PostgreSQL 장애 조치, 백업, 스케일링을 모두 사람이 런북대로 처리하다가 새벽 복구 시간이 길어졌습니다. 반복 가능한 운영 절차는 컨트롤러로 자동화할 수 있어야 합니다. Operator 패턴은 도메인 운영 지식을 Kubernetes 컨트롤 루프로 옮기는 방식입니다.
Operator 패턴 — CRD + Controller로 자동화 구축
PostgreSQL 클러스터를 Kubernetes에서 운영한다고 생각해봅시다. Primary 장애 시 Replica를 승격해야 하고, 백업 스케줄을 관리해야 하고, 스토리지가 부족하면 PVC를 확장해야 합니다. 이 모든 것을 수동으로 하려면 전담 DBA가 24시간 대기해야 합니다. Operator는 이 운영 노하우를 Kubernetes Controller 코드로 캡슐화합니다. 사람이 하던 "이 상황에서는 이렇게 한다"는 판단을 Reconcile 루프가 자동으로 실행합니다. CRD가 "무엇을 원하는지" 선언하는 인터페이스라면, Controller는 그 선언을 실현하는 로봇입니다.
Operator 패턴의 동작 원리를 이해하고, postgres-operator와 redis-operator로 실제 스테이트풀 애플리케이션을 선언적으로 운영합니다. Operator를 직접 구현하지 않아도 Controller가 내부에서 무슨 일을 하는지 알면 트러블슈팅이 훨씬 쉬워집니다.
- 1Operator를 구성하는 CRD와 Controller 두 구성요소의 역할 분리를 설명할 수 있다
- 2Watch, Diff, Act로 반복되는 Reconcile 루프를 설명할 수 있다
- 3postgres-operator로 PostgreSQL 클러스터를 선언적으로 관리할 수 있다
- 4redis-operator로 Redis Sentinel 클러스터를 구성할 수 있다
- 5Informer, WorkQueue, 멱등성 등 Controller가 하는 일을 설명할 수 있다
- 6Operator Hub에서 검증된 Operator를 찾을 수 있다
Helm v3와 kubectl이 설치된 환경이면 됩니다. 실제 PostgreSQL 클러스터를 생성하려면 스토리지 클래스가 필요합니다. 로컬 환경(minikube, kind)에서는 standard 또는 local-path 스토리지 클래스를 사용합니다.
kubectl cluster-infokubectl create namespace operator-labhelm repo add postgres-operator-charts https://opensource.zalando.com/postgres-operator/charts/ && helm repo updatekubectl get crd | wc -lhelm uninstall postgres-operator -n operator-lab && kubectl delete namespace operator-lab
Operator = CRD + Controller — 역할 분리 이해
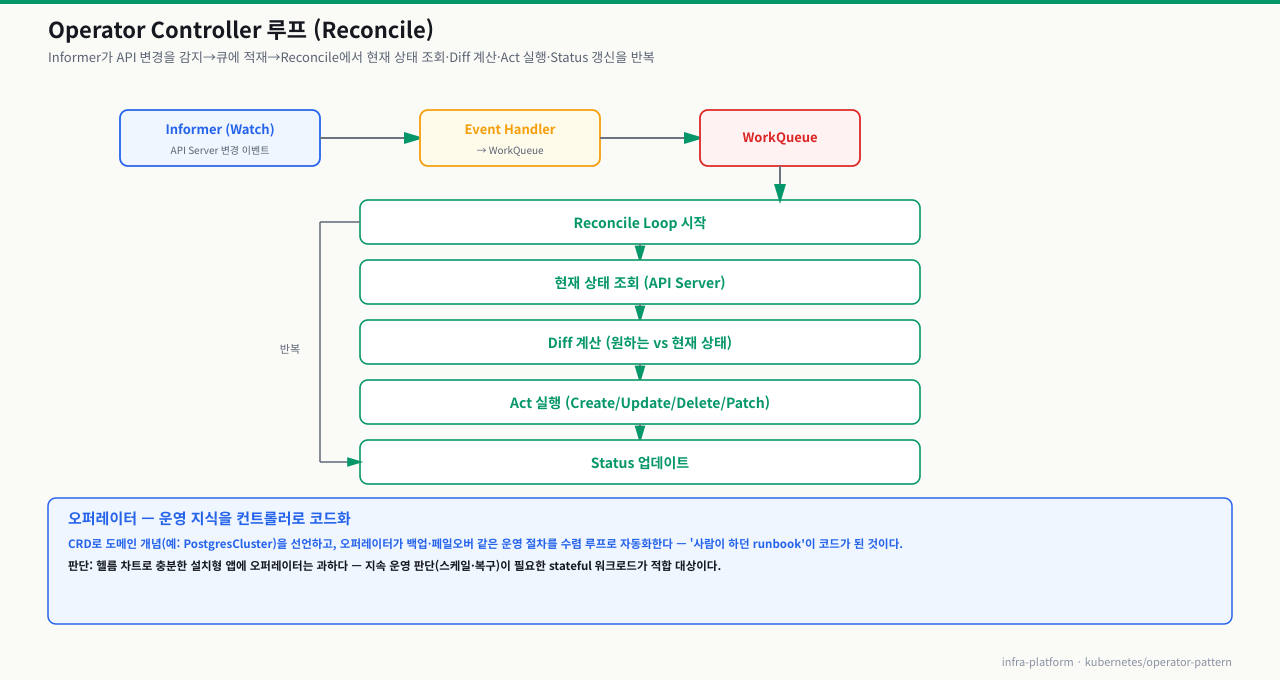
PostgreSQL을 StatefulSet으로 배포했는데 Primary 파드가 죽자 아무도 자동으로 Replica를 승격시키지 않습니다. 누군가 수동으로 failover 명령을 실행하기 전까지 서비스는 중단된 채로 있습니다. 이런 "이 상황에서는 이렇게 한다"는 운영 판단을 코드로 자동화하려면 Kubernetes의 기본 컨트롤러만으로는 부족합니다. Operator 패턴은 CRD로 새로운 API 타입을 정의하고, Controller가 그 리소스를 watch하며 원하는 상태를 실현하는 구조입니다. Operator라는 단어는 이 두 가지를 합친 개념입니다. 이 CB에서는 CRD와 Controller가 어떻게 분리되고 협력하는지, Operator가 어떤 Kubernetes 리소스를 만들어 운영을 자동화하는지를 다룹니다. CRD(Custom Resource Definition)는 새로운 API 타입을 정의하고, Controller는 그 타입의 리소스를 watch하면서 원하는 상태를 실현합니다. Operator는 이 둘을 묶어서 특정 애플리케이션의 운영 자동화를 담당하는 소프트웨어를 말합니다.
