배포는 항상 긴장됩니다. 서버 3대에 WAR 파일을 배포하고, 각각 서비스를 재시작하고, 로그를 확인하고, 문제가 있으면 롤백해야 합니다. 매번 수동으로 하다 보면 한 서버를 빠뜨리거나 순서를 틀리는 실수가 납니다.
스크립트로 자동화하면 사람의 실수가 사라지고, 실행 기록이 남고, 언제든 같은 방식으로 반복할 수 있습니다.
- 1변수, 인자($1/$2), 조건문([[ ]]), 반복문(for/while/read)을 올바르게 작성할 수 있다
- 2set -e와 set -o pipefail로 에러 안전한 스크립트를 만들 수 있다
- 3trap으로 스크립트 실패 시 정리 작업을 수행할 수 있다
- 4logger로 스크립트 실행 기록을 syslog에 남길 수 있다
- 5디스크 임계치 알림, WAR 배포 자동화, 서비스 기동 점검 스크립트를 작성할 수 있다
bash --version | head -1mkdir -p ~/scripts && ls -la ~/scriptslogger -t test 'shell scripting module started' && sudo tail -2 /var/log/syslog 2>/dev/null || sudo tail -2 /var/log/messages 2>/dev/null스크립트 기본 구조
셸이 스크립트 한 줄을 실행하는 순서 — 읽기부터 종료코드까지 5단계
cp $SRC "$DST" 한 줄을 셸은 그냥 실행하지 않습니다. 줄을 읽고 → 토큰으로 파싱하고(인용부호 해석) → 확장(변수·글롭·명령치환)을 정해진 순서로 펼친 뒤 → 명령을 실행하고 → 종료코드를 남깁니다. 이 순서를 알면 따옴표를 왜 씌우는지, set -e가 왜 어떤 자리에서는 안 멈추는지, cron에서 왜 경로가 깨지는지가 한꺼번에 설명됩니다. 셸 스크립트 사고의 대부분은 문법을 몰라서가 아니라 이 실행·확장 순서를 오해해서 납니다.
[셸] cp "$SRC"/*.war "$DST"
│
① 읽기·라인 분리 (스크립트를 줄 단위로 읽어 명령을 구성)
│
② 파싱·토큰화 (단어·연산자 분리, 인용부호 해석)
│
③ 확장(정해진 순서) (중괄호 → 틸드 → 변수·명령치환·산술 → 단어분리 → 글롭)
│ → 이 시점에 "$SRC"가 실제 경로로, *.war가 실제 파일 목록으로 바뀜
│
④ 명령 실행 (PATH에서 cp를 찾아 확장된 인자로 실행)
│
⑤ 종료코드 전파 ($?에 결과 저장 → set -e·|| 가 이 값으로 판단)
▼
[셸] 다음 줄로 (set -e면 0이 아닐 때 여기서 종료)
각 단계에서 무슨 일이 일어나고, 막히면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 막히면 |
|---|---|---|
| ① 읽기 | 스크립트를 줄 단위로 읽어 하나의 명령으로 구성 | shebang(#!/usr/bin/env bash) 없거나 CRLF 줄바꿈 → bad interpreter·^M 오류 |
| ② 파싱·인용 | 단어·연산자를 나누고 따옴표를 해석 | 따옴표 짝 안 맞음 → unexpected EOF / 작은따옴표 안은 확장 안 됨(의도와 달리 리터럴로) |
| ③ 확장 | 변수·명령치환·글롭을 정해진 순서로 펼침 | 따옴표 없는 $VAR에 공백·빈값 → 단어분리로 인자가 쪼개지고 엉뚱한 글롭 / set -u면 미정의 변수 → unbound variable |
| ④ 실행 | PATH에서 명령을 찾아 확장된 인자로 실행 | PATH 누락(cron 환경) → command not found / 실행권한 없음 → Permission denied |
| ⑤ 종료코드 | 결과를 $?에 남기고 다음 흐름이 판단 | local V=$(실패명령)·파이프 중간·if/&& 앞은 실패해도 $?가 0으로 덮여 set -e가 못 잡음 |
즉 스크립트 사고의 대부분은 이 순서를 오해한 데서 옵니다 — 확장(③)이 실행(④)보다 먼저라, 따옴표 없는 변수는 이미 여러 인자로 쪼개진 뒤 명령에 넘어갑니다(그래서 rm $f가 위험). 그리고 set -e는 종료코드(⑤)를 보는데, if·&& 앞이나 local V=$(...)는 애초에 그 자리에서 0으로 판정돼 실패가 가려집니다. 이상 동작을 만나면 bash -x로 ③ 확장 결과(펼쳐진 실제 인자)를 눈으로 확인하는 것이 첫 단계입니다 — 대개 변수가 예상과 다르게 확장돼 있습니다. 아래에서는 이 종료코드(⑤)를 안전장치로 삼는 스크립트 기본 틀부터 봅니다.
