운영 배포 직후 파드가 CrashLoopBackOff가 되었지만 팀원이 kubectl get, describe, logs의 차이를 몰라 같은 명령만 반복하고 있습니다. Kubernetes 장애 대응의 첫 5분은 대부분 kubectl 출력 읽기에서 결정됩니다. 기본 명령을 손에 익혀야 다음 단계의 진단이 가능합니다.
kubectl 기본 명령어
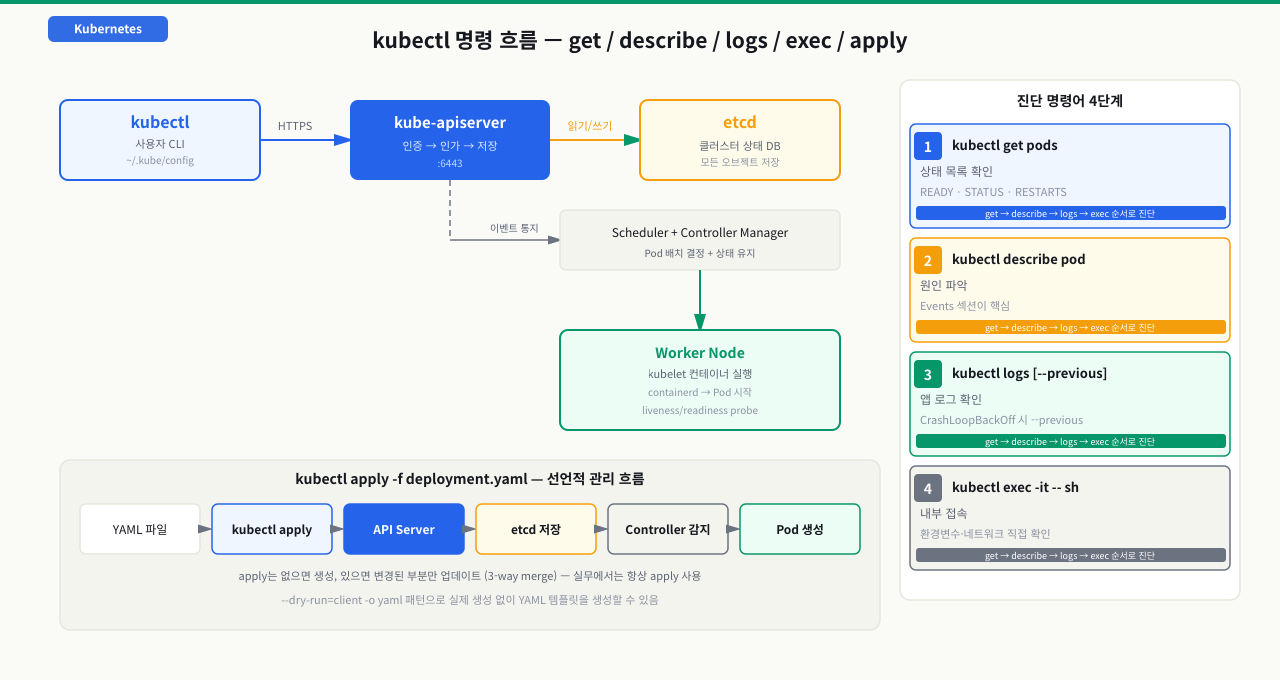
팀에 합류한 첫 날, 선임이 말했다. "Pod가 자꾸 죽는데, 로그 좀 봐줄 수 있어?" kubectl을 처음 본 신입은 화면을 뚫어져라 쳐다봤다. 명령어를 모르니 아무것도 할 수 없었다. Kubernetes는 아무리 강력한 플랫폼이어도, kubectl을 다루지 못하면 블랙박스일 뿐이다. kubectl은 Kubernetes를 조종하는 유일한 손이다. get으로 상태를 확인하고, describe로 원인을 찾고, logs로 앱 내부를 들여다보고, exec로 컨테이너 안으로 들어간다. 이 네 개 명령어만 능숙해도, 대부분의 Pod 장애는 10분 안에 원인을 찾을 수 있다.
매일 쓰는 kubectl 명령어를 체계적으로 익히고, 각 명령어가 장애 진단의 어느 단계에서 쓰이는지 파악합니다.
