Tomcat 서버에 새 버전 WAR 파일을 배포해야 합니다. 개발팀은 준비됐다고 했고, 팀장은 "오늘 밤 배포해"라고 합니다. 개발 서버에서는 잘 됐으니 그냥 올리면 될 것 같습니다. 파일 복사하고, Tomcat 재시작하고, 확인하면 끝 아닌가요?
그러다 배포 중 예상치 못한 오류가 납니다. 롤백해야 하는지, 계속 진행해야 하는지 판단이 서지 않습니다. 백업을 어디에 뒀는지, 이전 WAR 파일이 어디 있는지 기억이 안 납니다. 새벽 1시, 서비스는 다운된 상태입니다.
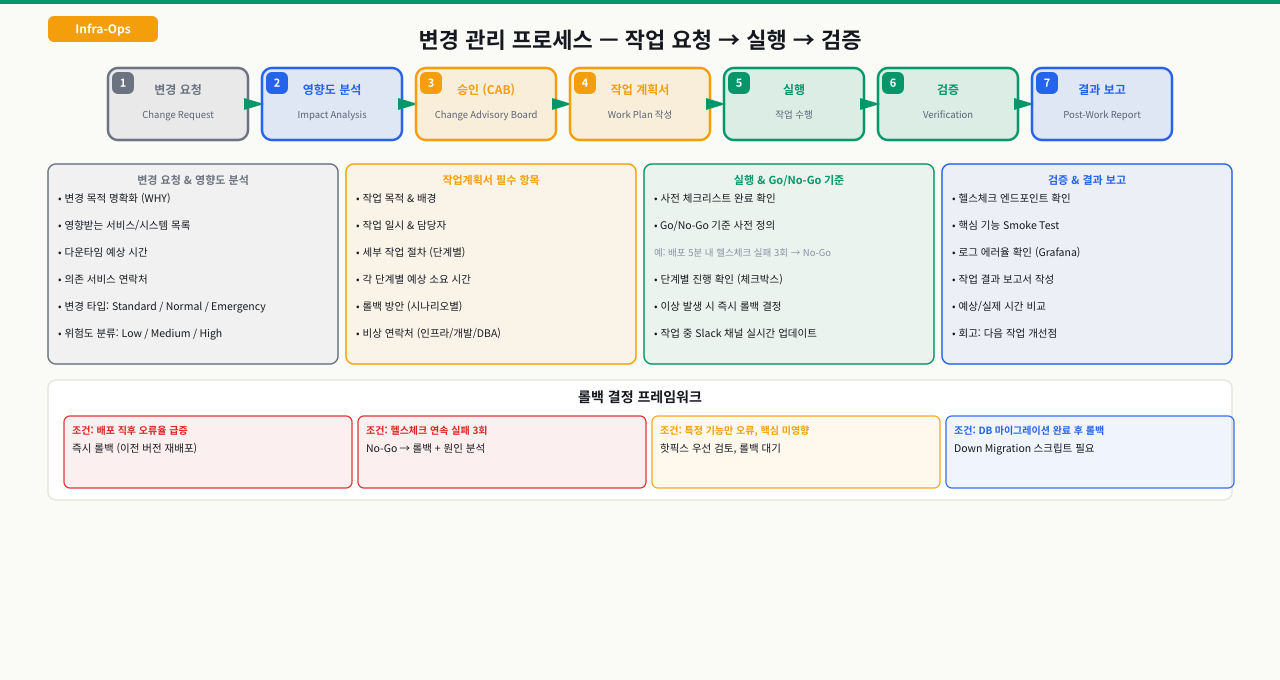
작업계획서는 이 패닉을 방지하는 도구입니다. 미리 작성해두면 실제 작업은 문서를 따라가는 것뿐입니다.
