서비스 오픈 일주일 전, 운영팀에서 연락이 왔습니다. "지금 WAS가 서버 한 대인데, 이게 죽으면 어떻게 됩니까?" 개발팀은 코드만 짰고, 인프라 담당자는 "로드밸런서 붙이면 됩니다"라고 했지만 — 어떤 로드밸런서를 어떻게 구성해야 하는지, Health Check는 어디로 잡아야 하는지, Active 장비가 죽으면 Standby로 어떻게 넘어가는지 아무도 정확히 모릅니다.
이 모듈에서는 L4/L7 차이를 구분하고, VIP+keepalived 기반 이중화 원리를 이해하며, Nginx upstream으로 Health Check와 분산 알고리즘을 직접 설정하는 과정을 다룹니다.
- 1L4와 L7 로드밸런서의 동작 계층 차이와 사용 기준을 설명할 수 있다
- 2VIP와 keepalived VRRP로 LB 이중화가 동작하는 원리를 이해할 수 있다
- 3Nginx upstream에서 분산 알고리즘과 Health Check를 설정할 수 있다
- 4Active/Standby Failover 동작 순서를 추적하고 검증할 수 있다
- 5HAProxy, Nginx upstream, F5의 상황별 선택 기준을 설명할 수 있다
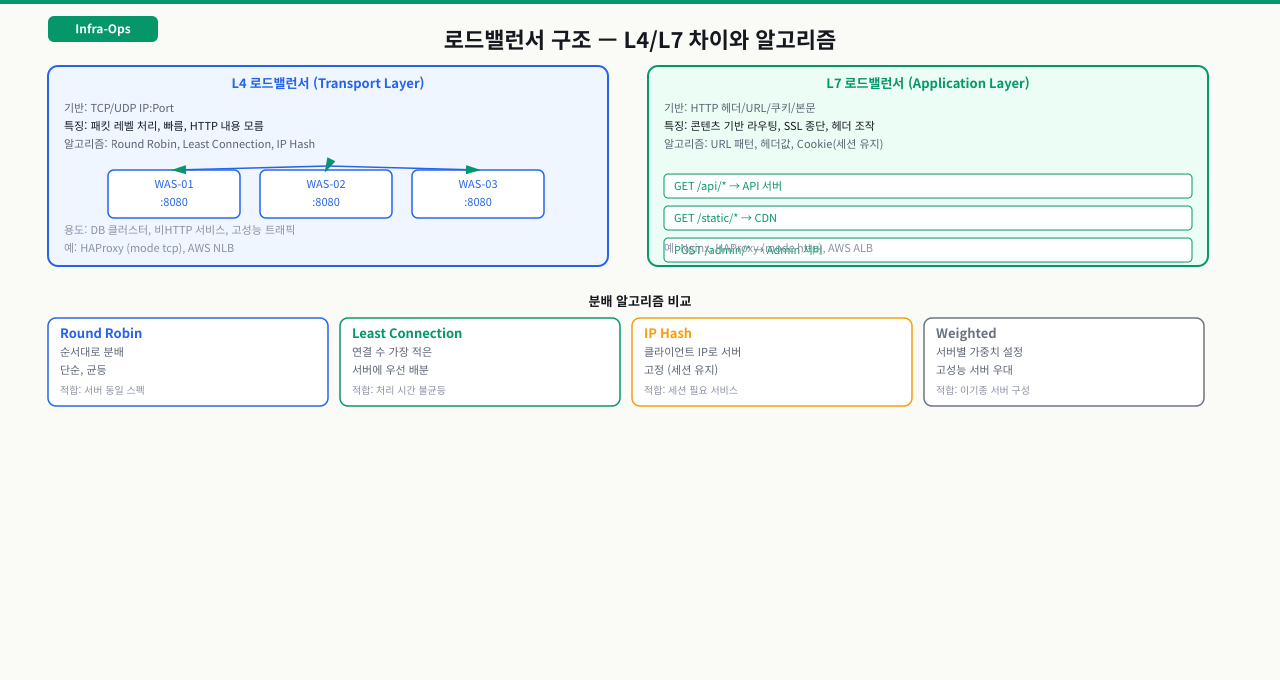
L4 vs L7 — 어느 계층에서 결정하나
L4 LB: IP와 포트만 본다
로드밸런서를 처음 접하면 "그냥 트래픽 나눠주는 거 아닌가?"라고 생각하기 쉽습니다. 하지만 어느 계층에서 결정을 내리느냐에 따라 할 수 있는 것과 없는 것이 완전히 달라집니다. L4 LB는 OSI 4계층(Transport Layer)에서 동작하기 때문에 패킷의 IP 주소와 TCP/UDP 포트 번호만 볼 수 있습니다. HTTP 메서드가 GET인지 POST인지, URL이 /api/인지 /static/인지 알 수 없습니다.
