새벽 3시, 운영 서버의 컨테이너가 OOM으로 죽었고 당직자가 노트북을 열기 전까지 요청은 계속 실패합니다. 컨테이너가 수십 개로 늘어난 팀에서는 사람이 하나씩 재시작하고 배치하는 방식이 더 이상 버티지 못합니다. Kubernetes는 이런 반복 운영을 컨트롤러와 스케줄러가 대신 처리하게 만드는 출발점입니다.
컨테이너 오케스트레이션 입문
새벽 3시, Slack 알림이 울렸다. 운영 서버의 컨테이너가 OOM으로 죽었다. 당직 팀원이 노트북을 열어 docker start 명령을 입력하는 동안, 사용자 요청은 5분째 전부 실패하고 있었다. 알림을 못 봤다면 30분, 1시간이 걸렸을 수도 있다. 같은 상황에서 Kubernetes 클러스터라면 어떻게 됐을까. 컨테이너가 죽는 순간 Controller가 감지하고, 사람이 잠든 사이에 새 컨테이너가 자동으로 살아난다. 이것이 오케스트레이션의 시작이다. Docker는 컨테이너를 실행하는 도구이고, Kubernetes는 수십~수천 개의 컨테이너를 사람 없이도 안정적으로 운영하기 위한 플랫폼이다.
Docker 컨테이너를 실제 서비스에서 안정적으로 운영하려면 왜 오케스트레이션이 필요한지, Kubernetes가 어떤 문제를 해결하는지 이해합니다.
- 1Docker 단독 운영의 4가지 실무 한계점을 설명할 수 있다
- 2컨테이너 오케스트레이션이 자동화하는 것들(자동 복구, 스케일링, 배포, 로드밸런싱)을 설명할 수 있다
- 3Kubernetes의 선언적(Declarative) 관리 철학을 설명할 수 있다
- 4K8s가 해결하는 자가 치유(Self-Healing), 수평 스케일링, 무중단 배포를 설명할 수 있다
이번 모듈은 개념 중심입니다. Docker가 설치된 환경이면 충분하며, kubectl과 minikube는 다음 모듈부터 본격적으로 사용합니다.
docker pskubectl version --client 2>/dev/null || echo 'kubectl 미설치 — 다음 모듈에서 설치'minikube version 2>/dev/null || echo 'minikube 미설치 — 선택 사항'Docker만으로 운영할 때 생기는 4가지 한계
서버 한 대에서 컨테이너 5개를 돌릴 때는 Docker만으로도 충분합니다. 그런데 서비스가 커지면 어떤 일이 벌어질까요? 컨테이너가 죽어도 아무도 모릅니다. 트래픽이 몰려도 자동으로 늘어나지 않습니다. 새 버전 배포 중에 서비스가 잠깐 끊깁니다. 서버가 10대가 되면 어느 서버에 어느 컨테이너를 띄울지 일일이 결정해야 합니다.
 확대
확대
문제 1: 자동 복구 없음
# 컨테이너가 죽었다 — 아무일도 일어나지 않는다
docker run -d --name my-api my-api:latest
# 5분 후, 메모리 부족으로 컨테이너 종료됨
docker ps
# CONTAINER ID IMAGE COMMAND ...
# (아무것도 없음 — 죽은 채로 있음)
# 알림을 받은 누군가가 수동으로 재시작
docker start my-api
--restart=always 옵션으로 단순 재시작은 가능하지만, 헬스체크 실패나 의존 서비스 장애, 노드 다운 시에는 속수무책입니다.
문제 2: 수동 스케일링
# 트래픽이 5배 폭증 — 수동으로 컨테이너를 추가해야 함
docker run -d --name my-api-2 my-api:latest
docker run -d --name my-api-3 my-api:latest
docker run -d --name my-api-4 my-api:latest
# 그리고 로드밸런서 설정도 수동으로 변경해야 한다
# nginx.conf 수정 → nginx -s reload
트래픽이 줄어들면 다시 수동으로 줄여야 합니다. 새벽에 폭증하면? 아무도 없습니다.