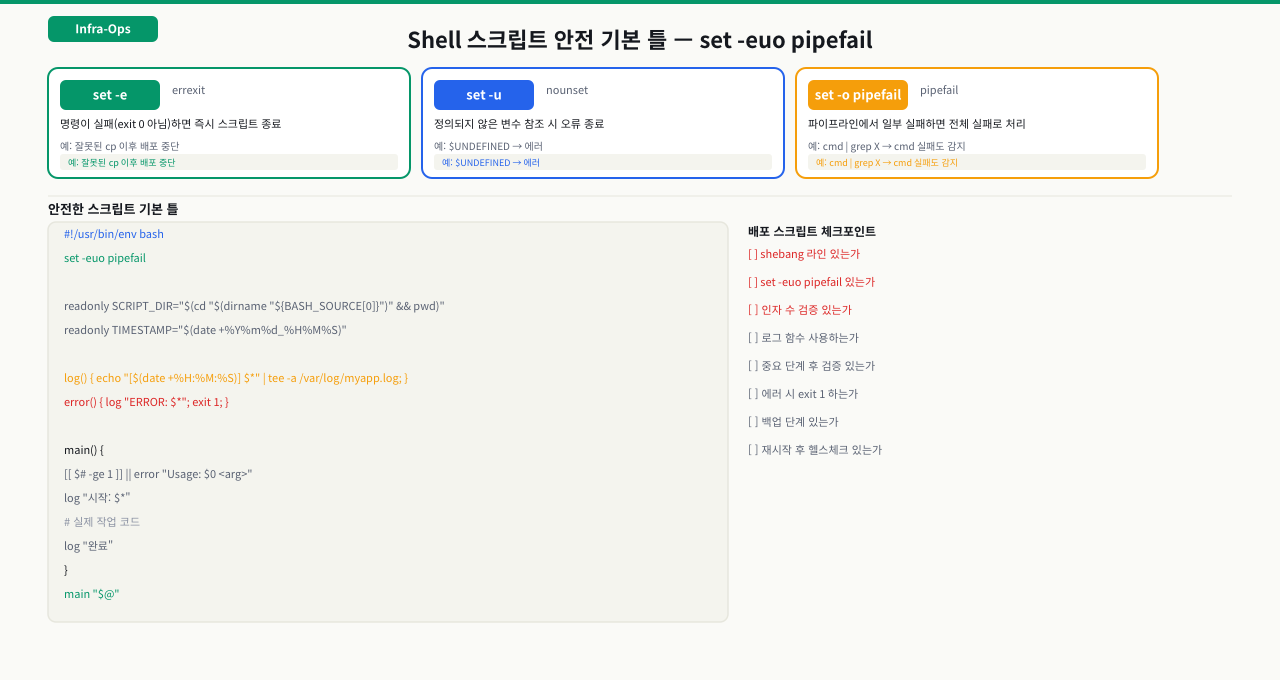
에러 안전한 스크립트 기본 틀
인프라 스크립트는 실패해도 멈추지 않으면 더 큰 사고를 만들 수 있습니다. set -e 없는 배포 스크립트는 중간 단계가 실패해도 다음 명령을 계속 실행하고, 그 결과는 종종 서비스 장애로 이어집니다. 어떤 상황에서도 안전하게 동작하는 스크립트를 만들려면 처음부터 올바른 틀 위에서 시작해야 합니다.
 확대
확대
배포 스크립트가 WAR 파일 복사에 실패했는데 오류를 무시하고 Tomcat을 재시작해버렸습니다. 이전 WAR 파일로 서비스가 올라왔고, "배포가 됐는데 변경 사항이 반영이 안 돼요"라는 제보가 들어왔습니다. set -e가 없는 스크립트는 중간에 실패해도 멈추지 않습니다. 로그도 없으면 언제, 어디서 실패했는지 추적조차 불가능합니다. 모든 인프라 스크립트는 이 틀로 시작합니다.
#!/usr/bin/env bash
# 파일명: deploy-app.sh
# 설명: 애플리케이션 배포 스크립트
# --- 안전장치 ---
set -e # 명령어 실패 시 즉시 종료
set -o pipefail # 파이프라인 중간 실패도 감지
set -u # 정의되지 않은 변수 사용 시 오류
# --- 상수 정의 ---
readonly SCRIPT_NAME="$(basename "$0")"
readonly LOG_TAG="deploy"
readonly TIMESTAMP="$(date +%Y%m%d_%H%M%S)"
# --- 함수 정의 ---
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $*"
logger -t "$LOG_TAG" "$*" # syslog에도 기록
}
error() {
echo "[ERROR] $*" >&2
logger -t "$LOG_TAG" "ERROR: $*"
exit 1
}
# --- 트랩 설정 (스크립트 종료 시 항상 실행) ---
cleanup() {
local exit_code=$?
if [[ $exit_code -ne 0 ]]; then
log "Script failed with exit code $exit_code"
fi
}
trap cleanup EXIT
# --- 인자 검증 ---
if [[ $# -lt 1 ]]; then
error "Usage: $SCRIPT_NAME <war_file>"
fi
WAR_FILE="$1"
if [[ ! -f "$WAR_FILE" ]]; then
error "File not found: $WAR_FILE"
fi
log "Starting deployment: $WAR_FILE"
# ... 실제 작업
log "Deployment completed"
왜 이 구조가 중요한가:
set -e: 중간에 실패해도 계속 진행하지 않음 → 망가진 상태 방지set -u:$DEPLOY_DIR을 잘못 쓰면 의도치 않게/에 작업하는 사고 방지trap cleanup EXIT: 스크립트가 어떻게 종료되든 정리 작업 실행logger: 크론탭으로 실행된 경우도 흔적이 남음
 확대
확대
변수, 인자, 조건문, 반복문
서버 10대에 동일한 명령을 수동으로 실행하다가 한 대를 빠뜨렸습니다. 다음 날 그 서버만 구버전으로 돌아가고 있었고, 버그 수정이 반영되지 않아 오류가 계속 나왔습니다. 반복문으로 서버 목록을 돌리고 조건문으로 이상 유무를 체크했다면 이 실수는 구조적으로 방지됩니다. 변수와 흐름 제어를 제대로 쓰지 못하면 스크립트는 반자동화에 머뭅니다.
