오전 9시, 모니터링 알림이 울립니다. "WAS 응답 없음." SSH로 접속해서 무엇부터 확인해야 할까요? 프로세스는 살아있는지, 어느 포트에서 대기 중인지, CPU와 메모리는 어떤지, 디스크는 꽉 차지 않았는지 — 5분 안에 서버 상태를 파악하는 것이 첫 번째 과제입니다.
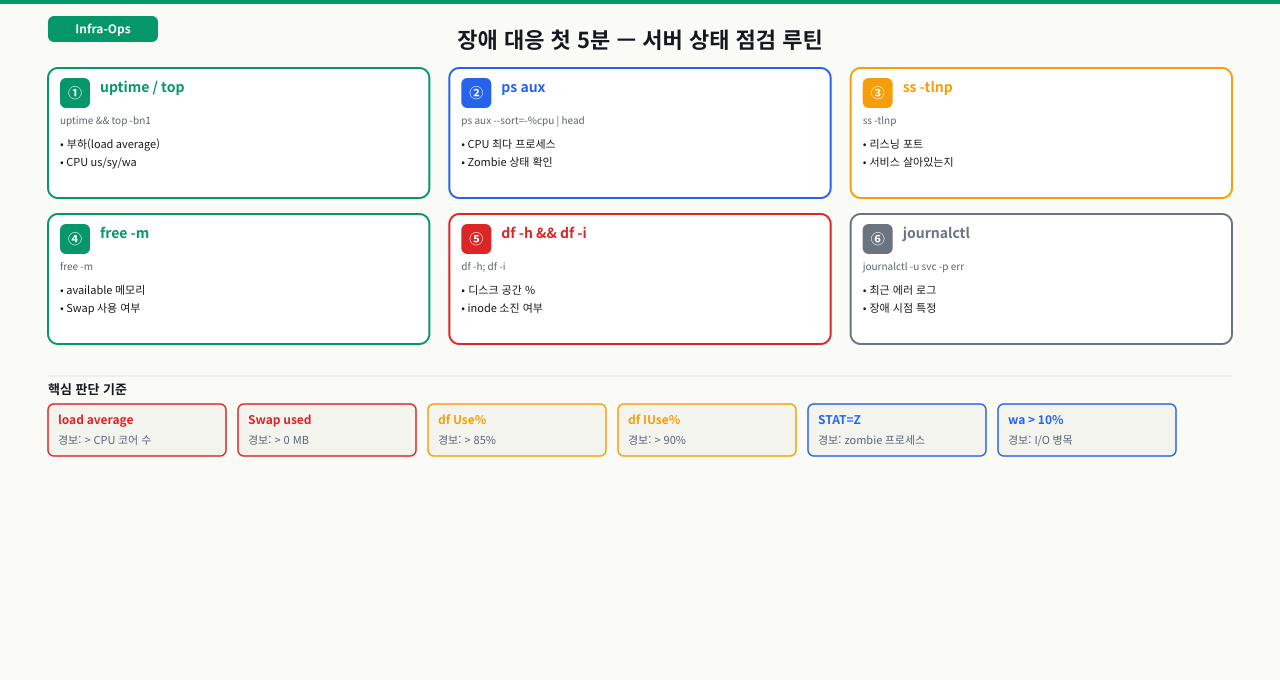
이 모듈의 명령어들이 장애 대응 첫 5분의 전부입니다.
- 1ps aux와 top으로 프로세스 목록과 CPU/메모리 사용량을 해석할 수 있다
- 2ss -tlnp로 리스닝 포트와 연결된 프로세스를 확인할 수 있다
- 3df -h로 디스크 사용량을 확인하고 df -i로 inode 소진 여부를 파악할 수 있다
- 4free -m으로 메모리/스왑 상태를 해석할 수 있다
- 5journalctl로 서비스 로그를 시간 기준으로 조회할 수 있다
which ps top htop ss lsof df du free journalctlsudo apt-get install -y htop 2>/dev/null || sudo dnf install -y htop 2>/dev/null; echo donewhich lsof || sudo apt-get install -y lsof 2>/dev/null || sudo dnf install -y lsof 2>/dev/null장애 신고 한 건을 원인 프로세스까지 좁히는 5단계 — 증상에서 조치까지
장애 알림은 늘 "느리다 / 안 뜬다 / 꽉 찼다"는 모호한 한 줄로 옵니다. 이걸 특정 프로세스·포트·자원 상한으로 좁히는 순서가 머릿속에 없으면 명령을 아무거나 두드리게 됩니다. 이후 절에서 ps·ss·df·free를 하나씩 익히기 전에, 그 명령들을 "증상 → 원인 프로세스"로 꿰는 전체 지도를 먼저 봅니다. 핵심은 한 단계에서 나온 신호가 어떤 원인을 가리키는가입니다 — 같은 "load 높음"도 CPU 포화일 수도, 디스크 I/O 대기일 수도 있기 때문입니다.