문제 3: 무중단 배포 어려움
# 새 버전 배포 — 이 사이에 다운타임 발생
docker stop my-api
docker rm my-api
docker run -d --name my-api my-api:v2
# 또는 Blue-Green 배포를 수작업으로 구현해야 함
# → 로드밸런서 전환, 이전 컨테이너 관리, 롤백 스크립트...
문제 4: 멀티 호스트 관리 복잡성
서버가 10대라면? 어느 서버의 CPU가 여유로운지, 어느 서버에 컨테이너를 배치할지, 서버 간 네트워크는 어떻게 구성할지 — 모두 수작업입니다.
서버1: docker run ... # SSH 접속 후 실행
서버2: docker run ... # SSH 접속 후 실행
서버3: docker run ... # SSH 접속 후 실행
# 10대면 10번 반복
Kubernetes가 해결하는 것: 선언적 관리
Docker 환경에서 컨테이너 수십 개를 명령어로 직접 관리하다 보면, 어느 서버에 어떤 버전이 떠 있는지 파악하기 어려워지고 배포할 때마다 수작업 실수가 생깁니다. 특히 장애가 났을 때 "무엇을 실행해야 하는지"를 사람이 일일이 판단해야 하는 구조에서는 복구 속도가 개인 역량에 달리게 됩니다. Kubernetes의 선언적 관리는 이 문제를 "원하는 상태를 기록하면 시스템이 알아서 맞춘다"는 방식으로 해결합니다. 운영자가 "3개를 실행하라"고 선언해두면 컨테이너가 죽든, 노드가 바뀌든 Kubernetes가 현재 상태를 원하는 상태로 계속 맞춰주는 것이 Reconciliation Loop입니다.
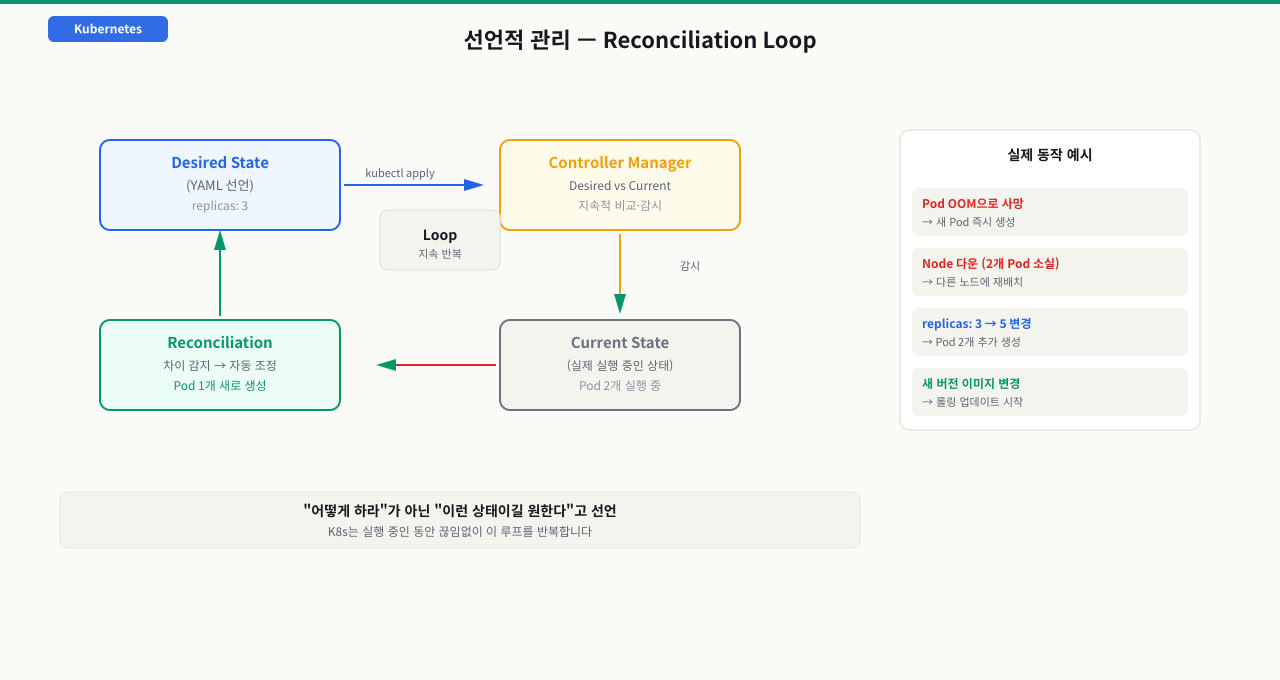 확대
확대
선언적 배포 예시
# deployment.yaml — "이런 상태이길 원한다"고 선언
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-api
spec:
replicas: 3 # 항상 3개 실행
selector:
matchLabels:
app: my-api
template:
metadata:
labels:
app: my-api
spec:
containers:
- name: my-api
image: my-api:v2 # 이 버전으로
resources:
