새벽 온콜 알림이 울렸고 결제 서비스 파드가 여러 Namespace에서 동시에 실패하고 있습니다. 명령어를 떠올리는 데 시간을 쓰면 원인보다 증상만 만지게 됩니다. Kubernetes 트러블슈팅은 이벤트, 로그, 리소스, 노드 상태를 정해진 순서로 좁혀가는 훈련입니다.
Kubernetes 트러블슈팅
프로덕션 Kubernetes 클러스터에서 파드 5개가 갑자기 Evicted 상태가 됐습니다. 무엇부터 해야 할까요. 무작정 파드를 삭제하고 재시작하면 같은 노드에 다시 스케줄되고 또 Evict됩니다. Kubernetes 장애는 대부분 패턴이 있습니다. Pending이면 스케줄링 실패, CrashLoopBackOff면 앱 시작 실패, OOMKilled면 메모리 초과, Evicted면 노드 자원 고갈 신호입니다. 이 패턴을 알면 kubectl describe → logs → events → exec 순서의 체계적 진단으로 대부분의 장애를 30분 안에 해결할 수 있습니다. 이 모듈은 실제 장애 시나리오별 진단 명령과 해결 절차를 담습니다. 이 모듈을 마치면 주요 파드 상태 이상을 혼자서 진단하고 복구할 수 있습니다.
- 1kubectl describe, logs, events, exec 순으로 체계적 진단을 수행할 수 있다
- 2리소스 부족, Affinity 미충족, PVC 미바인딩 등 Pending 원인을 분석할 수 있다
- 3앱 오류, 설정 오류, 리소스 한도 등 CrashLoopBackOff 원인을 진단할 수 있다
- 4메모리 limits 설정과 메모리 누수 패턴으로 OOMKilled를 진단할 수 있다
- 5노드 자원 압박, QoS 클래스, eviction 정책으로 Evicted를 진단할 수 있다
- 6노드 디스크 풀로 운영 파드가 전체 Evicted된 상황을 복구할 수 있다
kubectl get pods -A --field-selector=status.phase!=Runningkubectl get pods -A | grep -v -E 'Running|Completed'kubectl top nodeskubectl get events -A --sort-by='.lastTimestamp' | tail -30kubectl get deployment metrics-server -n kube-system체계적 진단 순서
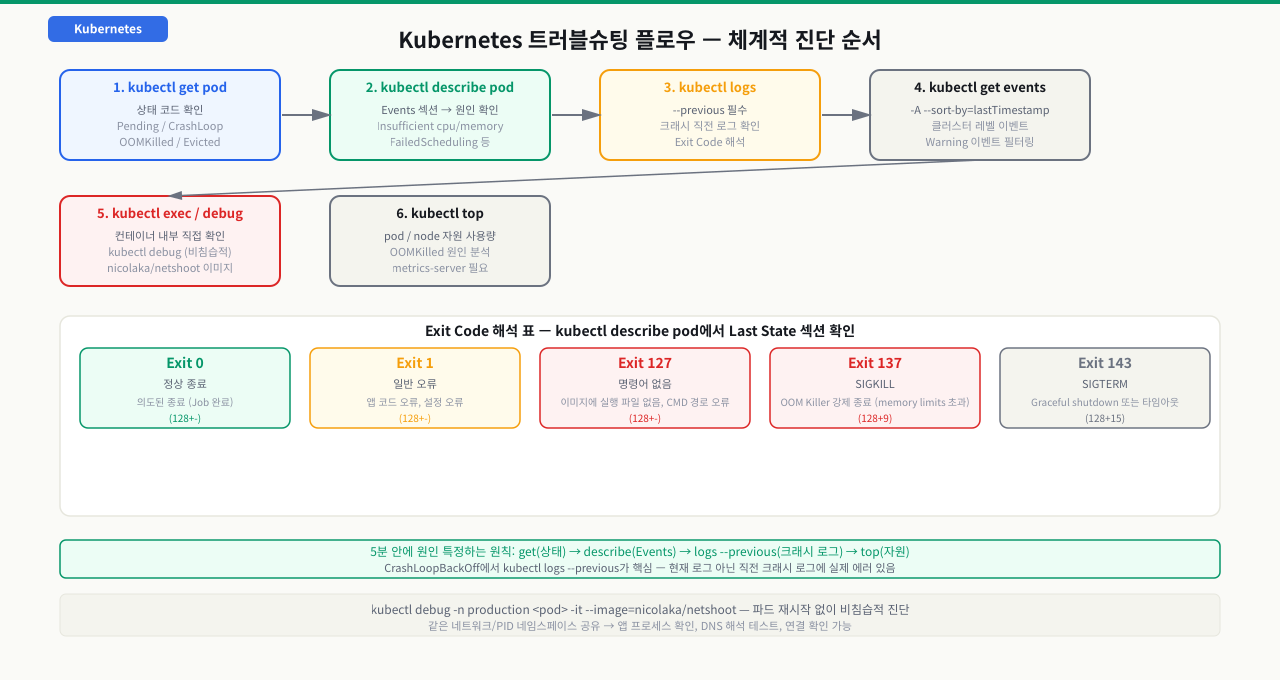
Kubernetes 장애 대응은 정보를 수집하는 순서가 있습니다. 무작정 재시작부터 하면 원인을 알 수 없게 됩니다.