 확대
확대
전통적 운영 vs Operator 패턴
전통적 운영:
DBA가 PostgreSQL 장애 감지 → 수동으로 failover 명령 실행
→ Replica를 Primary로 승격 → DNS 업데이트 → 애플리케이션 재연결
(수 분~수십 분 소요, 사람 개입 필요)
Operator 패턴:
postgres-operator Controller가 Primary 파드 실패 감지 (수 초)
→ 자동으로 Replica 중 하나를 Primary로 승격
→ Service 엔드포인트 업데이트
→ CRD status 업데이트 (새 Primary 정보)
(수십 초 이내, 자동)
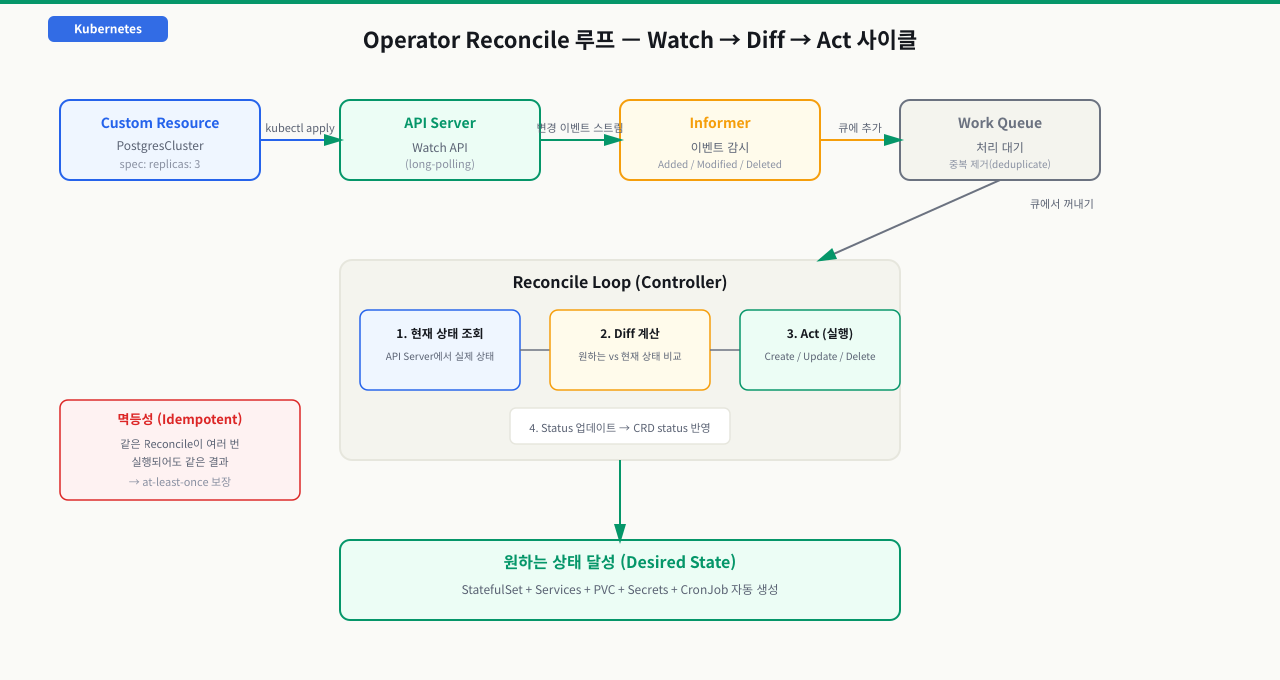
Controller의 Watch → Diff → Act 루프
 확대
확대
Operator가 관리하는 Kubernetes 리소스들
PostgresCluster CRD 하나가 생성되면 Operator가 다음을 만듭니다.
