서비스를 배포했는데 로그인 세션이 간헐적으로 끊기고, 검색 기능이 느립니다. Redis와 Elasticsearch를 사용하고 있다는 건 알겠는데 어디서 어떻게 확인해야 할지 모릅니다. "Redis OOM" 에러가 로그에 찍혔고, Elasticsearch API가 타임아웃 납니다.
관계형 DB 외에 서비스에 자주 붙는 보조 스토리지의 운영 기초를 익힙니다. Redis와 Elasticsearch의 상태 확인 방법과 흔한 장애 패턴을 정리합니다.
- 1redis-cli로 Redis 상태(ping, info, dbsize, memory)를 5단계로 확인할 수 있다
- 2maxmemory-policy의 역할과 allkeys-lru 설정 이유를 설명할 수 있다
- 3KEYS 대신 SCAN을 써야 하는 이유와 사용법을 설명할 수 있다
- 4Elasticsearch 클러스터 상태 API로 Green/Yellow/Red를 확인하고 대응할 수 있다
- 5Redis Sentinel과 Cluster의 차이를 설명할 수 있다
Redis 운영 기초
redis-cli — Redis 상태 확인 필수 명령어
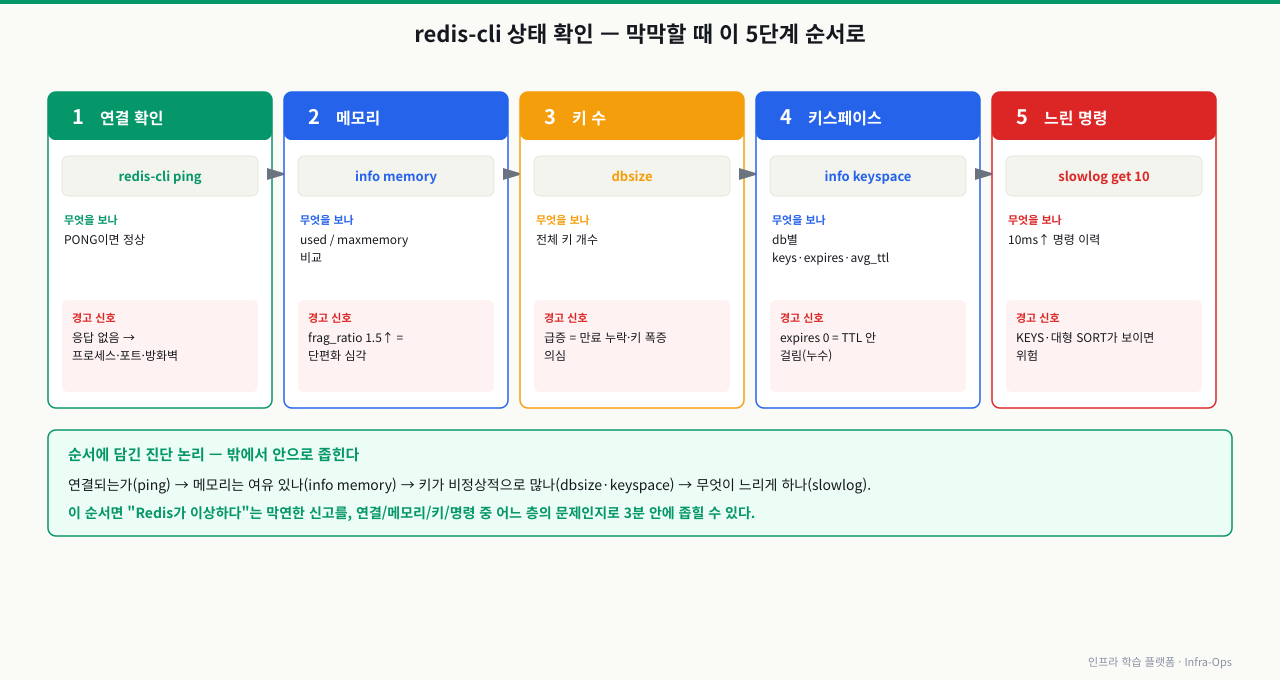
Redis가 정상인지 확인할 때 막막하다면, 5가지 명령어 순서만 기억하면 됩니다. 연결 확인 → 메모리 → 키 수 → 키스페이스 → 느린 명령어 순서입니다.