requests:
memory: "128Mi"
cpu: "100m"
kubectl apply -f deployment.yaml
# deployment.apps/my-api created
# → K8s가 알아서 3개의 Pod를 적절한 노드에 배치
# → 하나가 죽으면 자동으로 새로 생성
# → 버전 변경 시 롤링 업데이트 자동 진행
K8s가 자동으로 처리하는 것들
| 기능 | Docker 단독 | Kubernetes |
|---|---|---|
| 컨테이너 죽으면 | 수동 재시작 | 자동 재시작 (Self-Healing) |
| 트래픽 폭증 시 | 수동 docker run | HPA 자동 스케일링 |
| 새 버전 배포 | 다운타임 or 복잡한 스크립트 | 롤링 업데이트 자동화 |
| 멀티 노드 배치 | SSH로 각 서버 접속 | 스케줄러 자동 배치 |
| 헬스체크 | 직접 구현 필요 | liveness/readinessProbe 내장 |
| 로드밸런싱 | nginx 별도 설정 | Service 리소스로 자동화 |
Reconciliation Loop — K8s의 작동 원리
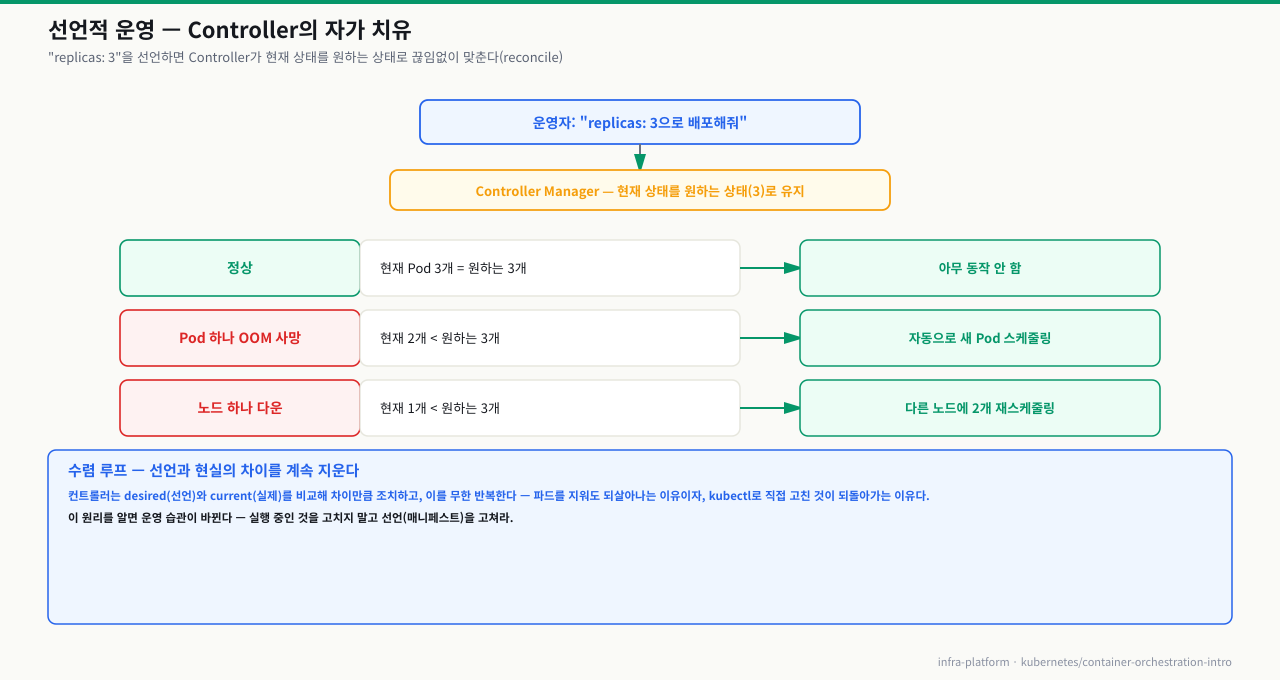 확대
확대
이 루프는 K8s가 실행되는 동안 끊임없이 반복됩니다. 운영자가 잠든 새벽에도, 휴일에도.
실습: Docker 한계 직접 경험하기
이번 실습은 Docker 환경에서 오케스트레이션 없이 컨테이너를 관리할 때 어떤 불편함이 있는지 체험합니다.
실습 1: 컨테이너 죽음 감지 없음 확인
# 테스트용 컨테이너 실행 (10초 후 종료되는 컨테이너)
docker run -d --name temp-test alpine sh -c "sleep 10 && exit 1"
# 실행 중 확인
docker ps
# CONTAINER ID IMAGE COMMAND CREATED STATUS
# abc123 alpine "sh -c 'sleep 10 && …" 3 seconds ago Up 2 seconds
# 15초 후 확인 — 아무런 알림 없이 죽어있음
sleep 15 && docker ps
# (비어있음)
docker ps -a