 확대
확대
장애 대응 순서:
1. kubectl get pod → 상태 코드 확인 (Pending/CrashLoop/OOMKilled/Evicted)
2. kubectl describe pod → Events 섹션에서 구체적 원인 확인
3. kubectl logs --previous → 크래시 직전 로그 확인
4. kubectl get events → 클러스터 레벨 이벤트
5. kubectl exec / kubectl debug → 컨테이너 내부 직접 확인
6. kubectl top pod/node → 자원 사용량 확인
Exit Code 해석 — 숫자로 원인을 알 수 있다
새벽 장애 대응 중 파드가 계속 재시작되는데 로그에는 아무것도 없고 상태 코드만 보입니다. "Exit Code 137"이나 "Exit Code 1"을 처음 마주하는 엔지니어는 이 숫자가 무엇을 의미하는지 몰라 로그만 반복해서 확인합니다. Exit Code는 파드가 왜 종료됐는지 알려주는 첫 번째 단서이며, 숫자마다 가리키는 원인이 다릅니다. 137이면 메모리 초과, 1이면 앱 오류, 127이면 실행 파일 없음입니다. 이 CB에서는 주요 Exit Code의 의미와 각 코드에 따른 진단 방향을 다룹니다. kubectl describe pod의 Last State 또는 State에서 확인할 수 있습니다.
 확대
확대
kubectl describe pod <pod-name> | grep -A5 "Last State"
# Last State: Terminated
# Reason: OOMKilled
# Exit Code: 137
# Started: Mon, 15 Jan 2024 02:31:22 +0000
# Finished: Mon, 15 Jan 2024 02:31:44 +0000
| Exit Code | 의미 | 주요 원인 |
|---|---|---|
| 0 | 정상 종료 | 의도된 종료 (Job 완료 등) |
| 1 | 일반 오류 | 앱 코드 오류, 설정 오류 |
| 2 | 쉘 에러 | 잘못된 시작 명령어 |
| 127 | 명령어 없음 | 이미지에 실행 파일 없음, CMD 경로 오류 |
| 128+N | 시그널 N으로 종료 | - |
| 137 | SIGKILL (128+9) | OOM Killer 또는 외부 강제 종료 |
| 143 | SIGTERM (128+15) | Graceful shutdown (정상) 또는 타임아웃 |
# Exit Code 137 확인 방법
kubectl get pod <pod-name> -o jsonpath='{.status.containerStatuses[0].lastState.terminated.exitCode}'
Pending 상태 진단
파드가 Pending이면 컨테이너가 아직 시작되지 않은 것입니다. 스케줄러가 적합한 노드를 찾지 못한 상태입니다.
# 1단계: Events에서 원인 확인
kubectl describe pod <pod-name> -n <namespace>
# Events 섹션 핵심 메시지들:
# 원인 1: 리소스 부족
# Warning FailedScheduling 0/3 nodes are available:
# 1 Insufficient cpu, 2 Insufficient memory.
# 원인 2: Node Affinity 미충족
# Warning FailedScheduling 0/3 nodes are available:
# 3 node(s) didn't match Pod's node affinity/selector.
# 원인 3: PVC 미바인딩
# Warning FailedScheduling 0/3 nodes are available:
# 3 pod has unbound immediate PersistentVolumeClaims.
# 원인 4: Taint/Toleration 불일치
# Warning FailedScheduling 0/3 nodes are available:
# 3 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }.
- kubectl describe pod <name>의 Events 섹션을 먼저 확인 — "FailedScheduling" 메시지가 있으면 스케줄링 문제이고 그 뒤 문장이 정확한 원인("Insufficient cpu", "node(s) had taint" 등)
- Events 메시지 기준: "0/N nodes are available"에서 N=클러스터 총 노드 수. 괄호 안 숫자 합계가 N과 맞으면 모든 노드를 검사했고 아무 곳도 조건을 충족 못 한 것
- "Insufficient cpu"이고 kubectl top nodes로 CPU 여유가 있어 보이면 → requests 값이 limits보다 높게 설정된 것. kubectl describe node에서 Allocated resources의 Requests 항목으로 실제 할당 현황 확인
리소스 부족 해결
# 노드별 할당 가능 자원 확인
kubectl describe nodes | grep -A5 "Allocated resources"
