새벽 2시, 모니터링 알람이 울립니다. "JVM Heap 사용률 90% 초과 — 서비스: order-service." Tomcat 로그에는 java.lang.OutOfMemoryError: Java heap space 에러가 쌓이고, 응답 지연이 길어지고 있습니다.
재시작하면 당장은 해결됩니다. 하지만 같은 알람이 또 울릴 것입니다. 원인을 모른 채 재시작만 반복하는 건 운영이 아닙니다. 힙 덤프를 떠서 무엇이 메모리를 먹는지 찾아야 합니다. 이 모듈에서 그 절차를 배웁니다.
- 1JVM 메모리 구조(Heap, Metaspace, Stack)와 각 영역의 역할을 설명할 수 있다
- 2GC 종류(Serial/Parallel/CMS/G1GC/ZGC)의 특징과 선택 기준을 구분할 수 있다
- 3jstat으로 GC 현황을 실시간 모니터링하고 Full GC 발생 여부를 확인할 수 있다
- 4Thread Dump와 Heap Dump를 생성하고 BLOCKED 스레드·OOM 원인을 분석할 수 있다
- 5OOM 알람 수신 시 표준 대응 절차를 순서대로 실행할 수 있다
java -version && which jps jstat jstack jmapjps -lmkdir -p /tmp/jvm-dumps && ls -ld /tmp/jvm-dumpscat /etc/tomcat9/tomcat9.conf 2>/dev/null || cat /opt/tomcat/bin/setenv.sh 2>/dev/null || echo 'setenv.sh 없음'JVM 메모리 구조
JVM이 메모리를 나누는 방식: 왜 Heap만 알면 안 되는가
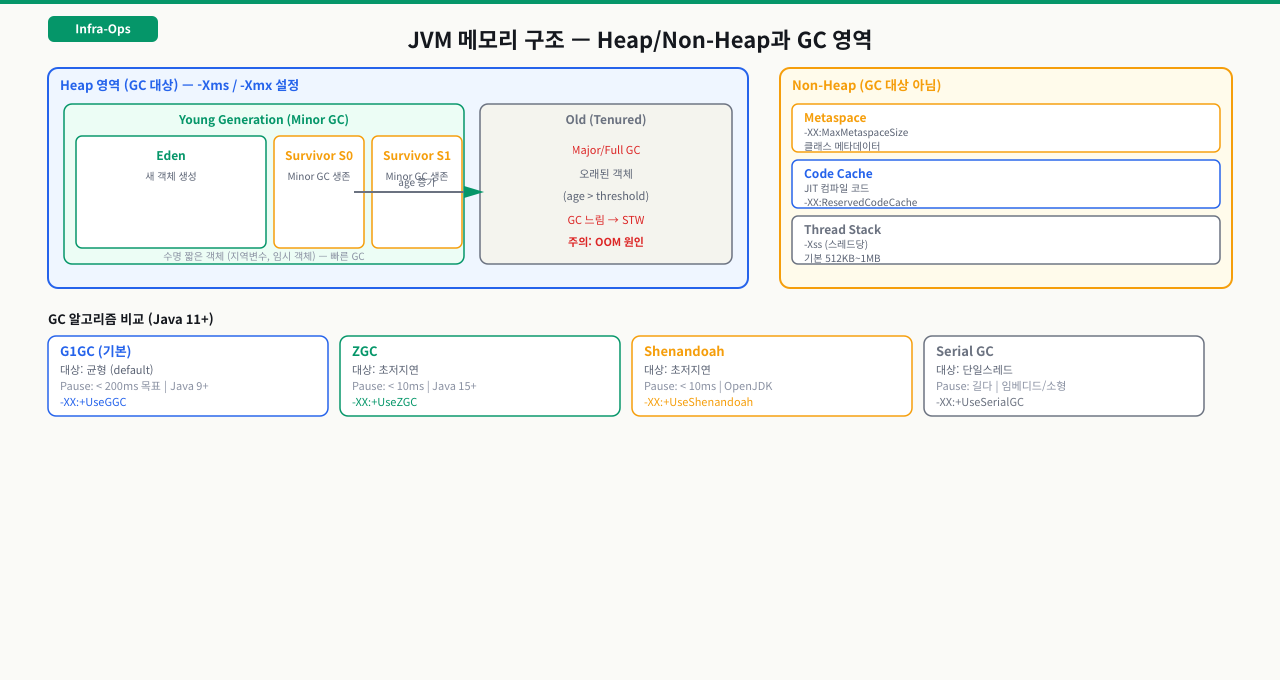
OOM(OutOfMemoryError)이 발생했을 때 단순히 Heap 크기를 늘리는 것은 잘못된 방향일 수 있습니다. OOM은 Heap이 아닌 Metaspace 고갈이나 네이티브 메모리 부족에서도 똑같이 발생하며, 원인 영역을 잘못 짚으면 같은 장애가 반복됩니다. JVM이 메모리를 어떤 영역으로 나누고 각 영역이 무엇을 담는지 이해해야 에러 메시지만 보고도 어느 JVM 옵션을 조정해야 할지 판단할 수 있습니다.