- 1kubectl get으로 리소스 목록을 조회하고 출력 형식(-o wide, -o yaml, -o json)을 조정할 수 있다
- 2kubectl describe의 이벤트와 상세 정보로 장애 원인을 파악할 수 있다
- 3kubectl logs(-f, --previous, --since)로 컨테이너 로그를 조회할 수 있다
- 4kubectl exec으로 실행 중인 컨테이너 내부에 접속할 수 있다
- 5kubectl apply/delete로 선언적 리소스를 관리할 수 있다
- 6--dry-run=client -o yaml 패턴으로 YAML 템플릿을 생성할 수 있다
minikube 사용 시: minikube start로 클러스터를 시작하세요. kubectl이 설치되어 있고 클러스터에 연결되어 있으면 바로 시작할 수 있습니다.
kubectl version --clientkubectl cluster-infokubectl config current-contextkubectl get allkubectl 명령 한 줄이 처리되는 법 — 클라이언트에서 응답까지 5단계
kubectl get pods를 치면 목록이 뜨고, 가끔은 Forbidden이나 connection refused가 뜹니다. 클러스터 아키텍처 모듈이 apiserver 안에서 벌어지는 일을 봤다면, 여기서는 내 PC의 kubectl이 그 요청을 만들어 보내고 응답을 그리기까지 클라이언트 쪽에서 무슨 일이 일어나는지를 봅니다. 이 흐름을 알면 같은 "안 된다"라도 context 문제인지, 인증 만료인지, 권한 거부인지, 연결 실패인지를 에러 메시지만으로 구분할 수 있습니다.
[내 PC] kubectl get pods
│
① kubeconfig 로드 → current-context 결정
│ (~/.kube/config에서 cluster·user·namespace 한 세트를 고름)
│
② API 엔드포인트·인증 재료 준비
│ (server URL, CA 인증서, client-cert 또는 token)
│
③ 명령을 REST 요청으로 조립 → 전송
│ (get pods → GET /api/v1/namespaces/<ns>/pods, TLS로 apiserver에)
│
④ apiserver 처리 → 응답 반환
│ (인증 → 인가(RBAC) → etcd 조회 → JSON 응답)
│
⑤ 응답 파싱 → 사람이 읽는 형식으로 출력
▼
[화면] NAME READY STATUS ... (-o wide/yaml/json으로 렌더링 형식만 바뀜)
각 단계가 무슨 일을 하고, 여기서 틀어지면 어떤 에러가 나는가:
| 단계 | 하는 일 | 여기서 틀어지면 |
|---|---|---|
| ① context 로드 | current-context의 cluster·user·namespace를 읽어 어느 클러스터·네임스페이스를 볼지 결정 | context가 다른 클러스터·네임스페이스를 가리킴 → 분명히 만든 리소스가 NotFound. 실제로는 다른 곳에 있음 |
| ② 인증 재료 준비 | server URL과 CA·client-cert·token을 로드 | 인증서·토큰 만료 → Unauthorized (401), You must be logged in to the server |
| ③ REST 요청 조립·전송 | 하위 명령을 HTTP 동사·경로로 변환해 TLS로 전송 | server 주소가 틀리거나 클러스터 다운 → connection refused 또는 타임아웃 |
| ④ apiserver 처리 | 인증 통과 후 RBAC로 권한 확인, etcd 조회 후 응답 | 권한 부족 → Forbidden (403) cannot list resource "pods" |
| ⑤ 응답 파싱·출력 | JSON 응답을 테이블·yaml·json으로 렌더링 | -o 형식 오타·jsonpath 오류 → 출력이 비거나 파싱 에러(요청 자체는 성공) |
즉 kubectl 에러는 대부분 "요청이 어느 단계에서 멈췄나"를 그대로 알려줍니다 — NotFound면 ①(context·네임스페이스)을, 401이면 ②(인증), refused·타임아웃이면 ③(연결), 403 Forbidden이면 ④(RBAC)를 봅니다. 안 될 때 가장 먼저 kubectl config current-context와 kubectl config view --minify로 지금 어느 클러스터·계정·네임스페이스로 말하고 있는지 확인하는 습관이 ①~②의 착각을 즉시 걷어냅니다.