변수와 인자:
# 변수 선언 (따옴표 항상 사용)
APP_DIR="/opt/tomcat"
APP_NAME="myapp"
MAX_RETRY=3
# 인자 처리
SCRIPT_NAME="$0" # 스크립트 이름
ARG1="$1" # 첫 번째 인자
ARG2="${2:-default}" # 두 번째 인자 (없으면 "default")
ARG_COUNT="$#" # 인자 개수
# 명령어 출력을 변수에 저장
CURRENT_DATE=$(date +%Y%m%d)
DISK_USAGE=$(df -h / | awk 'NR==2 {print $5}' | tr -d '%')
echo "오늘 날짜: $CURRENT_DATE, 디스크 사용: ${DISK_USAGE}%"
조건문:
# 파일/디렉터리 존재 확인
if [[ -f "/opt/app/config.yml" ]]; then
echo "설정 파일 존재"
elif [[ -d "/opt/app" ]]; then
echo "디렉터리만 존재"
else
echo "경로 없음"
fi
# 변수 비어있는지 확인
if [[ -z "$WAR_FILE" ]]; then
error "WAR_FILE이 비어있습니다"
fi
# 숫자 비교
if [[ "$DISK_USAGE" -ge 85 ]]; then
echo "경고: 디스크 사용률 ${DISK_USAGE}%"
fi
# 문자열 비교
if [[ "$ENV" == "production" ]]; then
echo "운영 환경"
fi
# 명령어 성공/실패 확인 (set -e 없이 수동 처리)
if systemctl is-active --quiet nginx; then
echo "nginx 실행 중"
else
echo "nginx 중지됨"
fi
반복문:
# for 반복문
for server in web01 web02 was01 was02; do
echo "점검 중: $server"
ssh "$server" "uptime && df -h / | tail -1"
done
# 파일 목록 반복
for war_file in /tmp/*.war; do
[[ -f "$war_file" ]] || continue # 파일 없으면 건너뜀
echo "처리: $war_file"
done
# while + read (파일에서 서버 목록 읽기)
while IFS= read -r server; do
[[ -z "$server" || "$server" =~ ^# ]] && continue # 빈 줄, 주석 건너뜀
echo "접속: $server"
ssh -o ConnectTimeout=5 "$server" "hostname"
done < /etc/server-list.txt
# C-style for (카운터)
for ((i=1; i<=3; i++)); do
echo "시도 $i/3"
curl -sf http://localhost:8080/health && break
sleep 5
done
1. set -euo pipefail 동작 확인
bash -c 'set -euo pipefail; echo "시작"; false; echo "이 줄은 출력 안 됨"'; echo "종료 코드: $?"2. 변수와 조건문 실습
DISK_USE=$(df / | awk 'NR==2 {print $5}' | tr -d '%'); echo "루트 파티션: ${DISK_USE}%"; [[ $DISK_USE -gt 5 ]] && echo '사용 중' || echo '거의 비어 있음'3. 반복문으로 다중 서비스 점검
for svc in nginx sshd cron; do systemctl is-active "$svc" &>/dev/null && echo "$svc: 실행 중" || echo "$svc: 중지됨"; done- set -e 스크립트에서 false 명령어 실행 후 echo가 출력되지 않고 즉시 종료되는지 먼저 확인 — 출력이 나오면 set -e가 적용되지 않은 것으로 #!/usr/bin/env bash 다음 줄에 위치했는지 점검
- DISK_USE=${use%%%} 패턴에서 변수에 숫자만 남아야 정상 — % 기호가 남아있으면 [ "$pct" -gt "$THRESHOLD" ] 비교에서 integer expression error 발생
- 반복문에서 실제 서버에 없는 서비스가 "중지됨"으로 표시되면 정상 — "명령어 없음" 오류가 나면 systemctl이 PATH에 없거나 sudo 권한 필요. 서비스 5개 이상 점검 시 병렬 실행(&) 고려
실무 스크립트 3가지
실무 스크립트 1: 디스크 임계치 알림
매일 아침 수동으로 df -h를 확인하다가 하루를 빠뜨렸는데, 그날 디스크가 100%가 됐습니다. 로그가 넘쳐서 새 파일이 만들어지지 않았고, Tomcat이 로그를 쓰지 못해 장애로 이어졌습니다. 임계치를 자동으로 감지해서 알려주는 스크립트가 있었다면 아무도 없던 새벽에 미리 알 수 있었습니다.
