서비스가 성장하면서 서버가 5대에서 12대로 늘었습니다. 장애가 발생했을 때 어느 서버의 로그를 먼저 봐야 하는지 모르고, 각 서버에 SSH 접속해서 확인하다 보면 10분이 지나 있습니다.
더 심각한 것은 요청이 Nginx(1번 서버) → Tomcat(3번 서버) → DB(5번 서버)를 거치는데, 각 서버 로그를 따로 보면 시간 순서로 연결해 보는 것이 거의 불가능합니다.
로그 중앙화는 "모든 서버의 로그를 한 곳에서"를 실현합니다. 검색 한 번으로 12대 서버 로그를 모두 뒤질 수 있고, 특정 요청 ID로 전체 흐름을 추적할 수 있습니다.
- 1rsyslog 원격 전송 설정으로 시스템 로그를 중앙 서버로 보낼 수 있다
- 2Filebeat를 설치하고 Nginx/Tomcat 로그를 Elasticsearch로 전송하도록 설정할 수 있다
- 3ELK Stack의 각 컴포넌트 역할을 설명하고 구조를 그릴 수 있다
- 4Grafana + Loki를 ELK의 경량 대안으로 이해하고 사용 시나리오를 구분할 수 있다
- 5Filebeat 문제(전송 안 됨, 중복 수집)를 파일 권한과 registry 관점에서 진단할 수 있다
로그 중앙화 필요성
서버 10대가 넘으면 달라지는 것들
서버 3대까지는 SSH 접속 후 tail -f로 각각 확인해도 장애 원인을 충분히 파악할 수 있습니다. 그런데 서버가 10대를 넘어서면 이 방식은 무너집니다. 장애가 어느 서버에서 시작됐는지 모르는 상태에서 10번의 SSH 접속을 돌아다니다 보면 10분이 지나 있고, 요청이 여러 서버를 거치는 경우 시간 순서로 로그를 연결해 보는 것 자체가 불가능합니다. 로그 중앙화는 서버 수가 늘어날수록 팀의 장애 대응 속도를 지키는 구조적 해결책입니다.
 확대
확대
서버가 3대일 때는 각각 SSH 접속해서 tail -f를 해도 됩니다. 하지만 10대가 넘으면 이 방식은 무너집니다.
서버 수가 늘어날수록 생기는 문제:
| 상황 | 서버 3대 | 서버 10대 이상 |
|---|---|---|
| 장애 발생 | SSH 접속 3번 | SSH 접속 10번 (어디서 났는지도 모름) |
| 요청 추적 | 수동으로 시간 맞춰 비교 | 사실상 불가 |
| 특정 에러 검색 | grep 3번 | grep 10번 + 결과 취합 |
| 로그 분석 | 텍스트 분석 | 집계 불가 |
중앙 로그 수집 후:
# 모든 서버의 Nginx 500 에러를 한 번에 검색 (Kibana/Loki)
nginx.response_code:500 AND @timestamp:[now-1h TO now]
# 특정 요청 ID로 전체 흐름 추적
request_id:"abc-123-def"
rsyslog 원격 전송
rsyslog로 시스템 로그 중앙 전송
10대 서버에 보안 사고가 발생했습니다. 침입자가 자신의 흔적을 지우려 로그 파일을 삭제했습니다. 로그가 각 서버에만 있었다면 그 서버의 기록은 영구히 사라집니다. 중앙으로 실시간 전송되고 있었다면 로컬 삭제와 무관하게 증거가 남습니다. 로그 중앙화는 분석 편의뿐 아니라 보안 증적 보존의 관점에서도 필수입니다. rsyslog는 추가 설치 없이 설정 한 줄로 이 기반을 만들 수 있습니다.
rsyslog는 대부분의 Linux 배포판에 기본 설치된 시스템 로그 데몬입니다. 별도 에이전트 없이 /etc/rsyslog.conf 설정만으로 원격 서버로 로그를 전송할 수 있습니다.
# rsyslog 설정 파일에 전송 규칙 추가
# /etc/rsyslog.d/forward.conf
# TCP 전송 (권장 — 신뢰성 있는 전송)
*.* @@logserver.internal:514
# UDP 전송 (빠르지만 유실 가능)
*.* @logserver.internal:514
# 특정 facility만 전송 (auth, kern만 중앙 전송)
auth,authpriv.* @@logserver.internal:514
# 중요도 이상만 전송 (warning 이상)
*.warning @@logserver.internal:514
# 설정 파일 문법 확인
sudo rsyslogd -N1 -f /etc/rsyslog.d/forward.conf
# rsyslog 재시작
sudo systemctl restart rsyslog
# 전송 테스트 (로그 서버에서 수신 확인)
logger "test message from $(hostname)"
# 로그 서버에서 확인
sudo tail -f /var/log/remote/$(hostname).log
로그 서버 측 rsyslog 설정 (수신 서버):
# /etc/rsyslog.conf 또는 /etc/rsyslog.d/receive.conf
# TCP 514 포트 수신 활성화
module(load="imtcp")
input(type="imtcp" port="514")
# 클라이언트별 파일로 분리 저장
template(name="RemoteLogs" type="list") {
constant(value="/var/log/remote/")
property(name="hostname")
constant(value=".log")
}
*.* ?RemoteLogs
rsyslog 방식은 시스템 로그(auth, kern, syslog 등)에 적합합니다. 애플리케이션 로그 파일(catalina.out, nginx access_log 등)을 수집하려면 Filebeat가 더 적합합니다.
