새벽 3시, 모니터링 알람이 울립니다. 서비스 에러율이 급증했습니다. SSH로 접속해서 무슨 일인지 파악해야 합니다. 개발자는 자고 있습니다. 지금 당장 로그만 보고 원인을 파악해야 합니다.
502인가, 504인가, 500인가. Nginx 문제인가, Tomcat 문제인가, DB 문제인가. 로그를 어디서, 어떻게 찾아야 하는가.
로그를 읽는 능력은 인프라 엔지니어의 가장 기본적인 생존 기술입니다. 이 모듈은 HTTP 에러 코드가 어디서 발생하는지를 인프라 관점에서 해석하고, 실제 로그 파일에서 원인을 추적하는 방법을 다룹니다.
- 1400~504 HTTP 에러 코드를 인프라 관점에서 해석하고 발생 위치를 특정할 수 있다
- 2Nginx access_log에서 awk로 에러 패턴을 추출하고 분석할 수 있다
- 3Tomcat catalina.out에서 Exception, OOM, Connection Pool 소진을 찾을 수 있다
- 4502/504/500/413/403 각각의 원인을 로그로 구분할 수 있다
- 5특정 API에서만 발생하는 간헐적 에러의 패턴을 시간대별로 분석할 수 있다
HTTP 에러 코드 — 인프라 관점 해석
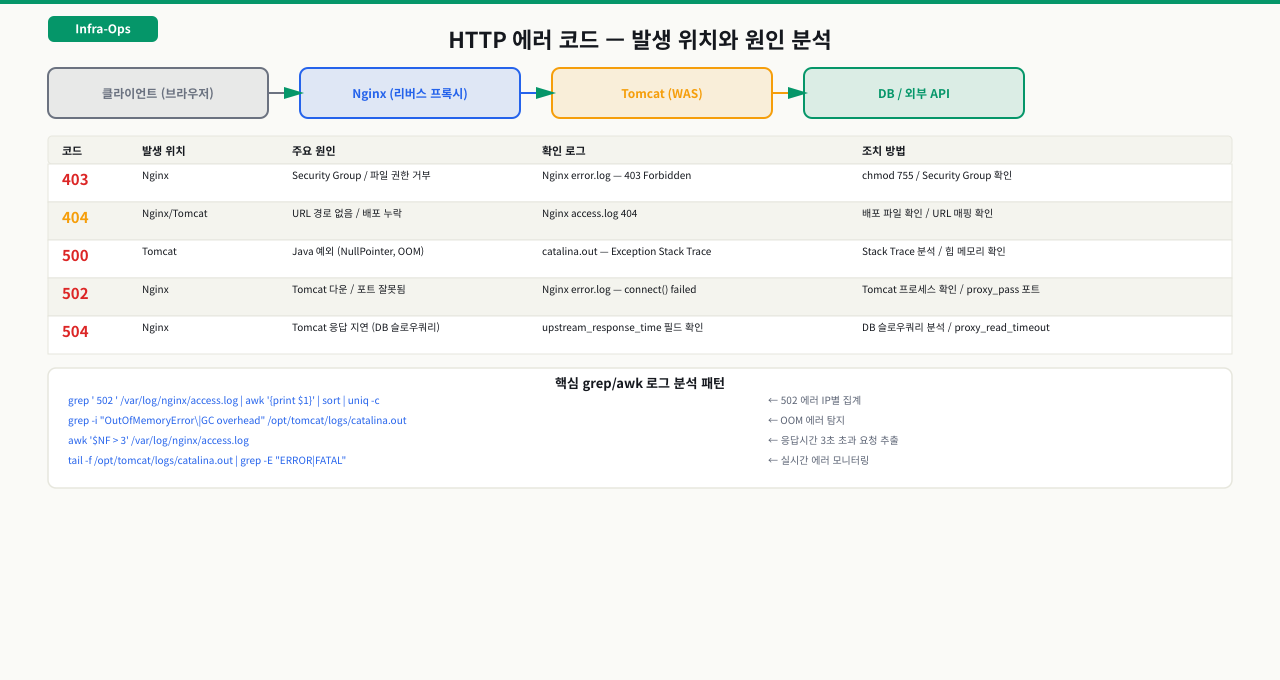
에러 코드가 어디서 생성되는가
브라우저에 502가 뜰 때 "Tomcat이 살아있는데 왜 502지?"라는 질문이 나온다면, 에러 코드가 어느 계층에서 만들어지는지 모르는 것입니다. 502는 Nginx가 Tomcat에 연결을 시도했지만 실패했다는 신호이고, 504는 연결은 됐지만 응답이 너무 늦었다는 신호입니다. 코드마다 발생하는 계층이 다르고, 계층이 다르면 열어봐야 할 로그 파일도 달라집니다. 이 매핑을 알아야 장애 대응 첫 3분을 낭비하지 않을 수 있습니다.