kubectl get — 상태 확인의 시작점
장애 대응 첫 5분, 아무것도 모르는 상황에서 가장 먼저 해야 할 일은 현재 상태를 파악하는 것입니다. 파드가 Running인지, 몇 개가 Ready인지, 어느 노드에 배치됐는지를 빠르게 확인해야 다음 단계로 진단을 좁힐 수 있습니다. kubectl get은 클러스터의 리소스 목록과 기본 상태를 한눈에 보여주는 가장 자주 쓰이는 명령어입니다. -o wide, -o yaml, -l 플래그를 조합하면 IP, 노드, 레이블까지 원하는 정보를 골라 볼 수 있습니다. 이 CB에서는 일상적인 상태 확인부터 장애 시 빠른 파악까지 kubectl get의 핵심 사용 패턴을 다룹니다.
 확대
확대
기본 사용법
# Pod 목록
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# nginx-xxx 1/1 Running 0 5m
# broken-xxx 0/1 Error 3 2m
# 모든 네임스페이스
kubectl get pods -A # 또는 --all-namespaces
# NAMESPACE NAME READY STATUS RESTARTS
# kube-system coredns-xxx 1/1 Running 0
# default nginx-xxx 1/1 Running 0
# 특정 네임스페이스
kubectl get pods -n kube-system
# 여러 리소스 동시 조회
kubectl get pods,services,deployments
# 모든 리소스 타입 조회
kubectl get all
- kubectl get pods에서 STATUS 열을 먼저 확인 — Running이 아니면 CrashLoopBackOff/Pending/ImagePullBackOff 중 하나로, 각각 원인이 다름. kubectl describe pod <name>으로 Events에서 구체적 원인 파악
- RESTARTS 수치 기준: 3회 미만은 일시적 오류, 5회 이상이면 kubectl logs <pod> --previous 로 이전 크래시 로그 확인. 10회 이상이면 liveness probe 설정 또는 메모리 limits 검토 필요
- STATUS=Running이고 READY=0/1이면 → 컨테이너는 실행 중이지만 readinessProbe가 실패한 것. 서비스 트래픽이 차단된 상태로, kubectl describe pod에서 Readiness probe: 항목과 마지막 실패 이유 확인
출력 형식 조정
# 넓은 형식 (노드 IP 포함)
kubectl get pods -o wide
# NAME READY STATUS IP NODE
# nginx-xxx 1/1 Running 10.244.0.5 minikube
# YAML 형식 (전체 스펙 확인)
kubectl get pod nginx-xxx -o yaml
# JSON 형식 (스크립트에서 파싱 시)
kubectl get pods -o json
# 특정 필드만 추출
kubectl get pods -o jsonpath='{.items[*].metadata.name}'
# nginx-xxx broken-xxx
# 테이블 커스텀 컬럼
kubectl get pods -o custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName
# NAME STATUS NODE
# nginx-xxx Running minikube
라벨 필터링
# 라벨로 필터
kubectl get pods -l app=nginx
kubectl get pods -l app=nginx,env=prod
# 라벨 표시
kubectl get pods --show-labels
# 실시간 감시 (상태 변화 추적)
kubectl get pods -w # watch
kubectl describe — 장애 원인의 보물창고
파드가 Pending인데 kubectl get만 보면 이유를 알 수 없습니다. 노드 자원 부족인지, 이미지 pull 실패인지, Affinity 조건 미충족인지 구분이 되지 않아 엉뚱한 방향으로 디버깅을 시작하게 됩니다. kubectl describe의 Events 섹션은 스케줄러와 kubelet이 파드에 무슨 일을 했는지 타임라인으로 기록합니다. "왜 그 상태인가"를 알려주는 핵심 도구입니다. 이 CB에서는 kubectl describe의 출력 구조와, Events 섹션에서 장애 원인을 빠르게 읽어내는 방법을 다룹니다. 특히 Events 섹션이 핵심입니다.
