이 모듈은 앞서 배운 모든 내용이 실제 장애 상황에서 어떻게 쓰이는지를 7가지 시나리오로 묶어 보여줍니다. 새벽 2시 알림, 인증서 만료, SSO 루프, WAF 오탐, DB 커넥션 소진, 긴급 롤백, 방화벽 오픈 요청 — 실제 운영팀 업무의 단면들입니다.
각 시나리오는 "상황 → 확인 → 조치 → 검증" 흐름으로 구성됩니다. 명령어를 외우는 것이 아니라, 어떤 순서로 생각하고 어디서 정보를 가져오는지를 익히는 것이 목표입니다.
- 1새벽 장애 알림 수신부터 원인 특정, 조치, 보고까지 흐름을 따를 수 있다
- 2SSL 인증서 만료를 openssl로 사전 확인하고 갱신 절차를 수행할 수 있다
- 3SSO redirect loop의 원인을 쿠키·세션 관점에서 분석할 수 있다
- 4WAF 오탐(False Positive) 발생 시 로그에서 규칙 ID를 찾고 예외 처리할 수 있다
- 5HikariCP/DB Connection Pool 소진 상황을 진단하고 임시 조치할 수 있다
- 6배포 후 오류 발생 시 Go/No-Go 롤백 결정 기준을 설명할 수 있다
- 7외부 API 연계 요청에서 방화벽 오픈 절차를 완료할 수 있다
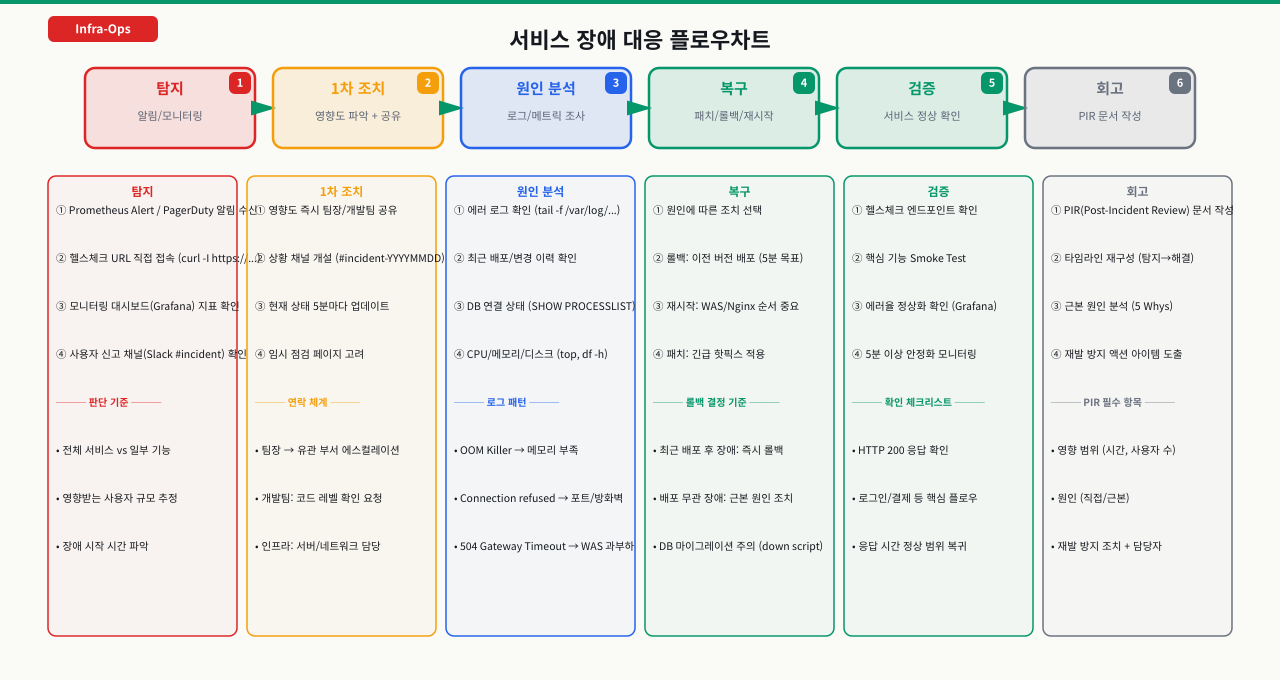
시나리오 1: 새벽 2시 서비스 장애
상황: 모니터링 알림 — 서비스 응답 없음
새벽 2시 17분, 슬랙 알림이 울립니다. "헬스체크 실패 — 서비스 응답 없음". 잠에서 깨서 노트북을 열었습니다. 어디서부터 시작해야 할까요?