 확대
확대
사용자가 "사이트가 안 된다"고 신고했습니다. 브라우저는 502를 표시합니다. 그런데 Tomcat 프로세스는 멀쩡히 올라와 있습니다. "Tomcat이 살아있는데 왜 502지?"라는 질문에 답하려면 에러 코드가 어느 계층에서 만들어지는지 알아야 합니다. 502는 Tomcat 자체의 문제가 아니라 Nginx가 Tomcat에 연결을 시도했지만 실패했다는 신호입니다. 계층을 알면 어느 로그를 봐야 하는지 즉시 결정됩니다.
에러 코드를 인프라 관점에서 해석하려면 "이 에러가 어느 계층에서 만들어지는가"를 알아야 합니다. 클라이언트 문제인지, Nginx 문제인지, Tomcat 문제인지, DB 문제인지에 따라 확인해야 하는 로그가 다릅니다.
에러 코드별 발생 위치와 원인:
| 코드 | 이름 | 발생 위치 | 일반적 원인 |
|---|---|---|---|
| 400 | Bad Request | Nginx/Tomcat | 잘못된 요청 형식, URL 인코딩 문제 |
| 401 | Unauthorized | Tomcat/앱 | JWT 만료, 인증 토큰 없음 |
| 403 | Forbidden | Nginx/Tomcat | 파일 권한, 디렉터리 접근 거부 |
| 404 | Not Found | Nginx/Tomcat | 파일/경로 없음, 잘못된 URL |
| 413 | Request Entity Too Large | Nginx | client_max_body_size 초과 |
| 500 | Internal Server Error | Tomcat/앱 | 애플리케이션 예외, DB 오류 |
| 502 | Bad Gateway | Nginx | upstream 연결 실패, 포트 불일치 |
| 503 | Service Unavailable | Nginx/Tomcat | 과부하, 서비스 다운 |
| 504 | Gateway Timeout | Nginx | upstream 응답 시간 초과 |
502와 503의 차이: 502는 "연결했는데 쓰레기 응답이 왔거나 아예 연결 실패", 503은 "서버가 요청을 받았지만 처리 불가(과부하, 유지보수 모드)"입니다. Nginx에서 upstream이 다운됐을 때는 보통 502가 납니다.
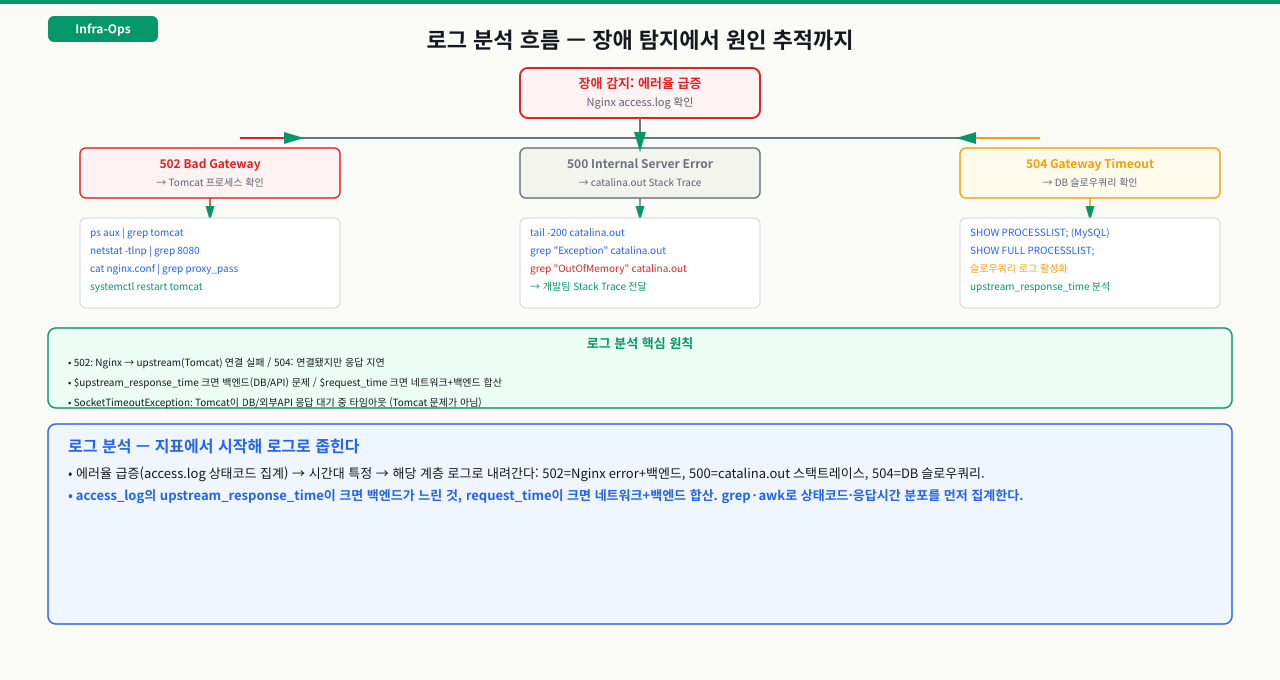
로그로 추적하는 순서
로그로 장애를 추적하는 순서 — 신고 접수부터 원인 확정까지 5단계
에러 코드가 어느 계층에서 나는지를 알았으면, 다음은 "그래서 어떤 순서로 로그를 뒤지는가"입니다. 뒤에 나오는 10가지 케이스는 이 절차의 ③(검색) 단계에 해당하는 낱개 기술이고, 실제 장애 대응은 증상 시각을 잡는 데서 시작합니다. 증상 시각 특정 → 그 시간대로 필터 → 에러·패턴 검색 → 요청 추적 → 원인 확정의 다섯 단계를 순서대로 밟아야, 케이스별 명령이 엉뚱한 로그를 뒤지지 않습니다.
