서비스 운영 중 갑자기 DB 서버 디스크가 가득 차서 MySQL이 멈췄습니다. 백업이 있다고 생각했는데 담당자가 퇴사하면서 백업 스크립트가 실제로 돌아가고 있는지 아무도 모르는 상태입니다. 복구를 시도하려 해도 마지막 백업이 3개월 전 것뿐입니다.
백업은 "있으면 좋은 것"이 아닙니다. 없으면 복구 자체가 불가능합니다. 이 모듈에서는 파일·설정·DB를 어떻게 백업하고, 실제로 복구가 되는지 검증하는 방법까지 다룹니다.
- 1RTO와 RPO 개념을 설명하고 우리 서비스 기준을 정의할 수 있다
- 2Full / Incremental / Differential 백업 차이를 알고 전략을 선택할 수 있다
- 3tar + rsync로 파일/설정 백업 스크립트를 작성하고 실행할 수 있다
- 4mysqldump --single-transaction으로 무중단 DB 백업을 수행할 수 있다
- 5백업에서 실제 복구 테스트를 수행하고 복구 성공을 검증할 수 있다
- 6DR(재해복구) 개념과 Active-Passive / Active-Active 구성 차이를 설명할 수 있다
백업의 기본 개념
RTO, RPO, 그리고 백업 유형
서버 디스크가 고장났습니다. "백업 있죠?"라는 질문에 "있긴 한데 일주일 전 것입니다"라고 답했습니다. 1주일치 주문 데이터가 사라질 수 있는 상황입니다. 복구까지 몇 시간이 걸리냐는 질문에는 답을 못 했습니다. 백업 주기와 복구 목표를 숫자로 정해두지 않으면, 막상 사고가 났을 때 "충분한가"를 판단할 기준이 없습니다. RTO와 RPO가 그 기준입니다.
백업 전략을 세우기 전에 두 가지 숫자를 먼저 정해야 합니다. RTO와 RPO입니다. 이 숫자를 정하지 않으면 "얼마나 자주", "어떤 방식으로" 백업해야 하는지 결정할 수 없습니다.
 확대
확대
RTO (Recovery Time Objective)
장애 발생 후 서비스 복구까지 허용되는 최대 시간
예: "RTO 4시간" → 장애 후 4시간 이내 서비스 재개 필요
RPO (Recovery Point Objective)
복구 시 허용 가능한 데이터 손실 기간
예: "RPO 1시간" → 최대 1시간 치 데이터 손실 감수 가능
→ 1시간마다 백업이 필요하다는 의미
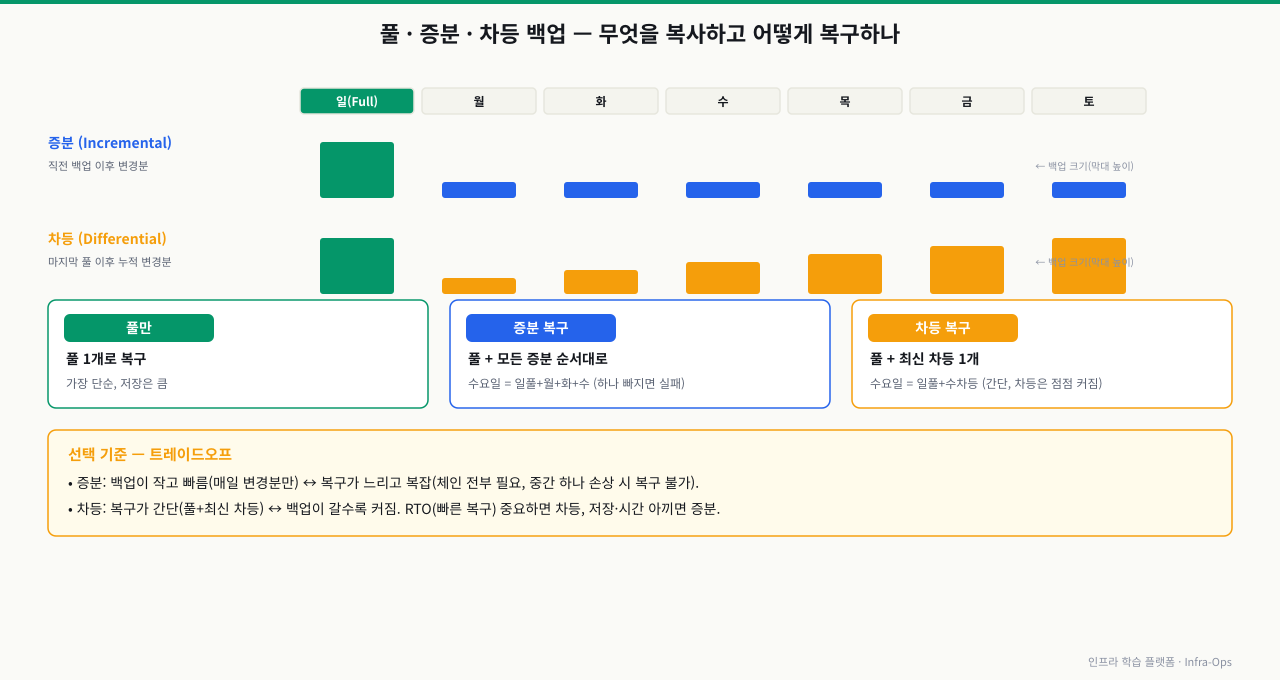
백업 유형 비교:
| 유형 | 내용 | 용량 | 복구 방법 | 적합한 상황 |
|---|---|---|---|---|
| Full (전체) | 전체 데이터 | 크다 | Full 하나로 복구 | 주 1회 |
| Incremental (증분) | 마지막 백업 이후 변경분 | 매우 작다 | Full + 모든 Incremental 순서대로 | 매일 백업, 용량 제한 시 |
| Differential (차등) | 마지막 Full 이후 변경분 | 중간 | Full + 최신 Differential | 복구 단순성 vs 용량 균형 |
 확대
확대
실무에서 가장 많이 쓰는 조합:
주 1회 Full 백업 (일요일 새벽)
일별 Incremental 백업 (월~토 새벽)
