API 서버의 메모리 사용량이 매주 늘어나는데 requests 값은 배포 첫날 그대로입니다. 너무 낮은 requests는 노드 압박을 만들고, 너무 높은 requests는 비용 낭비로 이어집니다. VPA는 실제 사용량을 기반으로 리소스 요청값을 조정하는 방법을 제공합니다.
VPA — 수직 파드 오토스케일러
팀에서 새로운 마이크로서비스를 배포할 때마다 이런 대화가 반복됩니다. "CPU requests를 얼마로 설정해야 하죠?" "일단 250m으로 해보죠." "메모리는요?" "512Mi?" 운이 좋으면 파드가 잘 돌아가지만, 실제 사용량은 requests의 30%에 불과해 자원이 낭비되거나, 반대로 limits에 걸려 파드가 OOM으로 죽기를 반복합니다. VPA(Vertical Pod Autoscaler)는 이 문제를 해결합니다. 파드의 실제 CPU/메모리 사용 패턴을 분석하여 최적의 requests와 limits를 자동으로 조정합니다. HPA가 "파드를 몇 개 띄울지" 결정한다면, VPA는 "각 파드가 얼마나 큰지"를 결정합니다. 이 모듈에서는 VPA의 세 가지 운영 모드와 실무에서 가장 안전하게 사용하는 방법을 다룹니다.
- 1VPA 아키텍처(Recommender, Updater, Admission Controller)를 설명할 수 있다
- 2Off, Initial, Auto 모드를 비교해 사용 시나리오를 선택할 수 있다
- 3minAllowed, maxAllowed, updatePolicy로 VPA를 설정할 수 있다
- 4HPA와 VPA의 선택 기준과 동시 사용 주의사항을 설명할 수 있다
- 5추천값 분석으로 현재 리소스 설정을 최적화할 수 있다
- 6VPA Auto 모드의 파드 재시작 최소화 전략을 적용할 수 있다
kubectl get deployment -n kube-system | grep vpakubectl get crd | grep verticalpodautoscalerkubectl top nodeskubectl apply -f https://github.com/kubernetes/autoscaler/releases/latest/download/vpa-v1-crd-gen.yamlVPA 아키텍처
VPA는 세 개의 컴포넌트로 동작합니다.
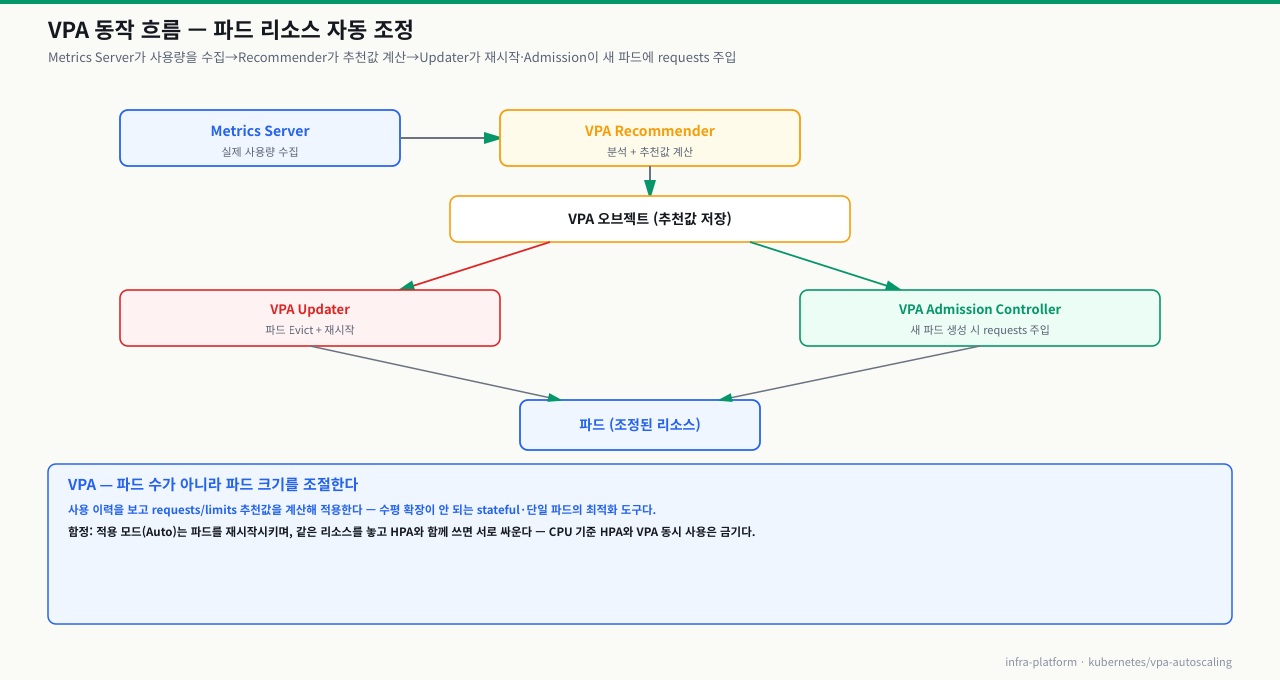 확대
확대
VPA가 파드 자원을 조정하기까지 — 관측에서 재생성까지 5단계
VPA에 requests를 맡겨두면 언젠가 파드의 CPU·메모리 요청값이 실사용에 맞게 바뀝니다. 그런데 이 조정은 즉시·무중단이 아니라 관측 → 추천 계산 → 모드별 적용의 파이프라인을 거치고, Auto일 때만 파드를 재생성해 반영합니다. 이 흐름을 단계로 알면 "왜 추천만 뜨고 안 바뀌지", "왜 자꾸 재시작하지", "Target은 계산됐는데 왜 파드는 그대로지"를 어느 단계의 문제인지로 좁힐 수 있습니다.
