서비스를 운영하다 보면 어느 날 갑자기 디스크가 꽉 차거나, 메모리 OOM으로 프로세스가 죽거나, 로그 파일이 수 GB로 불어나 있는 상황을 만납니다. 모두 "미리 알았더라면" 막을 수 있었던 일입니다.
모니터링은 장애가 나기 전에 이상 징후를 잡는 것이 목표입니다. CPU 80%가 5분 지속되면 알람을 보내고, 디스크 90%가 되면 즉각 대응하고, 로그 파일은 자동으로 정리되도록 설정해두는 것 — 그것이 이 모듈의 핵심입니다.
- 1CPU, 메모리, 디스크, inode 각각의 임계치 기준을 설명하고 단계별 대응을 판단할 수 있다
- 2logrotate 설정 파일을 작성하고 compress/delaycompress의 의미를 이해할 수 있다
- 3jstat -gcutil로 JVM Heap 사용률을 확인하고 이상 징후를 판단할 수 있다
- 4로그 폭증 발생 시 원인 파일을 찾고 임시 대응을 수행할 수 있다
- 5Zabbix, Nagios, CloudWatch의 역할을 설명하고 어떤 상황에 쓰이는지 구분할 수 있다
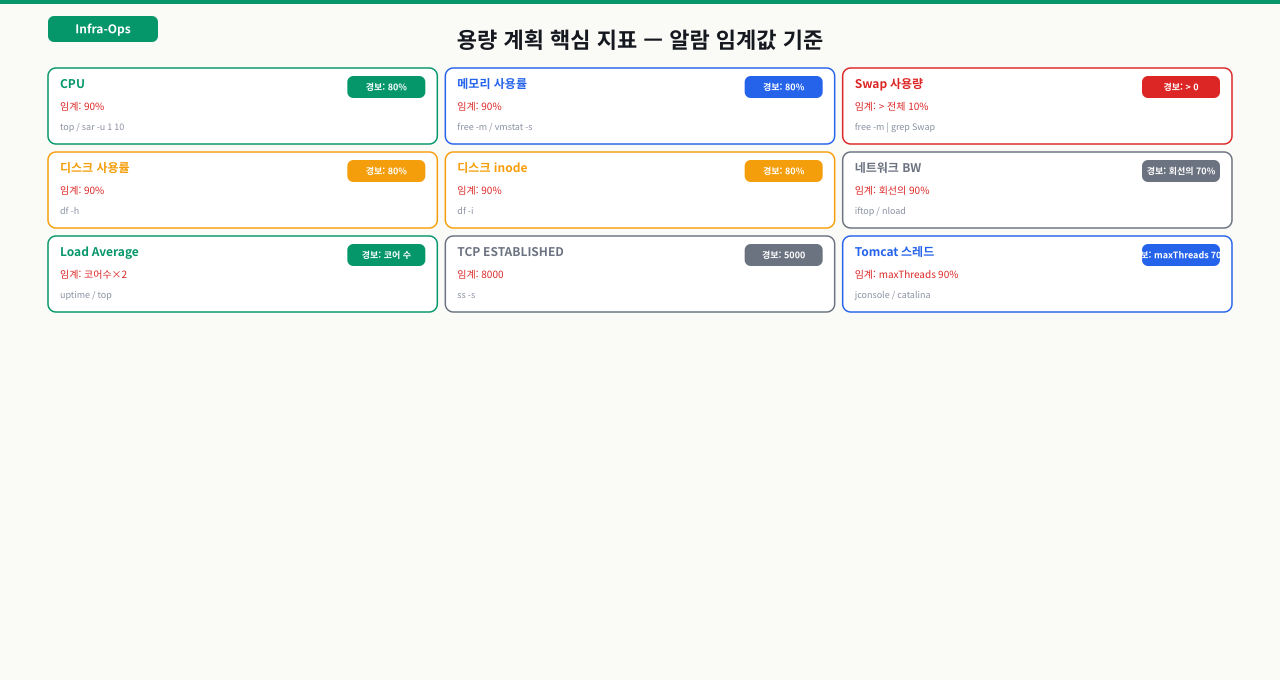
리소스 임계치 기준
언제 경고를 보낼 것인가 — 임계치 설계
팀 슬랙에 하루에 알람이 50건씩 옵니다. 절반은 CPU가 잠깐 70%를 넘었다가 내려간 것들입니다. 처음에는 확인했지만, 세 번째 주부터는 무시하기 시작했습니다. 그리고 진짜 장애가 났을 때 알람을 놓쳤습니다. 알람이 너무 많으면 아무도 보지 않게 되고, 너무 적으면 장애를 늦게 감지합니다. 임계치 설계는 이 균형을 맞추는 작업입니다.