[장애 신고] "느리다 / 안 뜬다 / 꽉 찼다" ← 증상은 늘 모호하다
│
① 증상 분류 + 부하 확인 uptime · top (느림인가 · 연결불가인가 · 기록실패인가)
│
② 원인 프로세스 특정 ps aux · top (누가 CPU · 메모리를 먹나, STAT는)
│
③ 포트 점유 · 바인딩 확인 ss -tlnp · lsof (기대 포트가 떴나, 누가 잡았나)
│
④ 자원 상한 확인 free · df · df -i · lsof +L1
│ (메모리 · 디스크 · inode · fd 중 어디가 한계인가)
│
⑤ 원인 프로세스 조치 kill · truncate · bind 수정 · 재시작
▼
[복구] 모호한 증상을 특정 프로세스 · 포트 · 자원으로 좁혀 조치
각 단계에서 무엇을 보고, 그 신호가 어떤 원인을 가리키나:
| 단계 | 무엇을 보나 | 이 신호가 나오면 (원인 매핑) |
|---|---|---|
| ① 부하 분류 | uptime의 load, top의 %us·%wa | load 높은데 %CPU 낮고 %wa 높음 → CPU 아닌 디스크 I/O 병목 |
| ② 프로세스 | ps aux의 %CPU·%MEM·STAT | STAT=Z 좀비(부모가 자식 회수 못 함) · D 다수(중단 불가 I/O 대기) |
| ③ 포트 | ss -tlnp의 LISTEN · 바인딩 · 점유 PID | Address already in use=포트 충돌 / DB가 0.0.0.0 바인딩=외부 노출 |
| ④ 자원 상한 | free(Swap) · df(용량) · df -i(inode) · lsof +L1 | Swap>0=메모리 압박 / inode 100%=파일 수 소진 / deleted-but-open=fd 누수로 공간 미회수 |
| ⑤ 조치 | 원인별 최소 개입 | 잔존 프로세스=kill / 실행 중 로그=truncate(rm 금지) / 노출=bind 주소 수정 |
핵심은 한 증상이 여러 원인을 가리킨다는 것입니다. "느리다"는 CPU(②)일 수도, I/O 병목(①의 %wa)일 수도, 메모리 스왑(④)일 수도 있고, "디스크가 꽉 찼다"는 용량 · inode(df -i) · 삭제됐지만 열린 파일(lsof +L1) 셋 중 하나입니다. 그래서 아무 명령이나 두드리지 말고 ①→⑤를 한 번 훑어 증상을 특정 프로세스 · 포트 · 자원으로 좁히는 것이 장애 첫 몇 분 대응의 뼈대입니다. 이후 절들은 이 단계마다 쓰는 ps · ss · df · free · journalctl을 하나씩 익힙니다.
프로세스 점검
ps로 프로세스 확인
서버에서 갑자기 CPU가 치솟거나 메모리가 부족해질 때, 어느 프로세스가 문제인지 가장 먼저 파악해야 합니다. ps 명령어를 모르면 top 출력만 바라보다 시간을 낭비하게 됩니다. 실무에서는 ps aux와 ps -ef를 상황에 맞게 구분해서 쓰는 것이 첫 번째 진단 루틴입니다.
 확대
확대
장애 알림을 받고 서버에 접속했는데 "뭘 먼저 확인해야 할지" 몰라서 5분을 허비했다면, 원인은 점검 루틴이 없어서입니다. Tomcat 프로세스가 살아있는지, CPU를 독점하는 프로세스가 있는지 — ps를 제대로 읽지 못하면 가장 기본적인 판단도 내릴 수 없습니다. 프로세스 상태를 30초 안에 파악하는 것이 장애 대응 속도의 출발점입니다.