[Metrics Server] 파드별 CPU·메모리 실사용량 수집
│
① 관측: Recommender가 사용량 히스토리를 축적
│
② 추천 계산: percentile 분석으로 Lower/Target/Upper 산출
│ → minAllowed·maxAllowed로 상·하한 클램프해 VPA 오브젝트에 저장
│ (여기까지는 파드를 건드리지 않음)
│
③ 모드 분기: updateMode에 따라 적용 방식 결정
│ Off → 여기서 멈춤 (추천만)
│ Initial → 파드가 새로 생성될 때만 주입
│ Auto → 아래 ④로
│
④ (Auto) evict: Updater가 추천과 크게 어긋난 파드를 Eviction API로 축출
│ → 이 evict는 PDB·레플리카 수 제약을 받음
│
⑤ 주입: 재생성되는 파드에 Admission Controller가 새 requests 주입
│ → request:limit 비율을 유지해 limit도 비례 상승
▼
[클러스터] 새 requests로 뜬 파드 (Off/Initial이면 옛 requests 유지)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 막히면 증상 |
|---|---|---|
| ① 관측 | Metrics Server 사용량을 Recommender가 히스토리로 축적 | metrics-server 미설치·다운 → 추천이 아예 계산 안 됨(Recommendation: not set) |
| ② 추천 계산 | percentile로 Lower/Target/Upper 산출, minAllowed·maxAllowed로 클램프 | 수집 초기엔 데이터 부족으로 추천 미확정 · 스파이크가 크면 Target 과대 계산 |
| ③ 모드 분기 | Off=추천만 / Initial=생성 시 주입 / Auto=지속 적용 | Off인데 반영을 기대하면 영영 안 바뀜(수동 patch 필요) |
| ④ evict(Auto) | Updater가 어긋난 파드를 Eviction API로 축출 | PDB 예산 0·단일/부족 레플리카면 evict 봉쇄 → Target 있어도 무동작 |
| ⑤ 주입 | 재생성 파드에 새 requests 주입, request:limit 비율 유지 | maxAllowed 미설정 시 limit이 과도히 커져 노드 오버커밋 위험 |
즉 VPA의 "적용"은 evict → 재생성이 유일한 경로라, ④가 막히면 ①②에서 추천이 완벽해도 파드는 첫날 값 그대로입니다. Off·Initial이 ③에서 멈추는 것은 정상이고, Auto 무동작은 ④(PDB·레플리카)를, 잦은 재시작은 ②의 추천 급변을 봅니다. 하나 더 — HPA와 VPA로 CPU를 동시에 제어하면 ②가 requests(HPA 사용률 계산의 분모)를 흔들어 스케일이 요동치므로, 함께 쓸 땐 controlledResources: ["memory"]로 역할을 분리합니다.
