장애가 끝난 뒤 원인을 찾으려 했지만 문제 파드는 이미 재시작되어 로컬 로그가 사라졌습니다. 컨테이너 로그를 중앙에서 수집하지 않으면 재현이 어려운 장애는 흔적 없이 지나갑니다. Loki는 Kubernetes 로그를 라벨 기반으로 모아 빠르게 추적하게 해줍니다.
Loki로 Kubernetes 로그 수집
운영 중인 쇼핑몰 결제 서비스에서 새벽 2시에 간헐적 500 에러가 발생했습니다. 노드가 12개, 파드가 80개 이상인 클러스터에서 어느 파드가 문제인지 찾으려면 어떻게 해야 할까요. kubectl logs를 파드마다 하나씩 실행하면 범인을 찾기 전에 날이 밝을 수도 있습니다. Loki는 Prometheus와 같은 레이블 기반 철학으로 설계된 로그 집계 시스템입니다. Promtail DaemonSet이 모든 노드의 컨테이너 로그를 자동으로 수집하고 Loki에 전송하면, Grafana에서 {namespace="production", app="payment"} |= "ERROR" 한 줄로 클러스터 전체의 관련 로그를 단번에 조회할 수 있습니다. Elasticsearch 기반 EFK 스택 대비 저장 비용이 70~90% 낮고, Prometheus와 같은 레이블 체계를 사용하기 때문에 메트릭-로그 연동이 자연스럽습니다. 이 모듈을 마치면 Loki 스택을 클러스터에 배포하고 LogQL로 실무 수준의 로그 분석을 수행할 수 있습니다.
- 1Loki 아키텍처(Loki, Promtail, Grafana 삼각 구조)를 설명할 수 있다
- 2Promtail DaemonSet을 배포하고 hostPath 마운트로 컨테이너 로그를 수집할 수 있다
- 3LogQL의 레이블 필터, 라인 필터, 집계 함수를 사용할 수 있다
- 4Grafana 데이터소스를 연결하고 Explore 탭에서 로그를 조회할 수 있다
- 5로그 볼륨, 에러율, 특정 키워드 알림으로 Loki 대시보드를 구성할 수 있다
- 6Loki에 로그가 보이지 않을 때 단계적으로 진단할 수 있다
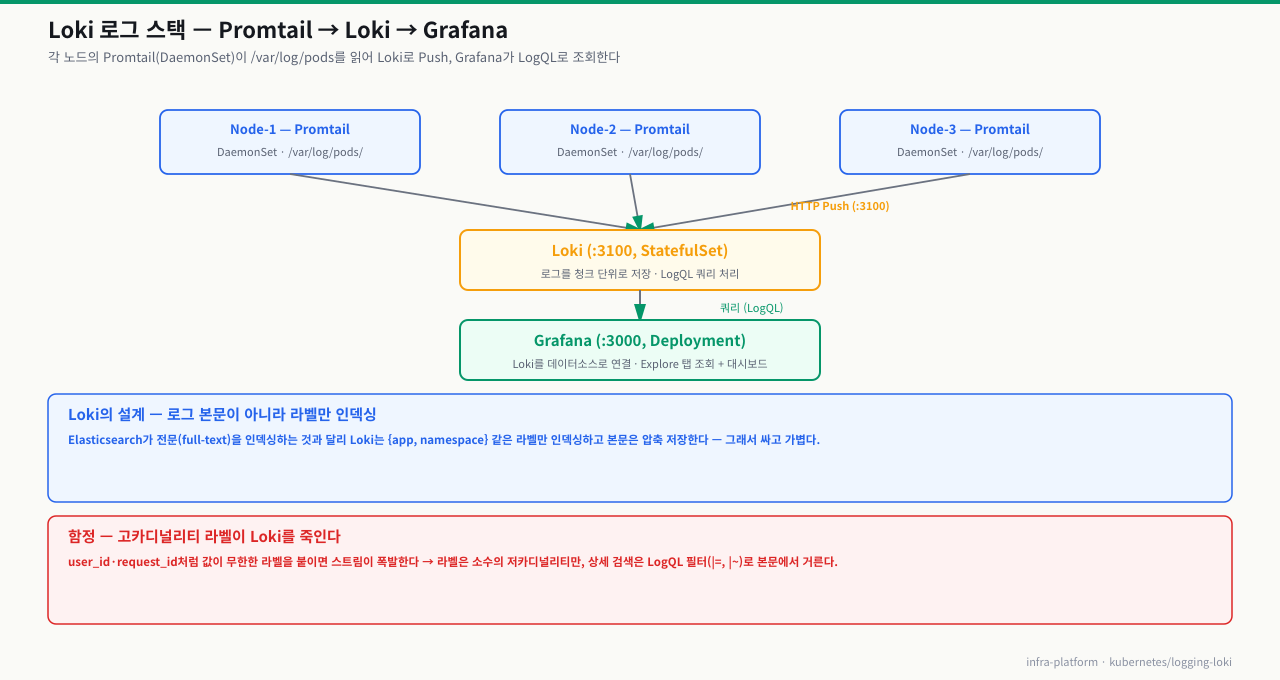
kubectl get nodeskubectl create namespace monitoring --dry-run=client -o yaml | kubectl apply -f -helm version --shortkubectl get pods -n monitoring | grep -E 'prometheus|grafana'helm repo add grafana https://grafana.github.io/helm-charts && helm repo updateLoki 스택 아키텍처
Loki 생태계는 세 가지 컴포넌트로 구성됩니다.