- StatefulSet — Primary, Replica 각각
- Services — Primary 엔드포인트, Replica 엔드포인트
- PersistentVolumeClaims — 데이터 디렉토리
- ConfigMaps — postgresql.conf, pg_hba.conf
- Secrets — 패스워드, TLS 인증서
- CronJobs — 백업 스케줄
- ServiceAccounts + RBAC — Operator 권한
reconcile 한 바퀴가 실제로 도는 순서 — 감지부터 상태 보고까지 6단계
앞에서 Operator를 "Watch → Diff → Act 루프"라고 요약했지만, 정작 numberOfInstances를 하나 올렸을 때 그 한 줄이 어떤 단계를 거쳐 새 파드가 되는지는 흐릿합니다. reconcile은 이벤트 하나에 대해 아래 여섯 단계를 한 바퀴 도는 함수입니다. 이 흐름을 알면 "왜 반영이 안 되지", "왜 CPU를 계속 쓰지"를 단계로 좁혀 진단할 수 있습니다. Operator가 하는 일은 결국 이 바퀴가 끝까지 돌아 실제 상태를 desired에 수렴시키는 것입니다.
[CR 변경] kubectl apply (spec의 numberOfInstances 2→3)
│
① Watch 이벤트 수신 (Informer가 API Server Watch 스트림에서 Modified 수신)
│ → 객체 키를 WorkQueue에 넣음 (같은 키 중복은 하나로 합쳐짐)
│
② 현재 상태 관측(Observe) (그 CR + 하위 StatefulSet·Service·Secret을 캐시에서 읽음)
│
③ Desired와 Diff (spec이 원하는 모습 vs 실제 상태를 비교해 차이 계산)
│
④ 조치(Act) (차이만큼만 하위 리소스 Create/Update/Delete — 멱등)
│ → 이미 같으면 아무것도 안 함(no-op)
│
⑤ 상태 보고(Status) (status.observedGeneration·conditions를 기록)
│
⑥ 반환 → Requeue (성공: 다음 이벤트·주기 resync까지 / 에러: 지수 백오프 재시도)
▼
[수렴] 실제 상태 == desired (generation == observedGeneration)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① Watch | Informer가 API Server Watch 스트림으로 CR·하위 리소스의 Added/Modified/Deleted를 받아 WorkQueue에 키를 넣는다. 폴링이 아니라 이벤트 기반 | RBAC에 watch 권한이 없으면 이벤트를 못 받아 루프가 아예 안 돈다 → failed to watch 로그, CR을 만들어도 하위 리소스가 안 생김 |
| ② Observe | 큐에서 키를 꺼내 그 CR의 현재 spec과 이미 만들어진 하위 리소스를 로컬 캐시에서 읽는다 | 캐시가 아직 안 데워졌거나(cold start) 재동기 전이면 오래된 상태를 봐 잘못된 diff를 낸다 |
| ③ Diff | desired(spec이 원하는 모습)와 current(실제)를 비교해 무엇이 다른지 계산 | spec 해석 버그·기본값 누락으로 매번 "다르다"고 판단하면 무한 reconcile(CPU 상승) |
| ④ Act | 차이만큼만 하위 리소스를 Create/Update/Delete. 같은 입력엔 같은 결과(멱등) | StatefulSet의 immutable 필드(volumeClaimTemplates 등)를 바꾸려다 API가 거부 → 매 바퀴 같은 지점서 실패 |
| ⑤ Status | status.observedGeneration·conditions에 "이 세대까지 반영함"을 기록 | status 서브리소스 미구현·권한 부족이면 밖에서 진행도를 못 읽어 멈춤 여부 판단 불가 |
| ⑥ Requeue | 성공이면 다음 이벤트·주기 resync까지 대기, 에러면 지수 백오프로 다시 큐에 넣음 | 에러가 안 풀리면 backoff 간격이 점점 늘며 조용히 재시도만 반복(상태 미수렴) |
즉 "Operator가 일했다"는 이 여섯 단계가 끝까지 돌아 ⑤에서 status.observedGeneration이 방금 오른 metadata.generation을 따라잡은 상태를 뜻합니다. 반영이 안 될 때는 (1) 두 generation을 비교해 밀렸는지 보고, (2) kubectl describe·events로 ④에서 막혔는지(immutable 충돌 등)를 확인하고, (3) 로그를 --since로 좁혀 매 바퀴 같은 자리서 반복되는 에러(무한 reconcile·백오프)를 찾습니다. 파드가 Running이라고 바퀴가 도는 게 아니라, ⑥에서 조용히 backoff 재시도만 반복하며 상태가 영영 안 맞을 수 있습니다.
postgres-operator — PostgreSQL 클러스터 선언적 관리
PostgreSQL HA 클러스터를 직접 구성하려면 Patroni 설정, pg_hba.conf, 백업 CronJob, failover 스크립트, 서비스 엔드포인트 관리를 모두 손으로 작성해야 합니다. 레플리카를 추가할 때마다 복제 설정을 수동으로 해줘야 하고, 버전 업그레이드는 순서를 지키지 않으면 데이터 손실 위험이 있습니다. postgres-operator는 이 모든 운영 노하우를 postgresql CRD 하나로 캡슐화합니다. Zalando의 postgres-operator는 CRD + Controller 패턴의 교과서적인 구현입니다. 이 CB에서는 postgresql CRD를 선언하면 Operator가 StatefulSet, Service, Secret, CronJob을 자동으로 생성하는 과정을 실습합니다. postgresql CRD 하나만 작성하면 HA PostgreSQL 클러스터 전체를 자동으로 구성합니다. Patroni를 사용한 자동 failover, WAL 백업, connection pooler(PgBouncer)까지 포함됩니다.