# 전체 프로세스 목록 (자주 쓰는 형식)
ps aux
# USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
# tomcat 1234 2.5 8.3 3145728 340000 ? Sl 09:00 2:15 java -Xmx2g ...
# nginx 5678 0.0 0.1 12345 4096 ? Ss 09:00 0:00 nginx: master
# ps -ef 형식 (PPID 포함, 프로세스 계층 파악에 유용)
ps -ef | grep tomcat
# 특정 프로세스만 필터링
ps aux | grep nginx | grep -v grep
# 프로세스 이름으로 PID만 추출
pgrep -f tomcat
# 또는
pidof nginx
ps aux 컬럼 해석:
| 컬럼 | 의미 | 주목할 상황 |
|---|---|---|
%CPU | CPU 사용률 | 지속적으로 100%+ → 무한루프, 고부하 |
%MEM | 메모리 사용률 | 지속 증가 → 메모리 누수 의심 |
VSZ | 가상 메모리 (KB) | Java는 VSZ가 크게 나와도 정상 |
RSS | 실제 사용 물리 메모리 (KB) | 실제 소비량은 RSS 기준 |
STAT | 프로세스 상태 | Z=좀비, D=I/O 대기(많으면 디스크 문제) |
TIME | 누적 CPU 시간 | 갑자기 증가하면 비정상 부하 |
# CPU 사용률 TOP 10
ps aux --sort=-%cpu | head -11
# 메모리 사용률 TOP 10
ps aux --sort=-%mem | head -11
top으로 실시간 리소스 모니터링
CPU가 100%를 찍고 있는데 어떤 프로세스가 원인인지 모르면 재시작만 반복하게 됩니다. 재시작하면 잠깐 나아지다가 30분 후 다시 튀는 패턴이 반복됐는데, top으로 확인하니 특정 배치 스크립트가 주기적으로 CPU를 독점하고 있었습니다. load average가 코어 수보다 높다는 것의 의미, wa(I/O 대기)가 높을 때의 판단 기준을 알아야 원인을 좁힐 수 있습니다.
 확대
확대
top
# top - 14:30:00 up 2 days, 3:15, 2 users, load average: 0.52, 0.48, 0.45
# Tasks: 185 total, 1 running, 184 sleeping, 0 stopped, 0 zombie
# %Cpu(s): 5.2 us, 1.1 sy, 0.0 ni, 93.5 id, 0.1 wa, 0.0 hi, 0.0 si
# MiB Mem : 7821.4 total, 2341.2 free, 3621.8 used, 1858.4 buff/cache
# MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 3819.4 avail Mem
load average 해석:
0.52, 0.48, 0.45: 1분, 5분, 15분 평균 실행 큐 길이- CPU 4코어 서버에서 load average 4.0 = 100% 포화
- CPU 코어 수보다 지속적으로 높으면 응답 지연 발생
%Cpu 컬럼 해석:
| 항목 | 의미 | 주목 기준 |
|---|---|---|
us | 사용자 프로세스 CPU | 높으면 앱 레벨 부하 |
sy | 시스템(커널) CPU | 높으면 시스템 콜 과다 |
wa | I/O 대기 | 높으면(5%+) 디스크/네트워크 병목 |
id | 유휴(idle) | 낮으면 전체 CPU 부하 높음 |
top 인터랙티브 키:
q: 종료
k: 프로세스 종료 (PID 입력)
M: 메모리 사용률 기준 정렬
P: CPU 사용률 기준 정렬 (기본)
1: 코어별 CPU 사용률 표시
1. CPU 최다 소비 프로세스 확인
ps aux --sort=-%cpu | head -62. 메모리 최다 소비 프로세스 확인
ps aux --sort=-%mem | head -63. load average와 CPU 사용률 확인
uptime && nproc- ps aux 출력에서 먼저 USER 컬럼으로 어떤 계정이 프로세스를 실행하는지 보고, 그 다음 STAT 컬럼으로 상태 확인 — root로 실행 중인 서비스 계정 프로세스는 보안 정책 위반
- load average 기준: nproc 코어 수와 같으면 포화 임박(주의), 코어 수의 1.5배 이상이면 CPU 처리 대기열 포화 — 1분/5분/15분 값 중 15분 값이 높으면 일시적 spike가 아닌 지속적 과부하
- STAT=Z(좀비)가 있는데 TIME이 큰 프로세스도 동시에 보이면 → 특정 부모 프로세스가 자식 종료를 처리 못 하는 구조 — ps aux | grep defunct 로 좀비 프로세스 부모 PID 추적
포트 점검
ss와 lsof로 포트 확인
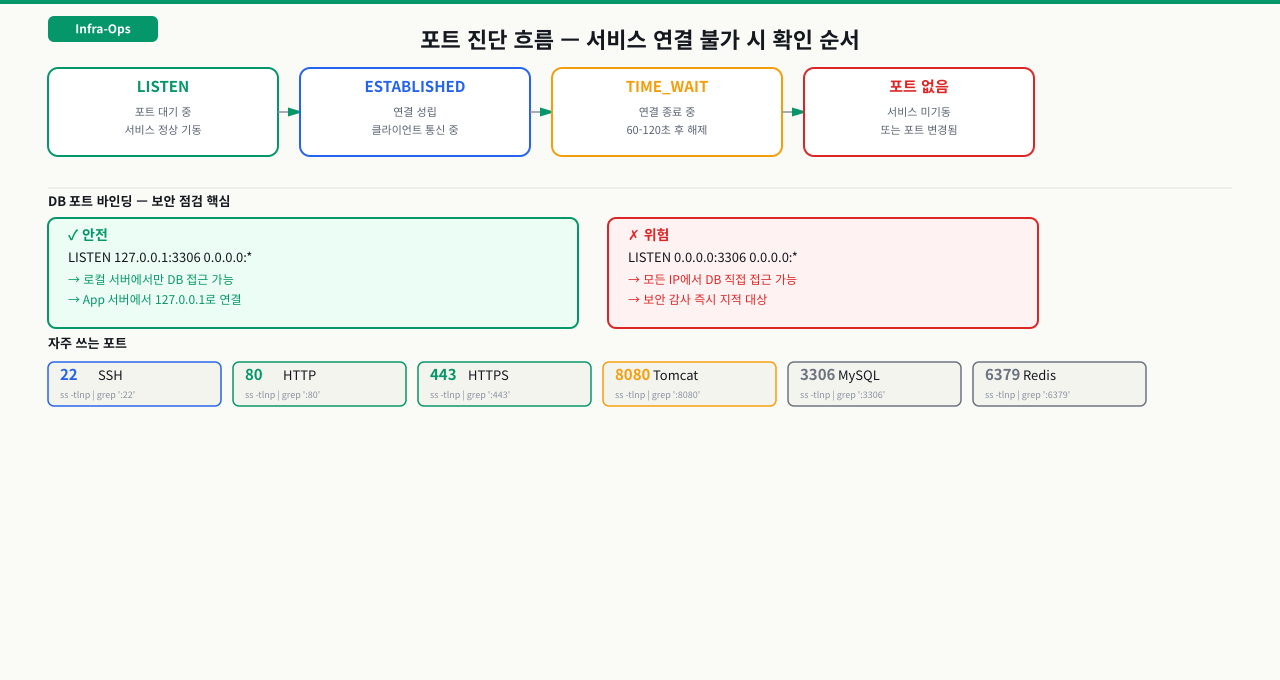
"서비스가 안 뜬다"는 제보를 받았는데 systemctl status는 정상이라고 합니다.
 확대
확인해보니 Tomcat이 8080이 아닌 18080으로 기동됐고, Nginx의 proxy_pass는 여전히 8080을 바라보고 있었습니다. 포트 번호가 맞지 않으면 서비스가 뜨더라도 트래픽이 전달되지 않습니다. 어떤 프로세스가 어느 포트를 점유하는지 1분 안에 파악하는 것이 연결 문제 진단의 핵심입니다.
확대
확인해보니 Tomcat이 8080이 아닌 18080으로 기동됐고, Nginx의 proxy_pass는 여전히 8080을 바라보고 있었습니다. 포트 번호가 맞지 않으면 서비스가 뜨더라도 트래픽이 전달되지 않습니다. 어떤 프로세스가 어느 포트를 점유하는지 1분 안에 파악하는 것이 연결 문제 진단의 핵심입니다.
netstat은 deprecated입니다. 현대 Linux에서는 ss를 사용합니다.
