이벤트 페이지 트래픽이 평소의 10배로 뛰자 운영팀이 수동으로 kubectl scale을 반복하고 있습니다. 사람의 판단 속도로는 급격한 부하 변화와 야간 트래픽을 안정적으로 따라가기 어렵습니다. HPA는 메트릭을 기준으로 Pod 수를 자동 조절해 온콜 부담을 줄입니다.
블랙프라이데이 당일 오전 10시, 이벤트 페이지에 트래픽이 몰리기 시작했습니다. 평소의 10배 요청이 들어오는데 파드는 3개뿐이고 응답 시간은 계속 늘어납니다. 팀원이 수동으로 kubectl scale deployment를 실행해 파드를 20개로 늘렸지만, 5시간 뒤 트래픽이 줄었을 때는 다시 수동으로 줄여야 했습니다. 만약 HPA가 설정되어 있었다면 이 모든 과정이 자동으로 일어났을 겁니다.
HPA(Horizontal Pod Autoscaler)는 파드의 리소스 사용량이나 커스텀 메트릭을 기반으로 Deployment나 ReplicaSet의 파드 수를 자동으로 조절합니다. CPU 사용률이 목표값을 넘으면 파드를 추가하고, 내려가면 줄입니다. 이 자동화가 없으면 운영팀은 항상 모니터링 화면 앞에 붙어 있어야 하며, 새벽에도 알람에 반응해야 합니다. HPA는 "트래픽에 알아서 대응하는 시스템"을 만드는 첫 번째 단계입니다.
- 1metrics-server를 설치하고 동작 원리를 설명할 수 있다
- 2kubectl autoscale과 YAML로 HPA 리소스를 생성할 수 있다
- 3스케일 업·다운 동작 과정을 이해할 수 있다
- 4HPA 상태를 읽고 트러블슈팅할 수 있다
- 5안정화 윈도우와 스케일링 정책을 커스텀할 수 있다
- 6메모리 기반 스케일링과 커스텀 메트릭을 적용할 수 있다
kubectl get deployment metrics-server -n kube-system 2>/dev/null || echo 'NOT INSTALLED'kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.2/components.yamlkubectl top nodeskubectl create namespace hpa-demometrics-server: HPA의 눈
HPA를 만들었는데 kubectl get hpa에서 TARGETS가 계속 <unknown>/50%로 표시된다면, metrics-server가 없기 때문입니다. HPA는 스케일링 결정을 내리기 위해 실시간 CPU 사용량이 필요하지만 그 데이터를 스스로 수집하지 않습니다. metrics-server가 각 노드의 kubelet에서 리소스 사용량을 수집하고 Metrics API로 제공해야 비로소 HPA가 동작합니다. 이 의존 관계를 모르면 HPA 설정은 올바른데 왜 스케일이 안 되는지 원인을 찾지 못합니다.
 확대
확대
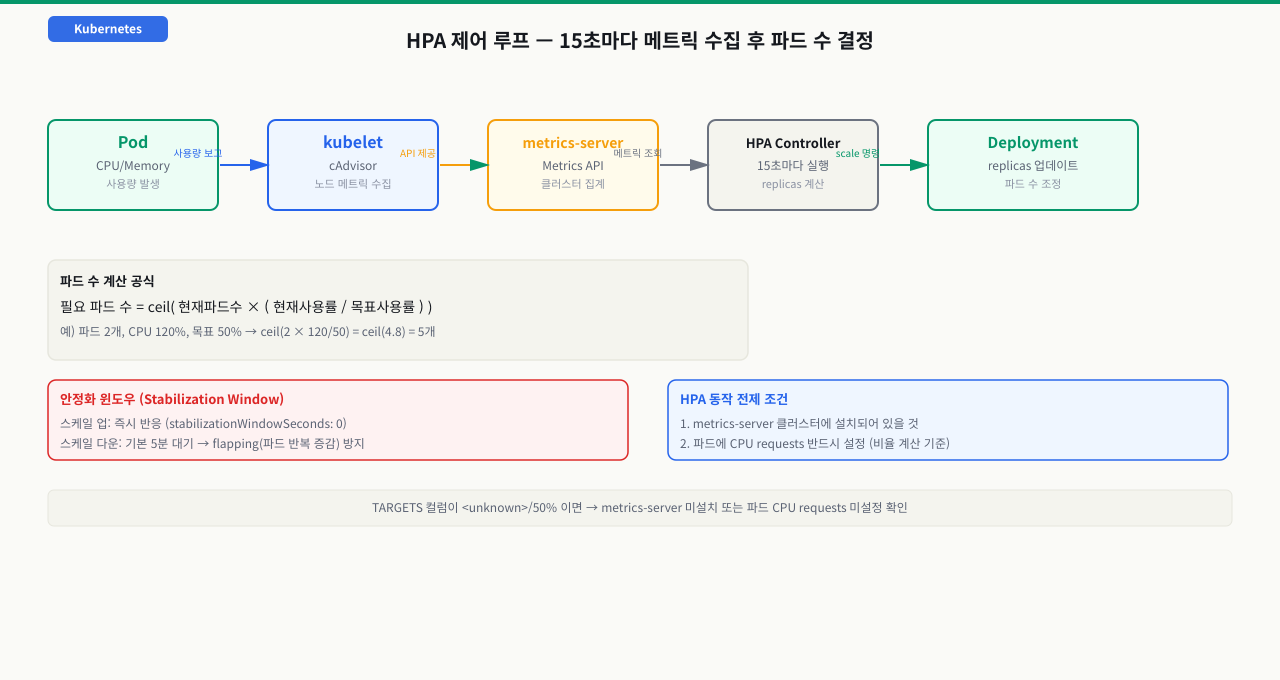