월별 Full 백업 → 별도 장기 보관
보관 정책 예시:
일별 백업 → 7일 보관
주별 백업 → 4주 보관
월별 백업 → 12개월 보관
파일/설정 백업
tar과 rsync로 설정 파일 백업하기
서버 장애 후 재구성할 때 가장 먼저 필요한 것이 설정 파일입니다. /etc/nginx/, /opt/tomcat/conf/, /etc/ssh/sshd_config — 이것들이 없으면 서버를 새로 만들어도 서비스가 올라오지 않습니다.
# 설정 파일 tar 백업 (날짜 포함 파일명)
sudo tar -czf /backup/config_$(date +%Y%m%d).tar.gz \
/etc/nginx/ \
/opt/tomcat/conf/ \
/etc/ssh/sshd_config \
/etc/systemd/system/
# 백업 파일 확인
ls -lh /backup/config_*.tar.gz
# 백업 내용 목록 확인 (복구 전 검증)
tar -tzf /backup/config_20260530.tar.gz | head -20
rsync로 원격 서버에 백업 (권장):
# 원격 서버로 애플리케이션 디렉터리 동기화
# --delete: 원본에서 삭제된 파일을 대상에서도 삭제
# -avz: archive(권한/타임스탬프 유지) + verbose + gzip 압축
rsync -avz /opt/app/ backup-server:/backup/app/ --delete
# 설정 파일 원격 백업
rsync -avz /etc/nginx/ backup-server:/backup/nginx-conf/
# SSH 키 인증 사용 (비밀번호 없이 자동 실행)
rsync -avz -e "ssh -i /root/.ssh/backup_key" /opt/app/ backup-server:/backup/app/
백업 자동화 (crontab):
# crontab -e 로 추가
# 매일 새벽 2시 설정 파일 백업 + rsync
0 2 * * * tar -czf /backup/config_$(date +\%Y\%m\%d).tar.gz /etc/nginx/ /opt/tomcat/conf/ && rsync -avz /backup/ backup-server:/backup/$(hostname)/
# 7일 지난 로컬 백업 정리: 먼저 목록만 확인하고 보존 정책·승인 후 삭제 절차를 등록합니다.
0 3 * * * find /backup/ -xdev -type f -name "config_*.tar.gz" -mtime +7 -print
DB 백업
MySQL 무중단 백업 — mysqldump
서비스를 내리고 MySQL을 백업하라는 지시를 받았습니다. 30분이면 된다고 했는데, 새벽 트래픽이 있어 서비스 중단이 불가능합니다. 그렇다고 서비스가 살아있는 상태에서 백업하면 트랜잭션 도중에 파일이 잘려 일관성이 깨질 수 있습니다. --single-transaction 옵션이 이 문제를 해결합니다. InnoDB 스토리지 엔진의 특성을 이용해 잠금 없이 일관된 스냅샷을 만들어 줍니다.