 확대
확대
- Promtail: 각 노드의
/var/log/pods/에서 로그 파일을 읽어 Loki로 전송 - Loki: 로그를 청크 단위로 저장, LogQL 쿼리 처리
- Grafana: Loki를 데이터소스로 연결, Explore 탭에서 조회 + 대시보드
로그 한 줄이 stdout에서 LogQL 조회까지 가는 법 — 수집·저장·조회 5단계
파드가 console.log나 stderr로 남긴 한 줄이, 잠시 뒤 Grafana에서 {app="payment"} |= "ERROR"로 조회됩니다. 그 사이에 로그는 stdout → 노드의 로그 파일 → Promtail이 tail·라벨 부착 → Loki에 push(라벨 인덱싱·청크 저장) → LogQL 조회의 경로를 지납니다. 이 경로를 알면 "로그가 왜 안 보이지", "왜 이 앱만 비지"를 단계로 좁힐 수 있습니다 — 각 단계마다 로그가 조용히 사라질 수 있는 지점이 다릅니다.
파드 컨테이너: console.log / stderr
│
① stdout·stderr → 노드 파일 (kubelet이 /var/log/pods/.../0.log에 기록)
│
② Promtail(DaemonSet)이 tail (노드마다 하나, 파일의 새 줄을 읽음)
│
③ 라벨 부착 + Loki로 push (app·namespace·pod 라벨 → HTTP push)
│
④ Loki 저장 (라벨만 인덱싱 + 로그 본문은 청크로 압축 저장)
│
⑤ LogQL 조회 (레이블 셀렉터로 스트림 선택 → 라인 필터로 grep)
▼
Grafana Explore에 로그 표시
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 막히면 증상 |
|---|---|---|
| ① 파일 기록 | 컨테이너의 stdout/stderr를 kubelet이 노드의 /var/log/pods/에 파일로 남김 | 앱이 stdout이 아닌 컨테이너 내부 파일에만 로그를 쓰면 이 경로에 안 남아 수집 대상에서 빠짐 |
| ② Promtail tail | DaemonSet이라 모든 노드에 하나씩 떠서 그 노드의 로그 파일을 읽음 | 노드에 Promtail이 없으면(taint·DaemonSet 미배포) 그 노드 파드 로그만 통째로 누락 |
| ③ 라벨·push | 낮은 카디널리티 라벨(app·namespace·pod)을 붙여 Loki로 HTTP push | RBAC 부족으로 파드 메타데이터 못 읽음 → 라벨 없음. Loki URL 오타 → connection refused |
| ④ 저장 | 라벨만 인덱싱하고 본문은 청크로 압축 저장. 수신량·시간 한도를 검사 | rate limit 초과 → 429로 배치 거부(피크 때만 국소 유실). retention 지나면 삭제 |
| ⑤ 조회 | 레이블 셀렉터로 스트림을 좁힌 뒤 라인 필터로 본문을 검색 | 라벨 값 오타·조회 시간범위 밖 → 결과 0건. 라벨 없이 전문검색 → 느림 |
즉 "로그가 보인다"는 다섯 단계가 모두 통과했다는 뜻이고, 안 보일 때는 단계를 거꾸로 짚습니다 — Grafana가 비면 먼저 ⑤(라벨 값·시간범위)를 의심하고, curl .../loki/api/v1/labels로 ④에 데이터가 들어왔는지 확인합니다. 라벨 자체가 없으면 ③(RBAC·Loki URL), 특정 노드만 비면 ②(Promtail 배포), 앱은 로그를 남겼는데 어디에도 없으면 ①(stdout 여부)입니다. 피크 시간대에만 특정 스트림이 듬성듬성 비면 ④의 rate limit 거부이지 연결 오류가 아닙니다 — loki_discarded_samples_total 지표로 확정합니다. 라벨은 스트림을 고르는 인덱스, 라인 필터는 그 안을 훑는 grep이라는 ⑤의 구분이 조회 성능의 핵심입니다.