# 리스닝 중인 TCP 포트 전체 + 프로세스 정보
ss -tlnp
# State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
# LISTEN 0 128 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=1234,fd=6))
# LISTEN 0 511 0.0.0.0:8080 0.0.0.0:* users:(("java",pid=5678,fd=32))
# LISTEN 0 128 127.0.0.1:3306 0.0.0.0:* users:(("mysqld",pid=9012,fd=25))
# UDP 포트 포함
ss -ulnp
# 특정 포트에 무엇이 연결됐는지
ss -tnp | grep ':8080'
# 특정 포트를 점유한 프로세스 확인
sudo lsof -i:8080
# COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
# java 5678 tomcat 123u IPv4 89012 0t0 TCP *:8080 (LISTEN)
# 특정 PID가 열고 있는 파일/소켓
sudo lsof -p 5678 | head -20
일반적인 포트 매핑:
| 포트 | 서비스 | 비고 |
|---|---|---|
| 80 | HTTP (Nginx/Apache) | |
| 443 | HTTPS | |
| 8080 | Tomcat HTTP | |
| 8443 | Tomcat HTTPS | |
| 3306 | MySQL/MariaDB | 127.0.0.1만 LISTEN이 정상 |
| 5432 | PostgreSQL | |
| 6379 | Redis | |
| 22 | SSH |
# 외부에서 DB 포트가 열려있는지 확인 (보안 점검)
ss -tlnp | grep ':3306'
# LISTEN 0 80 127.0.0.1:3306 0.0.0.0:* ← 안전 (127.0.0.1만 바인딩)
# LISTEN 0 80 0.0.0.0:3306 0.0.0.0:* ← 위험! 모든 IP에서 접근 가능
1. 리스닝 포트 전체 확인
ss -tlnp2. 특정 포트 점유 프로세스 확인
sudo lsof -i:8080 2>/dev/null || ss -tlnp | grep ':8080'3. DB 포트 외부 노출 여부 보안 점검
ss -tlnp | grep -E ':3306|:5432|:6379'- ss -tlnp 에서 먼저 Local Address 컬럼으로 바인딩 IP를 보고, 그 다음 users 컬럼으로 어떤 프로세스가 점유하는지 확인 — 바인딩 IP가 예상과 다르면 서비스 설정 파일 확인 필요
- 바인딩 기준: 0.0.0.0=모든 외부 접근 가능(웹서버 정상, DB는 위험), 127.0.0.1=로컬 전용(DB 정상), :::=IPv6 포함 모든 접근 — DB 포트(3306/5432)가 0.0.0.0이면 즉시 bind-address 수정
- 예상 포트가 없는데 서비스 프로세스는 살아있으면 → 서비스가 다른 포트로 기동된 것 — ss -tlnp | grep <프로세스명> 으로 실제 사용 포트 확인 후 설정 파일과 대조
리소스 점검
df로 디스크 사용량 확인
자정에 로그 파일이 자동 삭제됐는데 디스크 사용률이 100%에서 내려오지 않았습니다. 삭제된 파일을 열고 있는 프로세스가 파일 핸들을 놓지 않고 있었기 때문입니다. 공간은 있는데 파일이 안 만들어지는 경우는 inode가 소진됐을 때입니다. df -h와 df -i를 항상 세트로 확인해야 이런 함정에서 벗어날 수 있습니다.
