입사 첫 주, 선임 엔지니어가 이렇게 말합니다. "오늘 저녁 운영 배포 있어요. 같이 들어와요." 배포는 왜 새벽에 하는지, 왜 그렇게 많은 사람이 참여하는지, 왜 개발팀 서버랑 운영 서버가 따로인지 — 이 모든 것들이 '인프라 서비스 운영'의 기초입니다.
코드를 짜는 사람이 아니라 코드가 돌아가는 환경을 책임지는 사람. 그게 인프라 엔지니어입니다.
- 1인프라 엔지니어의 역할과 담당 레이어를 설명할 수 있다
- 2운영계/통시계/개발계의 차이와 분리 이유를 설명할 수 있다
- 3서비스 구조도(Web→WAS→DB 흐름)를 읽고 구성 요소를 파악할 수 있다
- 4개발자·DBA·인프라 엔지니어의 업무 분장을 구분할 수 있다
- 5변경관리(Change Management) 흐름의 기본 단계를 말할 수 있다
cat /etc/os-release | grep -E 'NAME|VERSION'hostname && hostname -fip addr show | grep 'inet '인프라 엔지니어가 담당하는 레이어
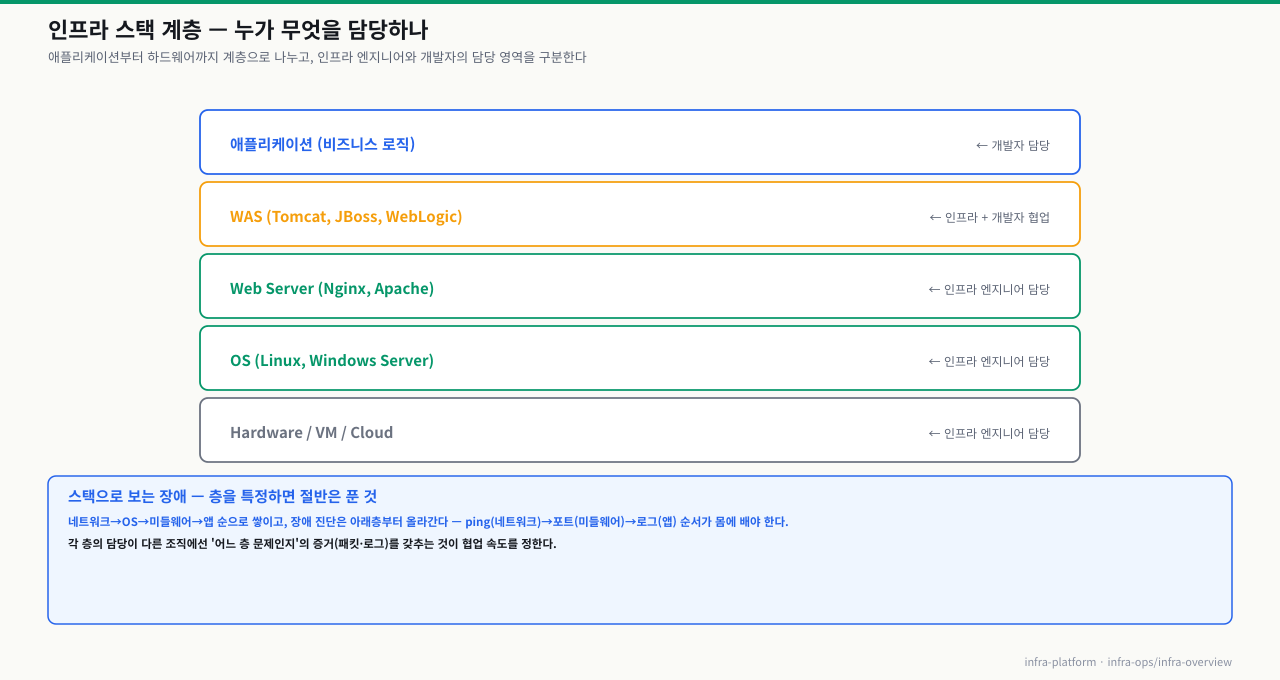
서비스를 운영하는 데 필요한 기술 스택은 여러 레이어로 나뉩니다. 인프라 엔지니어는 하드웨어부터 미들웨어까지의 영역을 담당합니다.