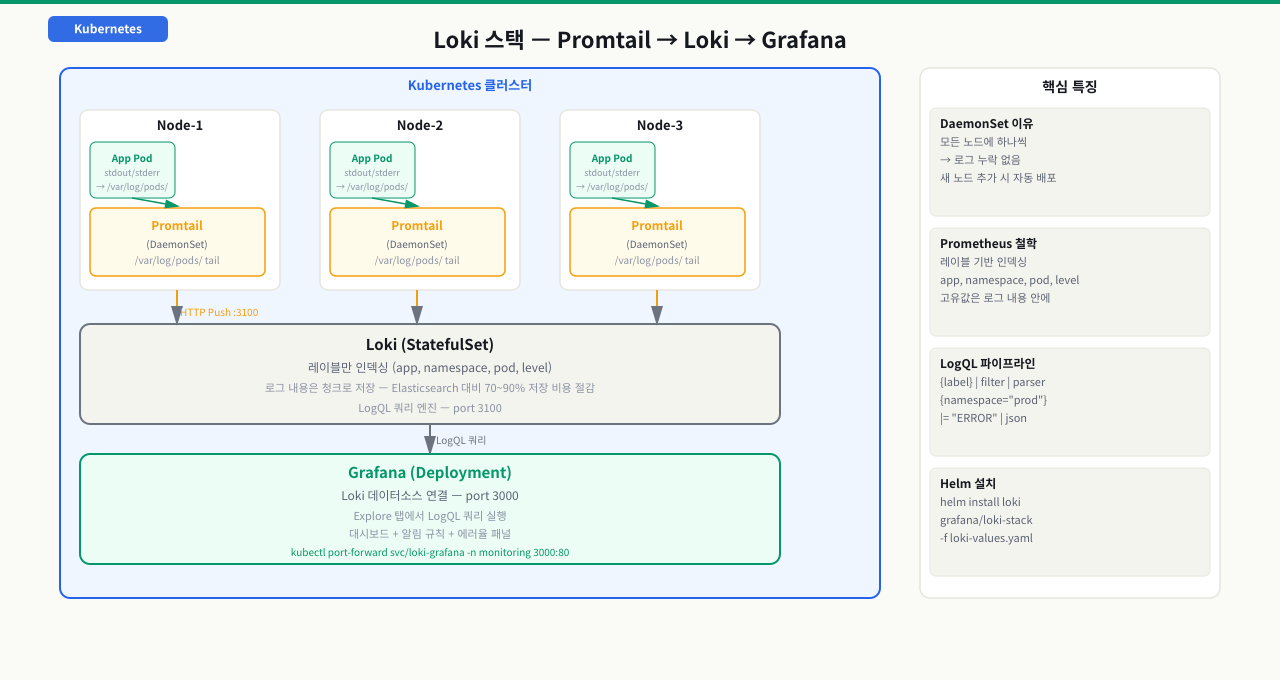
왜 Promtail은 DaemonSet인가 — 로그 파일 위치와 수집 구조
로그 수집기를 Deployment로 배포했더니 일부 노드의 로그가 수집되지 않았습니다. 어떤 노드에 파드가 배포될지 예측할 수 없기 때문에, 수집기가 없는 노드의 컨테이너 로그는 아무도 가져가지 못합니다. 새 노드가 클러스터에 추가될 때마다 수동으로 수집기를 배포해야 한다면 운영 부담이 커지고 누락 사고가 발생합니다. Kubernetes에서 컨테이너 로그는 각 노드의 로컬 파일시스템에 저장되기 때문에, 수집기는 반드시 해당 노드에서 실행되어야 합니다. DaemonSet은 현재와 미래의 모든 노드에 파드를 하나씩 자동 배포하는 유일한 방식입니다. 이 CB에서는 컨테이너 로그 파일이 노드에 어떻게 저장되는지와, Promtail이 DaemonSet으로 그것을 읽는 구조를 다룹니다. Promtail이 이 파일을 읽으려면 해당 노드에서 실행되어야 하고, 모든 노드의 로그를 빠짐없이 수집하려면 모든 노드에 하나씩 배포되어야 합니다. DaemonSet이 정확히 이 요구사항을 충족합니다.
 확대
확대
# 노드에서 컨테이너 로그 파일 실제 위치 확인
kubectl debug node/worker-1 -it --image=busybox -- ls /host/var/log/pods/
# 출력 예시:
# production_payment-7d9b4c8f6-xkp2n_abc123/
# payment/
# 0.log ← 실제 로그 파일 (JSON Lines 형식)
# 1.log ← 이전 컨테이너 로그 (재시작된 경우)
로그 파일은 JSON Lines 형식으로 저장됩니다:
{"log":"2024-01-15T02:31:44Z [ERROR] payment gateway timeout\n","stream":"stderr","time":"2024-01-15T02:31:44.123456789Z"}
{"log":"2024-01-15T02:31:44Z [INFO] retrying request...\n","stream":"stdout","time":"2024-01-15T02:31:44.234567890Z"}
Promtail은 이 파일을 tail하면서 새 라인이 추가될 때마다 Loki에 push합니다. 파드가 재시작되거나 새 파드가 배포되어도 kubelet이 새 경로를 만들고 Promtail이 자동으로 감지합니다.
Loki + Promtail 배포
Helm으로 Loki Stack 설치
# values 파일 생성 — 실습용 단순 설정
cat > loki-values.yaml << 'EOF'
loki:
auth_enabled: false # 인증 비활성화 (실습용)
storage:
type: filesystem # 프로덕션에서는 S3/GCS 권장
commonConfig:
replication_factor: 1 # 단일 인스턴스 (실습용)
limits_config:
retention_period: 7d # 7일 보관
ingestion_rate_mb: 16
ingestion_burst_size_mb: 32
promtail:
enabled: true
config:
clients:
- url: http://loki-gateway/loki/api/v1/push
scrape_configs:
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
pipeline_stages:
- cri: {} # CRI 포맷 파싱 (containerd)
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app]
target_label: app
- source_labels: [__meta_kubernetes_namespace]
target_label: namespace
- source_labels: [__meta_kubernetes_pod_name]
target_label: pod
- source_labels: [__meta_kubernetes_container_name]
target_label: container
grafana:
enabled: true
sidecar:
datasources:
enabled: true
additionalDataSources:
- name: Loki
type: loki
url: http://loki-gateway:80
access: proxy
isDefault: false
EOF
# Loki Stack 설치
helm install loki grafana/loki-stack \
--namespace monitoring \
--values loki-values.yaml
# 배포 상태 확인
kubectl get pods -n monitoring -l app.kubernetes.io/instance=loki
# 예상 출력:
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 2m
loki-promtail-4k9dx 1/1 Running 0 2m ← Node-1
loki-promtail-7rmnx 1/1 Running 0 2m ← Node-2
loki-promtail-9vzph 1/1 Running 0 2m ← Node-3
loki-grafana-6d8f4b5c7-xm2nk 1/1 Running 0 2m
Promtail DaemonSet 구조 살펴보기
# Promtail DaemonSet 상세 확인
kubectl describe daemonset loki-promtail -n monitoring
# hostPath 마운트 확인 — 로그 파일 접근 경로
kubectl get daemonset loki-promtail -n monitoring -o yaml | \
grep -A5 "hostPath"
핵심 볼륨 마운트 구조:
# Promtail Pod spec 핵심 부분
volumes:
- name: containers # 컨테이너 로그 경로
hostPath:
path: /var/lib/docker/containers
- name: pods # Pod 로그 경로 (kubelet 관리)
hostPath:
path: /var/log/pods
volumeMounts:
- name: pods
mountPath: /var/log/pods
readOnly: true # 읽기 전용 (보안)
- name: containers
mountPath: /var/lib/docker/containers
readOnly: true
LogQL 기초
LogQL은 Prometheus PromQL의 로그 버전입니다. 두 가지 유형의 쿼리가 있습니다.