# 출력:
# Allocated resources:
# (Total limits may be over 100 percent, i.e., overcommitted.)
# Resource Requests Limits
# -------- -------- ------
# cpu 1850m/2 3500m/2 ← 거의 꽉 찬 상태
# memory 1.8Gi/4Gi 3.2Gi/4Gi
# 파드별 리소스 요청량 확인
kubectl get pods -n <namespace> -o json | \
jq '.items[] | {name: .metadata.name, cpu: .spec.containers[0].resources.requests.cpu, mem: .spec.containers[0].resources.requests.memory}'
# 해결 1: 파드의 resources.requests 줄이기 (실제 사용량 기반)
kubectl top pod -n <namespace> # 실제 사용량 확인 후 requests 조정
# 해결 2: 노드 추가 (클러스터 오토스케일러 또는 수동)
# 해결 3: 다른 네임스페이스의 불필요한 파드 정리
PVC 미바인딩 해결
운영 리소스 직접 패치
안전한 실행 조건: 변경 내용을 코드에 반영할 계획이 있고 영향 범위를 검토했을 때만 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl patch pvc payment-data -n <namespace>위 항목을 모두 확인한 후 복사할 수 있습니다
# PVC 상태 확인
kubectl get pvc -n <namespace>
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS
# payment-data Pending - - - fast-ssd ← 문제
# PVC 상세 확인
kubectl describe pvc payment-data -n <namespace>
# Events:
# Warning ProvisioningFailed storageclass.storage.k8s.io "fast-ssd" not found
# → StorageClass 이름 오류
# 사용 가능한 StorageClass 확인
kubectl get storageclass
# PVC YAML 수정 (올바른 StorageClass로)
kubectl patch pvc payment-data -n <namespace> \
--type=json \
-p='[{"op":"replace","path":"/spec/storageClassName","value":"standard"}]'
CrashLoopBackOff 진단
컨테이너가 시작됐다가 즉시 종료되는 것을 반복합니다. Kubernetes가 재시작 간격을 점점 늘리면서 BackOff 상태가 됩니다.
# 현재 크래시 중인 컨테이너 로그
kubectl logs <pod-name> -n <namespace>
# 핵심: 이전 크래시 컨테이너 로그 (실제 오류 메시지는 여기에)
kubectl logs <pod-name> -n <namespace> --previous
# 재시작 횟수 확인
kubectl get pod <pod-name> -n <namespace> \
-o jsonpath='{.status.containerStatuses[0].restartCount}'
# 10 이상이면 심각한 반복 크래시
주요 CrashLoopBackOff 원인별 해결
# 원인 1: 설정 오류 (환경변수, ConfigMap, Secret)
kubectl logs <pod-name> --previous | grep -i "error\|fatal\|panic"
# 예: "Error: DB_HOST environment variable is required"
# 환경변수 확인
kubectl describe pod <pod-name> | grep -A20 "Environment:"
# Secret/ConfigMap 존재 확인
kubectl get secret db-credentials -n <namespace>
kubectl get configmap app-config -n <namespace>
# 원인 2: 이미지 실행 파일 없음 (CMD/ENTRYPOINT 오류)
# Exit Code: 127
kubectl describe pod <pod-name> | grep -E "Exit Code|Command|Args"
# 이미지 확인 (임시 컨테이너로)
kubectl run debug-img --image=payment:2.0.0 --restart=Never \
--command -- /bin/sh -c "ls /app && cat /app/start.sh"
# 원인 3: 포트 충돌 또는 바인딩 실패
kubectl logs <pod-name> --previous | grep "bind\|address already in use"
# 원인 4: 리소스 한도 초과로 즉시 OOMKilled
kubectl describe pod <pod-name> | grep -E "OOMKilled|Exit Code: 137"
컨테이너 내부 직접 진단
# 크래시 직전 컨테이너를 잡기 위한 debug 방법
# 방법 1: command 오버라이드로 sleep으로 시작 (YAML 수정 필요)
# command: ["sleep", "3600"] # 앱 대신 sleep으로 시작해서 exec로 내부 확인
# 방법 2: kubectl debug (비침습적)
kubectl debug -n <namespace> <pod-name> \
-it --image=busybox --copy-to=debug-pod \
--container=app -- sh
# 방법 3: 에러 재현을 위한 임시 파드
kubectl run test-pod -n <namespace> \
--image=payment:2.0.0 \
--restart=Never \
--env="DB_HOST=postgres.production.svc.cluster.local" \
--env="DB_PASSWORD=$(kubectl get secret db-creds -o jsonpath='{.data.password}' | base64 -d)" \
-- /bin/sh -c "/app/start.sh; echo exit_code=$?"