인프라 엔지니어의 책임 범위
서비스 장애가 났을 때 "코드는 멀쩡한데 서버가 문제"라는 말이 나오는 순간, 그것을 책임지는 사람이 인프라 엔지니어입니다. 개발자가 만든 코드가 실제 트래픽을 처리하려면 OS, 네트워크, 미들웨어가 빈틈없이 받쳐줘야 하고, 그 레이어를 소유하는 사람이 바로 인프라 엔지니어입니다. 어느 레이어가 누구 책임인지 명확히 알아야 장애 상황에서 빠르게 움직일 수 있습니다.
 확대
확대
서비스 스택을 계층으로 나누면 다음과 같습니다:
 확대
확대
인프라 엔지니어의 핵심 업무:
- OS 설치 및 초기 설정 (사용자, 네트워크, 보안)
- Web/WAS 미들웨어 설치·구성·운영
- 서버 용량 계획 및 리소스 모니터링
- 배포 스크립트 작성 및 배포 수행
- 장애 대응 및 로그 분석
- 방화벽 오픈 요청, DNS/SSL 인증서 관리
인접 역할과의 경계:
| 역할 | 담당 영역 |
|---|---|
| 개발자 | 비즈니스 로직, API, 소스 코드 |
| DBA | DB 스키마 설계, 쿼리 최적화, 백업 정책 |
| 인프라 엔지니어 | OS, 네트워크, Web/WAS, 배포, 모니터링 |
| 보안팀 | 보안 정책, 취약점 점검, 계정 관리 정책 |
실제 현장에서는 인프라 엔지니어가 이 네 영역을 모두 겸하는 경우도 많습니다.
 확대
확대
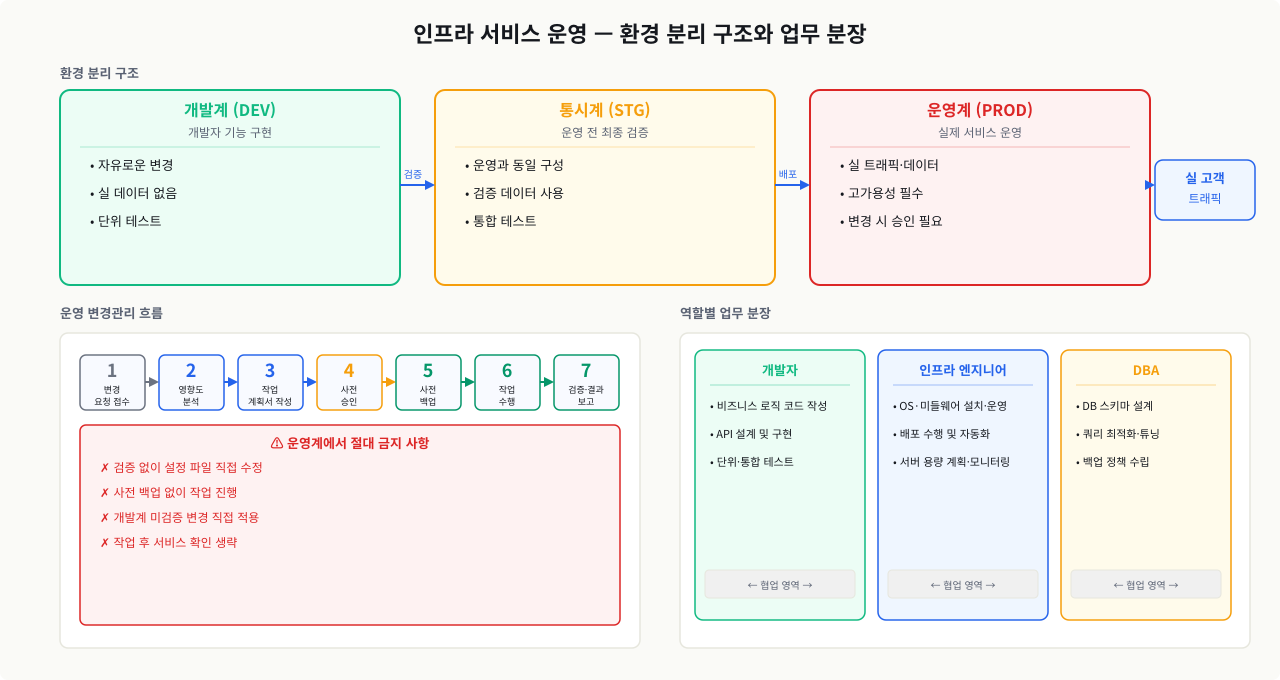
운영계 / 통시계 / 개발계 구조
"개발계에서는 됐는데 운영에 올리니까 안 돼요"라는 제보를 받은 날, 원인을 찾아보니 개발계 DB와 운영계 DB의 데이터 상태가 완전히 달랐습니다. 환경이 분리돼 있다는 것은 알았지만 왜 분리해야 하는지 몰랐던 것입니다. 실제 고객 트래픽과 데이터가 흐르는 운영계에서 테스트 코드를 돌리거나 임의로 재시작을 걸면, 서비스가 멈추고 데이터가 오염됩니다. 환경 분리는 이 사고를 구조적으로 막는 방법이고, 인프라 엔지니어가 어느 환경에서 작업하는지 항상 확인해야 하는 이유입니다.