로그 쿼리 (Log Query)
특정 조건의 로그 라인을 반환합니다.
# 기본 레이블 셀렉터 — app=nginx 레이블의 모든 로그
{app="nginx"}
# 네임스페이스 + 앱 조합
{namespace="production", app="payment"}
# 라인 필터: ERROR 포함 라인만
{namespace="production"} |= "ERROR"
# 라인 필터: 특정 문자열 제외
{app="nginx"} != "health-check"
# 정규식 필터
{app="api-server"} |~ "timeout|connection refused"
# JSON 파싱 후 특정 필드 필터
{app="payment"} | json | status_code=500
# 파이프라인 체이닝
{namespace="production", app="payment"}
|= "ERROR"
| json
| line_format "{{.level}} [{{.request_id}}] {{.message}}"
메트릭 쿼리 (Metric Query)
로그에서 숫자 메트릭을 추출합니다.
# 분당 에러 로그 수 (rate)
rate({app="payment"} |= "ERROR" [5m])
# 네임스페이스별 로그 수신 속도
sum(rate({namespace=~".+"}[5m])) by (namespace)
# HTTP 500 에러 비율 계산
sum(rate({app="nginx"} |= "HTTP/1.1 5" [5m])) /
sum(rate({app="nginx"} [5m]))
# 특정 패턴 카운트
count_over_time({app="order-service"} |= "payment_failed" [1h])
Grafana Explore에서 LogQL 실행
# Grafana 포트포워딩
kubectl port-forward svc/loki-grafana -n monitoring 3000:80
# 기본 admin 패스워드 확인(터미널·CI 로그에 출력/공유하지 말고 로컬 변수에만 저장)
GRAFANA_ADMIN_PASSWORD=$(kubectl get secret loki-grafana -n monitoring \
-o jsonpath='{.data.admin-password}' | base64 -d)
export GRAFANA_ADMIN_PASSWORD
브라우저에서 http://localhost:3000 접속 → Explore → 데이터소스 Loki 선택 → 쿼리 입력:
# 실습 1: 최근 1시간 production 네임스페이스 에러 로그
{namespace="production"} |= "ERROR" | limit 100
# 실습 2: 특정 파드 로그 실시간 tail
{pod=~"payment-.*"} | limit 50
# 실습 3: 분당 에러 수 그래프
rate({namespace="production"} |= "ERROR" [5m])
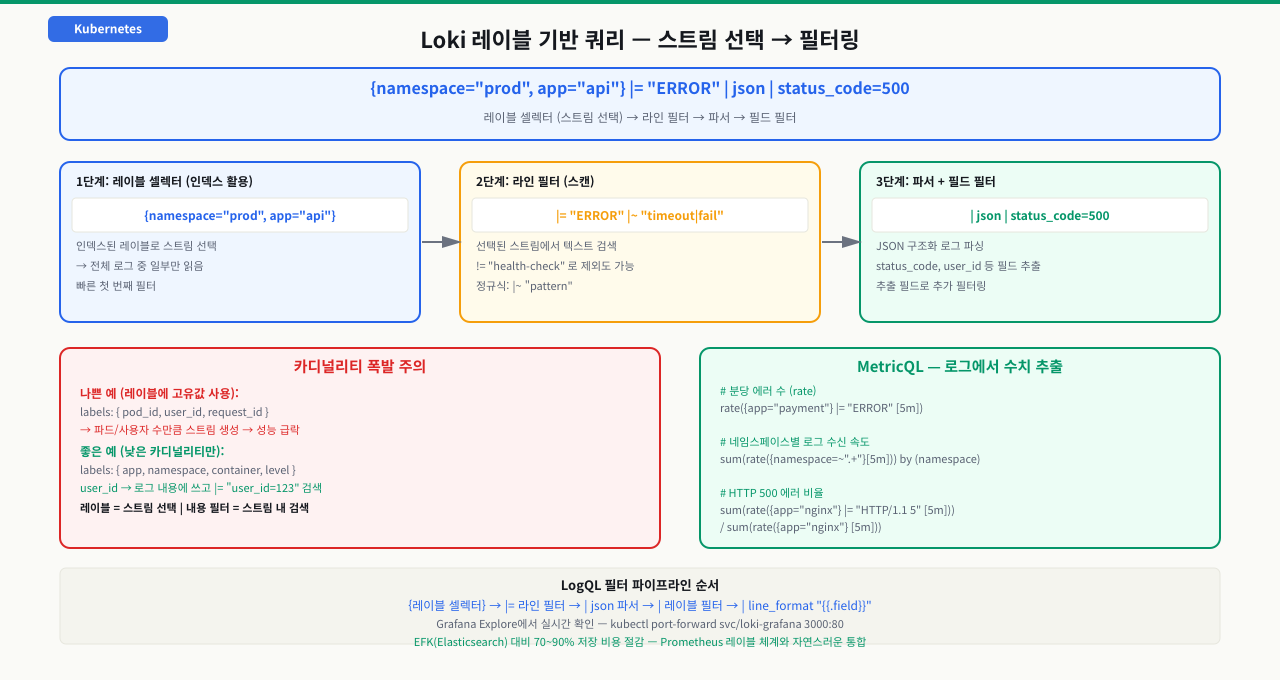
Loki 레이블 전략 — 카디널리티 폭발 주의
Loki를 도입한 초반에는 잘 동작하다가 어느 시점부터 쿼리가 느려지고 Loki 자체가 메모리를 과다 사용합니다. 원인을 찾아보면 Promtail 설정에서 user_id나 request_id 같은 고유값을 레이블로 추가한 것이 문제입니다. 레이블 조합이 수천 개로 늘어나면 Loki는 그만큼 많은 스트림을 관리해야 해 성능이 급격히 저하됩니다. 이를 카디널리티 폭발이라고 하며, Loki 운영에서 가장 흔한 성능 문제입니다. 이 CB에서는 낮은 카디널리티 레이블만 사용하는 설계 원칙과, 고유값 검색은 라인 필터로 처리하는 올바른 Loki 레이블 전략을 다룹니다. 레이블 수와 값의 조합이 너무 많아지면 스트림 수가 폭발적으로 증가해 성능이 급격히 저하됩니다. 이를 카디널리티 폭발이라고 합니다.
 확대
확대
