노드 패치를 위해 kubectl drain을 실행했더니 결제 파드가 동시에 내려가 서비스가 끊겼습니다. 계획된 유지보수라도 최소 가용 파드 수를 지키지 않으면 장애와 다르지 않습니다. PDB는 운영 작업 중에도 서비스 가용성을 지키도록 Eviction을 제어합니다.
PodDisruptionBudget — 무중단 노드 유지보수
새벽 2시, 클러스터 노드 패치를 위해 kubectl drain node-3을 실행했습니다. 잠시 후 슬랙 알림이 울립니다. "결제 서비스 다운, 주문 처리 불가." 나중에 확인해보니 결제 파드가 node-3에 2개, 다른 노드에 1개 있었는데 드레인으로 node-3의 파드 2개가 동시에 제거되면서 남은 파드 1개가 트래픽을 감당 못하고 OOM으로 죽은 것이었습니다. PodDisruptionBudget(PDB)는 이런 상황을 막기 위한 안전장치입니다. "이 서비스는 최소 2개의 파드가 항상 실행 중이어야 한다"고 클러스터에 선언하면, 노드 드레인이나 클러스터 업그레이드 같은 계획된 중단(voluntary disruption) 시 K8s가 이 조건을 지키면서 파드를 이동시킵니다.
- 1Voluntary Disruption과 Involuntary Disruption의 차이를 설명할 수 있다
- 2minAvailable과 maxUnavailable 설정 방식을 적용할 수 있다
- 3PDB가 kubectl drain에 미치는 영향을 설명할 수 있다
- 4퍼센트(%) 표기로 동적 보호를 설정할 수 있다
- 5PDB 상태를 모니터링하고 드레인 진행을 추적할 수 있다
- 6무중단 클러스터 업그레이드 체크리스트를 적용할 수 있다
kubectl get pdb -Akubectl create namespace pdb-demokubectl create deployment web --image=nginx --replicas=3 -n pdb-demokubectl get nodesVoluntary vs Involuntary Disruption
PDB는 **계획된 중단(Voluntary Disruption)**에만 적용됩니다. 노드 장애로 파드가 죽는 것(Involuntary)은 PDB가 막을 수 없습니다.
| 구분 | 예시 | PDB 적용 |
|---|---|---|
| Voluntary (계획됨) | kubectl drain, 클러스터 업그레이드, Eviction API | 적용됨 |
| Involuntary (비계획) | 노드 OOM, 하드웨어 장애, 커널 패닉 | 적용 안 됨 |
minAvailable vs maxUnavailable 설정
결제 서비스 파드가 3개 실행 중인데 노드 드레인 중 2개가 동시에 evict되면 남은 1개가 모든 트래픽을 받다 OOM으로 죽을 수 있습니다. PDB는 "이 서비스는 항상 최소 N개가 살아있어야 한다"는 제약을 클러스터에 선언하는 리소스입니다. 드레인이나 업그레이드 같은 계획된 중단 상황에서 Kubernetes가 이 조건을 지키면서 파드를 이동시킵니다. minAvailable과 maxUnavailable 두 가지 방식으로 보호 수준을 표현할 수 있으며, 서비스 특성에 따라 적합한 쪽을 선택합니다.
두 설정 모두 절대값과 퍼센트(%) 표기를 지원합니다.