DB 백업은 파일 백업보다 까다롭습니다. 서비스가 운영 중인 상태에서 데이터 일관성을 유지해야 하기 때문입니다. InnoDB에는 --single-transaction이 유용하지만, MyISAM 같은 비트랜잭션 테이블에는 동일한 일관성을 보장하지 않으므로 엔진 구성을 먼저 확인해야 합니다.
# MySQL 전체 DB 무중단 백업 (InnoDB 기준)
mysqldump \
--single-transaction \
--all-databases \
--routines \
--triggers \
-u root -p \
> /backup/mysql_$(date +%Y%m%d_%H%M).sql
# 특정 DB만 백업
mysqldump --single-transaction -u root -p mydb > /backup/mydb_$(date +%Y%m%d).sql
# 압축 저장 (용량 절감)
mysqldump --single-transaction --all-databases -u root -p | gzip > /backup/mysql_$(date +%Y%m%d).sql.gz
# 백업 파일 크기 확인
ls -lh /backup/mysql_*.sql.gz
DB 복구:
# SQL 파일에서 복구
mysql -u root -p < /backup/mysql_20260530.sql
# 압축 파일에서 복구
gunzip -c /backup/mysql_20260530.sql.gz | mysql -u root -p
# 특정 DB만 복구
mysql -u root -p mydb < /backup/mydb_20260530.sql
# 복구 후 확인
mysql -u root -p -e "SHOW DATABASES;"
mysql -u root -p mydb -e "SHOW TABLES;"
PostgreSQL 백업:
# pg_dump (PostgreSQL)
pg_dump -U postgres mydb > /backup/postgres_mydb_$(date +%Y%m%d).sql
# 전체 클러스터 백업
pg_dumpall -U postgres > /backup/postgres_all_$(date +%Y%m%d).sql
# 복구
psql -U postgres mydb < /backup/postgres_mydb_20260530.sql
스냅샷 백업
VM 스냅샷과 LVM 스냅샷
OS 업그레이드 작업을 시작했는데 중간에 패키지 충돌로 시스템이 불안정해졌습니다. tar 백업을 복원하려면 OS를 재설치하고 파일을 하나씩 복사해야 합니다. 작업 전에 VM 스냅샷이 있었다면, 클릭 한 번에 작업 이전 상태로 돌아올 수 있습니다. 스냅샷은 파일 백업과 다르게 디스크 전체 상태를 특정 시점에 동결합니다. 시스템 변경 작업 전에 반드시 찍어야 하는 이유입니다.
스냅샷은 특정 시점의 디스크 상태를 통째로 보존합니다. 파일 단위가 아닌 블록 레벨 복사라 복구가 빠르지만, 공간 효율은 낮습니다.
# LVM 스냅샷 (Linux 볼륨 관리자)
# 현재 LVM 구성 확인
lvdisplay
vgdisplay
# 스냅샷 생성 (10GB 용량 할당)
sudo lvcreate -L 10G -s -n data_snap /dev/vg0/data
# 스냅샷을 마운트해서 파일 확인
sudo mkdir /mnt/snap
sudo mount /dev/vg0/data_snap /mnt/snap
ls /mnt/snap/
# 스냅샷 삭제 (더 이상 필요 없을 때)
sudo umount /mnt/snap
sudo lvremove /dev/vg0/data_snap
AWS EBS 스냅샷 (클라우드 환경):
# EBS 스냅샷 생성 (AWS CLI)
aws ec2 create-snapshot \
--volume-id vol-12345678 \
--description "Daily backup $(date +%Y%m%d)"
# 스냅샷 목록 확인
aws ec2 describe-snapshots --owner-ids self
# 오래된 스냅샷 삭제 (30일 이전)
aws ec2 describe-snapshots --owner-ids self \
--query "Snapshots[?StartTime<='$(date -d '30 days ago' +%Y-%m-%d)'].SnapshotId" \
--output text | xargs -I {} aws ec2 delete-snapshot --snapshot-id {}
실습 — 백업 스크립트 실행과 복구 테스트
아래 백업 스크립트를 /opt/scripts/backup.sh로 저장하고 실행합니다. 실무에서 쓰는 백업 스크립트의 기본 구조입니다.
