신규 배치 파드 하나가 노드 메모리를 모두 사용하면서 같은 노드의 API 파드까지 느려졌습니다. requests와 limits를 설정하지 않으면 스케줄러도 용량을 예측할 수 없고 kubelet도 보호선을 그을 수 없습니다. 리소스 제한은 멀티테넌트 클러스터의 기본 안전장치입니다.
프로덕션 클러스터에서 새벽 2시 알람이 울렸습니다. 특정 노드의 메모리 사용률이 98%를 넘어서며 여러 파드가 동시에 죽기 시작한 겁니다. 원인을 파보니 며칠 전 배포한 데이터 처리 파드에 메모리 limits가 설정되어 있지 않았고, 배치 작업 중 메모리 누수가 쌓이면서 노드 전체를 잠식했습니다. 이 패턴은 Kubernetes 초기 운영 팀이 가장 자주 겪는 인시던트 유형입니다. requests와 limits를 이해하면 이런 상황을 사전에 차단할 수 있습니다.
Kubernetes의 리소스 관리 모델은 단순합니다. requests는 "이 파드를 스케줄링할 노드에 최소한 이만큼은 남아있어야 한다"는 예약량이고, limits는 "이 이상 사용하면 강제 종료한다"는 상한선입니다. 이 두 값의 비율이 파드의 QoS(Quality of Service) 클래스를 결정하고, 노드가 리소스 부족에 빠졌을 때 어떤 파드가 먼저 종료되는지를 결정합니다. 실무에서 이를 제대로 설정하지 않은 클러스터는 언제 터질지 모르는 시한폭탄과 같습니다.
- 1CPU requests와 limits의 동작 원리(throttling과 OOM)를 설명할 수 있다
- 2메모리 requests와 limits의 차이점을 설명할 수 있다
- 3QoS 클래스 3종(Guaranteed, Burstable, BestEffort)을 구분할 수 있다
- 4LimitRange로 네임스페이스 기본값을 강제할 수 있다
- 5ResourceQuota로 팀별 리소스를 할당할 수 있다
- 6실무 limits 설정 가이드라인을 적용할 수 있다
kubectl get nodes -o custom-columns='NAME:.metadata.name,CPU:.status.capacity.cpu,MEM:.status.capacity.memory'kubectl create namespace resource-demokubectl top nodes 2>&1 | head -3kubectl top pods -A 2>/dev/null | head -10requests와 limits: 스케줄러와 kubelet의 역할 분담
배치 작업 파드 하나가 노드 메모리를 모두 소진하면서 같은 노드에 있던 API 서버 파드들이 연이어 OOMKilled됐습니다. limits가 없었기 때문입니다. 반대로 requests를 너무 높게 설정하면 실제로는 여유가 있는 노드인데 파드가 Pending 상태로 스케줄이 안 됩니다. requests와 limits는 Kubernetes가 파드를 배치하고 실행 중에 제어하는 두 단계의 안전장치입니다. 이 두 값의 관계를 이해해야 클러스터 자원을 낭비하지 않으면서도 이웃 파드를 보호하는 올바른 설정을 할 수 있습니다.