Off / Initial / Auto 모드 비교
신규 서비스 배포 후 "requests를 얼마로 설정해야 하죠?"라는 질문이 항상 나옵니다. 과도하게 높으면 노드 자원이 낭비되고, 너무 낮으면 OOM이 발생합니다. VPA는 세 가지 모드로 이 문제에 접근합니다. Off 모드는 실제 사용량을 분석해 추천값만 제시하고 직접 건드리지 않습니다. Initial 모드는 파드 시작 시 한 번만 적용합니다. Auto 모드는 지속적으로 모니터링하며 자동으로 파드를 재시작해 최적값을 유지합니다. 처음 VPA를 도입할 때는 Off 모드로 시작해 추천값을 검토한 후 단계적으로 적용하는 것이 안전합니다.
# 1. Off 모드 — 추천만, 적용 안 함 (안전한 시작점)
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: api-server-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
updatePolicy:
updateMode: "Off" # 추천만 하고 파드 변경 안 함
resourcePolicy:
containerPolicies:
- containerName: api
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 2000m
memory: 4Gi
controlledResources: ["cpu", "memory"]
 확대
확대
# Off 모드 추천값 확인
kubectl describe vpa api-server-vpa -n production
# Recommendation:
# Container Recommendations:
# Container Name: api
# Lower Bound:
# Cpu: 150m ← 현재보다 낮추는 것이 가능한 하한
# Memory: 256Mi
# Target:
# Cpu: 380m ← VPA가 권장하는 최적값
# Memory: 512Mi
# Upper Bound:
# Cpu: 800m ← 피크 트래픽 대비 상한 추천
# Memory: 1Gi
# Uncapped Target:
# Cpu: 380m ← minAllowed/maxAllowed 제한 없이 계산한 값
# Memory: 512Mi
# 2. Initial 모드 — 파드 시작 시에만 적용, 이후 변경 안 함
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: batch-job-vpa
namespace: production
spec:
targetRef:
apiVersion: batch/v1
kind: Job
name: etl-job
updatePolicy:
updateMode: "Initial" # 파드 생성 시에만 requests 주입
resourcePolicy:
containerPolicies:
- containerName: etl
minAllowed:
cpu: 500m
memory: 1Gi
maxAllowed:
cpu: 8000m
memory: 32Gi
# 3. Auto 모드 — 지속적으로 추천값 적용 (파드 재시작 포함)
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: worker-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: background-worker
updatePolicy:
updateMode: "Auto"
# 최소 업데이트 간격 설정 (기본값은 없음)
minReplicas: 2 # 최소 2개 실행 중일 때만 Evict 허용
resourcePolicy:
containerPolicies:
- containerName: worker
minAllowed:
cpu: 200m
memory: 256Mi
maxAllowed:
cpu: 4000m
memory: 8Gi
# limits를 requests 대비 비율로 자동 설정
controlledResources: ["cpu", "memory"]
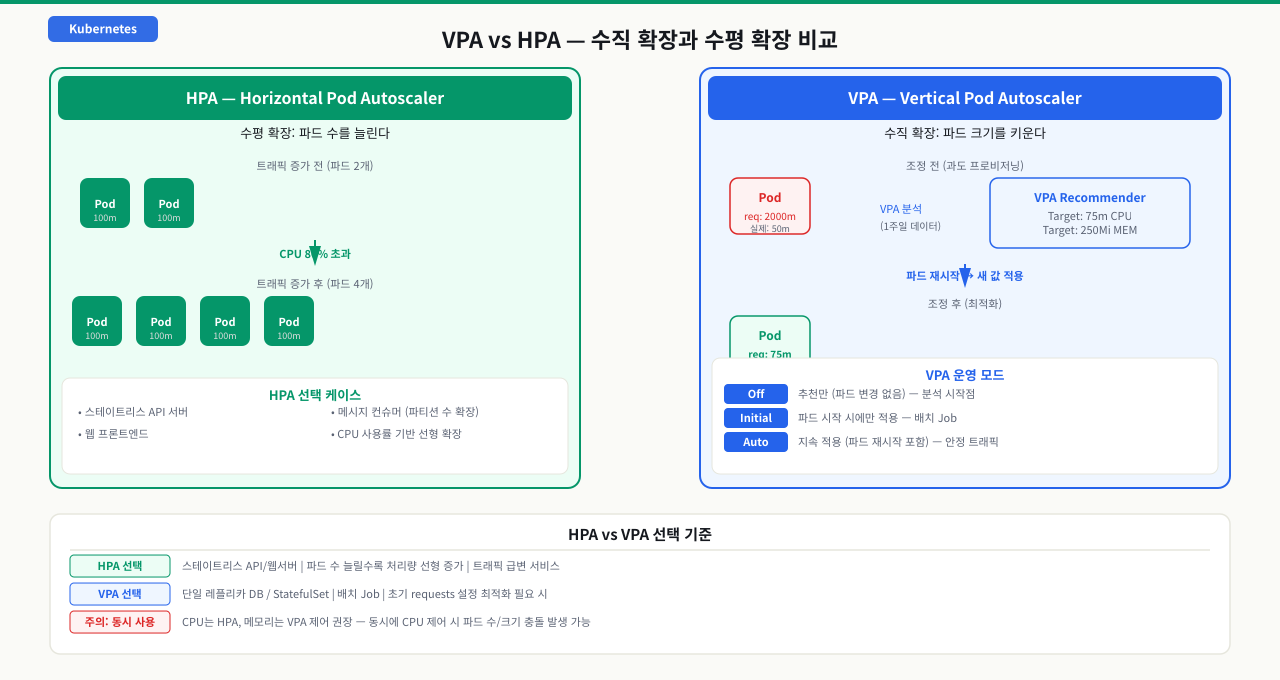
HPA vs VPA 선택 기준
트래픽이 몰릴 때 파드를 더 띄울지, 아니면 각 파드에 더 많은 자원을 줄지 판단해야 합니다. 잘못 선택하면 HPA가 파드를 늘리는 동안 VPA가 그 파드를 재시작시키는 충돌이 생길 수도 있습니다. HPA는 스테이트리스 서비스의 인스턴스 수를 조정하고, VPA는 수평 확장이 불가능한 서비스의 파드 크기를 조정합니다. 서비스 특성에 맞는 선택이 불필요한 재시작과 과금을 줄입니다.
| HPA 선택 (수평 확장 가능) | VPA 선택 (수직 확장 필요) |
|---|---|
