서비스 장애가 났는데 docker logs myapp에는 아무것도 나오지 않았습니다. 애플리케이션이 stdout이 아니라 /var/log/app.log 파일에 직접 로그를 쓰고 있었기 때문입니다.
다른 서버에서는 반대로 로그가 너무 많이 쌓여 /var/lib/docker 파티션이 100%가 됐습니다. Docker 로그는 어디에서 수집되고 얼마나 보관되는지 정하지 않으면, 장애를 못 찾거나 로그 때문에 다시 장애가 납니다.
도커 로그 관리와 디버깅
서비스 장애가 발생했을 때 가장 먼저 확인하는 것이 로그입니다. Docker 로그는 컨테이너 프로세스의 stdout/stderr를 자동으로 수집하는 방식으로 동작합니다. 로그를 올바르게 확인하는 방법과, 로테이션 설정 없이 운영할 때 발생하는 디스크 100% 장애를 예방하는 방법을 학습합니다.
컨테이너 로그가 어디에 어떻게 저장되는지 이해하고, 디스크 과적 없이 로그를 안전하게 관리하는 방법을 익힙니다.
- 1json-file / syslog / journald / fluentd / awslogs 로그 드라이버 종류를 구분할 수 있다
- 2docker logs의 -f (follow) / --tail / --since / --until 옵션을 활용할 수 있다
- 3json-file 드라이버의 max-size / max-file 로테이션을 설정할 수 있다
- 4컨테이너 stdout/stderr와 12-Factor App 로그 원칙을 적용할 수 있다
- 5로그가 디스크를 가득 채우는 장애 시나리오를 사전에 예방할 수 있다
로그 파일 직접 조회(/var/lib/docker/containers/)는 root 권한이 필요합니다. sudo 권한이 없는 환경이라면 docker logs 명령어 위주로 실습합니다.
docker psdocker info | grep 'Logging Driver'ls /var/lib/docker/containers/ 2>/dev/null | head -3docker pull nginx:alpineDocker 로그 수집 원리: stdout과 stderr
서비스가 갑자기 내려갔습니다. docker logs myapp을 실행했더니 아무것도 나오지 않습니다. 컨테이너는 분명히 실행 중인데 로그가 없습니다. 원인은 해당 앱이 /var/log/app.log 파일에 로그를 기록하고 있기 때문입니다. Docker는 stdout과 stderr로 나오는 출력만 캡처합니다. 파일에 직접 기록하는 로그는 docker logs로 볼 수 없습니다. 컨테이너 환경에서 로그를 올바르게 설계하지 않으면 장애 발생 시 원인을 추적할 수 없게 됩니다. 이 ConceptBlock에서는 Docker가 로그를 수집하는 원리와 로그 드라이버 종류를 다룹니다.
 확대
확대
컨테이너 로그의 동작 원리
Docker는 컨테이너의 PID 1 프로세스(메인 프로세스)가 표준 출력(stdout)과 표준 오류(stderr)로 내보내는 내용을 자동으로 캡처합니다.
- 컨테이너 내부 — PID 1: nginx 프로세스
- stdout →
"192.168.1.1 - GET /index.html 200" - stderr →
"error: connection reset by peer"
- stdout →
- Docker 데몬 — 두 스트림을 캡처해 로그 파일로 저장
/var/lib/docker/containers/[ID]/[ID]-json.log
docker logs 명령을 실행하면 이 파일을 읽어서 출력합니다.
stdout vs 파일 로그
[stdout 로그 — docker logs로 확인 가능]
app.py에서:
print("서버 시작됨") # stdout
sys.stderr.write("에러발생") # stderr
→ docker logs my-container 로 확인 가능 ✓
[파일 로그 — docker logs로 확인 불가]
app.py에서:
with open("/var/log/app.log", "a") as f:
f.write("서버 시작됨")
→ docker logs my-container : (아무 출력 없음) ✗
→ docker exec my-container cat /var/log/app.log 로 확인 ✓
로그 드라이버 종류
Docker는 로그를 어떻게 저장하고 전달할지 결정하는 로그 드라이버를 제공합니다.
| 드라이버 | 설명 | 특징 |
|---|---|---|
json-file | JSON 형식으로 로컬 파일 저장 | 기본값, docker logs 지원 |
local | 최적화된 바이너리 형식으로 저장 | json-file보다 효율적 |
syslog | 시스템 syslog로 전달 | 중앙 집중식 로깅 |
journald | systemd journal로 전달 | docker logs 지원 |
fluentd | Fluentd 로그 수집기로 전달 | 대규모 로그 파이프라인 |
none | 로그 비활성화 | 성능 최우선 시 |
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part4/exam_14 && cd /tmp/docker/part4/exam_14
# 기본 로그 드라이버 확인
docker info --format '{{.LoggingDriver}}'
# json-file (기본값)
# 특정 드라이버로 컨테이너 실행
docker run --log-driver local nginx
로그 파일 위치
# 로그 파일이 실제로 저장된 위치 확인
docker inspect my-container --format '{{.LogPath}}'
# /var/lib/docker/containers/abc123.../abc123...-json.log
# 직접 파일 내용 확인 (root 권한 필요)
sudo cat /var/lib/docker/containers/abc123.../abc123...-json.log
# {"log":"서버 시작됨\n","stream":"stdout","time":"2024-01-01T00:00:00Z"}
컨테이너 로그가 수집되는 전체 흐름 — write부터 조회까지 5단계
docker logs myapp를 쳤을 때 로그가 나오거나 안 나오거나, 원격 수집기에는 보이는데 docker logs에는 안 보이거나 하는 차이는 전부 로그가 앱에서 조회 지점까지 흘러가는 경로에서 갈립니다. 앱이 로그를 어디에 쓰는지(①), 어떤 드라이버가 캡처하는지(③), 어디에 저장·전달되는지(④)에 따라 "무엇으로 조회되는가"가 정해집니다. 이 경로를 단계로 보면 "왜 안 보이지", "왜 디스크가 찼지"를 어느 칸에서 끊겼는지로 좁힐 수 있습니다.