Filebeat 설치와 설정
Filebeat — 경량 로그 수집 에이전트
rsyslog는 시스템 로그를 잘 처리하지만, Nginx access.log나 Tomcat catalina.out 같은 애플리케이션 로그 파일을 중앙으로 보내려면 별도 처리가 필요합니다. cron으로 주기적으로 복사하는 방법은 수 분의 지연과 유실 위험이 있습니다. Filebeat는 파일 변경을 실시간으로 감지하고 끊김 없이 전송하며, 서버 재시작 후에도 마지막 위치를 기억합니다. 서버당 수십 MB 메모리만 쓰면서도 안정적인 수집을 보장합니다.
Filebeat는 각 서버에 설치되는 경량 에이전트입니다. 지정한 로그 파일을 읽어 Elasticsearch나 Logstash로 전송합니다. 메모리 사용량이 적고 설정이 단순합니다.
# Filebeat 설치 (Ubuntu/Debian)
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.x.x-amd64.deb
sudo dpkg -i filebeat-8.x.x-amd64.deb
# CentOS/RHEL
sudo rpm -ivh filebeat-8.x.x-x86_64.rpm
# 설치 확인
filebeat version
# /etc/filebeat/filebeat.yml
# 수집할 로그 파일 지정
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/tomcat/logs/catalina.out
- /opt/tomcat/logs/localhost.*.log
fields:
service: tomcat
environment: production
host: "{{ .Hostname }}"
fields_under_root: true
multiline.pattern: '^[0-9]{2}-[A-Z][a-z]+-[0-9]{4}'
multiline.negate: true
multiline.match: after
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