 확대
확대
L4 LB 동작 방식:
클라이언트 → [VIP:443] → L4 LB → 백엔드 서버 A (192.168.10.11:443)
백엔드 서버 B (192.168.10.12:443)
백엔드 서버 C (192.168.10.13:443)
L4 LB는 TCP 연결 수립 단계(SYN 패킷)에서 분산 결정을 내립니다. 연결이 맺어진 후의 HTTP 요청 내용은 보지 않습니다. 덕분에 처리 오버헤드가 낮고 속도가 빠릅니다.
대표적인 사용 사례:
- TCP 기반 서비스 (DB, Redis, SMTP)
- 단순 HTTP 트래픽 분산 (URL 기반 라우팅 불필요)
- 매우 높은 처리량이 필요한 환경
장단점:
| 항목 | 내용 |
|---|---|
| 처리 속도 | 빠름 (패킷 레벨 처리) |
| URL 기반 라우팅 | 불가 |
| SSL Termination | 불가 (패킷을 해석 못함) |
| 구현 예 | AWS NLB, HAProxy (TCP mode), LVS |
L7 LB: HTTP 내용까지 본다
API 요청과 정적 파일 요청을 서로 다른 서버군으로 보내야 합니다. API는 WAS 클러스터로, /static/은 CDN Origin으로, /admin/은 어드민 서버로 분리하고 싶습니다. L4 LB는 URL을 볼 수 없어서 이런 라우팅이 불가능합니다. HTTP 내용을 읽어야만 가능한 이 역할을 L7 LB가 합니다.
L7 LB는 OSI 7계층(Application Layer)에서 동작합니다. HTTP 요청을 완전히 파싱하기 때문에 URL 경로, Host 헤더, 쿠키, HTTP 메서드 등을 기반으로 분산 결정을 내릴 수 있습니다. 실제 운영 환경에서 웹 서비스를 위해 가장 많이 쓰이는 방식입니다.
L7 LB 동작 방식 (콘텐츠 기반 라우팅 예시):
클라이언트 GET /api/users → L7 LB → API 서버 A (192.168.10.11:8080)
클라이언트 GET /static/... → L7 LB → CDN Origin (192.168.10.20:80)
클라이언트 GET /admin/... → L7 LB → Admin 서버 (192.168.10.30:8080)
장단점:
| 항목 | 내용 |
|---|---|
| URL/헤더 기반 라우팅 | 가능 |
| SSL Termination | 가능 (인증서를 LB에서 처리) |
| 헬스체크 정밀도 | HTTP 응답 코드, body까지 확인 가능 |
| 처리 오버헤드 | L4보다 높음 |
| 구현 예 | Nginx upstream, HAProxy (HTTP mode), AWS ALB |
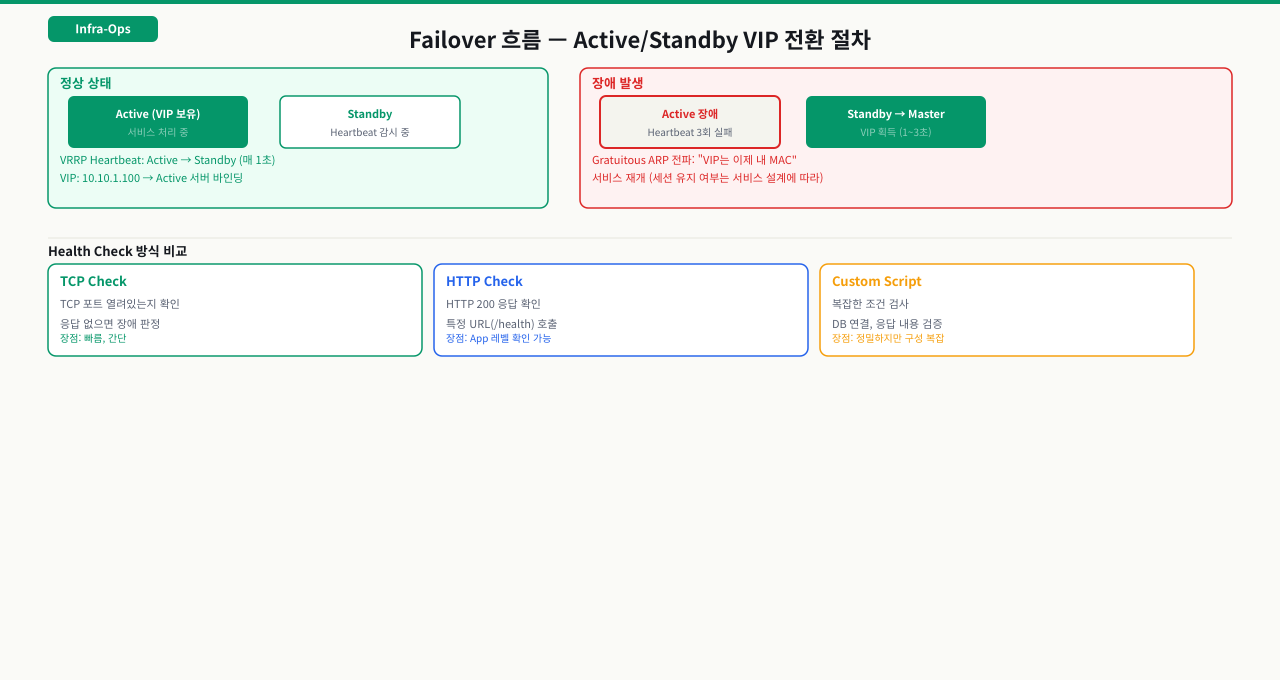
VIP와 keepalived — LB 이중화 원리
VIP와 VRRP — Failover가 동작하는 방식
로드밸런서 자체가 단일 장애점(SPOF)이 되면 안 됩니다. LB 이중화는 Active/Standby 구성으로 해결합니다. 이때 핵심 개념이 VIP(Virtual IP)입니다.