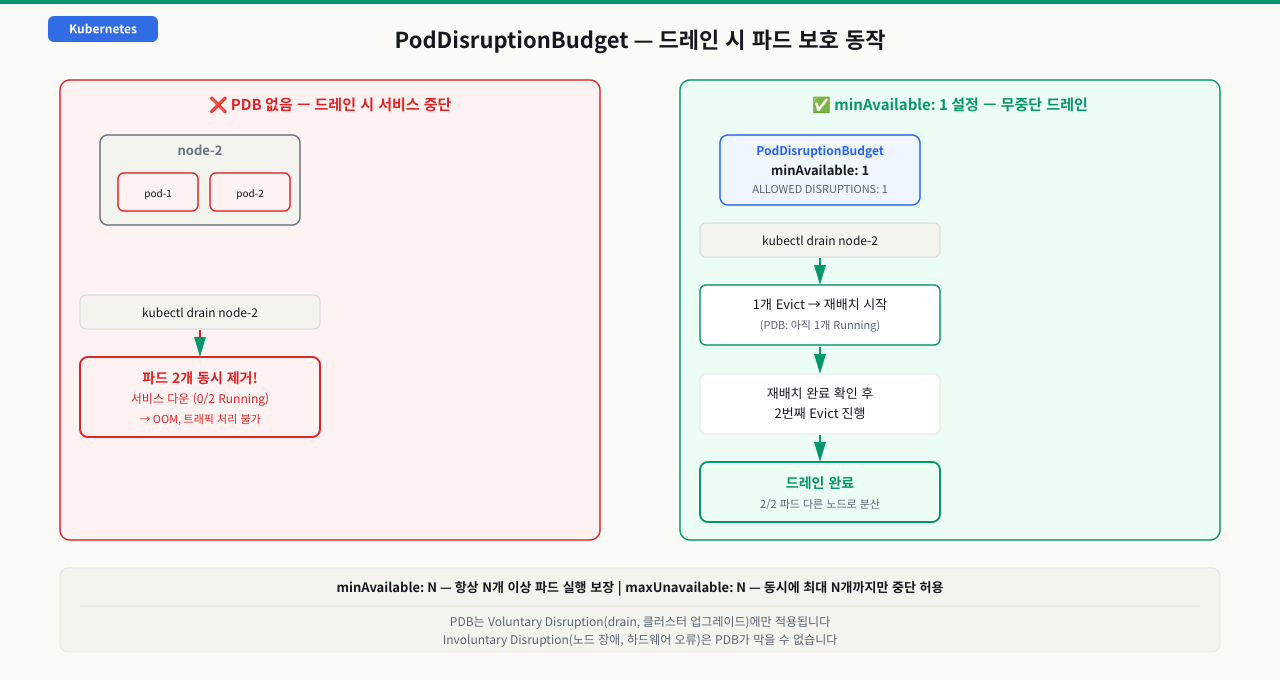 확대
확대
# minAvailable: 절대값 — 항상 최소 2개 실행 보장
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-pdb-min
namespace: pdb-demo
spec:
minAvailable: 2 # 절대값: 최소 2개
selector:
matchLabels:
app: web
---
# minAvailable: 퍼센트 — 전체의 66% 이상 실행 보장
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-pdb-percent
namespace: pdb-demo
spec:
minAvailable: "66%" # 3개 중 2개 (66.6% → 올림)
selector:
matchLabels:
app: web
---
# maxUnavailable: 한 번에 최대 1개만 중단 허용
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-pdb-max
namespace: pdb-demo
spec:
maxUnavailable: 1 # 동시에 최대 1개까지 중단 가능
selector:
matchLabels:
app: web
kubectl apply -f web-pdb-min.yaml
# PDB 상태 확인
kubectl get pdb -n pdb-demo
# NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
# web-pdb-min 2 N/A 1 30s
# ↑ 현재 3개 중 1개까지 내릴 수 있음
kubectl describe pdb web-pdb-min -n pdb-demo
# Status:
# Observed Generation: 1
# Disruptions Allowed: 1 ← 현재 Evict 가능한 파드 수
# Current Healthy: 3
# Desired Healthy: 2 (= minAvailable)
# Expected Pods: 3
- kubectl describe pdb <name>에서 Disruptions Allowed 값을 먼저 확인 — 0이면 현재 drain이 차단됨. Current Healthy가 minAvailable과 같거나 낮으면 파드를 한 개도 더 제거할 수 없는 상태
- Disruptions Allowed 수치 기준: minAvailable: 2이고 전체 파드 수가 3이면 1개 drain 가능, 2이면 0개 drain 가능. kubectl drain이 멈추면 Disruptions Allowed=0인 상태로 kubectl describe pdb로 즉시 확인
- kubectl drain이 오래 걸리고 "Cannot evict pod as it would violate PDB" 가 반복되면 → readinessProbe 실패로 일부 파드가 Healthy 카운트에서 제외된 것. kubectl get pods -l <selector>로 Running이지만 READY=0/1인 파드 찾기
축출 요청이 PDB 게이트를 통과하는 법 — 요청에서 재배치까지 5단계
PDB를 걸어두면 노드를 drain해도 서비스가 한꺼번에 죽지 않습니다. 비결은 kubectl drain이 파드를 직접 delete하지 않고 Eviction API를 거치며, 그 앞에 PDB라는 게이트가 있기 때문입니다. 축출 요청 하나가 이 게이트에서 허용될지 거부될지를 단계로 알면 "drain이 왜 멈췄지", "왜 한 개씩만 빠지지", "노드 고장은 왜 못 막지"를 정확히 설명할 수 있습니다.