fields:
service: nginx
environment: production
# Elasticsearch로 직접 전송 (Logstash 없이)
output.elasticsearch:
hosts: ["elasticsearch.internal:9200"]
username: "elastic"
password: "${ELASTIC_PASSWORD}"
index: "filebeat-%{[fields.service]}-%{+yyyy.MM.dd}"
# 또는 Logstash로 전송
# output.logstash:
# hosts: ["logstash.internal:5044"]
# 로깅 설정
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
multiline 설정은 Java stack trace처럼 여러 줄이 하나의 이벤트인 경우를 처리합니다. 첫 줄 패턴이 날짜로 시작하면, 날짜가 아닌 줄들은 이전 이벤트의 연속으로 합칩니다.
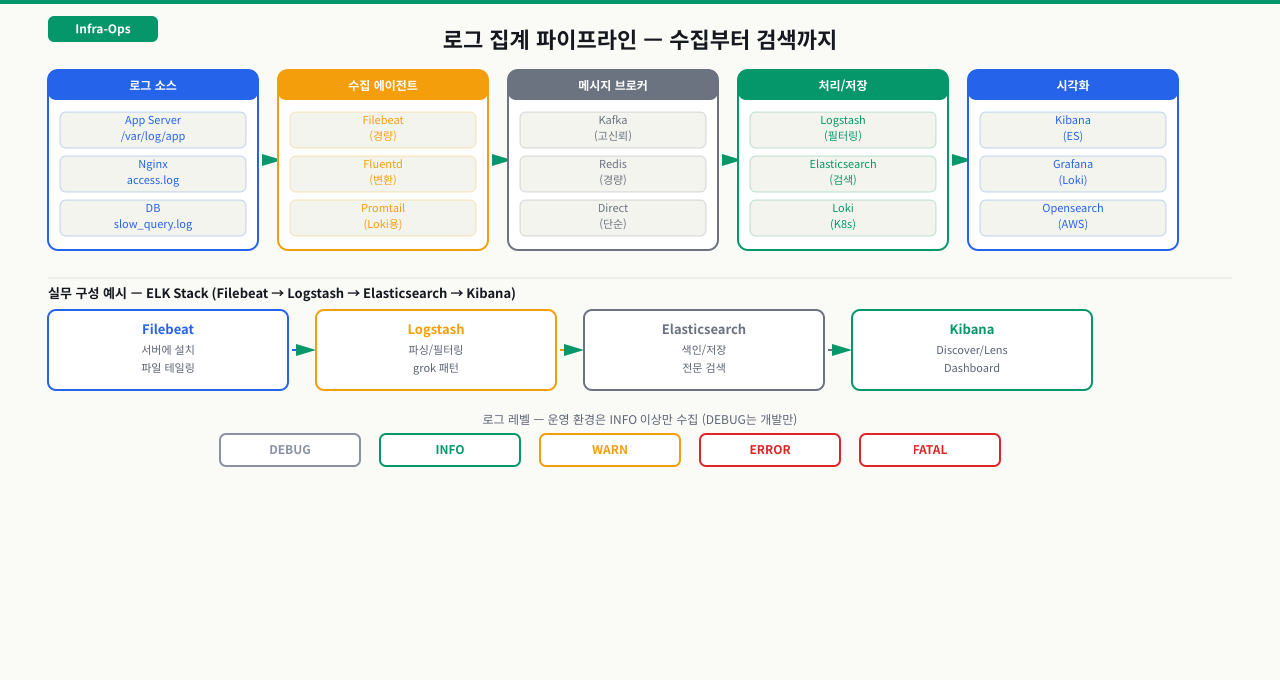
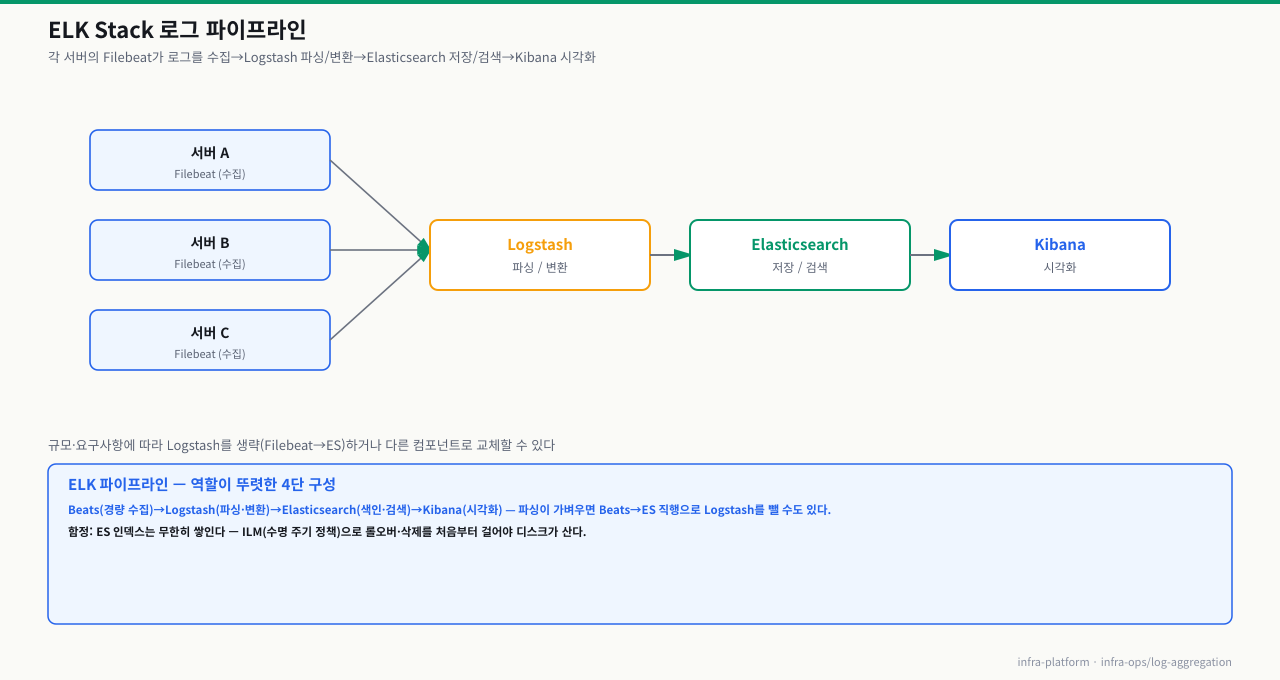
ELK Stack 구조
서버가 30대로 늘어나자 Kibana 없이 Elasticsearch에 쿼리로만 로그를 찾던 방식이 한계에 부딪혔습니다. 특정 서비스 에러 건수를 시간별 그래프로 보고 싶어도 쿼리를 매번 직접 작성해야 했습니다. ELK는 수집부터 시각화까지 파이프라인이 연결되어, 한 번 구성해두면 Kibana 대시보드에서 모든 서버의 로그를 시각적으로 탐색할 수 있습니다. 각 컴포넌트의 역할을 이해해야 장애 시 어느 단계가 막혔는지 파악할 수 있습니다.
ELK Stack은 로그 수집(Filebeat) → 처리(Logstash) → 저장·검색(Elasticsearch) → 시각화(Kibana)로 구성됩니다. 규모와 요구사항에 따라 Logstash를 생략하거나 다른 컴포넌트로 교체할 수 있습니다.