# 나쁜 예: 카디널리티 폭발
# pod_id, user_id, request_id 같은 고유값을 레이블로 사용하면
# 스트림이 파드/사용자/요청 수만큼 생성됨
scrape_configs:
- pipeline_stages:
- labels:
pod_id: __meta_kubernetes_pod_uid # 파드마다 고유 → 수천 개 스트림
user_id: user_id # 절대 사용 금지
request_id: request_id # 절대 사용 금지
# 좋은 예: 낮은 카디널리티 레이블만 사용
scrape_configs:
- pipeline_stages:
- labels:
app: # 앱 이름 (수십 개)
namespace: # 네임스페이스 (한 자릿수~수십 개)
container: # 컨테이너 이름 (앱당 보통 1~3개)
level: # 로그 레벨 (INFO/WARN/ERROR — 5개 미만)
user_id나 request_id 같은 고유값은 로그 라인 내용 안에 두고 LogQL의 라인 필터(|= "user_id=12345")나 JSON 파싱으로 검색하세요. 레이블은 스트림을 선택하는 용도, 내용 필터는 스트림 내에서 검색하는 용도로 구분하는 것이 Loki 성능의 핵심입니다.
# 현재 레이블 카디널리티 확인 (Loki API)
curl -s http://localhost:3100/loki/api/v1/labels | jq '.data'
curl -s "http://localhost:3100/loki/api/v1/label/pod/values" | jq '.data | length'
# 값이 수천 개라면 레이블 전략 재검토 필요
Grafana 대시보드 구성
주요 패널 설정
// 패널 1: 네임스페이스별 에러 로그 수 (시계열)
{
"title": "Error Rate by Namespace",
"type": "timeseries",
"targets": [{
"expr": "sum(rate({namespace=~\".+\"} |= \"ERROR\" [5m])) by (namespace)",
"legendFormat": "{{namespace}}"
}]
}
// 패널 2: 최근 에러 로그 (Logs 패널)
{
"title": "Recent Errors",
"type": "logs",
"targets": [{
"expr": "{namespace=\"production\"} |= \"ERROR\" | limit 200",
"legendFormat": ""
}]
}
// 패널 3: 로그 볼륨 (스택 바)
{
"title": "Log Volume",
"type": "barchart",
"targets": [{
"expr": "sum(count_over_time({namespace=~\".+\"} [1h])) by (app)",
"legendFormat": "{{app}}"
}]
}
알림(Alert) 설정
# Grafana Alert Rule — 1분간 에러 로그 10개 초과 시 알림
apiVersion: 1
groups:
- orgId: 1
name: loki-alerts
folder: Kubernetes
interval: 1m
rules:
- uid: loki-error-alert
title: "High Error Rate"
condition: C
data:
- refId: A
queryType: range
relativeTimeRange:
from: 300
to: 0
model:
expr: 'sum(count_over_time({namespace="production"} |= "ERROR" [1m]))'
- refId: C
type: classic_conditions
model:
conditions:
- type: query
evaluator:
type: gt
params: [10]
트러블슈팅
Loki를 배포하고 Grafana에서 {namespace="production"} 쿼리를 실행했는데 "No data" 또는 빈 결과가 반환됩니다.