 확대
확대
# 1. 연결 확인 (가장 기본)
redis-cli ping
# PONG → 정상
# 원격 Redis 접속 (패스워드 있는 경우)
redis-cli -h redis-server -p 6379 -a yourpassword ping
# 환경변수 방식 (보안)
REDISCLI_AUTH=yourpassword redis-cli -h redis-server ping
# 2. 메모리 상태 확인
redis-cli info memory | grep -E "used_memory_human|maxmemory_human|mem_fragmentation_ratio"
# used_memory_human: 1.50G → 현재 사용 메모리
# maxmemory_human: 2.00G → 설정된 최대 메모리
# mem_fragmentation_ratio: 1.2 → 1.5 이상이면 단편화 심각
# 3. 전체 키 수 확인
redis-cli dbsize
# (integer) 1234567 → 키 수
# 4. 키스페이스 (DB별 키 수, 만료 키 수)
redis-cli info keyspace
# db0:keys=1234567,expires=45678,avg_ttl=3600000
# 5. 느린 명령어 로그 확인
redis-cli slowlog get 10
# 실행 시간이 긴 명령어 목록 (기본 10ms 이상)
redis-cli slowlog len # 느린 명령어 누적 수
메모리 관리 — maxmemory와 eviction 정책
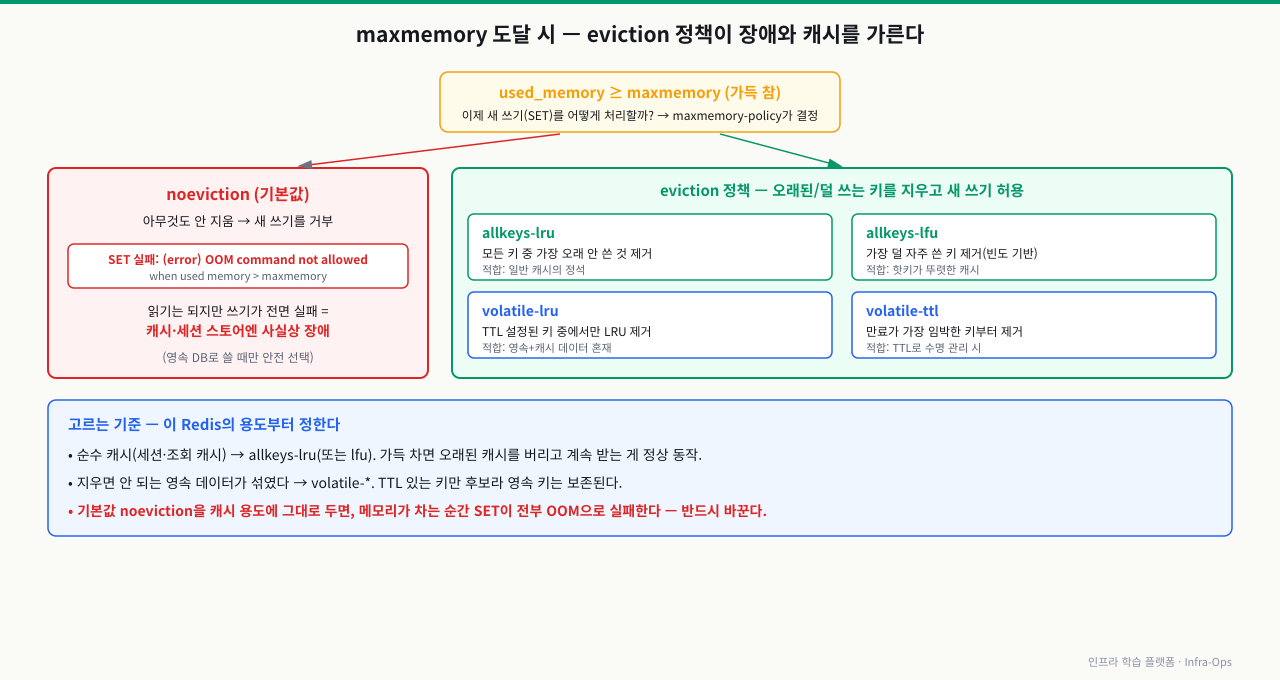
Redis가 메모리 한계에 도달했을 때 어떻게 동작할지는 설정에 달려있습니다. 이 설정을 빠뜨리면 갑자기 쓰기 명령이 전부 실패하는 장애가 납니다.