#!/usr/bin/env bash
# disk-check.sh — 디스크 사용률 점검 및 알림
set -euo pipefail
readonly THRESHOLD=85 # 경고 기준 (%)
readonly CRITICAL=95 # 위험 기준 (%)
readonly LOG_TAG="disk-check"
readonly HOSTNAME=$(hostname)
log() { logger -t "$LOG_TAG" "$*"; echo "[$(date '+%H:%M:%S')] $*"; }
check_disk() {
local mount_point="$1"
local usage
usage=$(df -h "$mount_point" | awk 'NR==2 {print $5}' | tr -d '%')
if [[ "$usage" -ge "$CRITICAL" ]]; then
log "CRITICAL: $HOSTNAME $mount_point 디스크 ${usage}% — 즉시 조치 필요"
# 실제 환경: curl -X POST $SLACK_WEBHOOK -d '{"text":"..."}'
return 1
elif [[ "$usage" -ge "$THRESHOLD" ]]; then
log "WARNING: $HOSTNAME $mount_point 디스크 ${usage}%"
return 0
else
log "OK: $mount_point ${usage}%"
return 0
fi
}
# inode 사용률도 함께 체크
check_inode() {
local mount_point="$1"
local inode_usage
inode_usage=$(df -i "$mount_point" | awk 'NR==2 {print $5}' | tr -d '%')
if [[ "$inode_usage" -ge "$THRESHOLD" ]]; then
log "WARNING: $HOSTNAME $mount_point inode ${inode_usage}%"
fi
}
# 점검할 마운트 포인트 목록
MOUNT_POINTS=("/" "/var" "/opt" "/data")
exit_code=0
for mp in "${MOUNT_POINTS[@]}"; do
# 마운트 포인트가 존재하는지 확인
mountpoint -q "$mp" 2>/dev/null || continue
check_disk "$mp" || exit_code=1
check_inode "$mp"
done
exit $exit_code
# crontab에 등록 (매 10분마다 실행)
# crontab -e
*/10 * * * * /opt/scripts/disk-check.sh >> /var/log/disk-check.log 2>&1
1. 스크립트 디렉터리 생성
mkdir -p ~/scripts && echo '디렉터리 준비 완료'2. 디스크 점검 스크립트 생성
cat > ~/scripts/disk-check.sh << 'EOF'
#!/usr/bin/env bash
set -euo pipefail
THRESHOLD=${1:-80}
echo "=== 디스크 점검 (임계: ${THRESHOLD}%) ==="
df -h | awk 'NR>1 && /^\/dev/' | while read fs size used avail use mp; do
pct=${use%%%}
if [[ $pct -ge $THRESHOLD ]]; then
echo "[경고] $mp: ${pct}% (용량: $size, 사용: $used)"
else
echo "[정상] $mp: ${pct}%"
fi
done
EOF
chmod +x ~/scripts/disk-check.sh && echo '생성 완료'3. 스크립트 실행
bash ~/scripts/disk-check.sh 50- chmod +x 없이 실행 시 Permission denied 오류 먼저 확인 — ls -la 로 실행 권한(-rwxr-xr-x)이 있는지 본 다음 스크립트 내용 점검으로 넘어간다
- 임계값 50으로 실행 시 50% 이상 파티션이 "[경고]"로 표시되면 정상 — 아무것도 표시 안 되면 df -h 파싱이 잘못된 것. pct=${use%%%} 위치가 use 변수 할당 이후인지 확인
- pct에 숫자 대신 "%"가 포함된 채로 비교하면 integer expression expected 오류 — 이 오류는 조용히 스크립트를 종료하지 않아 잘못된 알림이 발송됨. $1로 임계값을 인자로 받으면 재사용성과 테스트 용이성 모두 높아짐
실무 스크립트 2: WAR 배포 자동화
배포할 때마다 "백업, 중지, 복사, 시작, 확인"을 수동으로 하다 보면 한 단계씩 빠뜨리게 됩니다. 백업을 빠뜨리면 배포 후 문제가 생겼을 때 이전 버전으로 돌아가지 못합니다. 확인 단계가 없으면 서비스가 실제로 살아났는지 모른 채 배포가 완료됐다고 보고하게 됩니다. 이 스크립트 하나로 사람의 실수를 없애고 동일한 순서를 보장합니다.
#!/usr/bin/env bash
# deploy-war.sh — Tomcat WAR 파일 배포 스크립트
# 사용: ./deploy-war.sh /tmp/myapp-1.2.3.war [서버명]
set -euo pipefail
# --- 설정 ---
readonly TOMCAT_DIR="/opt/tomcat"
readonly WEBAPPS_DIR="$TOMCAT_DIR/webapps"
readonly BACKUP_DIR="$TOMCAT_DIR/webapps-backup"
readonly TOMCAT_SERVICE="tomcat"
readonly TOMCAT_USER="tomcat"
readonly LOG_TAG="deploy-war"
readonly TIMESTAMP=$(date +%Y%m%d_%H%M%S)
log() { echo "[$(date '+%H:%M:%S')] $*"; logger -t "$LOG_TAG" "$*"; }
error() { echo "[ERROR] $*" >&2; logger -t "$LOG_TAG" "ERROR: $*"; exit 1; }
# 인자 검증
[[ $# -ge 1 ]] || error "Usage: $(basename $0) <war_file>"
WAR_FILE="$1"
[[ -f "$WAR_FILE" ]] || error "WAR 파일 없음: $WAR_FILE"
APP_NAME=$(basename "$WAR_FILE" .war) # myapp-1.2.3
log "배포 시작: $APP_NAME"
# 1. 사전 백업
mkdir -p "$BACKUP_DIR"
if [[ -d "$WEBAPPS_DIR/$APP_NAME" ]]; then
tar -czf "$BACKUP_DIR/${APP_NAME}_${TIMESTAMP}.tar.gz" \
-C "$WEBAPPS_DIR" "$APP_NAME"
log "기존 버전 백업: ${APP_NAME}_${TIMESTAMP}.tar.gz"
fi
if [[ -f "$WEBAPPS_DIR/${APP_NAME}.war" ]]; then
cp "$WEBAPPS_DIR/${APP_NAME}.war" \
"$BACKUP_DIR/${APP_NAME}.war.${TIMESTAMP}"
fi
# 2. Tomcat 중지
log "Tomcat 중지 중..."