[컨테이너 앱] logger.info("...") 또는 print(...)
│
① 앱이 stdout / stderr 로 출력 (파일에 직접 쓰면 이 경로를 안 탐)
│
② PID 1 의 stdout/stderr → 파이프 → Docker 데몬이 반대쪽을 읽음
│
③ 컨테이너에 지정된 로그 드라이버가 캡처 (json-file · journald · fluentd · loki ...)
│
④ 저장 또는 전달
│ · 저장형(json-file/local) → 호스트 파일에 기록 ...-json.log
│ · 전달형(fluentd/syslog/awslogs) → 원격 백엔드로 전송
│
⑤ 조회
│ · json-file/journald → docker logs 가 로컬 파일을 읽어 출력
│ · 전달형 → 수집기(Kibana·Grafana)에서 조회
▼
[운영자] docker logs myapp 또는 중앙 로그 대시보드
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 앱 출력 | 앱이 로그를 stdout/stderr 스트림으로 내보낸다. 12-Factor 원칙대로면 파일이 아니라 표준 출력으로 흘려보낸다 | 앱이 /var/log/app.log 같은 파일에 직접 쓰면 이 스트림을 안 타서 docker logs 가 빈 출력 → docker exec로 파일을 직접 봐야 함 |
| ② 파이프 전달 | PID 1 의 stdout/stderr가 파이프로 Docker 데몬에 전달된다 | 기본 blocking 모드에서 드라이버가 밀리면 파이프 버퍼가 차고 앱의 write가 블로킹돼 요청 처리까지 느려짐 |
| ③ 드라이버 캡처 | 컨테이너에 지정된 로그 드라이버가 스트림을 받아 저장형인지 전달형인지에 따라 처리한다 | 드라이버가 none이면 아무것도 안 남음 · Python은 stdout 버퍼링으로 늦게 보임(PYTHONUNBUFFERED=1로 해제) |
| ④ 저장 or 전달 | json-file은 ...-json.log에 줄 단위로 기록 · 전달형은 원격 백엔드로 전송 | 로테이션(max-size·max-file) 미설정이면 파일이 무한정 커져 디스크 100% → 전체 컨테이너 다운 |
| ⑤ 조회 | 저장형은 docker logs가 로컬 파일을 읽어 출력 · 전달형은 수집기에서 조회 | fluentd·syslog·splunk 같은 전달형 드라이버는 docker logs를 지원하지 않아 로컬에서 안 보임 → 반드시 해당 수집 시스템에서 조회 |
즉 "docker logs에 안 나온다"와 "디스크가 로그로 찼다"는 서로 다른 칸의 문제입니다 — 전자는 대개 ①(앱이 파일에 씀)이나 ⑤(전달형 드라이버라 docker logs 미지원)에서 끊긴 것이고, 후자는 ④(로테이션 미설정)의 문제입니다. 어느 드라이버로 어디에 저장되는지를 docker inspect의 LogPath와 docker info의 Logging Driver로 먼저 확인하면 어느 칸을 볼지가 정해집니다.
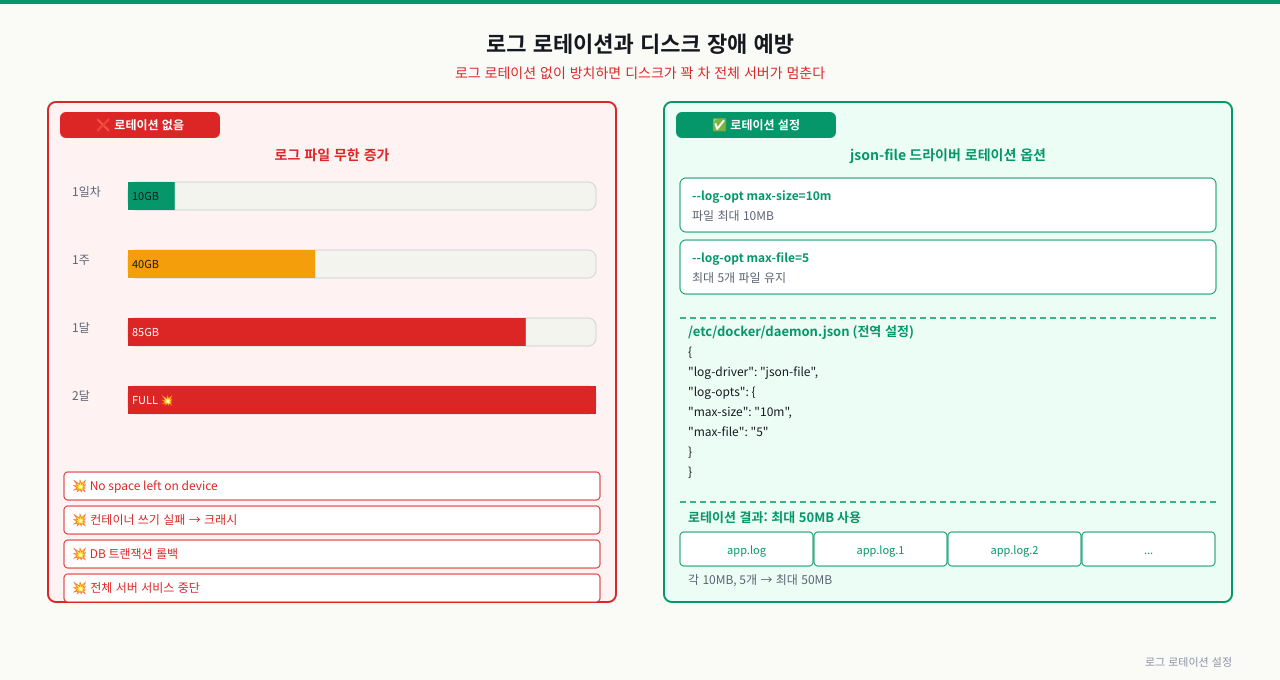
로그 로테이션과 디스크 장애 예방
서비스가 안정적으로 잘 돌아가고 있는데 어느 날 새벽 모든 컨테이너가 한꺼번에 내려갑니다. 원인은 디스크 풀(full)입니다. docker logs도 느려지고 컨테이너를 재시작해도 디스크가 이미 꽉 찬 상태입니다. 조사해보면 특정 서비스의 로그 파일이 수십 GB에 달합니다. Docker의 기본 로그 드라이버(json-file)는 파일 크기 제한이 없어서 로테이션을 설정하지 않으면 이런 상황이 발생합니다. 트래픽이 많지 않은 서비스도 몇 달이면 디스크를 채울 수 있습니다. 로그 로테이션은 선택이 아니라 운영 필수 설정입니다. 이 ConceptBlock에서는 Docker 로그 파일이 쌓이는 구조와 로테이션 설정 방법을 다룹니다.