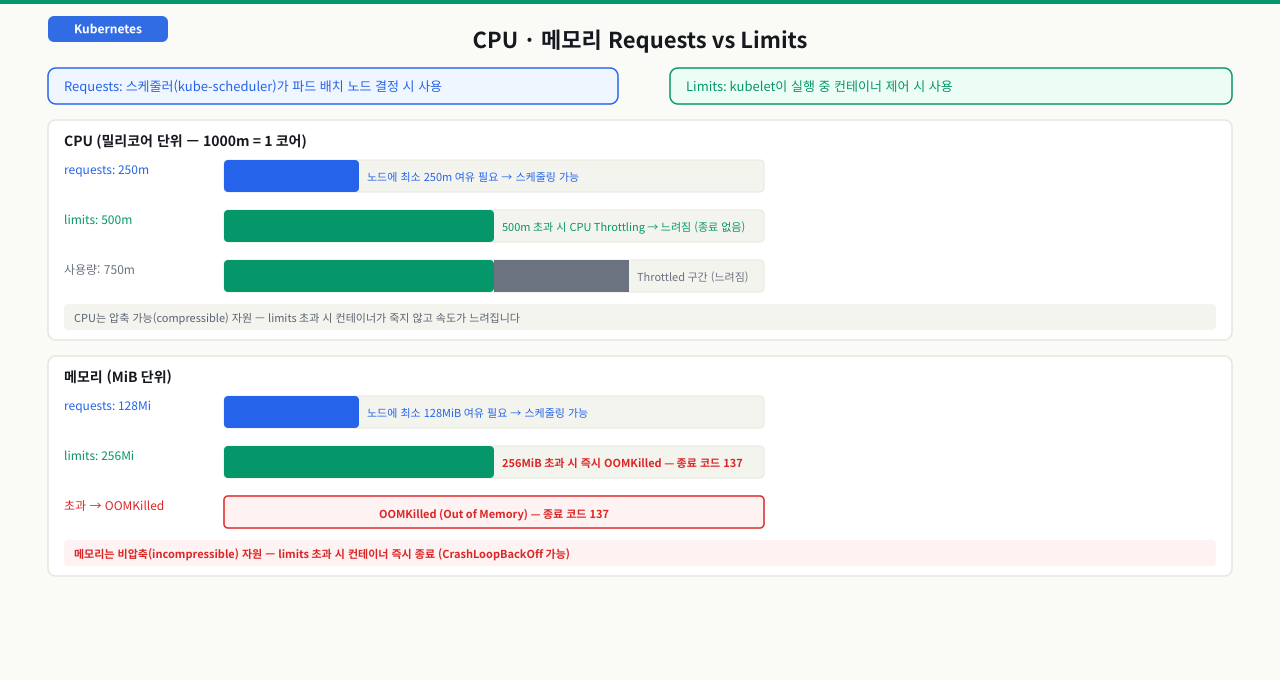
requests와 limits는 각각 다른 Kubernetes 컴포넌트가 사용합니다. requests는 스케줄러(kube-scheduler)가 파드를 어느 노드에 배치할지 결정할 때 사용하고, limits는 kubelet이 실행 중인 컨테이너를 제어할 때 사용합니다.
 확대
확대
CPU와 메모리는 동작 방식이 다릅니다.
- CPU limits 초과: 컨테이너는 죽지 않습니다. CPU throttling이 걸려 속도가 느려집니다.
- 메모리 limits 초과: 컨테이너가 즉시 OOMKilled(Out of Memory Killed, 종료 코드 137)됩니다.
# resource-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-demo
namespace: resource-demo
spec:
containers:
- name: app
image: nginx:1.25
resources:
requests:
memory: "128Mi" # 스케줄러: 이 노드에 128MiB 여유가 있어야 함
cpu: "250m" # 스케줄러: 0.25 코어(250 밀리코어) 여유 필요
limits:
memory: "256Mi" # kubelet: 초과 시 OOMKilled
cpu: "500m" # kubelet: 초과 시 CPU throttling (죽이지 않음)
CPU 단위 m은 밀리코어입니다. 1000m = 1 CPU 코어. 250m은 1코어의 25%를 의미합니다.