# CONTAINER ID IMAGE STATUS
# abc123 alpine Exited (1) 5 seconds ago
아무런 알림도 없습니다. 모니터링 시스템 없이는 서비스 다운을 사람이 먼저 발견해야 합니다.
실습 2: --restart=always의 한계
# restart 정책 설정
docker run -d --name restart-test --restart=always alpine sh -c "echo 'started'; sleep 5; exit 1"
# 계속 재시작되는지 확인
watch docker ps # 또는 아래 명령어 반복 실행
docker ps
# STATUS: Restarting (1) 3 seconds ago ← 재시작 중
# 재시작 횟수 확인
docker inspect restart-test | grep RestartCount
# "RestartCount": 5,
# 문제: 앱이 비정상 종료될 때마다 즉시 재시작 → 무한 루프
# CrashLoopBackOff는 K8s에서 이 패턴을 감지해 지연 재시작하는 방어 메커니즘
docker stop restart-test && docker rm restart-test
- docker inspect <container> | grep RestartCount에서 수치를 먼저 확인 — 5초 간격으로 계속 오르면 앱 자체가 비정상 종료 중인 것으로, 로그 원인 파악이 우선
- 재시작 횟수 기준: 3회 미만은 일시적 오류, 10회 이상이면 docker logs --tail 50 으로 반복되는 에러 패턴을 식별해야 함
- STATUS=Exited이고 RestartCount가 오르지 않으면 → --restart 정책이 없는 것. Kubernetes의 ReplicaSet과 달리 Docker 단독 환경에서는 수동 docker start 또는 --restart 플래그 재설정이 필요
실습 3: 수동 스케일링의 번거로움
# 웹 서버 3개를 수동으로 띄우기
for i in 1 2 3; do
docker run -d --name web-$i -p $((8079+i)):80 nginx:alpine
echo "web-$i started on port $((8079+i))"
done
# 결과 확인
docker ps --format "table {{.Names}}\t{{.Ports}}"