 확대
확대
장애 대응 8단계:
1. 영향도 파악 (가장 먼저)
→ 전체 서비스인가, 특정 기능인가
→ 실제 사용자 영향 범위 (트래픽 시간대 확인)
2. 관련자 공유 (1~2분 내)
→ 팀장, 당직 개발자에게 영향도 요약 전송
→ "20:17 서비스 전체 다운, 확인 중" (원인 몰라도 먼저 공유)
3. Nginx 로그 확인 (인프라 레이어부터)
4. WAS(Tomcat) 로그 확인
5. DB 연결 확인
6. 원인 특정 및 조치
7. 서비스 복구 확인
8. 보고서 작성 (5W1H)
실제 명령어 흐름:
# 3. Nginx 상태와 최근 에러 로그
sudo systemctl status nginx
sudo tail -100 /var/log/nginx/error.log | grep "$(date +%Y/%m/%d)"
# 액세스 로그에서 최근 상태코드 분포
sudo awk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn
# 출력 예: 502가 급증했다면 → Nginx는 살아있고 WAS가 다운
# 4. WAS 로그 확인
sudo tail -200 /opt/tomcat/logs/catalina.out | grep -E "ERROR|Exception|OutOfMemory"
# 메모리 상태 확인 (OOM 의심 시)
free -h
dmesg | grep -i "out of memory" | tail -10
# 5. DB 연결 확인 (WAS 로그에 DB 연결 오류 있을 때)
mysql -u app -p -e "SELECT 1;" 2>&1
# ERROR 2003 (HY000): Can't connect → DB 자체 문제
# ERROR 1040 (HY000): Too many connections → 커넥션 소진
# 6-1. Tomcat이 응답 안 하면 재시작
sudo systemctl restart tomcat
sudo tail -f /opt/tomcat/logs/catalina.out # 기동 로그 확인
# 7. 서비스 복구 확인
curl -o /dev/null -s -w "%{http_code}" http://localhost/health
# 200 이면 복구 완료
장애 보고서 5W1H:
언제(When): 2026-05-30 02:17 ~ 02:34 (17분간)
무엇이(What): 전체 서비스 응답 없음 (HTTP 502)
어디서(Where): app-server-01 Tomcat 프로세스
왜(Why): Tomcat heap 메모리 소진 → OOM Killer에 의해 프로세스 종료
어떻게(How): systemctl restart tomcat으로 즉시 복구
조치(Action): JVM 힙 설정 검토, 메모리 사용량 CloudWatch 알람 추가
시나리오 2: SSL 인증서 만료 긴급 대응
상황: 일부 사용자 '인증서 오류' 신고
고객센터에 "사이트가 안전하지 않다는 경고가 뜬다"는 신고가 들어왔습니다. 직접 들어가 보니 크롬에서 "ERR_CERT_DATE_INVALID" 오류가 납니다. 인증서 만료입니다.
 확대
확대
# 인증서 만료일 즉시 확인
echo | openssl s_client -connect example.com:443 2>/dev/null | \
openssl x509 -noout -dates
# notBefore=May 30 00:00:00 2025 GMT
# notAfter=May 30 23:59:59 2026 GMT ← 오늘 만료!
# 인증서 파일 직접 확인 (서버에서)
sudo openssl x509 -in /etc/nginx/ssl/example.com.crt -noout -dates