kubectl logs test-pod
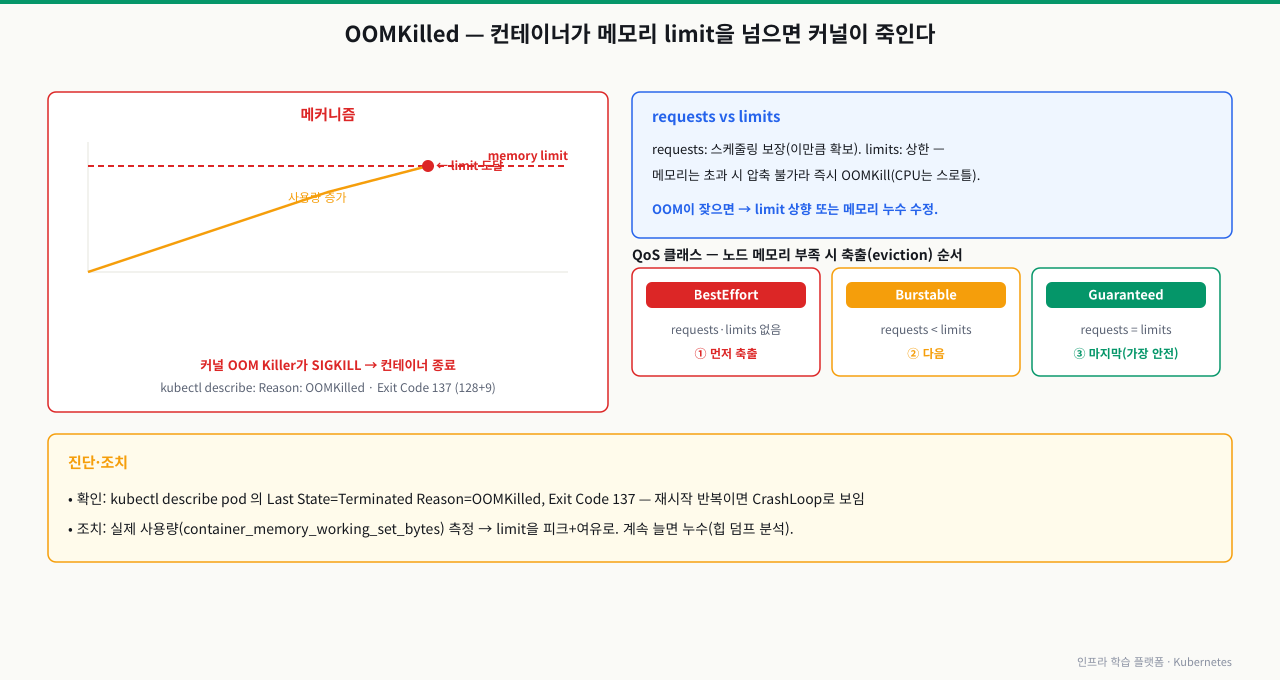
OOMKilled 진단과 메모리 최적화
 확대
확대
# OOMKilled 확인
kubectl describe pod <pod-name> | grep -A3 "OOM\|137"
# 실제 메모리 사용량 측정 (최소 24시간 관찰 권장)
kubectl top pod <pod-name> -n <namespace> --containers
# 과거 메모리 사용 추이 (Prometheus 쿼리)
# container_memory_working_set_bytes{pod="payment-xxx", namespace="production"}
# 메모리 limits 확인
kubectl get pod <pod-name> -n <namespace> \
-o jsonpath='{.spec.containers[0].resources.limits.memory}'
메모리 Limits 조정
# 측정값 기반으로 limits 상향 조정
# 실제 최대 사용량의 130% 정도를 limits로 설정
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment
spec:
template:
spec:
containers:
- name: payment
resources:
requests:
memory: "256Mi" # 평균 사용량
cpu: "100m"
limits:
memory: "512Mi" # 최대 사용량 × 1.3
cpu: "500m"
# 메모리 누수 패턴 감지 (시간에 따라 계속 증가하는지)
# 정상: 사용량이 일정 수준 유지 또는 GC 후 감소
# 누수: 사용량이 계속 우상향, GC 후에도 감소하지 않음
# Java 애플리케이션 메모리 덤프 (OOM 전에)
kubectl exec -n production <pod-name> -- \
jmap -dump:format=b,file=/tmp/heap.hprof $(pgrep java)
kubectl cp <pod-name>:/tmp/heap.hprof ./heap.hprof -n production
# Node.js 힙 스냅샷
kubectl exec -n production <pod-name> -- \
kill -SIGUSR2 $(pgrep node)
# inspector에서 heapsnapshot 파일 확인
# Python 메모리 프로파일링
kubectl exec -n production <pod-name> -- \
python -c "
import tracemalloc
tracemalloc.start()
# ... 앱 실행 ...
snapshot = tracemalloc.take_snapshot()
for stat in snapshot.statistics('lineno')[:10]:
print(stat)
"
Evicted 상태 진단
kubelet이 노드 자원 압박(메모리, 디스크, PID) 시 파드를 강제 종료합니다.
# Evicted 파드 전체 확인
kubectl get pods -A | grep Evicted
kubectl get pods -A --field-selector=status.phase=Failed | grep Evicted
# Eviction 이유 확인
kubectl describe pod <evicted-pod-name> | grep -A5 "Message"