- 1작업계획서 필수 항목을 이해하고 직접 작성할 수 있다
- 2영향도 분석을 통해 작업 시간과 방식을 결정할 수 있다
- 3사전 백업 목록을 구성하고 작업 전 스냅샷을 수집할 수 있다
- 4Go/No-Go 기준을 정의하고 작업 중단 여부를 판단할 수 있다
- 5결과 보고서를 작성해 이슈와 후속 조치를 기록할 수 있다
작업계획서 구성
작업계획서 필수 항목
운영 변경 작업에서 절차를 머릿속에 담고 있는 것과 문서에 적어둔 것은 새벽 장애 상황에서 완전히 다른 결과를 만듭니다. 작업계획서는 미리 작성된 체크리스트로 작업자 본인이 순서를 빠뜨리지 않게 하고, 작업 중 문제가 생겼을 때 지원자가 상황을 즉시 파악할 수 있는 공유 문서 역할을 동시에 합니다. 어떤 항목이 반드시 포함돼야 하는지를 알면 한 번 템플릿을 만들어두고 매번 채워 쓰는 것으로 충분합니다.
 확대
확대
새벽 배포 중에 예상치 못한 오류가 나면, 머릿속이 하얗게 됩니다. 롤백해야 하는지, 계속 진행해야 하는지, 백업 파일이 어디 있는지 기억이 나지 않습니다. 주변에 도움을 요청하려 해도 상황을 설명하는 데만 5분이 걸립니다. 작업계획서가 없으면 경험 있는 엔지니어도 이 패닉에 빠집니다. 미리 작성된 문서가 있으면 그것을 따라가는 것만으로 충분합니다.
작업계획서는 두 가지 목적을 가집니다. 첫째, 작업자 본인이 순서를 잊지 않도록 하는 체크리스트입니다. 둘째, 작업 중 문제가 생겼을 때 주변 사람이 상황을 빠르게 파악하고 지원할 수 있는 공유 문서입니다. 이 두 가지를 모두 만족하는 문서가 좋은 작업계획서입니다.
작업계획서 필수 항목:
1. 작업명 — 한 줄로 무슨 작업인지 명확히
2. 일시 — 시작/종료 예상 시각 (버퍼 포함)
3. 담당자 — 이름, 이메일, 전화번호 (새벽에도 연락 가능한 번호)
4. 영향 서비스 — 작업 중 어떤 서비스가 어떻게 영향받는지
5. 사전 백업 목록 — 어떤 파일/설정/DB를 백업했는지
6. 작업 절차 — 순서대로 나열한 세부 단계
7. 롤백 기준 — 언제 롤백할지 (Go/No-Go 판단 기준)
8. 롤백 절차 — 롤백 시 실행할 명령어 순서
9. 비상연락처 — 작업자 외 지원 가능한 담당자
10. 완료 검증 방법 — 작업이 성공했음을 어떻게 확인할지
항목이 많아 보이지만, 한 번 템플릿을 만들어두면 다음부터는 채워넣기만 하면 됩니다.
작업계획서 실전 템플릿
작업계획서는 형식이 있어야 빠르게 작성합니다. 매 배포마다 항목을 새로 생각하는 것은 실수를 유발합니다. 아래 템플릿을 팀 내 공유 문서(Confluence, Notion 등)에 저장해두고 배포마다 복사해서 작성하면 누락 없이 일관된 기록을 남길 수 있습니다.
 확대
확대
이 형식을 팀 내 공유 문서(Confluence, Notion 등)에 저장해두고 배포마다 복사해서 작성합니다.