VIP는 Active LB 장비가 보유하는 가상 IP 주소입니다. 클라이언트와 DNS는 항상 이 VIP로 접속합니다. Active LB가 장애로 죽으면 Standby LB가 VIP를 인계받아 서비스를 이어받습니다. 이 과정에서 클라이언트는 IP 변경을 인지하지 못합니다.
VRRP(Virtual Router Redundancy Protocol) 기반 keepalived:
[Active LB] 192.168.1.10 (Real IP) ← VIP 192.168.1.100 보유
↕ VRRP heartbeat (224.0.0.18, UDP)
[Standby LB] 192.168.1.11 (Real IP) ← VIP 없음, 대기 중
Failover 발생 순서:
- Active LB가 응답 없음 (VRRP 패킷 중단)
- Standby가
MASTER_DOWN_INTERVAL내에 감지 - Standby가 VIP를 자신의 NIC에 추가 (
ip addr add 192.168.1.100/24 dev eth0) - Gratuitous ARP 발송 → 스위치/라우터 ARP 캐시 갱신
- 트래픽이 Standby(이제 새 Active)로 유입
keepalived 설정 예시 (Active 장비):
# /etc/keepalived/keepalived.conf (Active)
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51 # Active/Standby 동일해야 함
priority 100 # Standby는 90 등 낮게 설정
advert_int 1 # 1초마다 VRRP 광고
authentication {
auth_type PASS
auth_pass secure1234 # Active/Standby 동일
}
virtual_ipaddress {
192.168.1.100/24 # VIP
}
# LB 프로세스 죽으면 우선순위 낮춰 Failover 유도
track_script {
chk_nginx
}
}
vrrp_script chk_nginx {
script "systemctl is-active nginx"
interval 2
weight -20 # nginx 죽으면 priority를 20 낮춤
}
# /etc/keepalived/keepalived.conf (Standby)
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90 # Active(100)보다 낮게
advert_int 1
# ... (나머지 동일)
}
 확대
확대
트래픽이 VIP로 들어와 실서버까지 갔다 오는 법 — 5단계
앞에서 VRRP가 VIP를 어떻게 지키는지 봤다면, 이번엔 클라이언트 요청 하나가 VIP로 들어와 실제 서버까지 갔다가 돌아오는 전체 경로를 단계로 봅니다. LB 장애를 진단할 때 "어느 단계까지 갔는지"로 원인을 좁히는 지도가 됩니다 — VIP에 아예 안 붙는 문제와, 붙는데 간헐적으로 실패하는 문제는 전혀 다른 단계입니다.