# 마운트된 파티션별 디스크 사용량
df -h
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 32G 16G 67% /
# /dev/sdb1 200G 45G 145G 24% /data
# tmpfs 3.9G 1.2M 3.9G 1% /dev/shm
# inode 사용량 (공간이 있어도 파일 못 만드는 상황 진단)
df -i
# Filesystem Inodes IUsed IFree IUse% Mounted on
# /dev/sda1 3276800 198432 3078368 7% /
# /var 655360 654990 370 100% /var ← inode 소진!
# 특정 디렉터리가 어느 파티션에 있는지 확인
df -h /opt/tomcat/logs
디스크 가득 찼을 때 원인 찾기:
# 각 디렉터리별 사용량 (1단계 깊이만)
du -sh /var/log/* | sort -rh | head -20
# 특정 디렉터리 하위 상세 확인
du -sh /var/log/nginx/*
# 가장 큰 파일 TOP 10 찾기 (전체 시스템)
sudo find / -xdev -type f -exec du -sh {} + 2>/dev/null | sort -rh | head -10
# /var 디렉터리 하위 큰 파일들
sudo du -ah /var | sort -rh | head -20
inode 소진 시 대응:
# inode 많이 쓰는 디렉터리 찾기
for dir in /var /tmp /opt; do
echo "$dir: $(find $dir -maxdepth 3 -type f 2>/dev/null | wc -l) files"
done
# 오래된 세션 파일, 임시 파일 정리 예시
find /var/lib/php/sessions -type f -mtime +7 -delete
find /tmp -type f -mtime +3 -delete
free로 메모리 상태 확인
Java 서비스가 갑자기 응답이 느려졌는데 CPU는 멀쩡했습니다. Swap 사용량을 보니 1GB가 사용 중이었고, JVM이 메모리 부족으로 디스크 swap을 쓰고 있었습니다. Swap은 디스크 속도로 동작하기 때문에 Java 애플리케이션은 swap이 0이어야 정상입니다. free -m을 보는 법을 모르면 이 상황을 메모리 문제로 진단하지 못합니다.
free -m
# total used free shared buff/cache available
# Mem: 7821 3621 2341 45 1858 3819
# Swap: 2047 0 2047
# 지속적으로 모니터링
watch -n 2 free -m
free 출력 해석 핵심:
-
available: 실제로 사용 가능한 메모리 (가장 중요한 지표)free + buff/cache 중 회수 가능한 것의 합available이 total의 10~15% 미만이면 메모리 부족 경고
-
buff/cache: OS 캐시 (필요 시 회수 가능) → 정상 현상- Linux는 남는 메모리를 캐시로 활용해 성능 향상
used가 높아 보여도buff/cache가 대부분이면 문제없음
-
Swap used> 0: 메모리 부족으로 디스크를 메모리처럼 사용 중- 응답 속도 급감의 원인, Java 애플리케이션은 특히 치명적
# Java 프로세스 실제 메모리 사용량 확인
ps aux --sort=-%mem | awk 'NR==1 || /java/'
# /proc으로 상세 확인
cat /proc/meminfo | grep -E 'MemTotal|MemFree|MemAvailable|SwapTotal|SwapFree|Cached'
journalctl로 서비스 로그 조회
서비스가 재시작됐는데 왜 재시작됐는지 알 수 없었습니다. catalina.out을 봤는데 로그가 너무 많아 어디서 오류가 났는지 찾기 힘들었습니다. journalctl로 시간 범위를 지정하면 장애 발생 시점의 로그만 추출할 수 있어 원인을 빠르게 좁힐 수 있습니다. 로그 파일을 전체 스크롤하는 것과 시간 기반으로 필터링하는 것의 차이는 30분 대 2분입니다.
# 특정 서비스 로그 (최근 100줄)
journalctl -u nginx -n 100 --no-pager
# 시간 범위 지정 조회
journalctl -u tomcat --since "2025-01-15 09:00:00" --until "2025-01-15 10:00:00"
journalctl -u tomcat --since "1 hour ago"
journalctl -u tomcat --since "30 min ago"
# 에러 레벨 이상만 조회
journalctl -u myapp -p err --since "today"
# 실시간 로그 팔로우
journalctl -u nginx -f
# 부팅 이후 전체 로그
journalctl -b
# 커널 메시지 (OOM killer 등 확인)
journalctl -k --since "today" | grep -E 'oom|killed|error' -i