[알람·사용자 신고] "3시경 에러 페이지가 났다"
│
① 증상 시각 특정 언제부터·어느 범위인지 시각과 창(window)을 확정
│
② 시간대 로그 필터 그 창으로 access.log · catalina.out 을 좁힘 (타임존 먼저 맞춤)
│
③ 에러·패턴 검색 상태코드·예외·키워드로 grep · awk · 쿼리
│
④ 요청 추적 correlation ID 로 Nginx → WAS → DB 한 요청의 전 구간 연결
│
⑤ 원인 확정 계층·코드 라인·외부 의존성으로 근본 원인 확정
▼
[결론] "어느 계층의 무엇이 원인" — 가설이 아니라 로그로 확정
각 단계에서 하는 일과, 막히면 나타나는 증상:
| 단계 | 하는 일 | 막히면 증상 |
|---|---|---|
| ① 증상 시각 특정 | 알람·신고에서 언제부터·어느 범위인지 시각을 확정한다 | 신고 시각이 부정확하거나 알람 지연을 감안 안 하면 엉뚱한 창을 뒤짐 |
| ② 시간대 로그 필터 | 확정한 창으로 access.log·catalina.out을 좁힌다 | Nginx(KST)와 컨테이너 WAS(UTC) 타임존이 어긋나면 '같은 시각'이 실제로는 9시간 차라 엉뚱한 구간을 뒤짐(아래 심화) |
| ③ 에러·패턴 검색 | 상태코드·예외·키워드로 grep·awk·쿼리한다 | 로그 레벨이 INFO면 스택·디버그가 없어 검색해도 안 나옴; grep -c는 멀티라인을 줄 단위로 세 건수를 부풀림(아래 심화) |
| ④ 요청 추적 | correlation ID(요청 ID)로 Nginx → WAS → DB 한 요청의 전 구간을 잇는다 | ID 가 없으면 계층 간 로그를 시각으로만 이어야 해 상관관계가 끊김(동시 요청이 많으면 오매칭) |
| ⑤ 원인 확정 | 계층·코드 라인·외부 의존성으로 근본 원인을 확정한다 | 표면 예외만 보면 오진 — Caused by 맨 아래·upstream 필드로 실제 계층을 갈라야 함 |
즉 추적이 막히면 어느 단계에서 막혔는지를 되짚습니다 — 로그가 아예 없으면 ①(시각 오류)나 ③(로그 레벨), 계층이 안 갈리면 ④(ID 부재), 시각 대조가 어긋나면 ②(타임존)입니다. 이 절차를 순서대로 밟은 뒤에야 뒤의 케이스별 명령이 제 로그를 겨냥합니다.
실제 에러 케이스 10가지
 확대
확대
케이스 1~5: Nginx 계층 에러
장애 대응 중에 에러 로그를 보면 비슷해 보이는 메시지들이 뒤섞여 있습니다. 502는 upstream 연결 실패, 504는 응답 시간 초과, 413은 파일 크기 초과인데 증상이 엇비슷해서 원인을 혼동하기 쉽습니다. 케이스별로 어떤 로그가 나오고 어떤 명령으로 확인하는지 패턴을 익히면, 실제 장애에서 첫 번째 명령 선택이 빨라집니다.
케이스 1: 502 — Tomcat 다운
Nginx 에러 로그에 connect() failed (111: Connection refused) 가 보입니다.
# Nginx 에러 로그 확인
sudo tail -20 /var/log/nginx/error.log
# 출력 예시:
# [error] upstream connect() failed (111: Connection refused)
# while connecting to upstream, server: localhost:8080
# Tomcat 상태 확인
sudo systemctl status tomcat
# → 다운 상태라면 기동
sudo systemctl start tomcat
케이스 2: 502 — proxy_pass 포트 불일치
Tomcat은 떠있는데 502가 납니다.