 확대
확대
OOM이 났을 때 "힙을 늘리면 되지 않나요?"라고 생각하기 쉽습니다. 하지만 OOM은 힙이 아닌 Metaspace에서도, 네이티브 메모리에서도 발생합니다. 영역별로 무엇이 쌓이는지 알아야 올바른 옵션을 고칠 수 있습니다.
Heap — 가장 큰 영역, GC 대상
 확대
확대
Metaspace (Java 8+, 구버전의 PermGen 대체)
클래스 메타데이터(클래스 구조, 메서드 바이트코드, static 변수 등)가 저장됩니다. 네이티브 메모리를 사용하며 기본적으로 크기 제한이 없어 무한정 증가할 수 있습니다. 클래스 누수(클래스로더 반복 생성)가 있으면 이 영역에서 OOM이 납니다.
# Metaspace OOM 메시지
java.lang.OutOfMemoryError: Metaspace
Stack — 스레드별로 존재
각 스레드가 독립적으로 소유합니다. 메서드 호출 정보(로컬 변수, 호출 스택)가 쌓입니다. 재귀 호출이 너무 깊으면 StackOverflowError가 납니다.
Native Memory
JVM 자체와 GC 스레드, JNI(네이티브 라이브러리) 등이 사용하는 OS 메모리입니다. java.lang.OutOfMemoryError: Unable to create new native thread가 이 영역 고갈의 신호입니다.
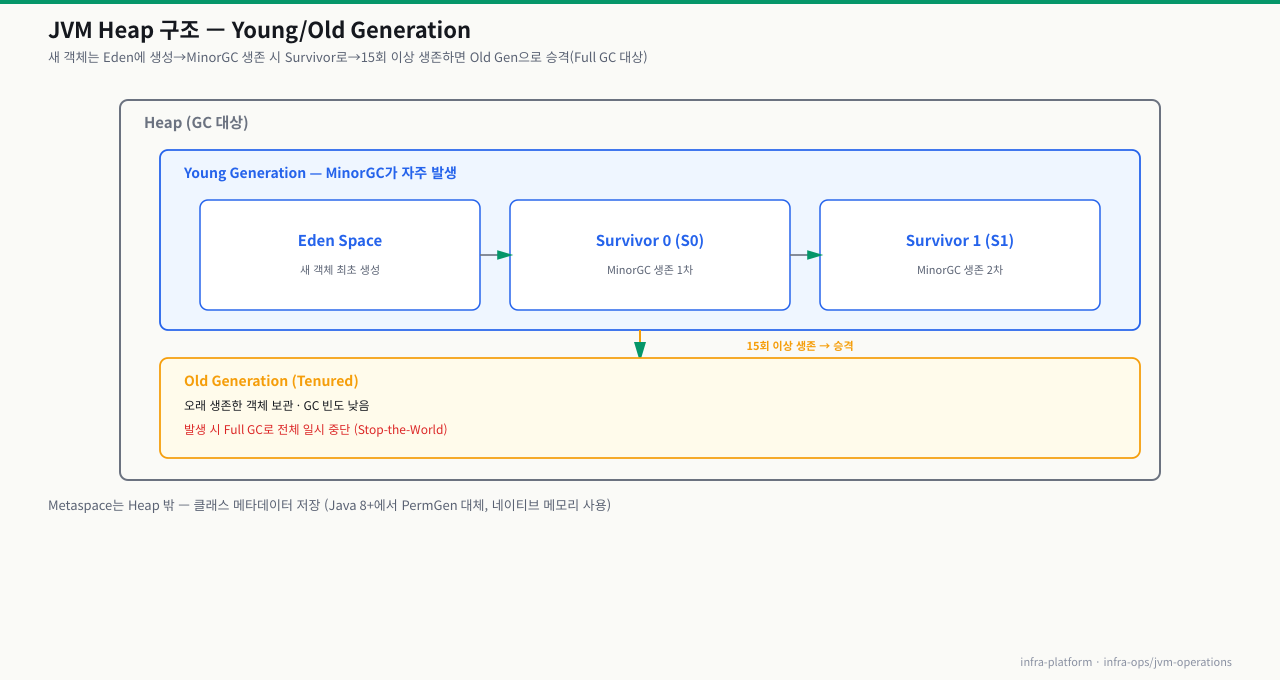
객체 하나가 힙에서 태어나 죽기까지 — Eden부터 Full GC·OOM까지
코드에서 new Order() 한 줄이면 객체가 생깁니다. 그런데 그 객체는 어디에 놓이고, 언제 사라지며, 왜 어떤 객체는 오래 살아남아 Full GC를 유발할까요? 객체의 일생은 Eden 할당 → Minor GC → Survivor 승격 → Old 승격 → Full GC → 회수 또는 OOM의 순서를 따릅니다. 이 흐름을 알면 jstat의 숫자(O·FGC)가 무슨 뜻인지, 왜 응답이 주기적으로 멈추는지, OOM 메시지가 어느 영역을 가리키는지를 단계로 읽어낼 수 있습니다.