# Message: The node was low on resource: ephemeral-storage.
# Threshold quantity: 10%, available: 1152Ki.
# 또는:
# Message: The node had condition: [MemoryPressure].
# 또는:
# Message: The node had condition: [DiskPressure].
# 노드 컨디션 확인
kubectl describe nodes | grep -A5 "Conditions:"
# MemoryPressure True → 메모리 압박
# DiskPressure True → 디스크 압박
# PIDPressure True → 프로세스 수 압박
Evicted 파드 정리
# Evicted 파드는 Running이 아니므로 수동 정리 필요
# (새 파드는 자동 생성되지만 Evicted 파드 객체는 남음)
# Evicted 파드 일괄 삭제
kubectl get pods -A --field-selector=status.phase=Failed \
-o json | \
jq -r '.items[] | select(.status.reason=="Evicted") | "\(.metadata.namespace) \(.metadata.name)"' | \
while read ns pod; do kubectl delete pod "$pod" -n "$ns"; done
# 한 줄 명령 버전
kubectl get pods --all-namespaces -o json | \
jq '.items[] | select(.status.phase=="Failed" and .status.reason=="Evicted") | .metadata | "\(.namespace) \(.name)"' -r | \
xargs -L1 bash -c 'kubectl delete pod $2 -n $1' _
트러블슈팅
월요일 아침, 모든 프로덕션 파드가 Evicted 상태가 됩니다. 새로 시작되는 파드도 곧 Evicted됩니다.
1단계: 상황 파악
# 전체 파드 상태 확인
kubectl get pods -n production
# NAME READY STATUS RESTARTS
# payment-7d9b4c8f6-xxx 0/1 Evicted 0
# order-6c8b9d7f5-yyy 0/1 Evicted 0
# catalog-5b7a8c6e4-zzz 0/1 Evicted 0
# Eviction 이유 확인
kubectl describe pod payment-7d9b4c8f6-xxx -n production | grep Message
# Message: The node was low on resource: ephemeral-storage.
# 노드 상태 확인
kubectl describe nodes worker-1 | grep -E "DiskPressure|ephemeral"
# DiskPressure True → 디스크 압박 활성화
2단계: 디스크 사용량 원인 파악
# 노드에 직접 접근해서 디스크 사용량 확인
kubectl debug node/worker-1 -it --image=busybox -- df -h
# /dev/sda1 100G 98G 0 100% / ← 가득 참!
# 가장 많이 차지하는 디렉토리 찾기
kubectl debug node/worker-1 -it --image=busybox -- \
du -sh /host/var/lib/docker/*
# 48G /host/var/lib/docker/overlay2 ← 컨테이너 레이어
# 또는 nsenter로 노드 파일시스템 직접 조회
kubectl debug node/worker-1 -it --image=busybox -- \
du -sh /host/var/log/pods/
# 32G /host/var/log/pods/ ← 로그 파일이 문제!
3단계: 로그 파일 정리
# 어느 파드 로그가 가장 큰지 확인
kubectl debug node/worker-1 -it --image=busybox -- \
find /host/var/log/pods -name "*.log" \
-exec ls -lh {} \; | sort -k5 -rh | head -10
# 출력 예시:
# -rw-r--r-- 1 root root 28G /host/var/log/pods/production_payment-.../payment/0.log
# 로그 로테이션 없이 한 파드가 28GB 사용 중
# 즉시 해당 로그 파일 비우기 (truncate)
kubectl debug node/worker-1 -it --image=busybox -- \
truncate -s 0 /host/var/log/pods/production_payment-.../payment/0.log
# 오래된 종료 파드의 로그 삭제
kubectl debug node/worker-1 -it --image=busybox -- \
find /host/var/log/pods -name "*.log" -mtime +7 -delete
# Docker/containerd 이미지 캐시 정리
# (SSH 접근 가능한 경우)
ssh worker-1 "docker system prune -f && docker image prune -a -f"
# 또는 crictl (containerd)
ssh worker-1 "crictl rmi --prune"
4단계: DiskPressure 해제 확인
위험한 kubectl 작업
안전한 실행 조건: 실습 환경이거나 영향 범위와 롤백 방법을 확인한 뒤에만 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl delete pods -n production --field-selector=status.phase=Failed위 항목을 모두 확인한 후 복사할 수 있습니다
# 노드 컨디션 회복 확인 (수 분 소요)
watch kubectl describe node worker-1 | grep DiskPressure
# DiskPressure False ← 해제되면 파드 재스케줄 시작
# 새 파드 시작 확인
kubectl get pods -n production -w
# 여전히 Evicted 파드 객체 정리
kubectl delete pods -n production --field-selector=status.phase=Failed
5단계: 재발 방지
# 컨테이너 로그 크기 제한 (kubelet 설정 또는 Docker daemon.json)
# /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m", # 컨테이너당 로그 최대 100MB
"max-file": "3" # 최대 3개 파일 보관