| 스테이트리스 API 서버 | 단일 레플리카 DB (Postgres, Redis) |
| 웹 프론트엔드 | 상태 저장 서비스 (StatefulSet) |
| 메시지 컨슈머 (파티션 수만큼 확장) | 배치 Job (더 큰 메모리로 빠르게) |
| 파드 수 늘릴 때 선형 처리량 증가 | 사이드카 컨테이너 (리소스 추정 어려움) |
| 초기 requests/limits 설정 최적화 |
동시 사용 주의: HPA는 CPU 사용률 기반으로 파드 수를 조정하는데, VPA가 requests를 올리면 CPU 사용률이 떨어진다. HPA가 파드를 줄이고 VPA가 requests를 올리는 사이클이 발생할 수 있으므로, 동시 사용 시 VPA에서 CPU 제어를 비활성화하고 메모리만 제어한다.
# HPA + VPA 동시 사용 시 — CPU는 HPA, 메모리는 VPA
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: api-server-vpa-mem-only
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: api
# CPU는 VPA가 건드리지 않음 (HPA가 CPU 메트릭으로 파드 수 조정)
controlledResources: ["memory"]
minAllowed:
memory: 256Mi
maxAllowed:
memory: 8Gi
실습: 리소스 낭비 파드 최적화
# 1. 과도하게 큰 requests를 가진 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: over-provisioned
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: over-provisioned
template:
metadata:
labels:
app: over-provisioned
spec:
containers:
- name: app
image: nginx
resources:
requests:
cpu: 2000m # 실제 사용량은 50m 수준
memory: 4Gi # 실제 사용량은 200Mi 수준
limits:
cpu: 4000m
memory: 8Gi
EOF
# 2. 실제 사용량 확인
kubectl top pods -l app=over-provisioned
# NAME CPU(cores) MEMORY(bytes)
# over-provisioned-aaa 52m 185Mi
# over-provisioned-bbb 48m 192Mi
# ← requests의 2.5%만 사용 중
- kubectl describe vpa <name>에서 Recommendation 섹션 먼저 확인 — LowerBound/Target/UpperBound가 있으면 VPA가 데이터를 수집 중. "Recommendation: (not set)"이면 아직 데이터 부족(Off 모드로 7일 이상 관측 권장)
- VPA Target의 memory 추천값 기준: 현재 kubectl top pod 값의 1.2~1.5배가 정상적인 추천값. 10배 이상 높은 추천값이 나오면 메모리 누수 또는 스파이크 패턴 — 실제 사용 패턴을 먼저 분석
- VPA Auto 모드에서 파드가 자주 재시작되면 → 추천값이 minAllowed보다 낮아 충돌 중이거나, HPA와 동시 사용으로 레이스 컨디션 발생. HPA와 VPA를 함께 쓸 때는 VPA의 controlledResources에서 CPU를 제외하고 memory만 제어
# 3. VPA Off 모드로 추천값 수집 (1-7일 데이터 수집 권장)
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: over-provisioned-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: over-provisioned
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: app
minAllowed:
cpu: 25m
memory: 64Mi
maxAllowed:
cpu: 500m
memory: 1Gi
kubectl apply -f over-provisioned-vpa.yaml
# 24시간 후 추천값 확인
kubectl describe vpa over-provisioned-vpa
# Target:
# Cpu: 75m ← 2000m → 75m으로 조정 추천
# Memory: 250Mi ← 4Gi → 250Mi로 조정 추천
# 4. 추천값을 Deployment에 수동 적용
kubectl patch deployment over-provisioned --type=json -p='[