[운영자] kubectl drain node-3 (또는 업그레이드·스케일다운의 축출)
│
① 축출 요청: 대상 파드마다 Eviction API 호출 (직접 delete가 아님)
│
② PDB 매칭: API server가 파드 라벨로 매칭되는 PDB를 selector로 찾음
│ → 매칭되는 PDB가 없으면 게이트 없이 바로 축출 (③④ 건너뜀)
│
③ 예산 계산: ALLOWED = Current Healthy − Desired Healthy(minAvailable 환산)
│
④ 판정:
│ ALLOWED > 0 → 축출 허용, 파드 종료 → 예산 1 감소
│ ALLOWED = 0 → 429 Too Many Requests로 거부 → drain 대기(재시도)
│
⑤ 재배치·회복: 축출된 파드가 다른 노드에서 Ready → Current Healthy 회복
│ → 예산이 다시 >0 → 다음 파드 축출 (항상 minAvailable만큼은 생존)
▼
[결과] 노드 유지보수 중에도 최소 가용 파드 수 유지
(자발적 중단만 보호 · 노드 고장 같은 비자발적 중단은 못 막음)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 막히면 증상 |
|---|---|---|
| ① 축출 요청 | drain·업그레이드·스케일다운이 대상 파드에 Eviction API 호출 | 노드 고장·커널 패닉 같은 비자발적 중단은 이 경로를 안 거쳐 PDB가 못 막음 |
| ② PDB 매칭 | API server가 파드 라벨로 매칭 PDB를 selector로 탐색 | selector 라벨이 파드와 안 맞으면 보호가 아예 안 걸림(게이트 없이 통과) |
| ③ 예산 계산 | ALLOWED = Current Healthy − Desired Healthy(minAvailable 환산) | unready·CrashLoop 파드가 Current Healthy를 깎아 예산이 0으로 떨어짐 |
| ④ 판정 | ALLOWED>0이면 축출 진행(예산 1 감소), 0이면 429로 거부·대기 | minAvailable=레플리카 수·단일 레플리카+minAvailable:1이면 예산이 처음부터 0 → 영구 대기 |
| ⑤ 재배치·회복 | 축출 파드가 다른 노드에서 Ready → 예산 회복 → 다음 축출 | 다른 노드 여유 없음·anti-affinity로 Pending이면 재배치 실패 → 다음 축출도 막힘 |
즉 PDB는 drain을 막는 게 아니라 **"한 번에 minAvailable만큼은 항상 살려두는 속도 제한"**입니다. drain이 멈추면 kubectl describe pdb로 ALLOWED가 0인지 보고, 0이면 과조임(④: minAvailable을 낮추거나 maxUnavailable로 전환·이중화)인지 건강 문제(③: unready 파드 복구 또는 unhealthyPodEvictionPolicy: AlwaysAllow)인지 가릅니다. 그리고 이 게이트는 자발적 중단에만 작동하므로(①), 노드 고장 대비는 PDB가 아니라 레플리카 수·멀티노드 분산의 몫입니다.
PDB와 kubectl drain의 상호작용
노드 유지보수를 위해 kubectl drain을 실행했는데 파드가 예상보다 빠르게 모두 내려가면서 서비스가 중단된 경험이 있다면, PDB 설정이 없었기 때문일 가능성이 높습니다. PDB가 설정된 환경에서 drain은 단순히 파드를 삭제하지 않고 Eviction API를 통해 PDB 조건을 확인하면서 순서대로 파드를 옮깁니다. 이 동작을 이해하면 drain이 멈추는 이유, 언제 다음 파드를 내릴 수 있는지를 정확히 예측할 수 있습니다.
kubectl drain은 내부적으로 Eviction API를 호출합니다. PDB 위반 시 429 Too Many Requests를 반환하고, drain은 이를 받아 대기합니다.