# 파드 생성 및 리소스 설정 확인
kubectl apply -f resource-demo.yaml
kubectl describe pod resource-demo -n resource-demo | grep -A 10 "Limits\|Requests"
# Limits:
# cpu: 500m
# memory: 256Mi
# Requests:
# cpu: 250m
# memory: 128Mi
# 실제 사용량 모니터링 (metrics-server 필요)
kubectl top pod resource-demo -n resource-demo
# NAME CPU(cores) MEMORY(bytes)
# resource-demo 3m 8Mi
- kubectl top pod <name> -n <ns>에서 현재 CPU/메모리 사용량을 먼저 확인 — 메모리 사용량이 limits에 설정한 값의 80% 이상이면 OOMKilled 임박. kubectl describe pod로 limits 값과 대조
- RESTARTS 수치가 오르면서 Events에 "OOMKilled"가 보이면 → 메모리 limits 부족. kubectl describe pod <name>의 "Last State: Terminated Reason: OOMKilled"로 확인 후 limits.memory를 최소 2배로 늘려 테스트
- kubectl top node에서 CPU% 높고 kubectl top pods에서 limits가 없는 파드가 있으면 → BestEffort QoS 파드가 CPU를 독점 중. requests와 limits를 모두 설정해 Guaranteed QoS로 전환하면 노드 압박 시 eviction 우선순위가 낮아짐
QoS 클래스: 메모리 부족 시 누가 먼저 죽는가
Kubernetes는 노드 메모리가 부족해질 때 파드를 evict(강제 퇴거)합니다. 이때 QoS 클래스에 따라 우선순위가 결정됩니다. BestEffort가 가장 먼저, Guaranteed가 가장 마지막으로 종료됩니다.
 확대
확대
# QoS: Guaranteed — requests == limits (모든 컨테이너, CPU+메모리 전부)
resources:
requests:
memory: "256Mi"
cpu: "500m"
limits:
memory: "256Mi" # requests와 동일
cpu: "500m" # requests와 동일
---
# QoS: Burstable — requests < limits, 또는 일부 컨테이너만 설정
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "512Mi" # requests와 다름
cpu: "1000m"
---
# QoS: BestEffort — requests, limits 모두 미설정
# (설정하지 않으면 자동으로 BestEffort)
resources: {}
# 파드의 QoS 클래스 확인
kubectl get pod resource-demo -n resource-demo \
-o jsonpath='{.status.qosClass}'
# Burstable
# 모든 파드의 QoS 클래스 일괄 확인
kubectl get pods -A \
-o custom-columns='NAMESPACE:.metadata.namespace,NAME:.metadata.name,QOS:.status.qosClass'
실무 가이드:
- DB, 메시지 큐, 결제 서비스 → Guaranteed (안정성 최우선)
- API 서버, 백엔드 서비스 → Burstable (평소에는 낮게, 트래픽 몰릴 때 버스트)
- 배치 작업, 개발 환경 → BestEffort (OK, 단 limits는 꼭 설정)
requests·limits가 스케줄부터 런타임까지 작동하는 법 — 4단계
같은 resources 블록 하나가 서로 다른 두 컴포넌트에서, 서로 다른 두 시점에 쓰입니다. requests는 파드가 뜨기 전 스케줄러가, limits는 파드가 뜬 뒤 kubelet이 씁니다. 이 분업을 단계로 펼쳐 보면 왜 어떤 파드는 Pending으로 안 뜨고(스케줄 실패), 어떤 컨테이너는 느려지기만 하고(CPU throttle), 어떤 컨테이너는 죽는지(OOMKilled), 그리고 노드가 터질 때 누가 먼저 쫓겨나는지가 한 줄기로 이어집니다.