 확대
확대
# 현재 메모리 정책 확인
redis-cli config get maxmemory
redis-cli config get maxmemory-policy
# 설정 변경 (재시작 없이 적용)
redis-cli config set maxmemory 2gb
redis-cli config set maxmemory-policy allkeys-lru
# redis.conf에서 영구 설정
# maxmemory 2gb
# maxmemory-policy allkeys-lru
eviction 정책 선택 기준:
| 정책 | 동작 | 적합한 경우 |
|---|---|---|
| noeviction | 메모리 초과 시 쓰기 거부 | 데이터 손실 불가(세션, 락) |
| allkeys-lru | 전체 키 중 최근 미사용 순 제거 | 일반 캐시 (권장) |
| volatile-lru | TTL 있는 키 중 최근 미사용 순 제거 | TTL 없는 영구 키와 혼용 시 |
| allkeys-random | 전체 키 중 무작위 제거 | 균등 접근 패턴 캐시 |
캐시 용도 Redis 권장 설정:
# 캐시 전용 Redis 서버
redis-cli config set maxmemory-policy allkeys-lru
# 세션 저장 Redis 서버 (데이터 손실 불가)
redis-cli config set maxmemory-policy noeviction
# noeviction이면 메모리 여유를 넉넉히 확보해야 함
KEYS vs SCAN — 운영에서 절대 KEYS를 쓰면 안 되는 이유
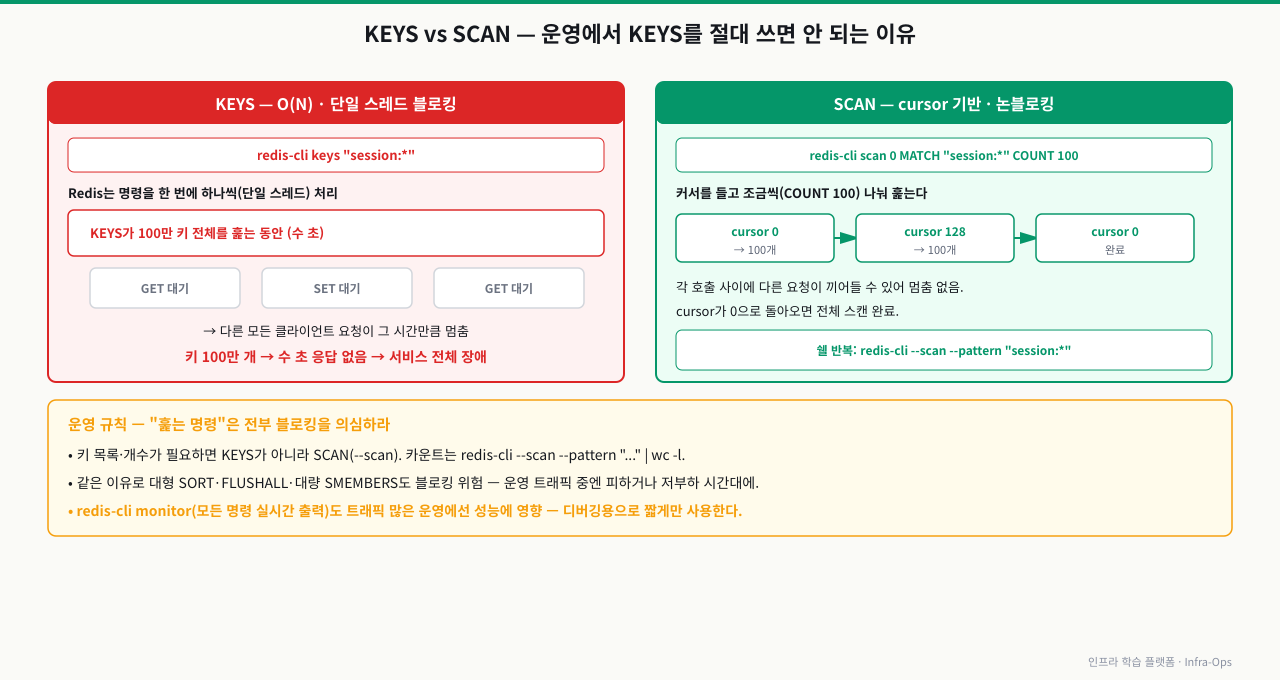
개발 환경에서 redis-cli keys "*" 같은 명령어를 썼다가 운영에 그대로 적용하면 서비스 장애가 납니다. 이유와 대안을 확실히 이해해야 합니다.