}
}
# ephemeral-storage limits 설정 (파드 스펙)
resources:
requests:
ephemeral-storage: "1Gi"
limits:
ephemeral-storage: "5Gi" # 이 이상 사용하면 Evict
# Eviction 임계값 조정 (kubelet 설정)
# /var/lib/kubelet/config.yaml
evictionHard:
memory.available: "200Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
evictionSoft:
memory.available: "300Mi"
nodefs.available: "15%"
evictionSoftGracePeriod:
memory.available: "1m30s"
nodefs.available: "2m"
고급 진단 도구
kubectl debug로 프로덕션 파드 비침습 진단
# 실행 중인 파드 옆에 디버그 컨테이너 붙이기 (파드 재시작 없음)
kubectl debug -n production <pod-name> \
-it --image=nicolaka/netshoot \
--target=payment # 같은 PID 네임스페이스 공유
# 디버그 컨테이너에서:
# - 같은 네트워크 네임스페이스 (네트워크 연결 테스트 가능)
# - 같은 PID 네임스페이스 (ps aux로 앱 프로세스 확인)
# - 파드 재시작 없이 진단 가능
# 네트워크 연결 테스트
kubectl debug -n production <pod-name> \
-it --image=nicolaka/netshoot -- \
curl -v http://postgres.production.svc.cluster.local:5432
# DNS 해석 확인
kubectl debug -n production <pod-name> \
-it --image=nicolaka/netshoot -- \
nslookup postgres.production.svc.cluster.local
kubectl events로 실시간 이벤트 모니터링
# 특정 네임스페이스 이벤트 실시간 확인
kubectl get events -n production --watch
# 경고 이벤트만 필터링
kubectl get events -n production \
--field-selector type=Warning \
--sort-by='.lastTimestamp'
# 특정 파드 관련 이벤트
kubectl get events -n production \
--field-selector involvedObject.name=<pod-name>
# 자주 발생하는 경고 이벤트 집계
kubectl get events -A --sort-by='.count' | \
grep Warning | tail -20
노드 수준 진단
노드 드레인
안전한 실행 조건: PDB, 복제본 수, 다른 노드의 여유 리소스를 확인한 유지보수 상황에서만 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl drain worker-1위 항목을 모두 확인한 후 복사할 수 있습니다
# 노드에 스케줄된 파드 현황
kubectl get pods -A --field-selector=spec.nodeName=worker-1
# 노드 자원 할당 현황 상세
kubectl describe node worker-1 | grep -A20 "Allocated resources"
# 노드 조건 전체 확인
kubectl get node worker-1 -o json | \
jq '.status.conditions[] | {type: .type, status: .status, message: .message}'
# 문제 노드 격리 (새 파드 스케줄 방지 + 기존 파드 evict)
kubectl drain worker-1 \
--ignore-daemonsets \
--delete-emptydir-data \
--grace-period=30
# 노드 수리 후 복구:
kubectl uncordon worker-1
# 일시적으로 새 파드만 스케줄 방지 (기존 파드 유지)
kubectl cordon worker-1
심화 — 노드가 죽으면 kubectl은 거짓말을 한다
심화: 하트비트, Terminating, 그리고 강제 삭제의 위험
지금까지는 파드 자체의 문제를 봤지만, 파드가 얹힌 노드가 통째로 죽으면 증상이 전혀 다르게 나타나고, 잘못 대응하면 데이터가 깨질 수 있습니다.
- 노드는 하트비트로 살아있음을 알립니다: kubelet이 주기적으로 자기 상태를 API 서버에 보고합니다. 노드가 죽거나 네트워크가 끊기면 하트비트가 멈추고, node-monitor-grace-period(기본 약 40초) 뒤 노드가 NotReady로 표시됩니다. 하지만 그 노드 위 파드들은 여전히 Running으로 보입니다 — 컨트롤 플레인은 죽었다는 걸 확인할 방법이 없어 마지막으로 보고된 상태를 그대로 둡니다. 즉 여기서의 Running은 지금 실행 중이 아니라 마지막으로 그렇게 보고됨입니다.
- 그다음 파드는 Terminating에 갇힙니다: 노드가 계속 안 돌아오면 컨트롤러가 파드에 deletionTimestamp를 찍어 Terminating으로 만듭니다. 그런데 kubelet이 죽어 실제 정리와 정리 완료 보고를 아무도 못 해, 파드 객체가 Terminating에 무한정 남습니다. Deployment는 새 노드에 대체 파드를 띄우지만, StatefulSet은 같은 이름 파드가 둘일 수 없다는 보장 때문에 옛 파드가 정리됐다고 확인되기 전엔 대체를 안 띄워 그 워크로드가 멈춥니다.
- 강제 삭제에는 함정이 있습니다: kubectl delete pod --force --grace-period=0은 API 서버에서 파드 객체만 지워 정리됐다고 간주하게 만듭니다. 노드가 정말 죽었으면 유효하지만, 노드가 살아있는데 네트워크만 끊긴 파티션이라면 옛 파드가 여전히 RWO 볼륨에 쓰는데 대체 파드가 같은 볼륨에 붙어 이중 쓰기·데이터 손상이 날 수 있습니다.
정리하면 파드 상태만 보지 말고 노드 상태(kubectl get nodes)를 함께 보십시오. 파드 여럿이 한 노드에서 동시에 이상하면 파드가 아니라 노드를 먼저 의심해야 합니다.
상황: 특정 워커 노드에 몰린 파드들이 트래픽에 응답하지 않는데 kubectl get pods는 여전히 Running으로 표시합니다. 파드를 지우니 Terminating으로 바뀌곤 몇 분째 그대로입니다. StatefulSet 파드는 대체 파드도 뜨지 않습니다.