sudo openssl x509 -in /etc/nginx/ssl/example.com.crt -noout -subject
# 현재 Nginx에 적용된 인증서 경로 확인
grep -r "ssl_certificate " /etc/nginx/conf.d/
Let's Encrypt 인증서 갱신:
# certbot이 설치된 경우
sudo certbot renew --dry-run # 먼저 테스트
sudo certbot renew # 실제 갱신
# 갱신 후 자동으로 Nginx reload 됨 (certbot hook 설정 시)
# 수동으로 reload
sudo nginx -t && sudo systemctl reload nginx
# 갱신 확인
echo | openssl s_client -connect example.com:443 2>/dev/null | \
openssl x509 -noout -dates
# notAfter가 3개월 후로 바뀌었는지 확인
유료 인증서(공인인증서) 갱신 절차:
# 1. CSR 생성 (기존 키 재사용)
openssl req -new \
-key /etc/nginx/ssl/example.com.key \
-out /tmp/example.com.csr \
-subj "/C=KR/ST=Seoul/L=Seoul/O=Company/CN=example.com"
# 2. CSR을 인증기관(CA)에 제출 → 새 인증서 파일(.crt) 수령
# 3. 기존 인증서 파일 교체
sudo cp /etc/nginx/ssl/example.com.crt /etc/nginx/ssl/example.com.crt.bak
sudo cp /tmp/new_example.com.crt /etc/nginx/ssl/example.com.crt
# 4. Nginx 설정 검증 후 reload
sudo nginx -t && sudo systemctl reload nginx
# 5. 브라우저에서 자물쇠 아이콘 확인
# 6. 갱신 스케줄 캘린더에 등록 (만료 30일 전 알람)
예방 — 만료 사전 모니터링:
# 만료 30일 이내 인증서 경고 스크립트 (crontab 등록)
#!/bin/bash
DOMAIN="example.com"
EXPIRY=$(echo | openssl s_client -connect $DOMAIN:443 2>/dev/null | \
openssl x509 -noout -enddate | cut -d= -f2)
EXPIRY_EPOCH=$(date -d "$EXPIRY" +%s)
NOW_EPOCH=$(date +%s)
DAYS_LEFT=$(( ($EXPIRY_EPOCH - $NOW_EPOCH) / 86400 ))
if [ $DAYS_LEFT -lt 30 ]; then
echo "경고: $DOMAIN 인증서 만료 $DAYS_LEFT 일 남음" | \
mail -s "SSL 인증서 만료 임박" admin@example.com
fi
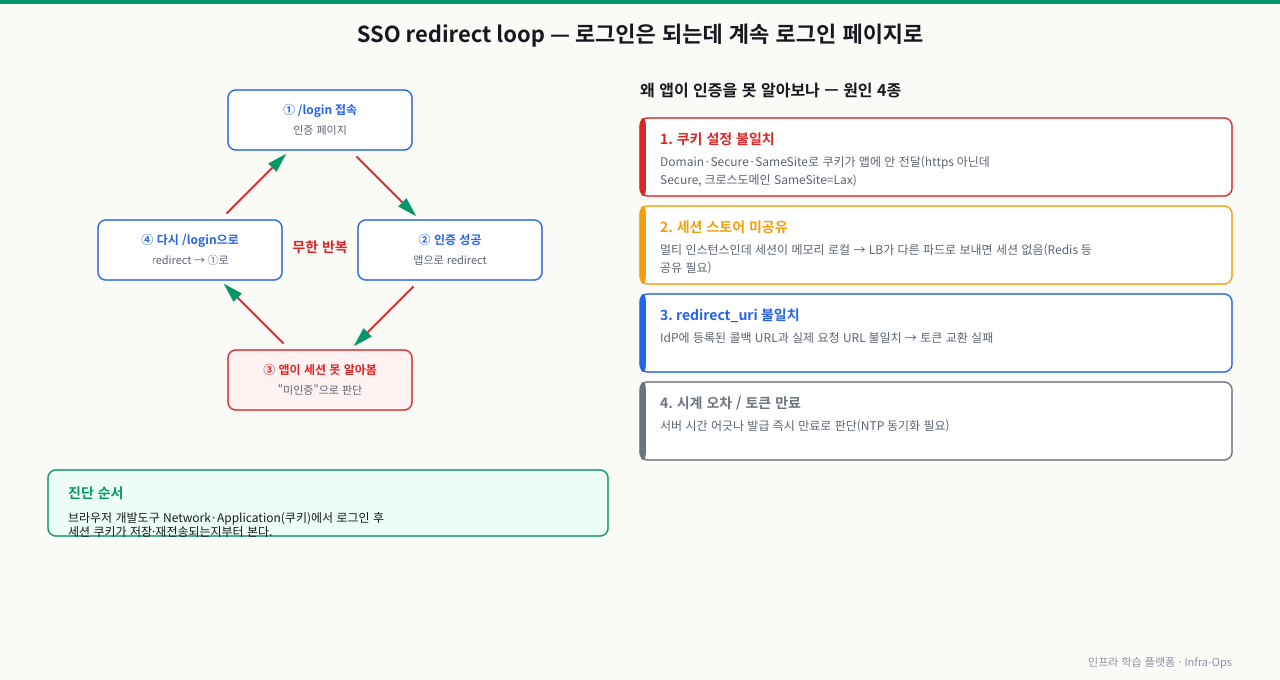
시나리오 3: SSO redirect loop 장애
상황: 로그인 후 계속 로그인 페이지로 돌아옴
사용자가 "로그인이 안 된다"고 신고합니다. 직접 해보니 ID/PW를 입력하면 계속 로그인 페이지로 리다이렉트됩니다. 브라우저 주소창이 빠르게 바뀌다가 "Too many redirects" 오류가 납니다.