파드 → kubelet(cAdvisor) → metrics-server → Metrics API → HPA 컨트롤러
# metrics-server 설치 (로컬 클러스터에서는 TLS 검증 비활성화 필요할 수 있음)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.2/components.yaml
# 로컬 Kind/Minikube 클러스터용: TLS 검증 비활성화 패치
kubectl patch deployment metrics-server -n kube-system \
--type='json' \
-p='[{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"--kubelet-insecure-tls"}]'
# 설치 확인 (30초~1분 소요)
kubectl rollout status deployment/metrics-server -n kube-system
# 메트릭 수집 확인
kubectl top nodes
# NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
# kind-worker 55m 1% 512Mi 26%
kubectl top pods -A
# NAMESPACE NAME CPU(cores) MEMORY(bytes)
# kube-system coredns-xxx 5m 18Mi
- kubectl get hpa에서 TARGETS 열 먼저 확인 — "5%/50%" 형식이면 정상(현재/목표), "<unknown>/50%"이면 metrics-server 미설치 또는 파드에 CPU requests 미설정
- REPLICAS 수치 기준: minReplicas 이상 maxReplicas 이하여야 정상. 부하 중에도 maxReplicas에 고정되면 노드 리소스 부족으로 더 이상 스케일 불가 — kubectl describe node로 Allocatable 확인
- TARGETS 사용률이 목표치 초과인데 REPLICAS가 안 늘면 → HPA 스케일 업 쿨다운(기본 3분) 중이거나 maxReplicas 도달. kubectl describe hpa <name>의 Events에서 "SuccessfulRescale" 또는 "DesiredReplicas" 메시지로 판단
부하에 따라 파드 수가 자동으로 조정되는 원리
부하가 오르면 파드 수가 자동으로 느는 법 — HPA 제어 루프 6단계
HPA를 걸어 두면 트래픽이 몰릴 때 파드가 알아서 늘고, 빠지면 줄어듭니다. 하지만 이건 마법이 아니라 기본 15초마다 도는 제어 루프의 결과입니다 — 메트릭을 읽고, 공식으로 필요한 파드 수를 계산하고, 범위로 자른 뒤, Deployment의 replicas를 고쳐 씁니다. 이 루프의 각 단계를 알면 "왜 안 늘지", "목표를 넘었는데 왜 그대로지"를 정확한 지점에서 진단할 수 있습니다.