 확대
확대
# KEYS — 절대 운영 사용 금지
redis-cli keys "session:*"
# O(N) 연산, 단일 스레드 블로킹
# 키 100만 개 → Redis 수 초 응답 없음 → 서비스 장애
# SCAN — 운영 환경에서 사용할 키 조회 방법
# cursor 기반으로 점진적 스캔 (블로킹 없음)
redis-cli scan 0 MATCH "session:*" COUNT 100
# 반환값: [다음 cursor, [키 목록]]
# cursor가 0으로 돌아오면 전체 스캔 완료
# 쉘에서 반복 스캔 (전체 패턴 키 조회)
redis-cli --scan --pattern "session:*"
# 내부적으로 SCAN을 반복 호출하며 모든 결과 출력
# 특정 패턴 키 수 카운트 (대략적)
redis-cli --scan --pattern "session:*" | wc -l
redis-cli monitor 명령어 (운영 중 주의 사용):
# 실시간으로 모든 명령어를 출력 (디버깅용)
redis-cli monitor
# 출력 예시:
# 1717041600.123456 [0 127.0.0.1:52341] "GET" "session:abc123"
# 트래픽 많은 운영 환경에서는 성능에 영향 — 짧게만 사용
Redis Sentinel vs Cluster — 고가용성 구성 선택 기준
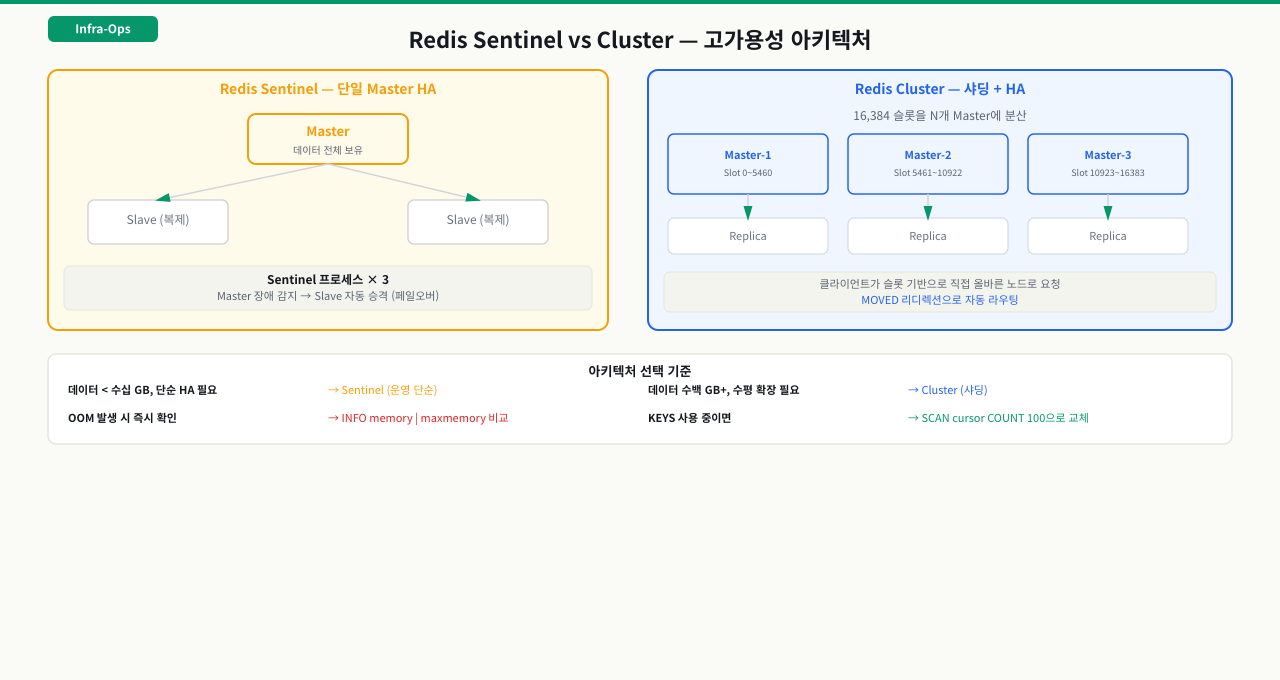
단일 Redis 서버가 다운되면 캐시 미스로 DB에 전체 부하가 몰립니다. 이를 막기 위해 Redis는 두 가지 고가용성 구성을 제공합니다. 어떤 것을 선택하느냐는 데이터 규모와 운영 복잡도에 따라 달라지므로, 인프라 엔지니어가 반드시 구분할 수 있어야 합니다.
Redis Sentinel — 단일 Master 고가용성(HA)
Master 1대 + Slave N대 구성에서 Sentinel 프로세스(최소 3개 권장)가 Master를 감시합니다. Master 장애 감지 시 Sentinel들이 과반수 투표로 Slave 중 하나를 자동으로 Master로 승격(Failover)시킵니다. 데이터는 Master 한 대에 집중되므로 데이터 용량이 서버 한 대 메모리를 초과하면 Sentinel은 한계에 부딪힙니다.
 확대
확대
Redis Cluster — 샤딩 + 고가용성 동시 해결
16384개의 hash slot을 여러 Master 노드에 분산해 데이터를 저장합니다. 각 Master는 Replica를 가지며, 특정 Master 장애 시 해당 Replica가 자동으로 Master로 승격됩니다. 대용량 데이터와 높은 처리량이 필요할 때 사용하지만 Multi-key 명령어 제한 등 운영 복잡도가 높습니다.