sudo systemctl stop "$TOMCAT_SERVICE"
# 중지 확인 (최대 30초 대기)
for i in $(seq 1 30); do
if ! systemctl is-active --quiet "$TOMCAT_SERVICE"; then
break
fi
sleep 1
done
systemctl is-active --quiet "$TOMCAT_SERVICE" && error "Tomcat 중지 실패"
# 3. 기존 배포 디렉터리 삭제 (war 파일 자동 압축 해제 방지)
TARGET_DIR="${WEBAPPS_DIR}/${APP_NAME}"
case "$TARGET_DIR" in
/opt/tomcat/webapps/*) ;;
*) error "허용되지 않은 배포 경로: $TARGET_DIR" ;;
esac
test -n "$APP_NAME" && test "$APP_NAME" != "ROOT" || error "APP_NAME 확인 필요"
test "$(readlink -f "$TARGET_DIR")" = "$TARGET_DIR" || error "심볼릭 링크/경로 검증 실패"
test -d "$TARGET_DIR" && rm -rf -- "$TARGET_DIR"
rm -f "$WEBAPPS_DIR/${APP_NAME}.war"
# 4. WAR 파일 복사 및 권한 설정
log "WAR 파일 배포 중..."
cp "$WAR_FILE" "$WEBAPPS_DIR/"
chown "${TOMCAT_USER}:${TOMCAT_USER}" "$WEBAPPS_DIR/${APP_NAME}.war"
chmod 644 "$WEBAPPS_DIR/${APP_NAME}.war"
# 5. Tomcat 시작
log "Tomcat 시작 중..."
sudo systemctl start "$TOMCAT_SERVICE"
# 6. 기동 확인 (최대 60초 대기)
log "서비스 기동 확인 중..."
for i in $(seq 1 60); do
if curl -sf http://localhost:8080/${APP_NAME}/health > /dev/null 2>&1; then
log "배포 완료! ($i초 소요)"
logger -t "$LOG_TAG" "SUCCESS: $APP_NAME deployed in ${i}s"
exit 0
fi
sleep 1
done
# 7. 기동 실패 → 자동 롤백
error "서비스 기동 실패 — 롤백을 수동으로 수행하세요: $BACKUP_DIR"
1. 배포 디렉터리 구조 준비
mkdir -p /tmp/deploy-test/{webapps,backup} && echo 'v1.0-original' > /tmp/deploy-test/webapps/app.war && echo '준비 완료'2. 배포 핵심 로직 실습
WAR_DIR=/tmp/deploy-test/webapps; BACKUP_DIR=/tmp/deploy-test/backup; TS=$(date +%Y%m%d_%H%M%S); [[ -f $WAR_DIR/app.war ]] && cp $WAR_DIR/app.war $BACKUP_DIR/app-${TS}.war && echo "백업 완료: app-${TS}.war"; echo 'v2.0-new' > /tmp/new-app.war; cp /tmp/new-app.war $WAR_DIR/app.war && echo '배포 완료'; ls -la $BACKUP_DIR/3. 배포 검증
cat /tmp/deploy-test/webapps/app.war && echo '' && ls /tmp/deploy-test/backup/- backup 디렉터리에서 타임스탬프 포함 파일명을 먼저 확인(ls -lh backup/) — 파일이 없으면 백업 단계에서 실패한 것. set -e 없이 작성했으면 cp 실패 후에도 배포가 진행돼 롤백 불가 상태
- 배포 후 webapps/app.war 내용이 v2.0-new로 변경됐는지 확인 — 변경 안 됐으면 cp 명령의 소스/대상 경로 오류. set -euo pipefail 없는 스크립트는 cp 실패를 무시하고 계속 실행됨
- || { echo "실패"; exit 1; } 패턴이 각 핵심 명령어(cp, systemctl)마다 있어야 중간 실패 감지 가능 — 패턴 없이 set -e만 의존하면 서브셸이나 파이프에서 발생한 에러를 놓칠 수 있음
실무 스크립트 3: 서비스 기동 상태 점검
WAS 서버 8대 중 한 대에서 서비스가 내려가 있었는데
 확대
, 로드밸런서가 해당 서버를 계속 살아있다고 판단해 트래픽을 보내고 있었습니다. 수동으로 8대를 일일이 확인하는 루틴을 만들어두지 않아서 30분 뒤에야 발견했습니다. 모든 서버를 동시에 점검하고 이상 서버만 출력하는 스크립트가 있으면 문제를 빠르게 찾을 수 있습니다.