임계치(threshold) 설정에 정답은 없지만, 현업에서 검증된 출발점은 있습니다. 너무 낮게 설정하면 false positive 알람이 쏟아져 팀이 피로해지고, 너무 높게 설정하면 정작 중요한 장애를 놓칩니다. 아래 기준을 서비스 특성에 맞게 조정하면서 시작하는 것을 권장합니다.
 확대
확대
CPU:
# 현재 CPU 사용률 확인
top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d. -f1
# 5분 평균 부하 확인 (1분/5분/15분 로드 에버리지)
uptime
# 예시: load average: 0.52, 1.20, 0.98
# load average가 CPU 코어 수를 초과하면 포화 상태
nproc # 코어 수 확인
| 수준 | 기준 | 대응 |
|---|---|---|
| 정상 | 80% 미만 | 모니터링 유지 |
| 경고 | 80% 이상 5분 지속 | 원인 프로세스 확인 |
| 위험 | 95% 이상 10분 지속 | 즉각 스케일업/프로세스 종료 검토 |
메모리:
# 사용 가능 메모리 확인
free -m
# available 컬럼이 핵심 — cached/buffers 제외한 실제 가용 메모리
# 메모리 상위 프로세스 5개
ps aux --sort=-%mem | head -6
| 수준 | 기준 | 대응 |
|---|---|---|
| 정상 | available > 20% | 유지 |
| 경고 | available < 10% | 대용량 프로세스 확인, 스왑 점검 |
| 위험 | available < 5% | OOM Killer 발동 전 즉각 조치 필요 |
디스크:
# 파일시스템별 사용률
df -h
# inode 사용률 (파일 수 한도)
df -i
# 디렉터리별 용량 (내림차순 상위 10개)
du -sh /var/log/* 2>/dev/null | sort -rh | head -10
| 수준 | 기준 | 대응 |
|---|---|---|
| 경고 | 80% | 정리 계획 수립, 오래된 로그/백업 확인 |
| 긴급 | 90% | 즉각 원인 파일 찾아 정리 |
| 불능 | 100% | 로그 기록 실패, DB 쓰기 오류, 서비스 중단 |
inode가 100%라면 파일 수가 한도를 초과한 것으로, 용량은 남아도 파일을 새로 만들 수 없습니다. 소규모 임시 파일이 폭발적으로 생성되는 버그가 있을 때 자주 발생합니다.
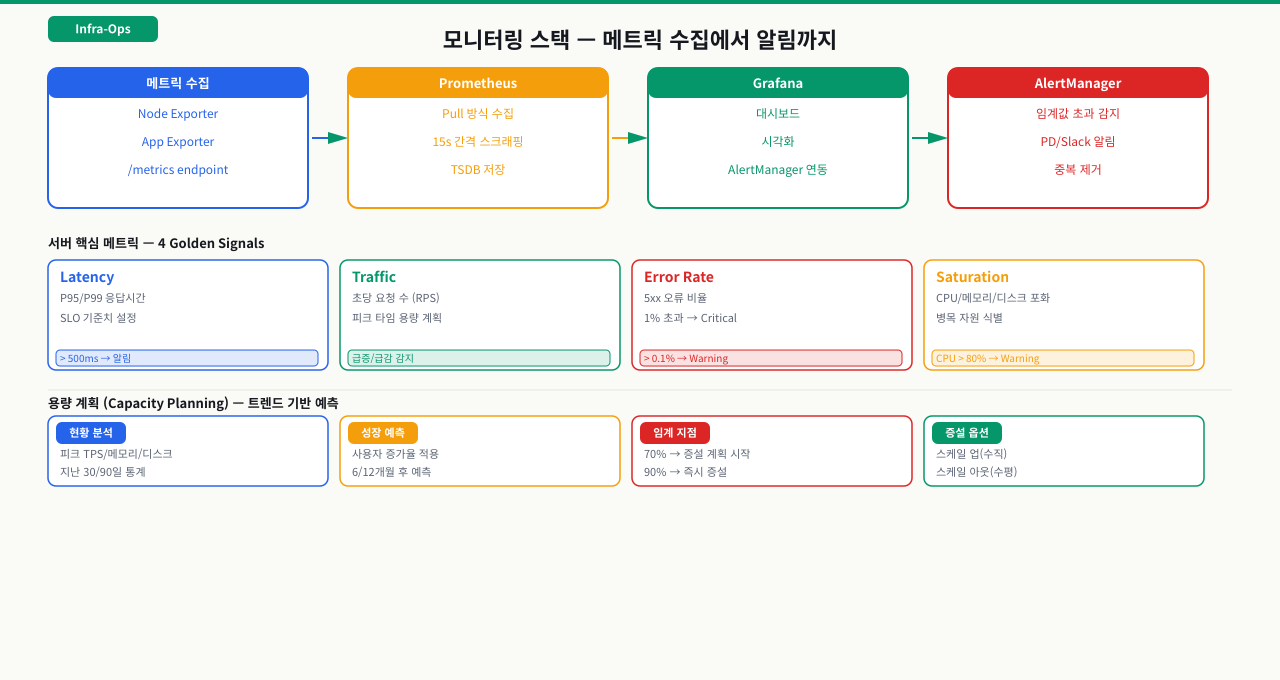