[객체 생성] new Order()
│
① Eden에 할당 (Young Generation, 빠른 bump 할당)
│
② Eden 꽉 참 → Minor GC (STW 짧음) (살아있는 객체만 Survivor로 복사)
│
③ Survivor S0 ⇄ S1 이동, age +1 (Minor GC마다 생존하면 나이 증가)
│
④ age 임계치 초과 → Old로 승격 (MaxTenuringThreshold, 기본 15)
│ → 오래 사는 객체(캐시·세션)가 Old에 쌓임
│
⑤ Old 꽉 참 → Major/Full GC (STW 김) (Old 전체 정리, 전 스레드 정지)
│
⑥ 회수 성공 → 공간 확보 / 실패 → OOM
▼
[결과] 회수되면 지속, 못 하면 java.lang.OutOfMemoryError: Java heap space
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① Eden 할당 | new로 만든 객체는 대부분 Eden에 즉시 할당(포인터만 밀어 빠름) | 대량 임시객체 폭주 → Eden이 금방 참 → Minor GC 빈발 |
| ② Minor GC | Eden이 차면 Young 영역 GC. 살아있는 객체만 Survivor로 복사, STW는 보통 수ms | 살아남는 객체가 많으면 YGCT(YGC 누적시간) 증가 → 복사 비용·짧은 멈춤 누적 |
| ③ Survivor age | 살아남은 객체가 S0·S1을 오가며 age가 1씩 증가 | Survivor가 너무 작으면 조기 승격(premature promotion) → Old를 이르게 압박 |
| ④ Old 승격 | age가 임계치(MaxTenuringThreshold) 초과 or Survivor 넘침 시 Old로 이동 | 누수 객체가 계속 승격 → jstat의 O(Old 사용률)가 단조 증가 |
| ⑤ Full GC | Old(또는 Metaspace)가 차면 힙 전체 GC. STW가 수백ms~수초로 김 | FGC가 잦고 pause가 길면 → 그 순간 전 스레드 정지 → 주기적 응답 멈춤 |
| ⑥ 회수 or OOM | 살릴 객체를 빼고 회수. 회수 못 하면 OOM | Full GC 후에도 O가 안 줄면 누수 확정 → Java heap space OOM · 클래스 누수면 Metaspace OOM |
즉 OOM 메시지가 어느 단계·어느 영역이 터졌는지를 알려줍니다. java.lang.OutOfMemoryError: Java heap space는 ⑥에서 힙 회수 실패(객체 누수 또는 힙 부족), : Metaspace는 힙이 아니라 클래스 메타데이터 영역(⑤⑥와 별개 영역, 보통 클래스로더 누수), GC overhead limit exceeded는 ⑤가 계속 도는데 ⑥ 회수량이 거의 없는 상태입니다. 그래서 진단의 출발점은 jstat -gcutil로 O가 Full GC(FGC) 뒤에도 줄지 않는지 보는 것이고, 줄지 않으면 힙 덤프로 ④에서 계속 승격되는 객체가 무엇인지 추적합니다. Full GC가 잦다는 것은 곧 힙 부족·누수의 신호입니다.
GC 종류와 선택 기준
배포 직후부터 응답이 주기적으로 3~5초씩 멈추는 현상이 보고됩니다. 에러는 없고, 로그도 정상인데 간헐적으로 느립니다. GC 로그를 보니 Full GC가 30초마다 발생하고 있습니다. Java 8에서 기본 GC(Parallel GC)를 그대로 쓰는 4GB 힙 서버에서 자주 나타나는 패턴입니다. GC 종류를 이해하고 올바른 것을 선택해야 이 문제가 사라집니다.