{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/cpu", "value": "75m"},
{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/memory", "value": "250Mi"},
{"op": "replace", "path": "/spec/template/spec/containers/0/resources/limits/cpu", "value": "200m"},
{"op": "replace", "path": "/spec/template/spec/containers/0/resources/limits/memory", "value": "500Mi"}
]'
# 절감 효과
echo "CPU requests 절감: 2000m → 75m (96% 절감)"
echo "Memory requests 절감: 4Gi → 250Mi (94% 절감)"
API 서버에 VPA Auto 모드를 적용했더니 하루에도 수십 번 파드가 재시작되고 있습니다. 재시작 중에는 서비스 중단이 발생하고, HPA로 파드 수를 늘려도 VPA가 계속 재시작시킵니다.
# 증상 확인
kubectl get pods -l app=api-server -w
# api-server-aaa Running → Terminating → Running (1시간에 3-4회 반복)
kubectl describe pod api-server-aaa | grep -A 5 "Events:"
# Warning Evicted VPA Updater evicted pod api-server-aaa
# to apply resource recommendation
# 원인 분석: VPA 추천값 변화 빈도 확인
kubectl describe vpa api-server-vpa
# Last Update Time: 2024-01-15 14:23:01 ← 빈번한 업데이트
# Last Update Time: 2024-01-15 14:18:44
# Last Update Time: 2024-01-15 14:11:22
# ← 5분마다 추천값이 크게 변동
# 트래픽 패턴 분석
kubectl top pods -l app=api-server --containers
# 09:00 api-server cpu: 50m memory: 200Mi (야간 트래픽)
# 12:00 api-server cpu: 800m memory: 1.2Gi (점심 피크)
# 15:00 api-server cpu: 200m memory: 400Mi (오후)
# ← 낮과 밤의 사용량 차이가 16배 → VPA 추천값이 급변
# 해결책 1: Auto → Initial 모드로 변경 (일일 1회 롤링 업데이트 방식)
kubectl patch vpa api-server-vpa --type=merge -p '
{"spec": {"updatePolicy": {"updateMode": "Initial"}}}'
# 해결책 2: Auto 모드 유지 + minAllowed/maxAllowed 범위 좁히기
# (추천값 변화 범위를 제한하여 Evict 빈도 감소)
kubectl patch vpa api-server-vpa --type=merge -p '
{
"spec": {
"resourcePolicy": {
"containerPolicies": [{
"containerName": "api",
"minAllowed": {"cpu": "200m", "memory": "400Mi"},
"maxAllowed": {"cpu": "1000m", "memory": "2Gi"}
}]
}
}
}'
# 범위를 좁히면 추천값의 최대 변화폭이 줄어들어 재시작 빈도 감소
# 해결책 3: Off 모드로 전환 후 수집한 추천값을 주기적으로 수동 적용
# 주 1회 리뷰 → 허용 변화량 초과 시 Deployment 직접 패치
# 해결책 4 (권장): 트래픽 패턴이 불규칙하면 HPA + 고정 resources 조합
# VPA로 '안정 구간'의 적정 requests 찾은 후 HPA로 파드 수 조정
# 1. VPA Off 모드 1주일 → 야간 최솟값 확인 (e.g., cpu 200m, mem 512Mi)
# 2. requests를 해당 값으로 고정
# 3. HPA로 CPU 80% 기준 파드 수 자동 조정
# → 재시작 없이 트래픽 변화에 대응
# 최종 안정 설정 확인
kubectl top pods -l app=api-server
kubectl get hpa api-server-hpa
핵심 교훈: VPA Auto 모드는 안정적인 트래픽 패턴을 가진 서비스에 적합합니다. 낮과 밤의 사용량 차이가 크거나 이벤트성 트래픽이 있는 서비스는 VPA Off 모드로 최적 기준값을 찾은 후 HPA를 조합하는 것이 더 안정적입니다.