# Tomcat이 실제로 듣는 포트 확인
sudo ss -tlnp | grep java
# 출력: LISTEN 0 128 :::8080 :::* users:(("java", pid=12345, fd=56))
# Nginx proxy_pass 설정 확인
grep proxy_pass /etc/nginx/conf.d/myapp.conf
# 출력: proxy_pass http://localhost:8090; ← 포트 불일치!
# 수정 후 reload
sudo vim /etc/nginx/conf.d/myapp.conf
sudo nginx -t && sudo systemctl reload nginx
케이스 3: 504 — DB 쿼리 느림, Tomcat 응답 지연
Nginx access_log에서 응답시간이 긴 요청을 찾습니다.
# log_format에 $upstream_response_time이 포함된 경우
# 응답시간 느린 요청 TOP 10
awk '{print $NF, $7}' /var/log/nginx/access.log | sort -rn | head -10
# 특정 API 경로에서만 느린지 확인
awk '$7 ~ /\/api\/orders/ {print $NF, $7}' /var/log/nginx/access.log \
| sort -rn | head -10
케이스 4: 413 — 파일 업로드 크기 제한
에러 로그에 client intended to send too large body 가 보입니다.
# 현재 설정 확인
grep client_max_body_size /etc/nginx/conf.d/myapp.conf
# 없으면 기본값 1m
# 설정 추가 (server 블록 또는 location 블록에)
# client_max_body_size 50m;
sudo vim /etc/nginx/conf.d/myapp.conf
sudo nginx -t && sudo systemctl reload nginx
케이스 5: 403 — 디렉터리 권한 문제
# Nginx 에러 로그
sudo tail -20 /var/log/nginx/error.log
# 출력: [error] open() "/var/www/myapp/uploads/file.pdf" failed
# (13: Permission denied)
# 파일 소유자 확인
ls -la /var/www/myapp/uploads/
# Nginx 유저 확인
grep '^user' /etc/nginx/nginx.conf
# 권한 수정
sudo chown -R nginx:nginx /var/www/myapp/uploads
sudo chmod 755 /var/www/myapp/uploads
케이스 6~10: Tomcat/애플리케이션 계층 에러
Nginx 로그에는 아무 이상이 없는데 Tomcat에서 500이 나옵니다. 이 경우 원인은 Java 코드 내부에 있고, 단서는 catalina.out의 스택 트레이스에 있습니다. NullPointerException, OutOfMemoryError, DB 커넥션 타임아웃은 증상이 달라 보여도 모두 Tomcat 계층에서 시작됩니다. 각 케이스별 로그 패턴과 첫 번째 확인 명령을 파악해두면 원인까지 도달하는 시간을 줄일 수 있습니다.
케이스 6: 500 — NullPointerException
catalina.out에서 스택 트레이스를 찾습니다.
# 최근 Exception 찾기
grep -A 10 "java.lang.NullPointerException" /opt/tomcat/logs/catalina.out \
| tail -30
# 출력 예시:
# java.lang.NullPointerException
# at com.myapp.service.OrderService.processOrder(OrderService.java:45)
# at com.myapp.controller.OrderController.createOrder(OrderController.java:23)
# 어떤 요청이 해당 코드를 호출했는지 Nginx 로그에서 확인
grep "/api/orders" /var/log/nginx/access.log | grep " 500 " | tail -10
케이스 7: 500 — DB Connection Pool 소진
# catalina.out에서 커넥션 풀 에러 찾기
grep -i "connection pool\|pool exhausted\|cannot get a connection" \
/opt/tomcat/logs/catalina.out | tail -10
# 출력 예시 (HikariCP):
# HikariPool-1 - Connection is not available, request timed out after 30000ms
# 또는 (DBCP):
# Cannot get a connection, pool error Timeout waiting for idle object
# 시간대별 분포 확인 (간헐적인지, 특정 시간에 집중되는지)
grep "pool error\|pool exhausted" /opt/tomcat/logs/catalina.out \
| awk '{print substr($0,1,20)}' | sort | uniq -c | sort -rn
케이스 8: OOM — Heap 부족
# OOM 발생 여부 확인
grep -i "OutOfMemoryError\|GC overhead limit exceeded" \
/opt/tomcat/logs/catalina.out
# OOM이 있다면 발생 시각 확인
grep -n "OutOfMemoryError" /opt/tomcat/logs/catalina.out | head -5
# GC 로그가 설정된 경우 확인
ls /opt/tomcat/logs/gc*.log 2>/dev/null
# GC 로그 마지막 부분
tail -50 /opt/tomcat/logs/gc.log
OOM 발생 시 Tomcat을 재시작해도 근본 원인이 해결되지 않으면 반복됩니다. Heap 크기 설정(-Xmx)을 늘리거나 메모리 누수를 찾아야 합니다.