[클라이언트] https://VIP(192.168.1.100):443
│
① VIP 수신 — 현재 Active LB가 VIP 보유 (VRRP Master)
│
② 후보 선별 — 헬스체크 통과(UP) 서버만 풀에 남김, DOWN은 제외
│
③ 실서버 선택 — 분산 알고리즘 적용 (RR · least_conn · ip_hash …)
│
④ 실서버로 전달
│ ├─ NAT 방식: 목적지를 실서버 IP로 바꿔(DNAT) 보냄 → 응답도 LB 경유
│ └─ DSR 방식: LB는 전달만, 실서버가 클라이언트에 직접 응답
│
⑤ 실서버 처리 → 응답 (NAT면 LB 거쳐, DSR이면 직접) → 클라이언트
▼
[클라이언트] 200 OK
(Active LB 장애 시) VRRP로 Standby가 VIP 인수 → GARP 방송 →
클라이언트는 같은 VIP로 계속 접속 (①의 입구는 그대로 유지)
각 단계에서 무슨 일이 일어나고, 어긋나면 어떤 증상인가:
| 단계 | 하는 일 | 여기서 어긋나면 |
|---|---|---|
| ① VIP 수신 | Active LB가 VIP를 들고 클라이언트 접속을 받음 | VIP 미이전(Failover 실패·Split-Brain) → 죽은 LB의 VIP로 감 → 전체 불가 또는 접속 오락가락 |
| ② 헬스체크 선별 | DOWN 판정 서버를 분산 대상에서 제외 | 체크가 얕아(포트만 확인) 좀비 서버를 UP로 오판 → 죽은 서버로 계속 보내 간헐 502 · 너무 민감 → 멀쩡한 서버 빼 남은 서버 과부하 |
| ③ 알고리즘 선택 | RR·least_conn·ip_hash 등으로 실서버 1대 결정 | ip_hash인데 클라이언트가 소수 프록시 뒤에 몰림 → 세션 편중(특정 서버만 과부하) |
| ④ 전달(NAT/DSR) | DNAT로 목적지 변환 또는 DSR로 전달만 | NAT면 응답도 LB 경유 → LB 대역폭 병목 · DSR인데 실서버에 VIP loopback 미설정 → 응답이 안 나감 |
| ⑤ 실서버 응답 | 처리 결과를 (경로에 맞게) 클라이언트로 | 실서버 직접은 200인데 LB 경유만 실패 → ④ 경로·방화벽 문제 |
정리하면 LB 진단은 "어느 단계까지 도달했나"로 좁힙니다. VIP에 아예 못 붙으면 ①(VIP 위치·VRRP 하트비트)이고, 붙는데 간헐 오류면 ②(죽은 서버를 살아있다 오판) 또는 ④(DSR 설정)이며, 특정 서버만 과부하면 ③(알고리즘·세션 편중)입니다. 그리고 ①의 입구(VIP)는 VRRP가 지켜주므로 Active가 죽어도 클라이언트는 같은 주소로 계속 접속합니다 — 단 헬스체크(②)와 VRRP 하트비트가 정확할 때만 그렇습니다(하트비트가 끊기면 Split-Brain, WEB/WAS/DB 망 분리와 이중화 구조 설계의 VRRP 심화 참조).
Health Check 전략
TCP/HTTP/Script — 세 가지 Health Check 방식
Health Check를 제대로 설정하지 않으면, 서버가 실제로 동작 불능이 되어도 LB가 계속 트래픽을 보냅니다. 반대로 너무 민감하게 설정하면 일시적 지연에도 서버를 제외시켜 불필요한 Failover가 생깁니다.