용량은 어떻게 관측되고 한계는 어떻게 예측되나 — 수집에서 증설 결정까지
앞의 임계치는 "지금 위험한가"를 봅니다. 하지만 용량 관리의 진짜 질문은 "언제 한계에 닿는가"입니다. 임계치 한 줄은 더 큰 파이프라인의 한 점일 뿐이어서, 지표가 수집되고 · 추세가 쌓이고 · 헤드룸이 평가되고 · 경보가 나가고 · 증설이 결정되는 흐름 안에 놓여야 "이 추세면 2주 뒤 디스크가 찬다"를 미리 말할 수 있습니다. 이 단계를 알면 "왜 급증을 놓쳤지", "왜 알람이 늦었지"를 어느 칸이 빈 것인지로 좁힐 수 있습니다.
[자원 지표] CPU · 메모리 · 디스크 · inode · 연결수
│
① 수집 주기적으로 지표를 긁어 시계열로 저장 (수집 주기: 예 15초 · 1분)
│
② 추세 분석 증가율 · 계절성 · 기준선(baseline) 파악
│
③ 헤드룸 평가 남은 여유 + 소진 예상 시점 계산
│
④ 경보 임계 초과가 N분 지속되면 발송
│
⑤ 증설 결정 스케일업 · 스케일아웃 · 정리/회수
▼
[예측] "지금 80%"가 아니라 "이 추세면 2주 뒤 100%"
각 단계가 하는 일과, 어긋났을 때의 증상:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① 수집 | 자원 지표를 주기적으로 저장 | 안 거는 축은 맹점(바이트만 보고 inode 놓침) · 샘플 간격 넓으면 급증 미포착 |
| ② 추세 | 시계열로 증가 속도 · 주기 파악 | 순간값만 보면 서서히 차는 누수 · 완만한 증가를 못 봄 |
| ③ 헤드룸 | 남은 여유와 소진 시점 산정 | 헤드룸 과소 산정=여유 없이 터짐 · 과대=쓸데없이 크게 증설 |
| ④ 경보 | 지속시간 조건으로 발송 | 순간 스파이크에 알람=피로로 무시됨 · 임계 너무 높음=늦은 감지 |
| ⑤ 증설 | 스케일 · 정리 결정 | 용량 산정 오류=부족(장애) 또는 과다(비용 낭비) |
정리하면 좋은 용량 관리는 "숫자 하나"가 아니라 "무엇을 수집해(①) + 어떻게 추세를 읽어(②) + 얼마의 여유를 두고(③) + 언제 알리고(④) + 어떻게 늘릴지(⑤)"의 연결입니다. 임계치(④)만 정교하게 다듬어도 ①에 구멍이 있으면 — 예컨대 df -i(inode)를 안 걸어 그 축이 통째로 비면 — 한계는 예측되지 않습니다. 아래의 logrotate · jstat · 모니터링 솔루션은 이 파이프라인의 각 칸을 실제 도구로 채우는 방법입니다.