환경 구분:
| 환경 | 별칭 | 목적 | 특징 |
|---|---|---|---|
| Development | 개발계, DEV | 개발자 기능 구현 및 단위 테스트 | 자유로운 변경, 실 데이터 없음 |
| Staging | 통시계, STG | 운영 배포 전 최종 검증 | 운영과 동일 구성, 운영 유사 데이터 |
| Production | 운영계, PROD | 실제 서비스 운영 | 실 트래픽, 실 데이터, 고가용성 |
운영계에서 절대 하면 안 되는 것:
- 검증되지 않은 설정 변경 직접 적용
- 테스트 목적의 임의 재시작
- 운영 DB에서 직접 UPDATE/DELETE 수행 (긴급 상황 제외, 승인 필요)
- root 비밀번호 변경 또는 계정 삭제
# 현재 접속된 서버가 어느 환경인지 확인하는 습관
hostname
# web01-prd → 운영계
# web01-stg → 통시계
# web01-dev → 개발계
# 환경변수로 환경을 구분하기도 함
echo $APP_ENV
# production / staging / development
실무 팁: 호스트명에 -prd, -stg, -dev 같은 접미사를 붙이는 것은 실수로 잘못된 환경에 작업하는 것을 방지하는 효과적인 방법입니다.
1. 서버 기본 정보 확인
hostnamectl && echo '---' && cat /etc/os-release | grep -E '^NAME|VERSION_ID'2. 실행 중인 서비스 파악