OOM(Out of Memory) 발생 확인:
# OOM Killer가 프로세스를 죽였는지 확인
journalctl -k --since "today" | grep -i "oom\|killed process\|out of memory"
# 또는
dmesg | grep -i "oom\|killed"
1. 디스크 공간·inode 동시 확인
df -h && echo '---' && df -i2. 큰 디렉터리 찾기
du -sh /var/log/* 2>/dev/null | sort -rh | head -103. 메모리·스왑 상태 확인
free -m- df -h 로 디스크 사용률 먼저 보고, 이상 없으면 df -i 로 inode 사용률 추가 확인 — 공간은 있어도 inode 고갈 시 파일 생성 불가이므로 두 가지를 세트로 체크
- 사용률 기준: df -h Use% 85% 이상=즉시 원인 파악, df -i IUse% 90% 이상=소규모 파일 대량 생성 서비스 점검, free -m Swap used 0 이상=Java 서비스는 GC pause 증가 시작
- df -h는 여유 있는데 파일 생성 실패가 나면 → df -i 로 inode 고갈 확인 — inode가 90% 이상이면 find / -xdev -type f | wc -l 로 소규모 파일 다수 생성 위치 추적
1. 프로세스 및 부하 확인
uptime && ps aux --sort=-%cpu | head -62. 리스닝 포트 및 프로세스 확인
ss -tlnp3. 메모리 상태 확인
free -m4. 디스크 사용률 확인
df -h && df -i5. 실패한 서비스 및 최근 에러 로그 확인
systemctl list-units --state=failed 2>/dev/null; journalctl -p err --since '30 min ago' --no-pager 2>/dev/null | tail -20- uptime → ss -tlnp → free -m → df -h && df -i → systemctl list-units --state=failed 순서로 5분 점검 — 앞 단계에서 이상 발견 시 해당 항목에 집중하고 뒤 단계로 넘어가지 않아도 됨
- 수치 기준: load average(15분)가 코어 수의 0.7 이하=여유, 1.0=포화, 1.5 이상=즉시 개입 / available 메모리 20% 이상=여유, 10% 미만=스왑 시작 위험 / IUse% 90% 이상=파일 생성 불가 임박
- load average는 정상인데 ss -tlnp에 기대 포트가 없으면 → 서비스가 다운된 것 — systemctl list-units --state=failed 로 어떤 서비스가 죽었는지 확인 후 journalctl -u <서비스명>으로 원인 추적
심화 — 지운 파일이 공간을 안 돌려줄 때
심화: unlink와 참조 카운트 — rm 했는데 왜 df가 안 내려가나
'디스크가 꽉 찼다'는 알림에서 큰 파일을 지웠는데도 df가 꿈쩍 않는 경험은 인프라 운영의 통과의례입니다. 그 이유는 리눅스가 파일을 지우는 방식에 있습니다.
- rm은 '내용 삭제'가 아니라 unlink: 파일 이름은 디렉터리가 inode를 가리키는 링크일 뿐입니다.
rm은 그 링크(하드링크) 하나를 떼어낼 뿐이고, 실제 데이터 블록은 하드링크 수(link count)와 그 파일을 연 프로세스 수가 모두 0이 될 때 비로소 해제됩니다. - 열린 핸들이 공간을 붙잡는다: 그래서 로그를 쓰는 프로세스가 파일을 계속 열고 있으면,
rm으로 이름을 지워도(디렉터리에서는 사라져du에 안 잡힘) 프로세스가 그 파일 디스크립터를 닫을 때까지 블록이 반환되지 않습니다.df(파일시스템 사용량)와du(존재하는 파일 합계)가 어긋나는 전형적 원인입니다. - 찾고 회수하는 법:
lsof -nP +L1(또는lsof / | grep deleted)은 링크 수가 0인, 즉 '삭제됐지만 열려 있는' 파일과 그걸 붙잡은 PID를 보여 줍니다. 회수는 그 프로세스를 재시작하거나, 로그라면logrotate의copytruncate/postrotate로 프로세스가 파일을 다시 열게 합니다. 급하면: > /proc/<PID>/fd/<번호>로 열린 채로 비울 수 있습니다.
핵심 교훈: 실행 중 서비스의 로그는 rm 하지 말 것. 회전(로테이션)이나 truncate로 비워야 프로세스가 핸들을 놓지 않은 채로도 공간이 돌아옵니다.
상황: 디스크 경보가 떠서 /var/log의 거대한 catalina.out을 rm으로 지웠습니다. 그런데 df -h는 여전히 95%이고, du -sh /*를 합산해도 사용 중이라는 용량과 수십 GB나 차이가 납니다. 재부팅하면 내려가지만 운영 중엔 그럴 수 없습니다.
원인: rm으로 파일 이름은 지웠지만 Tomcat(java) 프로세스가 그 로그 파일을 여전히 열어 쓰고 있습니다. 링크 수는 0이 됐어도 열린 디스크립터가 남아 inode·블록이 해제되지 않습니다. du는 이름이 사라진 파일을 못 세므로 df와 합계가 벌어지는 것입니다.