 확대
확대
원인 분석 흐름:
# 1. 브라우저 개발자도구 → Network 탭
# → 302 리다이렉트가 반복되는 패턴 확인
# → Set-Cookie 헤더가 있는지 확인
# 2. SP(서비스 제공자) 세션 쿠키 확인
# 크롬 개발자도구 → Application → Cookies
# → 세션 쿠키가 설정됐다가 사라지는 패턴?
# 3. Nginx 로그에서 리다이렉트 루프 확인
sudo grep "302" /var/log/nginx/access.log | tail -20
# 같은 URI로 302가 반복되는지 확인
# 4. SameSite 설정 확인 (가장 흔한 원인)
# SP 애플리케이션 설정에서 쿠키 SameSite 속성 확인
# SameSite=Strict: 다른 도메인에서 전송된 요청에 쿠키 미포함
# → IdP → SP 리다이렉트 시 SameSite=Strict 쿠키가 전달 안 됨
# 5. Nginx SSL terminate 환경에서 X-Forwarded-Proto 누락 확인
grep "X-Forwarded-Proto" /etc/nginx/conf.d/*.conf
# proxy_set_header X-Forwarded-Proto $scheme; 이 없으면
# 앱이 항상 HTTP로 인식 → HTTPS 강제 설정과 충돌 → 루프
조치:
# Nginx 설정에 X-Forwarded-Proto 추가
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme; # 이 줄 추가
}
# IdP 연동 로그 확인 (SAML/OIDC)
# IdP 로그에서 SP assertion 처리 성공 여부 확인
# 대부분의 IdP는 /var/log/shibboleth/ 또는 별도 관리 콘솔에서 확인
sudo nginx -t && sudo systemctl reload nginx
# 검증 — 브라우저 캐시 삭제 후 재로그인 테스트
# 시크릿 모드에서 테스트 (캐시 영향 배제)
시나리오 4: WAF 정상 요청 차단 (False Positive)
상황: 특정 API 요청이 403으로 차단됨
개발팀으로부터 "회원 등록 API가 갑자기 403을 반환한다"는 연락이 왔습니다. curl로 직접 테스트해도 동일합니다. WAF(Web Application Firewall) 오탐입니다.
# 1. WAF 로그에서 차단 규칙 확인
# AWS WAF 사용 시 CloudWatch Logs에서 확인
aws logs filter-log-events \
--log-group-name aws-waf-logs-my-waf \
--filter-pattern "BLOCK" \
--start-time $(date -d '1 hour ago' +%s)000 | \
python3 -c "import sys,json; [print(json.dumps(json.loads(e['message']), indent=2)) for e in json.load(sys.stdin)['events']]"
# 출력에서 확인할 항목:
# terminatingRuleId: 차단한 규칙 ID (예: AWS-AWSManagedRulesCommonRuleSet)
# terminatingMatchDetails: 매칭된 패턴 (어떤 파라미터가 걸렸는지)
# 온프레미스 ModSecurity WAF 로그 확인
sudo tail -100 /var/log/modsec_audit.log | grep "Access denied"
# [file "rules/REQUEST-942-APPLICATION-ATTACK-SQLI.conf"]
# [id "942100"] [msg "SQL Injection Attack Detected"]
오탐 처리 — 예외 규칙 추가:
# ModSecurity 예외 처리 (특정 URI + 규칙 ID 예외)
# /etc/nginx/modsecurity/exceptions.conf 에 추가
sudo tee -a /etc/nginx/modsecurity/exceptions.conf << 'RULE'
# /api/v1/register 경로에서 942100 규칙 예외
SecRule REQUEST_URI "@beginsWith /api/v1/register" \
"id:1001,phase:1,pass,nolog,ctl:ruleRemoveById=942100"
RULE
sudo nginx -t && sudo systemctl reload nginx
개발팀 요청 검토 기준:
오탐 확인 전:
1. 실제로 정상 요청인가 확인 (개발팀에 페이로드 공유 요청)
2. 해당 규칙이 왜 걸렸는지 이해 (SQL 인젝션 패턴 vs 실제 데이터)
3. 특정 URI/파라미터에만 예외 적용 (전체 규칙 비활성화 금지)
예외 처리 후:
4. 변경 내용 문서화
5. 보안팀 공유 (WAF 규칙 변경은 보안 이벤트)
6. 해당 파라미터를 애플리케이션 레벨에서도 검증하도록 개발팀 요청
시나리오 5: DB Connection Pool 소진
상황: HikariCP timeout 오류로 서비스 지연
Tomcat 로그에 "HikariPool-1 - Connection is not available, request timed out after 30000ms"가 쏟아집니다. DB 커넥션 풀이 가득 찼습니다.