 확대
확대
세 가지 방식 비교:
| 방식 | 확인 내용 | 신뢰도 | 적합 상황 |
|---|---|---|---|
| TCP | 포트 연결 가능 여부 | 낮음 | 포트만 열려있으면 통과 |
| HTTP | 지정 URL의 응답 코드 | 중간 | 앱 레벨 확인 가능 |
| Script | 커스텀 스크립트 실행 결과 | 높음 | DB 연결, 임계치 체크 등 복합 조건 |
Nginx upstream Health Check 설정:
# /etc/nginx/conf.d/upstream.conf
upstream backend_pool {
# 분산 알고리즘 (기본: Round Robin)
# least_conn; # 최소 연결 수 서버로
# ip_hash; # 클라이언트 IP 기반 고정 (Sticky Session)
server 192.168.10.11:8080 weight=1 max_fails=3 fail_timeout=30s;
server 192.168.10.12:8080 weight=1 max_fails=3 fail_timeout=30s;
server 192.168.10.13:8080 weight=2 max_fails=3 fail_timeout=30s;
# weight=2: 다른 서버의 2배 트래픽 수신
keepalive 32; # 백엔드 연결 풀 유지
}
server {
listen 80;
location / {
proxy_pass http://backend_pool;
proxy_connect_timeout 5s;
proxy_send_timeout 30s;
proxy_read_timeout 30s;
# Health Check 실패 서버 재시도
proxy_next_upstream error timeout http_500 http_502 http_503;
proxy_next_upstream_tries 2;
}
# Health Check 엔드포인트 (모니터링용)
location /health {
access_log off;
return 200 "OK\n";
add_header Content-Type text/plain;
}
}
HAProxy Health Check 설정 (더 세밀한 제어):
# /etc/haproxy/haproxy.cfg
backend web_servers
balance roundrobin
option httpchk GET /actuator/health # Spring Boot health endpoint
http-check expect status 200
server web1 192.168.10.11:8080 check inter 5s rise 2 fall 3
server web2 192.168.10.12:8080 check inter 5s rise 2 fall 3
# inter 5s: 5초마다 체크
# rise 2: 2번 성공하면 UP으로 복구
# fall 3: 3번 실패하면 DOWN으로 제외
분산 알고리즘 선택
실습 — 상태 확인
nginx -T는 include된 모든 설정 파일을 합쳐서 출력합니다. upstream 블록을 grep해서 현재 백엔드 풀 구성을 확인합니다. max_fails, fail_timeout, weight 값을 검토합니다.
# Nginx 전체 설정에서 upstream 관련 설정 확인
nginx -T | grep -A 20 upstream
# LB를 통한 헬스 엔드포인트 응답 확인
curl -v http://192.168.1.100/health
# upstream 각 서버 직접 확인 (LB 우회)
curl -v http://192.168.10.11:8080/actuator/health
curl -v http://192.168.10.12:8080/actuator/health
# Nginx 상태 모듈 (stub_status 활성화된 경우)
curl http://localhost/nginx-status
nginx -T | grep -A 20 upstream- nginx -T | grep -A 5 upstream 으로 upstream 블록 반영 확인 먼저, 그 다음 각 백엔드 서버에 직접 curl, 마지막으로 VIP 경유 curl 테스트 — 직접 접속은 되는데 VIP 경유가 안 되면 LB 설정 문제
- 헬스체크 기준: curl http://VIP/health 에서 200이면 LB와 백엔드 모두 정상, 502이면 upstream 서버 전체 장애 또는 LB 설정 오류, 504이면 백엔드 응답 시간 초과 — 503은 upstream 서버 max_fails 초과
- 일부 백엔드에서만 200이 나오는데 VIP 경유 시 간헐적 502가 나오면 → 응답 안 하는 서버로 요청이 라우팅된 것 — error.log에서 "connect() failed" 발생 서버 IP를 확인해 해당 서버 상태 점검
Active LB 장비에서 실행하면 Real IP와 VIP 두 개가 모두 보여야 합니다. Standby 장비에서는 Real IP만 보입니다.