확대
, 로드밸런서가 해당 서버를 계속 살아있다고 판단해 트래픽을 보내고 있었습니다. 수동으로 8대를 일일이 확인하는 루틴을 만들어두지 않아서 30분 뒤에야 발견했습니다. 모든 서버를 동시에 점검하고 이상 서버만 출력하는 스크립트가 있으면 문제를 빠르게 찾을 수 있습니다.
#!/usr/bin/env bash
# service-check.sh — 다중 서버 서비스 상태 일괄 점검
set -euo pipefail
# --- 설정 ---
readonly SERVER_LIST="/etc/infra/was-servers.txt" # 서버 목록 파일
readonly SSH_OPTS="-o ConnectTimeout=5 -o StrictHostKeyChecking=yes -o BatchMode=yes"
readonly LOG_TAG="service-check"
log() { logger -t "$LOG_TAG" "$*"; }
# 단일 서버 점검 함수
check_server() {
local server="$1"
local result=""
local status="OK"
# SSH로 원격 점검 명령 실행
result=$(ssh $SSH_OPTS "$server" '
# 서비스 상태
TOMCAT=$(systemctl is-active tomcat 2>/dev/null || echo "unknown")
NGINX=$(systemctl is-active nginx 2>/dev/null || echo "not-installed")
# 헬스체크 URL 응답
HEALTH=$(curl -sf -o /dev/null -w "%{http_code}" http://localhost:8080/health 2>/dev/null || echo "fail")
# 리소스 상태
DISK=$(df -h / | awk "NR==2{print \$5}")
MEM_AVAIL=$(free -m | awk "NR==2{print \$7}")
LOAD=$(uptime | awk -F"average:" "{print \$2}" | awk "{print \$1}" | tr -d ",")
echo "tomcat=${TOMCAT} nginx=${NGINX} health=${HEALTH} disk=${DISK} mem_avail=${MEM_AVAIL}MB load=${LOAD}"
' 2>/dev/null || echo "SSH_FAILED")
# 결과 파싱 및 이상 여부 판단
if [[ "$result" == "SSH_FAILED" ]]; then
status="SSH_FAIL"
elif echo "$result" | grep -q "tomcat=failed\|tomcat=inactive"; then
status="TOMCAT_DOWN"
elif echo "$result" | grep -q "health=fail\|health=503\|health=502"; then
status="HEALTH_FAIL"
fi
printf "%-15s %-10s %s\n" "$server" "[$status]" "$result"
log "$server $status: $result"
}
# 서버 목록 파일 생성 (없는 경우 예시)
if [[ ! -f "$SERVER_LIST" ]]; then
echo "서버 목록 파일 없음: $SERVER_LIST"
echo "예시 파일 형식:"
echo " 10.0.1.11 # was01-prd"
echo " 10.0.1.12 # was02-prd"
exit 0
fi
echo "=================================================="
echo " 서비스 기동 상태 점검 — $(date '+%Y-%m-%d %H:%M:%S')"
echo "=================================================="
printf "%-15s %-10s %s\n" "SERVER" "STATUS" "DETAIL"
echo "--------------------------------------------------"
FAIL_COUNT=0
while IFS= read -r line; do
# 빈 줄, 주석 건너뜀
[[ -z "$line" || "$line" =~ ^[[:space:]]*# ]] && continue
server=$(echo "$line" | awk '{print $1}')
result_line=$(check_server "$server")
echo "$result_line"
echo "$result_line" | grep -qv '\[OK\]' && ((FAIL_COUNT++)) || true
done < "$SERVER_LIST"
echo "=================================================="
echo "점검 완료: 이상 서버 ${FAIL_COUNT}대"
log "점검 완료: 이상 ${FAIL_COUNT}대"
[[ "$FAIL_COUNT" -gt 0 ]] && exit 1 || exit 0
# 사용법
chmod +x ~/scripts/service-check.sh
# 직접 실행
~/scripts/service-check.sh
# crontab — 매 5분마다 실행
*/5 * * * * /opt/scripts/service-check.sh >> /var/log/service-check.log 2>&1
스크립트 파일 생성
cat > ~/scripts/disk-simple.sh << 'EOF'
#!/usr/bin/env bash
set -euo pipefail
THRESHOLD=80
df -h | awk 'NR>1 && /^\/dev/' | while read fs size used avail use mp; do
pct=${use%%%}
if [[ $pct -ge $THRESHOLD ]]; then
echo "WARNING: $mp 디스크 ${pct}% (임계: ${THRESHOLD}%)"
logger -t disk-check "WARNING: $(hostname) $mp ${pct}%"
fi
done
EOF
chmod +x ~/scripts/disk-simple.sh스크립트 실행 테스트
bash ~/scripts/disk-simple.sh; echo 'Exit code:' $?syslog 기록 확인
logger -t test-script 'practice session running' && sudo grep 'test-script' /var/log/syslog 2>/dev/null || sudo grep 'test-script' /var/log/messages 2>/dev/null || journalctl -t test-script -n 3 --no-pagerset -e 동작 확인
bash -c 'set -e; echo start; false; echo this_should_not_print'; echo "exit: $?"조건문 및 파일 확인 실습
FILE=/etc/hostname; if [[ -f $FILE ]]; then echo "$FILE 존재: $(cat $FILE)"; else echo "$FILE 없음"; fi- disk-simple.sh 실행 시 출력을 먼저 확인 — 80% 이상 파티션에 WARNING이 나오면 정상. 아무 출력도 없으면 df -h 파싱 실패 또는 임계값 조건이 맞지 않는 것
- bash -c "set -e; false; echo test" 실행 시 "test"가 출력되지 않아야 set -e 정상 동작 — 출력되면 false가 파이프나 && 뒤에 있어 set -e가 무시된 구조
- logger 실행 후 journalctl -t <태그명> --since "1 min ago"로 즉시 확인 — 로그가 없으면 systemd-journald가 실행 중인지 확인. 로그가 있고 Exit code: 0이면 스크립트 정상 완료로 cron 등록 준비 완료
심화 — 안전장치의 한계: set -e는 만능이 아니다
심화: set -e의 함정 — 켜 놨는데도 안 멈추는 자리들
set -euo pipefail을 스크립트 맨 위에 넣는 습관은 옳습니다. 하지만 그것을 '무조건 실패하면 멈추는 스위치'로 믿으면, 정작 실패가 조용히 지나가는 자리에서 사고가 납니다. set -e가 일부러 발동하지 않는 경우들을 알아야 진짜 안전한 스크립트가 됩니다.