# 1. HikariCP 로그에서 pool 상태 확인
sudo grep -A 5 "HikariPool" /opt/tomcat/logs/catalina.out | tail -30
# "Total=50, Active=50, Idle=0, Waiting=23" → pool 전부 사용 중
# 2. MySQL SHOW PROCESSLIST — 현재 실행 중인 쿼리 확인
mysql -u root -p -e "SHOW FULL PROCESSLIST;"
# 또는
mysql -u root -p -e "
SELECT id, user, host, db, command, time, state, left(info, 100) as query
FROM information_schema.processlist
WHERE command != 'Sleep'
ORDER BY time DESC;"
# 오래된 연결 (Sleep 포함) 확인
mysql -u root -p -e "
SELECT id, user, host, time, command
FROM information_schema.processlist
WHERE time > 60
ORDER BY time DESC;"
# 3. 느린 쿼리 강제 종료 (ID 확인 후)
mysql -u root -p -e "KILL QUERY 1234;" # 쿼리만 종료 (연결 유지)
mysql -u root -p -e "KILL 1234;" # 연결 전체 종료
# 4. 슬로우 쿼리 로그에서 근본 원인 찾기
sudo tail -100 /var/log/mysql/slow.log
# Query_time: 45.123456 → 45초 걸린 쿼리
# Full table scan, filesort → 인덱스 없음
# 5. 임시 Pool 크기 증가 (application.properties 또는 환경변수)
# spring.datasource.hikari.maximum-pool-size=50 → 100으로 변경
# → 재배포 또는 재시작 필요 (임시방편)
근본 원인 분석 — 인덱스 확인:
-- 슬로우 쿼리를 EXPLAIN으로 분석
EXPLAIN SELECT * FROM orders WHERE customer_email = 'user@example.com';
-- type: ALL → 풀스캔 (인덱스 없음)
-- rows: 1000000 → 100만 행 스캔
-- 인덱스 추가 (온라인 DDL — 서비스 중단 없이)
ALTER TABLE orders ADD INDEX idx_customer_email (customer_email);
-- 인덱스 추가 후 재확인
EXPLAIN SELECT * FROM orders WHERE customer_email = 'user@example.com';
-- type: ref → 인덱스 사용
-- rows: 5 → 5행만 스캔
시나리오 6: 배포 후 서비스 오류 → 긴급 롤백
상황: 신규 버전 배포 후 결제 오류 다발 신고
오후 3시 배포를 마쳤는데 15분 후부터 결제 오류 신고가 쏟아집니다. 헬스체크는 200이지만 실제 결제가 안 됩니다.
Go/No-Go 롤백 결정 기준:
롤백 결정 기준:
Go(유지): 에러율 1% 미만, 경미한 UI 버그, 핫픽스 가능
No-Go(롤백): 에러율 5% 이상, 핵심 기능(결제/인증) 오류, 데이터 손실 위험
결제 오류 → 즉시 No-Go 결정
롤백 절차:
# 1. 오류 확인 — 실제 영향도
sudo grep "ERROR\|Exception" /opt/tomcat/logs/catalina.out | \
grep "$(date +%Y-%m-%d)" | wc -l
# 오류 수가 급증했는지 확인
# 에러 패턴 파악
sudo grep "PaymentException\|TransactionException" /opt/tomcat/logs/catalina.out | \
tail -20
# 2. 롤백 결정 → 이전 버전 WAR 파일로 교체
# 배포 전 백업된 WAR 파일 위치 확인
ls -lt /opt/deploy/backup/
# -rw-r--r-- myapp-v1.2.3.war ← 이전 버전
# -rw-r--r-- myapp-v1.2.4.war ← 현재 버전 (문제 있는 버전)
# 3. 서비스 중지 → 파일 교체 → 재시작
sudo systemctl stop tomcat
sudo cp /opt/deploy/backup/myapp-v1.2.3.war /opt/tomcat/webapps/ROOT.war
# 기존 배포 디렉터리 삭제 (재배포를 위해)
ROOT_DIR="/opt/tomcat/webapps/ROOT"
test "$(sudo readlink -f "$ROOT_DIR")" = "$ROOT_DIR" || { echo "ROOT 경로 검증 실패" >&2; exit 1; }
sudo test -d "$ROOT_DIR" && sudo rm -rf -- "$ROOT_DIR"
sudo systemctl start tomcat
sudo tail -f /opt/tomcat/logs/catalina.out # 기동 로그
# 4. 기동 확인
curl -o /dev/null -s -w "%{http_code}" http://localhost/health
# 200 확인
# 5. 결제 기능 동작 확인 (스모크 테스트)
curl -X POST http://localhost/api/payment/test \
-H "Content-Type: application/json" \
-d '{"amount": 100, "method": "test"}'
# 6. 에러율 정상화 확인
sudo grep "ERROR" /opt/tomcat/logs/catalina.out | \
grep "$(date +%H:%M)" | wc -l
# 0 또는 정상 수준으로 감소 확인
롤백 후에도 오류 지속 — DB 스키마 확인:
# v1.2.4에서 DB 마이그레이션이 실행됐는지 확인
mysql -u app -p mydb -e "SELECT * FROM flyway_schema_history ORDER BY installed_rank DESC LIMIT 5;"
# v1.2.4 마이그레이션이 실행됐다면 → v1.2.3 코드와 스키마 불일치 가능
# 마이그레이션 롤백 (down migration) 스크립트가 있는 경우
# → 개발팀과 협의 필수 (데이터 손실 가능성 있음)
# 임시 방법: v1.2.4 코드로 빠르게 핫픽스 적용
시나리오 7: 방화벽 오픈 없이 외부 API 연계 요청
상황: 외부 결제사 API 연동인데 호출이 안 됨
개발팀이 외부 결제 API를 연동했는데 서버에서 호출이 타임아웃됩니다. 개발 PC에서는 잘 되는데 서버에서만 안 됩니다.