 확대
확대
기본 사용법
kubectl describe pod <pod-name>
kubectl describe node <node-name>
kubectl describe deployment <deployment-name>
kubectl describe service <service-name>
describe 출력 구조 이해
kubectl describe pod nginx-xxx
# Name: nginx-xxx
# Namespace: default
# Priority: 0
# Node: minikube/192.168.49.2 ← 어느 노드에서 실행 중인지
# Start Time: ...
# Labels: app=nginx
# Status: Running
# IP: 10.244.0.5
#
# Containers:
# nginx:
# Image: nginx:alpine
# Port: 80/TCP
# State: Running
# Ready: True
# Restart Count: 0 ← 재시작 횟수 (높으면 문제)
# Limits: ...
# Requests: ...
# Liveness: http-get ... ← 헬스체크 설정
#
# Conditions:
# Type Status
# Initialized True
# Ready True ← Ready가 False면 문제
# ContainersReady True
# PodScheduled True
#
# Events: ← 여기가 핵심!
# Type Reason Age Message
# Normal Scheduled 5m Successfully assigned default/nginx-xxx to minikube
# Normal Pulling 5m Pulling image "nginx:alpine"
# Normal Pulled 4m Successfully pulled image
# Normal Created 4m Created container nginx
# Normal Started 4m Started container nginx
이벤트로 장애 진단
# 이미지 pull 실패 예시
# Events:
# Warning Failed 2m Failed to pull image "nginx:nonexistent": ...
# ImagePullBackOff
# 리소스 부족으로 스케줄 실패
# Events:
# Warning FailedScheduling ... 0/1 nodes available: 1 Insufficient memory.
# 네임스페이스 전체 이벤트 확인 (장애 시 빠른 파악)
kubectl get events --sort-by='.lastTimestamp'
kubectl get events --field-selector type=Warning # 경고만
kubectl logs, exec — 컨테이너 내부 들여다보기
파드가 Running인데 API가 500을 반환합니다. kubectl get과 kubectl describe에는 이상이 없고, 문제는 컨테이너 안에서 돌고 있는 애플리케이션에 있습니다. 이때 필요한 것이 kubectl logs와 kubectl exec입니다. logs는 앱이 stdout/stderr에 출력한 내용을 보여주고, exec는 컨테이너 내부로 직접 들어가 환경변수, 파일, 네트워크 연결을 확인합니다. CrashLoopBackOff 상황에서는 --previous 플래그로 죽기 직전 로그를 볼 수 있습니다. 이 CB에서는 로그 조회와 컨테이너 내부 접속의 핵심 패턴을 다룹니다.
kubectl logs — 앱 로그 확인
# 기본 로그 조회
kubectl logs <pod-name>
# 실시간 스트리밍
kubectl logs -f <pod-name>
# 마지막 N줄
kubectl logs --tail=100 <pod-name>
# 특정 시간 이후 로그
kubectl logs --since=1h <pod-name>
kubectl logs --since-time="2024-01-15T10:00:00Z" <pod-name>
# 이전 컨테이너 로그 (CrashLoopBackOff 시 필수)
kubectl logs --previous <pod-name>
# ← 현재 컨테이너가 죽기 전 로그를 봄
# 멀티 컨테이너 Pod에서 특정 컨테이너 로그
kubectl logs <pod-name> -c <container-name>
# 라벨 셀렉터로 여러 Pod 로그 동시
kubectl logs -l app=nginx --tail=50
kubectl exec — 컨테이너 내부 접속
# 인터랙티브 셸 접속
kubectl exec -it <pod-name> -- bash
kubectl exec -it <pod-name> -- sh # bash 없을 때
# 단일 명령어 실행 (셸 없이)
kubectl exec <pod-name> -- ls /app
kubectl exec <pod-name> -- cat /etc/nginx/nginx.conf
kubectl exec <pod-name> -- env | grep DB
# 멀티 컨테이너 Pod에서 특정 컨테이너
kubectl exec -it <pod-name> -c <container-name> -- bash
# 환경변수 확인 (설정 디버깅 시)
kubectl exec <pod-name> -- env
# 네트워크 확인 (내부에서 다른 서비스 접근 테스트)
kubectl exec -it <pod-name> -- curl http://other-service:8080/health
kubectl exec -it <pod-name> -- nslookup other-service
실습: 핵심 명령어 마스터하기
실습 1: 기본 CRUD 패턴
# 실습용 리소스 생성
cat <<EOF > /tmp/practice-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: practice-nginx
labels:
app: practice
env: dev
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
env:
- name: MY_ENV
value: "hello-k8s"