⚠️
kubectl delete pod같은 일반 삭제는 Eviction API를 거치지 않으므로 PDB가 차단하지 않습니다. PDB는 강제 삭제나 노드 장애를 막는 방화벽이 아니라,drain·Eviction API 같은 자발적 중단 요청에만 적용되는 보호 장치입니다. 운영 검증은kubectl drain <node> --dry-run=server와kubectl get/describe pdb로 먼저 수행하세요.
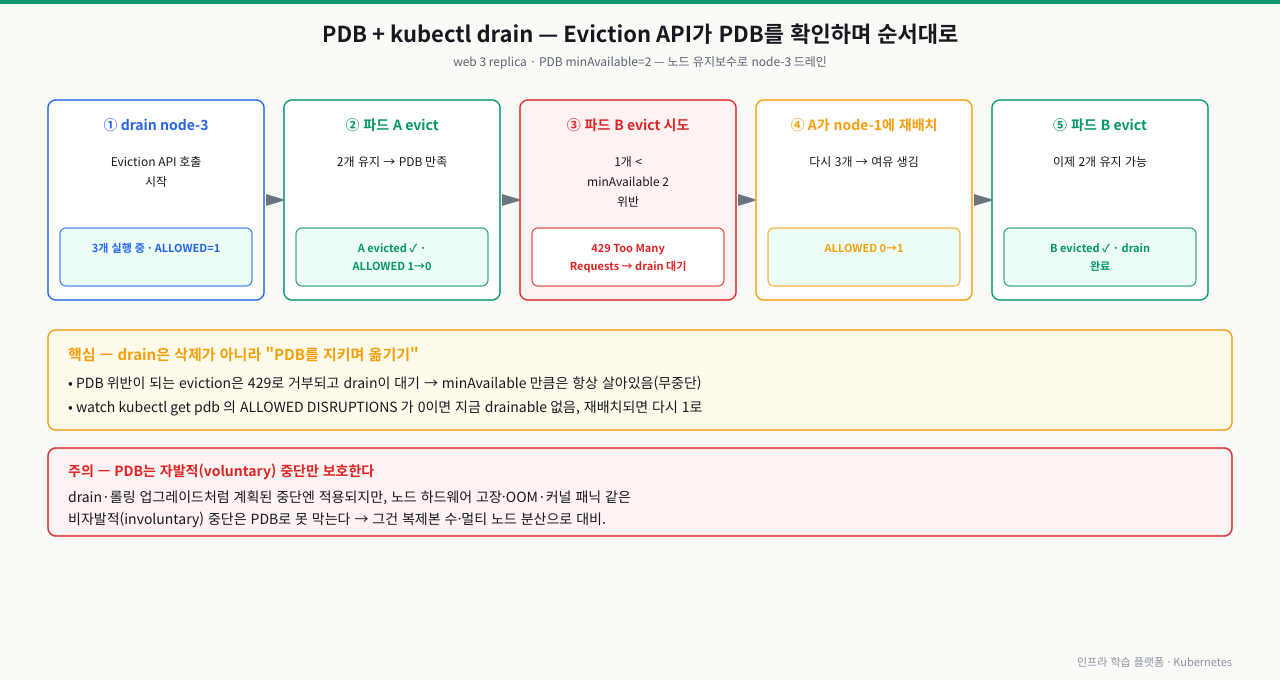 확대
확대
노드 드레인
안전한 실행 조건: PDB, 복제본 수, 다른 노드의 여유 리소스를 확인한 유지보수 상황에서만 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl drain node-3위 항목을 모두 확인한 후 복사할 수 있습니다
