장애 알림을 받은 온콜 엔지니어가 kubectl get nodes를 실행했는데 Control Plane과 Worker Node 중 어디가 문제인지 감이 오지 않습니다. API Server, etcd, Scheduler, kubelet의 역할을 구분하지 못하면 복구 순서도 잘못 잡게 됩니다. 클러스터 구조를 이해해야 장애 지점을 빠르게 좁힐 수 있습니다.
Kubernetes 클러스터 아키텍처
kubectl apply를 눌렀다. 배포가 시작됐다. 그런데 아무것도 안 일어난다. 5분이 지났다. Pod가 Pending에서 멈춰있다. 로그를 보려 했더니 kubectl마저 응답하지 않는다. 클러스터 내부에서 무슨 일이 벌어지고 있는지 모르면, 이 상황에서 아무것도 할 수 없다. Kubernetes는 단순히 컨테이너를 실행하는 단일 프로그램이 아니다. 여러 컴포넌트가 각자의 역할을 나눠 협력하는 분산 시스템이다. 어느 컴포넌트가 무엇을 담당하는지 알아야, 장애가 났을 때 어디를 먼저 봐야 하는지 알 수 있다.
Kubernetes 클러스터를 구성하는 각 컴포넌트의 역할을 이해하고, 장애 시 어느 컴포넌트를 먼저 확인해야 하는지 파악합니다.
- 1Control Plane의 4개 컴포넌트(API Server, etcd, Scheduler, Controller Manager)와 각 역할을 설명할 수 있다
- 2Worker Node의 컴포넌트(kubelet, kube-proxy, Container Runtime)와 각 역할을 설명할 수 있다
- 3kubectl apply 시 컴포넌트 간 요청 흐름을 추적할 수 있다
- 4API Server가 응답하지 않는 Control Plane 장애를 진단할 수 있다
minikube를 사용한다면: minikube start 후 진행하세요. 클러스터가 없어도 개념 파악은 가능합니다.
kubectl version --clientkubectl cluster-infokubectl get nodeskubectl get pods -n kube-systemControl Plane — 클러스터의 두뇌
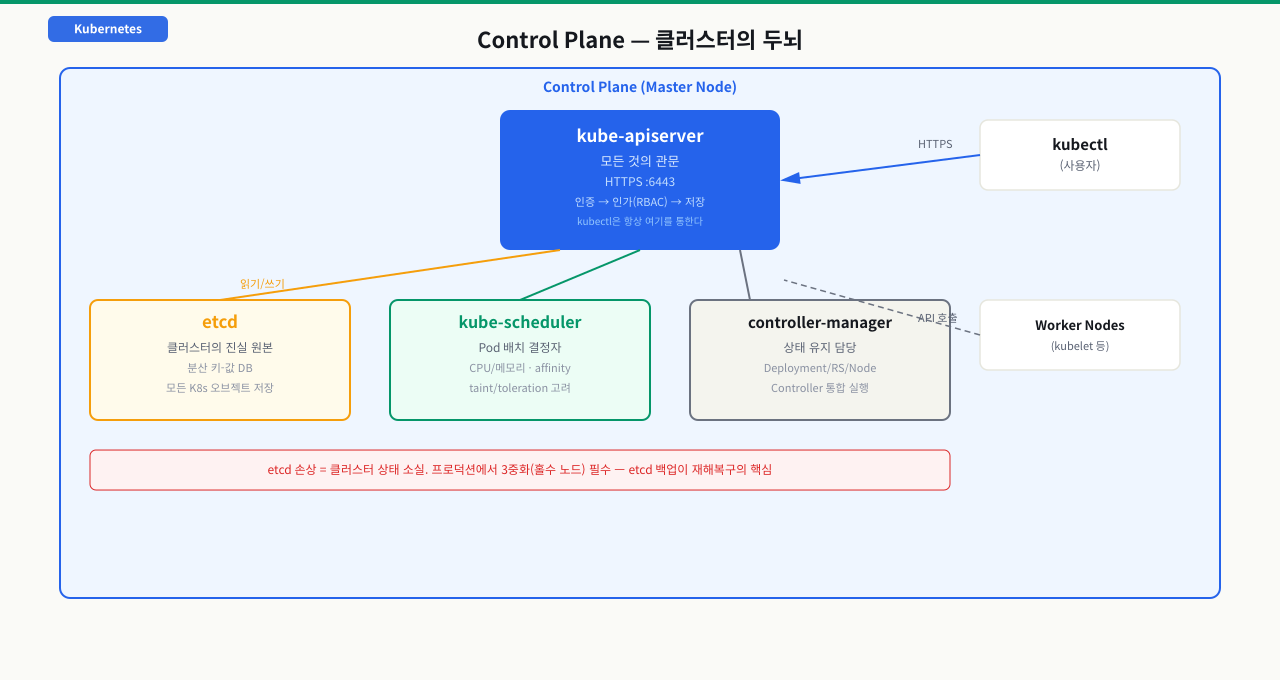
kubectl apply를 눌렀는데 Pod가 스케줄되지 않는다면, 가장 먼저 Control Plane 컴포넌트가 살아 있는지 확인해야 합니다. 클러스터 장애의 많은 경우가 kube-apiserver, etcd, scheduler 중 하나가 비정상 상태에서 발생합니다. 각 컴포넌트의 역할을 모르면 어디부터 확인해야 할지 막막합니다. 특히 etcd가 다운되면 배포, 조회, 설정 변경 등 모든 API 작업이 불가능해지지만 이미 실행 중인 Pod는 살아있어 증상이 명확하지 않습니다. 그래서 Control Plane 구성과 각 컴포넌트의 역할을 먼저 이해해야 장애 진단 순서가 생깁니다.