# 현재 이 장비가 VIP를 보유하고 있는지 확인
ip addr show | grep -E 'inet.*eth'
# Active 장비 예시:
# inet 192.168.1.10/24 brd 192.168.1.255 scope global eth0
# inet 192.168.1.100/24 scope global secondary eth0 ← VIP
# keepalived 서비스 상태 및 현재 역할 확인
systemctl status keepalived
# keepalived 로그에서 MASTER/BACKUP 전환 이력 확인
journalctl -u keepalived -n 50 --no-pager | grep -E "MASTER|BACKUP|Entering"
ip addr show | grep -E 'inet.*eth'- Active LB에서 ip addr show | grep secondary 로 VIP 보유 확인 먼저, 그 다음 Standby LB에서 같은 명령 실행해 VIP가 없는지 확인 — 양쪽 모두 VIP가 있으면 Split-Brain 상태이므로 즉시 조치
- VIP 상태 기준: Active에 secondary IP 존재=정상, Standby에도 secondary IP 존재=Split-Brain(두 장비가 동시에 MASTER 상태, 데이터 불일치 위험), 양쪽 모두 없으면 keepalived 장애
- Active에 VIP가 있는데 curl http://VIP 가 실패하면 → 방화벽이 VIP 트래픽을 차단 중 또는 Nginx가 VIP에서 listen 안 하는 것 — ss -tlnp | grep :80 으로 Nginx가 0.0.0.0 또는 VIP에서 리스닝하는지 확인
트러블슈팅
원인: Health Check 경로를 /로 설정했을 때 자주 발생합니다. /는 단순히 웹 서버가 살아있는지만 확인하고, 애플리케이션이 실제로 정상인지(DB 연결, 의존 서비스 연결 등)는 확인하지 않습니다. Nginx나 Tomcat은 떠 있지만 DB 연결 풀이 고갈된 상태에서 LB는 계속 정상으로 판단합니다.
# 현재 Health Check 경로 확인
nginx -T | grep -E "(health|check|upstream)"
grep -r "httpchk\|health" /etc/haproxy/
# 앱이 제공하는 실제 헬스 엔드포인트로 변경
# Spring Boot: /actuator/health (DB, Redis 연결까지 체크)
# 직접 만든 앱: /health/ready (의존성 체크 로직 포함)
# 헬스 엔드포인트 응답 내용 확인
curl -s http://192.168.10.11:8080/actuator/health | python3 -m json.tool
# 정상: {"status":"UP","components":{"db":{"status":"UP"},...}}
# 비정상: {"status":"DOWN","components":{"db":{"status":"DOWN"},...}}
해결: Health Check 경로를 앱의 /actuator/health 또는 커스텀 /health/ready 엔드포인트로 변경하고, 해당 엔드포인트가 DB 연결, 캐시 서버 연결까지 체크하도록 앱 팀과 협의합니다.
원인: Standby LB에 maxconn 설정이 Active보다 낮게 잡혀 있거나, Standby가 오래 대기하다가 갑자기 Active가 되면서 TCP 연결 큐가 쌓립니다. HAProxy의 경우 Standby의 기본 maxconn이 다르게 설정된 경우입니다. Nginx의 경우 worker_processes나 worker_connections가 낮을 수 있습니다.
# HAProxy Standby 서버의 maxconn 확인
grep -E "maxconn|timeout" /etc/haproxy/haproxy.cfg
# HAProxy 런타임 통계 확인 (socat 필요)
echo "show info" | socat stdio /var/run/haproxy/admin.sock | grep -E "MaxConn|CurrConns"
# Nginx worker 설정 확인
nginx -T | grep -E "worker_processes|worker_connections"
# 현재 연결 수 확인
ss -s
netstat -an | grep ESTABLISHED | wc -l
해결: Active와 Standby의 maxconn, worker_connections 설정을 동일하게 맞춥니다. Failover 발생 시 systemctl reload haproxy 또는 nginx -s reload로 연결 큐를 초기화합니다. 장기적으로는 양쪽 LB 설정을 Ansible이나 Chef로 동기화하여 설정 차이가 생기지 않게 관리합니다.
심화 — Failover가 오히려 장애를 만드는 두 가지 모드
심화: VRRP의 실패 모드 — 스플릿브레인과 preemption 플래핑
지금까지 VRRP는 'Active가 죽으면 Backup이 VIP를 인수한다'로 이해했습니다. 그런데 VRRP가 오작동해 오히려 장애를 만드는 두 모드가 있습니다. 둘 다 컨트롤(하트비트) 경로의 문제라, 데이터 경로만 보면 원인을 못 찾습니다.