 확대
확대
postgres-operator 설치
# Helm으로 postgres-operator 설치
helm install postgres-operator \
postgres-operator-charts/postgres-operator \
--namespace operator-lab \
--create-namespace
# Operator Pod 실행 확인
kubectl get pods -n operator-lab
# NAME READY STATUS RESTARTS
# postgres-operator-5d97b6f4d9-x8p2k 1/1 Running 0
# 설치된 CRD 확인
kubectl get crd | grep acid.zalan.do
# postgresqls.acid.zalan.do 2026-05-16T10:00:00Z
# operatorconfigurations.acid.zalan.do
# postgresteams.acid.zalan.do
- kubectl get <cr-kind> -n <namespace>에서 STATUS/PHASE 열 먼저 확인 — Operator가 status 서브리소스를 구현했다면 Running/Ready/Failed 같은 값이 보임. 빈 값이면 Operator가 아직 Reconcile을 수행하지 않은 것
- 커스텀 리소스 생성 후 30초 이내에 하위 리소스(Deployment, Service 등)가 생성되지 않으면 → Operator 파드 로그 확인. kubectl logs -l app=<operator> --tail=50으로 Reconcile 에러 메시지 파악
- kubectl describe <cr> <name>의 Events가 비어있고 STATUS가 변경 안 되면 → CRD의 status 서브리소스 미활성화 또는 Operator의 RBAC 권한 부족. kubectl auth can-i update <cr>/status --as=system:serviceaccount:<ns>:<sa>로 확인
PostgreSQL 클러스터 생성
# postgres-cluster.yaml
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: my-postgres-cluster
namespace: operator-lab
spec:
teamId: "platform" # 팀 식별자 (파드 이름 접두사)
volume:
size: 5Gi # 데이터 볼륨 크기
numberOfInstances: 2 # Primary 1개 + Replica 1개
users:
app_user: # 생성할 DB 유저
- login
- superuser
databases:
app_db: app_user # 생성할 DB: 소유자
postgresql:
version: "16"
parameters:
shared_buffers: "256MB"
max_connections: "100"
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 1000m
memory: 2Gi
kubectl apply -f postgres-cluster.yaml
# 클러스터 생성 과정 관찰
kubectl get pods -n operator-lab -w
# NAME READY STATUS RESTARTS
# my-postgres-cluster-0 0/1 Pending 0
# my-postgres-cluster-0 1/1 Running 0 ← Primary
# my-postgres-cluster-1 1/1 Running 0 ← Replica
# 생성된 리소스 확인
kubectl get all -n operator-lab | grep -v "postgres-operator"
# pod/my-postgres-cluster-0 1/1 Running
# pod/my-postgres-cluster-1 1/1 Running
# service/my-postgres-cluster ClusterIP (Primary)
# service/my-postgres-cluster-repl ClusterIP (Replica)
# statefulset.apps/my-postgres-cluster
# 클러스터 상태 확인
kubectl get postgresql -n operator-lab
# NAME TEAM VERSION PODS VOLUME STATUS AGE
# my-postgres-cluster platform 16 2 5Gi Running 5m
자동 생성된 Secret으로 연결
# postgres-operator가 생성한 패스워드 Secret
kubectl get secrets -n operator-lab | grep my-postgres
# app_user.my-postgres-cluster.credentials.postgresql.acid.zalan.do
# 패스워드 추출
APP_PASS=$(kubectl get secret \
app_user.my-postgres-cluster.credentials.postgresql.acid.zalan.do \
-n operator-lab \
-o jsonpath='{.data.password}' | base64 -d)
# psql로 연결 테스트
kubectl run -it --rm psql-client \
--image=postgres:16-alpine \
--restart=Never \
-n operator-lab \
-- psql -h my-postgres-cluster -U app_user -d app_db \
-c "SELECT version();"
redis-operator — Redis Sentinel 클러스터 관리
Redis HA를 직접 구성하려면 Primary, Replica, Sentinel 파드를 각각 관리하고 Sentinel이 올바른 Primary를 가리키도록 설정해야 합니다. Sentinel 수는 홀수여야 하고, Redis 설정 파일은 파드마다 다르게 주입해야 합니다. Primary가 바뀌면 연결 풀도 재설정이 필요합니다. redis-operator는 RedisFailover CRD 하나로 이 구성을 선언하면 Primary/Replica/Sentinel 파드를 자동으로 배포하고 failover 시 Sentinel 투표를 통해 새 Primary를 선출합니다. 이 CB에서는 RedisFailover CRD를 선언해 Redis HA 클러스터를 배포하고 연결하는 방법을 다룹니다. Primary/Replica/Sentinel 구성을 자동으로 처리하고 장애 시 자동 failover를 수행합니다.