심화 — VPA가 '아무 일도 안 하는' 조용한 무동작
심화: VPA는 어떻게 '적용'하나 — Updater·eviction·limit 비율의 진실
앞 TroubleCase는 VPA Auto가 파드를 '너무 자주' 재시작하는 문제였습니다. 그런데 정반대 — VPA Auto인데 며칠째 아무것도 안 바뀌는 조용한 무동작도 흔합니다. 이걸 이해하려면 VPA가 추천을 실제로 어떻게 적용하는지를 알아야 합니다.
VPA의 적용 경로는 세 컴포넌트로 나뉩니다.
- Recommender: 사용량을 분석해 Target을 계산하고 checkpoint에 저장합니다(여기까지는 파드를 안 건드립니다).
- Updater: 현재 파드가 추천과 크게 어긋나면 그 파드를 evict합니다. 살아있는 파드의 requests를 직접 못 바꾸므로, VPA는 evict → 재생성으로만 적용됩니다(그래서 재시작이 따라옵니다).
- Admission Controller: 재생성되는 파드에 새 requests를 주입합니다.
여기서 핵심은 Updater의 evict가 Eviction API를 거친다는 점입니다. 즉 evict도 PDB의 지배를 받습니다. 대상 워크로드의 PDB 예산이 0이거나(앞 pod-disruption-budget 모듈), 레플리카가 부족/단일이면 Updater가 안전을 위해 evict를 못 해 추천값이 영원히 적용되지 않습니다 — Target은 describe에 떠 있는데 파드는 첫날 그대로인 무동작이 됩니다.
두 가지 더 알아둘 점이 있습니다. 첫째, VPA는 requests만이 아니라 원래 파드의 request:limit 비율을 유지하며 limits도 비례해 올립니다 — 원래 limit이 request의 4배였다면 추천 request가 오를 때 limit도 4배로 커져 노드 오버커밋을 부를 수 있으니 maxAllowed로 상한을 꼭 겁니다. 둘째, VPA는 반응이 분 단위 + eviction이 필요하므로 갑작스런 메모리 폭증은 못 막습니다 — VPA가 손쓰기 전에 OOMKill이 납니다. VPA는 '추세 최적화'이지 'OOM 실시간 방어'가 아닙니다.
상황: VPA를 Auto로 설정했고 kubectl describe vpa에는 Target 추천값이 잘 계산돼 있습니다. 그런데 파드의 requests는 배포 첫날 그대로이고, 앞 사례처럼 잦은 재시작도 전혀 없습니다. VPA가 고장 난 것처럼 보입니다.
원인: Updater가 추천을 적용하려면 파드를 evict해야 하는데, 그 evict가 막혀 있습니다. 두 갈래입니다. (a) 대상 워크로드에 PDB가 걸려 있고 예산이 0(또는 minAvailable이 빡빡)이라 Eviction API가 거부, 또는 (b) 레플리카가 부족하거나 단일이라 Updater가 안전을 위해 evict를 보류. 그래서 추천은 계산되지만 적용은 안 되는 조용한 무동작이 됩니다.
진단: Target은 있는데 requests가 그대로인지, 그리고 eviction이 막힐 조건인지를 확인합니다.
kubectl describe vpa <name> -n <ns> | grep -A8 "Recommendation" # Target은 존재
kubectl get pod <pod> -n <ns> -o jsonpath='{.spec.containers[0].resources.requests}' # 옛 값 그대로
kubectl get pdb -n <ns> # ALLOWED DISRUPTIONS 확인
kubectl get deploy <target> -n <ns> # 레플리카 수 확인
kubectl logs -n kube-system -l app=vpa-updater | grep -iE "evict|disruption|pdb"
Target이 있는데 requests가 안 바뀌고, 대상 PDB의 ALLOWED DISRUPTIONS가 0이거나 레플리카가 부족하면 eviction 봉쇄로 확정입니다.