 확대
확대
1. kube-apiserver — 모든 것의 관문
# 모든 kubectl 명령은 API Server를 통한다
kubectl get pods
# → HTTPS 요청 → kube-apiserver:6443 → etcd 조회 → 응답
# API Server 주소 확인
kubectl cluster-info
# Kubernetes control plane is running at https://192.168.49.2:8443
# API Server에 직접 요청 (디버깅 시 유용)
kubectl proxy & # 로컬 프록시 실행
curl http://localhost:8001/api/v1/namespaces/default/pods
API Server는 모든 요청에 대해 인증(Authentication) → 인가(Authorization, RBAC) → 어드미션 컨트롤 순으로 검증합니다.
2. etcd — 클러스터의 진실 원본
# etcd는 모든 K8s 오브젝트를 저장하는 분산 키-값 DB
# 직접 접근은 거의 하지 않지만 백업은 매우 중요
# etcd 상태 확인 (kubeadm 기반 클러스터)
kubectl get pods -n kube-system | grep etcd
# etcd-minikube 1/1 Running 0 10m
# etcd 백업 (프로덕션 필수)
ETCDCTL_API=3 etcdctl snapshot save backup.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
etcd 데이터가 손실되면 클러스터의 모든 상태 정보가 사라집니다. etcd 백업은 재해복구의 핵심입니다.