redis-operator 설치 및 RedisFailover 생성
# redis-operator Helm 저장소 추가
helm repo add redis-operator https://spotahome.github.io/redis-operator
helm repo update
# redis-operator 설치
helm install redis-operator redis-operator/redis-operator \
--namespace operator-lab
# RedisFailover CRD 생성
kubectl apply -f - << 'EOF'
apiVersion: databases.spotahome.com/v1
kind: RedisFailover
metadata:
name: my-redis
namespace: operator-lab
spec:
sentinel:
replicas: 3 # Sentinel 인스턴스 수 (홀수 권장)
resources:
requests:
cpu: 50m
memory: 32Mi
redis:
replicas: 3 # Redis 인스턴스 (Primary 1 + Replica 2)
resources:
requests:
cpu: 100m
memory: 128Mi
storage:
persistentVolumeClaim:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
EOF
# Operator가 생성한 파드 확인
kubectl get pods -n operator-lab | grep redis
# rfr-my-redis-0 1/1 Running (Redis Replica/Primary)
# rfr-my-redis-1 1/1 Running
# rfr-my-redis-2 1/1 Running
# rfs-my-redis-0 1/1 Running (Sentinel)
# rfs-my-redis-1 1/1 Running
# rfs-my-redis-2 1/1 Running
# RedisFailover 상태 확인
kubectl get redisfailover my-redis -n operator-lab
# NAME AGE
# my-redis 3m
Redis 연결 방법
# redis-operator는 두 개의 Service를 생성
kubectl get svc -n operator-lab | grep redis
# rfs-my-redis ClusterIP 10.96.x.x 26379/TCP (Sentinel)
# rfr-my-redis ClusterIP 10.96.x.x 6379/TCP (Redis)
# 애플리케이션에서는 Sentinel 주소로 연결 (Primary 자동 감지)
# 예: redis-py에서
# from redis.sentinel import Sentinel
# sentinel = Sentinel([('rfs-my-redis.operator-lab.svc', 26379)])
# master = sentinel.master_for('mymaster')
실습 — Operator 동작 관찰하기
1단계: Operator 설치 및 CRD 확인
# postgres-operator 설치 (이미 설치했다면 생략)
helm install postgres-operator \
postgres-operator-charts/postgres-operator \
-n operator-lab
# Operator가 등록한 CRD 목록
kubectl get crd | grep acid
# postgresqls.acid.zalan.do
# operatorconfigurations.acid.zalan.do
# Operator Pod 로그 확인 (Reconcile 루프 관찰)
kubectl logs -n operator-lab \
-l app.kubernetes.io/name=postgres-operator \
--follow &
2단계: PostgresCluster 생성 및 Reconcile 관찰
kubectl apply -f postgres-cluster.yaml
# 다른 터미널에서 이벤트 스트리밍
kubectl get events -n operator-lab --watch &
# Operator 로그에서 Reconcile 사이클 관찰
# 2026-05-16 10:00:01 INFO cluster has been created (my-postgres-cluster)
# 2026-05-16 10:00:01 INFO creating statefulset my-postgres-cluster
# 2026-05-16 10:00:01 INFO creating service my-postgres-cluster
# 2026-05-16 10:00:01 INFO creating service my-postgres-cluster-repl
# 2026-05-16 10:00:01 INFO cluster my-postgres-cluster is in the Running state
3단계: 수동 장애 시뮬레이션 및 자동 복구 확인
# Primary 파드가 어느 것인지 확인
kubectl exec -n operator-lab my-postgres-cluster-0 -- \
patronictl -c /home/postgres/postgres.yml list
# + Cluster: my-postgres-cluster (7891234567) ------+----+-----------+
# | Member | Host | Role | State | TL |
# +--------------------------+----------+---------+--------+----+
# | my-postgres-cluster-0 | 10.x.x.x | Leader | running| 1 | ← Primary
# | my-postgres-cluster-1 | 10.x.x.x | Replica | running| 1 |
# Primary 파드 강제 삭제 (장애 시뮬레이션)
kubectl delete pod my-postgres-cluster-0 -n operator-lab
# 30초 내로 Replica가 Primary로 승격 확인
kubectl exec -n operator-lab my-postgres-cluster-1 -- \
patronictl -c /home/postgres/postgres.yml list
# | my-postgres-cluster-1 | 10.x.x.x | Leader | running| 2 | ← 새 Primary!
# | my-postgres-cluster-0 | 10.x.x.x | Replica | running| 2 | ← 재시작 후 Replica
4단계: postgresql CRD status 확인
kubectl get postgresql my-postgres-cluster -n operator-lab -o yaml | \
grep -A 20 "status:"