EOF
# 적용
kubectl apply -f /tmp/practice-pod.yaml
# pod/practice-nginx created
# 상태 확인
kubectl get pod practice-nginx -o wide
# 상세 확인
kubectl describe pod practice-nginx
# 라벨 필터링
kubectl get pods -l app=practice
실습 2: 로그와 exec 실습
# nginx 로그 확인
kubectl logs practice-nginx
# 실시간 로그 (다른 터미널에서 curl을 날리면서 확인)
kubectl logs -f practice-nginx
# 컨테이너 내부 접속
kubectl exec -it practice-nginx -- sh
# 내부에서 실행할 명령어들:
# ls /usr/share/nginx/html
# cat /etc/nginx/nginx.conf | head -20
# env | grep MY_ENV # MY_ENV=hello-k8s 확인
# exit
실습 3: --dry-run과 -o yaml 패턴
# 실제 생성 없이 YAML 생성 (템플릿 작성 시 유용)
kubectl run my-app --image=nginx:alpine --dry-run=client -o yaml
# apiVersion: v1
# kind: Pod
# metadata:
# creationTimestamp: null
# labels:
# run: my-app
# name: my-app
# spec:
# containers:
# - image: nginx:alpine
# name: my-app
# resources: {}
# ...
# 파일로 저장해서 수정 후 사용
kubectl run my-app --image=nginx:alpine --dry-run=client -o yaml > /tmp/my-app.yaml
# 기존 리소스의 YAML 추출 (현재 설정 확인)
kubectl get pod practice-nginx -o yaml > /tmp/practice-nginx-export.yaml
Pod 삭제 — 즉시 종료, 처리 중인 요청 강제 중단
안전한 실행 조건: kubectl config current-context 로 현재 컨텍스트가 minikube 또는 로컬 개발 클러스터인지 반드시 확인 후 실행하세요.
실행 전 반드시 확인
- kubectl config current-context 로 현재 컨텍스트가 개발 클러스터(minikube 등)인지 확인
- kubectl get pod practice-nginx 로 삭제 대상이 실습용 파드인지 이름 확인
kubectl delete pod practice-nginx위 항목을 모두 확인한 후 복사할 수 있습니다
# 정리
kubectl delete pod practice-nginx
실습 4: kubectl apply vs create 비교
cat <<EOF > /tmp/test-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: test-config
data:
key: "value1"
EOF
# apply: 없으면 생성, 있으면 업데이트
kubectl apply -f /tmp/test-cm.yaml
# configmap/test-config created
kubectl apply -f /tmp/test-cm.yaml
# configmap/test-config unchanged ← 이미 동일하면 변경 없음
# 내용 변경 후 재apply
sed -i 's/value1/value2/' /tmp/test-cm.yaml
kubectl apply -f /tmp/test-cm.yaml
# configmap/test-config configured ← 변경됨
# create는 이미 존재하면 에러
kubectl create -f /tmp/test-cm.yaml
# Error from server (AlreadyExists): configmaps "test-config" already exists
# 정리
kubectl delete configmap test-config
상황
kubectl logs my-pod
# Error from server (NotFound): pods "my-pod" not found
kubectl describe pod my-pod
# Error from server (NotFound): pods "my-pod" not found
분명히 배포했는데 Pod를 찾을 수 없다는 에러입니다.
진단: 네임스페이스 확인
# 1. 현재 컨텍스트의 네임스페이스 확인
kubectl config get-contexts
# CURRENT NAME CLUSTER AUTHINFO NAMESPACE
# * minikube minikube minikube (비어있으면 default)
# 2. 모든 네임스페이스에서 검색
kubectl get pods -A | grep my-pod
# production my-pod 1/1 Running 0 5m
# ↑ 'production' 네임스페이스에 있었음!
# 3. 네임스페이스를 명시해서 명령 실행
kubectl logs my-pod -n production
kubectl describe pod my-pod -n production
원인과 해결
| 원인 | 해결 |
|---|---|
| 다른 네임스페이스에 배포됨 | -n <namespace> 플래그 추가 |
| Pod가 실제로 없음 (배포 실패) | kubectl get events로 배포 오류 확인 |
| 이름 오타 | kubectl get pods -A | grep <partial-name> |
| 이미 종료되어 삭제됨 | Job/CronJob이면 정상 (--previous 로그 확인) |
기본 네임스페이스 변경 (자주 쓰는 네임스페이스가 있을 때)
# 현재 컨텍스트의 기본 네임스페이스 변경
kubectl config set-context --current --namespace=production
# 이후 -n 생략 가능
kubectl get pods # production 네임스페이스가 기본
# 다시 default로
kubectl config set-context --current --namespace=default
핵심 교훈: NotFound 에러의 80%는 네임스페이스 문제입니다. 항상 -A 플래그로 모든 네임스페이스를 먼저 확인하세요.