systemctl list-units --type=service --state=running | grep -v '@' | tail -20- hostname 출력을 먼저 확인 — prd/prod가 포함되면 운영계로 간주하고 모든 작업 전 재확인. dev/stg가 없으면 환경 구분이 안 된 서버로 IP 대역과 서비스 URL을 추가로 확인
- ss -tlnp에서 포트별 서비스 역할 파악 — 80/443이면 Web(nginx/apache), 8080/8443이면 WAS(tomcat), 3306/5432이면 DB(mysql/postgresql). 3개 포트가 모두 열려있으면 단일 서버에 Web+WAS+DB 구성
- 호스트명에 prd가 있고 3306 포트도 외부(0.0.0.0)에 열려있는 조합이면 — 운영 DB가 직접 노출된 위험 상태. 즉시 방화벽 확인 후 127.0.0.1 바인딩 또는 방화벽 차단 조치 필요
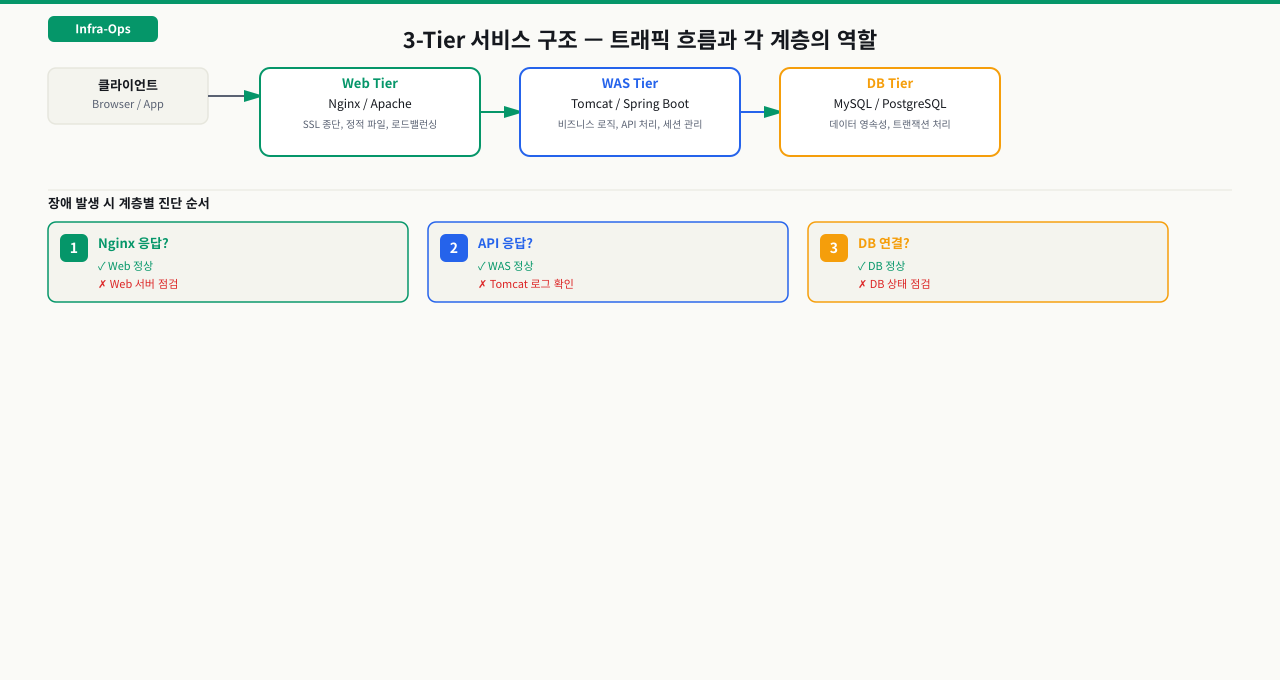
서비스 구조도 읽기
인프라 엔지니어가 처음 해야 할 일은 담당 서비스의 구조도를 파악하는 것입니다.
일반적인 3-Tier 서비스 구조
처음 서버에 들어갔을 때 어떤 프로세스가 어떤 역할인지 모르면 장애 상황에서 어디를 봐야 할지 막막합니다.
 확대
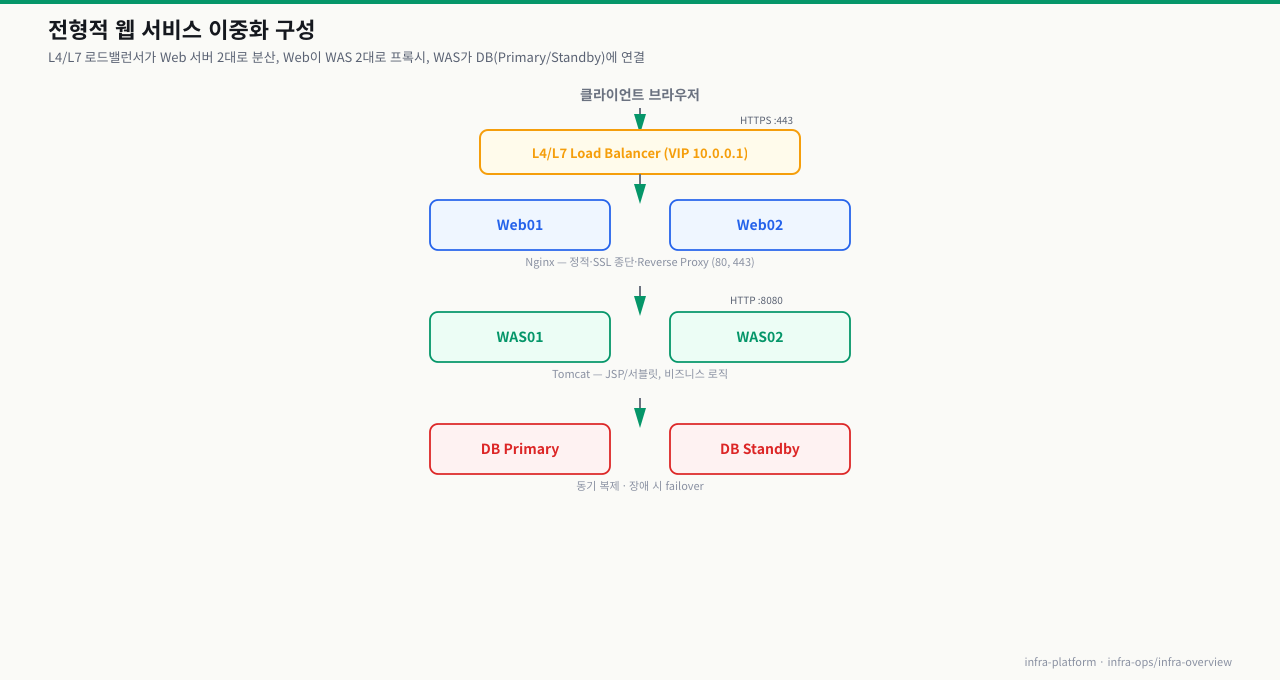
고객 민원이 들어왔는데 Nginx가 문제인지 Tomcat이 문제인지 DB가 문제인지 구분 못 하면, 복구 시간이 수십 분에서 몇 시간으로 늘어납니다. 서비스 구조도를 머릿속에 그릴 수 있어야 "어디서부터 확인할지"를 바로 판단할 수 있습니다. 대부분의 웹 서비스는 Web → WAS → DB의 3계층 구조를 가집니다.
확대