파드 생성 (requests: cpu 250m·mem 128Mi / limits: cpu 500m·mem 256Mi)
│
① 스케줄 배정 (kube-scheduler가 requests로 노드 여유 확인 → 배치)
│
② 런타임 제한 설정 (kubelet이 limits를 노드의 cgroup에 기록)
│
├─③a CPU가 limit 초과 (압축 가능 → CFS로 throttle: 느려질 뿐 안 죽음)
├─③b 메모리가 limit 초과 (압축 불가 → OOMKilled, exit 137, 재시작)
│
④ 노드 메모리 부족 시 축출 순위 (QoS: BestEffort → Burstable → Guaranteed)
▼
requests=배치 기준 · limits=상한(초과 시 throttle 또는 kill) · 둘의 관계=QoS 등급
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 (누가·언제) | 여기서 어긋나면 |
|---|---|---|
| ① 스케줄 배정 | kube-scheduler가 파드 생성 시 requests 합이 들어갈 노드를 찾음(bin-packing) | 어떤 노드도 requests만큼 여유가 없음 → 파드가 Pending. requests 과대 설정도 같은 낭비 증상 |
| ② 런타임 제한 | kubelet이 파드 기동 시 limits를 cgroup(CPU 쿼터·메모리 상한)으로 커널에 설정 | limits 미설정이면 상한이 없어 이웃 파드까지 위협(BestEffort) |
| ③a CPU 초과 | CPU는 압축 가능 자원 → CFS가 주기마다 쿼터로 조임 | throttle로 느려짐. top은 낮아도 스로틀 카운터가 오르면 p99 지연 |
| ③b 메모리 초과 | 메모리는 압축 불가 → 회수 못 해 커널이 프로세스 종료 | OOMKilled(exit 137) → RESTARTS 증가 → CrashLoopBackOff |
| ④ 축출 우선순위 | 노드 메모리 압박 시 QoS 등급으로 evict 순서 결정 | 설정 없는 BestEffort 파드가 가장 먼저 쫓겨남 |
즉 하나의 증상은 하나의 단계를 가리킵니다 — Pending이면 ①(requests가 노드 여유보다 큼), 느려지기만 하면 ③a(CPU throttle), RESTARTS와 exit 137이 함께면 ③b(메모리 OOMKilled), 노드가 붐빌 때 유독 먼저 죽으면 ④(BestEffort/Burstable). 그래서 requests는 표시값이 아니라 ①과 ④의 입력이고, limits는 ②에서 설정돼 ③의 방식(throttle 대 kill)을 가르는 상한입니다.
LimitRange: 네임스페이스 기본값 강제
팀원이 resources를 빠뜨리고 배포할 때를 대비해 LimitRange로 기본값과 허용 범위를 강제할 수 있습니다. resources를 설정하지 않은 파드에는 자동으로 default 값이 주입됩니다.
# limitrange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: default-limits
namespace: resource-demo
spec:
limits:
- type: Container
default: # limits 미설정 시 자동 주입
cpu: "500m"
memory: "256Mi"
defaultRequest: # requests 미설정 시 자동 주입
cpu: "100m"
memory: "128Mi"
max: # 이 값 이상은 허용 안 함
cpu: "2"
memory: "2Gi"
min: # 이 값 미만은 허용 안 함
cpu: "50m"
memory: "64Mi"
kubectl apply -f limitrange.yaml
# 검증: resources 없이 파드 생성
kubectl run test-default --image=nginx:1.25 -n resource-demo
# 자동으로 default 값이 주입됐는지 확인
kubectl describe pod test-default -n resource-demo | grep -A 8 "Limits\|Requests"
# Limits:
# cpu: 500m ← LimitRange에서 주입됨
# memory: 256Mi ← LimitRange에서 주입됨
kubectl delete pod test-default -n resource-demo
실습: 메모리 limits 효과 직접 확인
실제로 메모리 limits를 초과하면 어떤 일이 발생하는지 확인합니다.
OOMKilled 유발 파드 생성 — 노드 메모리 압박
안전한 실행 조건: kubectl config current-context 로 개발 클러스터인지 확인. kubectl top nodes 로 노드 여유 메모리가 충분한지(최소 200MB 이상) 확인 후 진행하세요.