## 작업계획서
작업명: Tomcat WAR 배포 (myapp v1.2.0)
일시: 2026-05-30 22:00 ~ 23:00 (1시간, 버퍼 30분)
담당: 홍길동 (infra@company.com / 010-1234-5678)
검토자: 김팀장 (010-9876-5432)
영향 서비스:
- myapp 서비스 (Tomcat 재시작 중 약 2분 다운 예상)
- 사용자 로그인/결제 기능 일시 중단
사전 백업:
- 현재 WAR 파일: /opt/tomcat/webapps/myapp.war → /opt/backup/myapp_v1.1.0_20260530.war
- 설정 파일: /opt/tomcat/conf/context.xml → /opt/backup/context.xml_20260530
- catalina.out 마지막 100줄: /opt/backup/catalina_pre_deploy.log
작업 절차:
1. [ ] 사전 백업 완료 확인
2. [ ] Tomcat shutdown (systemctl stop tomcat)
3. [ ] Tomcat 중지 후 `find /opt/tomcat/webapps -maxdepth 1 -name 'myapp*' -print`로 목록을 검토하고, `readlink -f`가 승인된 `/opt/tomcat/webapps/myapp`와 일치할 때만 정확한 WAR·폭발 디렉터리를 이동/삭제 (운영 승인 필수, glob 삭제 금지)
4. [ ] 신규 WAR 복사 (cp myapp-v1.2.0.war /opt/tomcat/webapps/myapp.war)
5. [ ] Tomcat startup (systemctl start tomcat)
6. [ ] 기동 로그 확인 (tail -f catalina.out)
7. [ ] 헬스체크 확인 (curl http://localhost:8080/myapp/health)
8. [ ] 주요 기능 동작 확인 (로그인, 메인 화면)
Go/No-Go 기준:
- 배포 후 10분 내 헬스체크 URL 200 응답 → GO (완료)
- 10분 내 500 에러율 5% 초과 → NO-GO (즉시 롤백)
- catalina.out에 OutOfMemoryError 발생 → NO-GO (즉시 롤백)
롤백 절차:
1. systemctl stop tomcat
2. `readlink -f /opt/tomcat/webapps/myapp.war`와 `find /opt/tomcat/webapps -maxdepth 1 -name 'myapp*' -print`로 대상 목록을 확인하고 승인 기록
3. 백업 체크섬을 확인한 뒤 승인된 정확한 WAR 파일만 이동·교체 (glob 전체 삭제 금지)
`sha256sum /opt/backup/myapp_v1.1.0_20260530.war`
`cp -- /opt/backup/myapp_v1.1.0_20260530.war /opt/tomcat/webapps/myapp.war`
4. systemctl start tomcat
5. 헬스체크 확인
완료 검증:
- curl http://localhost:8080/myapp/health → HTTP 200
- 로그인 시도 → 성공
- catalina.out에 ERROR 없음
영향도 분석
작업 전 영향도 파악하기
주간 피크 시간에 Nginx를 재시작했다가 결제 중이던 사용자 수백 명의 세션이 끊긴 사고가 실제로 있습니다. 담당자는 "잠깐이면 될 것 같아서"라고 했지만, 그 잠깐이 얼마나 큰 영향을 주는지를 사전에 계산하지 않았습니다. 영향도를 분석하지 않으면 작업 시간 선택이 감에 의존하게 됩니다. 트래픽 패턴과 연관 서비스를 먼저 파악해야 "언제, 어떻게"를 결정할 수 있습니다.
영향도 분석은 작업을 언제, 어떻게 할지 결정하는 기준입니다. 영향이 크면 야간에 해야 하고, 롤백 방안을 더 세밀하게 준비해야 합니다.
확인해야 할 항목:
# 1. 현재 서비스 사용자 수 (트래픽 파악)
# 모니터링 시스템 없는 경우 Nginx 로그로 추정
awk '{print $4}' /var/log/nginx/access.log \
| grep "$(date +'%d/%b/%Y:%H')" \
| wc -l
# → 현재 시간대 요청 수 확인
# 2. 피크 시간 확인 (요청이 가장 많은 시간대)
awk '{print substr($4,14,2)}' /var/log/nginx/access.log \
| sort | uniq -c | sort -rn | head -5
# → 어느 시간대에 트래픽이 집중되는지 확인
# 3. 연관 서비스 확인
# 배포하는 서비스를 호출하는 다른 서비스가 있는지
grep "proxy_pass" /etc/nginx/conf.d/*.conf
# → Nginx → Tomcat 프록시 설정 확인
영향도에 따른 작업 시간 선택:
| 영향 범위 | 다운타임 | 권장 작업 시간 |
|---|---|---|
| 내부 관리 도구 | 수 분 가능 | 업무 시간 (팀원 지원 가능) |
| 일부 사용자 영향 | 1분 미만 | 새벽 2~4시 |
| 전체 서비스 다운 | 다운타임 발생 | 새벽 2~4시 + 사전 공지 |
| 무중단 배포 가능 | 0 | 언제든 가능 |
사전 백업
배포 전 반드시 백업할 것들
"백업은 당연히 하죠"라고 생각하지만, 정작 롤백이 필요한 상황에서 "어디에 백업했더라?"를 찾는 데 10분을 쓰는 경우가 많습니다. 백업 파일명에 날짜와 버전을 포함시키는 습관이 중요합니다.