[HPA 컨트롤러] 기본 15초 주기(--horizontal-pod-autoscaler-sync-period)
│
① metrics-server에서 대상 파드들의 CPU/메모리 수집
│ metrics-server 없으면 여기서 실패 → TARGETS 가 unknown
│
② 사용률 = 현재 사용량 / 파드의 resources.requests
│ requests 없으면 분모가 없어 계산 불가 → 역시 unknown
│
③ desiredReplicas = ceil(현재 replica × 현재값 / 목표값)
│ (목표 대비 ±10% 관용 구간이면 그대로 둠)
│
④ min/max로 클램프 → minReplicas ≤ 결과 ≤ maxReplicas
│
⑤ 스케일 업: 즉시 반영 / 스케일 다운: 안정화 윈도우(기본 5분) 후 반영
│
⑥ Deployment 의 spec.replicas 갱신 → ReplicaSet이 파드 증감
▼
[결과] 파드 수가 목표 사용률에 수렴 (노드가 아니라 '파드 수'를 조정)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 메트릭 수집 | 15초마다 Metrics API로 대상 파드의 실제 사용량을 읽는다 | metrics-server 미설치·비정상이면 수집 실패 → TARGETS가 <unknown>/50%로 굳고 스케일 불가 |
| ② 사용률 계산 | 사용량을 파드의 requests로 나눠 퍼센트를 낸다 | requests 미설정이면 분모가 없어 계산 불가 → 역시 <unknown>. requests가 너무 낮으면 사용률이 부풀려져 과잉 확장 |
| ③ 목표 수 계산 | ceil(현재 replica × 현재값/목표값)으로 필요 수 산출 | 목표 대비 ±10%(관용) 안이면 무반응 — 목표 50%에 52%는 그대로 둔다 |
| ④ 범위 클램프 | min·max 사이로 자른다 | 부하가 높아도 maxReplicas에 닿으면 더 못 늘림 → maxReplicas 도달 알람이 필요 |
| ⑤ 방향별 타이밍 | 업은 즉시, 다운은 안정화 윈도우로 지연 | 부하가 빠졌는데 파드가 안 주는 건 정상 — 5분 관찰 후 축소(flapping 방지) |
| ⑥ replicas 갱신 | 계산 결과를 Deployment에 써서 파드를 늘리고 줄인다 | 노드 자원이 부족하면 새 파드가 Pending — HPA는 파드 수만 늘릴 뿐 노드는 못 늘림 |
핵심은 HPA가 조정하는 대상이 '노드'가 아니라 '파드 수'라는 것입니다 — 사용률이 목표를 넘으면 파드를 더 찍어내지만, 그 파드를 올릴 노드 여유가 없으면 새 파드는 Pending에 걸립니다. 노드까지 자동으로 늘리는 건 HPA가 아니라 Cluster Autoscaler의 몫입니다. 그리고 이 계산의 두 축 — metrics-server(수집)와 resources.requests(사용률의 분모) — 중 하나만 없어도 루프는 ①②에서 <unknown>으로 멈춥니다.
진단은 루프의 입력부터. kubectl get hpa로 TARGETS가 <unknown>인지 실제 값인지 보고(입력이 들어오는지 판정), <unknown>이면 metrics-server 상태와 파드 requests를 확인합니다. 값은 정상인데 REPLICAS가 기대와 다르면 kubectl describe hpa의 Events에서 SuccessfulRescale·목표 계산 로그와 안정화 윈도우 대기를 읽고, kubectl top pod로 HPA가 본 실제 사용량이 맞는지 대조합니다.
HPA 생성: 기본 CPU 기반 스케일링
이벤트 트래픽이 몰릴 것을 예상해 HPA를 미리 설정했는데 막상 부하가 들어와도 파드가 늘어나지 않는다면, CPU requests가 설정되지 않았을 가능성이 높습니다. HPA는 "현재 CPU 사용량 / CPU requests"로 사용률을 계산하는데 requests가 없으면 비율 계산 자체가 불가능합니다. 반대로 requests가 너무 낮게 설정되면 실제 부하가 낮아도 HPA가 과도하게 스케일 업해 비용이 낭비됩니다. HPA 설정 시 minReplicas, maxReplicas, 목표 사용률을 서비스 특성에 맞게 조율하는 것이 실무 운영의 핵심입니다.
 확대
확대
# php-apache-deployment.yaml
# 부하 테스트에 자주 쓰이는 예시 이미지
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
namespace: hpa-demo
spec:
replicas: 1
selector:
matchLabels:
app: php-apache
template:
metadata:
labels:
app: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
requests:
cpu: "200m" # HPA 계산 기준값 (필수!)