#!/bin/bash
# /opt/scripts/backup.sh
BACKUP_DIR="/backup/$(date +%Y%m%d)"
LOG_FILE="/var/log/backup.log"
mkdir -p "$BACKUP_DIR"
echo "[$(date)] 백업 시작" >> "$LOG_FILE"
# 1. 설정 파일 백업
tar -czf "$BACKUP_DIR/config.tar.gz" \
/etc/nginx/ \
/opt/tomcat/conf/ 2>> "$LOG_FILE"
echo "[$(date)] 설정 파일 백업 완료" >> "$LOG_FILE"
# 2. MySQL 백업 (비밀번호는 /root/.my.cnf에 저장)
mysqldump --single-transaction --all-databases 2>> "$LOG_FILE" | \
gzip > "$BACKUP_DIR/mysql.sql.gz"
echo "[$(date)] MySQL 백업 완료" >> "$LOG_FILE"
# 3. 원격 rsync (backup-server가 접근 가능한 경우)
# rsync -avz "$BACKUP_DIR/" backup-server:/backup/$(hostname)/ 2>> "$LOG_FILE"
echo "[$(date)] 백업 완료: $BACKUP_DIR" >> "$LOG_FILE"
# 7일 이전 후보만 출력합니다. 목록과 마운트 지점을 검토한 뒤,
# 승인된 보존 정책·백업 카탈로그를 통해 별도 삭제 작업을 수행합니다.
find /backup/ -mindepth 1 -maxdepth 1 -type d -mtime +7 -print 2>> "$LOG_FILE"
sudo bash /opt/scripts/backup.sh- /backup/YYYYMMDD/ 디렉터리 생성 여부를 먼저 확인(ls -la /backup/) — 디렉터리가 없으면 스크립트 실행 자체가 실패한 것으로 exit code와 /var/log/backup.log 첫 줄부터 확인
- ls -lh /backup/YYYYMMDD/에서 config.tar.gz와 mysql.sql.gz 파일 크기 확인 — 0바이트 또는 1KB 미만이면 압축 실패. 정상적인 MySQL 덤프는 테이블 수에 따라 수 MB 이상
- 파일이 생성됐고 크기도 정상인데 /var/log/backup.log에 "백업 완료"가 없으면 — 체크섬 검증 또는 원격 전송 단계에서 실패한 것. 로그 마지막 ERROR 줄이 실제 실패 원인
백업이 있다고 안심하면 안 됩니다. 복구가 실제로 되는지 정기적으로 테스트해야 합니다. 개발 환경의 별도 DB(test_restore)에 복구해 봅니다.
실습 전제와 안전 경계: 운영 DB에 접속한 상태에서 실행하지 마세요. 격리된 개발 인스턴스와 복구 전용 계정(최소 권한)을 사용하고,
SELECT @@hostname, @@port, DATABASE();로 대상과 DB 이름을 먼저 확인합니다.test_restore가 이미 존재하면 중단하고 담당자의 승인 후 별도 이름을 사용하세요. 이 실습에는 운영 DB 삭제 명령이 포함되지 않습니다.
# 테스트용 DB 생성
mysql -u root -p -e "CREATE DATABASE test_restore;"
# 백업에서 복구
gunzip -c /backup/$(date +%Y%m%d)/mysql.sql.gz | mysql -u root -p test_restore
# 복구 결과 확인
mysql -u root -p test_restore -e "SHOW TABLES;"