케이스 9: Connection Refused — 서비스 미기동
# 어느 포트에서 Connection Refused가 나는지 확인
sudo ss -tlnp | grep 8080
# → 아무것도 안 나오면 Tomcat이 해당 포트에서 안 듣고 있음
# Tomcat 상태 확인
sudo systemctl status tomcat
# → inactive (dead) 상태라면 기동
sudo systemctl start tomcat
케이스 10: SSL Handshake Failed — 인증서 만료
# 인증서 만료일 확인
sudo openssl x509 -noout -enddate -in /etc/nginx/ssl/server.crt
# 출력: notAfter=May 30 00:00:00 2026 GMT
# 오늘 날짜 이전이면 만료
# Nginx 에러 로그에서 SSL 에러 확인
grep -i "ssl\|certificate\|handshake" /var/log/nginx/error.log | tail -10
# Let's Encrypt 사용 시 갱신
sudo certbot renew --dry-run # 테스트
sudo certbot renew # 실제 갱신
sudo systemctl reload nginx
Nginx 로그 분석
awk로 로그 패턴 추출하기
장애 대응 중에 "최근 1시간 동안 500이 몇 건이나 났는지"를 알아야 합니다. 로그 파일은 수십만 줄이고, grep 만으로는 특정 시간대, 특정 상태코드, 특정 IP를 동시에 걸러내기 어렵습니다. awk는 로그 필드를 열 단위로 분리해 원하는 조합을 정확하게 추출합니다. 한 번 패턴을 익혀두면 그 어떤 로그 분석 요구에도 빠르게 대응할 수 있습니다.
Nginx access_log는 구조화된 텍스트입니다. 필드 위치를 알면 awk로 원하는 정보를 정확하게 추출할 수 있습니다.
# access_log 기본 형식 (log_format main):
# $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent
# 필드: $1 $2 $3 $4 $5~$7 $8 $9
# 500 에러 요청 추출
awk '$9 == "500"' /var/log/nginx/access.log | tail -20
# 에러 코드별 집계
awk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn
# 출력 예시:
# 12453 200
# 234 304
# 89 404
# 12 500
# 3 502
# 응답시간 느린 요청 TOP 10 (log_format에 $upstream_response_time 포함 시)
awk '{print $NF, $7}' /var/log/nginx/access.log | sort -rn | head -10
# 특정 시간대 로그 필터링
awk '$4 > "[30/May/2026:14:00" && $4 < "[30/May/2026:15:00"' \
/var/log/nginx/access.log | head -20
# 특정 URI 패턴의 에러만 추출
awk '$7 ~ /\/api\/payment/ && $9 >= "500"' /var/log/nginx/access.log | tail -10
# IP별 요청 수 TOP 10 (DDoS 탐지, 특정 클라이언트 분석)
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -rn | head -10
# 분당 요청 수 추이 (트래픽 급증 탐지)
awk '{print substr($4, 2, 17)}' /var/log/nginx/access.log \
| sort | uniq -c
Tomcat 로그 분석
catalina.out에서 원인 찾기
개발팀이 "스택 트레이스가 없다"고 합니다. 로그 레벨을 INFO로 설정해두어서 예외 상세가 찍히지 않은 경우입니다. 반대로 DEBUG 레벨을 운영 서버에 켜두면 수기가 안에 GB 단위 로그가 쌓여 디스크가 꽉 찹니다. catalina.out에서 필요한 예외만 빠르게 찾고, 분량이 많은 로그를 다루는 방법을 미리 익혀두어야 실제 장애에서 시간을 낭비하지 않습니다.
Tomcat의 주요 로그는 catalina.out입니다. 모든 Java 예외, 기동/종료 메시지, 애플리케이션 로그가 여기 모입니다.
# Exception이 있는 라인과 이후 5줄 함께 출력
grep -A 5 "Exception" /opt/tomcat/logs/catalina.out | tail -50
# 특정 에러 패턴 찾기
grep -i "error\|exception\|failed" /opt/tomcat/logs/catalina.out \
| grep -v "^#" | tail -30
# OOM 및 GC 문제 확인
grep -i "OutOfMemoryError\|GC overhead\|heap space" \
/opt/tomcat/logs/catalina.out
# DB 커넥션 관련 에러
grep -i "connection\|pool\|datasource\|jdbc" \
/opt/tomcat/logs/catalina.out | grep -i "error\|fail\|timeout" | tail -10
# 기동 시간 확인 (배포 후 얼마나 걸려 떴는지)
grep "Server startup in" /opt/tomcat/logs/catalina.out | tail -3
# 특정 시간대 로그 (시간 범위가 짧으면 grep으로 충분)
grep "30-May-2026 14:" /opt/tomcat/logs/catalina.out | head -20
Tomcat 로그 파일 위치 정리:
| 파일 | 내용 |
|---|---|
logs/catalina.out | 모든 stdout, stderr (가장 중요) |
logs/catalina.{date}.log | Tomcat 엔진 로그 (날짜별 분리) |
logs/localhost.{date}.log | 웹앱별 에러 (deployment 에러 포함) |
logs/access_log.{date}.txt | Tomcat 자체 액세스 로그 |
실습
400 이상 에러 코드와 URI를 함께 집계합니다. 어떤 경로에서 어떤 에러가 많이 나는지 한눈에 파악할 수 있습니다.