 확대
확대
로그 로테이션 없이 운영 시 발생하는 문제
Docker의 기본 설정에서는 로그 파일 크기 제한이 없습니다. 트래픽이 많은 서비스를 오랫동안 운영하면 로그 파일이 수십 GB로 커져 디스크를 가득 채울 수 있습니다.
# 로테이션 없는 컨테이너의 로그 파일 크기 확인
sudo du -sh /var/lib/docker/containers/*/
# 52G /var/lib/docker/containers/abc123.../ ← 장애!
# 전체 도커 데이터 디스크 사용량
docker system df
# TYPE TOTAL ACTIVE SIZE RECLAIMABLE
# Containers 5 3 52.3GB 12.1GB
디스크가 100%가 되면 새 로그를 기록하지 못하는 것은 물론, 컨테이너가 새 프로세스를 생성하지 못해 서비스 전체가 다운될 수 있습니다.
로그 로테이션 설정 방법
방법 1: 컨테이너 실행 시 개별 설정
docker run \
--log-driver json-file \
--log-opt max-size=10m \
--log-opt max-file=3 \
nginx
max-size=10m: 로그 파일이 10MB에 도달하면 새 파일 생성
max-file=3: 최대 3개 파일 유지 → 최대 30MB
방법 2: Docker 데몬 전역 설정 (권장)
모든 컨테이너에 기본 로테이션이 적용됩니다.
// /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
# 설정 적용
sudo systemctl restart docker
방법 3: Docker Compose에서 설정
services:
web:
image: nginx
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
api:
image: my-api
logging:
driver: "json-file"
options:
max-size: "50m" # API는 로그가 많으므로 크게
max-file: "5"
로테이션 동작 시각화
시간 흐름 →
파일1: [0MB → 10MB] → 순환
파일2: [0MB → 10MB] → 순환
파일3: [0MB → 10MB] → 순환
파일1: [0MB → ...] (파일1 재사용, 이전 내용 삭제)
최대 유지되는 로그: 파일1 + 파일2 + 파일3 = 30MB
docker logs 명령의 다양한 옵션을 실제로 사용해봅니다.
1단계: 로그를 생성하는 테스트 컨테이너 실행
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
# 실습 디렉토리 준비
mkdir -p /tmp/docker/part2/exam_4 && cd /tmp/docker/part2/exam_4
# 로그 테스트용 docker-compose.yml 생성
cat > docker-compose.yml << 'EOF'
version: '3.8'
services:
app:
image: nginx:alpine
logging:
driver: json-file
options:
max-size: "10m"
max-file: "3"
EOF
이제 실습을 진행합니다.
# 1초마다 타임스탬프와 함께 로그를 출력하는 컨테이너
docker run -d --name log-demo alpine sh -c \
"while true; do echo \"\$(date '+%Y-%m-%d %H:%M:%S') 서비스 정상 동작 중\"; sleep 1; done"
2단계: 기본 로그 확인
# 전체 로그 출력
docker logs log-demo
# 실시간 로그 스트리밍 (Ctrl+C로 종료)
docker logs -f log-demo
3단계: 최근 N줄만 보기
# 최근 5줄만 출력
docker logs --tail 5 log-demo
# 최근 5줄부터 실시간 스트리밍
docker logs -f --tail 5 log-demo
4단계: 시간 기반 필터링
# 지난 30초 동안의 로그
docker logs --since 30s log-demo
# 특정 시각 이후 로그
docker logs --since "2024-01-01T12:00:00" log-demo
# 특정 시각 이전 로그 (until)
docker logs --until "2024-01-01T12:05:00" log-demo
# 시간 범위 지정
docker logs --since 2m --until 1m log-demo
5단계: 타임스탬프 포함 출력
# Docker가 캡처한 시각의 타임스탬프 포함
docker logs -t log-demo
# 2024-01-01T12:00:01.123456789Z 2024-01-01 12:00:01 서비스 정상 동작 중
# 실시간 + 타임스탬프 + 최근 10줄
docker logs -f -t --tail 10 log-demo
6단계: stdout/stderr 분리 확인
# stdout과 stderr 모두 출력하는 컨테이너
docker run -d --name mixed-log alpine sh -c \
"while true; do
echo 'stdout: 정상 처리'
echo 'stderr: 경고 발생' >&2
sleep 2
done"
# 기본은 stdout + stderr 합쳐서 출력
docker logs mixed-log
로그 실습 컨테이너 강제 삭제
안전한 실행 조건: docker logs 옵션 확인을 끝낸 뒤 실습 컨테이너를 정리하는 경우에만 실행합니다.