- 조건으로 쓰인 명령:
if cmd; then ...,while cmd; do ...의cmd는 실패해도 종료되지 않습니다(성공/실패를 판단하는 게 목적이니 당연).until,!뒤도 마찬가지입니다. &&·||체인의 앞부분:cmd1 && cmd2에서cmd1이 실패하면set -e가 안 잡고 그냥cmd2를 건너뜁니다.A || B형태도 A의 실패를 '처리된 것'으로 봅니다.- 파이프라인 중간:
pipefail이 없으면a | b의 exit code는 마지막b만 따릅니다.pipefail을 켜야 중간 실패도 잡힙니다(이 모듈 본문에서 다룬 이유). local/declare와 명령 치환의 결합: 가장 악명 높은 함정입니다.local OUT=$(cmd)는cmd가 실패해도local선언 자체의 exit code(0) 가 최종값이 돼$?가 0으로 덮입니다. 선언과 대입을 나눠local OUT; OUT=$(cmd)로 써야cmd의 실패가 드러납니다.
그래서 성숙한 스크립트는 set -e에만 기대지 않고, 정말 실패하면 안 되는 핵심 단계에는 명시적으로 || error "..." 를 붙입니다. set -e는 '깜빡한 실패'를 잡는 그물이지, 설계된 방어선이 아닙니다.
상황: 배포 스크립트에 set -euo pipefail을 분명히 넣었습니다. 그런데 헬스체크 URL이 죽어 있었는데도 스크립트가 멈추지 않고 끝까지 진행돼 '배포 성공'으로 보고했습니다. 정작 실패해야 할 곳에서 안 멈춘 것입니다.
원인: 문제의 줄이 함수 안에서 local STATUS=$(curl -fs "$HEALTH_URL") 형태였습니다. curl -f는 HTTP 오류에서 실패를 반환하지만, local STATUS=$(...)처럼 선언과 명령 치환을 한 줄에 쓰면 최종 exit code가 local 명령의 성공(0)으로 덮여 set -e가 실패를 못 봅니다. 결과적으로 죽은 헬스체크가 '통과'로 처리됐습니다.
진단: 실패가 무시된 정확한 줄을 좁힙니다. bash -x script.sh로 추적하면 curl이 비정상 종료했는데도 흐름이 이어지는 지점이 보입니다. local/declare와 $(...)가 한 줄에 있는 곳, 그리고 if·&&·파이프 안에 숨은 핵심 명령을 훑습니다.
해결: 선언과 대입을 분리합니다 — local STATUS; STATUS=$(curl -fs "$HEALTH_URL"). 그러면 curl 실패가 그대로 드러나 set -e가 멈춥니다. 더 확실하게는 핵심 단계에 명시적 검증을 답니다: curl -fs "$HEALTH_URL" || error "헬스체크 실패". set -e는 보조 그물일 뿐, 배포 성패를 가르는 단계는 손으로 한 번 더 확인하는 게 안전합니다.