# status:
# PostgresClusterStatus: Running
# instances: 2
# latestCRDVersion: v1
# latestRestoreJobId: ""
# masterServiceName: my-postgres-cluster
문제 상황
# postgresql CRD를 적용했지만 파드, StatefulSet이 생성되지 않음
kubectl apply -f postgres-cluster.yaml
# postgresql.acid.zalan.do/my-postgres-cluster created ← CRD 적용은 됨
kubectl get pods -n operator-lab
# NAME READY STATUS
# postgres-operator-5d97b6f4d9-x8p2k 1/1 Running
# (PostgreSQL 파드가 없음)
kubectl get postgresql -n operator-lab
# NAME STATUS
# my-postgres-cluster (비어 있음 또는 Creating 상태에서 멈춤)
원인 1: Operator Pod 자체 문제
# Operator 로그에서 오류 확인
kubectl logs -n operator-lab \
-l app.kubernetes.io/name=postgres-operator \
--tail=50
# 흔한 오류들:
# "failed to watch resources: watch error" → RBAC 권한 부족
# "no storage class found" → 스토리지 클래스 미설정
# "quota exceeded" → 네임스페이스 리소스 쿼터 초과
원인 2: RBAC 권한 부족
# Operator의 ServiceAccount가 필요한 권한을 가졌는지 확인
kubectl get clusterrolebinding | grep postgres-operator
kubectl describe clusterrole postgres-operator
# 권한 부족 로그 예시:
# "failed to create statefulset: statefulsets.apps is forbidden:
# User "system:serviceaccount:operator-lab:postgres-operator"
# cannot create resource"
# 해결: Helm 재설치 또는 ClusterRole 재적용
helm upgrade postgres-operator postgres-operator-charts/postgres-operator \
-n operator-lab
원인 3: 스토리지 클래스 없음
# 스토리지 클래스 확인
kubectl get storageclass
# (출력 없음) ← 스토리지 클래스 없음!
# Operator 로그에서 확인
# "could not create persistent volume claim: no persistent volumes available"
# 해결 A: minikube에서 스토리지 활성화
minikube addons enable storage-provisioner
# 해결 B: kind에서 local-path provisioner 설치
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/main/deploy/local-path-storage.yaml
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
# 해결 C: postgresql CRD에 스토리지 클래스 명시
# spec:
# volume:
# storageClass: standard ← 존재하는 스토리지 클래스 이름
원인 4: 리소스 쿼터 초과
# 네임스페이스 리소스 사용량 확인
kubectl describe resourcequota -n operator-lab
# 출력 예시:
# Resource Used Hard
# pods 8 10
# requests.memory 3Gi 4Gi ← 거의 꽉 찼을 때
# 해결: 쿼터 증가 또는 리소스 요청량 줄이기
# spec.resources.requests.memory 값 줄이기
일반 디버깅 체크리스트
# 1. CRD 적용 확인
kubectl get crd | grep acid.zalan.do
# 2. Operator Pod 상태
kubectl get pods -n operator-lab -l app.kubernetes.io/name=postgres-operator
# 3. Operator 로그 (가장 중요)
kubectl logs -n operator-lab \
-l app.kubernetes.io/name=postgres-operator \
--since=5m
# 4. Events (리소스 생성 실패 이유)
kubectl get events -n operator-lab --sort-by=.creationTimestamp | tail -20
# 5. postgresql 리소스 상세 상태
kubectl describe postgresql my-postgres-cluster -n operator-lab
심화 — Operator가 최신 spec을 따라잡았는지 밖에서 읽기
심화: level-triggered 조정과 observedGeneration
Operator를 도입하고 나면 다음 질문이 반드시 옵니다 — 지금 Operator가 내 변경을 반영하는 중인가, 아니면 멈춰 있는가? 이걸 로그를 뒤지지 않고 1초에 답하려면 조정 루프의 성질과 status의 관례를 알아야 합니다.
- Reconcile는 level-triggered입니다: 이벤트 하나에 한 번 반응하는(edge-triggered) 방식이 아니라, 매번 지금 실제 상태 대 원하는 상태를 통째로 다시 계산해 수렴시킵니다. 그래서 이벤트를 놓쳐도, Controller가 재시작돼도, informer의 주기적 resync가 reconcile을 다시 호출해 결국 원하는 상태에 도달합니다. edge-triggered였다면 놓친 이벤트 하나가 곧 영구적 불일치가 됐을 것입니다.
- generation은 spec이 바뀔 때마다 오릅니다: 오브젝트의 spec을 편집할 때마다
metadata.generation이 1씩 증가합니다(status만 바뀌는 것으로는 오르지 않습니다). - observedGeneration은 Operator가 남기는 영수증입니다: status 서브리소스를 구현한 Operator는 자신이 반영을 끝낸 세대를
status.observedGeneration에 기록합니다. 그래서metadata.generation과status.observedGeneration이 같으면 최신 spec까지 반영된 것이고, generation이 더 크면 Operator가 아직 못 따라잡은 것(진행 중이거나 어딘가에서 막힘)입니다.
이 두 값 비교가 Operator가 일하고 있는지를 판단하는 첫 지표입니다. 파드가 Running이라고 해서 조정이 진행 중이라는 뜻은 아닙니다 — reconcile이 에러로 backoff 재시도 중일 수 있고, 그때 generation은 앞서 있고 observedGeneration은 뒤처져 있습니다.
상황: postgresql 리소스의 numberOfInstances를 2에서 3으로 올려 apply했고 configured 응답까지 받았는데, 몇 분이 지나도 새 파드가 뜨지 않습니다. Operator 파드는 1/1 Running이고 로그를 훑어도 눈에 띄는 에러가 없어 무엇이 막혔는지 감이 오지 않습니다.
원인: reconcile이 어딘가에서 막혀 조용히 backoff 재시도 중입니다. spec을 바꿔 metadata.generation은 올랐지만 status.observedGeneration은 이전 세대에 머물러 있습니다. 흔한 원인은 Operator가 하위 리소스(StatefulSet 등)의 immutable 필드를 바꾸려다 API 서버에 거부당해 매 reconcile마다 같은 지점에서 실패하는 경우, 또는 admission/validation 훅에서 patch가 반복 거부되는 경우입니다.
진단: kubectl get postgresql <name> -o jsonpath로 metadata.generation과 status.observedGeneration을 비교합니다 — 다르면 Operator가 최신 spec을 아직 반영하지 못한 것입니다. 그다음 kubectl describe와 kubectl get events로 왜 막혔는지(예: Forbidden updates to statefulset spec 같은 메시지)를 확인하고, Operator 로그를 --since로 좁혀 매 주기 반복되는 reconcile 에러 라인을 찾습니다.