실행 전 반드시 확인
- docker logs로 필요한 로그 확인을 마쳤다
- 삭제 대상이 log-demo와 mixed-log임을 확인했다
- 보존해야 할 로그가 없음을 확인했다
docker rm -f log-demo mixed-log위 항목을 모두 확인한 후 복사할 수 있습니다
- docker logs log-demo 출력에서 1초마다 생성된 로그가 보이는가?
- docker logs -f --tail 5 log-demo가 최근 5줄부터 실시간으로 이어지는가?
- docker logs mixed-log 출력에서 stdout과 stderr가 함께 보이는가?
- 정리 후 docker ps -a에서 log-demo와 mixed-log가 남아있지 않은가?
로그 로테이션을 설정하고 실제로 파일이 순환되는 것을 확인합니다.
1단계: 로테이션 없는 컨테이너의 로그 파일 확인
# 로테이션 없이 실행
docker run -d --name no-rotate nginx:alpine
# 로그 파일 경로 확인
LOG_PATH=$(docker inspect no-rotate --format '{{.LogPath}}')
echo "로그 파일: $LOG_PATH"
# 현재 크기 확인
sudo ls -lh "$LOG_PATH"
# 처음엔 매우 작지만 트래픽이 쌓이면 무한정 커짐
2단계: 로테이션 설정한 컨테이너 실행
docker run -d --name with-rotate \
--log-driver json-file \
--log-opt max-size=1m \
--log-opt max-file=3 \
alpine sh -c "while true; do
# 빠르게 로그를 생성해 로테이션 유발
for i in \$(seq 1 100); do
echo \"로그 데이터: \$(date) - \$(cat /dev/urandom | head -c 100 | base64)\"
done
done"
3단계: 로그 파일 로테이션 관찰
# 로그 파일 디렉토리 감시
LOG_DIR=$(dirname $(docker inspect with-rotate --format '{{.LogPath}}'))
sudo watch -n 1 "ls -lh $LOG_DIR/"
# 처음: with-rotate-json.log (단일 파일)
# 1MB 초과 후: with-rotate-json.log + with-rotate-json.log.1
# 다시 초과: ...log + ...log.1 + ...log.2
# 3개 유지: 가장 오래된 파일 자동 삭제
4단계: docker logs는 계속 동작함 확인
# 로테이션 후에도 docker logs는 최신 로그를 정상 출력
docker logs --tail 5 with-rotate
5단계: 정리
로그 로테이션 실습 컨테이너 강제 삭제
안전한 실행 조건: 로그 로테이션 관찰을 끝낸 뒤 실습 컨테이너를 정리할 때만 실행합니다.
실행 전 반드시 확인
- 로그 파일 로테이션 결과를 확인했다
- docker logs --tail 5 with-rotate 확인을 마쳤다
- 삭제 대상이 실습 컨테이너뿐임을 확인했다
docker rm -f no-rotate with-rotate위 항목을 모두 확인한 후 복사할 수 있습니다
애플리케이션이 파일에 직접 로그를 기록할 때 접근하는 방법을 익힙니다.
1단계: 파일에 로그를 기록하는 컨테이너 시뮬레이션
# /var/log/app.log 파일에 직접 기록하는 컨테이너
docker run -d --name file-logger alpine sh -c \
"while true; do
echo \"\$(date '+%Y-%m-%d %H:%M:%S') [INFO] 주문 처리 완료 ID=\$(shuf -i 1000-9999 -n 1)\" >> /var/log/app.log
sleep 1
done"
2단계: docker logs로 확인 시도 (실패)
docker logs file-logger
# (아무 출력 없음) — 파일에 기록했으므로 docker logs에 안 잡힘
3단계: exec로 컨테이너 내부에서 확인
# 최근 10줄 확인
docker exec file-logger tail -10 /var/log/app.log
# 실시간 파일 로그 스트리밍
docker exec file-logger tail -f /var/log/app.log
4단계: 로그 파일 호스트로 복사
# 분석을 위해 호스트로 복사
docker cp file-logger:/var/log/app.log ./app-logs-backup.log
cat ./app-logs-backup.log | head -20
5단계: 근본 해결 — stdout으로 심볼릭 링크
일부 컨테이너 이미지는 로그 파일을 stdout으로 리디렉션해 이 문제를 해결합니다.
# nginx 공식 이미지가 사용하는 방식 확인
docker run --rm nginx:alpine cat /etc/nginx/nginx.conf | grep access_log
# access_log /dev/stdout main; ← stdout으로 리디렉션!
# error_log /dev/stderr notice; ← stderr로 리디렉션!
6단계: 정리
rm -f ./app-logs-backup.log
파일 로그 실습 컨테이너 강제 삭제
안전한 실행 조건: 필요한 로그를 호스트로 복사했거나 로그 보존이 필요 없는 실습 상황에서만 실행합니다.