실행 전 반드시 확인
- kubectl config current-context 로 개발 클러스터(minikube 등)인지 확인
- kubectl top nodes 로 노드 메모리 여유가 충분한지 확인
- 실습 완료 후 kubectl delete pod memory-stress -n resource-demo 로 즉시 정리
kubectl apply -f - (memory-stress 파드 생성)위 항목을 모두 확인한 후 복사할 수 있습니다
# 메모리를 급격히 소모하는 파드 생성 (limits: 64Mi)
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: memory-stress
namespace: resource-demo
spec:
containers:
- name: stress
image: polinux/stress
args: ["--vm", "1", "--vm-bytes", "128M", "--vm-hang", "1"]
resources:
requests:
memory: "64Mi"
limits:
memory: "64Mi" # 128MB 요청하지만 64MB만 허용
EOF
# 파드 상태 관찰 (OOMKilled 대기)
kubectl get pod memory-stress -n resource-demo -w
# NAME READY STATUS RESTARTS AGE
# memory-stress 0/1 OOMKilled 0 5s
# memory-stress 0/1 CrashLoopBackOff 1 10s
# 종료 이유 확인
kubectl describe pod memory-stress -n resource-demo | grep -A 5 "Last State"
# Last State: Terminated
# Reason: OOMKilled
# Exit Code: 137
# 정리
kubectl delete pod memory-stress -n resource-demo
실습: ResourceQuota로 네임스페이스 총량 제한
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-quota
namespace: resource-demo
spec:
hard:
requests.cpu: "2"
requests.memory: "2Gi"
limits.cpu: "4"
limits.memory: "4Gi"
pods: "10"
EOF
# 현재 사용량 vs 할당량 확인
kubectl describe resourcequota team-quota -n resource-demo
# Name: team-quota
# Namespace: resource-demo
# Resource Used Hard
# -------- ---- ----
# limits.cpu 500m 4
# limits.memory 256Mi 4Gi
# pods 1 10
# requests.cpu 100m 2
# requests.memory 128Mi 2Gi
신규 데이터 집계 서비스를 배포한 후 처음 며칠은 정상 동작했습니다. 그런데 시간이 지나면서 파드가 주기적으로 재시작되고, 재시작 간격이 점점 짧아지더니 결국 노드 전체가 느려지기 시작했습니다. kubectl get pods를 보면 RESTARTS 숫자가 비정상적으로 높습니다.
# 증상 확인
kubectl get pods -n production
# NAME READY STATUS RESTARTS AGE
# data-aggregator 0/1 CrashLoopBackOff 47 6h
# 1단계: 종료 이유 파악
kubectl describe pod data-aggregator -n production | grep -A 10 "Last State\|Reason\|Exit Code"
# Last State: Terminated
# Reason: OOMKilled ← 핵심 단서
# Exit Code: 137
# Started: Fri, 16 May 2026 03:14:22
# Finished: Fri, 16 May 2026 03:19:57
# 2단계: 현재 리소스 설정 확인
kubectl get pod data-aggregator -n production \
-o jsonpath='{.spec.containers[0].resources}' | python3 -m json.tool
# {} ← resources가 아예 없음!
# 3단계: 파드가 실제로 얼마나 쓰고 있었는지 (이전 로그)
kubectl logs data-aggregator -n production --previous 2>&1 | tail -20
# 4단계: 동종 파드가 있다면 현재 메모리 사용량 측정
kubectl top pod -l app=data-aggregator -n production
# NAME CPU(cores) MEMORY(bytes)
# data-aggregator-xyz-abc 15m 487Mi
# 5단계: 안전한 limits 계산 (측정값 × 1.5 여유)
# 측정값 487Mi → limits: 768Mi, requests: 256Mi 로 설정
# 6단계: Deployment 수정
kubectl set resources deployment/data-aggregator \
-n production \
--requests=cpu=100m,memory=256Mi \
--limits=cpu=500m,memory=768Mi
# 7단계: 롤아웃 확인
kubectl rollout status deployment/data-aggregator -n production
# 8단계: 이후 안정성 모니터링
kubectl top pod -l app=data-aggregator -n production --watch
근본 원인: resources 블록 자체가 없어 QoS 클래스가 BestEffort였습니다. 메모리 누수가 있는 상황에서 limits가 없으니 프로세스는 계속 메모리를 늘렸고, 결국 노드의 OOM killer가 컨테이너를 강제 종료했습니다.
예방: 모든 Deployment에 resources 블록을 필수로 작성하도록 팀 컨벤션을 정하고, LimitRange로 미설정 시 기본값이 주입되도록 네임스페이스를 설정해두세요. CI 파이프라인에서 kubectl apply --dry-run=server로 LimitRange 위반 여부를 사전 검사할 수도 있습니다.