GC는 "어떤 알고리즘으로 힙을 청소하느냐"의 차이입니다. 처리량(Throughput)과 응답 지연(Latency) 사이의 트레이드오프입니다. 운영 환경에 맞는 GC를 선택하지 않으면 주기적인 응답 지연이 발생합니다.
| GC 종류 | Java 기본값 | 특징 | 적합 환경 |
|---|---|---|---|
| Serial GC | Java 1~5 | 단일 GC 스레드, STW | 소규모 배치, 싱글코어 |
| Parallel GC | Java 8 기본 | 멀티 GC 스레드, STW | 처리량 우선, 배치 서버 |
| CMS | Java 9에서 deprecated | Old Gen을 백그라운드 GC | 응답 시간 민감, 소~중간 힙 |
| G1GC | Java 9+ 기본 | Region 분할, 예측 가능한 STW | 4GB 이상 힙, 웹 서비스 |
| ZGC | Java 15+ | 1ms 이하 STW 목표 | 초대형 힙, 초저지연 요구 |
STW(Stop-The-World): GC가 실행되는 동안 모든 애플리케이션 스레드가 멈추는 현상입니다. 이 시간이 길수록 응답 지연이 발생합니다.
실무 선택 기준 — Tomcat 웹 서비스 기준:
힙 < 4GB, Java 8: Parallel GC (기본값)
힙 >= 4GB, Java 8: -XX:+UseG1GC 명시적 지정
Java 9+: G1GC (기본, 별도 옵션 불필요)
Java 15+, 초저지연: -XX:+UseZGC
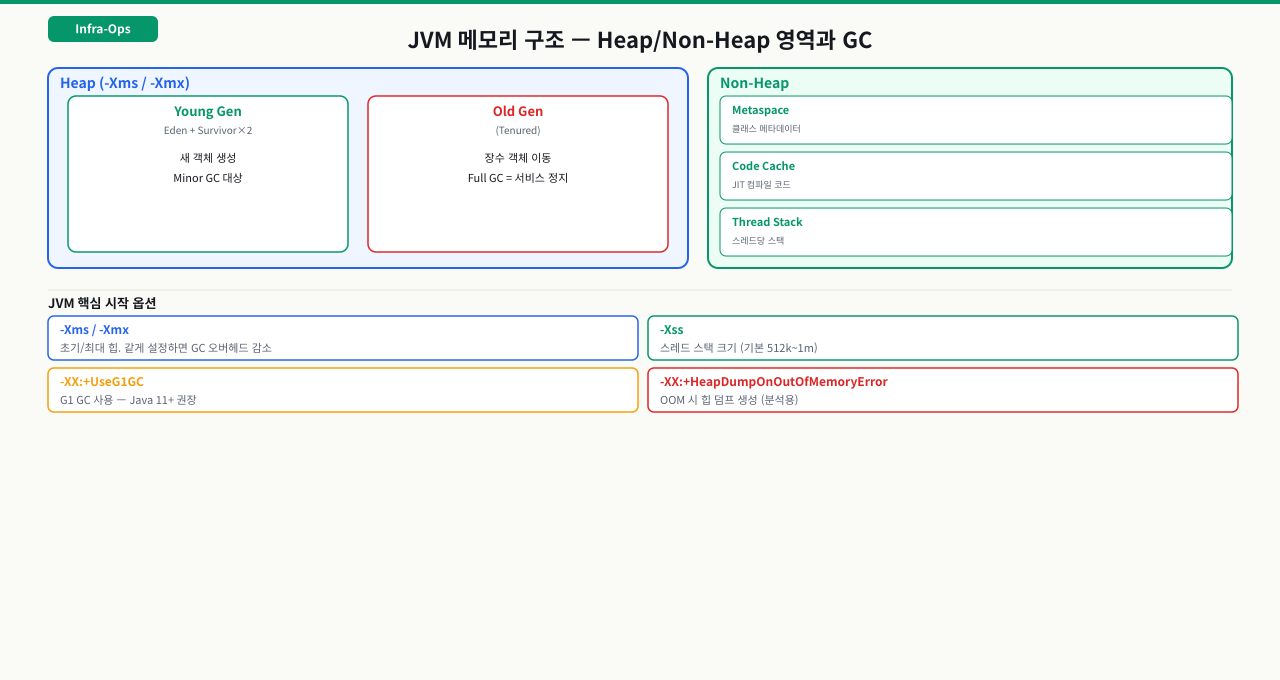
JVM 옵션 설정
Tomcat setenv.sh에 JVM 옵션 집어넣기
OOM 알람을 받고 Tomcat을 재시작했는데, 힙 덤프가 남아있지 않습니다. "HeapDumpOnOutOfMemoryError 옵션을 설정했었나요?" — 아무도 모릅니다. 현장에서 이런 상황은 생각보다 자주 발생합니다. setenv.sh 하나만 제대로 관리하면 이런 상황을 예방할 수 있습니다. JVM 옵션이 어디에 있는지 모른다는 것 자체가 운영 리스크입니다.