mysql -u root -p test_restore -e "SELECT COUNT(*) FROM users;" # 레코드 수 확인
# 설정 파일 복구 테스트
tar -tzf /backup/$(date +%Y%m%d)/config.tar.gz # 내용 확인
tar -xzf /backup/$(date +%Y%m%d)/config.tar.gz -C /tmp/restore_test/ # 임시 경로에 풀기
ls /tmp/restore_test/etc/nginx/ # 파일 존재 확인
# 테스트용 DB 정리는 반드시 개발 환경임을 재확인하고, 대상 이름을 고정한 뒤 실행합니다.
mysql -u root -p -e "SELECT @@hostname, DATABASE();"
# 운영 DB에서는 DROP을 실행하지 마세요. 테스트 환경에서만 승인 후:
# mysql -u root -p -e "DROP DATABASE test_restore;"
gunzip -c /backup/$(date +%Y%m%d)/mysql.sql.gz | mysql -u root -p test_restore- 복구 테스트 시 SHOW TABLES 결과를 먼저 본다 — 테이블 수가 원본 DB와 일치해야 정상. 0개이면 dump 파일이 비었거나 DB 지정 오류
- SELECT COUNT(*) FROM users 등 핵심 테이블의 레코드 수를 원본과 비교 — 1% 이상 차이나면 백업 도중 트랜잭션이 잘린 것으로 --single-transaction 옵션 없이 덤프한 경우 발생
- 테이블도 있고 레코드 수도 맞는데 설정 파일 복구 시 오류가 나면 — tar.gz 내 경로가 절대 경로로 저장됐는지 확인(tar tvf config.tar.gz). 경로 불일치면 복구 경로에 strip 옵션 필요
DR(재해복구) 개념
백업 한 벌이 재해 복구로 이어지기까지 — 생성부터 서비스 재개까지 6단계
새벽에 주 전산실이 정전·침수로 통째로 내려갔습니다. 이제 "백업 있어요?"만으로는 부족합니다 — 그 백업이 어디에 있고, 어느 시점으로 되돌릴지 고르고, 정말 복원되는지 확인하고, 서비스를 다시 띄우기까지가 한 줄로 이어져야 합니다. 백업은 이 사슬의 첫 고리일 뿐이고, 한 고리라도 끊기면 "백업은 있는데 복구가 안 되는" 사고가 납니다. 온프레미스 운영에서 이 사슬이 실제로 어떻게 흐르는지 단계로 봅니다.
[평상시]
│
① 백업 생성 주기(일·주)·방식(Full·증분·스냅샷)으로 원본을 뜬다
│ → 백업 성공 로그 + 무결성(gunzip -t) 확인
│
② 오프사이트 보관 같은 랙·같은 전산실을 벗어난 곳으로 사본을 옮긴다
│ (원격 NAS·테이프 반출·타 전산실/타 리전)
│
─ ─ ─ ─ ─ 여기까지가 재해 '전'에 끝나 있어야 한다 ─ ─ ─ ─ ─
│
③ 재해 발생 주 사이트 소실(정전·화재·랜섬웨어) → 원본·로컬백업 동시 상실
│
④ 복구 지점 선택 살아남은 사본 중 어느 시점으로 되돌릴지 고른다 = RPO 결정
│ (가장 최근 정상 백업 · 랜섬웨어면 감염 이전 시점)
│
⑤ 복원 · 검증 DR 사이트·새 서버에 복원 → 건수·정합성 확인 후에야 '복구' 인정
│
⑥ 서비스 재개 앱 기동 → 접속정보 전환 → DNS를 DR로 재지정 → 검증 = RTO 종료
▼
[정상화] 이 ①~⑥ 전체 시간이 RTO, ④에서 잃은 데이터 폭이 RPO
각 단계가 하는 일과, 그 단계가 비어 있을 때 터지는 것:
| 단계 | 하는 일 | 이 단계가 비면 |
|---|---|---|
| ① 백업 생성 | 정해진 주기·방식으로 원본을 뜨고 성공/무결성을 남긴다 | 크론이 조용히 죽어 있으면 "3개월 전 것"만 남음 · 무결성 미확인이면 복원 때 잘린 파일 발견 |
| ② 오프사이트 보관 | 사본을 주 사이트 밖으로 물리적으로 분리한다 | 원본과 같은 서버·랙에만 있으면 재해 시 백업도 함께 소실(3-2-1 규칙 위반) |
| ③ 재해 발생 | (통제 밖 사건) 감지·선언이 여기서 이뤄진다 | 감지·에스컬레이션 절차가 없으면 복구 착수가 늦어 RTO를 먹는다 |
| ④ 복구 지점 선택 | 살아남은 사본 중 되돌릴 시점을 고른다 | 최신 백업만 기계적으로 고르면 랜섬웨어·논리오류가 그대로 복원됨 · 백업 간격이 곧 손실 폭(RPO) |
| ⑤ 복원 · 검증 | DR 사이트에 실제로 올리고 건수·정합성을 확인 | 검증 없이 "복원됨"으로 넘기면 깨진 덤프·빠진 테이블을 운영에서 발견 |
| ⑥ 서비스 재개 | 기동·접속전환·DNS 재지정·최종 검증 | DR 사이트 매핑(IP·DNS·시크릿)이 준비 안 됐으면 데이터는 살아도 트래픽이 안 붙음 |
즉 "복구됐다"는 ①~⑥이 모두 이어졌다는 뜻이고, 흔한 사고는 대부분 ②(사본이 같이 죽음)·④(감염 시점 복원)·⑤(미검증 백업)·⑥(DR 매핑 부재)에서 사슬이 끊깁니다. 그래서 온프레 운영은 백업 스크립트만 믿지 않고 오프사이트 반출·복구 지점 정책·복구 리허설·DR 사이트 매핑을 사슬의 각 고리로 따로 점검합니다. 전체 ①~⑥ 시간을 재면 RTO가, ④에서 고른 시점과 장애 순간의 간격을 재면 RPO가 실제 숫자로 드러납니다.