[Cluster 구조 — 최소 3 Master + 3 Replica]
Master1(slot 0-5460) Master2(slot 5461-10922) Master3(slot 10923-16383)
↓ ↓ ↓
Replica1 Replica2 Replica3
| 항목 | Sentinel | Cluster |
|---|---|---|
| 데이터 분산 | 없음 (Master 1대) | 샤딩 (N개 Master) |
| 용량 한계 | 서버 1대 메모리 | 전체 노드 합산 |
| 페일오버 | 자동 (Sentinel 투표) | 자동 (내장) |
| 권장 규모 | 소~중형 (수십 GB 이하) | 대형 (100GB 이상) |
| 운영 복잡도 | 낮음 | 높음 |
Redis 상태 확인 실습
Redis 서버 상태를 순서대로 확인하는 5단계 루틴입니다. 장애 대응 시에도 이 순서로 확인합니다.
# 1단계: 연결 확인
redis-cli -h redis-server -p 6379 ping
# PONG
# 2단계: 메모리 상태
redis-cli -h redis-server info memory | grep -E "used_memory_human|maxmemory_human|maxmemory_policy"
# 3단계: 전체 키 수
redis-cli -h redis-server dbsize
# 4단계: DB별 키 분포
redis-cli -h redis-server info keyspace
# 5단계: 느린 명령어 확인
redis-cli -h redis-server slowlog get 5
# 출력 형식: [ID, 실행시각, 소요시간(마이크로초), 명령어, 인수]
# 1) 1) (integer) 14 ← slowlog ID
# 2) (integer) 1717041600 ← 실행 시각 (unix timestamp)
# 3) (integer) 15432 ← 소요 시간 (15.4ms)
# 4) 1) "KEYS" ← 문제 명령어 발견
# 2) "*"
redis-cli ping && redis-cli info memory | grep used_memory_human && redis-cli dbsize && redis-cli info keyspace && redis-cli slowlog get 5- redis-cli ping 응답을 먼저 확인 — PONG이 즉시(1초 이내) 오면 연결 정상. 지연이 있거나 Connection refused이면 Redis 프로세스 상태 확인(systemctl status redis)
- used_memory_human과 maxmemory_human을 비교 — used가 maxmemory의 80% 이상이면 eviction 시작 임박. 90% 이상이면 noeviction 정책 시 신규 쓰기 거부됨
- slowlog에 KEYS 명령어가 있고 used_memory가 높은 조합이면 — KEYS는 모든 키를 순회하는 O(N) 명령으로 Redis가 block됨. SCAN으로 대체하고 캐시 키 규모가 10만 개 이상이면 즉시 조치
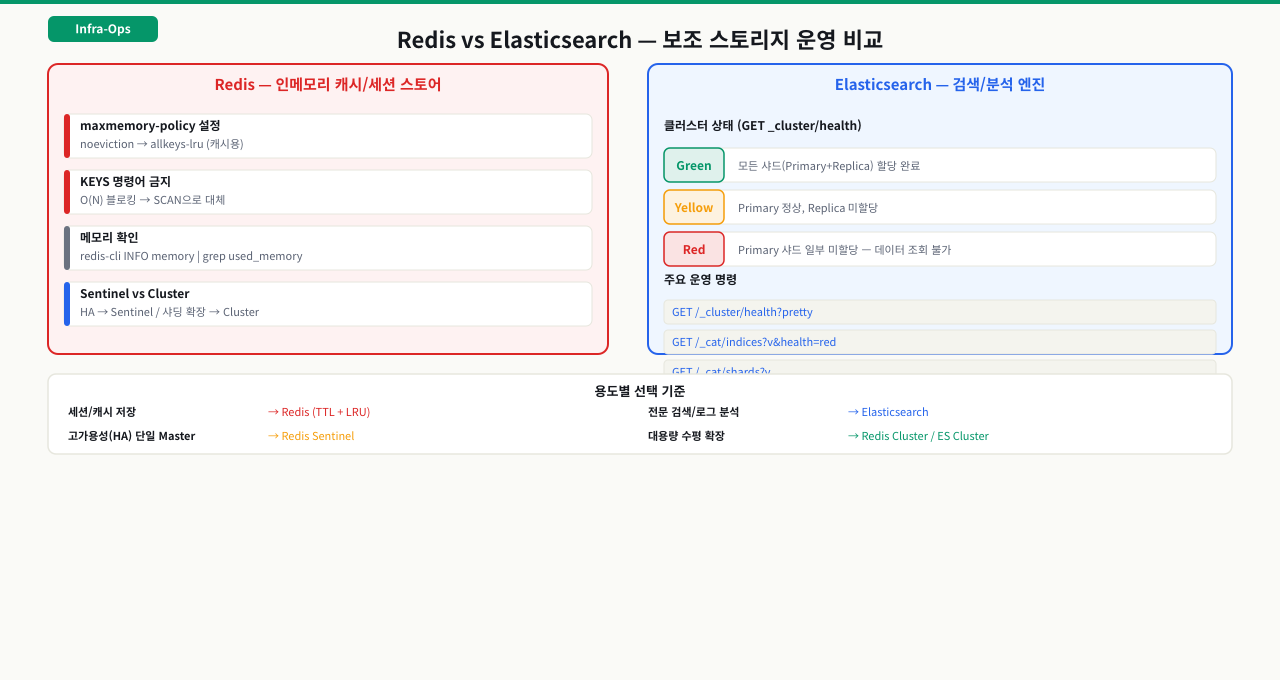
Elasticsearch 클러스터 상태 확인
Elasticsearch 클러스터 상태 API — Green/Yellow/Red 대응
Elasticsearch는 REST API로 모든 상태를 확인합니다. 클러스터 상태, 인덱스 목록, 노드 상태를 curl 한 줄로 볼 수 있습니다.