실행 전 반드시 확인
- docker cp로 필요한 로그 백업을 완료했다
- 삭제 대상이 file-logger인지 확인했다
- 로컬 백업 파일 삭제 여부를 별도로 판단했다
docker rm -f file-logger위 항목을 모두 확인한 후 복사할 수 있습니다
증상
컨테이너가 실행 중인데 docker logs를 실행해도 아무 내용이 나오지 않습니다.
docker logs my-java-app
# (출력 없음)
docker ps
# my-java-app Up 2 hours ← 분명히 실행 중인데...
원인 진단
원인 1: 애플리케이션이 파일에 로그를 기록
# 컨테이너 내부에 로그 파일이 있는지 확인
docker exec my-java-app find /var/log -name "*.log" 2>/dev/null
# /var/log/application/app.log ← 여기에 기록 중
# 파일 로그 확인
docker exec my-java-app tail -50 /var/log/application/app.log
원인 2: 로그 드라이버가 none으로 설정됨
docker inspect my-java-app --format '{{.HostConfig.LogConfig.Type}}'
# none ← 로그 드라이버 비활성화 상태
원인 3: 로그 버퍼링 (Python/Java에서 흔함)
# Python은 기본적으로 stdout을 버퍼링
# 버퍼가 가득 차기 전까지 docker logs에 나타나지 않음
# 해결: 환경변수로 버퍼링 비활성화
docker run -e PYTHONUNBUFFERED=1 my-python-app
# 또는
docker run my-python-app python -u app.py # -u: unbuffered
해결 방법
로그를 stdout으로 출력하도록 애플리케이션 수정
# Python: 파일 대신 stdout으로 출력
import sys
print("로그 메시지", file=sys.stdout, flush=True)
// Java/Spring Boot: application.properties
logging.file.name= # 파일 로깅 비활성화
# 콘솔 출력은 자동으로 stdout으로 전달됨
# Nginx: /dev/stdout으로 심볼릭 링크
ln -sf /dev/stdout /var/log/nginx/access.log
ln -sf /dev/stderr /var/log/nginx/error.log
증상
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 50G 0 100% / ← 재앙!
docker ps
# ERROR: Cannot connect to Docker daemon — 도커도 동작 중단!
즉각 대응 (디스크 공간 확보)
1. 로그 파일 크기 확인
sudo du -sh /var/lib/docker/containers/*/
# 45G /var/lib/docker/containers/abc123.../ ← 원인 발견!
# 해당 컨테이너 이름 확인
sudo docker inspect abc123... --format '{{.Name}}'
2. 긴급 로그 파일 비우기 (컨테이너 중단 없이)
# ⚠️ rm이 아니라 truncate로! rm하면 프로세스가 파일 핸들 유지해 공간 안 줄어듦
sudo truncate -s 0 /var/lib/docker/containers/abc123.../abc123...-json.log
# 공간 확인
df -h
# 공간 확보됨!
3. 사용하지 않는 Docker 리소스 정리
로그 장애 대응 중 Docker 리소스 정리
안전한 실행 조건: 디스크 장애 대응 중이며 삭제 대상 리소스와 볼륨을 확인한 경우에만 실행합니다.
실행 전 반드시 확인
- sudo du 또는 docker system df로 디스크 원인을 확인했다
- docker volume ls로 보존할 볼륨이 없는지 확인했다
- 먼저 truncate와 로그 로테이션 설정을 검토했다
docker system prune -f --volumes위 항목을 모두 확인한 후 복사할 수 있습니다
재발 방지 설정
// /etc/docker/daemon.json — 즉시 적용
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
sudo systemctl restart docker
# 이후 모든 새 컨테이너에 로테이션 자동 적용
기존 실행 중인 컨테이너에 적용하려면: 컨테이너를 재생성해야 합니다. 로그 드라이버 설정은 컨테이너 생성 시에만 적용됩니다.
심화 — 로그가 앱을 느리게 만들 때
심화: 로그 드라이버의 blocking 모드 — 로깅이 앱 성능을 잡아먹는 경로
로그는 관찰 도구일 뿐 앱 성능과는 무관하다고 생각하기 쉽지만, 로그 드라이버가 밀리면 앱 자체가 느려질 수 있습니다. Docker가 stdout을 어떻게 실어 나르는지 한 겹 더 봐야 이해됩니다.
- stdout은 파이프로 흐릅니다: 컨테이너 PID 1의 stdout/stderr는 파이프를 통해 Docker 데몬의 로그 드라이버로 전달됩니다. 기본 동작은 blocking 모드입니다.
- 백엔드가 막히면 앱이 막힙니다: 로그 드라이버가 목적지(원격 fluentd·loki·awslogs 등)로 로그를 밀어내지 못하면 파이프 버퍼가 찹니다. 버퍼가 가득 차면 앱의 write 호출이 그 자리에서 블로킹되고, 로그를 남기려던 요청 처리까지 멈춥니다. 로그 수집기가 밀리니 앱이 느려지는 역설이 이렇게 생깁니다.
- non-blocking 모드로 결합을 끊습니다: mode=non-blocking과 max-buffer-size를 주면, 버퍼가 차더라도 앱을 멈추는 대신 로그를 드롭합니다. 앱 가용성과 로그 완전성 중 앱을 지키는 선택입니다.
- 애초에 디커플하는 게 낫습니다: 컨테이너는 로컬 json-file에만 쓰게 하고, Promtail·Fluent Bit 같은 에이전트가 그 파일을 tail해 백엔드로 보내면, 백엔드 장애가 앱으로 전파되지 않습니다.
원격 로그 드라이버 직결은 설정이 간단하지만, 백엔드 장애가 곧 앱 장애가 될 수 있다는 비용을 안고 있습니다.
상황: 로그 드라이버를 로컬 json-file에서 원격 fluentd로 바꾼 뒤부터, 트래픽이 몰리는 시간대에 앱 응답이 전체적으로 느려집니다. 이상하게도 로그 수집기(fluentd)를 재시작하면 앱 지연도 같이 사라집니다.