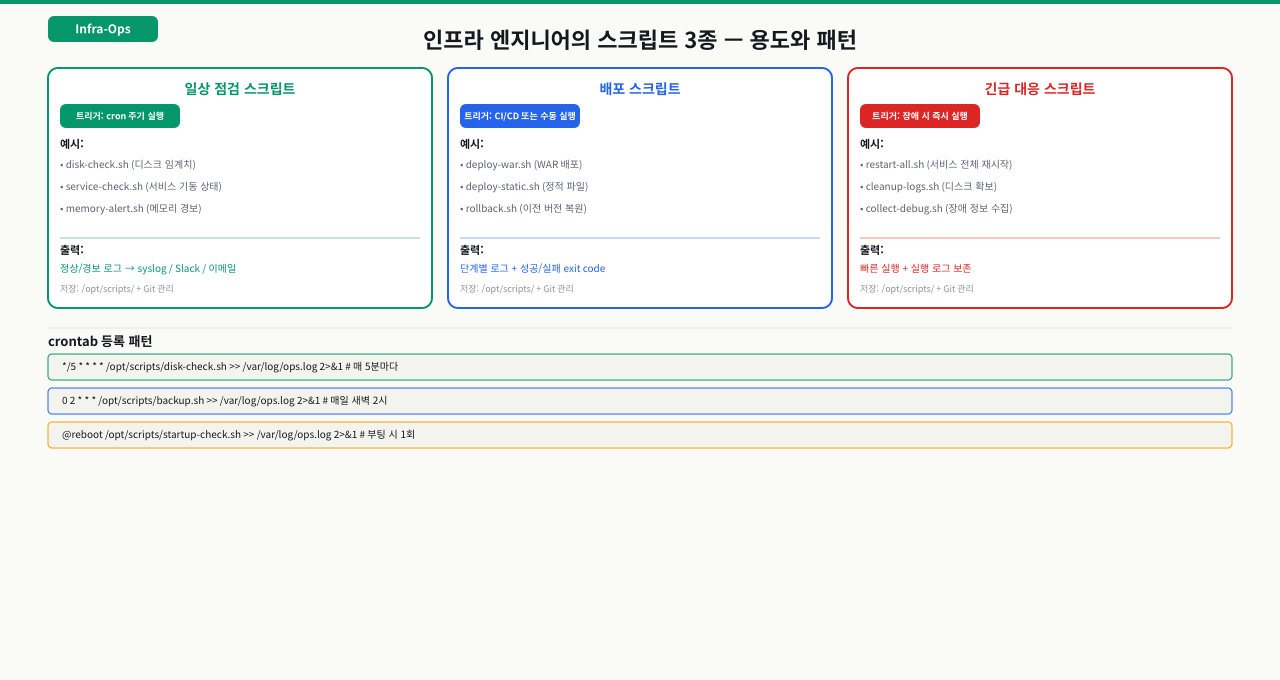
실제 업무에서 이 지식이 쓰이는 상황:
인프라 엔지니어가 작성하는 스크립트는 크게 세 종류입니다:
- 일상 점검 스크립트 (disk-check, service-check): 크론탭으로 실행, 이상 감지 시 알림
- 배포 스크립트 (deploy-war, deploy-static): 배포 프로세스의 표준화, 사람의 실수 제거
- 긴급 대응 스크립트 (restart-all, cleanup-logs): 장애 시 빠른 대응용
스크립트를 ~/scripts/ 또는 /opt/scripts/에 정리하고 Git으로 관리하면, 팀원 누구나 같은 방식으로 작업할 수 있고 변경 이력도 추적됩니다.
작은 스크립트부터 시작하세요. 매주 수동으로 하는 작업 하나를 스크립트로 만들면 3개월 후에는 운영의 많은 부분이 자동화됩니다.
명령어·단축키 빠른 참조
에러 안전한 인프라 스크립트 작성에서 쓴 bash 옵션·구문·명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
set -euo pipefail | 안전 3종(실패 즉시 종료·파이프·미정의 변수) | 모든 스크립트 2번째 줄에 배치 |
trap … EXIT | 종료 시 정리 작업 보장 | trap cleanup EXIT |
logger -t | 실행 기록을 syslog에 남김 | logger -t deploy "started", 확인 journalctl -t deploy |
[[ … ]] | 조건 검사(파일·변수·비교) | [[ -f "$f" ]], [[ -z "$v" ]], [[ "$n" -ge 85 ]] |
${VAR:-기본값} | 미정의 변수 기본값(set -u 안전) | THRESHOLD=${1:-80} |
for / while read | 서버·파일 목록 반복 | for s in web01 web02; do …, while IFS= read -r s; do … done < list |
local VAR; VAR=$(…) | 명령 치환 실패 감지(한 줄 결합 금지) | local OUT; OUT=$(curl -f …) |
systemctl is-active --quiet | 서비스 상태로 분기 | systemctl is-active --quiet nginx && echo up |
curl -sf | 헬스체크(실패 시 비정상 종료) | curl -sf http://localhost:8080/health || error 실패 |
ssh -o … | 원격 일괄 점검 옵션 | ssh -o ConnectTimeout=5 -o BatchMode=yes "$s" uptime |
awk / tr -d | 출력 파싱(사용률 추출) | df -h / | awk 'NR==2{print $5}' | tr -d '%' |
bash -x | 스크립트 실행 추적 디버깅 | bash -x deploy.sh |
chmod +x | 스크립트 실행 권한 부여 | chmod +x ~/scripts/disk-check.sh |
crontab */N * * * * | 스크립트 정기 실행 등록 | */10 * * * * /opt/scripts/disk-check.sh >> log 2>&1 |
관련 모듈로 더 깊이:
- Cron/Quartz 장애 분석과 배치 재처리 실무 — 작성한 스크립트를 cron/배치로 정기 실행하고 운영하는 법
- SFTP/배치 파일 송수신과 외부 기관 연계 실무 — SFTP 전송과 파일 배치 처리를 스크립트로 자동화하는 패턴
- 프로세스(ps), 포트(netstat), 리소스(top) 모니터링 실무 — 점검 스크립트가 들여다볼 프로세스·포트·리소스 상태 읽는 법
다음 모듈에서는 Web/WAS 구조 — Nginx, Apache, Tomcat의 역할과 실제 설정을 다룹니다.