연계 구조 파악과 연결 테스트:
# 1. 연계 구조 파악
# 어떤 서버에서 어느 외부 IP:Port로 나가는지 확인
# 개발팀에게 확인: "어떤 URL로 호출하나요?"
# 예: https://api.payment.com (443) 또는 http://api.payment.com (80)
# 2. nc(netcat)로 포트 연결 테스트
nc -zv api.payment.com 443
# Connection to api.payment.com 443 port [tcp/https] succeeded! → 포트 열림
# nc: connect to api.payment.com port 443 (tcp) timed out → 차단됨
# curl로 HTTP 레벨 확인
curl -v --connect-timeout 10 https://api.payment.com/health
# connect: Connection timed out → 방화벽 차단
# 3. 현재 방화벽 규칙 확인 (온프레미스)
sudo iptables -L OUTPUT -n | grep -E "443|payment"
# 또는 보안장비(ASA, FortiGate 등)에 접속해 아웃바운드 규칙 확인
# AWS 환경이면 Security Group outbound 확인
aws ec2 describe-security-groups --group-ids sg-12345678 \
--query "SecurityGroups[0].IpPermissionsEgress"
방화벽 오픈 요청서 작성:
방화벽 오픈 신청서
신청 목적: 외부 결제 API 연동
요청자: 인프라팀 홍길동
승인자: 팀장 김철수
변경 유형: Outbound 규칙 추가
Source:
서버: app-server-01 (10.0.1.100)
서브넷: 10.0.1.0/24
Destination:
대상: api.payment.com
IP: 203.0.113.50 (DNS 확인 후 기재)
Port: 443 (HTTPS)
Protocol: TCP
비즈니스 사유: 결제 기능 구현을 위한 외부 PG사 API 연동
보안 검토: HTTPS 암호화 통신, 상용 PG사 (PCI-DSS 인증)
방화벽 오픈 후 확인 테스트:
# 방화벽 오픈 완료 후 즉시 검증
nc -zv api.payment.com 443
# Connection to api.payment.com 443 port succeeded!
curl -I --connect-timeout 10 https://api.payment.com/
# HTTP/2 200 → 연결 성공
# 개발팀에 연결 성공 공유 후 앱 레벨 테스트 요청
실습 — 주요 시나리오 직접 실행
실습 환경에서 Nginx 에러 로그를 열고 최근 에러 패턴을 확인합니다. 없다면 의도적으로 에러를 발생시켜 확인합니다.
# 의도적으로 잘못된 요청 보내 에러 생성
curl -s http://localhost/nonexistent-path
curl -s http://localhost/../etc/passwd # 경로 탐색 시도
# 에러 로그 확인
sudo tail -20 /var/log/nginx/error.log
# 액세스 로그에서 상태코드 분포 확인
sudo awk '{print $9}' /var/log/nginx/access.log | sort | uniq -c | sort -rn
sudo tail -100 /var/log/nginx/error.log- Nginx 에러 로그에서 에러 패턴과 발생 시각을 먼저 확인 — 같은 에러가 분당 10건 이상 반복되면 루프 또는 자동화 도구에 의한 공격 가능성. 산발적이면 실제 사용자 오류
- 액세스 로그에서 5xx 비율이 전체 요청의 1% 이상이면 서비스 이상 — 0.1% 미만이면 간헐적 오류. 5xx와 함께 upstream timed out 에러가 나오면 WAS 응답 지연이 원인
- 의도적으로 보낸 잘못된 요청이 로그에 없으면 — 로그 형식이 에러를 기록하지 않는 설정이거나 로그 경로가 다른 것. 에러 로그가 있고 5xx 비율이 1% 이상인 조합이면 즉시 WAS 상태 확인
공개 도메인(google.com)으로 인증서 만료일 확인 방법을 실습합니다. 서버 자체 인증서가 있다면 localhost 또는 실제 도메인으로 교체합니다.