고객 민원이 들어왔는데 Nginx가 문제인지 Tomcat이 문제인지 DB가 문제인지 구분 못 하면, 복구 시간이 수십 분에서 몇 시간으로 늘어납니다. 서비스 구조도를 머릿속에 그릴 수 있어야 "어디서부터 확인할지"를 바로 판단할 수 있습니다. 대부분의 웹 서비스는 Web → WAS → DB의 3계층 구조를 가집니다.
 확대
확대
각 구성요소의 역할:
- LB (로드밸런서): 트래픽을 여러 서버에 분산. VIP 하나로 여러 서버를 묶음
- Web Server (Nginx): 정적 파일(.html, .js, .css, 이미지) 직접 처리. 동적 요청은 WAS로 전달
- WAS (Tomcat): Java 애플리케이션 실행. DB 연결, 비즈니스 로직 처리
- DB: 영구 데이터 저장. Primary-Standby 이중화로 가용성 확보
인프라 엔지니어가 관리하는 범위: LB부터 DB까지의 모든 서버와 구성
변경관리(Change Management) 흐름
운영 환경에서의 작업은 반드시 절차를 따릅니다. "빨리 해야 해서 대충 했다"가 가장 큰 장애 원인 중 하나입니다.
운영 변경관리 표준 흐름
주말 오전에 긴급 패치를 적용했는데 서비스가 전면 다운됐습니다. 알고 보니 영향도 분석을 빠뜨리고 연계 서비스를 확인하지 않았던 것입니다. 운영 환경에서 "빨리 해야 한다"는 압박에 절차를 건너뛰면, 장애 복구에 걸리는 시간이 원래 작업 시간의 열 배를 넘기기도 합니다. 변경 전 백업과 롤백 계획이 없으면 단순한 설정 오타 하나가 몇 시간짜리 장애로 이어집니다.
- 변경 요청 접수 — 개발팀 또는 내부 요청 (지라 티켓, 이메일 등)
- 영향도 분석 — 어떤 서버? 어떤 서비스? 중단 필요 여부? 롤백 가능?