1단계: Promtail DaemonSet Pod 상태 확인
# 모든 노드에서 Promtail이 Running 상태인지 확인
kubectl get daemonset loki-promtail -n monitoring
# DESIRED와 READY가 같아야 함
# DESIRED CURRENT READY UP-TO-DATE AVAILABLE
# 3 3 3 3 3
# 특정 노드 Promtail Pod 로그 확인
kubectl logs -n monitoring -l app=promtail --tail=50
# 에러 메시지 패턴:
# level=error ... msg="error connecting to loki" err="connection refused"
# level=warn ... msg="failed to send batch" err="Post ... : dial tcp..."
# level=error ... msg="error reading log file" err="permission denied"
- kubectl logs <promtail-pod> -n monitoring에서 "error sending batch" 또는 "connection refused" 메시지를 먼저 확인 — Loki URL이 잘못됐거나 Loki 파드가 Ready 상태가 아닌 것
- Grafana Explore에서 LogQL 쿼리 실행 후 결과가 0개이면: 레이블 값 확인 필요. {app="nginx"}에서 app 레이블 값이 실제 파드 레이블과 다른 경우가 가장 흔함. kubectl get pods --show-labels로 실제 레이블 값 대조
- Promtail DaemonSet DESIRED와 READY 수치가 다르면 → 일부 노드 로그 미수집 상태. kubectl describe ds promtail로 특정 노드의 파드가 왜 뜨지 않는지 Events 확인
2단계: Loki Service 연결 확인
# Loki Service 이름과 포트 확인
kubectl get svc -n monitoring | grep loki
# Promtail ConfigMap에서 Loki URL 확인
kubectl get configmap loki-promtail -n monitoring -o yaml | \
grep -A3 "clients:"
# Promtail Pod 내부에서 Loki 연결 테스트
kubectl exec -n monitoring -it $(kubectl get pod -n monitoring -l app=promtail -o name | head -1) \
-- wget -qO- http://loki-gateway:80/ready
# 출력: "ready" 라면 정상
3단계: 로그 파일 마운트 확인
# Promtail Pod에 /var/log/pods 가 마운트됐는지 확인
kubectl exec -n monitoring \
$(kubectl get pod -n monitoring -l app=promtail -o name | head -1) \
-- ls /var/log/pods/
# 특정 네임스페이스 파드 로그 파일 존재 확인
kubectl exec -n monitoring \
$(kubectl get pod -n monitoring -l app=promtail -o name | head -1) \
-- ls /var/log/pods/ | grep "^production"
4단계: Promtail 수집 상태 API 확인
# Promtail Pod 포트포워딩
kubectl port-forward -n monitoring \
$(kubectl get pod -n monitoring -l app=promtail -o name | head -1) \
9080:9080
# 수집 중인 타겟 확인
curl -s http://localhost:9080/targets | grep -E "state|filename"
# state: "success" 여야 함
# state: "dropped" 라면 relabel 설정 문제
# tail 중인 파일 목록
curl -s http://localhost:9080/targets | jq '.[].labels'
5단계: Loki 수신 상태 확인
# Loki 포트포워딩
kubectl port-forward svc/loki -n monitoring 3100:3100
# 메트릭 확인 — 수신된 로그 청크 수
curl -s http://localhost:3100/metrics | grep "loki_ingester_chunks_stored_total"
# Loki 레이블 목록 (데이터가 있으면 여기 나타남)
curl -s "http://localhost:3100/loki/api/v1/labels" | jq '.data'
흔한 원인과 해결:
# 원인 1: Promtail ConfigMap의 Loki URL이 잘못됨
# helm values 수정 후 재배포
helm upgrade loki grafana/loki-stack -n monitoring \
--set promtail.config.clients[0].url=http://loki:3100/loki/api/v1/push
# 원인 2: RBAC 권한 부족 (Promtail이 Pod 메타데이터를 못 읽음)
kubectl auth can-i list pods --as=system:serviceaccount:monitoring:loki-promtail
# "no" 라면 ClusterRole 수정 필요
# 원인 3: 노드에 Promtail이 배포 안 됨 (Taint 문제)
kubectl describe nodes | grep -E "Taints:|Name:"
kubectl get daemonset loki-promtail -n monitoring -o yaml | grep -A5 tolerations
심화 — Loki가 로그를 '조용히' 버리는 지점
심화: Loki 쓰기 경로 — distributor·ingester와 rate limit
"Promtail도 Running, Loki도 Running이니 로그는 다 들어오겠지"에서 설계를 멈추면, 정작 트래픽이 몰리는 날 로그가 비어 있어 당황합니다. 로그가 Promtail을 떠나 저장되기까지는 여러 단계를 거치고, 각 단계에는 조용히 로그를 떨어뜨리는 지점이 있습니다.
쓰기 경로는 Promtail → (HTTP push) → distributor → ingester → chunk → object storage 순서입니다.
- distributor의 한도 검사: 들어온 요청은 먼저 distributor가 검증합니다. 여기서 테넌트 전체 수신량(
ingestion_rate_mb·ingestion_burst_size_mb)과 스트림 단위 한도(per_stream_rate_limit)를 초과하면 429를 돌려주고 그 배치를 거부합니다. 거부는 Loki가 죽은 게 아니라 "정상 동작으로서의 방어"입니다. - 오래된 로그 거부:
reject_old_samples가 켜져 있으면reject_old_samples_max_age보다 오래된 타임스탬프의 라인은 버려집니다. 지연 수집·백필 상황에서 흔히 걸립니다. - 스트림 수 한도:
max_streams_per_user를 넘으면 새 스트림 생성이 막힙니다(카디널리티 폭발의 실제 벽). - ingester와 flush: ingester는 청크를 메모리에 들고 있다가 크기·시간 기준으로 object storage에 flush합니다. WAL이 크래시를 보호하지만, 한도에 걸려 애초에 받지 못한 로그는 WAL에도 없습니다.