# NAMES PORTS
# web-3 0.0.0.0:8082->80/tcp
# web-2 0.0.0.0:8081->80/tcp
# web-1 0.0.0.0:8080->80/tcp
# 로드밸런서 없이는 트래픽을 나눌 방법이 없음
# 포트도 일일이 달라야 함 → 외부에서 어떻게 접근?
# 정리
for i in 1 2 3; do docker stop web-$i && docker rm web-$i; done
K8s라면 replicas: 3으로 선언하고 Service로 단일 진입점을 자동 구성합니다.
상황
새벽 2:47 AM — 모니터링 대시보드에 갑자기 에러율 100%
docker ps 확인 → 컨테이너 없음
docker ps -a 확인 → Exited (137) 2 hours ago
Exit code 137 = 128 + 9 (SIGKILL). OOM Killer가 죽인 것입니다.
원인 파악
# 컨테이너 마지막 로그 확인
docker logs --tail 50 <container_id>
# 시스템 OOM 로그 확인
dmesg | grep -i "out of memory" | tail -10
# [123456.789] Out of memory: Kill process 1234 (node) score 900 or sacrifice child
# [123456.790] Killed process 1234 (node) total-vm:1048576kB, anon-rss:524288kB
# 컨테이너 리소스 제한 확인
docker inspect <container_id> | grep -A5 Memory
임시 해결 (Docker 단독 환경)
# 수동 재시작
docker start <container_id>
# 또는 메모리 제한을 높여서 새로 실행
docker run -d --name my-api --memory="512m" --restart=on-failure:5 my-api:latest
근본 해결: Kubernetes에서는
# resources.limits로 OOM 전에 Pod를 재스케줄
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
# → OOM 발생 시 K8s가 자동으로 새 Pod 생성
# → 알림 없이 새벽에 자동 복구됨
핵심 교훈: 수동 관리 환경에서는 컨테이너 다운 = 서비스 다운 + 사람의 수동 개입 필요. Kubernetes는 이 개입을 자동화합니다.
Docker 컨테이너 단독 실행 — 자동 복구 없음 확인
docker run -d --name orch-test alpine sh -c 'echo started; sleep 5; exit 1'
sleep 8 && docker ps -a | grep orch-test예상 출력
orch-test alpine "sh -c 'echo star..." Exited (1)
--restart=always 옵션 동작 확인
docker run -d --name restart-demo --restart=always alpine sh -c 'sleep 3; exit 1'
sleep 10 && docker inspect restart-demo --format '{{.RestartCount}} restarts'예상 출력
3 restarts
수동 스케일링의 번거로움 체험
for i in 1 2 3; do docker run -d --name web-demo-$i nginx:alpine; done
docker ps --format 'table {{.Names}}\t{{.Status}}'예상 출력
NAMES STATUS web-demo-3 Up web-demo-2 Up web-demo-1 Up
Kubernetes 선언적 배포 비교 (kubectl 환경에서)
kubectl create deployment nginx-demo --image=nginx:alpine --replicas=3
kubectl get deployment nginx-demo예상 출력
NAME READY UP-TO-DATE AVAILABLE nginx-demo 3/3 3 3
실습 리소스 정리
docker rm -f orch-test restart-demo web-demo-1 web-demo-2 web-demo-3 2>/dev/null; kubectl delete deployment nginx-demo 2>/dev/null; echo done예상 출력
done
심화 — 자가 치유가 못 고치는 것
심화: CrashLoopBackOff의 의미 — 인프라는 고쳐도 앱 버그는 못 고친다
이 모듈에서 K8s가 죽은 파드를 자동으로 되살린다는 것을 배웠습니다. 그런데 자동 복구를 믿고 배포했더니 파드가 Running도 아니고 CrashLoopBackOff에 갇혀 영영 안 뜨는 상황을 실무 첫날 만나게 됩니다. 자가 치유가 무엇을 고치고 무엇을 못 고치는지 선을 그어야 합니다.