Active-Passive DR과 Active-Active DR
백업은 "데이터 보호"이고, DR(Disaster Recovery)은 "서비스 연속성"입니다. 서버 건물이 화재로 소실됐을 때 다른 곳에서 서비스를 재개하는 것이 DR의 목표입니다.
DR 구성 유형:
| 유형 | 구성 | RTO | RPO | 비용 | 특징 |
|---|---|---|---|---|---|
| Active-Passive | 주 센터 운영 중, 백업 센터 대기 | 수 시간 | 수 시간~1일 | 중간 | 가장 일반적 |
| Active-Active | 두 센터 모두 운영, 트래픽 분산 | 수 분 | 거의 0 | 높음 | 대형 서비스 |
| Cold Standby | 백업 센터 꺼진 상태 | 수일 | 마지막 백업 | 낮음 | 소규모/비핵심 |
 확대
확대
Active-Passive DR 흐름:
평상시: 주 센터 운영, 백업 센터에 rsync/복제로 데이터 동기화
장애시: DNS를 백업 센터 IP로 변경
→ 서비스 재개 (RTO: DNS TTL + 기동 시간)
Active-Active DR 흐름:
평상시: 두 센터 모두 트래픽 처리 (로드밸런서로 분산)
장애시: 한 센터 장애 → 자동으로 다른 센터로 100% 전환
→ 서비스 중단 거의 없음 (RTO: 수 초~수 분)
복구 테스트가 중요한 이유:
실제 사례:
백업은 3년간 매일 실행
→ 어느 날 복구 시도
→ mysqldump 파일이 깨져 있음 (디스크 용량 부족으로 중간에 잘린 파일)
→ 실제 복구 불가
예방:
월 1회 개발환경에서 복구 테스트 실행
복구 성공 여부를 로그로 기록
정기 리포트로 백업 상태 모니터링
트러블슈팅
원인: 백업 중 디스크 용량 부족, 네트워크 단절, 또는 mysqldump 실행 중 DB 연결 끊김으로 파일이 중간에 잘립니다. 파일 크기는 있어도 내용이 불완전한 경우입니다.
# 백업 파일 무결성 확인
gunzip -t /backup/mysql_20260530.sql.gz
# 출력이 없으면 파일 정상, gzip: ... unexpected end of file 이면 파일 손상
# SQL 파일 끝부분 확인 (정상적인 mysqldump 결과의 마지막 줄)
gunzip -c /backup/mysql_20260530.sql.gz | tail -5
# 정상: -- Dump completed on 2026-05-30 02:15:31
# 백업 스크립트에 검증 추가
mysqldump --single-transaction --all-databases | gzip > /backup/mysql.sql.gz
if [ ${PIPESTATUS[0]} -ne 0 ]; then
echo "백업 실패!" | mail -s "BACKUP FAILED" admin@example.com
fi
# 디스크 용량 사전 확인 (백업 전)
df -h /backup
# Use% 80% 이상이면 백업 전 정리 필요
예방: 백업 스크립트에 종료 코드 체크와 파일 크기 최소 임계값 검증을 추가합니다. 월 1회 복구 테스트를 캘린더에 등록해 습관화합니다.
원인: 로그 테이블(audit_log, access_log 등)이 수백만 건 쌓인 상태에서 전체 dump를 받으면 수십 GB가 되는 경우가 있습니다. 이 테이블들은 백업이 필요 없는 경우가 많습니다.