3. kube-scheduler — Pod 배치 결정자
# 스케줄러가 고려하는 것들:
# - 노드의 CPU/메모리 여유 (requests 기준)
# - nodeSelector, nodeAffinity 규칙
# - taint/toleration
# - Pod anti-affinity (같은 노드에 배치 금지)
# Pending Pod의 스케줄링 실패 이유 확인
kubectl describe pod <pod-name> | grep -A5 Events
# Events:
# Warning FailedScheduling ... 0/1 nodes are available: 1 Insufficient memory.
# 노드 리소스 현황 확인
kubectl describe nodes | grep -A5 "Allocated resources"
4. kube-controller-manager — 상태 유지 담당
Controller Manager는 여러 컨트롤러를 하나의 프로세스로 실행합니다:
Deployment Controller → ReplicaSet 생성/관리
ReplicaSet Controller → Pod 수 유지 (죽으면 새로 생성)
Node Controller → 노드 장애 감지 및 처리
Job Controller → 일회성 작업 완료 관리
ServiceAccount Controller → 서비스 어카운트 생성
# Controller Manager 로그 확인 (kubeadm 기반)
kubectl logs -n kube-system kube-controller-manager-minikube | tail -20
Worker Node — Pod가 실제로 실행되는 곳
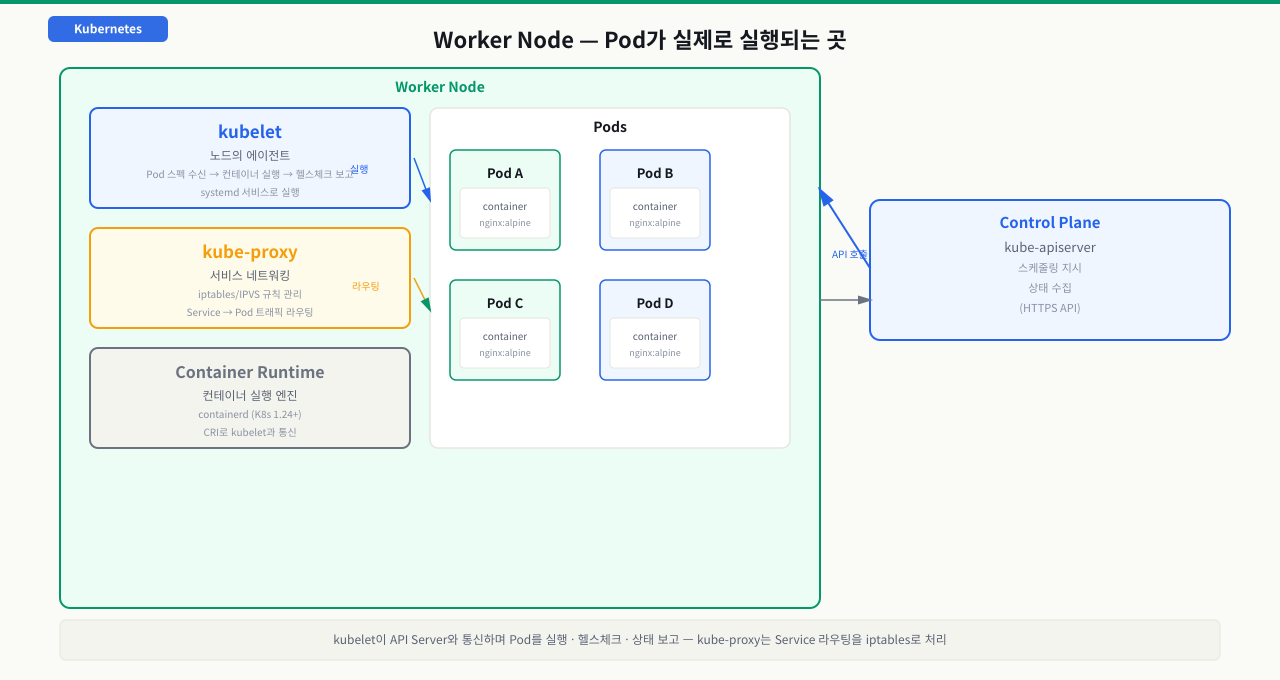
Control Plane이 살아 있어도 Pod가 Running 상태가 되지 않는다면, 워커 노드 컴포넌트를 확인해야 합니다. kubelet이 컨테이너 런타임에 요청을 보내지 못하거나, kube-proxy가 Service 라우팅 규칙을 업데이트하지 못하면 Pod는 생성되더라도 트래픽이 닿지 않습니다. 노드가 NotReady 상태일 때 단순히 노드 재시작이 아니라 kubelet 로그부터 확인해야 하는 이유가 여기에 있습니다. 각 컴포넌트가 어떤 역할을 나눠서 담당하는지 알아야 증상에서 원인 컴포넌트로 빠르게 좁힐 수 있습니다.
 확대
확대
1. kubelet — 노드의 에이전트
# kubelet은 systemd 서비스로 실행
systemctl status kubelet