해결: 근본 원인(immutable 필드 충돌 등)을 없애야 수렴이 재개됩니다. 바꿀 수 없는 필드가 원인이면 그 하위 리소스를 지워 Operator가 새로 만들게 하거나, Operator가 지원하는 경로(볼륨 확장은 CRD의 정해진 필드로만 등)로 변경합니다. generation이 계속 observedGeneration보다 앞서 있다면 reconcile이 아직 막혀 있다는 뜻이므로, 실제 파드가 바뀌었는지가 아니라 이 두 값이 같아졌는지로 반영 완료를 판정합니다.
배경
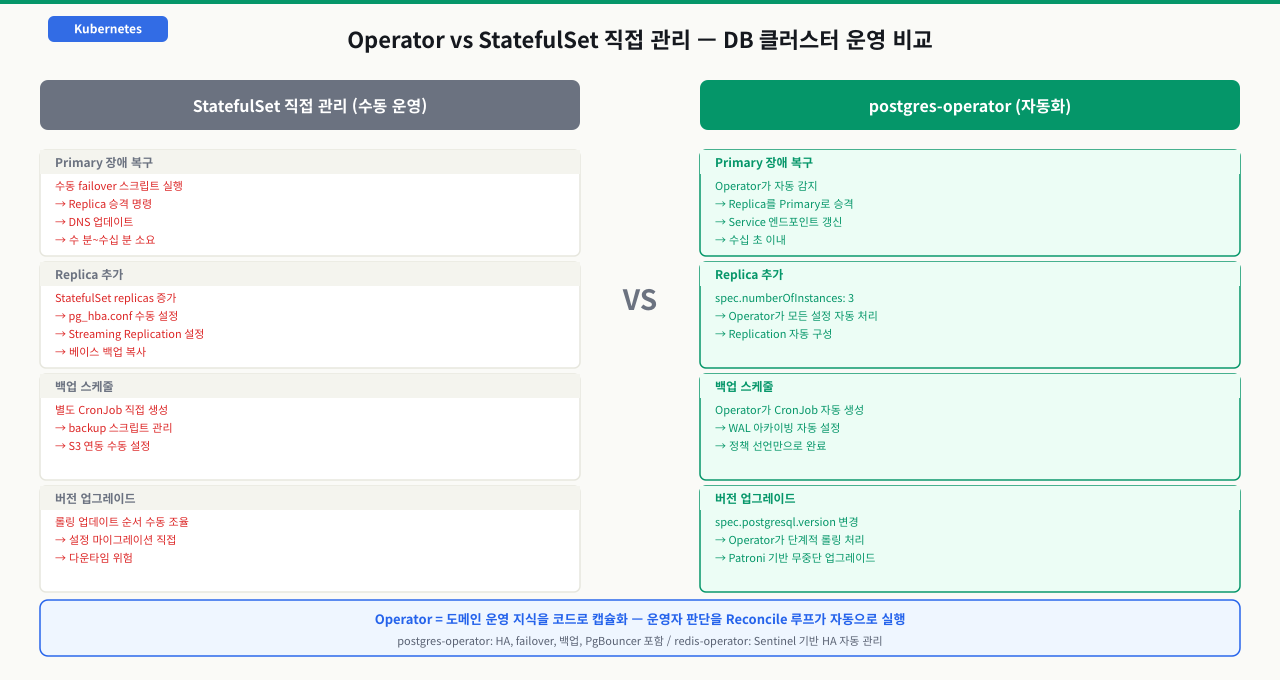
중견 이커머스 회사의 인프라팀. 15개 MySQL 인스턴스를 Kubernetes 외부에서 전통적으로 운영하다가 Kubernetes 마이그레이션을 결정했습니다. DB 파드를 직접 StatefulSet으로 관리할지, Operator를 쓸지 고민했습니다.
직접 StatefulSet 관리의 문제
- Primary 파드가 죽으면? → 수동으로 failover 스크립트 실행
- PostgreSQL 마이너 버전 업그레이드? → 롤링 업데이트 순서 수동 조율
- Replica 추가? → postgresql.conf, pg_hba.conf 수동 설정
- 백업 스케줄? → 별도 CronJob을 직접 관리
Operator 도입 후 달라진 것
# 이것만 변경하면 Replica 추가
spec:
numberOfInstances: 3 # 2 → 3으로 변경
# Operator가 자동으로:
# 1. 새 Replica 파드 생성
# 2. Primary에서 베이스 백업 복사
# 3. Streaming Replication 설정
# 4. Service 엔드포인트 업데이트
# → 운영자는 spec만 수정, 나머지는 Operator
현실적인 주의사항
1. Operator 자체도 관리 대상이다
→ Operator 버전 업그레이드 시 breaking change 확인 필수
→ Operator Pod 자체 장애 시 DB는 영향 없지만 자동화는 멈춤
2. Operator가 모든 것을 해결하지 않는다
→ 스토리지 확장, 대용량 마이그레이션은 여전히 주의 필요
→ Operator의 동작 방식을 이해해야 문제 발생 시 대응 가능
3. 운영 노하우가 Operator에 종속된다
→ postgres-operator를 쓰면 Patroni 이해도 필요
→ Operator 오픈소스 이슈 트래커를 구독할 것
postgres-operator 설치 및 CRD 확인
helm install postgres-operator postgres-operator-charts/postgres-operator -n operator-lab --create-namespace
kubectl get crd | grep acid.zalan.do예상 출력
postgresqls.acid.zalan.do operatorconfigurations.acid.zalan.do
Operator Pod 실행 상태 및 초기 로그 확인
kubectl get pods -n operator-lab -l app.kubernetes.io/name=postgres-operator
kubectl logs -n operator-lab -l app.kubernetes.io/name=postgres-operator --tail=10예상 출력
NAME READY STATUS RESTARTS postgres-operator-... 1/1 Running 0
PostgresCluster CRD 생성 및 Reconcile 관찰
kubectl apply -f postgres-cluster.yaml
kubectl get pods -n operator-lab -w | head -10예상 출력
NAME READY STATUS RESTARTS my-postgres-cluster-0 1/1 Running 0 my-postgres-cluster-1 1/1 Running 0
postgresql CRD 상태 및 생성된 리소스 확인
kubectl get postgresql -n operator-lab
kubectl get all -n operator-lab | grep -v postgres-operator예상 출력
NAME TEAM VERSION PODS STATUS my-postgres-cluster platform 16 2 Running
Primary 파드 강제 삭제 — 자동 복구 확인
kubectl delete pod my-postgres-cluster-0 -n operator-lab
sleep 30 && kubectl get pods -n operator-lab | grep postgres-cluster예상 출력
my-postgres-cluster-0 1/1 Running 0 my-postgres-cluster-1 1/1 Running 0
핵심 요약
| 개념 | 설명 |
|---|---|
| Operator | CRD(인터페이스) + Controller(구현)로 구성된 Kubernetes 애플리케이션 자동화 소프트웨어 |
| Reconcile 루프 | Watch → Diff → Act를 반복하며 선언 상태와 실제 상태를 맞추는 제어 루프 |