- 작업 계획서 작성 — 작업 내용, 작업 시간, 담당자, 롤백 절차 명시
- 사전 승인 (팀장/운영 담당) — 긴급 장애 대응은 사후 보고로 대체하기도 함
- 사전 백업 — 설정 파일, 데이터, 현재 버전 (cp/tar/스냅샷)
- 작업 수행 — 계획서대로 순서대로, 변경 로그 기록
- 작업 후 검증 — 서비스 정상 동작 확인, 로그 오류 없음 확인
- 결과 보고 — 완료 보고, 이상 시 롤백 수행 후 원인 분석
실제로 자주 일어나는 실수:
- 사전 백업 없이 설정 파일 수정 → 원복 불가
- 영향도 분석 누락 → 연계 서비스 장애
- 개발계에서 검증하지 않고 운영에 직접 적용
- 작업 후 검증 없이 "됐겠지" → 다음날 오전에 민원
# 설정 파일 변경 전 반드시 백업하는 습관
cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak.$(date +%Y%m%d%H%M)
# 결과: nginx.conf.bak.202501151430
서버 기본 정보 확인
hostnamectl && echo '---' && cat /etc/os-release | grep -E 'NAME|VERSION_ID'실행 중인 주요 서비스 확인
systemctl list-units --type=service --state=running | grep -E 'nginx|apache|tomcat|mysql|mariadb'네트워크 리스닝 포트 확인
ss -tlnp | grep LISTEN디스크 및 메모리 기본 상태
df -h && echo '---' && free -m- hostnamectl에서 호스트명을 먼저 확인 — -prd/-prod는 운영계, -stg/-staging은 스테이징, -dev는 개발계. 구분자가 없으면 IP 대역으로 환경을 재확인(운영은 보통 10.1.x.x, 개발은 10.0.x.x)
- df -h에서 / 또는 /var 사용률이 80% 이상이면 즉시 용량 점검 — 90% 이상이면 로그 로테이션, 임시 파일 정리 즉각 실행. 100%이면 Tomcat 로그 쓰기 실패로 서비스 장애로 이어짐
- 호스트명이 운영계이고 df -h 사용률이 85% 이상인 조합이면 — 작업을 중단하고 용량 확보를 먼저. /var가 가득 찬 상태에서 배포하면 WAR 복사 실패로 서비스 장애 발생
심화 — 증상은 브라우저에, 원인은 한 계층에
심화: 장애 계층 좁히기 — 상태 코드가 범인을 가리킨다
3-Tier 구조를 '그림'으로만 알면 정작 장애가 났을 때 어디부터 봐야 할지 막막합니다. 한 단계 더 들어가, 요청이 계층을 지나며 실패할 때 어떤 신호가 어느 계층을 가리키는지를 알면 복구 시간이 몇 분의 일로 줄어듭니다.
- 502 Bad Gateway: 리버스 프록시(Web/Nginx)가 뒤단 WAS에 연결했지만 정상 응답을 못 받은 것. WAS 프로세스가 죽었거나,
proxy_pass가 가리키는 포트·주소가 실제 WAS와 다를 때 납니다. → WAS 계층부터 봅니다. - 504 Gateway Timeout: 프록시가 WAS까지는 붙었는데 제한 시간 안에 응답이 안 온 것. WAS가 DB 응답을 기다리며 멈춰 있거나 스레드가 고갈됐을 때 흔합니다. → WAS~DB 사이의 지연을 봅니다.
- 애플리케이션 500 / 스택트레이스: 요청이 WAS까지 무사히 도달해 코드가 실행됐다는 뜻. → 애플리케이션·DB 로직 문제이고 인프라 계층은 대개 정상입니다.
- 연결 자체가 안 됨(Connection refused / timeout): 프록시 앞단, 즉 LB·방화벽·Web 기동 문제일 가능성이 큽니다.
즉 "안 돼요"라는 한마디를 상태 코드로 번역하면 뒤져야 할 계층이 하나로 좁혀집니다. 여기에 더해, 운영 서비스는 대개 LB 뒤에 같은 서버가 여러 대라는 사실을 늘 염두에 둬야 합니다 — '반은 되고 반은 안 되는' 증상은 대부분 여러 노드 중 일부만 비정상이라는 신호입니다.
상황: 신규 버전을 배포한 직후부터 같은 URL을 여러 번 새로고침하면 절반은 정상, 절반은 오류가 납니다. 개발계에서는 재현되지 않습니다.
원인: 이 서비스는 로드밸런서 뒤에 WAS가 2대(was01, was02)로 이중화돼 있는데, 배포 스크립트가 한 대에만 새 WAR를 반영하고 다른 한 대는 기동에 실패했거나 옛 버전 그대로였습니다. LB는 두 대가 모두 살아 있다고 보고 요청을 번갈아 분산하므로, 정상 노드로 간 요청만 성공한 것입니다.