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
namespace: hpa-demo
spec:
ports:
- port: 80
selector:
app: php-apache
kubectl apply -f php-apache-deployment.yaml
# 방법 1: kubectl autoscale (빠른 생성)
kubectl autoscale deployment php-apache \
-n hpa-demo \
--cpu-percent=50 \
--min=1 \
--max=10
# 방법 2: YAML로 생성 (권장, GitOps 관리 가능)
cat <<EOF | kubectl apply -f -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa
namespace: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # CPU 사용률 50% 목표
EOF
# HPA 상태 확인
kubectl get hpa -n hpa-demo
# NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
# php-apache-hpa Deployment/php-apache 3%/50% 1 10 1 30s
TARGETS 컬럼 읽는 법: 현재사용률/목표사용률. 3%/50%는 현재 3%를 쓰고 있고 목표는 50%라는 의미입니다.
스케일링 동작 과정과 안정화 윈도우
트래픽이 잠깐 치솟았다 내려갈 때마다 파드가 늘었다 줄었다를 반복하면 파드 시작/종료 오버헤드가 오히려 서비스 안정성을 해칩니다. 이 "플래핑" 문제를 막기 위해 HPA는 스케일 다운에 기본 5분 안정화 윈도우를 적용합니다. 스케일 업은 즉각 반응해야 하지만 스케일 다운은 신중해야 한다는 운영 원칙이 반영된 설계입니다. 안정화 윈도우와 스케일링 정책을 커스텀하면 서비스 특성에 맞는 민감도를 조율할 수 있습니다.
필요 파드 수 = ceil(현재파드수 × (현재사용률 / 목표사용률))
예: 파드 1개, 현재 CPU 150%, 목표 50%
→ ceil(1 × (150 / 50)) = ceil(3) = 3개
스케일 다운이 느린 이유는 안정화 윈도우 때문입니다.
# 스케일링 정책 커스텀
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa-custom
namespace: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 2 # 최소 2개 유지 (HA 보장)
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # 즉시 스케일 업
policies:
- type: Percent
value: 100 # 한 번에 최대 100% 증가
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300 # 5분 안정화 후 스케일 다운
policies:
- type: Pods
value: 2 # 한 번에 최대 2개씩 감소
periodSeconds: 60
실습: 부하 테스트로 HPA 동작 확인
# 터미널 1: HPA 상태 실시간 모니터링
watch kubectl get hpa php-apache-hpa -n hpa-demo
# 터미널 2: 부하 생성 (무한 HTTP 요청)
kubectl run load-generator \
--image=busybox:1.36 \
--restart=Never \
-n hpa-demo \
-- /bin/sh -c "while true; do wget -q -O- http://php-apache.hpa-demo.svc.cluster.local; done"
# 터미널 1에서 변화 관찰 (약 1-2분 소요)
# NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
# php-apache-hpa Deployment/php-apache 3%/50% 1 10 1
# php-apache-hpa Deployment/php-apache 142%/50% 1 10 1 ← 급등
# php-apache-hpa Deployment/php-apache 142%/50% 1 10 3 ← 스케일 업
# php-apache-hpa Deployment/php-apache 72%/50% 1 10 4
# php-apache-hpa Deployment/php-apache 53%/50% 1 10 5
# 파드 수 변화 확인
kubectl get pods -n hpa-demo -w
# 부하 중단 (터미널 2에서) — 아래 DangerBlock 확인 후 실행
부하 생성 파드 삭제 — HPA 스케일 다운 트리거
안전한 실행 조건: kubectl config current-context 로 개발 클러스터인지 확인. kubectl get pod -n hpa-demo 로 load-generator 파드가 실습용인지 확인 후 실행하세요.
실행 전 반드시 확인
- kubectl config current-context 로 현재 컨텍스트가 개발 클러스터(minikube 등)인지 확인
- kubectl get pod load-generator -n hpa-demo 로 삭제 대상 파드 확인
kubectl delete pod load-generator -n hpa-demo위 항목을 모두 확인한 후 복사할 수 있습니다
kubectl delete pod load-generator -n hpa-demo
# 약 5분 후 파드가 다시 줄어듦 (안정화 윈도우)
# 스케일 다운 이벤트 확인
kubectl describe hpa php-apache-hpa -n hpa-demo | grep -A 5 "Events"
HPA를 만들었는데 며칠이 지나도 파드 수가 변하지 않습니다. kubectl get hpa 결과를 보면 TARGETS 컬럼이 <unknown>/50%로 표시됩니다.