JVM 옵션은 Tomcat 시작 스크립트에 환경변수로 넣습니다. /opt/tomcat/bin/setenv.sh 파일이 없으면 새로 만듭니다. CATALINA_OPTS에 추가하면 Tomcat 프로세스에만 적용됩니다.
# /opt/tomcat/bin/setenv.sh
export CATALINA_OPTS="
-Xms2g
-Xmx2g
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/jvm-dumps/
-Xlog:gc*:file=/logs/gc.log:time,uptime:filecount=5,filesize=20m
-Dfile.encoding=UTF-8
-Duser.timezone=Asia/Seoul
"
옵션별 의미:
| 옵션 | 값 예시 | 설명 |
|---|---|---|
-Xms | 2g | 힙 초기 크기 |
-Xmx | 2g | 힙 최대 크기 (같게 설정해 resize 방지) |
-XX:MetaspaceSize | 256m | Metaspace 초기 임계값 |
-XX:MaxMetaspaceSize | 512m | Metaspace 최대 크기 제한 |
-XX:+UseG1GC | — | G1GC 명시적 활성화 (Java 8용) |
-XX:MaxGCPauseMillis | 200 | GC 목표 최대 중단 시간(ms) |
-Dfile.encoding | UTF-8 | 한국어 등 멀티바이트 문자 인코딩 |
-Duser.timezone | Asia/Seoul | JVM 기본 시간대 설정 |
 확대
확대
JVM 현황 모니터링
jps -l로 Java 프로세스 PID를 확인한 뒤, jstat -gcutil PID 1000 10으로 1초 간격 10회 GC 통계를 출력합니다. Tomcat PID를 직접 지정해도 됩니다. 이 명령은 JVM을 재시작하거나 서비스를 중단하지 않고 실행 중인 프로세스에 attach해 정보를 읽어옵니다.
jps -l && jstat -gcutil $(jps -l | grep -v Jps | awk '{print $1}' | head -1) 1000 10- jstat 출력에서 먼저 O(Old Gen) 사용률 트렌드를 보고, 그 다음 FGC 증가 속도 확인 — O가 샘플마다 증가하면 메모리 누수, FGC가 분당 1회 이상이면 즉시 힙 분석 필요
- 수치 기준: O(Old Gen) 80% 이상=Full GC 빈도 증가 시작, 90% 이상=응답 지연 및 OOM 위험 / YGCT/YGC(평균 YGC 시간)가 100ms 이상이면 힙 크기 증설 검토 / FGC가 10분에 3회 이상이면 메모리 누수 의심
- O(Old Gen)가 계속 증가하는데 FGC 후에도 줄어들지 않으면 → 메모리 누수 확정 — jmap -dump:format=b,file=/tmp/heap.hprof <PID> 로 힙 덤프 생성 후 MAT/VisualVM 으로 분석
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 45.23 72.15 38.42 96.74 89.33 145 2.341 2 0.531 2.872
0.00 45.23 81.20 38.42 96.74 89.33 145 2.341 2 0.531 2.872
0.00 0.00 8.43 41.15 96.74 89.33 146 2.389 2 0.531 2.920
위 출력에서 YGC가 145→146으로 증가하며 Eden(E)이 리셋됐습니다. 정상적인 MinorGC입니다. Old Gen(O)이 38→41로 증가했다면 장기적으로 모니터링이 필요합니다.
Thread Dump와 Heap Dump
실행 중인 모든 스레드의 현재 상태를 스냅샷으로 저장합니다. kill -3 PID도 동일한 효과지만 Tomcat 로그(catalina.out)에 출력되므로 파일로 분리하는 jstack을 권장합니다. 응답 지연 또는 행(hang) 상황에서는 5초 간격으로 3회 이상 연속 수집해 변화를 비교합니다.
jstack $(jps -l | grep -v Jps | awk '{print $1}' | head -1) > /tmp/jvm-dumps/threaddump_$(date +%Y%m%d_%H%M%S).txt- ls -lh /tmp/jvm-dumps/threaddump_*.txt 로 파일 생성 먼저 확인, 그 다음 grep -c "BLOCKED" 로 BLOCKED 스레드 수 확인, 마지막으로 grep "Found.*deadlock" 으로 데드락 자동 감지 — 이 순서로 심각도 판단
- BLOCKED 스레드 기준: 0개=정상, 1~3개=경미한 경합(모니터링 필요), 5개 이상=서비스 응답 지연 발생 중, 데드락 감지=즉시 조치(재시작 불가피) — WAITING 스레드는 정상 범주이므로 BLOCKED에 집중
- BLOCKED 스레드 5개 이상인데 모두 "waiting to lock <0x동일주소>" 이면 → 단일 락 객체에 경합 집중 — 해당 객체를 보유한 스레드(RUNNABLE) 스택을 추적해 어떤 메서드가 락을 오래 보유하는지 확인
# Thread Dump 내 상태별 스레드 수 빠르게 집계
grep 'java.lang.Thread.State:' /tmp/jvm-dumps/threaddump_*.txt \
| awk '{print $NF}' | sort | uniq -c | sort -rn
42 WAITING
28 TIMED_WAITING
9 BLOCKED
3 RUNNABLE
BLOCKED가 9개라면 특정 락을 9개 스레드가 기다리는 중입니다. 어떤 락인지 waiting to lock 다음 객체 주소를 추적합니다.