# 백업 디렉터리 생성 (날짜 포함)
BACKUP_DIR="/opt/backup/$(date +%Y%m%d_%H%M)"
mkdir -p $BACKUP_DIR
# WAR 파일 백업
cp /opt/tomcat/webapps/myapp.war $BACKUP_DIR/myapp_current.war
# 설정 파일 백업
cp /opt/tomcat/conf/server.xml $BACKUP_DIR/
cp /opt/tomcat/conf/context.xml $BACKUP_DIR/
cp /etc/nginx/conf.d/myapp.conf $BACKUP_DIR/
# 현재 배포 버전 기록
ls -la /opt/tomcat/webapps/myapp.war >> $BACKUP_DIR/deployment_info.txt
java -version >> $BACKUP_DIR/deployment_info.txt 2>&1
systemctl status tomcat >> $BACKUP_DIR/deployment_info.txt
echo "백업 완료: $BACKUP_DIR"
ls -la $BACKUP_DIR
백업 대상 목록:
| 대상 | 백업 이유 | 예시 경로 |
|---|---|---|
| 현재 WAR/JAR | 롤백 시 이전 버전 복원 | /opt/tomcat/webapps/myapp.war |
| Nginx 설정 | 설정 변경 롤백 | /etc/nginx/conf.d/myapp.conf |
| Tomcat 설정 | context.xml 수정 시 | /opt/tomcat/conf/context.xml |
| SSL 인증서 | 인증서 교체 시 | /etc/nginx/ssl/server.crt |
| .env / 환경 설정 | 환경변수 변경 시 | /opt/app/.env |
작업 전 스냅샷 수집
작업 전 서버 상태를 파일로 남겨두면, 작업 중 "원래 이랬나?"를 확인할 수 있습니다. 작업 후 비교 기준이 됩니다.
# 한 번에 실행하는 스냅샷 스크립트
SNAP_DIR="/tmp/pre_work_$(date +%Y%m%d_%H%M)"
mkdir -p $SNAP_DIR
# 실행 중인 서비스 프로세스
ps aux | grep -E "tomcat|nginx|java|python|node" > $SNAP_DIR/ps.txt
# 디스크 사용량 (배포 후 디스크 부족 방지)
df -h > $SNAP_DIR/df.txt
# 메모리 상태
free -m > $SNAP_DIR/mem.txt
# 현재 서비스 상태
systemctl status tomcat nginx > $SNAP_DIR/service_status.txt 2>&1
# 포트 사용 현황
ss -tlnp > $SNAP_DIR/ports.txt
echo "Pre-work snapshot: $SNAP_DIR"
mkdir -p /tmp/pre_work && ps aux | grep -E 'tomcat|nginx|java' > /tmp/pre_work/ps.txt && df -h > /tmp/pre_work/df.txt && free -m > /tmp/pre_work/mem.txt && echo 'Snapshot done'- ls -la $SNAP_DIR로 스냅샷 파일 생성 여부를 먼저 확인 — ps.txt, df.txt, service_status.txt 세 파일이 모두 있어야 작업 전 기준선 완성. 하나라도 없으면 해당 항목 수동 재수집
- df.txt에서 배포 대상 디렉터리(보통 /opt)의 여유 공간 확인 — WAR 파일 크기의 3배 이상 여유가 있어야 안전(현재 WAR + 백업 WAR + 임시 압축 해제 공간). 여유가 부족하면 배포 전 로그 정리 선행
- service_status.txt에서 active인 서비스가 ps.txt의 프로세스 목록과 일치하는지 교차 확인 — systemctl로 active이지만 ps에 프로세스가 없으면 좀비 상태로 재기동 필요
작업 후 검증
배포 완료 후 헬스체크 URL로 서비스 정상 여부를 확인합니다. HTTP 응답코드와 응답시간을 함께 확인합니다.