심화 — CPU가 한가한데 왜 느릴까
심화: CPU limit은 어떻게 강제되나 — CFS 쿼터와 스로틀링의 함정
메모리 limit은 초과하면 OOMKilled로 죽어서 눈에 잘 띕니다. 반면 CPU limit은 죽이지 않고 느리게 만들기만 해서, 정작 장애 원인일 때조차 지나치기 쉽습니다. CPU limit이 실제로 어떻게 강제되는지 알면 이 함정을 피할 수 있습니다.
CPU limit은 리눅스 커널의 CFS 대역폭 컨트롤러가 강제합니다. 시간을 짧은 주기(period, 기본 100ms) 로 쪼개고, 그 주기 안에서 cgroup이 쓸 수 있는 쿼터(quota) 를 정합니다. limit이 500m이면 매 100ms마다 50ms의 CPU 시간을 줍니다(모든 코어 합산). 문제는 쿼터를 언제 다 쓰느냐입니다.
- 버스트가 쿼터를 초반에 소진하면 남은 주기 내내 스로틀됩니다. 예컨대 4개 스레드가 동시에 25ms씩 벽시계 시간을 돌면 100ms 주기의 쿼터를 초반 25ms 만에 소진하고, 나머지 75ms 동안 그 컨테이너는 CPU를 못 받습니다. 이 75ms가 그대로 응답 지연이 됩니다.
- 그래서 1분 평균 사용률(kubectl top)이 낮아도 스로틀은 심할 수 있습니다. 평균은 낮지만 매 주기마다 짧고 굵게 스로틀당하는 것이라, top으로는 절대 안 보이고 p99 지연으로만 드러납니다.
- 멀티코어일수록 쉽게 걸립니다. 쿼터는 코어 합산이라, 병렬 처리를 하는 앱에 낮은 CPU limit을 걸면 짧은 순간에 여러 코어가 쿼터를 함께 소진합니다.
확인 지표는 사용률이 아니라 스로틀 카운터입니다. cgroup의 cpu.stat에서 nr_throttled(스로틀된 주기 수)와 throttled_time, 또는 Prometheus의 container_cpu_cfs_throttled_periods_total을 봅니다. 스로틀된 주기 비율이 높으면 CPU limit이 병목입니다. 그래서 지연에 민감한 서비스는 CPU requests만 두고 CPU limit은 제거하거나 넉넉히 잡는 팀이 많습니다 — CPU는 압축 가능 자원이라 limit이 없어도 노드가 붐빌 때 requests 비율대로 공정하게 나눠 갖기 때문입니다(메모리와 달리 폭주로 노드를 죽이지 않습니다).
상황: 트래픽도 배포도 그대로인데 특정 서비스의 p99 지연이 주기적으로 튑니다. kubectl top pod로 보면 CPU는 limit의 30% 남짓이라 리소스 부족처럼 보이지 않고, 메모리도 여유가 있습니다. 슬로우 쿼리나 GC를 의심해 봐도 딱 맞지 않습니다.
원인: CPU limit에 의한 CFS 스로틀링입니다. 평균 사용률은 낮지만, 요청이 몰리는 순간 여러 스레드가 100ms 주기의 쿼터를 초반에 소진해 남은 주기 동안 스로틀됩니다. 평균값(top)으로는 절대 안 보이고, 순간 스로틀이 꼬리 지연(p99)으로만 나타납니다.
진단: 사용률이 아니라 스로틀 카운터를 봅니다. 파드 안에서 cat /sys/fs/cgroup/cpu.stat(cgroup v2, v1은 cpu.cfs_throttled...)의 nr_throttled·throttled_time이 계속 증가하는지, 또는 대시보드에서 container_cpu_cfs_throttled_periods_total을 전체 주기 수와 비교합니다. 스로틀 비율이 유의미하게 높고 그 시점이 지연 스파이크와 겹치면 확정입니다.