# kubelet 로그 확인 (컨테이너 시작 실패 시 유용)
journalctl -u kubelet -n 50 --no-pager
# kubelet이 관리하는 노드 상태 확인
kubectl describe node <node-name>
# Conditions:
# Ready: True ← kubelet이 API Server에 보고
# MemoryPressure: False
# DiskPressure: False
kubelet의 동작 순서:
- API Server를 통해 자신의 노드에 스케줄된 Pod 스펙 수신
- 컨테이너 런타임(containerd)에 컨테이너 시작 요청
- liveness/readiness probe 실행
- 상태를 API Server에 주기적으로 보고
2. kube-proxy — 서비스 네트워킹
# kube-proxy는 Service → Pod 트래픽 라우팅 담당
# iptables 또는 IPVS 규칙을 관리
# kube-proxy 상태 확인
kubectl get pods -n kube-system | grep kube-proxy
# kube-proxy-xxxxx 1/1 Running 0 1h
# iptables 규칙 확인 (Service ClusterIP로의 라우팅)
sudo iptables -t nat -L KUBE-SERVICES | head -20
3. Container Runtime — 컨테이너 실행 엔진
# K8s 1.24 이후 Docker 제거, containerd가 기본
# CRI(Container Runtime Interface)로 kubelet과 통신
# containerd 상태 확인
systemctl status containerd
# crictl로 컨테이너 직접 확인 (디버깅 시)
crictl ps
crictl images
crictl logs <container-id>
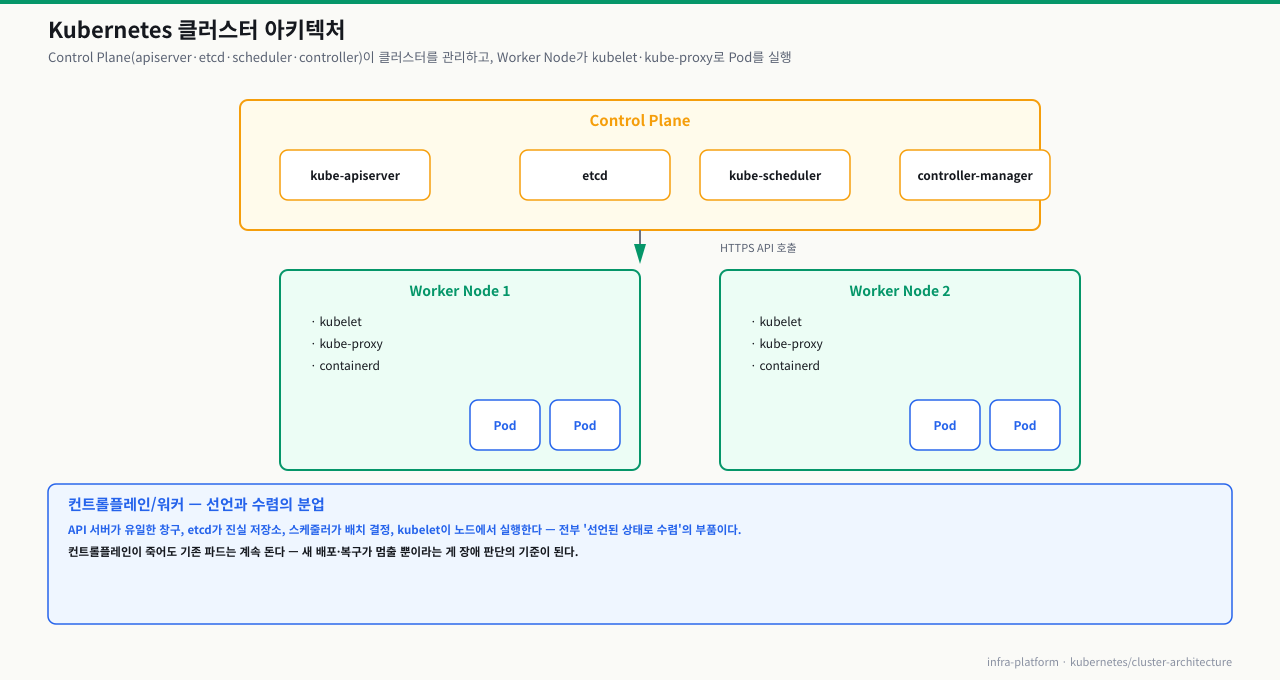
전체 아키텍처 요약
 확대
확대
kubectl apply 한 줄이 클러스터 안에서 도는 법 — 요청부터 Running까지 7단계
kubectl apply -f pod.yaml 한 줄. Enter를 누르면 잠시 뒤 kubectl get pod에 Running이 뜹니다. 이 짧은 순간에 클러스터 안에서는 apiserver → etcd → controller-manager → scheduler → kubelet이 순서대로 바통을 넘깁니다. 이 흐름을 알면 "배포했는데 아무 일도 안 일어난다"를 단계로 좁혀 어느 컴포넌트가 멈췄는지 짚을 수 있습니다. 배포가 막히는 지점마다 증상이 다르기 때문입니다.