- 자가 치유의 범위: reconcile 루프와 ReplicaSet은 파드 개수를 원하는 수로 되돌립니다. 노드가 죽거나 파드가 사라지면 새로 띄우는, 곧 인프라 수준의 소실을 복구하는 일입니다.
- 못 고치는 것: 파드가 떠도 앱이 시작 즉시 크래시하면(잘못된 설정, 없는 환경변수, 못 붙는 DB, 마이그레이션 실패) K8s는 그 원인을 모릅니다. 재시작만 반복하고, 반복이 잦아지면 지수 백오프로 재시작 간격을 늘립니다(10s → 20s → 40s … 최대 5분). 이 상태가
CrashLoopBackOff입니다. - 왜 이렇게 설계됐나: 무한 즉시 재시작은 노드 CPU를 태우고 로그를 폭주시킵니다. 백오프는 고장난 걸 계속 못 고치니 간격을 늘려 피해를 줄이자는 방어이자, 되살아나길 기다리지 말고 사람이 로그를 보라는 신호입니다.
정리하면 자가 치유는 인프라 장애를 자동 복구하지만 애플리케이션 버그는 못 고칩니다. Docker의 --restart=always가 무한 즉시 재시작으로 CPU를 태우던 문제를 K8s는 백오프로 다스릴 뿐입니다. CrashLoopBackOff를 보면 알아서 하겠지가 아니라 kubectl logs --previous로 크래시 원인을 읽는 게 첫 수순입니다.
상황: kubectl apply로 새 이미지를 배포했는데 kubectl get pods를 보니 RESTARTS가 계속 오르고 STATUS는 CrashLoopBackOff입니다. 시간이 지나도 Running으로 넘어가지 않습니다. 자동 복구를 기대했는데 오히려 서비스가 뜨지 않습니다.
원인: 파드는 정상적으로 스케줄되고 컨테이너도 시작하지만, 앱 프로세스가 시작 직후 종료(exit 1)합니다. 흔한 원인은 필수 환경변수·ConfigMap 누락, 붙지 못하는 DB 주소, 잘못된 커맨드, 마이그레이션 실패입니다. K8s는 왜 죽었는지를 모르므로 재시작을 반복하고, 반복이 잦아지자 백오프로 간격을 늘려 CrashLoopBackOff로 표시합니다. 이건 K8s의 고장이 아니라 앱 시작 실패를 알리는 정상 동작입니다.
진단: kubectl logs <pod> --previous로 죽기 직전(이전 컨테이너)의 로그를 봅니다 — 진짜 원인이 거의 여기 있습니다. kubectl describe pod <pod>의 Events와 Last State의 Terminated에서 Exit Code·Reason을 확인합니다. Exit Code가 137(OOM)인지 1(앱 에러)인지에 따라 리소스 문제인지 설정·버그 문제인지 갈립니다.
해결: 근본 원인은 앱·설정 쪽이므로 그것을 고쳐 새 이미지·매니페스트로 다시 배포합니다. reconcile 루프는 고쳐진 선언이 들어와야 정상 상태로 수렴하며, 스스로 버그를 고치지는 않습니다. 배포 전 readinessProbe를 걸어 두면 준비 안 된 새 파드로 트래픽이 넘어가는 것을 막아 롤아웃이 자동으로 멈추고 구버전이 계속 트래픽을 처리합니다.