해결: CPU limit을 실제 버스트를 담을 만큼 올리거나, 지연에 민감한 서비스라면 CPU limit을 제거합니다(CPU requests는 유지 — 스케줄링·공정 분배 기준). CPU는 압축 가능 자원이라 limit이 없어도 노드가 붐빌 때 requests 비율대로 나눠 가질 뿐, 메모리처럼 노드를 위협하지 않습니다. 메모리 limit은 그대로 두는 것과 대비됩니다. 조정 후 다시 스로틀 카운터가 잠잠해지는지, p99가 안정되는지 확인합니다(HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장).
시나리오: 신규 API 서비스의 리소스 설정값 결정
스타트업의 첫 번째 Kubernetes 마이그레이션을 맡았습니다. VM에서 잘 돌던 Node.js API 서버를 K8s로 옮기는데, resources를 어떻게 설정해야 할지 모르겠습니다.
# 1단계: VM에서 현재 사용량 측정 (이전 환경 참고)
# VM에서: top, htop, free -m 등으로 1주일치 평균 측정
# 측정 결과: 평균 CPU 0.15코어, 평균 메모리 180MB, 피크 메모리 320MB
# 2단계: 초기 값 보수적으로 설정하고 배포
cat <<EOF > api-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-server
namespace: production
spec:
replicas: 2
selector:
matchLabels:
app: api-server
template:
metadata:
labels:
app: api-server
spec:
containers:
- name: api
image: myapp/api:v1.0.0
ports:
- containerPort: 3000
resources:
requests:
cpu: "200m" # 평균 0.15코어 + 여유
memory: "256Mi" # 평균 180MB 올림
limits:
cpu: "800m" # 버스트 허용 (Burstable QoS)
memory: "512Mi" # 피크 320MB + 안전 여유
EOF
kubectl apply -f api-deployment.yaml
# 3단계: 1주일 후 실제 사용량 기반으로 튜닝
kubectl top pods -l app=api-server -n production
# NAME CPU(cores) MEMORY(bytes)
# api-server-xxx-aaa 45m 198Mi
# api-server-xxx-bbb 52m 205Mi
# CPU가 요청의 25%밖에 안 쓰므로 requests 하향 조정
kubectl set resources deployment/api-server \
-n production \
--requests=cpu=100m,memory=256Mi \
--limits=cpu=500m,memory=512Mi
# 4단계: HPA 설정을 위한 기준선 완성
# (다음 모듈에서 HPA 추가 예정)
실무 포인트: requests는 측정값 기반으로, limits는 "이게 넘어가면 뭔가 잘못된 것"이라는 안전망 개념으로 설정합니다. 처음부터 완벽한 값을 찾으려 하지 말고, 배포 후 kubectl top으로 1-2주 모니터링해 실측값 기반으로 조정하는 것이 현실적입니다.