[내 PC] kubectl apply -f pod.yaml
│
① kubectl → kube-apiserver:6443 (kubeconfig 로드 → HTTPS 요청)
│
② API server 검증: 인증 → 인가(RBAC) → Admission
│
③ etcd에 오브젝트 저장 (desired state 기록) → apiserver가 "created" 응답
│ ← 여기까지가 "선언 접수". 아직 컨테이너는 없음
│
④ controller-manager가 watch로 desired 감지
│ (Deployment → ReplicaSet → Pod 오브젝트 생성, nodeName은 아직 비어 있음)
│
⑤ scheduler가 nodeName 없는 Pod 감지 → 노드 선정 후 바인딩
│ (Pod.spec.nodeName에 배정 노드 기록)
│
⑥ 배정된 노드의 kubelet이 watch로 자기 Pod 감지 → 컨테이너 런타임에 생성 요청
│
⑦ kubelet이 상태를 API server에 보고 → etcd 갱신
▼
[결과] kubectl get pod → Running (⑦의 보고가 반영된 것)
각 단계가 무슨 일을 하고, 그 컴포넌트가 멈추면 어떤 증상인가:
| 단계 | 하는 일 | 이 단계가 막히면 |
|---|---|---|
| ① kubectl→apiserver | kubeconfig의 current-context로 서버 주소·인증 정보를 싣고 HTTPS 요청 전송 | apiserver 다운 → connection refused. kubectl 전 명령이 실패 |
| ② 인증·인가·Admission | apiserver가 요청자 신원 확인 → RBAC로 권한 확인 → Admission으로 검증·변형 | 권한 없음 → Forbidden. Admission 거부 → 정책 위반 메시지로 생성 자체가 반려 |
| ③ etcd 저장 | 검증 통과한 오브젝트를 etcd에 desired state로 기록 | etcd 다운 → 저장·조회 불가로 배포·변경 전부 실패. 단 이미 뜬 파드는 계속 실행 |
| ④ controller 감지 | controller-manager가 desired를 보고 ReplicaSet·Pod 오브젝트 생성 | controller-manager 다운 → Deployment는 만들어져도 Pod 오브젝트가 안 생김(레플리카 0에서 정지) |
| ⑤ scheduler 배정 | 노드 미배정 Pod를 골라 노드 선정 후 바인딩 | scheduler 다운 → Pod가 Pending에 영구 정체, NODE가 <none>에서 안 바뀜 |
| ⑥ kubelet 생성 | 배정 노드의 kubelet이 컨테이너 런타임에 생성 요청 | 그 노드 kubelet 다운 → 노드 NotReady, 그 노드 파드는 ContainerCreating에서 멈춤 |
| ⑦ kubelet 보고 | 컨테이너 상태·probe 결과를 apiserver에 주기 보고 | 보고 끊김 → 상태가 갱신 안 됨(오래된 채로 표시), 노드 NotReady 판정 |
즉 "배포가 안 된다"는 한 가지 증상이 아니라 이 7단계 중 어디서 끊겼는지의 문제입니다. kubectl get pods -n kube-system으로 apiserver·etcd·controller-manager·scheduler가 모두 1/1인지 먼저 보고(③~⑤), 파드가 Pending이면 scheduler(⑤)를, ContainerCreating에서 멈추면 그 노드의 kubelet(⑥)을 의심합니다. 증상이 어느 단계의 것인지 아는 것이 복구 순서를 정하는 출발점입니다.
실습: kubectl apply 흐름 추적하기
kubectl apply -f pod.yaml을 실행할 때 내부에서 무슨 일이 일어나는지 단계별로 확인합니다.
실습 1: 간단한 Pod 배포 및 컴포넌트 동작 확인
# 테스트용 Pod 정의
cat <<EOF > /tmp/test-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nginx
labels:
app: test
spec:
containers:
- name: nginx
image: nginx:alpine
resources:
requests:
memory: "32Mi"
cpu: "10m"
EOF
# Pod 생성
kubectl apply -f /tmp/test-pod.yaml
# pod/test-nginx created
# 스케줄링 확인 (어느 노드에 배치됐는지)
kubectl get pod test-nginx -o wide
# NAME READY STATUS NODE IP
# test-nginx 1/1 Running minikube 10.244.0.5
# 스케줄링 이벤트 확인
kubectl describe pod test-nginx | grep -A10 Events
# Events:
# Normal Scheduled ... Successfully assigned default/test-nginx to minikube
# Normal Pulling ... Pulling image "nginx:alpine"
# Normal Pulled ... Successfully pulled image
# Normal Created ... Created container nginx
# Normal Started ... Started container nginx
- kubectl get pods -n kube-system에서 READY 열 먼저 확인 — etcd, apiserver, scheduler, controller-manager 모두 1/1이면 Control Plane 정상, 하나라도 0/1이면 해당 컴포넌트 로그 즉시 확인
- RESTARTS 수치 기준: 0~2회는 초기 재시작으로 정상, 5회 이상이면 CrashLoopBackOff 진입 가능성 높음 — kubectl logs -n kube-system <pod> --previous 로 이전 로그 확인