# 에러 코드별 URI 집계
awk '$9 >= 400 {print $9, $7}' /var/log/nginx/access.log \
| sort | uniq -c | sort -rn | head -20
# 출력 예시:
# 89 404 /favicon.ico
# 12 500 /api/orders
# 5 502 /api/payment
# 3 403 /admin/
# 500 에러만 시간대별 분포 확인
awk '$9 == "500" {print substr($4,14,5)}' /var/log/nginx/access.log \
| sort | uniq -c | sort -rn | head -10
# → 특정 시간대에 집중되면 그 시간에 무슨 일이 있었는지 확인
awk '$9 >= 400 {print $9, $7}' /var/log/nginx/access.log | sort | uniq -c | sort -rn | head -20- awk로 에러 코드별 집계 먼저 실행, 그 다음 500 에러가 집중된 URI 패턴 확인, 마지막으로 시간대 분포 확인 — URI 집중이면 특정 기능 문제, 시간대 집중이면 배포/트래픽 패턴 연계
- 에러 코드 기준: 5xx 비율이 전체 요청의 1% 이상이면 서비스 영향 있는 장애, 0.1% 미만이면 일시적 이상 — 500이 특정 URI에 집중되면 해당 API의 Tomcat 로그 추적 필요
- 500 에러가 특정 시간대에만 집중되고 평소에는 없으면 → 해당 시간대 배포 또는 외부 의존성(DB, 외부 API) 변화 확인 — git log 또는 배포 이력과 에러 발생 시각 대조
전체 Exception 발생 횟수를 먼저 파악하고, 가장 최근 발생한 것을 상세하게 봅니다.
# Exception 발생 총 횟수
grep -c "Exception" /opt/tomcat/logs/catalina.out
# 최근 Exception 5개 (각 10줄씩)
grep -n "Exception" /opt/tomcat/logs/catalina.out \
| tail -5 | awk -F: '{print $1}' | while read line; do
sed -n "${line},$((line+10))p" /opt/tomcat/logs/catalina.out
echo "---"
done
# Exception 종류별 집계
grep "Exception" /opt/tomcat/logs/catalina.out \
| grep -oP '\w+Exception' | sort | uniq -c | sort -rn | head -10
# 출력 예시:
# 45 NullPointerException
# 12 SocketTimeoutException
# 5 SQLException
# 2 OutOfMemoryError
grep -c 'Exception' /opt/tomcat/logs/catalina.out- grep -c "Exception" 으로 총 횟수 먼저 파악, 그 다음 Exception 종류별 집계로 가장 빈번한 것 확인, 마지막으로 해당 Exception의 스택 트레이스에서 발생 클래스:줄번호 확인 — 총 횟수만 보면 원인 불명
- Exception 유형 기준: NullPointerException이 다수=코드 로직 오류(데이터 null 처리 미흡), SocketTimeoutException이 다수=외부 API 또는 DB 응답 지연, SQLException이 다수=쿼리 오류 또는 DB 연결 문제, OutOfMemoryError=메모리 누수 또는 힙 설정 부족
- Exception 발생 시각과 Nginx access.log의 500 에러 시각이 일치하는데 스택 트레이스에 at com.ourapp 클래스가 없으면 → 프레임워크/라이브러리 수준 오류 — 스택에서 at com.ourapp이 나오는 첫 번째 줄이 실제 원인 코드
트러블슈팅
상황: Nginx 로그에서 /api/report 경로의 응답시간이 30초 이상으로 찍히고 있습니다. 다른 API는 정상입니다.
# 문제 API 경로 응답시간 확인
awk '$7 ~ /\/api\/report/ {print $NF, $4, $7}' /var/log/nginx/access.log \
| sort -rn | head -20
# Tomcat 로그에서 해당 요청 처리 로그 확인
grep -i "report\|slow\|timeout" /opt/tomcat/logs/catalina.out | tail -20
# DB slow query 로그 확인 (MySQL 기준)
sudo tail -50 /var/log/mysql/slow.log
# 또는
grep -i "slow\|Query_time" /var/log/mysql/slow.log | tail -20
# 해당 쿼리 실행계획 확인 (DB 접속 후)
# EXPLAIN SELECT * FROM reports WHERE created_at > DATE_SUB(NOW(), INTERVAL 30 DAY);
원인이 DB slow query라면 인덱스 추가나 쿼리 최적화가 필요합니다. 임시 조치로 proxy_read_timeout을 늘리는 방법도 있지만, 근본 원인은 애플리케이션/DB 레벨에서 해결해야 합니다.