# PDB가 있는 상태에서 노드 드레인
kubectl drain node-3 \
--ignore-daemonsets \
--delete-emptydir-data \
--timeout=5m
# 드레인 진행 출력 예시:
# evicting pod pdb-demo/web-6d8b4b5c9-abcde
# evicting pod pdb-demo/web-6d8b4b5c9-fghij
# error when evicting pods/"web-6d8b4b5c9-fghij" -n "pdb-demo"
# (will retry after 5s): Cannot evict pod as it would violate
# the pod's disruption budget.
# pod/web-6d8b4b5c9-abcde evicted ← 첫 번째 파드 성공적으로 evict
# waiting for eviction of pod/web-6d8b4b5c9-fghij... ← PDB 대기 중
# 다른 터미널에서 파드 재배치 확인
kubectl get pods -n pdb-demo -w
# web-6d8b4b5c9-abcde 0/1 Terminating → node-1로 재배치
# web-6d8b4b5c9-xyzab 0/1 Pending → Running 후 두 번째 drain 진행
# PDB 상태 실시간 확인 (드레인 진행 중)
watch kubectl get pdb -n pdb-demo
# NAME MIN AVAILABLE ALLOWED DISRUPTIONS AGE
# web-pdb-min 2 0 2m ← 0이면 현재 drainable 없음
# web-pdb-min 2 1 2m ← 재배치 완료 후 1로 늘어남
실습: PDB 없을 때와 있을 때 비교
노드 드레인
안전한 실행 조건: PDB, 복제본 수, 다른 노드의 여유 리소스를 확인한 유지보수 상황에서만 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl drain node-2위 항목을 모두 확인한 후 복사할 수 있습니다
# 1. PDB 없이 드레인 시뮬레이션
kubectl create deployment payment \
--image=nginx --replicas=2 -n pdb-demo
# 파드 2개가 같은 노드에 있는 경우를 가정
kubectl get pods -n pdb-demo -o wide | grep payment
# payment-xxx Running node-2
# payment-yyy Running node-2
# PDB 없이 node-2 드레인 → 파드 2개 동시 제거 → 서비스 다운
kubectl drain node-2 --ignore-daemonsets --delete-emptydir-data --dry-run
# (실제로는 실행 않고 dry-run만)
# 2. PDB 추가 후 동일한 상황
cat <<EOF | kubectl apply -f -
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: payment-pdb
namespace: pdb-demo
spec:
minAvailable: 1
selector:
matchLabels:
app: payment
EOF
# 이제 drain 시도 → 1개 Evict 후 재배치 완료될 때까지 대기
kubectl drain node-2 \
--ignore-daemonsets \
--delete-emptydir-data \
--timeout=3m
# 드레인 완료 후 파드 분산 확인
kubectl get pods -n pdb-demo -o wide | grep payment
# payment-xxx Running node-1 ← 재배치됨
# payment-yyy Running node-3 ← 재배치됨
# 3. PDB Disruptions Allowed 변화 모니터링
kubectl get pdb payment-pdb -n pdb-demo -w
# NAME MIN AVAILABLE ALLOWED DISRUPTIONS
# payment-pdb 1 1 ← 드레인 전
# payment-pdb 1 0 ← 첫 파드 Evict 중
# payment-pdb 1 1 ← 재배치 완료 후 복구
클러스터 보안 패치를 위해 노드를 순서대로 드레인했습니다. node-2를 드레인하는 순간 API 에러율이 급상승하고 결제 서비스가 15초간 다운되었습니다.