Heap Dump 생성과 분석 도구
"OOM이 나서 재시작했습니다. 원인을 모르겠습니다." — 이 말이 3번 반복되면 팀장이 묻습니다. "힙 덤프는 남겼습니까?" OOM은 발생 순간 증거를 남기지 않으면 사후 분석이 불가능합니다. 프로세스가 죽기 전 힙 전체를 파일로 떠두는 것이 힙 덤프입니다. 이 파일 하나가 "무엇이 메모리를 먹었는가"를 밝혀주는 유일한 단서가 됩니다.
힙 덤프는 특정 시점 힙 전체를 파일로 복사합니다. OOM의 원인 객체를 찾는 데 사용합니다. 파일 크기가 힙 크기와 비슷하므로(2GB 힙 → 2GB 파일) 디스크 여유를 미리 확인해야 합니다. 힙 덤프 생성 중 JVM은 잠깐 멈춥니다.
# 실행 중인 프로세스에서 힙 덤프 수동 생성
jmap -dump:format=b,file=/tmp/jvm-dumps/heap_$(date +%Y%m%d_%H%M%S).hprof PID
# OOM 발생 시 자동 생성 (setenv.sh에 미리 추가)
# -XX:+HeapDumpOnOutOfMemoryError
# -XX:HeapDumpPath=/tmp/jvm-dumps/
# 힙 덤프 파일 크기 및 생성 확인
ls -lh /tmp/jvm-dumps/*.hprof
분석 도구:
| 도구 | 특징 | 사용법 |
|---|---|---|
| Eclipse MAT | 가장 강력, Leak Suspects 자동 분석 | .hprof 파일 직접 열기 |
| VisualVM | JDK 기본 포함, 연결/파일 분석 모두 가능 | 별도 설치 없이 사용 |
| JProfiler | 유료, 실시간 프로파일링 강력 | 라이선스 필요 |
힙 공간은 남아있지만 GC가 너무 자주, 너무 오래 실행되는 상황입니다. JVM 기본 정책은 "GC에 전체 시간의 98% 이상을 쓰면서도 힙의 2% 미만을 회수하면 OOM으로 처리한다"입니다. 실질적으로 힙 부족과 같은 의미입니다.
# 1. Full GC 빈도 즉시 확인
jstat -gcutil PID 2000 5
# FGC 컬럼이 2초마다 1씩 증가하면 연속 Full GC
# 2. 힙 덤프 즉시 생성 (프로세스 살아있는 동안)
jmap -dump:format=b,file=/tmp/jvm-dumps/heap_oom.hprof PID
# 3. Old Gen 사용률 확인
# O 컬럼이 95% 이상이면 힙 부족이 원인
# 단기 대응: 힙 크기 증가 (Xmx 상향 후 재시작)
# 근본 대응: 힙 덤프를 Eclipse MAT으로 분석해 누수 객체 찾기
-XX:+GCOverheadLimitExceeded 옵션으로 이 제한을 해제할 수 있지만, 원인을 해결하지 않는 임시방편입니다. 반드시 힙 덤프 분석으로 근본 원인을 찾아야 합니다.
CPU 사용률이 갑자기 100%에 근접하면서 응답 지연이 발생하는 경우, 배경에서 Full GC가 반복 실행 중일 가능성이 높습니다. Full GC는 힙 전체를 대상으로 STW를 일으키기 때문에 애플리케이션이 수 초간 멈춥니다.
# 1. GC 실시간 모니터링
jstat -gcutil PID 1000
# FGC 컬럼이 빠르게 증가하면 Full GC 반복 확인
# 2. CPU 높은 스레드 찾기
top -H -p PID
# 또는
ps -mo pid,tid,fname,user,pcpu -p PID
# 3. 높은 CPU 스레드가 GC 스레드인지 확인 (Thread Dump)
jstack PID | grep -E 'GC Task|VM Thread'
# "GC task thread" 스레드가 RUNNABLE이면 GC 과부하 확인
# 4. GC 로그로 Full GC 시간 확인 (Java 9+)
grep 'Pause Full' /logs/gc.log | tail -20
# 단기 대응: Old Gen이 꽉 찼으면 jcmd로 수동 GC 유도
jcmd PID GC.run
# 근본 대응: 힙 덤프 분석으로 Old Gen 점유 객체 확인
심화 — 컨테이너 안의 JVM은 힙 덤프도 없이 죽는다
심화: cgroup 한도·RSS의 실제 구성·OOMKill vs OutOfMemoryError
지금까지의 OOM 대응은 모두 '자바가 OutOfMemoryError를 던지고 힙 덤프를 남긴다'를 전제로 합니다. 그런데 컨테이너/쿠버네티스에서 도는 JVM은 힙 덤프 한 장 없이 조용히 죽는 방식이 따로 있습니다.