 확대
확대
# 1. 클러스터 전체 상태 (가장 먼저 확인)
curl http://es-server:9200/_cluster/health?pretty
# 응답 예시 (Green):
# {
# "cluster_name": "my-cluster",
# "status": "green",
# "number_of_nodes": 3,
# "number_of_data_nodes": 3,
# "active_primary_shards": 15,
# "active_shards": 30,
# "relocating_shards": 0,
# "initializing_shards": 0,
# "unassigned_shards": 0 ← 0이어야 Green
# }
# 응답 예시 (Yellow):
# "status": "yellow",
# "unassigned_shards": 5 ← Replica 샤드 미할당
# 응답 예시 (Red):
# "status": "red",
# "unassigned_shards": 3 ← Primary 샤드 미할당
# 2. 인덱스 목록 및 상태
curl http://es-server:9200/_cat/indices?v
# 출력:
# health status index uuid pri rep docs.count store.size
# green open products-2026 abc123 1 1 1234567 2.3gb
# yellow open orders-2025 def456 1 1 567890 890mb
# 3. 노드 상태 확인
curl http://es-server:9200/_cat/nodes?v
# 출력:
# ip heap.percent ram.percent cpu load_1m node.role name
# 10.0.1.10 45 78 5 0.5 mdi node-1
# 10.0.1.11 52 80 8 0.8 mdi node-2
# 4. 미할당 샤드 상세 원인 확인 (Yellow/Red 시)
curl http://es-server:9200/_cluster/allocation/explain?pretty
클러스터 상태별 대응:
| 상태 | 원인 | 대응 |
|---|---|---|
| Green | - | 정상 |
| Yellow | Replica 미할당 (노드 부족) | 노드 추가 또는 replica 수 줄이기 |
| Red | Primary 미할당 | 즉시 대응 — 노드 복구 또는 샤드 재할당 |
ES 상태 확인은 항상 클러스터 레벨 → 인덱스 레벨 → 노드 레벨 순서로 확인합니다.
# 전체 상태 요약 (한 줄 형식)
curl -s "http://es-server:9200/_cat/health?v"
# epoch timestamp cluster status node.total node.data shards pri relo init unassign
# 1717041600 09:00:00 my-cluster green 3 3 30 15 0 0 0
# Yellow 상태 시 미할당 샤드 확인
curl -s "http://es-server:9200/_cat/shards?v&h=index,shard,prirep,state,node" | grep UNASSIGNED
# Yellow 해결 — replica 수를 1에서 0으로 줄이기 (단일 노드 환경)
curl -X PUT "http://es-server:9200/_settings" \
-H "Content-Type: application/json" \
-d '{"index": {"number_of_replicas": 0}}'
# 특정 인덱스만 변경
curl -X PUT "http://es-server:9200/my-index/_settings" \
-H "Content-Type: application/json" \
-d '{"index": {"number_of_replicas": 0}}'
curl -s http://es-server:9200/_cluster/health?pretty- _cluster/health에서 status 필드를 먼저 확인 — green이면 모든 샤드 정상. yellow이면 레플리카 미할당(기능은 정상), red이면 프라이머리 샤드 미할당(데이터 접근 불가 인덱스 존재)
- unassigned_shards가 0이 아닌데 노드 수는 정상이면 — 디스크 사용률이 85% 이상인 노드가 있어 샤드 할당을 거부하는 경우. _cat/nodes?v의 disk.used.percent 확인
- heap.percent가 80% 이상이면 GC 빈발로 성능 저하 — 85% 이상이면 OutOfMemoryError 위험. heap.percent가 높고 status가 yellow인 조합이면 샤드 재배치를 할 여유 메모리가 없는 상태
트러블슈팅
원인: Redis의 메모리 사용량이 maxmemory 한계에 도달했고, maxmemory-policy가 noeviction으로 설정돼 있어 새로운 쓰기 명령을 모두 거부하고 있습니다.