진단: sudo lsof -nP +L1로 링크 수 0인 열린 파일을 나열합니다 — (deleted) 표시와 함께 크기가 큰 항목, 그리고 그걸 붙잡은 PID(java)가 보입니다. lsof / | grep deleted로도 같은 것을 확인할 수 있고, ls -l /proc/<PID>/fd에서 (deleted) 링크로 어느 디스크립터인지까지 짚을 수 있습니다.
해결: 급한 회수는 해당 디스크립터를 열린 채로 비우는 것입니다 — : > /proc/<PID>/fd/<번호>. 안전하게는 로그를 여는 프로세스(Tomcat)를 재시작하면 즉시 공간이 반환됩니다. 재발 방지로는 catalina.out에 logrotate의 copytruncate(또는 앱의 롤링 로거)를 걸어, 앞으로는 rm이 아니라 회전으로 로그가 관리되게 합니다.
실제 업무에서 이 지식이 쓰이는 상황:
이 모듈의 명령어들은 장애 대응 시 가장 먼저 실행하는 것들입니다.
온콜(On-call) 대응 시 첫 3분:
# 1. 부하 확인
uptime; top -bn1 | head -15
# 2. 문제 서비스 상태
systemctl status tomcat nginx
# 3. 포트 확인 (서비스가 떠있는지)
ss -tlnp | grep ':8080'
# 4. 최근 에러 로그
journalctl -u tomcat --since "5 min ago" --no-pager
# 5. 디스크/메모리
df -h; free -m
이 다섯 단계로 대부분의 원인을 3분 안에 좁힐 수 있습니다. "뭔지 모르겠어요"가 아니라 "CPU 문제입니다" "디스크 꽉 찼습니다" "프로세스가 죽었습니다"로 빠르게 전달할 수 있어야 합니다.
명령어·단축키 빠른 참조
장애 첫 5분 서버 상태 점검(프로세스·포트·리소스·로그)에서 다룬 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
ps aux | 프로세스 스냅샷(CPU/MEM/STAT) | ps aux --sort=-%cpu | head, --sort=-%mem |
pgrep / pidof | 이름으로 PID 추출 | pgrep -f tomcat, pidof nginx |
top | 실시간 부하·%Cpu·load average | top -bn1 | head -15, 키: M(메모리) P(CPU) 1(코어별) |
uptime / nproc | load average를 코어 수와 비교 | uptime && nproc |
ss -tlnp | LISTEN 포트·프로세스 확인 | ss -tlnp | grep ':8080'(DB는 127.0.0.1 바인딩 확인) |
lsof | 포트·FD 점유 프로세스 확인 | lsof -i:8080, lsof -nP +L1(삭제됐지만 열린 파일) |
df -h | 디스크 사용률 | df -h(Use% 85%↑ 주의) |
df -i | inode 소진 확인(공간 남아도 생성 실패) | df -i(IUse% 100%면 소진) |
du -sh | 큰 디렉터리·파일 찾기 | du -sh /var/log/* | sort -rh | head |
free -m | 메모리·스왑 상태 | free -m(available·Swap used), watch -n 2 free -m |
journalctl -u | 서비스 로그 시간·레벨 필터 | journalctl -u tomcat --since '30 min ago' -p err |
journalctl -k / dmesg | 커널·OOM 로그 확인 | journalctl -k --since today | grep -i oom |
kill -9 | 잔존 프로세스 강제 종료 | kill -9 <PID>(포트 충돌 시 마지막 수단) |
: > /proc/<PID>/fd/<n> | 삭제 안 된 열린 로그 즉시 비우기 | : > /proc/5678/fd/3(rm 후 df가 안 빠질 때) |
관련 모듈로 더 깊이:
- Shell 스크립팅과 자동화 — 이 점검 절차를 자동화 스크립트로 묶는 법
- systemd 서비스 등록과 자동 재시작 설정 — 죽은 프로세스를 systemd 서비스로 안정적으로 기동·관리하는 법
- 장애/배포/연계/보안 케이스 실전 종합 — 포트·리소스 진단이 실제 장애 대응 흐름에서 쓰이는 종합 사례
다음 모듈에서는 이런 점검 과정을 자동화하는 Shell 스크립팅을 다룹니다.