실습용 파드 생성 및 상태 확인
kubectl run practice-nginx --image=nginx:alpine --labels=app=practice
kubectl get pod practice-nginx -o wide예상 출력
NAME READY STATUS RESTARTS AGE IP practice-nginx 1/1 Running 0 ...
describe로 이벤트 확인
kubectl describe pod practice-nginx | grep -A 10 Events예상 출력
Events: Type Reason Age Message Normal Scheduled ... Successfully assigned
컨테이너 로그 조회
kubectl logs practice-nginx --tail=20예상 출력
/docker-entrypoint.sh: Configuration complete; ready for start up
컨테이너 내부 명령어 실행
kubectl exec practice-nginx -- nginx -v
kubectl exec practice-nginx -- ls /usr/share/nginx/html예상 출력
nginx version: nginx/ index.html 50x.html
dry-run으로 YAML 생성 후 파드 정리
kubectl run my-app --image=nginx:alpine --dry-run=client -o yaml | head -10
kubectl delete pod practice-nginx예상 출력
apiVersion: v1 kind: Pod pod "practice-nginx" deleted
심화 — exec가 통하지 않을 때
심화: 셸 없는 이미지와 임시(ephemeral) 디버그 컨테이너
kubectl exec는 만능처럼 보이지만, 정작 프로덕션 파드에 들어가려 할 때 막히는 경우가 많습니다. 그 이유와 우회로를 알아야 실전 디버깅이 가능합니다.
- exec는 컨테이너 안에 있는 바이너리를 빌려 쓰는 것입니다: kubectl exec는 대상 컨테이너의 프로세스 네임스페이스 안에서 지정한 실행 파일(sh/bash/ls)을 새 프로세스로 실행합니다. 그 바이너리가 이미지에 없으면 executable file not found가 납니다.
- 요즘 프로덕션 이미지엔 셸이 일부러 없습니다: 보안과 크기를 위해 distroless(gcr.io/distroless)나 scratch 기반으로 빌드하면 sh는 물론 ls, cat조차 없습니다. exec -- sh, exec -- bash 둘 다 실패하는 건 잘못 배포된 게 아니라 의도된 슬림 이미지라는 신호입니다.
- 그래서 exec 대신 임시(ephemeral) 컨테이너를 붙입니다:
kubectl debug -it <pod> --image=busybox --target=<container>는 도구가 든 컨테이너를 실행 중인 파드에 추가합니다. --target으로 대상 컨테이너의 프로세스 네임스페이스를 공유하면, 앱 이미지는 건드리지 않고 그 프로세스와 /proc를 통한 파일시스템까지 들여다볼 수 있습니다. 파드 재시작도 필요 없습니다.
정리하면 exec는 컨테이너가 스스로 진단 도구를 품고 있어야 통합니다. 도구가 없는 슬림 이미지는 exec가 아니라 ephemeral 디버그 컨테이너를 표준으로 삼아야 합니다.
상황: 프로덕션 파드가 500을 내서 안에 들어가 설정 파일을 보려고 kubectl exec -it -- sh를 실행했더니 not found. bash로 바꿔도 마찬가지입니다. kubectl get pod로 보면 파드는 1/1 Running으로 멀쩡합니다.
원인: 이미지가 distroless나 scratch 기반이라 셸과 기본 유틸리티가 아예 들어 있지 않습니다. exec는 컨테이너 안의 바이너리를 실행하는 것이라, 없는 sh를 실행할 수 없어 executable file not found가 납니다. 파드가 Running이라는 사실과 셸 유무는 무관합니다.
진단: kubectl get pod <pod> -o jsonpath로 컨테이너 image를 확인하거나 kubectl describe pod의 Image 필드를 봅니다. distroless/scratch 계열이면 확정입니다. exec -- ls마저 not found면 셸뿐 아니라 기본 유틸리티도 없는 것입니다.