# 헬스체크 URL 확인 (상태코드 출력)
curl -s -o /dev/null -w "HTTP %{http_code} - %{time_total}s\n" \
http://localhost:8080/myapp/health
# 로그 확인 (배포 후 2분간 ERROR 없는지)
tail -f /opt/tomcat/logs/catalina.out | grep -E "ERROR|Exception|WARN" &
sleep 120
kill %1
# Nginx 접근 로그에서 500 에러 확인
grep " 500 " /var/log/nginx/access.log | tail -10
curl -s -o /dev/null -w '%{http_code}' http://localhost:8080/myapp/health- 헬스체크 HTTP 응답 코드를 먼저 확인 — 200이면 애플리케이션 기동 성공. time_total 값이 스냅샷의 기준 응답시간(df.txt와 함께 기록해둔 기준값) 대비 2배 이상이면 성능 저하
- 응답 코드 200이어도 catalina.out에 ERROR 또는 Exception이 있으면 — 헬스체크 엔드포인트는 통과했지만 다른 기능에 문제가 있는 불완전 기동 상태. 로그인과 주요 조회 기능을 반드시 수동 확인
- HTTP 200이고 catalina.out 오류 없고 주요 기능 정상인 세 조건이 모두 충족되면 배포 완료 선언 가능 — 세 조건 중 하나라도 미충족이면 Go/No-Go 기준에 따라 즉시 롤백 여부 결정
트러블슈팅
상황: 배포 중 catalina.out에 ClassNotFoundException이 떴습니다. 서비스는 기동됐지만 일부 API가 500 에러를 반환합니다. 계속 진행하면 괜찮을지, 롤백해야 하는지 모르겠습니다.
이런 상황에서 즉각 판단할 수 있는 것은 미리 정의한 Go/No-Go 기준뿐입니다.
# No-Go 판단 체크
# 1. 헬스체크 실패 여부
curl -s -o /dev/null -w "%{http_code}" http://localhost:8080/myapp/health
# → 200이 아니면 즉시 롤백
# 2. 최근 1분간 에러율 확인
# (Nginx 로그 기준)
TOTAL=$(awk '{print $4}' /var/log/nginx/access.log \
| grep "$(date +'%d/%b/%Y:%H:%M')" | wc -l)
ERRORS=$(awk '$9 ~ /^5/ {print $4}' /var/log/nginx/access.log \
| grep "$(date +'%d/%b/%Y:%H:%M')" | wc -l)
echo "Total: $TOTAL, Errors: $ERRORS"
# → 에러율 5% 초과 시 롤백
# 3. OOM 발생 여부
grep -i "OutOfMemoryError" /opt/tomcat/logs/catalina.out | tail -3
# → 있으면 즉시 롤백
No-Go 판단 후 롤백을 결정했다면, 망설이지 말고 즉시 실행합니다. "조금만 더 기다려보자"는 생각이 장애 시간을 늘립니다. 작업계획서에 롤백 절차가 있다면 그대로 따르면 됩니다.
상황: 야간 배포를 마치고 서비스가 뜬 것을 확인하고 퇴근했습니다. 다음날 아침, 야간에 특정 API가 간헐적으로 느렸다는 사용자 민원이 접수됐습니다. 배포와 연관이 있는지 확인하려는데 아무 기록이 없습니다.
결과 보고서는 작업 완료 후 30분 안에 작성하는 것이 원칙입니다.