원인: 노드가 죽었거나 API 서버와의 네트워크가 끊겨 kubelet 하트비트가 멈췄습니다. 컨트롤 플레인은 파드의 마지막 보고 상태(Running)를 그대로 보여줄 뿐 실제 상태를 모릅니다. grace period 뒤 노드가 NotReady가 되고 파드에 deletionTimestamp가 찍혀 Terminating이 되지만, 죽은 kubelet이 정리 완료를 보고하지 못해 파드 객체가 남습니다. StatefulSet은 옛 파드가 확실히 사라지기 전엔 동일 이름의 대체를 만들지 않아 워크로드가 정지합니다.
진단: kubectl get nodes로 그 노드가 NotReady인지 먼저 확인합니다(파드가 아니라 노드가 근본입니다). kubectl describe node로 마지막 하트비트 시각(Conditions의 LastHeartbeatTime)과 Ready가 Unknown인지 확인합니다. 파드가 한 노드에 몰려 동시에 이상하면 노드 장애 신호입니다.
해결: 노드가 정말 죽었으면 노드를 복구·교체하거나, 확인 후 kubectl delete node <node>로 노드 객체를 제거하면 그 위 파드들이 정리되고 대체 파드가 뜹니다. 개별 파드는 kubectl delete pod --force --grace-period=0로 지울 수 있으나, 이는 정리됐다고 API에 통보만 하는 것이라 반드시 노드가 진짜 죽은 걸 확인한 뒤에만 씁니다 — 노드가 살아있는데(네트워크 파티션) 강제 삭제하면 옛 파드가 RWO 볼륨에 계속 쓰는 채로 대체 파드가 같은 볼륨에 붙어 데이터가 손상될 수 있습니다.
시나리오: 새벽 장애 대응 체크리스트 — 단계별 5분 안에 원인 특정
새벽 3시, PagerDuty 알림. "결제 서비스 Health Check 실패". SSH 접속 후 체계적으로 진단합니다.
운영 Deployment 재시작
안전한 실행 조건: 무중단 배포 설정과 모니터링을 확인한 뒤 변경 창구에서 실행하세요.
실행 전 반드시 확인
- 현재 컨텍스트와 Namespace가 의도한 대상인지 확인했는가
- 운영 트래픽이나 상태 저장 데이터에 미치는 영향을 확인했는가
- 되돌릴 매니페스트, 백업, 또는 복구 절차가 준비되어 있는가
kubectl rollout restart deployment/payment -n production위 항목을 모두 확인한 후 복사할 수 있습니다
# T+00:00 — 전체 현황 파악 (30초)
kubectl get pods -n production
# payment-7d9b4c8f6-abc 0/1 CrashLoopBackOff 5 12m
# T+00:30 — 재시작 횟수와 이전 Exit Code 확인
kubectl describe pod payment-7d9b4c8f6-abc -n production | \
grep -E "Restart Count|Exit Code|Reason"
# Restart Count: 5
# Exit Code: 1 ← 앱 오류 (127=파일없음, 137=OOM)
# T+01:00 — 이전 크래시 로그 확인 (핵심)
kubectl logs payment-7d9b4c8f6-abc -n production --previous | tail -30
# 출력: "Error: DATABASE_URL is required but not set"
# → 환경변수 누락 발견!
# T+01:30 — 환경변수 확인
kubectl describe pod payment-7d9b4c8f6-abc -n production | \
grep -A30 "Environment:"
# DATABASE_URL: <set to the key 'url' in secret 'db-secret'> Optional: false
# Secret 참조는 있는데...
# T+02:00 — Secret 존재 확인
kubectl get secret db-secret -n production
# Error from server (NotFound): secrets "db-secret" not found
# → Secret 없음! 배포 시 Secret 생성 누락
# T+02:30 — 긴급 조치: Secret 복구
kubectl create secret generic db-secret -n production \
--from-literal=url="postgresql://user:password@postgres:5432/payment"
# T+03:00 — 파드 재시작 확인
kubectl rollout restart deployment/payment -n production
kubectl rollout status deployment/payment -n production
# T+04:00 — 복구 확인
kubectl get pods -n production | grep payment
# payment-6c9d5e8f7-xyz 1/1 Running 0 45s ← 정상!
curl -s http://payment.production.svc.cluster.local/health
# {"status": "ok"}
# T+05:00 — 사후 조치
# 1. Secret 생성 누락된 배포 파이프라인 수정
# 2. Health check alert 임계값 검토
# 3. Secret 존재 여부 확인하는 pre-deploy 검증 스크립트 추가
교훈: kubectl logs --previous가 핵심입니다. CrashLoopBackOff에서 현재 로그는 짧거나 없지만, 이전 크래시 로그에 실제 에러 메시지가 있습니다. 5가지 상태(Pending/CrashLoop/OOMKilled/Evicted/Unknown) 각각에 대한 진단 패턴을 외워두면 새벽 장애 대응 시간이 30분에서 5분으로 줄어듭니다.