실무 시나리오: 스타트업 → 성장 → K8s 도입 시점
Phase 1 (초기 스타트업): Docker만으로 충분
- 서비스 2-3개, 서버 1-2대
- 팀 규모 소수, 트래픽 예측 가능
- 복잡한 인프라보다 빠른 배포가 우선
# 이 정도는 docker-compose로 충분
docker-compose up -d
Phase 2 (성장기): 한계 도달 신호
- 새벽 알림에 팀원이 지침
- 서비스 개수 5개 이상, 서버 3대 이상
- 배포 시 다운타임이 사용자에게 영향
- 트래픽 급등 시 수동 대응에 지침
Phase 3 (K8s 도입): 자동화 전환
SRE 팀에서 흔히 듣는 말: "K8s 세팅 비용은 크지만, 그 이후 새벽 알림이 90% 줄었다."
# K8s 도입 후 배포
kubectl apply -f deployment.yaml
# → 롤링 업데이트 자동
# → 실패 시 자동 롤백
# → 스케일링 자동
# → 새벽 장애 자동 복구
현실적 조언: K8s는 작은 서비스엔 과할 수 있습니다. 하지만 서비스가 성장하고 팀이 새벽 알림에 지치기 시작했다면, 그때가 도입 시점입니다. 이 트랙은 그 결정을 내리기 위한 기반 지식을 제공합니다.
명령어·단축키 빠른 참조
이 모듈은 "Docker 단독 운영의 한계 → Kubernetes 자동화"를 비교하며 다뤘습니다. 그 과정에서 쓴 docker·kubectl 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
docker ps / docker ps -a | 실행 중·전체(종료 포함) 컨테이너 확인 | docker ps -a로 Exited·Exit Code 확인 |
docker run -d --restart=always | 재시작 정책으로 컨테이너 실행 | --restart=on-failure:5 / --memory="512m" |
docker start | 죽은 컨테이너 수동 재시작 | Docker 단독은 자동 복구가 없어 수동 |
docker inspect | 컨테이너 상세(재시작 횟수 등) | docker inspect <c> | grep RestartCount |
docker logs | 컨테이너 로그로 종료 원인 파악 | docker logs --tail 50 <c> |
dmesg | 커널 OOM 로그 확인 | dmesg | grep -i "out of memory" |
docker-compose up -d | 소규모는 컴포즈로 충분 | 서비스 2~3개·서버 1대 단계 |
docker rm -f | 컨테이너 강제 정리 | docker rm -f web-1 web-2 web-3 |
kubectl create deployment | K8s 선언적 배포·자동 복구 | ... nginx --image=nginx:alpine --replicas=3 |
kubectl apply -f | YAML로 원하는 상태 선언 | kubectl apply -f deployment.yaml |
kubectl get deployment | 선언 상태 반영 확인 | READY 3/3이면 정상 |
kubectl logs <pod> --previous | CrashLoopBackOff 원인(이전 로그) | 크래시 직전 컨테이너 로그 확인 |
관련 모듈로 더 깊이:
- Control Plane과 Worker Node 컴포넌트 간 유기적 구조 분석 — 오케스트레이션을 실제로 수행하는 클러스터의 내부 구조
- Deployment를 이용한 안정적인 서비스 배포와 롤백 전략 — 자동 복구·롤링 업데이트·스케일링이 실제로 동작하는 단위
- get, describe, logs, exec 필수 kubectl 명령어 10선 — 이 모든 것을 명령어로 다루는 첫 진입점
- 포트 바인딩 오류 방지와 컨테이너의 핵심 상태 변화 — K8s가 오케스트레이션하는 그 컨테이너의 생애주기 (Docker 트랙 · 이 모듈의 선수 개념)
다음 모듈 cluster-architecture에서는 Kubernetes 클러스터의 내부 구조, Control Plane과 Worker Node의 각 컴포넌트가 어떤 역할을 하는지 살펴봅니다.