INDEX CONCURRENTLY | 운영 중 락 없이 인덱스 생성 | 대용량 테이블 무중단 인덱싱 |
관련 모듈로 더 깊이:
- InnoDB 스토리지 엔진 구조와 한글 인코딩, Auto Increment — 같은 RDBMS인 MySQL/InnoDB와 기능을 비교해 선택 기준 잡기
- B-Tree 인덱스의 작동 원리와 인덱스 설계의 핵심 조건 — JSONB·전문검색을 빠르게 만드는 GIN 인덱스의 기반 개념
- Document DB (MongoDB) 임베딩 vs 참조 설계 기준 — JSONB 비정형 처리와 문서 DB(MongoDB) 접근법의 비교
다음 모듈에서는 MySQL InnoDB 스토리지 엔진 구조와 한글 인코딩 설정, Auto Increment 동작 방식을 다룹니다.