requests와 limits가 설정된 파드 배포
kubectl create namespace resource-demo
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: resource-demo
namespace: resource-demo
spec:
containers:
- name: app
image: nginx:1.25
resources:
requests:
memory: '128Mi'
cpu: '250m'
limits:
memory: '256Mi'
cpu: '500m'
EOF
kubectl get pod resource-demo -n resource-demo예상 출력
NAME READY STATUS RESTARTS AGE resource-demo 1/1 Running 0 10s
파드 리소스 설정 확인
kubectl describe pod resource-demo -n resource-demo | grep -A6 'Limits\|Requests'예상 출력
Limits: cpu: 500m memory: 256Mi Requests: cpu: 250m memory: 128Mi
QoS 클래스 확인
kubectl get pod resource-demo -n resource-demo \
-o jsonpath='{.status.qosClass}'예상 출력
Burstable
LimitRange 적용 후 기본값 자동 주입 확인
kubectl apply -f - <<EOF
apiVersion: v1
kind: LimitRange
metadata:
name: default-limits
namespace: resource-demo
spec:
limits:
- type: Container
default:
cpu: '500m'
memory: '256Mi'
defaultRequest:
cpu: '100m'
memory: '128Mi'
EOF
kubectl run test-default --image=nginx:1.25 -n resource-demo
kubectl describe pod test-default -n resource-demo | grep -A6 'Limits\|Requests'예상 출력
Limits: cpu: 500m memory: 256Mi Requests: cpu: 100m memory: 128Mi
실제 리소스 사용량 확인 (metrics-server 필요)
kubectl top pod resource-demo -n resource-demo예상 출력
NAME CPU(cores) MEMORY(bytes) resource-demo 3m 8Mi
핵심 요약
| 개념 | 역할 | 초과 시 동작 |
|---|---|---|
| CPU requests | 스케줄링 기준 | — |
| CPU limits | 실행 중 제어 | throttling (느려짐, 종료 없음) |
| Memory requests | 스케줄링 기준 | — |
| Memory limits | 실행 중 제어 | OOMKilled (종료 코드 137) |
| LimitRange | 네임스페이스 기본값/범위 | 초과 시 파드 거부 |
| ResourceQuota | 네임스페이스 총량 제한 | 초과 시 파드 거부 |
| QoS 클래스 | 조건 | Eviction 우선순위 |
|---|---|---|
| Guaranteed | requests == limits (전 컨테이너) | 마지막 |
| Burstable | requests < limits (일부라도 설정) | 중간 |
| BestEffort | 설정 없음 | 가장 먼저 |
명령어·단축키 빠른 참조
이 모듈에서 사용량을 재고 QoS·OOM·스로틀을 진단할 때 쓴 kubectl 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl top pod | 실제 CPU/메모리 사용량 측정 | kubectl top pod --sort-by=memory · kubectl top pods -A |
kubectl top node | 노드 여유 자원 확인 | kubectl top nodes |
kubectl describe node | 노드 Allocatable·예약된 requests 확인 | kubectl describe node X | grep -A5 Allocated |
kubectl describe pod | limits·requests·종료 사유 확인 | kubectl describe pod X | grep -A5 "Last State" (OOMKilled) |
kubectl get pod -o jsonpath | QoS 클래스 확인 | kubectl get pod X -o jsonpath='{.status.qosClass}' |
kubectl get pods -o custom-columns | QoS 일괄 조회 | ... -o custom-columns='NAME:.metadata.name,QOS:.status.qosClass' |
kubectl set resources | requests/limits 즉시 수정 | kubectl set resources deploy/X --requests=cpu=100m,memory=256Mi --limits=cpu=500m,memory=768Mi |
kubectl describe resourcequota | 사용량 vs 할당량 대조 | kubectl describe resourcequota team-quota -n <ns> |
kubectl get pod -w | OOMKilled→CrashLoop 전환 관찰 | kubectl get pod memory-stress -w |
cat .../cpu.stat | CPU 스로틀 카운터 확인 | nr_throttled·throttled_time이 늘면 CFS 스로틀 |
| Exit Code 137 | OOMKilled 판별 | describe의 Reason: OOMKilled + Exit Code: 137 |
관련 모듈로 더 깊이:
- HPA(Horizontal Pod Autoscaler) 메트릭 기반 파드 확장 — CPU requests를 기준으로 파드 수를 늘리고 줄이는 수평 스케일링
- VPA(Vertical Pod Autoscaler) 기반 실시간 리소스 최적화 — requests/limits 값 자체를 자동으로 최적화하는 수직 스케일링
- Namespace를 활용한 여러 개발팀 간 리소스 분할 운영 — LimitRange·ResourceQuota로 네임스페이스 단위 자원을 강제하는 법
다음 모듈 hpa-autoscaling에서는 설정한 CPU requests를 기준으로 자동 스케일링하는 HPA를 다룹니다. requests 설정이 HPA 동작에 왜 필수인지, maxReplicas 설정으로 비용을 어떻게 제어하는지 실습합니다.