# 1. 현재 메모리 상태 확인
redis-cli info memory | grep -E "used_memory_human|maxmemory_human|maxmemory_policy"
# maxmemory_policy: noeviction ← 문제 설정 확인
# 2. 전체 키 수 및 TTL 없는 키 비율 확인
redis-cli dbsize
redis-cli info keyspace
# expires 수가 keys에 비해 매우 작으면 TTL 미설정 키 과다
# 3. 즉각 조치 (서비스 중단 방지)
# 옵션 A: eviction 정책 변경 (캐시 성격이면)
redis-cli config set maxmemory-policy allkeys-lru
# 옵션 B: maxmemory 임시 증가 (장기 해결책이 아님)
redis-cli config set maxmemory 4gb
# 옵션 C: TTL 없는 불필요 키 삭제
redis-cli --scan --pattern "old-cache:*" | xargs -L 100 redis-cli del
# 4. redis.conf 영구 반영
# maxmemory 4gb
# maxmemory-policy allkeys-lru
원인: 클러스터에 Replica 샤드를 배치할 노드가 부족합니다. 노드가 1대인데 replica가 1로 설정돼 있거나, 노드 한 대가 다운된 경우입니다.
# 1. 미할당 샤드 확인
curl -s "http://es-server:9200/_cat/shards?v" | grep UNASSIGNED
# 2. 원인 상세 확인
curl -s "http://es-server:9200/_cluster/allocation/explain?pretty"
# "explanation": "cannot allocate because a previous copy of the primary shard existed..."
# "explanation": "the shard cannot be allocated because there are not enough nodes"
# 3-A: 단일 노드 환경 — replica를 0으로 설정
curl -X PUT "http://es-server:9200/_all/_settings" \
-H "Content-Type: application/json" \
-d '{"index.number_of_replicas": 0}'
# 3-B: 다운된 노드가 있는 경우 — 노드 복구 후 샤드 자동 재할당 대기
# 노드 복구 후 상태 확인
curl -s "http://es-server:9200/_cat/nodes?v"
# 3-C: 노드 추가 (장기 해결책)
# 새 노드를 같은 클러스터 이름으로 시작하면 자동으로 샤드 재배치됨
# 4. 상태 모니터링 (자동 복구 확인)
watch -n 5 'curl -s "http://es-server:9200/_cat/health?v"'
심화 — 겉으로 멀쩡한데 터지는 순간들
심화: Redis 스냅샷의 숨은 비용 — fork와 copy-on-write
used_memory는 maxmemory 아래인데도 밤마다 같은 시각 Redis가 지연 폭주하거나 OS의 OOM killer에 죽는 일이 있습니다. 범인은 명령어가 아니라 Redis가 데이터를 디스크로 저장하는 방식입니다.
- 저장은 fork로 일어납니다:
BGSAVE(RDB 스냅샷)나 AOF rewrite는 자식 프로세스를fork해 그 스냅샷을 디스크에 씁니다. fork 순간 자식은 부모의 메모리를 copy-on-write로 공유해, 처음엔 복사 없이 페이지를 함께 봅니다. - 쓰기가 메모리를 부풀립니다: 저장이 도는 동안 부모가 키를 수정하면 해당 메모리 페이지가 복제됩니다(COW). 쓰기가 많은 워크로드에서는 저장 도중 물리 메모리(
used_memory_rss)가 최악의 경우 거의 2배까지 튀어,maxmemory는 여유로워 보여도 OS 레벨에서 OOM이 나 커널이 Redis를 죽일 수 있습니다. - fork 자체가 지연을 만듭니다: 데이터셋이 크면 fork로 페이지 테이블을 복제하는 것만으로 수십~수백 ms 멈춤이 생깁니다. "매일 특정 시각 지연"은 대개 스케줄된 저장·rewrite 시각과 일치합니다.
- 한계/대응:
used_memory가 아니라used_memory_rss와latest_fork_usec를 함께 봐야 합니다. 순수 캐시라면 RDB/AOF를 끄거나 저빈도로 돌리고, 영속이 필요하면 Replica에서 저장을 수행해 Master의 fork 부담을 덜며,vm.overcommit_memory=1로 fork 실패를 예방합니다.
그래서 Redis 용량 계획은 데이터 크기만이 아니라 "저장이 돌 때의 여유 메모리"까지 잡아야 합니다.
상황: 클러스터 상태는 green(샤드 모두 할당)인데 문서 색인 요청만 죄다 cluster_block_exception으로 거부됩니다. 읽기·검색은 정상입니다. Yellow도 Red도 아니라 상태만 보면 멀쩡해 원인이 안 잡힙니다.