# 증상 확인
kubectl get hpa -n hpa-demo
# NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
# php-apache-hpa Deployment/php-apache <unknown>/50% 1 10 1
# 1단계: HPA 이벤트 확인
kubectl describe hpa php-apache-hpa -n hpa-demo | tail -20
# Events:
# Warning FailedGetResourceMetric 2m horizontal-pod-autoscaler
# unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API
# 2단계: metrics-server 설치 여부 확인
kubectl get pods -n kube-system | grep metrics-server
# (아무 출력도 없음 — 미설치)
# 또는 설치는 됐지만 비정상
# metrics-server-xxx 0/1 CrashLoopBackOff 5 10m
# 3단계-A: metrics-server 설치
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.2/components.yaml
# 3단계-B: 로컬 클러스터(Kind/Minikube)라면 TLS 패치 추가
kubectl patch deployment metrics-server -n kube-system \
--type='json' \
-p='[{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"--kubelet-insecure-tls"}]'
# 4단계: metrics-server 정상화 확인 (1-2분 소요)
kubectl rollout status deployment/metrics-server -n kube-system
kubectl top nodes # 이게 나와야 정상
# NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
# 5단계: HPA 상태 재확인
kubectl get hpa -n hpa-demo
# NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
# php-apache-hpa Deployment/php-apache 3%/50% 1 10 1
# ↑ <unknown>가 실제 값으로 바뀜
# 추가: requests 미설정 케이스
# 만약 metrics-server는 정상인데 여전히 unknown이면
kubectl get pod -n hpa-demo -o jsonpath='{.items[0].spec.containers[0].resources}'
# {} ← requests가 없음! CPU requests를 설정해야 HPA가 동작함
원인 요약: HPA의 <unknown> 문제는 99%가 (1) metrics-server 미설치/비정상, (2) 파드에 CPU requests 미설정, 이 두 가지입니다. 두 가지를 순서대로 확인하면 빠르게 해결됩니다.
심화 — HPA는 '즉시'가 아니다: 지연 사슬과 관측 반응
심화: HPA가 늦게 반응하는 이유 — 지연 사슬·관용·준비성
metrics-server가 붙고 공식대로 계산돼도 HPA가 부하 급증에 곧바로 반응하는 건 아닙니다. HPA는 미래를 예측하는 게 아니라 관측한 값에 반응하는 제어 루프라, 그 반응까지 여러 단계의 지연이 겹칩니다. 이 지연의 출처를 알아야 스파이크성 트래픽에서 HPA만 믿다 낭패 보지 않습니다.
- 지연 사슬: 컨테이너가 CPU를 태움 → kubelet/cAdvisor가 표본을 모음 → metrics-server가 수십 초 해상도로 집계 → HPA 컨트롤러가 기본 15초 주기로 읽어 계산 → 새 파드가 스케줄·이미지 풀·기동·Ready. 이 사슬 전체가 더해져 급증 시점부터 실제 처리 능력이 늘 때까지 1~2분 이상 걸릴 수 있습니다. HPA는 "즉시"가 아닙니다.
- 관용(tolerance): 목표 대비 실제 비율이 기본 ±10% 안이면 HPA는 아무것도 하지 않습니다. 목표 50%에서 52%는 그대로 둡니다. 자잘한 변동에 출렁이지 않게 만든 의도된 무반응 구간입니다.
- 준비성 게이팅: 아직 Ready가 아니거나 방금 뜬 파드는 평균 계산에서 제외·보정됩니다. 덕분에 콜드스타트 CPU 스파이크가 곧장 과잉 스케일업으로 번지진 않지만, 반대로 CPU requests를 너무 낮게 잡으면 사용률이 부풀려져 과잉 확장이 날 수 있습니다.
- 메모리 기반 HPA의 함정: 많은 런타임이 한 번 늘어난 힙을 OS에 잘 반환하지 않아, 부하가 빠져도 메모리 사용률이 잘 안 내려갑니다. 그래서 memory 타깃 HPA는 축소가 거의 안 일어나기도 합니다 — 확장 트리거로는 CPU나 커스텀 지표가 대체로 더 낫습니다.
정리하면 HPA는 "예측"이 아니라 "관측 후 반응"입니다. 예고된 급증(정산·오픈런)은 HPA에만 맡기지 말고 minReplicas 상향이나 예약 스케일링으로 미리 바닥을 높여 둡니다.