- 스플릿브레인(둘 다 MASTER): Backup은 'Active가 죽었는지'를 직접 아는 게 아니라 'Active의 VRRP 광고(advertisement)가 들리는지'로 판단합니다. 그래서 Active가 멀쩡해도 둘 사이 하트비트 경로만 끊기면 Backup이 MASTER로 승격해 VIP를 함께 듭니다. 흔한 원인은 방화벽이 VRRP(IP proto 112)·멀티캐스트
224.0.0.18을 차단, 하트비트용 NIC/스위치 포트 단절, 또는 같은 L2에서virtual_router_id가 다른 인스턴스와 충돌하는 것입니다. 같은 L2에 VIP가 둘이 되면 서로 GARP를 뿌려 스위치 ARP 테이블이 두 MAC 사이에서 흔들리고, 접속이 오락가락합니다. - preemption 플래핑: 죽었던 원래 Active가 복구되면 기본 설정(preempt)에서는 우선순위가 높으므로 VIP를 도로 뺏어옵니다 — 한 번의 장애에 전환이 두 번(넘어갈 때, 돌아올 때) 일어나 그때마다 순단이 생깁니다.
track_script가 nginx 상태로 우선순위를 올렸다 내렸다 하면 VIP가 두 장비를 오가며 플래핑할 수도 있습니다.nopreempt나 안정적인 우선순위 설계로 '돌아오는 전환'을 없앱니다.
핵심 설계: VIP failover는 컨트롤 경로(VRRP 하트비트)가 정확해야 신뢰할 수 있습니다. (1) 방화벽에 VRRP(proto 112)·멀티캐스트를 허용하거나 unicast_peer로 하트비트를 명시, (2) L2 세그먼트에서 virtual_router_id를 유일하게, (3) 불필요한 복귀 전환은 nopreempt로 차단, (4) 스플릿브레인 판별은 tcpdump로 양쪽이 서로의 광고를 받는지 확인합니다.
상황: keepalived 이중화 뒤 클라이언트가 간헐적으로 접속 실패·리셋을 겪습니다. ip addr로 보니 양쪽 장비 모두 VIP(secondary)를 보유하고, 두 keepalived 로그가 다 MASTER입니다. 서버는 둘 다 정상입니다.
원인: 스플릿브레인입니다. Backup이 Active의 VRRP 광고를 못 받아 자신도 MASTER로 승격해 VIP를 든 것입니다. Active가 죽은 게 아니라 둘 사이 VRRP 하트비트 경로가 끊긴 것으로, 흔한 원인은 방화벽이 VRRP(IP proto 112)나 멀티캐스트 224.0.0.18을 차단, 하트비트 인터페이스 단선, 또는 같은 L2에 virtual_router_id가 겹친 다른 인스턴스입니다. 같은 VIP가 둘이라 GARP가 충돌해 스위치 ARP가 흔들리고 접속이 오락가락합니다.
진단: 각 장비에서 journalctl -u keepalived로 둘 다 'Entering MASTER STATE'인지 확인합니다. tcpdump -i eth0 vrrp(또는 proto 112)로 상대의 VRRP 광고가 실제로 도착하는지 양방향으로 봅니다 — 안 오면 하트비트 경로 차단이 확정입니다. 이어 iptables -L·보안그룹에서 proto 112·224.0.0.18 허용 여부와 virtual_router_id 중복 여부를 점검합니다.
해결: 방화벽에 VRRP(proto 112)와 멀티캐스트를 허용하거나 keepalived를 unicast_peer로 바꿔 하트비트를 명시합니다. virtual_router_id가 겹쳤으면 유일한 값으로 바꿉니다. 회복 후 불필요한 재전환을 막으려면 nopreempt를 검토합니다. 데이터 경로가 아니라 컨트롤(하트비트) 경로를 고쳐야 하는 케이스임을 기억합니다(네트워크 방화벽 정책과 요청서 작성 실무에서 VRRP·멀티캐스트 허용 규칙을 함께 설계).
실제 업무에서 이 지식이 쓰이는 상황:
인프라 담당자가 LB를 처음 구성할 때 가장 많이 받는 질문 두 가지가 있습니다. "Health Check 경로 어떻게 설정하나요?"와 "Active 장비가 죽으면 어떻게 됩니까?"입니다.