# 테이블별 크기 확인 (큰 테이블 찾기)
mysql -u root -p -e "
SELECT table_schema, table_name,
ROUND(data_length/1024/1024, 2) AS data_MB,
ROUND(index_length/1024/1024, 2) AS index_MB
FROM information_schema.tables
ORDER BY data_length DESC
LIMIT 20;"
# 특정 테이블 제외하고 백업
mysqldump --single-transaction \
--ignore-table=mydb.audit_log \
--ignore-table=mydb.access_log \
mydb | gzip > /backup/mydb_no_logs_$(date +%Y%m%d).sql.gz
# 데이터 없이 스키마만 백업 (로그 테이블은 구조만)
mysqldump --no-data mydb audit_log > /backup/audit_log_schema.sql
# 로그 테이블 주기적 정리 (30일 이전 데이터 삭제)
mysql -u root -p mydb -e "
DELETE FROM audit_log WHERE created_at < DATE_SUB(NOW(), INTERVAL 30 DAY);"
예방: 백업 전략 수립 시 테이블별 백업 필요성을 분류합니다. 로그·임시·캐시 테이블은 제외 목록에 넣고 문서화합니다.
심화 — 복구가 되는 것과, 제 시간에 서비스가 사는 것은 다르다
심화: RTO/RPO는 '백업이 있다'가 아니라 '페일오버가 된다'로 증명된다
복구 테스트를 통과했다고 안심하면, 정작 진짜 재해 당일에 목표 시간을 못 맞춰 놀라게 됩니다. 파일이 살아 있다는 것과 서비스가 제 시간에 다시 산다는 것은 다른 약속이기 때문입니다.
- RTO는 파일 복원이 아니라 종단(end-to-end) 시간: 실제 복구 시간에는 장애 감지, 대기(standby) 승격, DNS를 대기 사이트로 재지정하고 그 TTL이 전파되기까지의 대기, 애플리케이션의 접속 문자열·시크릿 교체, 콜드 캐시 예열, 최종 검증이 모두 들어갑니다. 파일 복구 테스트는 이 중 한 조각만 재므로, 종단 RTO는 훨씬 큽니다.
- RPO는 백업 주기가 아니라 장애 순간의 복제 지연: 대기로 비동기 복제 중이라면 실제 손실은 '몇 시간마다 백업'이 아니라 장애가 난 그 순간의 복제 지연(
Seconds_Behind_Master)만큼입니다. 그 지연이 진짜 RPO이고, 아무도 재지 않으면 사고 때 처음 알게 됩니다. - RTO/RPO는 리허설로만 증명된다: 유일하게 믿을 수 있는 숫자는 점검 시간에 실제 페일오버를 일으켜 시계로 잰 값입니다. 정기적인 페일오버 리허설(game day)로 종단 시간을 측정하고 런북의 빠진 단계를 찾아냅니다.
- 되살아난 주(primary)를 그대로 다시 붙이지 않는다: 페일오버 후 옛 주가 복구되면, 승격된 대기와 동시에 쓰기를 받아 데이터가 갈라지는 split-brain이 납니다. 옛 주는 자동 복귀시키지 말고 격리(fencing)한 뒤 대기와 재동기화해야 데이터 정합이 유지됩니다.
정리하면, 백업은 '데이터가 있다'를 보장하고, DR 리허설은 '제 시간에 정합성을 지키며 산다'를 보장합니다. 둘 다 있어야 재해에 버팁니다.
상황: 페일오버 자체는 빨랐습니다. 대기를 승격하고 접속을 돌려 5분 만에 서비스가 정상으로 보였습니다. 그런데 장애 직전 몇 초 사이의 주문이 사라졌고, PG에는 결제가 찍혔는데 우리 DB에는 대응 주문이 없는 교차 불일치가 다수 발견됐습니다.
원인: 복제가 비동기(async)였습니다. 주는 커밋을 마치면 대기의 반영을 기다리지 않으므로, 대기는 항상 복제 지연만큼 주보다 뒤처져 있습니다. 주가 죽는 순간 아직 대기로 전송되지 않은 커밋들은 승격된 대기에 존재하지 않아 유실됐고, 그 지연 폭이 곧 실제 RPO였습니다. 아무도 Seconds_Behind_Master를 실제 손실 지표로 보지 않았던 것이 근본 원인입니다.