상황: 이벤트 오픈 순간 요청이 10배로 뛰었습니다. HPA는 정상 설정돼 있었지만, 초반 1~2분간 기존 파드가 포화돼 타임아웃·5xx가 터졌고, 파드 증설은 그 사태가 한창일 때 뒤늦게 시작됐습니다.
원인: HPA는 관측 기반 반응 루프라 본질적으로 지연이 있습니다. 메트릭 수집·집계·15초 주기 계산에 더해, 새 파드가 스케줄→이미지 풀→기동→Ready가 되어 실제로 트래픽을 받기까지 또 시간이 걸립니다. "급증 시점"과 "증설된 용량이 실제로 도는 시점" 사이의 이 공백에 장애가 난 것입니다. HPA 설정 자체엔 문제가 없었습니다.
진단: kubectl describe hpa의 이벤트 타임스탬프와 요청 급증 시각을 겹쳐 봅니다. 급증 후 첫 스케일업 이벤트까지의 간격, 그리고 새 파드가 Ready가 된 시각까지의 추가 간격을 각각 재면 지연이 "감지"에서 왔는지 "기동"에서 왔는지 나뉩니다. 이미지 풀 시간과 프로브 initialDelaySeconds도 함께 확인합니다.
해결: 예고된 급증은 HPA에만 의존하지 않습니다 — 이벤트 전 minReplicas를 미리 올리거나(수동·예약) 바닥 용량을 확보합니다. scaleUp behavior를 더 공격적으로(짧은 periodSeconds·큰 percent 정책) 잡아 반응을 앞당기고, 이미지 프리풀·가벼운 기동·적절한 readiness로 새 파드가 빨리 트래픽을 받게 합니다. 근본적으로 CPU보다 앞서 움직이는 선행 지표(대기열 길이·초당 요청 수)가 있으면 그걸 커스텀 지표로 삼아 더 일찍 늘립니다.
시나리오: 프로덕션 API 서버에 HPA 도입
월말 정산이 있는 서비스를 운영 중입니다. 평소에는 파드 3개로 충분한데 매월 1일 새벽에 트래픽이 10배 이상 몰려 수동으로 스케일을 조절하고 있습니다. HPA로 이 작업을 자동화하려고 합니다.
# 1단계: 현재 리소스 설정 확인 및 requests 추가
kubectl get deployment api-server -n production \
-o jsonpath='{.spec.template.spec.containers[0].resources}'
# requests가 없다면 먼저 추가
kubectl set resources deployment/api-server \
-n production \
--requests=cpu=200m,memory=256Mi \
--limits=cpu=1000m,memory=512Mi
# 2단계: HPA 생성 (YAML 파일로 관리 권장)
cat <<EOF > api-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-server-hpa
namespace: production
annotations:
description: "월말 정산 트래픽 대응용 HPA"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
minReplicas: 3 # 평소 최솟값 (HA)
maxReplicas: 30 # 월말 최대 예상 × 1.5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
behavior:
scaleUp:
stabilizationWindowSeconds: 60 # 1분 안정화 후 스케일 업
scaleDown:
stabilizationWindowSeconds: 600 # 10분 안정화 후 스케일 다운
EOF
kubectl apply -f api-hpa.yaml
# 3단계: 월말 이벤트 전 부하 테스트로 스케일링 검증
kubectl run load-test \
--image=grafana/k6 \
--restart=Never \
-n production \
-- run - <<'K6SCRIPT'
import http from 'k6/http';
export let options = { vus: 100, duration: '5m' };
export default function() { http.get('http://api-server/health'); }
K6SCRIPT
watch kubectl get hpa api-server-hpa -n production
# 4단계: 알람 설정 (HPA가 maxReplicas에 도달하면 알람)
# Prometheus AlertManager 또는 클라우드 알람으로 설정
# kube_horizontalpodautoscaler_status_current_replicas == kube_horizontalpodautoscaler_spec_max_replicas
실무 포인트: maxReplicas에 도달하면 HPA는 더 이상 스케일 업을 못 합니다. 이 상황이 되면 사람이 개입해야 하므로, maxReplicas 도달 시 알람을 반드시 설정해두세요. Cluster Autoscaler와 함께 사용하면 노드 자체도 자동으로 늘릴 수 있습니다.