logrotate 설정
로그 파일을 자동으로 정리하는 방법
Nginx나 Tomcat처럼 매일 로그를 생성하는 서비스를 방치하면, 수개월 후 /var/log 디렉터리가 수십 GB를 차지합니다. logrotate는 이 문제를 자동으로 해결합니다 — 오래된 로그를 압축하고, 일정 기간이 지나면 삭제하고, 새 로그 파일로 전환합니다.
설정 파일은 /etc/logrotate.d/ 아래 서비스별로 분리해 관리합니다.
# /etc/logrotate.d/nginx 예시
/var/log/nginx/*.log {
daily # 매일 로테이션
rotate 30 # 30개 보관 (30일치)
compress # 로테이션된 파일 gzip 압축
delaycompress # 가장 최근 로테이션 파일은 다음 사이클에 압축 (Nginx가 아직 열고 있을 수 있으므로)
missingok # 로그 파일이 없어도 에러 내지 않음
notifempty # 빈 파일은 로테이션 건너뜀
sharedscripts # postrotate를 glob 대상 전체에 한 번만 실행
postrotate
nginx -s reopen # Nginx에 새 로그 파일로 전환하도록 신호
endscript
}
주요 옵션 의미:
| 옵션 | 설명 |
|---|---|
daily / weekly / monthly | 로테이션 주기 |
rotate 30 | 보관 파일 수. 30이면 30번 로테이션 후 가장 오래된 것 삭제 |
compress | 로테이션된 파일을 .gz로 압축 (디스크 절약) |
delaycompress | 가장 최근 파일은 압축 유예 — compress와 세트로 씀 |
missingok | 대상 파일이 없을 때 에러 무시 |
notifempty | 비어있는 파일 건너뜀 |
postrotate | 로테이션 후 실행할 스크립트 |
sharedscripts | glob 매칭 파일이 여러 개여도 postrotate 한 번만 실행 |
compress와 delaycompress를 반드시 함께 써야 하는 이유: Nginx는 파일 디스크립터를 유지하면서 로그를 씁니다. 로테이션 직후 파일이 즉시 압축되면, 아직 이전 디스크립터로 쓰려는 Nginx가 압축 파일에 잘못된 데이터를 씁니다. delaycompress가 한 사이클 유예 기간을 줘서 postrotate의 nginx -s reopen이 먼저 실행된 뒤 압축이 진행됩니다.
# 설정 검증 (실제 로테이션 없이 시뮬레이션)
logrotate -d /etc/logrotate.d/nginx
# 강제 로테이션 (테스트 목적)
logrotate -f /etc/logrotate.d/nginx
# logrotate 상태 확인 (마지막 실행 시각 등)
cat /var/lib/logrotate/status | grep nginx
JVM 메모리 모니터링
jstat으로 GC 상태 파악하기
Java 애플리케이션(Tomcat, Spring Boot 등)은 JVM Heap 메모리를 자체적으로 관리합니다. free -m으로는 JVM 내부 상태를 볼 수 없습니다. jstat이 JVM 내부 GC 통계를 실시간으로 보여주는 도구입니다.