- STATUS=Running이지만 Events에 Warning이 있으면 → kubectl describe pod <pod> -n kube-system으로 정확한 오류 메시지 확인 후 원인 컴포넌트 특정
실습 2: 컴포넌트별 상태 확인 명령어
# Control Plane 컴포넌트 상태 (kubeadm 기반)
kubectl get pods -n kube-system
# NAME READY STATUS RESTARTS
# coredns-787d4945fb-xxxxx 1/1 Running 0
# etcd-minikube 1/1 Running 0
# kube-apiserver-minikube 1/1 Running 0
# kube-controller-manager-minikube 1/1 Running 0
# kube-proxy-xxxxx 1/1 Running 0
# kube-scheduler-minikube 1/1 Running 0
# 컴포넌트 상태 요약 (구버전 방식)
kubectl get componentstatuses
# NAME STATUS MESSAGE
# scheduler Healthy ok
# controller-manager Healthy ok
# etcd-0 Healthy {"health":"true"}
# 노드 상태 상세
kubectl describe node minikube | grep -A20 Conditions
실습 3: 컴포넌트 간 통신 확인
# API Server 로그에서 요청 추적
kubectl logs -n kube-system kube-apiserver-minikube --tail=10
# Controller Manager가 ReplicaSet 관리하는 것 확인
# (Deployment 생성 시)
kubectl create deployment test-deploy --image=nginx:alpine --replicas=2
kubectl get replicaset # Controller Manager가 RS 생성
kubectl get pods # RS Controller가 Pod 생성
# 정리 (아래 DangerBlock 확인 후 실행)
Deployment 삭제 — 관리 중인 ReplicaSet과 Pod 전체 종료
안전한 실행 조건: kubectl config current-context 로 개발 클러스터인지 확인. kubectl get deployment 로 삭제 대상이 실습용 test-deploy인지 확인 후 실행하세요.
실행 전 반드시 확인
- kubectl config current-context 로 현재 컨텍스트가 개발 클러스터인지 확인
- kubectl get deployment 로 삭제 대상이 test-deploy(실습용)인지 이름 확인
kubectl delete deployment test-deploy위 항목을 모두 확인한 후 복사할 수 있습니다
kubectl delete deployment test-deploy
kubectl delete pod test-nginx
상황
kubectl get pods
# The connection to the server 192.168.49.2:8443 was refused
# - did you specify the right host or port?
kubectl이 완전히 응답하지 않습니다. 이는 kube-apiserver 문제입니다.
진단 순서
# 1. 클러스터가 살아있는지 확인 (minikube)
minikube status
# minikube
# type: Control Plane
# host: Stopped ← 이 경우 minikube가 꺼진 것
# kubelet: Stopped
# apiserver: Stopped
# 2. API Server Pod 직접 확인 (kubeadm 기반 클러스터)
# 마스터 노드에 SSH로 접속 후
sudo crictl ps | grep apiserver
# 비어있으면 API Server 컨테이너가 죽은 것
# 3. API Server 로그 확인
sudo crictl logs <apiserver-container-id>
# 4. Static Pod 설정 확인
ls /etc/kubernetes/manifests/
# kube-apiserver.yaml etcd.yaml kube-controller-manager.yaml kube-scheduler.yaml
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep -E "image:|port:"
# 5. etcd 상태 확인 (API Server가 etcd에 연결 못하면 시작 실패)
sudo ETCDCTL_API=3 etcdctl endpoint health \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
원인별 해결
| 원인 | 확인 방법 | 해결 |
|---|---|---|
| minikube 꺼짐 | minikube status | minikube start |
| API Server 크래시 | crictl logs apiserver | 설정 파일 오류 확인 후 수정 |
| etcd 연결 실패 | etcdctl endpoint health | etcd Pod 상태 확인 및 재시작 |
| 인증서 만료 | openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -dates | kubeadm certs renew all |
| 잘못된 kubeconfig | kubectl config view | ~/.kube/config 경로/권한 확인 |
핵심 원칙
API Server가 다운됐을 때 이미 실행 중인 Pod는 계속 동작합니다. kubelet이 로컬에서 관리하기 때문입니다. 하지만 새로운 배포, 스케일링, 조회, 삭제 등 모든 관리 작업이 불가능해집니다.