| Informer | Watch API를 추상화한 client-go 메커니즘 — 이벤트 캐싱과 리스트 기능 포함 |
| 멱등성 | 같은 Reconcile이 여러 번 실행되어도 동일한 결과 — Controller 설계의 핵심 원칙 |
| postgres-operator | Zalando의 PostgreSQL Operator — Patroni 기반 HA, 자동 failover, 백업 |
| redis-operator | Spotahome의 Redis Operator — Sentinel 기반 HA 클러스터 관리 |
| Controller 로그 | Operator 트러블슈팅의 시작점 — kubectl logs -l app=operator |
| OperatorHub | operatorhub.io — 검증된 Operator 카탈로그 |
명령어·단축키 빠른 참조
이 모듈에서 다룬 Operator 배포·CRD 상태·Reconcile 진단 명령을 실전 옵션과 함께 모았습니다. Operator가 최신 spec을 반영했는지는 metadata.generation과 status.observedGeneration 비교가 첫 지표입니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
helm install <operator> | Operator 배포 | helm install postgres-operator postgres-operator-charts/postgres-operator -n operator-lab |
kubectl get crd | grep | Operator가 등록한 CRD 확인 | kubectl get crd | grep acid.zalan.do |
kubectl get <cr> | 커스텀 리소스 상태(STATUS/PODS) 확인 | kubectl get postgresql -n operator-lab |
kubectl get all | grep -v | Operator가 생성한 하위 리소스 확인 | kubectl get all -n operator-lab | grep -v postgres-operator |
kubectl logs -l app=<operator> | Reconcile 에러 확인(진단 1순위) | kubectl logs -n operator-lab -l app.kubernetes.io/name=postgres-operator --since=5m |
kubectl get events --sort-by | 리소스 생성 실패 이유 확인 | kubectl get events -n operator-lab --sort-by=.creationTimestamp | tail -20 |
-o jsonpath(generation 비교) | Operator가 최신 spec 반영했는지 확인 | metadata.generation ≠ status.observedGeneration이면 미반영 |
kubectl describe <cr> | status·Events로 막힌 지점 파악 | kubectl describe postgresql my-postgres-cluster -n operator-lab |
kubectl auth can-i .../status | Operator RBAC(status 업데이트) 점검 | kubectl auth can-i update postgresql/status --as=system:serviceaccount:operator-lab:postgres-operator |
kubectl get secret -o jsonpath | Operator 자동 생성 인증정보 추출 | kubectl get secret <cred> -o jsonpath='{.data.password}' | base64 -d |
kubectl delete pod | 장애 시뮬레이션(자동 failover 관찰) | kubectl delete pod my-postgres-cluster-0 -n operator-lab |
kubectl get pods -w | Reconcile로 파드 생성/승격 실시간 관찰 | kubectl get pods -n operator-lab -w |
관련 모듈로 더 깊이:
- CRD(Custom Resource Definition)와 쿠버네티스 API 정의 — Operator가 감시하는 CRD를 직접 정의하고 스키마 검증을 설정하는 법
- 나만의 커스텀 Helm Chart 작성법과 환경별 Value 튜닝 — Operator와 CRD를 패키징해 일관되게 배포·버전 관리하는 또 다른 자동화 축
- Prometheus Operator와 Grafana 연동 대시보드 구축 — Reconcile 루프와 Controller 상태를 메트릭으로 관측해 Operator를 운영하는 법
다음 모듈 custom-resources에서는 Operator가 감시하는 CRD를 직접 정의하는 방법을 다룹니다. openAPIV3Schema로 스키마 검증을 설정하고, status 서브리소스로 Controller와 사용자 권한을 분리하는 CRD 설계 패턴을 익힙니다.