진단: LB를 거치지 말고 각 노드의 내부 주소로 직접 확인합니다 — curl -s http://10.0.1.11:8080/health와 curl -s http://10.0.1.12:8080/health를 각각 때려 응답이 갈리는지 봅니다. 배포된 빌드 버전이나 파일 타임스탬프(배포 경로에서 ls -l)를 두 노드에서 비교하면 어느 쪽이 반영 안 됐는지 바로 드러납니다.
해결: 문제 노드를 LB 풀에서 잠시 빼고(drain) 재배포·재기동한 뒤, 헬스체크가 통과하면 다시 풀에 넣습니다. 재발 방지로는 배포 스크립트가 모든 노드의 기동 확인까지 마친 뒤에야 완료로 보고하도록 만들고, 노드별 배포 결과를 로그로 남깁니다. 이중화 환경에서 '한 대만 반영'은 가장 흔한 배포 사고 유형입니다.
실제 업무에서 이 지식이 쓰이는 상황:
인프라 엔지니어의 하루는 크게 정기 운영과 대응 업무로 나뉩니다.
정기 운영에는 일일 서버 상태 점검(CPU/메모리/디스크/서비스 상태), 예정된 패치 및 업데이트, 배포 수행, 용량 계획 보고가 포함됩니다.
대응 업무는 모니터링 알림에 따른 장애 대응, 개발팀의 방화벽/계정/환경 설정 요청 처리, 보안 취약점 조치입니다.
"이 서버가 운영계인지 개발계인지"를 항상 확인하는 습관이 가장 중요합니다. 실제 현장에서 잘못된 환경에 작업해서 장애를 내는 경우가 상당히 많습니다.
명령어·단축키 빠른 참조
이 모듈에서 새 서버 환경을 식별하고 3-Tier 장애 계층을 좁힐 때 쓴 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
hostname / hostnamectl | 서버 환경·역할 식별(prd/stg/dev) | hostname -f(FQDN), hostnamectl(OS·커널까지) |
cat /etc/os-release | 배포판·버전 확인 | cat /etc/os-release | grep -E 'NAME|VERSION' |
ip addr show | IP·네트워크 인터페이스 확인 | ip addr show | grep 'inet ' |
ss -tlnp | LISTEN 포트로 서비스 구성 파악 | ss -tlnp | grep LISTEN(80/443=Web, 8080=WAS, 3306=DB) |
systemctl list-units | 실행 중 서비스 목록 | systemctl list-units --type=service --state=running |
df -h / free -m | 디스크·메모리 빠른 점검 | df -h | grep '/$'(루트 사용률), free -m |
echo $APP_ENV | 환경변수로 운영/개발 구분 | echo $APP_ENV → production/staging/development |
cp … .bak.$(date …) | 변경 전 설정 백업 습관 | cp nginx.conf nginx.conf.bak.$(date +%Y%m%d%H%M) |
rpm -qa / dpkg -l | 설치 패키지 확인(인계 시) | rpm -qa | grep -E 'nginx|tomcat', dpkg -l | grep nginx |
last / crontab -l | 로그인 이력·예약 작업 파악 | last | head -20, crontab -l |
curl -s <노드>:8080/health | LB 우회로 개별 노드 헬스체크 | curl -s http://10.0.1.11:8080/health(반반 장애 노드 특정) |
관련 모듈로 더 깊이:
- 리눅스 서버 초기 구축 세팅 및 보안 하드닝 체크리스트 — 개요에서 본 운영 흐름의 첫 실무 단계인 새 서버 초기 설정
- Web Server와 WAS 미들웨어 구조의 이해 — 인프라가 떠받치는 Web/WAS 아키텍처의 구성 요소를 더 자세히
- Linux 핵심 파일시스템 구조와 권한(chmod) 체계 완벽 요약 — 모든 서버 운영의 토대가 되는 Linux 파일시스템과 권한 체계
다음 모듈에서는 새 서버를 받았을 때 처음 해야 할 초기 설정 — hostname, timezone, 계정, SSH 보안 설정 — 을 다룹니다.