- 프로세스 RSS는
-Xmx가 아닙니다: JVM이 실제 점유하는 물리 메모리(RSS)는 힙(-Xmx)뿐 아니라 Metaspace, 스레드마다의 스택(스레드 수 ×-Xss), 다이렉트 버퍼(off-heap), GC·JIT 자료구조, 코드 캐시의 합입니다.-Xmx2g여도 RSS는 2.5~3g가 되기 쉽습니다. 컨테이너 메모리 한도를-Xmx와 똑같이 잡으면 off-heap이 한도를 밀어냅니다. - JVM은 컨테이너 한도를 알아야 합니다: Java 8 초기 버전(u191 이전)이나
UseContainerSupport가 꺼진 JVM은/proc/meminfo로 호스트 전체 RAM을 봅니다. 기본 힙을 호스트 RAM의 1/4로 잡으므로, 64g 호스트의 512m 컨테이너에서 힙을 16g로 산정하려다 곧바로 한도를 넘습니다. 요즘 JVM은UseContainerSupport(u191+ 기본 on)로 cgroup 한도를 읽고, 힙은-XX:MaxRAMPercentage로 한도의 비율로 지정합니다. - OOMKill과 OutOfMemoryError는 다릅니다: 힙이
-Xmx에 닿아 JVM이 던지는OutOfMemoryError는 자바 예외라 로그와 힙 덤프가 남습니다. 반면 프로세스 RSS가 cgroup 한도를 넘으면 커널 OOM killer가SIGKILL로 즉시 죽입니다 — 컨테이너는 exit code 137(128+9)로 끝나고, 이건 자바 밖의 일이라 자바 OOM 로그도 힙 덤프도 없습니다. 그냥 파드가 재시작됩니다.
핵심 설계: 컨테이너에서는 (1) UseContainerSupport를 유지하고(구형 JVM이면 업그레이드), (2) -XX:MaxRAMPercentage나 -Xmx로 힙을 한도의 50~75%만 잡아 off-heap 여유를 남기며, (3) 죽었을 때 자바 OOM 로그가 아니라 커널 로그(dmesg)와 컨테이너 exit code(137)로 OOMKill 여부를 먼저 가립니다.
상황: 쿠버네티스(또는 도커) 환경에서 파드가 주기적으로 재시작됩니다. HeapDumpOnOutOfMemoryError를 켜 뒀는데도 힙 덤프가 생기지 않고, 자바 OOM 로그도 없습니다. 유일한 단서는 컨테이너 종료 코드 137입니다.
원인: 자바가 OutOfMemoryError를 던진 게 아니라, 프로세스 RSS가 cgroup 메모리 한도를 넘어 커널 OOM killer가 SIGKILL(137 = 128+9)로 죽인 것입니다. 힙은 -Xmx 안이었지만 Metaspace·스레드 스택·다이렉트 버퍼 같은 off-heap이 더해져 RSS가 한도를 초과했습니다. 흔한 방아쇠는 컨테이너 한도와 -Xmx를 같게 잡았거나, UseContainerSupport를 모르는 구형 JVM이 호스트 RAM 기준으로 힙을 과다 산정한 경우입니다.
진단: 먼저 자바 OOM인지 커널 OOMKill인지 가립니다. kubectl describe pod의 Last State가 OOMKilled인지, 노드 dmesg에 Out of memory: Killed process ... java가 찍혔는지 확인합니다. NMT(-XX:NativeMemoryTracking)를 켜 뒀다면 jcmd PID VM.native_memory로 off-heap 내역을, 아니면 한도 대비 RSS 추이를 관측합니다.
해결: 컨테이너 한도보다 힙(-Xmx 또는 MaxRAMPercentage로 계산된 값)을 낮춰 off-heap 여유(한도의 25~50%)를 남깁니다. UseContainerSupport를 유지하고 구형 JVM이면 업그레이드합니다. 스레드 폭증·다이렉트 버퍼 누수가 원인이면 그쪽을 잡습니다. 자바 OOM이 아니므로 힙 덤프가 아니라 커널·NMT를 봐야 원인이 잡힌다는 것이 이 케이스의 핵심입니다(CPU/메모리/디스크 임계치 관리와 logrotate의 컨테이너 메모리 알람과 함께 설계).