심화 — 다 살아있는데도 굼뜬 클러스터
심화: etcd 디스크 지연이 컨트롤 플레인 전체의 속도를 결정한다
컴포넌트가 모두 1/1 Running인데 배포가 느리고 kubectl이 간헐적으로 멈춘다면, 다음으로 의심할 곳은 etcd의 디스크입니다. etcd 건강은 살았나/죽었나의 이분법이 아니라 얼마나 빨리 쓰느냐의 문제이기 때문입니다.
- 모든 쓰기가 디스크를 기다립니다: etcd는 Raft 합의를 위해 각 쓰기를 WAL에 남기고
fsync로 디스크에 강제 동기화한 뒤에야 완료로 칩니다. apiserver의 모든 쓰기(파드 생성·상태 갱신·리스 갱신)가 이 fsync 뒤에 줄을 서므로, 디스크가 느리면 클러스터 전체가 함께 느려집니다. - 리더 리스가 흔들립니다: scheduler·controller-manager는 리더 선출(lease)로 단일 활성 인스턴스를 유지하는데, 이 리스 갱신도 결국 etcd 쓰기입니다. fsync가 밀리면 리스 갱신이 실패해 리더십이 계속 바뀌고(leader flapping), 그때마다 컨트롤러가 잠시 일을 멈춥니다.
- 공유 디스크가 흔한 원인입니다: 네트워크 스토리지나 다른 무거운 워크로드와 디스크를 나눠 쓰면 IO 경합으로 fsync가 수 ms에서 수십 ms로 치솟습니다. etcd에 전용 저지연 SSD가 권장되는 이유입니다.
즉 etcd가 Running이니 괜찮다는 판단은 착각입니다. etcd의 건강은 etcd_disk_wal_fsync_duration_seconds 같은 지연 지표로 봐야 하고, 이 값이 나쁘면 클러스터의 모든 제어 동작이 함께 느려집니다.
상황: 배포도 트래픽 변화도 없는데 며칠 전부터 kubectl apply가 몇십 초씩 걸리고 kubectl get도 가끔 타임아웃이 납니다. kubectl get pods -n kube-system으로 보면 etcd·apiserver 모두 1/1 Running이라 어디가 문제인지 잡히지 않습니다.
원인: etcd가 얹힌 노드의 디스크가 다른 워크로드와 공유되면서 IO 경합이 생겼습니다. etcd는 모든 쓰기를 WAL에 fsync한 뒤 완료 처리하는데, 디스크 응답이 느려지자 apiserver의 모든 쓰기가 그 뒤에 밀렸고 scheduler·controller-manager의 리더 리스 갱신까지 지연돼 리더십이 간헐적으로 바뀌었습니다.
진단: etcd 지표에서 etcd_disk_wal_fsync_duration_seconds의 p99가 정상(수 ms)보다 크게 치솟았는지, etcd_server_leader_changes_seen_total이 계속 증가하는지 확인합니다. etcd 파드 로그에는 apply request took too long·leader changed 메시지가 보입니다. 노드에서 iostat -x 1로 디스크 await·%util을 보고 경합을 일으키는 프로세스를 특정합니다.
해결: etcd 데이터 디렉터리를 전용 저지연 SSD(로컬 NVMe)로 옮기고, 같은 디스크에 무거운 IO 워크로드를 얹지 않습니다. 관리형 컨트롤 플레인이 아니라면 etcd를 별도 디스크로 분리하고, 재발 방지로 etcd_disk_wal_fsync_duration_seconds에 알람을 걸어 조용한 성능 저하를 조기에 잡습니다.
실무 시나리오: 신입 SRE의 첫 번째 클러스터 장애 대응
상황: 오전 10시, 팀장에게 연락이 왔습니다. "배포가 안 됩니다."
진단 체크리스트 (컴포넌트 기반)
# Step 1: kubectl 자체가 동작하는지
kubectl get nodes
# Step 2: 모든 컴포넌트 상태
kubectl get pods -n kube-system
# Step 3: 문제 있는 컴포넌트 로그
kubectl logs -n kube-system <problem-pod>
# Step 4: 노드 상태 (워커 노드 문제인지)
kubectl describe nodes | grep -E "Conditions|Ready"
# Step 5: 최근 이벤트 확인
kubectl get events --sort-by='.lastTimestamp' | tail -20
실제 케이스: 배포가 안 된다는 신고 → kubectl get pods -n kube-system 확인 → kube-scheduler-xxx 가 CrashLoopBackOff → kubectl logs로 로그 확인 → 스케줄러 설정 파일 오류 발견 → /etc/kubernetes/manifests/kube-scheduler.yaml 수정 → 자동 복구
아키텍처 지식이 없었다면: "배포가 왜 안 되지? API는 동작하는데..." 무한 미궁.