핵심은 Promtail은 429/500을 받으면 곧바로 포기하지 않고 백오프로 재시도한다는 점입니다. 하지만 거부가 지속되면 Promtail의 전송 버퍼가 차고, 그때부터 오래된 로그부터 버립니다. 그래서 "Loki가 떠 있다 ≠ 모든 로그가 저장된다"이고, 유실은 조용히 — 에러 페이지 없이 그래프의 빈칸으로만 — 드러납니다.
상황: 모든 파드가 Running이고 connection refused 같은 연결 오류도 없습니다. 그런데 피크 시간대에 유독 로그가 많은 한 앱의 로그가 Grafana에서 듬성듬성 빕니다. 정작 해당 파드에 kubectl logs를 걸면 그 라인들은 멀쩡히 찍혀 있습니다 — 앱은 로그를 남겼는데 Loki에만 없습니다.
원인: 그 앱의 스트림이 per_stream_rate_limit(또는 테넌트 전체 ingestion_rate_mb)을 버스트 구간에만 초과했습니다. distributor가 초과분을 429로 거부했고, Promtail이 백오프 재시도를 하는 사이 전송 버퍼가 차서 오래된 배치부터 버려졌습니다. 그래서 유실이 '피크 때, 그 시끄러운 스트림에만' 국소적으로 나타납니다. 앞의 카디널리티 CB가 '스트림이 너무 많아지는' 문제였다면, 이건 '한 스트림에 너무 많이 몰리는' 반대편 문제입니다.
진단: 먼저 Promtail 로그에서 거부의 흔적을 봅니다.
kubectl logs -n monitoring -l app=promtail --tail=200 | grep -E "status=429|rate limit"
# level=warn ... msg="error sending batch, will retry" status=429
# error="... Per stream rate limit exceeded ..."
그다음 Loki가 실제로 얼마나 버렸는지 지표로 확정합니다.
kubectl port-forward svc/loki -n monitoring 3100:3100
curl -s http://localhost:3100/metrics | grep loki_discarded_samples_total
# loki_discarded_samples_total{reason="per_stream_rate_limit",...} ← 0보다 크면 확정
# loki_discarded_samples_total{reason="rate_limited",...}
reason 라벨이 per_stream_rate_limit/rate_limited이고 그 증가 시점이 빈칸 구간과 일치하면 원인이 확정됩니다.
해결: 근본은 두 방향입니다. (1) 한도를 워크로드에 맞게 올리기 — limits_config의 per_stream_rate_limit·per_stream_rate_limit_burst·ingestion_rate_mb를 그 앱의 정상 피크를 감당하도록 상향합니다. (2) 원천에서 양을 줄이기 — Promtail pipeline_stages의 drop/match로 무의미한 debug 라인을 수집 전에 버려 스트림 부담을 낮춥니다. 그리고 재발을 눈에 보이게 만들려면 loki_discarded_samples_total에 알람을 걸어(Prometheus Operator와 Grafana 연동 대시보드 구축), 다음엔 그래프 빈칸을 발견하기 전에 '버려지고 있다'는 신호를 먼저 받도록 합니다.
시나리오: 결제 서비스 간헐적 오류 — 멀티 파드 환경에서 로그로 원인 특정
금요일 오후 6시, 고객센터에서 "결제가 간헐적으로 실패한다"는 보고가 들어왔습니다. Deployment에 payment 파드가 5개 실행 중이고, 어느 파드가 문제인지 알 수 없습니다.
# Step 1: 최근 1시간 결제 서비스 에러 전수 조회
{namespace="production", app="payment"} |= "ERROR" | limit 500
# Step 2: 에러 패턴 파악 — JSON 파싱 후 error_type 집계
{namespace="production", app="payment"}
| json
| error_type != ""
| line_format "{{.pod}} {{.error_type}} {{.message}}"
# Step 3: 특정 파드에 에러가 집중되는지 확인
sum(count_over_time(
{namespace="production", app="payment"} |= "ERROR" [1h]
)) by (pod)
# 출력 예시:
# {pod="payment-7d9b4c8f6-xkp2n"} → 142건
# {pod="payment-7d9b4c8f6-abc12"} → 3건
# {pod="payment-7d9b4c8f6-def34"} → 2건
# xkp2n 파드에 집중 → 해당 파드 단독 조사
# Step 4: 해당 파드 상세 로그 시간순 조회
{pod="payment-7d9b4c8f6-xkp2n"} | limit 200
# Step 5: 에러 발생 직전 컨텍스트 파악
{pod="payment-7d9b4c8f6-xkp2n"}
| json
| line_format "{{.time}} [{{.level}}] {{.message}}"
| limit 50
# 발견: "DB connection pool exhausted" 에러가 반복됨
# → 해당 파드 환경변수의 DB_POOL_SIZE 설정 확인
kubectl describe pod payment-7d9b4c8f6-xkp2n -n production | grep DB_POOL
# DB_POOL_SIZE: 5 ← 다른 파드는 20, 이 파드만 재배포 시 설정 누락됨
Loki 없이 kubectl logs를 파드 5개에 수동으로 실행해서 패턴을 찾았다면 20~30분은 걸렸을 작업을 LogQL 쿼리 몇 줄로 5분 내에 완료했습니다. 실제 프로덕션에서는 파드 수십 개, 네임스페이스 수십 개에서 이 차이가 더 극적으로 드러납니다.