metrics-server 설치 및 동작 확인
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.2/components.yaml
kubectl rollout status deployment/metrics-server -n kube-system
kubectl top nodes예상 출력
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% minikube 120m 3% 800Mi 41%
CPU requests가 설정된 Deployment 배포
kubectl create namespace hpa-demo
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
namespace: hpa-demo
spec:
replicas: 1
selector:
matchLabels:
app: php-apache
template:
metadata:
labels:
app: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
resources:
requests:
cpu: '200m'
EOF
kubectl get deployment php-apache -n hpa-demo예상 출력
NAME READY UP-TO-DATE AVAILABLE AGE php-apache 1/1 1 1 15s
HPA 생성 및 상태 확인
kubectl autoscale deployment php-apache \
-n hpa-demo \
--cpu-percent=50 \
--min=1 \
--max=10
kubectl get hpa -n hpa-demo예상 출력
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 3%/50% 1 10 1 30s
부하 생성으로 스케일 업 트리거
kubectl run load-generator \
--image=busybox:1.36 --restart=Never -n hpa-demo \
-- /bin/sh -c 'while true; do wget -q -O- http://php-apache.hpa-demo.svc.cluster.local; done'
sleep 90
kubectl get hpa -n hpa-demo예상 출력
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS php-apache Deployment/php-apache 142%/50% 1 10 3
부하 제거 후 스케일 다운 확인 (약 5분 소요)
kubectl delete pod load-generator -n hpa-demo
kubectl describe hpa php-apache -n hpa-demo | grep -A5 'Events'예상 출력
Events: Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 1; reason: All metrics below target
핵심 요약
| 항목 | 설명 |
|---|---|
| HPA 전제 조건 | metrics-server 설치 + 파드에 CPU requests 설정 |
| 스케일 업 | 즉각 반응 (stabilizationWindowSeconds: 0 권장) |
| 스케일 다운 | 기본 5분 대기 (flapping 방지) |
| TARGETS: unknown | metrics-server 미설치 or requests 미설정 |
| minReplicas | HA를 위해 최소 2 이상 권장 |
| maxReplicas | 노드 용량 + 비용 고려해 현실적으로 설정 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 HPA·metrics-server 관련 kubectl 명령을 실전 옵션과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl autoscale | 빠르게 HPA 생성 | kubectl autoscale deploy php-apache --cpu-percent=50 --min=1 --max=10 |
kubectl get hpa | TARGETS(현재/목표)·REPLICAS 확인 | kubectl get hpa -n hpa-demo (unknown이면 metrics/requests 문제) |
kubectl describe hpa | 스케일 이벤트·실패 원인 | kubectl describe hpa php-apache | grep -A5 Events |
kubectl top | 노드·파드 실제 사용량 | kubectl top nodes, kubectl top pods -A |
kubectl set resources | requests/limits 설정(HPA 전제) | kubectl set resources deploy/api --requests=cpu=200m,memory=256Mi |
kubectl rollout status | metrics-server 기동 대기 | kubectl rollout status deploy/metrics-server -n kube-system |
kubectl patch deployment | metrics-server TLS 검증 끄기(로컬) | ... --type=json -p='[{"op":"add",...,"value":"--kubelet-insecure-tls"}]' |
watch kubectl get hpa | 스케일 동작 실시간 관찰 | watch kubectl get hpa php-apache-hpa -n hpa-demo |
kubectl get pods -w | 파드 증감 실시간 추적 | kubectl get pods -n hpa-demo -w |
kubectl apply -f (autoscaling/v2) | behavior 등 세밀 HPA(GitOps) | kubectl apply -f api-hpa.yaml (scaleUp/scaleDown 커스텀) |
관련 모듈로 더 깊이:
- requests와 limits 적정 값 계산과 CPU 스로틀링 대처 — HPA의 전제 조건인 CPU requests를 설정하는 법
- Deployment를 이용한 안정적인 서비스 배포와 롤백 전략 — HPA가 replicas를 조정하는 대상이 되는 Deployment
- VPA(Vertical Pod Autoscaler) 기반 실시간 리소스 최적화 — 파드 수가 아닌 파드 크기를 자동 조정하는 VPA
다음 모듈 vpa-autoscaling에서는 파드 수가 아닌 CPU·메모리 크기를 자동으로 조정하는 VPA를 다룹니다. HPA와의 차이점, Off/Auto 모드 선택 기준, HPA와 병행 사용 시 충돌을 피하는 설정을 익힙니다.