원인: 기본 blocking 모드에서 fluentd가 유입량을 못 따라가자, 컨테이너 stdout 파이프 버퍼가 가득 차 앱의 로그 write가 블로킹됐습니다. 요청 처리 도중 로그 한 줄을 남기려다 멈추니, 로깅 지연이 그대로 응답 지연으로 나타난 것입니다. 수집기를 재시작하면 밀린 버퍼가 뚫려 앱도 함께 회복됩니다.
진단: 컨테이너의 로그 드라이버와 모드를 확인합니다(기본은 blocking). 앱 지연 구간과 로그 백엔드의 처리 지연·큐 적체 시각이 겹치는지 대조하고, 같은 앱을 로컬 json-file로 돌렸을 때 지연이 사라지는지로 로깅 경로가 원인인지 좁힙니다.
해결: 로그 드라이버를 mode=non-blocking으로 바꾸고 max-buffer-size를 트래픽에 맞게 잡아, 백엔드가 밀려도 앱이 멈추지 않게 합니다(대신 초과분 로그는 드롭). 더 견고하게는 컨테이너를 로컬 json-file로 받게 하고 Promtail 같은 에이전트가 수집하도록 앱과 로깅을 분리합니다. 로그 수집기 자체의 버퍼·처리량도 함께 늘립니다(cAdvisor + Prometheus + Grafana 모니터링 실무).
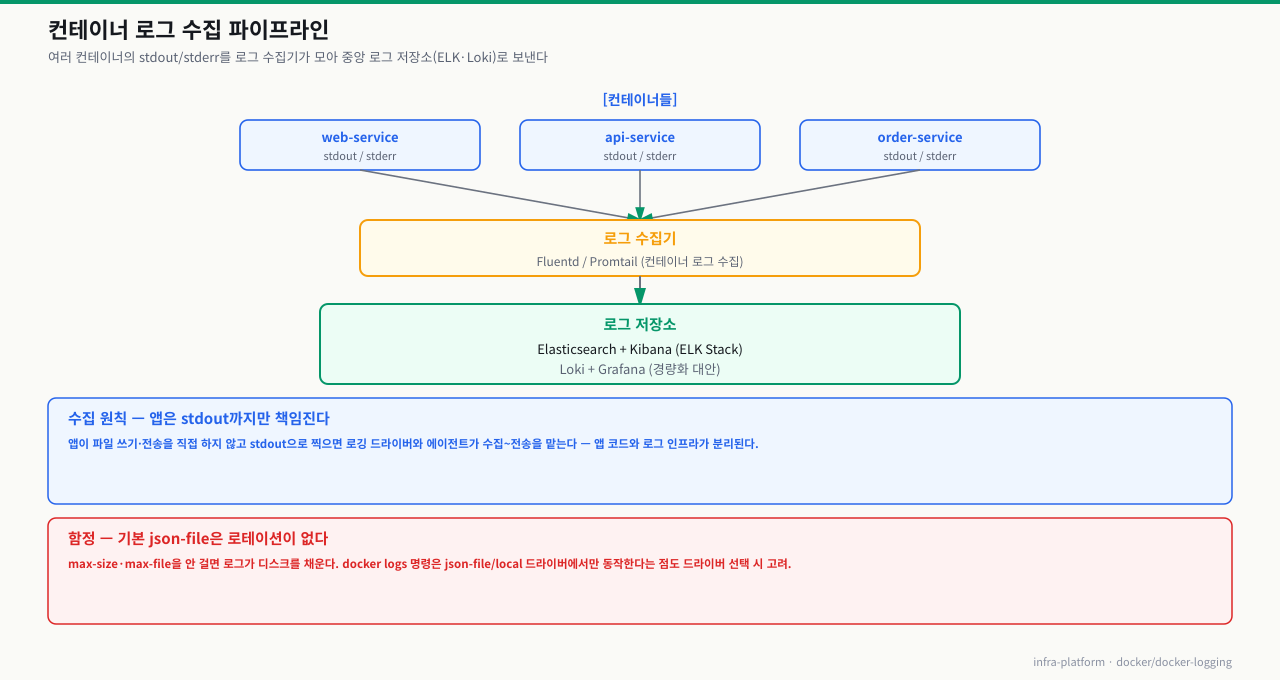
소규모 서비스는 docker logs로 충분하지만, 여러 서버에 분산된 마이크로서비스 환경에서는 중앙 집중식 로그 관리 시스템이 필수입니다.
실무 로그 파이프라인 아키텍처
 확대
확대
Docker Compose에서 Loki 로그 드라이버 사용
version: "3.9"
services:
app:
image: my-app
logging:
driver: loki # Loki로 직접 전송
options:
loki-url: "http://loki:3100/loki/api/v1/push"
loki-batch-size: "400"
loki-retries: "5"
labels: "service=app,env=production"
loki:
image: grafana/loki:latest
ports:
- "3100:3100"
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
현업에서의 로그 레벨 전략
DEBUG → 개발 환경에서만 (stdout)
INFO → 주요 이벤트, 운영에서 항상 수집
WARN → 주의 필요, 알림 연동 고려
ERROR → 즉시 알림 발송 (Slack/PagerDuty)
FATAL → 서비스 중단 수준, 온콜 호출
이 플랫폼의 e-commerce 프로젝트에서는 각 언어별 로깅 라이브러리(Winston, Structlog, Logrus, SLF4j)가 모두 JSON 형식으로 stdout에 출력하도록 설정되어 있어, Promtail이 자동으로 수집해 Loki로 전달하는 구조입니다. 실무 DevOps 엔지니어는 모든 서비스의 로그를 단일 대시보드(Grafana)에서 통합 조회하고, 에러 패턴을 알림으로 설정합니다.
구조적 로그(Structured Logging)와 멀티라인 처리
 확대
확대
왜 구조적 로그인가?