1. 신규 서비스 LB 구성 체크리스트:
# 1. upstream 서버 목록과 분산 알고리즘 결정
# 2. Health Check 경로 앱 팀과 협의 (/actuator/health 권장)
# 3. max_fails, fail_timeout 설정 (3회 실패, 30초 제외)
# 4. VIP 설정 및 keepalived 구성
# 5. Failover 테스트: Active keepalived 중지 후 VIP 이동 확인
systemctl stop keepalived # Active에서 실행
ip addr show # Standby에서 VIP 인계 확인
2. 장애 발생 시 LB 점검 순서:
# LB 상태 확인
systemctl status nginx haproxy keepalived
# VIP 보유 장비 확인
ip addr show | grep 'VIP주소'
# 백엔드 서버 상태 확인 (HAProxy 통계 페이지)
curl http://localhost:8404/stats # HAProxy stats 페이지 (설정 필요)
# Nginx upstream 에러 확인
grep "upstream" /var/log/nginx/error.log | tail -20
3. HAProxy vs Nginx upstream vs F5 선택 기준:
| 제품 | 적합한 상황 |
|---|---|
| Nginx upstream | 이미 Nginx 사용 중인 환경, 간단한 L7 분산 |
| HAProxy | 세밀한 Health Check, TCP/HTTP 혼용, 통계 대시보드 필요 |
| F5 BIG-IP | 금융/공공기관, 하드웨어 어플라이언스 필요, 벤더 지원 계약 필요 |
| AWS ALB/NLB | 클라우드 네이티브 환경, 관리 부담 최소화 |
LB 이중화와 Health Check를 올바르게 구성하는 것만으로도 서비스 가용성을 99.9% 이상으로 끌어올릴 수 있습니다.
명령어·단축키 빠른 참조
이 모듈에서 다룬 로드밸런서·VIP·헬스체크 운영 명령을 모았습니다. Failover 문제는 데이터 경로가 아니라 VRRP 하트비트(컨트롤 경로)부터 봅니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
nginx -T | grep -A20 upstream | upstream 풀·알고리즘 확인 | max_fails·weight·fail_timeout 검토 |
nginx -t && systemctl reload nginx | 문법검사 후 무중단 반영 | Failover 시 연결 큐 초기화 |
curl -v http://<VIP>/health | LB 경유 헬스 확인 | 502=백엔드 전체 장애, 504=응답 초과 |
curl http://<백엔드>:8080/actuator/health | 백엔드 직접 확인(LB 우회) | UP/DOWN JSON 확인 |
ip addr show | VIP 보유 여부 확인 | ip addr show | grep secondary (VIP=secondary) |
systemctl status keepalived | keepalived 역할·상태 | MASTER/BACKUP 확인 |
journalctl -u keepalived | MASTER/BACKUP 전환 이력 | journalctl -u keepalived | grep -E "MASTER|BACKUP" |
tcpdump -i eth0 vrrp | VRRP 광고 수신 확인 | 스플릿브레인(proto 112 차단) 진단 |
ss -tlnp | grep :80 | Nginx 리스닝 주소 확인 | 0.0.0.0 또는 VIP에서 listen하는지 |
ss -s | 현재 연결 수 집계 | netstat -an | grep ESTABLISHED | wc -l 로도 |
curl http://localhost:8404/stats | HAProxy 통계 페이지 | 백엔드 UP/DOWN 상태(설정 필요) |
grep upstream error.log | Nginx upstream 에러 | grep upstream /var/log/nginx/error.log | tail |
관련 모듈로 더 깊이:
- Nginx 리버스 프록시와 로드밸런싱 설정 — L7 분산을 Nginx upstream으로 직접 구성하는 실무
- HTTP 요청이 서버에 도달하기까지의 전체 흐름 — LB가 전체 요청 흐름 중 어느 위치에서 어떻게 동작하는지
- 네트워크 방화벽 정책과 요청서 작성 실무 — VIP로 들어오는 트래픽에 맞춘 방화벽 정책 설계
다음 모듈에서는 폐쇄망 환경에서 내부 서버가 외부 기관과 통신하는 Proxy/NAT 구조를 다룹니다.