 확대
확대
각 컴포넌트 역할:
| 컴포넌트 | 역할 | 특징 |
|---|---|---|
| Filebeat | 로그 파일 읽어서 전송 | 경량, 각 서버에 설치 |
| Logstash | 파싱, 필터링, 변환 | Grok 패턴으로 구조화 |
| Elasticsearch | 인덱싱, 저장, 검색 | 고성능 풀텍스트 검색 |
| Kibana | 대시보드, 알림 | 브라우저 기반 UI |
Logstash 없이 운영하는 경우:
단순 로그 전송만 필요하면 Filebeat → Elasticsearch로 Logstash를 건너뛸 수 있습니다. Filebeat 자체에 간단한 필드 파싱 기능이 있어 Nginx, Apache, System 로그는 별도 설정 없이 구조화됩니다.
 확대
확대
수집 파이프라인 한눈에 — 로그가 모이는 단계
로그 한 줄이 파일에 찍힌 뒤 대시보드에 뜨기까지 — 수집 파이프라인 5단계
앞서 rsyslog·Filebeat·ELK 컴포넌트를 따로 봤지만, 실제 로그 한 줄은 이 조각들을 순서대로 통과해 대시보드에 도착합니다. 각 서버가 로그를 만들고 → 에이전트가 파일 끝을 tail 해 전송하고 → 파이프라인이 파싱·인덱싱하고 → 중앙 저장소에 쌓이고 → 조회·대시보드로 보입니다. 이 흐름을 알아야 "로그가 안 보인다"가 어느 단계에서 끊긴 것인지 — 원본에 없나, 전송이 안 되나, 파싱이 깨졌나, 조회 설정 문제인가 — 를 구분할 수 있습니다.
[각 서버·컨테이너] 앱이 catalina.out · access.log · stdout 에 로그를 씀
│
① 로그 생성 파일·표준출력에 한 줄씩 기록 (멀티라인 스택 포함)
│
② 에이전트 tail·전송 Filebeat harvester 가 끝을 추적 · registry 로 위치 기억 · 전송
│
③ 파싱·가공 Logstash·ingest 가 grok 으로 필드 구조화 · @timestamp 정규화
│
④ 중앙 저장·인덱싱 Elasticsearch 인덱스에 저장 · ILM 으로 수명 관리
│
⑤ 조회·대시보드 Kibana·Grafana 에서 검색·시각화
▼
[중앙] 12대 서버 로그를 한 화면에서 검색·추적
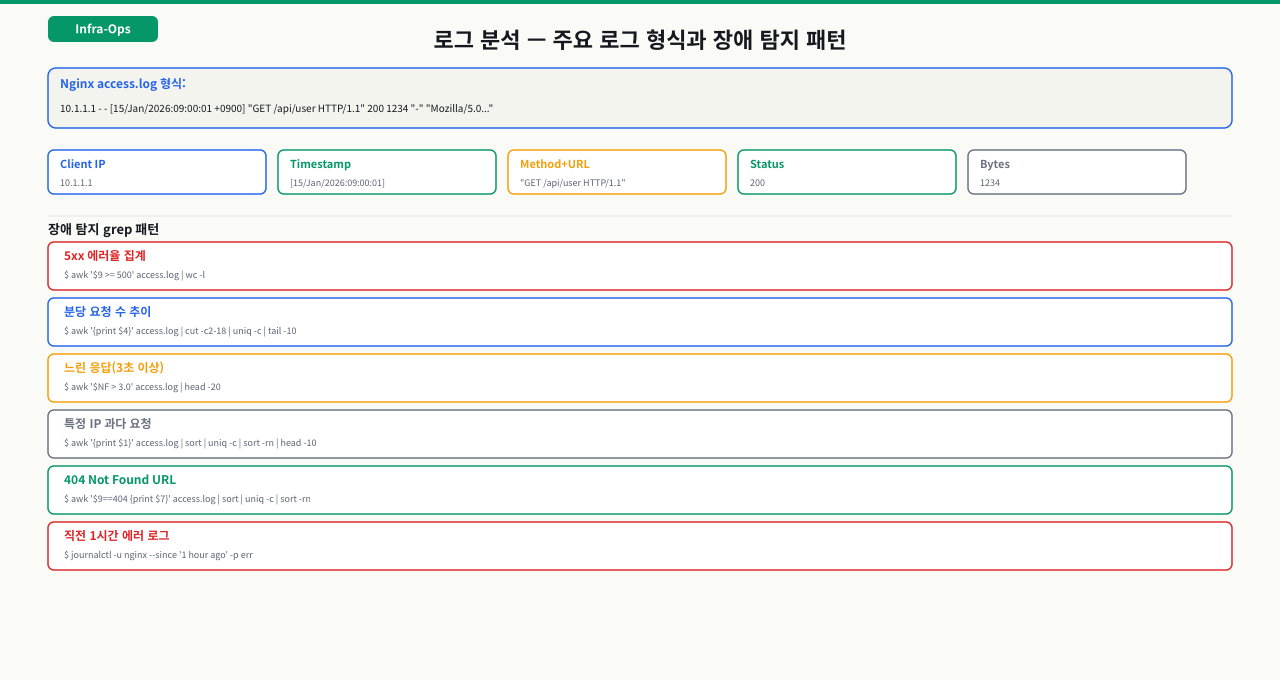
각 단계에서 하는 일과, 막히면 나타나는 증상:
| 단계 | 하는 일 | 막히면 증상 |
|---|---|---|
| ① 로그 생성 | 앱이 파일·stdout에 로그를 기록한다 | 로그 레벨이 INFO면 스택·디버그가 아예 안 찍혀 나중에 원본에도 정보가 없음; 멀티라인 스택이 한 줄씩 쪼개짐 |
| ② 에이전트 tail·전송 | Filebeat harvester 가 파일 끝을 추적하고 registry로 위치를 기억해 전송한다 | 에이전트 다운·파일 읽기 권한 없음이면 그 구간 유실(로테이션으로 사라진 파일은 복구 후에도 못 읽음); registry 손상 시 처음부터 다시 읽어 중복 |
| ③ 파싱·가공 | Logstash·ingest 가 grok으로 필드를 구조화하고 @timestamp를 정규화한다 | grok 패턴 불일치면 message가 통째로 미파싱 필드로 들어가 필드 검색이 안 됨; 타임존 미지정이면 @timestamp가 어긋나 다른 날짜 인덱스로 들어감 |
| ④ 중앙 저장·인덱싱 | Elasticsearch 가 인덱스에 저장하고 ILM 으로 수명을 관리한다 | 폭주 시 ES 가 429로 거절해 백프레셔·수집 지연(아래 심화); ILM 없으면 디스크가 차 인덱싱이 멈춤 |
| ⑤ 조회·대시보드 | Kibana·Grafana 에서 검색·시각화한다 | 인덱스 패턴 미등록·조회 타임존 설정 차이면 데이터가 저장돼 있어도 검색 결과에 안 뜸 |