온콜 시나리오: "JVM Heap 90%" 알람 수신
새벽 2시에 Heap 90% 알람이 오면 당황하지 말고 순서대로 확인합니다.
# 1단계: 현재 상태 빠르게 파악 (30초)
jps -l
# → Tomcat PID 확인
jstat -gcutil TOMCAT_PID 2000 5
# → Old Gen(O), Full GC(FGC) 수치 확인
# → Old Gen 95% 이상 + FGC 계속 증가면 위험
# 2단계: Thread Dump 수집 (1분)
jstack TOMCAT_PID > /tmp/jvm-dumps/td_$(date +%H%M%S).txt
jstack TOMCAT_PID > /tmp/jvm-dumps/td_$(date +%H%M%S)_2.txt
# → 5~10초 간격으로 2회 이상 수집
grep 'BLOCKED\|deadlock' /tmp/jvm-dumps/td_*.txt | head -20
# 3단계: Heap Dump 생성 (OOM 직전인 경우)
jmap -dump:format=b,file=/tmp/jvm-dumps/heap_$(date +%H%M%S).hprof TOMCAT_PID
# → 힙 크기만큼 시간 걸림, 디스크 여유 확인 필수
# 4단계: 즉각 조치 판단
# 서비스 영향이 시작됐으면 → Tomcat 재시작 (서비스 복구 우선)
# 아직 여유 있으면 → Heap Dump 먼저 수집 후 재시작
# 5단계: 재발 방지 — setenv.sh에 자동 덤프 옵션 확인
grep 'HeapDumpOnOutOfMemoryError' /opt/tomcat/bin/setenv.sh
# 없으면 추가 후 다음 재시작 때 적용
인계 시 반드시 남길 정보:
[JVM 장애 기록]
발생 시각: 2026-05-30 02:14 KST
대상 서비스: order-service (Tomcat PID: 12345)
증상: Heap 90% 알람 → OOM 발생 → 응답 불가
조치: Heap Dump 수집 후 Tomcat 재시작
파일: /tmp/jvm-dumps/heap_021420.hprof (2.1GB)
복구 시각: 02:22 KST
잔여 조치: Eclipse MAT으로 덤프 분석, 메모리 누수 원인 확인 필요
명령어·단축키 빠른 참조
이 모듈에서 다룬 JVM 진단 명령을 모았습니다. OOM·GC·스레드 문제를 서비스 중단 없이 실행 중 프로세스에서 파악합니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
jps -l | 실행 중 Java 프로세스·PID | 대상 Tomcat PID 특정 |
jstat -gcutil <pid> 1000 | GC 통계 실시간 | jstat -gcutil <pid> 2000 5 (Old Gen·FGC 추이) |
jstack <pid> | 스레드 덤프 | jstack <pid> | grep -A5 BLOCKED (락 경합) |
jmap -dump:format=b,file=… | 힙 덤프 생성 | jmap -dump:format=b,file=/tmp/heap.hprof <pid> |
jcmd <pid> GC.run | 수동 Full GC 유도 | jcmd <pid> VM.native_memory (off-heap 내역) |
kill -3 <pid> | 스레드 덤프(→catalina.out) | jstack 못 쓸 때 대체 |
top -H -p <pid> | 스레드별 CPU 확인 | GC 스레드가 CPU 점유 중인지 |
which jps jstat jstack jmap | JDK 진단 도구 존재 확인 | JRE만 있으면 도구 없음 |
grep 'Pause Full' gc.log | Full GC 정지시간 확인 | pause 길면 응답 지연 원인 |
grep 'Thread.State:' | uniq -c | 상태별 스레드 집계 | ... | awk '{print $NF}' | sort | uniq -c |
kubectl describe pod / dmesg | 커널 OOMKill 판별 | exit 137이면 OOMKilled·dmesg의 Killed process java |
grep HeapDumpOnOutOfMemoryError setenv.sh | 자동 덤프 옵션 확인 | 없으면 추가 후 다음 재시작에 적용 |
관련 모듈로 더 깊이:
- WAR 배포부터 server.xml 튜닝, 장애 대응까지 — JVM 위에서 도는 Tomcat의 구조와 기동 옵션을 함께 이해하기
- CPU/메모리/디스크 임계치 관리와 logrotate — Heap/메모리 임계치 알람을 설계해 OOM을 미리 잡는 법
- 애플리케이션 성능 모니터링과 대시보드 구성 — JMX Exporter로 JVM 메트릭을 Grafana 대시보드로 상시 관측하는 법
다음 모듈에서는 SSL/TLS 인증서 형식 변환과 Nginx/Tomcat 인증서 교체 절차를 다룹니다.