# JVM Heap/GC 통계 확인 (1초 간격, 5회)
jstat -gcutil <PID> 1000 5
# 출력 예시:
# S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
# 0.00 85.23 72.45 61.20 97.43 94.23 42 2.840 3 1.230 4.070
# PID 확인
pgrep -a java
# 또는
ps aux | grep java
컬럼 의미:
| 컬럼 | 의미 |
|---|---|
S0, S1 | Survivor Space 0/1 사용률 (%) |
E | Eden Space 사용률 (%) — Young Gen |
O | Old Generation 사용률 (%) |
M | Metaspace 사용률 (%) |
YGC | Minor GC 발생 횟수 |
FGC | Full GC 발생 횟수 |
FGCT | Full GC 누적 소요 시간 (초) |
판단 기준:
O(Old Gen) 85% 이상 지속 → Full GC 빈발 → 메모리 누수 또는 Heap 크기(-Xmx) 부족 의심FGC횟수가 빠르게 증가 → Stop-The-World 시간 누적 → 응답 지연 발생M(Metaspace) 90% 이상 → 클래스 언로딩 문제,-XX:MaxMetaspaceSize설정 필요
# Heap 덤프 수집 (메모리 누수 분석용)
jmap -dump:format=b,file=/tmp/heap.hprof <PID>
# 이후 Eclipse MAT 또는 JVisualVM으로 분석
로그 폭증 대응
갑자기 디스크가 꽉 찰 때
특정 서비스가 예외를 폭발적으로 던지거나, DEBUG 레벨 로깅이 운영 서버에 활성화되어 있으면 수 분 만에 디스크를 가득 채울 수 있습니다. 조용히 지켜보다가 100%가 되면 서비스 전체가 멈춥니다.
원인 파일 찾기:
# /var/log 아래 대용량 파일 상위 10개
du -sh /var/log/* 2>/dev/null | sort -rh | head -10
# 특정 디렉터리 세부 확인
du -sh /opt/tomcat/logs/* | sort -rh | head -10
# 현재 열려있는 상태로 계속 써지는 파일 확인 (lsof)
lsof | grep -i "log" | awk '{print $9, $7}' | sort -k2 -rn | head -10
임시 대응 — 로그 잘라내기:
# 파일을 삭제하지 않고 비우기 (프로세스가 파일을 열고 있을 때 안전)
> /opt/tomcat/logs/catalina.out
# 또는
truncate -s 0 /opt/tomcat/logs/catalina.out
파일을 rm으로 삭제하면 프로세스는 여전히 삭제된 inode에 계속 쓰므로 디스크가 실제로 회수되지 않습니다. truncate나 리다이렉션(>)으로 내용을 비워야 즉시 디스크가 회수됩니다.
근본 대응:
# 로그 레벨 확인 (Logback/Log4j 기준)
grep -r "level" /opt/tomcat/conf/logging.properties
# 애플리케이션 로그 레벨 임시 변경 (재시작 없이)
# Spring Boot Actuator가 활성화된 경우
curl -X POST http://localhost:8080/actuator/loggers/ROOT \
-H "Content-Type: application/json" \
-d '{"configuredLevel": "WARN"}'
 확대
확대
모니터링 솔루션 개요
Zabbix, Nagios, CloudWatch — 어떤 상황에 쓰이나
서버가 20대가 넘어서자 쉘 스크립트 기반 모니터링이 한계에 달했습니다. cron으로 각 서버에 스크립트를 배포하고 알람 메일을 보내는 방식은 관리 포인트가 너무 많고, 대시보드도 없습니다. 신규 입사자가 "우리 회사는 어떤 모니터링 쓰나요?"라고 물으면 즉시 답할 수 있어야 하고, 환경에 맞는 선택을 설명할 수 있어야 합니다. 세 가지 도구의 차이를 알아야 왜 그 선택이 이 환경에 맞는지 이해할 수 있습니다.
직접 스크립트로 모니터링할 수 있지만, 규모가 커지면 전용 솔루션이 필요합니다. 세 가지 대표적인 선택지를 비교합니다.
 확대
확대
| 솔루션 | 형태 | 적합 환경 | 특징 |
|---|---|---|---|
| Zabbix | 오픈소스, 자체 설치 | 온프레미스, 다수 서버 | 에이전트 설치, SNMP 지원, 한국 기업 다수 사용 |
| Nagios | 오픈소스, 자체 설치 | 레거시 환경 | 플러그인 생태계 방대, 오래된 인터페이스 |
| CloudWatch | AWS 관리형 SaaS | AWS 인프라 | 인프라 코드화 가능, EC2/RDS/Lambda 자동 통합 |
실무에서 가장 많이 보이는 패턴은 AWS 환경이면 CloudWatch를 기본으로 쓰고, 온프레미스 혼합 환경이면 Prometheus + Grafana 조합을 추가합니다. Zabbix는 제조업, 금융권 온프레미스 환경에 여전히 많이 사용됩니다.
alert 발송 채널은 이메일보다 Slack 또는 PagerDuty 연동이 현업에서 더 빠릅니다 — 새벽 장애 알람을 이메일로만 받으면 아침에 발견하게 됩니다.