즉 "로그가 안 보인다"는 단계마다 원인이 다릅니다 — 원본에 아예 없음(①), 전송이 안 됨(②: filebeat test output·파일 권한), 파싱 실패로 필드가 없음(③), 저장이 밀림(④: _cat/thread_pool/write 의 rejected), 조회 설정 문제(⑤: 인덱스 패턴). 원본 파일 → Filebeat 로그 → 파싱 결과 → ES 인덱스 docs.count → Kibana 패턴 순으로 짚으면 어느 칸에서 끊겼는지 드러납니다.
Grafana + Loki (경량 대안)
ELK 대신 Loki를 선택하는 상황
ELK는 강력하지만 Elasticsearch 운영 비용이 높습니다. 소규모 팀이나 리소스가 제한된 환경에서는 Grafana + Loki가 현실적인 대안입니다.
# Loki 대상으로 전송하는 Promtail 설정
# (Filebeat 역할을 Promtail이 대신)
# /etc/promtail/config.yml
server:
http_listen_port: 9080
clients:
- url: http://loki.internal:3100/loki/api/v1/push
scrape_configs:
- job_name: tomcat
static_configs:
- targets:
- localhost
labels:
job: tomcat
host: "{{ hostname }}"
__path__: /opt/tomcat/logs/catalina.out
- job_name: nginx
static_configs:
- targets:
- localhost
labels:
job: nginx
__path__: /var/log/nginx/*.log
ELK vs Grafana+Loki 선택 기준:
| 기준 | ELK | Grafana + Loki |
|---|---|---|
| 로그 검색 성능 | 매우 빠름 (인덱스) | 상대적으로 느림 (풀스캔) |
| 저장 공간 | 많이 필요 | 효율적 (압축) |
| 운영 복잡도 | 높음 | 낮음 |
| 비용 | 높음 | 낮음 |
| 메트릭 연동 | 별도 설정 필요 | Grafana로 메트릭과 통합 |
| 적합 규모 | 대규모, 복잡한 검색 | 중소규모, 단순 운영 |
이미 Grafana + Prometheus로 메트릭을 보고 있다면, 같은 Grafana에서 Loki로 로그도 보는 것이 대시보드 통합 면에서 훨씬 편합니다.
 확대
확대
로그 보존 정책
인덱스 수명 관리
로그를 영구히 저장하면 Elasticsearch 디스크가 금방 찹니다. 인덱스 수명 관리(ILM, Index Lifecycle Management)로 오래된 로그를 자동 삭제합니다.
# Elasticsearch ILM 정책 설정 예시 (API 호출)
# 30일 후 삭제하는 정책
curl -X PUT "elasticsearch:9200/_ilm/policy/filebeat-policy" \
-H 'Content-Type: application/json' \
-d '{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB",
"max_age": "1d"
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}'
# 인덱스 목록 확인
curl "elasticsearch:9200/_cat/indices?v&s=index" | grep filebeat
일반적인 보존 기간 기준:
| 로그 유형 | 권장 보존 기간 | 이유 |
|---|---|---|
| Nginx access_log | 30일 | 트래픽 분석, 장애 추적 |
| Tomcat catalina.out | 30일 | 장애 원인 분석 |
| Auth/보안 로그 | 90일 이상 | 보안 감사, 법적 요구사항 |
| DB slow query | 30일 | 성능 분석 |
실습
Filebeat를 설치하고 설정한 후 기동합니다. 출력 테스트로 Elasticsearch 연결이 되는지 먼저 확인합니다.