## 배포 결과 보고서
작업명: Tomcat WAR 배포 (myapp v1.2.0)
완료 일시: 2026-05-30 22:47
작업자: 홍길동
결과: 정상 완료
실행 내역:
22:00 - 사전 백업 완료
22:05 - Tomcat shutdown
22:08 - WAR 파일 교체
22:10 - Tomcat startup
22:15 - 헬스체크 확인 (HTTP 200)
22:47 - 주요 기능 확인 완료
발생 이슈:
- 기동 후 첫 1분간 DB 커넥션 풀 초기화로 응답 지연 발생
(catalina.out: HikariPool - Starting at 22:10:32)
→ 신규 버전에서 커넥션 풀 크기 변경됨. 다음 배포 시 사전 확인 필요
후속 조치:
- 커넥션 풀 설정 검토 (개발팀 확인 요청)
- 배포 후 5분간 응답시간 모니터링 강화 검토
다음 배포 시 개선사항:
- 기동 후 warm-up 요청 추가 (헬스체크 전 주요 API 사전 호출)
심화 — 롤백 계획이 '있다'와 '작동한다'는 다르다
심화: 리허설하지 않은 롤백과 되돌릴 수 없는 지점
작업계획서에 롤백 절차 칸을 채웠다고 안전한 것이 아닙니다. 한 번도 실행해 본 적 없는 롤백은 장애 당일 처음 돌려 보는 코드입니다. 계획의 '실효성'을 어떻게 확보하는지가 초급과 중급을 가릅니다.
- 롤백은 리허설해야 계획이 된다: 운영과 같은 구조의 스테이징에서 '배포 → 롤백'을 실제로 한 번 돌려 봐야 절차의 오타·권한·누락이 드러납니다. 백업 파일이 실제로 복원 가능한지(손상·빈 파일이 아닌지)까지 확인해야 합니다 — '백업이 있다'와 '복원된다'는 다릅니다.
- 되돌릴 수 없는 지점(point of no return): 파괴적 DDL(DROP/TRUNCATE), 비가역 데이터 마이그레이션, 이미 외부로 나간 알림·결제, 한 번 올라간 스키마 버전은 앱 바이너리를 되돌려도 원복되지 않습니다. 작업계획서는 절차의 어느 단계부터가 되돌릴 수 없는지 표시하고, 그 직전에 마지막 롤백 결정 게이트를 둬야 합니다.
- 롤백에도 시간·영향이 든다: 롤백 자체가 다운타임·재기동을 유발하므로 목표 복구 시간(RTO)을 계획에 넣고, 롤백이 그 시간을 넘길 것 같으면 '되돌리기' 대신 '전진 수정(roll-forward, 핫픽스)'으로 전환하는 기준도 미리 정합니다.
- 한계: 완벽한 롤백 계획도 '변경 창 동안 동시에 벌어진 다른 변경'이나 '데이터가 이미 신버전 형식으로 쓰인 상태'는 못 되돌립니다. 그래서 변경 창 동안 다른 변경을 얼리고(freeze), 앱 롤백만으로 복구되도록 스키마를 신·구 양쪽 호환(backward-compatible)으로 설계하는 것이 근본 방어입니다.
상황: 배포 후 심각한 오류로 No-Go 판정을 내리고, 계획서의 롤백 절차대로 이전 WAR를 복원한 뒤 Tomcat을 재기동했습니다. 그런데 롤백 후에도 앱이 계속 500을 냅니다. 새벽에 롤백마저 안 먹혀 패닉에 빠졌습니다.
원인: 두 가지가 겹쳤습니다. (1) 백업해 둔 '이전 WAR'가 실제로는 배포 직전이 아니라 며칠 전 것이었고, 롤백을 한 번도 리허설한 적이 없어 아무도 이를 검증하지 않았습니다. (2) 이번 배포에 포함된 DB 마이그레이션이 컬럼을 비가역적으로 바꿔, 구버전 WAR로 되돌려도 스키마가 맞지 않아 여전히 실패했습니다 — 앱만 되돌리고 스키마는 못 되돌리는 '되돌릴 수 없는 지점'을 이미 지난 것입니다.
진단: 롤백 후에도 실패하면 먼저 복원된 WAR의 체크섬·타임스탬프를 원본과 대조합니다(md5sum). 그다음 catalina.out의 에러가 이번엔 SQL/스키마 관련(Unknown column 등)으로 바뀌었는지 확인해, '무엇이 아직 신버전 상태로 남아 있나'를 찾습니다.