아키텍처를 알면: "스케줄러가 죽으면 Pod 배치가 안 된다. 스케줄러 상태 먼저 확인." 5분 안에 원인 파악.
Control Plane 컴포넌트 상태 확인
kubectl get pods -n kube-system예상 출력
NAME READY STATUS RESTARTS etcd-minikube 1/1 Running 0 kube-apiserver-minikube 1/1 Running 0 kube-controller-manager-minikube 1/1 Running 0 kube-scheduler-minikube 1/1 Running 0
테스트 파드 생성 및 스케줄링 이벤트 확인
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: test-nginx
spec:
containers:
- name: nginx
image: nginx:alpine
resources:
requests:
memory: "32Mi"
cpu: "10m"
EOF
kubectl describe pod test-nginx | grep -A10 Events예상 출력
Events: Normal Scheduled ... Successfully assigned default/test-nginx to minikube Normal Pulled ... Successfully pulled image Normal Started ... Started container nginx
파드 배치 노드 및 IP 확인
kubectl get pod test-nginx -o wide예상 출력
NAME READY STATUS NODE IP test-nginx 1/1 Running minikube 10.244.0.5
노드 컴포넌트 상태 요약 확인
kubectl get componentstatuses 2>/dev/null || kubectl get cs예상 출력
NAME STATUS MESSAGE
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}실습 리소스 정리
kubectl delete pod test-nginx예상 출력
pod "test-nginx" deleted
명령어·단축키 빠른 참조
이 모듈에서 클러스터 구조를 진단할 때 쓴 kubectl·crictl·etcdctl 명령을 "어느 컴포넌트부터 볼지" 순서로 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl cluster-info | API Server 주소·구동 확인 | 클러스터 접속 첫 점검 |
kubectl get nodes | 노드 Ready 상태 확인 | kubectl get nodes -o wide (IP·버전까지) |
kubectl get pods -n kube-system | 컨트롤 플레인 컴포넌트 상태 | ... | grep etcd / ... | grep kube-proxy |
kubectl get componentstatuses | scheduler·controller·etcd 헬스 요약 | kubectl get cs (축약) |
kubectl describe pod <pod> | 스케줄 실패 원인(이벤트) 확인 | ... | grep -A10 Events |
kubectl describe node <node> | 노드 Conditions·할당 리소스 확인 | ... | grep -A5 "Allocated resources" |
kubectl logs -n kube-system <pod> | 죽은 컴포넌트 로그 확인 | ... --tail=20 / CrashLoop 시 --previous |
kubectl get events | 최근 클러스터 이벤트 시간순 | kubectl get events --sort-by='.lastTimestamp' | tail -20 |
kubectl get pod <pod> -o wide | 배치 노드·Pod IP 확인 | 스케줄링 결과 검증 |
kubectl config current-context | 조작 대상 클러스터 확인 | 위험 명령 전 컨텍스트 점검 |
systemctl status kubelet | 노드 에이전트(kubelet) 상태 | journalctl -u kubelet -n 50 --no-pager (로그) |
crictl ps | 노드에서 컨테이너 직접 확인 | crictl logs <id> (kubelet 우회 디버깅) |
etcdctl endpoint health | etcd 응답·건강 확인 | ETCDCTL_API=3 etcdctl snapshot save backup.db (백업) |
minikube status | 로컬 클러스터 구동 확인 | minikube start (꺼졌으면 기동) |
관련 모듈로 더 깊이:
- 수십 개의 컨테이너를 스스로 관리하게 만드는 오케스트레이션 — 이런 컴포넌트 구조가 애초에 왜 필요해졌는지의 배경
- get, describe, logs, exec 필수 kubectl 명령어 10선 — 이 컴포넌트들과 실제로 상호작용하는 명령어들
- Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드 — 컴포넌트가 죽었을 때 클러스터 장애를 진단하는 법
다음 모듈 kubectl-basics에서는 클러스터와 상호작용하는 핵심 명령어들을 실습합니다. get, describe, logs, exec부터 apply, delete까지 실무에서 매일 쓰는 명령어를 체계적으로 마스터합니다.