# Filebeat 기동
sudo systemctl enable --now filebeat
# 상태 확인
sudo systemctl status filebeat
# Elasticsearch 연결 테스트
sudo filebeat test output
# 출력 예시:
# elasticsearch: http://elasticsearch.internal:9200...
# parse url... OK
# connection...
# parse host... OK
# dns lookup... OK
# addresses: 10.0.1.100
# dial up... OK
# TLS... WARN secure connection disabled
# talk to server... OK
# version: 8.x.x
# 설정 파일 문법 검증
sudo filebeat test config
sudo systemctl start filebeat && sudo systemctl status filebeat- filebeat test config 로 설정 문법 먼저 확인, 그 다음 filebeat test output 으로 ES 연결 확인, 마지막으로 systemctl status filebeat 로 서비스 상태 확인 — 설정 오류가 있으면 서비스가 떠도 로그 전송 안 됨
- test 결과 기준: Config OK + "talk to server... OK"=Filebeat 정상 가동 준비 완료 / Config ERROR=설정 파일 문법 오류(들여쓰기, 경로 오류 등) / "connection refused"=ES가 미기동이거나 주소 오류
- Config OK이고 test output OK인데 /var/log/filebeat/filebeat 로그에 "Failed to open" 에러가 있으면 → 모니터링 대상 로그 파일 읽기 권한 없음 — ls -la 로 로그 파일 소유자 확인 후 filebeat 실행 계정에 읽기 권한 부여
Filebeat가 로그를 전송하면 Elasticsearch에 인덱스가 생성됩니다. 인덱스 목록에서 오늘 날짜 인덱스가 생성됐는지 확인합니다.
# 인덱스 목록 확인
curl -s "http://elasticsearch.internal:9200/_cat/indices?v" | grep filebeat
# 출력 예시:
# health status index docs.count store.size
# green open filebeat-nginx-2026.05.30 12453 2.3mb
# green open filebeat-tomcat-2026.05.30 8921 1.8mb
# 최근 수집된 로그 10건 확인
curl -s "http://elasticsearch.internal:9200/filebeat-nginx-*/_search?pretty&size=1" \
| grep -E '"message"|"@timestamp"|"service"'
curl -s 'http://elasticsearch.internal:9200/_cat/indices?v' | grep filebeat- _cat/indices 에서 오늘 날짜 filebeat 인덱스 존재 먼저 확인, 그 다음 docs.count 증가 추이 확인 — 인덱스는 있는데 docs.count가 0이면 Filebeat가 연결은 됐지만 로그를 전송 안 하는 것
- docs.count 기준: 1분 이상 경과해도 0이면 Filebeat가 로그를 읽지 못하는 상태 / 수십 초마다 증가하면 정상 수집 중 / 인덱스 자체가 없으면 Filebeat가 ES에 연결 자체를 못 한 것
- docs.count가 증가하는데 Kibana에서 검색 안 되면 → 인덱스 패턴이 미설정이거나 시간대(timezone)가 달라 다른 날짜 인덱스에 들어간 것 — Kibana Index Pattern에 filebeat-*로 등록됐는지 확인
트러블슈팅
상황: Filebeat는 실행 중인데 Elasticsearch에 인덱스가 생성되지 않습니다.
원인은 크게 세 가지입니다: 로그 파일 읽기 권한 없음, Elasticsearch 연결 실패, 설정 파일 경로 오류.
# 1. Filebeat 로그에서 에러 확인
sudo tail -50 /var/log/filebeat/filebeat
# 찾을 패턴:
# "Failed to open" → 파일 권한 문제
# "dial tcp ... connection refused" → ES 연결 실패
# "No such file or directory" → 경로 설정 오류
# 2. 로그 파일 권한 확인
ls -la /opt/tomcat/logs/catalina.out
# Filebeat는 기본적으로 root 또는 filebeat 유저로 실행
# → 소유자와 읽기 권한 확인
sudo chmod o+r /opt/tomcat/logs/catalina.out
# 또는 filebeat 유저를 tomcat 그룹에 추가
sudo usermod -aG tomcat filebeat
# 3. ES 연결 테스트
sudo filebeat test output
# → FAIL이면 ES 호스트/포트/인증 정보 확인
# 4. 설정 파일의 paths 경로 직접 확인
sudo ls -la /opt/tomcat/logs/catalina.out
sudo ls -la /var/log/nginx/access.log
상황: Elasticsearch에 같은 로그 라인이 두 번 이상 저장됩니다.
Filebeat는 registry 파일에 "어느 파일의 어느 위치까지 읽었는지"를 기록합니다. 이 파일이 손상되거나 삭제되면 처음부터 다시 읽어 중복이 발생합니다.