상태별 진단 요약표
| 상태 | 첫 번째 확인 | 주요 원인 | 해결 |
|---|---|---|---|
| Pending | describe pod → Events | 리소스 부족, Affinity, PVC | 리소스 확보, 노드 추가, PVC 수정 |
| CrashLoopBackOff | logs --previous | 앱 오류, 설정 누락, CMD 오류 | 로그로 원인 파악, 설정/이미지 수정 |
| OOMKilled | describe → Exit Code 137 | memory limits 초과 | limits 상향, 메모리 누수 수정 |
| Evicted | describe → Message | 노드 자원 압박 | 디스크/메모리 정리, 자원 제한 설정 |
| ImagePullBackOff | describe → Events | 이미지 없음, 레지스트리 인증 | 이미지 태그 확인, ImagePullSecret |
| Terminating | describe → Finalizers | Finalizer 미제거, 강제 삭제 필요 | Finalizer 제거 또는 force delete |
CrashLoopBackOff 시나리오 재현 및 로그 확인
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: crash-demo
spec:
containers:
- name: crash
image: busybox
command: ["sh", "-c", "echo 'starting...' && exit 1"]
EOF
kubectl get pod crash-demo예상 출력
NAME READY STATUS RESTARTS crash-demo 0/1 CrashLoopBackOff 2
이전 크래시 컨테이너 로그 확인
kubectl logs crash-demo --previous예상 출력
starting...
파드 Events 확인 — 크래시 이유 파악
kubectl describe pod crash-demo | grep -A 15 Events예상 출력
Events: Warning BackOff ... Back-off restarting failed container Normal Pulled ... Successfully pulled image Normal Started ... Started container crash Warning Failed ... Error: exit code 1
OOMKilled 시나리오 재현
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: oom-demo
spec:
containers:
- name: oom
image: polinux/stress
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "200M", "--vm-hang", "1"]
resources:
limits:
memory: "64Mi"
EOF
sleep 10
kubectl describe pod oom-demo | grep -E "OOMKilled|Exit Code|State"예상 출력
State: Terminated Reason: OOMKilled Exit Code: 137
실습 리소스 정리
kubectl delete pod crash-demo oom-demo예상 출력
pod "crash-demo" deleted pod "oom-demo" deleted
명령어·단축키 빠른 참조
이 모듈에서 다룬 장애 진단 kubectl 명령을 상태별 실전 옵션과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
kubectl get pods | 이상 상태 파드 빠른 필터 | kubectl get pods -A --field-selector=status.phase!=Running |
kubectl describe pod | Events·Last State에서 원인 단서 | kubectl describe pod X | grep -A5 'Last State' (OOMKilled/Exit Code) |
kubectl logs --previous | 크래시 직전 컨테이너 로그 | kubectl logs X --previous | tail -30 |
kubectl get events | 이벤트 시간순·경고만 필터 | kubectl get events -A --sort-by=.lastTimestamp, --field-selector type=Warning |
kubectl top | 노드·파드 실제 자원 사용 | kubectl top nodes, kubectl top pod X --containers |
kubectl debug (pod) | 재시작 없이 디버그 컨테이너 부착 | kubectl debug X -it --image=nicolaka/netshoot --target=app |
kubectl debug node/ | 노드 파일시스템·디스크 진단 | kubectl debug node/worker-1 -it --image=busybox -- df -h |
kubectl get pod -o jsonpath | Exit Code 직접 추출 | ... -o jsonpath='{.status.containerStatuses[0].lastState.terminated.exitCode}' |
kubectl drain / cordon | 노드 격리·유지보수 | kubectl drain worker-1 --ignore-daemonsets --delete-emptydir-data |
kubectl get nodes / describe node | 노드 NotReady·컨디션 확인 | kubectl describe nodes | grep -A5 Conditions: |
kubectl delete pod --force | 죽은 노드의 Terminating 파드 제거 | kubectl delete pod X --force --grace-period=0 (노드 사망 확인 후만) |
관련 모듈로 더 깊이:
- Prometheus Operator와 Grafana 연동 대시보드 구축 — 장애가 터진 뒤 대응하는 대신 메트릭 기반으로 이상 징후를 선제 감지하는 법
- Grafana Loki와 Promtail을 이용한 경량 로그 중앙 수집 — describe·events로 부족할 때 로그 중앙 수집으로 원인을 좁히는 또 하나의 단서
- Liveness, Readiness, Startup Probe 헬스 체크 설정 — CrashLoopBackOff·트래픽 유입 실패의 흔한 뿌리인 liveness/readiness 프로브 오설정
- 백엔드 서버 이슈를 쫓는 도커 셸 접속과 디버깅 기법 — 파드 안의 컨테이너에 셸로 들어가 로그·프로세스를 직접 추적하는 Docker 디버깅 기법 (Docker 트랙)
다음 모듈 monitoring-prometheus에서는 트러블슈팅에서 반응형 대응을 넘어 메트릭 기반 선제 감지를 다룹니다. kube-prometheus-stack으로 Prometheus와 Grafana를 한 번에 설치하고, ServiceMonitor와 PromQL로 클러스터 이상 징후를 Alert로 자동화하는 방법을 실습합니다.