실습
세 개의 명령을 이어서 실행해 디스크/메모리/CPU를 한눈에 확인합니다. df -h는 파일시스템별 사용률, free -m은 메모리 상태, top -bn1은 현재 CPU 부하를 보여줍니다. 장애 대응 첫 30초에 반드시 실행하는 루틴입니다.
df -h && echo '---' && free -m && echo '---' && top -bn1 | head -5- df -h 로 디스크 먼저 확인, free -m 으로 메모리, top 의 load average 순서로 확인 — 디스크 풀이 가장 즉각적인 서비스 장애 원인이므로 항상 첫 번째로 체크
- 수치 기준: df -h Use% 80% 이상=즉시 원인 파악 필요, 90% 이상=로그/코어덤프 긴급 정리 / free -m available이 전체의 10% 미만=스왑 사용 시작 위험 / load average(15분)가 코어 수 초과=CPU 포화
- df -h 는 여유 있는데 /var/log 가 별도 마운트 파티션이고 그 파티션이 풀이면 → df -h /var/log 로 별도 확인 필요 — 루트 파티션과 분리된 /var/log 는 전체 df -h 에서 별도 행으로 보임
-d 옵션은 시뮬레이션 모드입니다. 실제로 파일을 로테이션하지 않고 어떤 파일이 대상이 되는지, 설정이 올바른지 확인합니다. 설정 파일 경로가 없거나 문법이 잘못된 경우 이 단계에서 에러가 납니다.
logrotate -d /etc/logrotate.d/nginx- logrotate -d 출력에서 먼저 "considering log" 메시지로 대상 파일 인식 여부 확인, 그 다음 "error" 또는 "warning" 키워드 없는지 확인 — "considering log" 가 없으면 설정 파일의 로그 경로가 실제 파일과 다른 것
- 출력 기준: "would rotate" 메시지가 나오면 다음 실행 시 실제로 로테이션됨(정상), "log does not need rotating" 이면 아직 조건(크기/날짜) 미충족 — "error opening" 이면 대상 파일 읽기 권한 없음
- "considering log"는 나오는데 rotate 후 compress 메시지가 없으면 → compress 설정이 logrotate.conf에 없거나 delaycompress만 있어서 다음 회차에 압축 예정 — cat /etc/logrotate.d/nginx 로 compress 항목 확인
트러블슈팅
원인: postrotate 블록에서 nginx -s reopen 명령이 누락됐거나, sharedscripts 없이 여러 파일에 postrotate가 중복 실행됐을 때 발생합니다. Nginx는 기동 시 파일 디스크립터를 열고 유지하므로, 로테이션 후 명시적으로 재오픈 신호를 보내지 않으면 원본 파일(이제는 .1로 이름이 바뀐 파일)에 계속 씁니다.
# 현재 Nginx가 어느 파일에 쓰고 있는지 확인
lsof -p $(pgrep nginx | head -1) | grep "access.log"
# postrotate 블록 내용 확인
cat /etc/logrotate.d/nginx | grep -A3 postrotate
# 올바른 postrotate 설정 예시
# postrotate
# nginx -s reopen
# endscript
# 수동으로 신호 보내기 (테스트)
nginx -s reopen
# 이후 새 access.log 파일에 로그가 찍히는지 확인
ls -la /var/log/nginx/access.log*
tail -2 /var/log/nginx/access.log
원인: 로그 파일이 짧은 시간에 폭발적으로 커졌을 가능성이 높습니다. 예외가 루프를 돌며 반복 출력되거나, DEBUG 레벨이 운영에 켜져 있는 경우입니다.