해결: kubectl debug -it <pod> --image=busybox:1.36 --target=<container>로 busybox를 임시 컨테이너로 얹고, 그 안에서 ps, wget, cat /proc/1/root/... 로 대상 컨테이너의 프로세스와 파일을 진단합니다. --target으로 프로세스 네임스페이스를 공유해야 대상 컨테이너 내부가 보입니다. 앱 로그와 환경변수는 컨테이너 밖에서 kubectl logs와 kubectl get pod -o yaml로 확인하면 됩니다. 프로덕션 이미지는 셸이 없는 게 정상이므로, 디버깅 표준을 exec에서 ephemeral 컨테이너로 옮기는 것이 근본 대응입니다.
실무 시나리오: kubectl 장애 대응 플로우
팀장: "API 서버에서 500 에러가 납니다."
1단계: 빠른 상태 파악 (30초)
kubectl get pods -n production
# NAME READY STATUS RESTARTS AGE
# api-server-xxx 0/1 CrashLoopBackOff 5 10m
2단계: 이벤트로 원인 파악 (1분)
kubectl describe pod api-server-xxx -n production | grep -A20 Events
# Events:
# Warning BackOff ... Back-off restarting failed container
3단계: 로그로 앱 오류 확인 (2분)
# 현재 컨테이너 로그
kubectl logs api-server-xxx -n production --tail=50
# Error: Cannot connect to database at postgres:5432
# 이전 컨테이너 로그 (죽기 직전)
kubectl logs api-server-xxx -n production --previous | tail-20
4단계: 내부 진단 (필요시)
# DB 연결 확인
kubectl exec -it api-server-xxx -n production -- nc -zv postgres 5432
# postgres (5432:) open ← 연결 가능
# postgres (5432:) refused ← DB 다운
# 환경변수 확인
kubectl exec api-server-xxx -n production -- env | grep DB
총 소요 시간: 5분 이내에 "DB 연결 문제" 파악 완료.
kubectl get → describe → logs → exec 이 4단계 흐름이 K8s 장애 진단의 표준 패턴입니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 kubectl 기본 명령을 자주 쓰는 플래그·조합과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl get | 리소스 목록·상태(진단 시작점) | kubectl get pods -A -o wide, -l app=nginx, -w(watch) |
kubectl get -o | 출력 형식 조정·필드 추출 | -o yaml, -o jsonpath='{.items[*].metadata.name}', -o custom-columns=... |
kubectl describe | Events·Conditions로 원인 파악 | kubectl describe pod X | grep -A15 Events |
kubectl logs | 앱 stdout/stderr 확인 | kubectl logs -f X --tail=100, --since=1h |
kubectl logs --previous | 크래시 직전 로그(CrashLoopBackOff) | kubectl logs X --previous |
kubectl exec -it | 실행 중 컨테이너 셸 접속 | kubectl exec -it X -- sh (bash 없을 때), -c <container> |
kubectl exec -- (단일) | 셸 없이 명령 실행 | kubectl exec X -- env | grep DB, -- nc -zv postgres 5432 |
kubectl apply / create | 선언적 관리 / 일회성 생성 | kubectl apply -f pod.yaml (create는 존재 시 AlreadyExists) |
--dry-run=client -o yaml | 배포 없이 YAML 템플릿 생성 | kubectl run app --image=nginx --dry-run=client -o yaml > app.yaml |
kubectl config | 컨텍스트·기본 네임스페이스 변경 | kubectl config set-context --current --namespace=production |
-n / -A | 네임스페이스 지정 / 전체 | kubectl get pods -n kube-system, kubectl get pods -A | grep X |
관련 모듈로 더 깊이:
- Pending, Running, Failed, CrashLoopBackOff 생명주기 분석 — get/describe로 본 Pod 상태가 어떤 상태 머신을 거쳐 만들어지는지의 원리
- Kubernetes 장애 원인을 빠르게 격리하는 트러블슈팅 가이드 — get → describe → logs → exec 4단계를 실제 장애 격리 절차로 확장하는 법
- 컨테이너 실행 옵션과 네임스페이스 작동 원리 — kubectl 이전, 컨테이너를 직접 띄우고 exec·logs로 다루는 Docker CLI의 기본기 (Docker 트랙)
다음 모듈 pod-lifecycle에서는 Pod가 Pending → Running → Succeeded/Failed로 전환되는 상태 머신을 이해하고, CrashLoopBackOff와 ImagePullBackOff 같은 실무에서 자주 만나는 에러를 체계적으로 진단합니다.