상황: 매일 오전 9시~10시 사이에 간헐적으로 500 에러가 납니다. catalina.out에 HikariPool - Connection is not available이 보입니다.
# 에러 발생 시간대 분포 확인
grep "Connection is not available\|pool error\|Timeout waiting" \
/opt/tomcat/logs/catalina.out \
| awk '{print substr($0,1,20)}' | sort | uniq -c | sort -rn | head -20
# → 오전 9시~10시 집중 확인
# 동시 요청 수 추이 (Nginx 로그 기준)
awk '{print substr($4,14,5)}' /var/log/nginx/access.log \
| sort | uniq -c | sort -rn | head -20
# → 같은 시간대에 요청 수도 급증하는지 확인
# 현재 DB 커넥션 수 확인 (MySQL)
# SHOW STATUS LIKE 'Threads_connected';
# SHOW PROCESSLIST;
오전 업무 시작 시간에 트래픽이 집중되어 커넥션이 고갈되는 패턴입니다. 해결책은 커넥션 풀 크기를 늘리거나(context.xml의 maxActive), 쿼리가 커넥션을 오래 점유하는 원인을 찾아 최적화하는 것입니다.
심화 — 로그를 세고 대조할 때 조용히 무너지는 두 가지
심화: grep -c로 예외를 세면 왜 틀리나 — 멀티라인 스택트레이스의 함정
장애 대응 첫 3분에 grep -c "Exception"으로 예외 건수를 셌다면, 그 숫자는 십중팔구 실제 장애 건수가 아닙니다. 스택 트레이스는 본질적으로 여러 줄짜리 하나의 이벤트인데 grep은 줄 단위로만 세기 때문입니다. "예외가 있나 없나"의 신호로는 훌륭하지만 "몇 건인가"의 지표로는 신뢰하면 안 됩니다.
- 한 번의 실패가 여러 줄의 예외를 만든다: 자바 예외는
Caused by:로 원인 예외를 감싸 중첩합니다. 한 요청이 한 번 실패해도 로그에는...Exception이 2~4번 찍혀,grep -c가 장애 1건을 여러 건으로 부풀립니다. 반대로at ...프레임 줄은 예외 이름을 포함하지 않아 세는 데서 빠집니다. - 진짜 원인은 맨 아래
Caused by에 있다: 표면 예외(예: 트랜잭션 롤백 래퍼)만 보면 엉뚱한 곳을 고칩니다. 스택은 바깥에서 안으로 감싸므로,grep "Caused by"로 체인을 뽑고 그중 가장 마지막 것을 봐야 근본 원인 클래스에 닿습니다. - 로테이션이 트레이스를 반토막 낸다:
catalina.out이 자정·크기 기준으로 회전하면 하나의 스택 트레이스가 두 파일에 걸쳐 잘립니다. 첫 줄만 이전 파일에 남고 나머지가 다음 파일로 넘어가면, 한 파일만grep하면 예외를 통째로 놓칩니다. - 정확히 세려면 이벤트 경계를 잡는다: 타임스탬프로 시작하는 로그 헤더 줄만 세거나(들여쓰기 없는 최상단 예외 줄만 매칭), 로그를 수집 단계에서 멀티라인으로 묶어 한 이벤트=한 문서로 만들어야 "장애 건수"에 가까워집니다(Filebeat/rsyslog 기반 로그 수집 파이프라인 구성의 multiline 병합).
상황: 사용자 신고 시각 21:05에 맞춰 Nginx access.log에서 /api/orders의 500을 확인했습니다. 같은 21:05로 catalina.out을 뒤졌지만 그 시각엔 평범한 INFO 로그뿐이었습니다. 30분을 헤매다 우연히 12:05 근처에서 문제의 스택 트레이스를 발견했습니다.
원인: Nginx는 호스트 타임존(KST, +0900)으로 로그를 찍고, 컨테이너 안에서 도는 Tomcat/JVM은 기본값인 UTC로 찍고 있었습니다. 두 로그의 '같은 21:05'가 실제로는 9시간 어긋난 서로 다른 순간이라, 시각 대조가 조용히 틀어진 것입니다. access.log 끝의 [.../+0900]과 catalina.out의 오프셋 없는 타임스탬프를 무의식적으로 같은 시간대로 읽은 것이 함정이었습니다.
진단: 두 로그에 모두 남는 '동일 사건'을 앵커로 잡아 오프셋을 잽니다 — 배포 직후 첫 요청, 헬스체크 실패 순간 등. 그리고 각 프로세스의 타임존을 명시적으로 확인합니다.