# 1단계: 어디서 공간을 차지하는지 찾기
du -sh /var/log/* 2>/dev/null | sort -rh | head -10
du -sh /opt/tomcat/logs/* 2>/dev/null | sort -rh | head -5
# 2단계: 해당 파일을 비우기 (삭제 말고 truncate)
truncate -s 0 /opt/tomcat/logs/catalina.out
# 3단계: 디스크 회수 확인
df -h /opt
# 4단계: 로그 폭증 원인 파악
# 방금 비운 파일이 다시 빠르게 차는지 모니터링
watch -n 5 "du -sh /opt/tomcat/logs/catalina.out"
# 5단계: 반복되는 에러 메시지 확인 (임시로 tail)
tail -100 /opt/tomcat/logs/catalina.out | grep -c "Exception"
# 100줄 안에 Exception이 수십 개라면 루프 에러
심화 — 지표를 잘못 읽으면 임계치가 배신한다
심화: load average는 CPU 사용률이 아니다 — 임계치를 순간값·평균으로 걸 때의 함정
앞에서 "load average가 코어 수를 넘으면 포화"라고 했지만, 이는 편의상의 단순화입니다. 임계치를 설계하려면 이 지표가 실제로 무엇을 세는지 한 겹 더 들어가야, 정상인데 알람이 울리거나 위험한데 조용한 상황을 피할 수 있습니다.
- load average는 R뿐 아니라 D(무중단 슬립)도 센다: 리눅스 load average는 실행 중·실행 대기(R) 프로세스뿐 아니라 디스크·네트워크 IO를 기다리는 무중단 슬립(D state) 프로세스까지 포함합니다. 그래서 CPU가 5%인데 load average가 30일 수 있습니다 — CPU 포화가 아니라 느린 디스크·NFS 같은 IO 병목의 신호입니다. 원인이 CPU인지 IO인지는
top의wa(iowait)와 R/D 상태 프로세스 수(ps -eo state)로 갈라야 합니다. - 순간값·산술평균은 이중봉 부하를 숨긴다: 절반은 idle, 절반은 100%인 서버의 평균은 50%로 보여 실제 고통을 가립니다. 그래서 평균보다 p95·최댓값과 '지속 시간(N분)' 조건을 함께 봐야 스파이크(무해)와 지속 포화(장애)를 구분합니다.
- 정적 임계치는 기준선 이동에 취약하다: 트래픽이 계절적으로 자라면 어제의 80%가 오늘의 정상이 됩니다. baseline이 움직이므로 정적 임계치는 주기적으로 재보정하거나, 기준선 대비 이탈(anomaly)로 보는 방식이 필요합니다.
- 컨테이너에서는 host 지표가 거짓말을 한다: cgroup으로 제한된 컨테이너는 호스트
free·CPU가 한가해도 자기 한도에서 스로틀·OOM될 수 있습니다. 컨테이너 워크로드는 host가 아니라 cgroup 한도(memory.max, CPU quota) 기준으로 봐야 합니다.
정리하면, 좋은 임계치는 '숫자 하나'가 아니라 '무엇을 세는 지표인지 + 얼마나 지속되는지 + 어떤 기준선 대비인지'의 조합입니다.
상황: 디스크 사용률은 60%로 넉넉한데, 애플리케이션이 임시·세션 파일을 생성하려 하면 No space left on device가 반복됩니다. 로그도 새로 못 남기고, 디스크를 아무리 비워도(바이트를 지워도) 증상이 그대로입니다.
원인: 바이트가 아니라 inode(파일 개수 한도) 가 고갈된 것입니다. 파일시스템은 파일마다 inode를 하나씩 쓰는데, 세션 파일·메일 큐·캐시 조각처럼 아주 작은 파일이 수백만 개 쌓이면 용량은 남아도 inode가 100%가 되어 새 파일을 만들 수 없습니다. df -h(바이트)만 감시하는 모니터링은 이 장애를 절대 못 잡습니다.
진단: 바이트가 아니라 inode를 봅니다.