# registry 파일 위치 확인
sudo find /var/lib/filebeat -name "*.json" 2>/dev/null
# 또는
cat /etc/filebeat/filebeat.yml | grep registry
# registry 내용 확인 (JSON 형식)
sudo cat /var/lib/filebeat/registry/filebeat/data.json | python3 -m json.tool | head -30
# 중복이 발생한 경우 registry를 격리해 리셋 (처음부터 재수집)
# 주의: 이미 수집된 로그가 다시 전송됩니다. 원본을 바로 삭제하지 않습니다.
sudo systemctl stop filebeat
REGISTRY_DIR="/var/lib/filebeat/registry"
sudo test "$(sudo readlink -f "$REGISTRY_DIR")" = "$REGISTRY_DIR" || { echo "registry 경로 검증 실패" >&2; exit 1; }
sudo mv -- "$REGISTRY_DIR" "${REGISTRY_DIR}.backup.$(date +%Y%m%d%H%M%S)"
sudo systemctl start filebeat
# 중복 제거가 필요하다면 Elasticsearch에서 직접 처리
# (document_id를 로그 파일 경로 + 오프셋으로 설정해 중복 방지)
중복 방지를 위한 설정:
# filebeat.yml에 document ID 지정
output.elasticsearch:
hosts: ["elasticsearch.internal:9200"]
pipeline: "filebeat-%{[fields.service]}"
로그 중복보다 더 나쁜 것은 로그 누락입니다. 중복이 발생하면 Elasticsearch의 deduplication 기능을 활용하거나, 잠시 감수하는 것도 방법입니다.
심화 — 파이프라인이 밀릴 때: 백프레셔와 수집 지연
심화: 로그가 폭증하면 어디에 고이나 — 백프레셔의 내부 동작
수집 파이프라인은 평상시엔 잘 흐르다가 정작 장애로 로그가 폭증하는 순간 병목을 드러냅니다. Filebeat가 어떻게 흐름을 조절하는지 알아야, 중앙화가 "장애 때 오히려 눈을 가리는" 역설을 피할 수 있습니다.
- Filebeat는 유실보다 블로킹을 택한다: 다운스트림(Elasticsearch/Logstash)이 못 받으면 Filebeat는 내부 큐가 차고, 그러면 harvester가 파일을 읽는 속도 자체를 늦춥니다(백프레셔). 기본 정책은 at-least-once라, 함부로 버리지 않고 기다립니다. 그 대가로 수집이 실시간에서 밀립니다.
- ES가
429를 던지면 재시도가 쌓인다: Elasticsearch가 색인 부하로 bulk 요청을 거절(429 Too Many Requests)하면 Filebeat는 지수 백오프로 재시도합니다. 폭주가 계속되면 재시도 큐가 커지고, Kibana에 보이는 최신@timestamp가 현재보다 수 분 뒤처집니다. - 밀림은 디스크로 전가된다: harvester가 느려지는 동안 원본 로그 파일은 계속 커집니다. 로테이션이 돌아도 Filebeat가 아직 다 못 읽은 파일의 inode를 붙잡고 있으면, 지워진 파일이 디스크에서 해제되지 않아 용량이 샙니다(
close_removed·clean_removed설정과 얽힘). - 그래서 한계는 '드롭 여부'가 아니라 '어디까지 버티나': 큐 크기(
queue.mem), 백오프 상한, ES 색인 처리량이 폭주를 얼마나 흡수하는지가 관건입니다. 흡수 한계를 넘으면 결국 디스크가 차거나(블로킹형) 오래된 이벤트를 포기(드롭형)하게 됩니다.
정리하면, 중앙 로그는 '평균 처리량'이 아니라 '피크 폭주'를 기준으로 용량을 잡아야 하고, 온콜은 대시보드의 최신 데이터가 실시간이라고 가정하면 안 됩니다.
상황: 대형 장애로 에러 로그가 평소의 수십 배로 쏟아졌습니다. 온콜이 Kibana를 보니 몇 분 전부터 새 에러가 안 보였고 "회복됐다"고 판단해 대응을 늦췄습니다. 그런데 사용자 신고는 계속 들어왔습니다.
원인: 폭주로 Elasticsearch 색인이 밀려 bulk 요청에 429가 반환됐고, Filebeat가 백프레셔로 전송을 늦추며 재시도 큐에 로그가 적체됐습니다. Kibana에 보이는 최신 @timestamp가 실제 현재보다 8분 뒤처져, '에러가 멈춘 것'이 아니라 '최신 에러가 아직 도착하지 않은 것'이었습니다. 중앙화가 만든 착시입니다.
진단: 파이프라인이 밀렸는지부터 확인합니다.
# ES가 bulk를 거절하는지(색인 큐/거절 카운트)
curl -s "http://elasticsearch.internal:9200/_cat/thread_pool/write?v&h=node_name,active,queue,rejected"
# Filebeat가 백프레셔로 발행이 막혔는지(로그에 429/backoff)
sudo grep -iE "429|Too Many Requests|backoff|pipeline blocked" /var/log/filebeat/filebeat | tail -20
동시에 @timestamp의 최댓값과 현재 시각의 차이(수집 지연)를 재고, 서버 로컬의 원본 로그(tail -f catalina.out)와 대조합니다.