# 사후 분석
kubectl get events -n production --sort-by='.lastTimestamp' | tail -20
# Warning Killing payment-pod-abc Stopping container payment
# Warning Killing payment-pod-def Stopping container payment
# ← 두 파드가 거의 동시에 삭제됨
# PDB 확인
kubectl get pdb -n production
# (출력 없음 — PDB 미설정)
# 파드 배치 분산 여부 확인
kubectl get pods -n production -o wide | grep payment
# payment-abc node-2 ← 두 파드가 같은 노드에 있었음
# payment-def node-2
# 대응 1: PDB 즉시 추가 (다음 유지보수 전에)
cat <<EOF | kubectl apply -f -
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: payment-pdb
namespace: production
spec:
minAvailable: 1
selector:
matchLabels:
app: payment
EOF
# 대응 2: 파드 반분산 (PodAntiAffinity) 추가
# Deployment spec.template.spec에 추가:
# affinity:
# podAntiAffinity:
# preferredDuringSchedulingIgnoredDuringExecution:
# - weight: 100
# podAffinityTerm:
# labelSelector:
# matchLabels:
# app: payment
# topologyKey: kubernetes.io/hostname
# 대응 3: 드레인 전 PDB 상태 확인을 SOP에 추가
kubectl get pdb -A | grep -v "N/A" # ALLOWED DISRUPTIONS가 0인 항목 확인
예방 체크리스트:
- 모든 프로덕션 Deployment에 PDB 설정 확인:
kubectl get pdb -n production - PDB의
ALLOWED DISRUPTIONS가 0이면 드레인 전에 조건 확인 --timeout옵션으로 드레인 대기 시간 제한 설정- 드레인 후 파드 재배치 완료 확인 후 다음 노드로 진행
심화 — PDB가 드레인을 '영원히' 멈추게 만들 때
심화: ALLOWED DISRUPTIONS의 산수 — 조이면 문이 잠긴다
PDB를 붙였는데 노드 업그레이드가 몇 시간째 안 끝나거나, 단일 레플리카 서비스가 드레인을 아예 영구 차단하는 일이 흔합니다. PDB는 가드레일이지만, 산수를 틀리면 스스로 문을 잠급니다. 앞 TroubleCase가 'PDB가 없어서' 생긴 문제였다면, 여기서는 'PDB가 있어서, 그것도 잘못 조여서' 생기는 정반대의 함정을 봅니다.
핵심은 ALLOWED DISRUPTIONS = Current Healthy − Desired Healthy라는 계산입니다(minAvailable 기준). 이 값이 0이면 어떤 파드도 evict할 수 없고, Eviction API는 429 Too Many Requests를 돌려주며 drain은 기본적으로 타임아웃 없이 무한 대기합니다.
- 함정 1 — 예산이 처음부터 0:
minAvailable을 레플리카 수와 같게(예: replicas 3에 minAvailable 3) 걸면3 − 3 = 0이라 아무것도 못 내립니다. 특히 단일 레플리카에 minAvailable: 1은 보호가 아니라 영구 잠금입니다. 파드가 하나뿐이면 그걸 내리는 순간 0이 되니, 무중단 드레인 자체가 불가능합니다. 이건 PDB로 풀 문제가 아니라 레플리카를 늘려야 하는 문제입니다. - 함정 2 — 건강하지 않은 파드가 예산을 갉아먹음: 파드 하나가 CrashLoop이거나 readiness에 실패하면 Current Healthy가 줄어 Desired 밑으로 떨어지고 ALLOWED가 0이 됩니다. 그러면 정상 파드를 지키느라, 정작 그 고장 난 파드가 있는 노드조차 드레인하지 못하는 교착이 생깁니다. 기본 정책(
IfHealthyBudget)은 예산이 있을 때만 unready 파드를 evict하기 때문입니다. K8s 1.26+의unhealthyPodEvictionPolicy: AlwaysAllow를 주면 "어차피 고장 난 파드는 예산과 무관하게 내보낸다"로 이 교착을 풉니다.
그래서 PDB는 "지나치게 조이면 유지보수를 막고, 너무 느슨하면 의미가 없다"의 균형입니다. 대개 maxUnavailable: 1(또는 %)이 레플리카 수 변화에 더 안전하고, 단일 레플리카는 PDB가 아니라 이중화가 답입니다.
상황: 클러스터 업그레이드로 노드를 드레인하는데 Cannot evict pod as it would violate the pod's disruption budget만 반복되며 몇 시간째 진행이 없습니다. PDB는 분명히 존재하고 설정도 그럴듯합니다 — 앞의 'PDB 미설정' 사례와는 정반대 상황입니다.
원인: ALLOWED DISRUPTIONS = Current Healthy − Desired Healthy = 0이라 evict가 원천 봉쇄된 것입니다. 두 갈래 중 하나입니다. (a) minAvailable이 현재 레플리카 수와 같거나 커서 예산이 처음부터 0(특히 단일 레플리카 + minAvailable: 1), 또는 (b) 파드 하나가 readiness 실패·CrashLoop라 Current Healthy가 Desired 밑으로 떨어져 예산이 0이 된 경우입니다.