# 비구조적 로그 (텍스트 파싱이 어려움)
2026-04-05 10:30:15 ERROR User login failed: invalid password for user john
# 구조적 로그 (JSON — 필드별 검색/집계 가능)
{"time":"2026-04-05T10:30:15Z","level":"ERROR","event":"login_failed",
"user":"john","reason":"invalid_password","ip":"192.168.1.100","latency_ms":5}
구조적 로그는 Elasticsearch, Loki 같은 로그 저장소에서 user=john AND event=login_failed 같은 쿼리로 빠르게 검색할 수 있습니다.
앱에서 구조적 로그 출력하기
# Python — structlog 라이브러리
import structlog
log = structlog.get_logger()
log.error("login_failed", user="john", reason="invalid_password", ip="1.2.3.4")
# {"event": "login_failed", "user": "john", "reason": "invalid_password", ...}
// Node.js — pino 라이브러리 (고성능)
const pino = require('pino');
const log = pino();
log.error({ user: 'john', reason: 'invalid_password' }, 'login failed');
// {"level":50,"time":1712300000000,"user":"john","reason":"invalid_password","msg":"login failed"}
// Java — logback JSON 레이아웃
// logback.xml에서 JsonLayout 설정
// 모든 로그가 자동으로 JSON으로 출력됨
logger.error("login failed", kv("user", "john"), kv("reason", "invalid_password"));
멀티라인 로그 문제 (스택 트레이스)
Docker의 json-file 드라이버는 줄 단위로 로그를 저장합니다. Java 스택 트레이스처럼 여러 줄인 경우 각 줄이 별개 이벤트로 분리됩니다.
# 실제 저장된 로그 파일 확인
sudo cat /var/lib/docker/containers/<id>/<id>-json.log | head -5
# {"log":"Exception in thread \"main\"\n","stream":"stderr","time":"..."}
# {"log":"\tat com.example.App.main(App.java:42)\n","stream":"stderr","time":"..."}
# {"log":"\tat com.example.App.run(App.java:28)\n","stream":"stderr","time":"..."}
# ← 스택 트레이스가 3개의 별개 이벤트로 분리됨!
멀티라인 처리 방법
# 방법 2: Promtail (Loki 수집기) 멀티라인 파서 설정
scrape_configs:
- job_name: docker
pipeline_stages:
- multiline:
firstline: '^\d{4}-\d{2}-\d{2}' # 날짜로 시작하는 줄이 첫 줄
max_wait_time: 3s
로그 포맷 권장 사항
| 상황 | 권장 방식 |
|---|---|
| 단순 개발/디버깅 | 텍스트 로그 (가독성 우선) |
| 운영 환경 (로그 집중화 예정) | JSON 구조적 로그 |
| 멀티라인 예외가 많은 Java | JSON + 스택 트레이스 직렬화 |
| 고성능 필요 | binary format (Loki native, OpenTelemetry) |
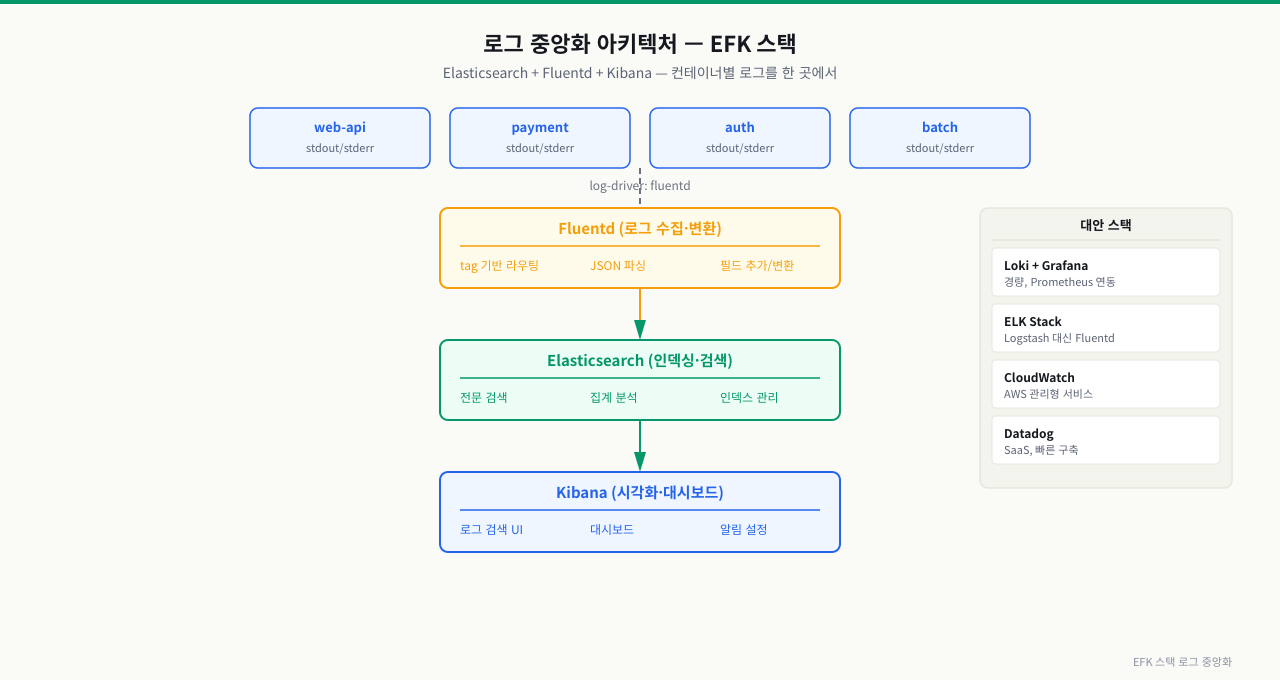
로그 중앙화 — 여러 컨테이너 로그를 한 곳에서 보기
 확대
확대
왜 중앙화가 필요한가
컨테이너가 5개일 때는 docker logs로 하나씩 확인할 수 있습니다. 하지만 수십 개의 컨테이너가 있다면 docker logs로는 불가능합니다.