# 내부 서버 인증서 확인
sudo openssl x509 -in /etc/nginx/ssl/server.crt -noout -dates 2>/dev/null || \
echo "인증서 파일 없음 — Let's Encrypt 사용 시 /etc/letsencrypt/live/"
# Let's Encrypt 인증서 확인
sudo ls -la /etc/letsencrypt/live/*/
sudo openssl x509 -in /etc/letsencrypt/live/*/cert.pem -noout -dates 2>/dev/null
echo | openssl s_client -connect google.com:443 2>/dev/null | openssl x509 -noout -dates- openssl 출력에서 notAfter 날짜를 먼저 확인 — 현재 날짜와 비교해 30일 이내면 갱신 일정 수립. 이미 지났으면 브라우저에서 NET::ERR_CERT_DATE_INVALID 오류가 발생 중인 것
- notAfter가 남아있는데 브라우저에서 인증서 오류가 나면 — 도메인 불일치(CN 또는 SAN 확인) 또는 중간 CA 인증서 체인 누락. openssl s_client -connect 로 chain 검증
- 인증서 파일 경로(/etc/nginx/ssl/ 또는 /etc/letsencrypt/live/)가 없으면 — Nginx가 기동은 됐지만 SSL 설정을 안 읽고 있는 것. nginx -T | grep ssl_certificate로 실제 로드 중인 경로 확인
현재 실행 중인 MySQL 쿼리와 연결 상태를 확인합니다. time 값이 크면 슬로우 쿼리입니다.
# 30초 이상 실행 중인 쿼리 찾기
mysql -u root -p -e "
SELECT id, user, time, state, LEFT(info,100) AS query
FROM information_schema.processlist
WHERE time > 30 AND command != 'Sleep'
ORDER BY time DESC;"
# 전체 커넥션 수 확인
mysql -u root -p -e "SHOW STATUS LIKE 'Threads_connected';"
# Value가 max_connections에 근접하면 위험
mysql -u root -p -e "SHOW VARIABLES LIKE 'max_connections';"
mysql -u root -p -e 'SHOW PROCESSLIST'- 시나리오 1부터 순서대로 진행 — Nginx 에러 로그에서 에러 빈도(분당 건수)를 먼저 파악. 시나리오별 핵심 지표를 하나씩 수집한 다음 연결된 해석으로 넘어가는 것이 올바른 진단 순서
- 시나리오 5에서 Threads_connected가 max_connections의 80% 이상이면 커넥션 고갈 임박 — SHOW PROCESSLIST의 time이 30초 이상인 쿼리가 5개 이상이면 슬로우 쿼리가 커넥션을 점유 중인 것
- Threads_connected가 높고 processlist에 Sleep 상태가 대부분인 조합이면 — 애플리케이션이 커넥션 풀을 반납하지 않는 누수 상태. wait_timeout 설정을 줄이고 커넥션 풀 max-size와 max_connections를 함께 조정 필요
트러블슈팅
원인: 새 버전 배포 중 DB 마이그레이션(컬럼 추가, 테이블 변경)이 실행됐습니다. 이전 버전 코드로 롤백했지만 DB 스키마는 새 버전 기준으로 남아 있어 이전 코드가 오류를 냅니다.
# 1. 마이그레이션 히스토리 확인 (Flyway)
mysql -u app -p mydb -e "
SELECT version, description, installed_on, success
FROM flyway_schema_history
ORDER BY installed_rank DESC
LIMIT 10;"
# 2. 이전 버전 코드가 어떤 컬럼을 참조하는지 파악
# → 개발팀에 "v1.2.3이 필요한 컬럼 목록" 요청
# 3. 추가된 컬럼이 NOT NULL이 아니라면 임시 허용 가능
# NOT NULL 컬럼이면 이전 코드가 INSERT 시 오류
DESCRIBE mydb.orders; # 컬럼 정의 확인
# 4. 선택지 A: 핫픽스로 v1.2.4 재배포 (권장)
# 선택지 B: 마이그레이션 수동 롤백 (down migration — 데이터 손실 위험)
# 선택지 C: 추가된 컬럼에 DEFAULT 값 추가해 이전 코드와 호환
ALTER TABLE orders MODIFY new_column VARCHAR(50) DEFAULT NULL;
예방: 배포 전 롤백 시나리오를 항상 설계합니다. DB 마이그레이션이 포함된 배포는 "backward compatible"하게(이전 버전 코드도 새 스키마에서 동작) 설계하는 것이 원칙입니다.
원인: WAF 규칙 예외를 추가했는데도 403이 계속 나오는 경우, 설정 반영이 안 됐거나 다른 규칙이 동일한 요청을 차단하고 있습니다.