진단: describe로 산수를 직접 확인하고, 두 갈래 중 어느 쪽인지 가릅니다.
kubectl describe pdb <name> -n <ns> | grep -E "Allowed disruptions|Current healthy|Desired healthy|Expected pods"
# Allowed disruptions: 0 / Current healthy: 2 / Desired healthy: 2 → 여유 0 확정
kubectl get deploy <app> -n <ns> # replicas와 minAvailable 관계 확인 (함정 1)
kubectl get pods -l app=<app> -n <ns> # READY 0/1 인 unready 파드 존재 여부 (함정 2)
replicas == minAvailable이면 함정 1, READY가 0/1인 파드가 있으면 함정 2입니다.
해결: 원인에 따라 다릅니다. **함정 1(과조임)**은 minAvailable을 레플리카보다 낮추거나 maxUnavailable: 1로 바꿔 여유 1을 만들고, 단일 레플리카 서비스는 PDB로 풀 수 없으니 replicas ≥ 2 + PodAntiAffinity로 이중화합니다(정말 단일뿐인 스테이트풀은 유지보수 창을 따로 잡습니다). **함정 2(건강 문제)**는 먼저 unready 파드의 probe·크래시 원인을 고쳐(Liveness, Readiness, Startup Probe 헬스 체크 설정) Current Healthy를 회복시키면 예산이 되살아나고, 이미 회복 불가한 파드가 드레인을 막는다면 그 워크로드 PDB에 unhealthyPodEvictionPolicy: AlwaysAllow(1.26+)를 설정합니다. 급하면 --timeout으로 무한 대기를 끊고, 최후의 수단으로만 --disable-eviction(PDB 무시)을 씁니다. 재발 방지로 업그레이드 전 kubectl get pdb -A에서 ALLOWED DISRUPTIONS가 0인 항목을 미리 걸러냅니다.
시나리오: 클러스터 버전 업그레이드 전 PDB 점검
EKS를 1.28에서 1.29로 업그레이드하기 전, SRE 온콜이 점검 항목 리스트를 줬습니다. "PDB 없는 프로덕션 서비스 목록 뽑아서 팀에 공유해줘."
# 프로덕션 네임스페이스의 Deployment 목록
kubectl get deployments -n production -o json | \
jq '.items[].metadata.name' -r | sort > /tmp/deployments.txt
# PDB의 selector와 매칭되는 Deployment 추출
kubectl get pdb -n production -o json | \
jq '.items[].spec.selector.matchLabels.app' -r | sort > /tmp/pdb-covered.txt
# PDB 없는 Deployment 식별
comm -23 /tmp/deployments.txt /tmp/pdb-covered.txt
# catalog-service ← PDB 없음
# notification-svc ← PDB 없음
# 일괄 PDB 생성 스크립트
for svc in catalog-service notification-svc; do
cat <<EOF | kubectl apply -f -
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: ${svc}-pdb
namespace: production
spec:
maxUnavailable: 1
selector:
matchLabels:
app: ${svc}
EOF
done
# 업그레이드 중 PDB 상태 모니터링
watch -n 5 "kubectl get pdb -n production"
실무 포인트: 클러스터 업그레이드 전 PDB 점검은 "가드레일 설치"입니다. 업그레이드 툴(eksctl, kubeadm)은 PDB를 존중하며 노드를 드레인하므로, PDB만 제대로 있으면 업그레이드 중 서비스 중단 없이 노드를 순서대로 교체할 수 있습니다.
테스트 Deployment 생성
kubectl create deployment web --image=nginx --replicas=3 -n pdb-demo
kubectl get pods -n pdb-demo -l app=web예상 출력
NAME READY STATUS RESTARTS AGE web-... 1/1 Running 0 ... web-... 1/1 Running 0 ... web-... 1/1 Running 0 ...
minAvailable PDB 생성 및 상태 확인
kubectl create pdb web-pdb --selector=app=web --min-available=2 -n pdb-demo
kubectl get pdb -n pdb-demo예상 출력
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE web-pdb 2 N/A 1 ...