중앙화 전: 컨테이너마다 docker logs 명령 실행
→ 로그가 각 서버에 분산
→ 서버 장애 시 로그 유실
중앙화 후: 모든 로그를 한 곳에 수집
→ 전체 서비스 로그를 한 화면에서 검색/분석
→ 장기 보관 및 알람 연동
주요 스택 선택
| 스택 | 수집기 | 저장소 | 시각화 | 특징 |
|---|---|---|---|---|
| ELK | Filebeat/Logstash | Elasticsearch | Kibana | 강력한 검색, 무거움 |
| PLG (Grafana) | Promtail | Loki | Grafana | 경량, Prometheus와 통합 |
| 클라우드 AWS | CloudWatch Agent | CloudWatch | Console | 관리형, 비용 발생 |
| 클라우드 GCP | Ops Agent | Cloud Logging | Console | 관리형, 비용 발생 |
Docker 로그 드라이버로 직접 전송
# docker-compose.yml
services:
app:
image: myapp
logging:
driver: "json-file" # 기본 (로컬 저장 + docker logs 지원)
options:
max-size: "10m"
max-file: "3"
app-prod:
image: myapp
logging:
driver: "awslogs" # AWS CloudWatch로 직접 전송
options:
awslogs-region: "ap-northeast-2"
awslogs-group: "/myapp/prod"
awslogs-stream: "api-1"
Loki + Promtail 빠른 설정 (Docker Compose)
# monitoring/compose.yml
services:
loki:
image: grafana/loki:latest
ports:
- "3100:3100"
volumes:
- loki-data:/loki
promtail:
image: grafana/promtail:latest
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock
- ./promtail-config.yml:/etc/promtail/config.yml
grafana:
image: grafana/grafana:latest
ports:
- "3001:3000"
environment:
- GF_AUTH_ANONYMOUS_ENABLED=true
volumes:
- grafana-data:/var/lib/grafana
volumes:
loki-data:
grafana-data:
# promtail-config.yml
scrape_configs:
- job_name: docker
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 5s
relabel_configs:
- source_labels: [__meta_docker_container_name]
target_label: container
Grafana에서 Loki 데이터소스를 추가하면 {container="myapp"} 쿼리로 모든 컨테이너 로그를 한 화면에서 검색할 수 있습니다.
정리
Docker 로그 관리의 핵심을 요약합니다.
| 명령/설정 | 용도 |
|---|---|
docker logs -f [컨테이너] | 실시간 로그 스트리밍 |
docker logs --tail 100 | 최근 100줄 출력 |
docker logs --since 1h | 지난 1시간 로그 |
max-size: "10m" | 로그 파일 최대 크기 |
max-file: "3" | 최대 파일 개수 유지 |
모든 컨테이너에 로그 로테이션을 설정하는 것은 운영 환경 필수 사항입니다. /etc/docker/daemon.json에 전역 설정을 추가해 새로 생성되는 모든 컨테이너에 자동 적용하세요.
명령어·단축키 빠른 참조
이 모듈에서 다룬 docker logs 옵션과 로그 드라이버·로테이션 설정을 실전 조합과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
docker logs | 컨테이너 stdout/stderr 조회 | docker logs -f --tail 100 <c> |
docker logs --since/--until | 시간 구간으로 로그 필터 | docker logs --since 10m --until 1m <c> |
docker logs -t | 캡처 시각 타임스탬프 포함 | docker logs -f -t --tail 10 <c> |
docker inspect -f | 로그 파일 경로·드라이버 확인 | docker inspect -f '{{.LogPath}}' <c> |
docker info | 데몬 기본 로그 드라이버 확인 | docker info -f '{{.LoggingDriver}}' |
--log-driver | 컨테이너 로그 드라이버 지정 | docker run --log-driver local nginx |
--log-opt | 로그 로테이션 옵션 설정 | docker run --log-opt max-size=10m --log-opt max-file=3 nginx |
docker exec | 파일 로그(stdout 미출력) 직접 확인 | docker exec <c> tail -f /var/log/app.log |
docker cp | 로그 파일을 호스트로 추출 | docker cp <c>:/var/log/app.log ./app.log |
docker system df | 컨테이너 로그 포함 디스크 점유 확인 | docker system df |
truncate | 긴급 시 로그 파일 비우기(컨테이너 유지) | sudo truncate -s 0 $(docker inspect -f '{{.LogPath}}' <c>) |
관련 모듈로 더 깊이:
- cAdvisor + Prometheus + Grafana 모니터링 실무 — 로그를 넘어 메트릭 시계열로 이상 징후를 찾는 cAdvisor·Prometheus 흐름
- 백엔드 서버 이슈를 쫓는 도커 셸 접속과 디버깅 기법 — 로그로 좁힌 원인을 exec·nsenter로 컨테이너 내부에서 확정하는 법
- requests와 limits 적정 값 계산과 CPU 스로틀링 대처 — 로그 디스크 폭증과 함께 다뤄야 할 컨테이너 자원 제한 설정
- logrotate로 서버 용량 갉아먹는 로그 파일 자동 압축/분할 — 컨테이너 로그가 채우는 호스트 디스크를 logrotate로 지키는 리눅스 로테이션 (Linux 트랙)
다음 모듈에서는 Docker 환경에서 실행 중인 컨테이너를 관찰하고, 메트릭 기반으로 이상 징후를 찾는 모니터링 흐름을 다룹니다.