진단: 대기의 복제 지연 이력을 확인합니다 — 평소 0에 가까웠는지, 트래픽 피크에 튀었는지. 살릴 수 있다면 옛 주의 마지막 커밋 지점과 대기의 마지막 반영 지점을 비교해 유실 구간을 특정하고, 그 시간대의 PG 정산 기록을 주문 테이블과 대사(reconciliation)해 어떤 결제가 주문 없이 떠 있는지 목록화합니다. semi-sync/동기 복제가 설정돼 있었는지도 확인합니다.
해결: 유실분은 PG 정산 기록을 기준으로 주문을 재생성해 정합을 맞춥니다(그래서 앱은 재실행해도 중복되지 않는 멱등 설계가 필요합니다). 재발 방지로 핵심 경로는 semi-sync 복제(주가 대기 ack를 기다림)나 동기 복제로 바꿔 RPO를 좁히고, 복제 지연에 알람을 겁니다. 그리고 승격 절차·데이터 대사를 페일오버 리허설에 포함해, 손실 폭과 대사 런북을 사고 전에 검증해 둡니다.
실제 업무에서 이 흐름이 생명줄이 되는 상황:
백업은 평소에는 존재 자체를 잊게 만드는 것이 잘 된 백업입니다. 그러나 사고가 났을 때 없으면 모든 것이 끝납니다. 실무에서 주니어가 바로 적용할 수 있는 최소 기준:
# 1. 지금 당장 실행: 우리 서버에 백업이 돌고 있는가 확인
crontab -l | grep backup
ls -lt /backup/ | head -10 # 가장 최근 백업 날짜 확인
# 2. 백업이 없다면: 최소 스크립트라도 crontab에 등록
# 3. 백업이 있다면: 복구 테스트 한 번이라도 해보기
# 복구 테스트 기록 템플릿
echo "$(date): 복구 테스트 성공 — DB 레코드 수 일치, 설정 파일 정상" >> /var/log/restore_test.log
RTO/RPO를 서비스 오너(개발 리더, 기획팀)와 합의해두는 것도 인프라팀의 역할입니다. "4시간 내 복구"를 목표로 한다면 백업 주기, 복구 절차, DR 구성이 모두 그에 맞게 설계되어야 합니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 파일·설정·DB 백업과 복구 검증 명령을 실전 옵션과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
tar -czf / -tzf / -xzf | 설정 파일 묶기·목록 확인·복원 | tar -czf config_$(date +%F).tar.gz /etc/nginx/ |
rsync -avz --delete | 원격 서버로 증분 동기화 백업 | rsync -avz /opt/app/ backup-host:/backup/app/ |
mysqldump --single-transaction | InnoDB 무중단 일관 백업 | mysqldump --single-transaction --all-databases | gzip > db.sql.gz |
mysql < | SQL 덤프에서 DB 복구 | gunzip -c db.sql.gz | mysql -u root -p test_restore |
pg_dump / pg_dumpall | PostgreSQL DB·클러스터 백업 | pg_dump -U postgres mydb > mydb.sql |
gunzip -t | 백업 gzip 무결성 검증 | gunzip -t db.sql.gz (에러 없으면 정상) |
mysqldump --ignore-table | 대용량 로그 테이블 제외 백업 | --ignore-table=mydb.access_log |
lvcreate -s | LVM 스냅샷(작업 전 시점 동결) | lvcreate -L 10G -s -n data_snap /dev/vg0/data |
aws ec2 create-snapshot | EBS 볼륨 스냅샷 생성 | --volume-id vol-123 --description "$(date +%F)" |
crontab -e / -l | 백업 자동화 등록·확인 | 0 2 * * * /opt/scripts/backup.sh |
find … -mtime +7 -delete | 오래된 백업 정리 | find /backup/ -name 'config_*.tar.gz' -mtime +7 -delete |
df -h | 백업 전 디스크 여유 확인 | df -h /backup (Use% 80%↑면 정리) |
관련 모듈로 더 깊이:
- AWS 기반 인프라 운영 실무와 전환 고려사항 — 스냅샷·다중 AZ 등 클라우드가 제공하는 백업·DR 기능 활용
- 계정 권한 관리, 보안 헤더, TLS 강화 실무 — 백업 데이터 자체의 보안과 무결성 관리
다음 모듈에서는 온프레미스와 클라우드 인프라의 차이, AWS EC2/RDS/S3/CloudWatch 운영 실무를 다룹니다.