해결: 원인에 맞춰 evict가 가능하게 열어줍니다. (1) PDB 여유 확보 — 대상 워크로드 PDB를 maxUnavailable: 1 등으로 조정해 Updater가 한 번에 하나씩 evict할 수 있게 합니다(PDB(PodDisruptionBudget) 설정으로 가용성 지키며 드레인하기). (2) 레플리카 확보 또는 모드 전환 — 단일 레플리카는 VPA Auto가 안전하게 evict하지 못하므로 레플리카를 늘리거나, Auto 대신 Initial/Off + 수동 패치로 추천을 적용합니다(단일 스테이트풀은 유지보수 창에 수동 반영). (3) limit 상한 점검 — 적용이 시작되면 limits도 비율대로 함께 오르므로 maxAllowed로 상한을 반드시 겁니다. 마지막으로 vpa-updater 로그에서 evict 시도가 실제로 일어나는지 추적해 조치 효과를 확인합니다.
시나리오: 신규 서비스의 requests/limits 초기값 설정
백엔드 팀에서 새로운 Java 마이크로서비스를 K8s에 배포하려는데 "requests를 얼마로 설정해야 하죠?"라는 질문이 왔습니다. 부하 테스트 결과가 없어 추정이 어렵습니다.
# 전략: VPA Off 모드로 스테이징에서 1주일 관찰 → 추천값을 프로덕션에 적용
# 1단계: 스테이징 배포 (보수적 초기값)
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-java-service
namespace: staging
spec:
replicas: 2
template:
spec:
containers:
- name: app
image: myrepo/java-service:v1.0
resources:
requests:
cpu: 500m # Java는 시작 시 CPU 소비 많음
memory: 512Mi # JVM 힙 기본 256Mi + 오버헤드
limits:
cpu: 2000m
memory: 2Gi
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: java-service-vpa
namespace: staging
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: new-java-service
updatePolicy:
updateMode: "Off" # 관찰만
resourcePolicy:
containerPolicies:
- containerName: app
minAllowed:
cpu: 100m
memory: 256Mi
maxAllowed:
cpu: 4000m
memory: 4Gi
EOF
# 2단계: 1주일 후 추천값 확인
kubectl describe vpa java-service-vpa -n staging | grep -A 10 "Recommendation:"
# 3단계: 추천값 기반으로 프로덕션 초기값 설정
# Target CPU: 320m → requests: 350m, limits: 1000m
# Target Memory: 768Mi → requests: 800Mi, limits: 1.5Gi
# 4단계: 프로덕션 배포 후 VPA Off 모드로 계속 모니터링
실무 포인트: Java 서비스는 JVM 웜업으로 초기 CPU/메모리가 높고, 안정화 후 낮아집니다. VPA는 최근 사용 패턴을 가중치 있게 반영하므로 웜업 기간 이후 데이터가 충분히 쌓인 후의 추천값이 더 정확합니다. 스테이징에서 최소 1주일(주중+주말 패턴 포함) 관찰을 권장합니다.
과도한 requests를 가진 Deployment 배포
kubectl create deployment over-provisioned --image=nginx -n default
kubectl set resources deployment/over-provisioned --requests=cpu=2000m,memory=4Gi --limits=cpu=4000m,memory=8Gi
kubectl get deployment over-provisioned예상 출력
NAME READY UP-TO-DATE AVAILABLE over-provisioned 1/1 1 1
실제 사용량 확인 — kubectl top
kubectl top pods -l app=over-provisioned예상 출력
NAME CPU(cores) MEMORY(bytes) over-provisioned-... 50m 150Mi
VPA Off 모드 생성 — 추천값 수집 시작
kubectl apply -f - <<EOF
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: over-provisioned-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: over-provisioned
updatePolicy:
updateMode: "Off"
resourcePolicy:
containerPolicies:
- containerName: nginx
minAllowed:
cpu: 25m
memory: 64Mi
maxAllowed:
cpu: 500m
memory: 1Gi
EOF예상 출력
verticalpodautoscaler.autoscaling.k8s.io/over-provisioned-vpa created
VPA 추천값 조회
kubectl describe vpa over-provisioned-vpa | grep -A 10 'Recommendation:'예상 출력
Recommendation:
Container Recommendations:
Container Name: nginx
Target:
Cpu: ...