# inode 사용률 확인 (IUse%가 100%면 inode 고갈)
df -i
# Filesystem Inodes IUsed IFree IUse% Mounted on
# /dev/nvme0 6.5M 6.5M 0 100% /var ← 바이트는 60%인데 inode 100%
# inode를 많이 먹는 하위 디렉터리 찾기(파일 개수 기준)
for d in /var/*; do echo "$(find "$d" -xdev 2>/dev/null | wc -l) $d"; done | sort -rn | head
해결: 원인 디렉터리의 소파일을 대량 정리하고(오래된 세션·캐시 파일 배치 삭제), 파일을 무한 생성하는 로직을 고치거나 정리 cron을 겁니다. 무엇보다 모니터링에 df -h(바이트)와 함께 df -i(IUse%) 임계치를 반드시 걸어, inode 고갈을 바이트 포화와 별개의 알람으로 감시해야 재발하지 않습니다. '디스크가 찼다'는 신고를 받으면 바이트뿐 아니라 inode도 함께 의심하는 습관이 핵심입니다.
실제 업무에서 이 지식이 쓰이는 상황:
신입 인프라 엔지니어가 배포 후 처음 당하는 장애 중 하나가 "디스크 꽉 참"입니다. 새벽에 알람이 오고 접속해보면 /var/log가 100%입니다. 이때 당황하지 않고 du -sh /var/log/*로 원인 파일을 찾고, truncate로 비우고, logrotate 설정을 점검하는 것 — 이 루틴이 이 모듈의 핵심 가치입니다.
모니터링 임계치 설정 체크리스트:
- CPU: 80% 이상 5분 지속 → 경고, 95% 10분 → 긴급
- Memory available: 10% 미만 → 경고
- Disk: 80% → 경고, 90% → 긴급
- inode: 80% → 점검
- JVM Old Gen: 85% 이상 지속 → Full GC 점검
logrotate 주간 점검 루틴:
# logrotate 마지막 실행 확인
cat /var/lib/logrotate/status | grep -E "nginx|tomcat"
# 현재 로그 파일 크기 확인
ls -lh /var/log/nginx/ /opt/tomcat/logs/
# 압축 파일 보관 현황
ls /var/log/nginx/*.gz | wc -l
명령어·단축키 빠른 참조
리소스 임계치를 점검하고 로그·JVM을 관리할 때 쓰는 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
df -h | 파일시스템 용량(바이트) | 80% 경고·90% 긴급 |
df -i | inode(파일 수 한도) 사용률 | 바이트 남아도 IUse% 100%면 생성 불가 |
du -sh * | sort -rh | 디렉터리별 용량 상위 | du -sh /var/log/* | sort -rh | head |
free -m | 메모리 가용량 | available 컬럼이 핵심 |
top -bn1 / uptime | CPU·load average | uptime으로 1·5·15분 부하 |
ps aux --sort=-%mem | 메모리 상위 프로세스 | ps aux --sort=-%mem | head -6 |
lsof | grep deleted | 삭제됐지만 열린 파일(공간 미회수) | df/du 불일치 원인 |
truncate -s 0 / > | 로그 파일 비우기(삭제 아님) | truncate -s 0 catalina.out — 즉시 회수 |
logrotate -d | 로테이션 시뮬레이션(dry-run) | 설정 검증, 실제 미실행 |
logrotate -f | 강제 로테이션(테스트) | logrotate -f /etc/logrotate.d/nginx |
jstat -gcutil <PID> | JVM Heap·GC 통계 | jstat -gcutil <PID> 1000 5 (O 85%↑ 주의) |
jmap -dump | Heap 덤프(누수 분석) | jmap -dump:format=b,file=/tmp/heap.hprof <PID> |
nginx -s reopen | 로테이션 후 로그 파일 재오픈 | postrotate의 핵심 |
watch -n 5 | 값 변화 주기 관찰 | watch -n 5 "du -sh catalina.out" (재증가 감시) |
관련 모듈로 더 깊이:
- 애플리케이션 성능 모니터링과 대시보드 구성 — 임계치 알람을 넘어 JVM 메트릭을 Grafana로 상시 시각화하는 구성
- Filebeat/rsyslog 기반 로그 수집 파이프라인 구성 — 로그 폭증의 근본 대응인 로그 중앙 수집 파이프라인
- Heap/GC/Thread Dump 분석과 OOM 대응 실무 — 메모리 임계치 알람이 울렸을 때 Heap/GC를 분석하는 실무
다음 모듈에서는 JMX Exporter와 Prometheus를 연동해 JVM 메트릭을 Grafana 대시보드로 시각화하는 APM 모니터링 구성을 다룹니다.