해결: 즉시로는 스키마를 UNDO SQL로 함께 되돌리거나(가역인 경우), 되돌릴 수 없으면 전진 수정(핫픽스)으로 전환합니다. 근본적으로는 (1) 모든 배포 전 스테이징에서 '배포 → 롤백'을 리허설하고 백업 복원 가능성을 체크섬으로 검증하고, (2) 작업계획서에서 앱·스키마·설정을 하나의 롤백 단위로 묶어 '되돌릴 수 없는 지점'을 표시하며, (3) 가능하면 스키마를 확장→수축 2단계로 설계해 앱 롤백만으로 복구되게 합니다.
실제 업무에서 이 지식이 쓰이는 상황:
처음 운영 배포를 맡으면 가장 무서운 것이 "내가 잘못하면 어떡하지?"입니다. 작업계획서가 있으면 그 두려움이 많이 줄어듭니다. 무엇을 해야 하는지, 실패했을 때 어떻게 되돌리는지가 문서에 있기 때문입니다.
팀의 시니어들이 작업계획서를 중요시하는 이유는 본인이 경험한 사고 때문입니다. 백업 없이 배포하다가 파일을 날린 경험, 롤백 절차를 미리 안 짜놔서 새벽에 당황했던 기억이 있습니다. 작업계획서 문화는 그 경험들의 산물입니다.
변경관리(ITSM) 시스템과의 연동:
규모 있는 조직에서는 JIRA, ServiceNow 같은 변경관리 시스템에 변경 요청(Change Request)을 등록하고 승인받는 절차가 있습니다.
ITSM 변경 요청 흐름:
작업자 → CR 등록 (작업계획서 첨부)
→ 팀장 검토/승인
→ 작업 실행
→ 결과 보고 (CR 닫기)
ITSM이 없는 팀이라면 Slack/메일로 팀장 승인을 받는 것만으로도 충분합니다. 중요한 것은 작업 전 검토가 이뤄졌다는 기록입니다.
명령어·단축키 빠른 참조
이 모듈은 절차 중심이지만, 작업 전 스냅샷·백업과 작업 후 검증에 쓰는 명령을 모았습니다. 작업계획서의 "사전 백업 / 영향도 / 완료 검증" 항목에 그대로 대응합니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
mkdir -p + cp | 날짜별 사전 백업 | BACKUP_DIR=/opt/backup/$(date +%F_%H%M); mkdir -p $BACKUP_DIR |
ps aux | grep | 작업 전 프로세스 스냅샷 | ps aux | grep -E 'tomcat|nginx|java' > ps.txt |
df -h | 배포 여유 디스크 확인 | 산출물 크기의 3배 이상 여유 확인 |
free -m | 메모리 기준선 기록 | 작업 전후 비교용 스냅샷 |
ss -tlnp | 포트 사용 현황 기록 | ss -tlnp > ports.txt |
systemctl status | 서비스 상태 스냅샷 | systemctl status tomcat nginx |
awk (access.log) | 시간대별 트래픽·피크 분석 | awk '{print substr($4,14,2)}' access.log | sort | uniq -c | sort -rn |
grep proxy_pass | 연관 서비스(프록시) 파악 | grep proxy_pass /etc/nginx/conf.d/*.conf |
curl -w '%{http_code}' | 작업 후 헬스체크 | curl -s -o /dev/null -w '%{http_code}' http://localhost:8080/myapp/health |
grep " 500 " access.log | 배포 후 5xx 에러 확인 | grep " 500 " /var/log/nginx/access.log | tail |
관련 모듈로 더 깊이:
- 파일/설정/DB/인증서 롤백 절차와 판단 기준 — 작업 실패 시 사전 백업을 활용해 롤백하는 구체적 절차
- WAR/JAR/정적파일 배포와 배포 스크립트 작성 — 작업계획서가 실제로 적용되는 배포 흐름의 구조
- 타임라인 분석과 재발 방지 대책 수립 — 변경이 장애로 이어졌을 때 원인 분석과 보고서 작성
다음 모듈에서는 배포 후 실제로 문제가 생겼을 때 파일, 설정, DB를 어떻게 롤백하는지를 다룹니다.