Memory: ...실습 리소스 정리
kubectl delete vpa over-provisioned-vpa
kubectl delete deployment over-provisioned
echo cleaned예상 출력
verticalpodautoscaler.autoscaling.k8s.io "over-provisioned-vpa" deleted deployment.apps "over-provisioned" deleted cleaned
HPA vs VPA 선택 요약
| 기준 | HPA | VPA |
|---|---|---|
| 확장 방향 | 수평 (파드 수) | 수직 (파드 크기) |
| 적합한 서비스 | 스테이트리스 API | DB, Stateful, 배치 Job |
| 반응 속도 | 빠름 (파드 수 즉시 조정) | 느림 (재시작 필요) |
| 서비스 중단 | 없음 | Auto 모드: 재시작 시 순단 |
| 초기 설정 최적화 | 불가 | Off/Initial 모드로 가능 |
| 동시 사용 | 주의 필요 (CPU 충돌) | 메모리만 VPA 제어 시 가능 |
핵심 요약
| 개념 | 명령/설정 | 실무 사용 빈도 |
|---|---|---|
| VPA 조회 | kubectl get vpa -n <ns> | 리소스 최적화 시 |
| 추천값 확인 | kubectl describe vpa <name> | Off 모드 분석 |
| Off 모드 | updateMode: "Off" | 초기 추천값 수집 |
| Initial 모드 | updateMode: "Initial" | 배치 Job, 안정적 적용 |
| Auto 모드 | updateMode: "Auto" | 안정적 트래픽 서비스 |
| 범위 제한 | minAllowed / maxAllowed | 추천값 급변 방지 |
| CPU+메모리 분리 | controlledResources: ["memory"] | HPA 동시 사용 시 |
| 실제 사용량 확인 | kubectl top pods --containers | VPA 전 현황 파악 |
명령어·단축키 빠른 참조
이 모듈에서 VPA 추천값을 읽고 적용·무동작을 진단할 때 쓴 kubectl 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl get vpa | VPA 오브젝트 조회 | kubectl get vpa -n <ns> |
kubectl describe vpa | 추천값(Target/Lower/Upper) 확인 | kubectl describe vpa X | grep -A10 Recommendation |
kubectl top pods --containers | 컨테이너별 실사용량 확인 | kubectl top pods -l app=X --containers |
kubectl patch vpa --type=merge | updateMode 전환 | kubectl patch vpa X --type=merge -p '{"spec":{"updatePolicy":{"updateMode":"Initial"}}}' |
kubectl patch deployment --type=json | 추천값 수동 반영 | requests/limits를 Target 값으로 replace |
kubectl set resources | requests/limits 조정 | kubectl set resources deploy/X --requests=cpu=75m,memory=250Mi --limits=cpu=200m,memory=500Mi |
kubectl get pdb | eviction 차단(무동작) 확인 | kubectl get pdb -n <ns> (ALLOWED DISRUPTIONS 0=봉쇄) |
kubectl get pod -o jsonpath | 실제 반영된 requests 확인 | ... -o jsonpath='{.spec.containers[0].resources.requests}' |
kubectl describe pod | VPA Evicted 이벤트 확인 | kubectl describe pod X | grep -A5 Events |
kubectl logs vpa-updater | evict 시도 추적 | kubectl logs -n kube-system -l app=vpa-updater | grep -i evict |
updateMode | Off/Initial/Auto 선택 | Off(추천만) · Initial(생성 시) · Auto(지속·재시작) |
관련 모듈로 더 깊이:
- requests와 limits 적정 값 계산과 CPU 스로틀링 대처 — VPA가 자동으로 조정하는 requests/limits의 기본 개념과 QoS 클래스
- HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장 — VPA와 동시에 쓸 때 controlledResources로 충돌을 피하는 수평 스케일링
- Node Affinity와 Taint/Toleration 기반 스케줄링 제어 — 최적화된 자원 크기에 맞춰 파드를 적절한 노드에 배치하는 제약
다음 모듈 node-affinity에서는 파드를 특정 노드에 배치하는 방법을 다룹니다. VPA가 "얼마나 많이 쓸지"를 최적화한다면, Node Affinity는 "어느 노드에서 실행할지"를 제어합니다. GPU 노드 배치, 가용 영역 분산, Taint/Toleration 조합으로 정교한 배치 전략을 구현합니다.