PDB 상세 상태 — Disruptions Allowed 확인
kubectl describe pdb web-pdb -n pdb-demo | grep -E 'Disruptions Allowed|Current Healthy|Desired Healthy'예상 출력
Disruptions Allowed: 1 Current Healthy: 3 Desired Healthy: 2
파드 수를 줄여 PDB 경계 조건 관찰
kubectl scale deployment/web --replicas=2 -n pdb-demo
kubectl get pdb -n pdb-demo예상 출력
NAME MIN AVAILABLE ALLOWED DISRUPTIONS web-pdb 2 0
실습 리소스 정리
kubectl delete pdb web-pdb -n pdb-demo
kubectl delete deployment web -n pdb-demo
echo cleaned예상 출력
poddisruptionbudget.policy "web-pdb" deleted deployment.apps "web" deleted cleaned
핵심 요약
| 개념 | 명령/설정 | 실무 사용 빈도 |
|---|---|---|
| PDB 생성 | kubectl create pdb <name> --selector=app=<app> --min-available=1 | 서비스 배포 시 |
| PDB 상태 확인 | kubectl get pdb -n <ns> | 유지보수 전 |
| Disruptions Allowed | kubectl describe pdb <name> | 드레인 전 확인 |
| 노드 드레인 | kubectl drain <node> --ignore-daemonsets --delete-emptydir-data | 노드 유지보수 |
| 드레인 타임아웃 | --timeout=5m | 장시간 대기 방지 |
| 강제 드레인 (PDB 무시) | --disable-eviction (비권장) | 긴급 상황만 |
| PDB 커버리지 확인 | kubectl get pdb -A + Deployment 매칭 | 업그레이드 전 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 PDB 조회·드레인 제어 명령을 실전 옵션과 함께 모았습니다. ALLOWED DISRUPTIONS = Current Healthy − Desired Healthy가 0이면 드레인이 대기합니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl create pdb | PDB 빠르게 생성 | kubectl create pdb web-pdb --selector=app=web --min-available=2 -n pdb-demo |
kubectl get pdb | ALLOWED DISRUPTIONS 값 확인 | kubectl get pdb -A(0이면 drain 차단 상태) |
kubectl describe pdb | 예산 산수(Current/Desired Healthy) 확인 | kubectl describe pdb web-pdb | grep -E "Allowed disruptions|Current|Desired" |
kubectl get pdb -w | 드레인 중 ALLOWED 변화 추적 | kubectl get pdb payment-pdb -n pdb-demo -w |
kubectl drain | 노드 유지보수(Eviction API) | kubectl drain node-3 --ignore-daemonsets --delete-emptydir-data --timeout=5m |
kubectl drain --dry-run | 실제 evict 전 영향 미리 보기 | kubectl drain node-2 --ignore-daemonsets --dry-run |
--disable-eviction | PDB 무시 강제 드레인(비권장) | 교착 긴급 해소 최후 수단 |
kubectl scale deployment | 레플리카 조정으로 예산 경계 관찰 | kubectl scale deployment/web --replicas=2 -n pdb-demo |
kubectl get pods -o wide | grep | 파드 노드 분산·같은 노드 집중 확인 | kubectl get pods -n <ns> -o wide | grep payment |
kubectl get pods -l <selector> | unready(READY 0/1) 파드로 예산 잠김 확인 | kubectl get pods -l app=web -n pdb-demo |
kubectl get pdb -A | grep -v N/A | 업그레이드 전 ALLOWED=0 항목 사전 점검 | kubectl get pdb -A | grep -v "N/A" |
kubectl get events --sort-by | 동시 evict된 파드 사후 분석 | kubectl get events -n production --sort-by='.lastTimestamp' | tail -20 |
관련 모듈로 더 깊이:
- Deployment를 이용한 안정적인 서비스 배포와 롤백 전략 — PDB가 보호하는 대상인 ReplicaSet과 롤링 업데이트의 동작 원리
- HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장 — 가용 파드 수가 자동으로 변할 때 PDB의 min-available 계산이 달라지는 맥락
- Node Affinity와 Taint/Toleration 기반 스케줄링 제어 — 노드 드레인 후 파드가 재배치될 위치를 결정하는 스케줄링 제약
다음 모듈 hpa-autoscaling에서는 파드 수를 수동으로 조정하지 않고 CPU 사용률에 따라 자동 스케일링하는 HPA를 다룹니다. metrics-server 설치부터 scaleDown stabilizationWindow 튜닝까지, 실무 HPA 설정의 핵심을 실습합니다.