원인: 데이터 노드의 디스크 사용률이 flood_stage 워터마크(기본 95%) 를 넘었습니다. ES는 디스크가 꽉 차 인덱스가 손상되는 것을 막으려고, 그 노드에 샤드를 가진 인덱스를 자동으로 read-only(index.blocks.read_only_allow_delete=true)로 전환합니다. 그래서 쓰기만 막히고 상태는 green으로 남습니다. (85% high 워터마크는 신규 샤드 할당을 멈추고, 그 위에서는 샤드를 다른 노드로 옮기려 시도합니다.)
진단: _cat/allocation?v나 _cat/nodes?v의 disk.used_percent로 95%를 넘긴 노드를 찾습니다. 인덱스 설정에서 index.blocks.read_only_allow_delete가 걸렸는지 확인합니다.
해결: 먼저 디스크를 비웁니다(오래된 인덱스 삭제·ILM 롤오버, 볼륨 확장). 사용률을 flood_stage 아래로 내린 뒤, 자동으로 걸린 read-only 블록을 해제합니다(index.blocks.read_only_allow_delete를 null로 설정). 재발 방지로 디스크 알람을 워터마크보다 낮게 걸고, ILM으로 오래된 인덱스를 자동 정리합니다.
실제 업무에서 이 지식이 쓰이는 상황:
1. 배포 직후 Redis 상태 확인 루틴:
# 신규 서비스 배포 후 캐시 동작 확인
redis-cli -h redis-server info memory | grep used_memory_human
redis-cli -h redis-server dbsize
# 키 수가 급격히 늘었으면 TTL 설정 여부 점검
redis-cli -h redis-server info keyspace | grep expires
2. Redis 느린 응답 민원 접수 시:
# 느린 명령어 먼저 확인
redis-cli slowlog get 20 | grep -A 4 '"KEYS"'
# KEYS 명령어 발견 → 개발팀에 SCAN으로 교체 요청
# 메모리 단편화 확인
redis-cli info memory | grep mem_fragmentation_ratio
# 1.5 이상이면 Redis 재시작 또는 MEMORY PURGE 고려
3. Elasticsearch 정기 점검:
# 매일 아침 헬스체크 스크립트
STATUS=$(curl -s "http://es-server:9200/_cat/health?h=status" | tr -d '\n')
if [ "$STATUS" != "green" ]; then
echo "ES 클러스터 상태 이상: $STATUS"
curl -s "http://es-server:9200/_cluster/allocation/explain?pretty"
fi
명령어·단축키 빠른 참조
이 모듈에서 다룬 Redis(redis-cli)·Elasticsearch(REST API) 상태 점검 명령을 실전 옵션과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
redis-cli ping | 연결 확인(첫 단계) | PONG이면 정상, -h <host> -p 6379로 원격 |
redis-cli info memory | 메모리·단편화 확인 | used_memory_human·mem_fragmentation_ratio |
redis-cli dbsize | 전체 키 수 확인 | 급증이면 TTL 누락·키 폭증 의심 |
redis-cli info keyspace | DB별 keys·expires·ttl | expires가 0이면 TTL 미설정 |
redis-cli slowlog get 10 | 느린 명령어 추적 | KEYS·대형 SORT 보이면 위험 |
redis-cli --scan --pattern | 운영 안전 키 조회(KEYS 대체) | redis-cli --scan --pattern "session:*" |
redis-cli config set | 무중단 정책 변경 | config set maxmemory-policy allkeys-lru |
redis-cli monitor | 실시간 명령 확인(짧게만) | 운영 트래픽에선 성능 영향 |
curl _cluster/health | ES 클러스터 상태 확인 | curl <es>:9200/_cluster/health?pretty |
curl _cat/health?v | 상태 한 줄 요약 | status가 green/yellow/red |
curl _cat/nodes?v | 노드 heap·disk 확인 | disk.used_percent 95% 넘으면 쓰기 차단 |
curl _cat/shards | 미할당 샤드 식별 | | grep UNASSIGNED로 Yellow/Red 원인 추적 |
curl _cluster/allocation/explain | 샤드 미할당 원인 상세 | ?pretty로 이유 확인 |
관련 모듈로 더 깊이:
- JDBC Connection Pool과 DB 장애 분리 실무 — 주 저장소인 RDB 연결·풀 관리와 보조 스토리지의 역할 분담
- CPU/메모리/디스크 임계치 관리와 logrotate — Redis 메모리·ES 클러스터 상태를 지속 감시하는 모니터링
다음 모듈에서는 cron과 Quartz 스케줄러 장애 분석과 Spring Batch 재처리 실무를 다룹니다.