Loki Helm 저장소 추가 및 설치
helm repo add grafana https://grafana.github.io/helm-charts && helm repo update
helm install loki grafana/loki-stack -n monitoring --create-namespace --set grafana.enabled=true예상 출력
NAME: loki LAST DEPLOYED: ... STATUS: deployed
Promtail DaemonSet 및 Loki 파드 상태 확인
kubectl get pods -n monitoring
kubectl get daemonset loki-promtail -n monitoring예상 출력
NAME DESIRED CURRENT READY loki-promtail ... ... ...
Promtail 로그 수집 상태 확인
kubectl logs -n monitoring -l app=promtail --tail=20 | grep -E 'level=info|level=error' | head -10예상 출력
level=info msg="Tailing new file" path=/var/log/pods/
Grafana 관리자 패스워드 확인 및 포트 포워딩
GRAFANA_ADMIN_PASSWORD=$(kubectl get secret loki-grafana -n monitoring -o jsonpath='{.data.admin-password}' | base64 -d)
export GRAFANA_ADMIN_PASSWORD
kubectl port-forward svc/loki-grafana -n monitoring 3000:80 &예상 출력
dev-password-123
Loki API로 레이블 수집 확인
kubectl port-forward svc/loki -n monitoring 3100:3100 &
sleep 3 && curl -s http://localhost:3100/loki/api/v1/labels | jq '.data'예상 출력
["app", "container", "namespace", "pod"]
핵심 요약
| 구성요소 | 역할 | 배포 방식 |
|---|---|---|
| Loki | 로그 저장, LogQL 처리 | StatefulSet |
| Promtail | 노드 로그 수집, Loki 전송 | DaemonSet |
| Grafana | 시각화, 알림 | Deployment |
LogQL 필터 우선순위: 레이블 셀렉터({}) → 라인 필터(\|=, !=, \|~) → 파서(\| json) → 레이블 필터 → 포맷(\| line_format)
카디널리티 원칙: 레이블은 낮은 카디널리티 값만 (app, namespace, level). 고유값(user_id, request_id)은 로그 내용 안에 두고 라인 필터로 검색.
명령어·단축키 빠른 참조
이 모듈에서 다룬 Promtail 진단·Loki API·LogQL 명령을 실전 옵션과 함께 모았습니다. LogQL은 레이블로 스트림을 좁힌 뒤 라인 필터로 검색하는 순서가 핵심입니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl logs -l app=promtail | 수집기 로그로 1차 진단 | kubectl logs -n monitoring -l app=promtail --tail=200 | grep -E "status=429|rate limit" |
kubectl get daemonset | Promtail 노드별 배포 상태(DESIRED=READY) | kubectl get ds loki-promtail -n monitoring |
kubectl describe daemonset | hostPath 마운트·tolerations 확인 | kubectl describe ds loki-promtail -n monitoring |
kubectl port-forward | Grafana·Loki API 로컬 접속 | kubectl port-forward svc/loki-grafana -n monitoring 3000:80 |
kubectl get secret -o jsonpath | Grafana admin 패스워드 추출 | kubectl get secret loki-grafana -n monitoring -o jsonpath='{.data.admin-password}' | base64 -d |
curl .../loki/api/v1/labels | Loki에 수집된 레이블 확인 | curl -s http://localhost:3100/loki/api/v1/labels | jq '.data' |
curl .../metrics | grep | 버려진 로그(rate limit) 지표 확정 | curl -s http://localhost:3100/metrics | grep loki_discarded_samples_total |
| LogQL 레이블 셀렉터 | 인덱싱된 레이블로 스트림 선택 | {namespace="production", app="payment"} |
| LogQL 라인 필터 | 스트림 내 문자열 검색(grep) | {app="nginx"} |= "ERROR" · != "health" · |~ "timeout|refused" |
| LogQL 파서·포맷 | JSON 파싱 후 필드 추출·정렬 | {app="payment"} | json | line_format "{{.level}} {{.message}}" |
| LogQL 메트릭 쿼리 | 로그에서 초당 rate·건수 집계 | sum(rate({namespace=~".+"} |= "ERROR" [5m])) by (namespace) · count_over_time({...}[1h]) |
kubectl auth can-i | Promtail RBAC(파드 메타데이터 read) 점검 | kubectl auth can-i list pods --as=system:serviceaccount:monitoring:loki-promtail |
관련 모듈로 더 깊이:
- Prometheus Operator와 Grafana 연동 대시보드 구축 — 로그(Loki)와 짝을 이루는 메트릭 기둥, 같은 Grafana에서 통합 관측하는 법
- Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드 — 수집한 로그를 CrashLoopBackOff·OOMKilled 같은 실제 장애 진단에 적용하는 절차
- 컨테이너 로그 유실 방지와 효율적인 실시간 로깅 전략 — 컨테이너 stdout/stderr 로그 유실을 막는 Docker 로깅 드라이버, 중앙 수집의 출발점 (Docker 트랙)
다음 모듈 k8s-troubleshooting에서는 Loki 로그와 Prometheus 메트릭을 활용해 CrashLoopBackOff, OOMKilled, 스케줄링 실패 같은 실제 장애를 체계적으로 진단하는 방법을 다룹니다. 로그와 메트릭이 결합됐을 때 문제 원인을 얼마나 빠르게 좁힐 수 있는지 실습합니다.