# Nginx 타임스탬프의 오프셋 확인(끝에 +0900 붙는지)
tail -1 /var/log/nginx/access.log
# 컨테이너 Tomcat의 실제 타임존 확인
docker exec tomcat date
docker exec tomcat sh -c 'echo $TZ; cat /etc/timezone 2>/dev/null'
해결: 모든 로그를 UTC로 통일하거나(권장), 최소한 타임스탬프에 오프셋을 반드시 포함시킵니다. 급할 땐 상관분석 전에 한쪽을 다른 쪽 타임존으로 환산해 창(window)을 맞춘 뒤 대조합니다. 근본적으로는 로그 수집 단계에서 @timestamp를 UTC로 정규화해(Filebeat/rsyslog 기반 로그 수집 파이프라인 구성), 사람이 매번 시차를 암산하지 않도록 만듭니다. '같은 시각 대조'는 이 모듈의 핵심 기술이지만, 시간대가 어긋나면 그 기술 자체가 배신합니다.
실제 업무에서 이 지식이 쓰이는 상황:
장애 대응의 첫 5분이 가장 중요합니다. 이 시간에 "Nginx 문제인가, Tomcat 문제인가, DB 문제인가"를 결정해야 합니다. 에러 코드 하나로 범위를 좁힐 수 있습니다.
장애 대응 첫 3분 체크리스트:
# 1. 어떤 에러가 얼마나 나는가
awk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn
# 2. 언제부터 시작됐는가
awk '$9 >= 500' /var/log/nginx/access.log | tail -5
# 3. Nginx, Tomcat 상태는 살아있는가
systemctl status nginx tomcat
# 4. 최근 Exception이 있는가
grep -c "Exception" /opt/tomcat/logs/catalina.out
tail -3 <(grep "Exception" /opt/tomcat/logs/catalina.out)
# 5. DB 연결이 되는가
# mysql -u user -p -e "SELECT 1;" 또는 서비스 헬스체크 엔드포인트
이 5가지를 3분 안에 확인하면 "Nginx/Tomcat/DB 중 어디가 문제다"라는 가설을 세울 수 있습니다. 가설이 생기면 이후 조치가 빠릅니다.
명령어·단축키 빠른 참조
로그로 장애를 추적할 때 반복해서 쓰는 명령을 옵션과 함께 모았습니다. "예" 열 조합을 그대로 붙여 써도 됩니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
tail -f | 로그 실시간 추적 | tail -f /var/log/nginx/error.log (502·504 실시간) |
grep -A N | 매칭 줄 + 이후 N줄(스택 트레이스 전체) | grep -A 10 "NullPointerException" catalina.out |
grep -c | 매칭 줄 수(예외 유무 신호용) | grep -c "Exception" catalina.out — 건수 지표론 부정확 |
grep -i | 대소문자 무시 패턴 | grep -i "OutOfMemoryError|GC overhead" catalina.out |
grep -oP | 예외명만 뽑아 집계 | grep -oP '\w+Exception' catalina.out | sort | uniq -c |
awk '$9>=500' | 상태코드 필드로 에러 필터 | awk '$9>=500 {print $9,$7}' access.log | tail |
awk '{print $9}' | sort | uniq -c | 상태코드 분포 집계 | 200·404·500·502 건수 한눈에 |
awk '{print $NF,$7}' | sort -rn | 응답시간 TOP(upstream_response_time) | 느린 요청·URI 상위 10 |
substr($4,…) | 시간대별 분포 | awk '$9==500{print substr($4,14,5)}' access.log | sort | uniq -c |
ss -tlnp | 리슨 포트·PID 확인 | ss -tlnp | grep 8080 (502 포트 불일치) |
systemctl status | 서비스 생사 확인 | systemctl status nginx tomcat |
nginx -t && systemctl reload nginx | 설정 검증 후 무중단 반영 | 413·403·502 설정 수정 후 |
openssl x509 -noout -enddate | 인증서 만료일 확인 | openssl x509 -noout -enddate -in server.crt |
docker exec <c> date | 컨테이너 타임존 확인(로그 시각 대조) | Nginx(KST) vs Tomcat(UTC) 9시간 오차 |
관련 모듈로 더 깊이:
- HTTP 요청이 서버에 도달하기까지의 전체 흐름 — 에러 코드가 어느 구간(LB/Nginx/Tomcat/DB)에서 났는지 흐름으로 짚기
- Filebeat/rsyslog 기반 로그 수집 파이프라인 구성 — 서버가 늘어났을 때 로그를 한 곳에서 보는 Filebeat/ELK 파이프라인
- 타임라인 분석과 재발 방지 대책 수립 — 로그로 찾은 원인을 타임라인과 재발 방지 대책으로 정리하는 법
다음 모듈에서는 서버가 10대 이상으로 늘어났을 때 이 로그들을 한 곳에서 보는 방법(Filebeat/ELK)을 다룹니다.