DEPLOYMENT
00:00 경과
LABLAB-K8S-06-HPA중급
HPA — CPU 기반 오토스케일링
ELAPSED
00:00
PHASE
0 / 5
SLA
45분
⎈ Kubernetes← 목록
INCIDENT RESPONSE
0 / 6 단계 완료
📚 PREREQUISITES
TRACK
KUBERNETES
SLA
45분
LEVEL
중급
PHASES
4단계
ENV
local
INCOMING TICKET
“이벤트 기간 대비 운영 준비: "다음 주 블랙프라이데이 트래픽 급증에 대비해 오토스케일링 구성해주세요"”
YOUR ROLE
인프라 엔지니어
안 하면 나중에
오토스케일링 미구성 시 트래픽 급증으로 서비스 응답 지연 및 장애 발생 가능
📋상황 브리핑
블랙프라이데이가 일주일 남았습니다.
"지난번 이벤트 때 트래픽 3배 몰려서 서버 다운됐잖아요. 이번엔 HPA 달아놓고 가세요."
수동으로 Pod 수를 늘리는 것은 근본적인 해결책이 아닙니다. 트래픽이 언제 얼마나 올지 정확히 알 수 없고, 사람이 항상 모니터링하고 있을 수도 없습니다.
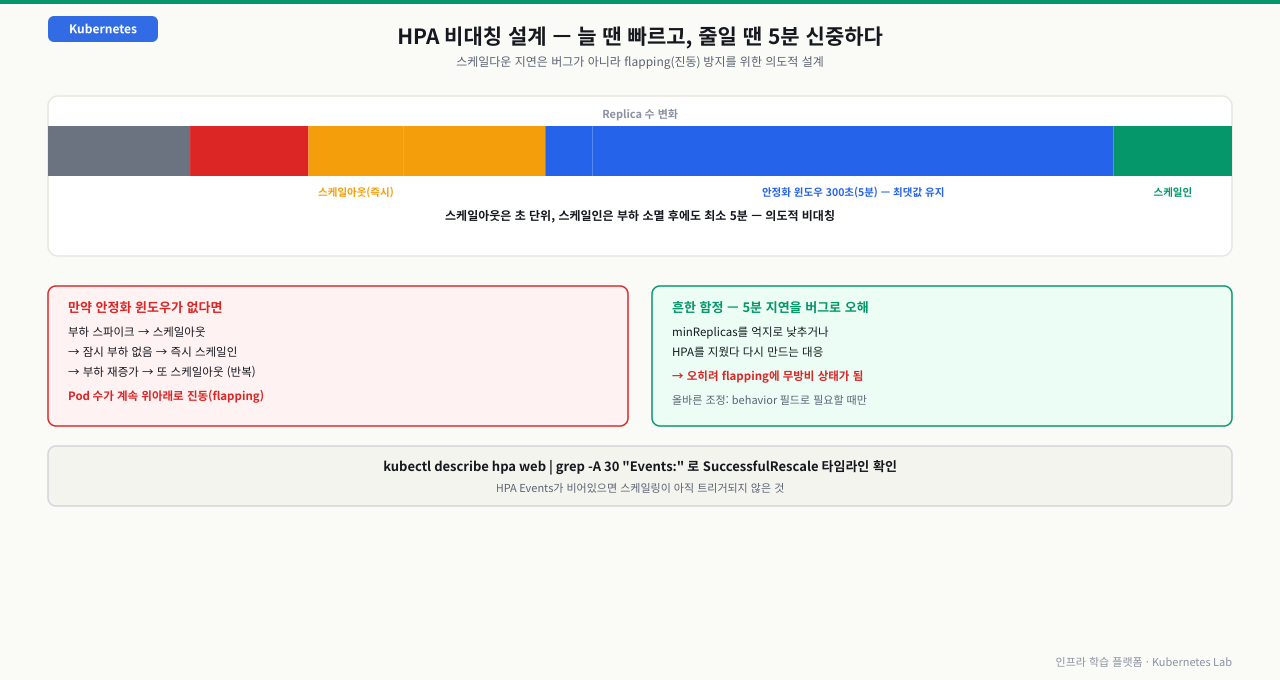
HPA(Horizontal Pod Autoscaler)는 CPU 사용량 같은 메트릭이 임계값을 초과하면 Pod를 자동으로 늘리고, 부하가 줄면 다시 줄여줍니다. Metrics Server에서 실시간 데이터를 받아 동작합니다.
CPU 70% 초과 시 최소 2개에서 최대 10개까지 자동 확장되는 HPA를 구성하고, 부하 시뮬레이션으로 실제 스케일아웃이 일어나는지 확인합니다.
 확대
확대⏱ 45분📊 중급🔧 4단계#kubernetes#hpa#autoscaling#metrics-server
MISSION
1
Metrics Server 확인 및 Deployment 준비
HPA의 전제조건인 Metrics Server가 동작하는지 확인하고, HPA 대상 Deployment를 resources 설정과 함께 생성한다
2
HPA 생성 — kubectl autoscale
kubectl autoscale로 CPU 70% 기준 최소 2개~최대 10개 HPA를 생성하고 상태를 확인한다
3
부하 시뮬레이션 — kubectl run으로 CPU 부하 발생
busybox 컨테이너로 지속적인 HTTP 요청을 발생시켜 CPU 사용률을 70% 이상으로 올리고 HPA가 스케일아웃을 시작하는지 확인한다
4
스케일아웃/인 확인 — kubectl get hpa -w
부하 중단 후 HPA가 스케일인(Pod 수 감소)하는 것까지 확인하고 HPA 동작 전체를 검증한다
📌 선수 지식
• [실습] k8s-basics-pod-deploy
• [실습] k8s-pod-oomkilled
• [이론] kubernetes/deployment-basics
• [이론] kubernetes/resource-limits
• [이론] kubernetes/hpa-autoscaling
ℹ️ 실습 환경
환경: local
필요 도구: kubectl, kubernetes cluster
검증 스크립트:
/labs/lab-k8s-07-hpa/scripts/verify.sh🔒
실습 실행은 Pro 플랜 전용입니다
인시던트 브리프와 학습 자료는 지금 바로 확인할 수 있습니다. 실제 실습 진행 및 터미널 사용은 Pro 플랜에서 가능합니다.
Pro로 업그레이드 →>_ LAB WORKSPACE
NOTES