해결: 회복 판단은 중앙 대시보드 하나에 의존하지 말고, 원본 로컬 로그나 앱 지표(에러율 메트릭)로 교차확인합니다. 근본 대책은 피크 흡수력 확보 — ES 색인 성능·샤드 설계 개선, Filebeat와 ES 사이에 버퍼(Kafka/Logstash persistent queue) 도입, Kibana 대시보드에 '수집 지연(ingestion lag)' 패널을 상시 노출해 지연 자체를 지표로 감시하는 것입니다. '로그가 안 보임'은 '문제가 없음'이 아니라 '아직 안 들어옴'일 수 있습니다.
실제 업무에서 이 지식이 쓰이는 상황:
팀 규모가 커지고 서버 수가 늘면 로그 중앙화는 선택이 아니라 필수가 됩니다. 처음 ELK를 도입할 때 가장 큰 허들은 "어디서부터 시작하는가"입니다.
단계적 도입 전략:
1단계 (서버 5대 미만): 개별 SSH 확인
→ tail -f, grep 으로 충분
2단계 (5~20대): 중앙 로그 서버 + rsyslog
→ 한 서버에 rsyslog 수신 설정
→ 각 서버에서 @@logserver:514 전송
3단계 (20대 이상 또는 팀 확장): Filebeat + ELK/Loki
→ Filebeat 에이전트 각 서버 설치
→ Elasticsearch 클러스터 또는 Loki 구축
→ Kibana/Grafana 대시보드 구성
ELK를 도입하기 전에 Filebeat가 수집할 로그 파일 목록과 예상 로그 양을 먼저 계산합니다. 하루 로그 100MB 서버 10대라면 1GB/day, 30일 보존이면 30GB입니다. Elasticsearch 디스크는 이것의 2배 이상 여유가 필요합니다(인덱스 복제본 포함).
Loki를 먼저 시도하는 이유:
Elasticsearch는 강력하지만 운영이 무겁습니다. 처음 로그 중앙화를 도입한다면 Grafana + Loki + Promtail 조합이 빠르게 셋업하고 유지 비용이 낮아 현실적입니다. 이미 Prometheus로 메트릭 모니터링을 하고 있다면 같은 Grafana 화면에서 로그까지 통합해서 볼 수 있습니다.
명령어·단축키 빠른 참조
수집 파이프라인을 세팅·점검하고 폭주 시 밀림을 진단할 때 쓰는 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
*.* @@host:514 | rsyslog 시스템 로그 TCP 원격 전송(신뢰성) | @host는 UDP(빠르나 유실) |
rsyslogd -N1 -f | rsyslog 설정 문법 검증 | rsyslogd -N1 -f /etc/rsyslog.d/forward.conf |
logger | 전송 테스트용 로그 발생 | logger "test from $(hostname)" 후 수신 확인 |
filebeat test config | Filebeat 설정 문법 검증 | 기동 전 필수 |
filebeat test output | ES/Logstash 연결 확인 | talk to server... OK면 정상 |
systemctl enable --now filebeat | 부팅 등록 + 즉시 기동 | 상태는 systemctl status filebeat |
curl _cat/indices | ES 인덱스 수신 확인 | curl -s 'es:9200/_cat/indices?v' | grep filebeat |
curl _cat/thread_pool/write | ES 색인 큐·거절(rejected) 확인 | 폭주·백프레셔 진단 |
curl _search | 최근 수집 문서 조회 | curl -s 'es:9200/filebeat-*/_search?pretty&size=1' |
grep -iE "429|backoff" | Filebeat 백프레셔·전송 지연 확인 | … /var/log/filebeat/filebeat | tail |
ls -la / chmod o+r | 로그 파일 읽기 권한 진단·부여 | chmod o+r /opt/tomcat/logs/catalina.out |
find /var/lib/filebeat -name '*.json' | registry(읽은 위치) 파일 찾기 | 중복 수집 시 확인 |
rm -rf …/registry | registry 리셋(처음부터 재수집) | 중복 감수, stop 후 실행 |
관련 모듈로 더 깊이:
- HTTP 에러 코드 해석과 장애 원인 추적 — 중앙으로 모은 로그에서 에러 코드와 스택 트레이스를 해석하는 법
- CPU/메모리/디스크 임계치 관리와 logrotate — 수집한 로그 폭증에 대응하는 logrotate와 디스크 임계치 관리
- 애플리케이션 성능 모니터링과 대시보드 구성 — 로그와 함께 같은 Grafana에서 메트릭까지 통합 관측하는 구성
다음 모듈에서는 CPU/메모리/디스크 임계치 관리와 logrotate — 서버 용량 기반 모니터링 알람 설계를 다룹니다.