# 1. 설정 반영 확인
sudo nginx -T | grep -A 10 "SecRule.*1001" # 예외 규칙이 포함됐는지
# ModSecurity가 실제로 재로드됐는지 확인
sudo systemctl status nginx | grep -i modsec
sudo journalctl -u nginx -n 20 --no-pager | grep -i modsec
# 2. 같은 요청에 대한 WAF 로그 재확인
sudo tail -f /var/log/modsec_audit.log &
curl -X POST http://localhost/api/v1/register -d '{"name": "test"}' 2>&1
# terminatingRuleId 가 1001 외 다른 ID인지 확인
# → 다른 규칙이 차단 중이면 해당 규칙도 예외 처리 필요
# 3. ModSecurity Detection Only 모드로 임시 전환 (디버깅용)
# nginx.conf의 modsecurity_rules_file 수정
# SecRuleEngine On → SecRuleEngine DetectionOnly
# → 차단하지 않고 로그만 기록 (일시적 조치)
sudo nginx -t && sudo systemctl reload nginx
# 디버깅 완료 후 반드시 On으로 복원
심화 — 복구가 끝이 아니다: 증거 보존과 2차 붕괴
심화: 재시작은 증상을 지우고, 회복은 2차 장애를 부른다
7가지 시나리오를 관통하는 반사 신경은 '빨리 살린다'입니다. 그런데 시니어의 대응이 주니어와 갈리는 지점은 그 앞뒤에 있습니다 — 살리기 전에 무엇을 남기고, 살린 직후에 무엇을 대비하느냐입니다.
- 재시작은 증거를 함께 지운다:
systemctl restart한 줄이면 서비스는 돌아오지만, OOM·커넥션 누수·데드락의 원인이 담긴 실시간 상태(jstack스레드 덤프,jmap힙 덤프,SHOW PROCESSLIST,ss -s,/proc,dmesg)도 같이 사라집니다. '재시작하니 됐다'로 끝내면 같은 장애가 다음 달에 또 나고 그때도 원인을 못 짚습니다. 그래서 복구를 지나치게 늦추지 않는 선에서 재시작 전에 덤프부터 확보하는 것이 규율입니다. - 회복 그 자체가 2차 장애를 부른다: 서비스가 뜨는 순간, 장애 동안 밀린 클라이언트 재시도와 재접속이 한꺼번에 쏟아지고(thundering herd) 캐시는 비어 있어(cache stampede) 모든 요청이 DB로 몰립니다. 커넥션 풀과 CPU가 즉시 소진돼 방금 살린 서비스가 다시 무너집니다. 이건 새 버그가 아니라 회복 방식이 만든 붕괴입니다.
- 완화 — 문을 활짝 열지 않는다: 복구 트래픽은 로드밸런서 뒤에서 단계적으로 램프업하고(인스턴스·트래픽을 조금씩 붙이거나 워밍업 동안 게이트웨이에서 레이트리밋), 트래픽을 받기 전에 캐시를 예열합니다. 클라이언트·게이트웨이는 지수 백오프에 지터를 넣고 서킷 브레이커를 둬 재시도가 동기화되지 않게 합니다.
정리하면, 장애 대응은 '살리는 순간'만이 아니라 '살리기 직전의 증거 확보'와 '살린 직후의 램프업'까지입니다 — 회복도 설계의 대상입니다.
상황: 원인을 조치하고 WAS를 기동하면 잠깐 정상으로 보이다가 1~2분 만에 다시 다운되는 것이 반복됩니다. 기동 직후 DB 커넥션과 CPU가 즉시 최대치로 튀는 패턴이 매번 똑같습니다.
원인: 회복 순간의 재시도 폭주입니다. 장애가 이어지는 동안 클라이언트 앱과 상위 게이트웨이가 실패한 요청을 계속 재시도·큐잉했고, 서비스가 뜨는 그 순간 밀려 있던 요청과 재접속이 동시에 쏟아졌습니다. 여기에 캐시까지 비어 있어(콜드 캐시) 모든 조회가 DB로 직행하면서 커넥션 풀과 CPU를 즉시 소진시켜 다시 죽는 것입니다. 재시도에 지터가 없으면 요청이 같은 박자로 겹쳐 폭발이 증폭됩니다.
진단: 패턴을 봅니다 — 기동 후 몇 초는 정상이다가 Active 커넥션이 순식간에 최대치로 뛰는지(ss -s, HikariCP Active=max, DB Threads_connected 급등), 액세스 로그에 기동 시각과 맞물린 요청 폭주가 찍히는지, 기동 직후 캐시 히트율이 0에 가까운지 확인합니다. 붕괴 시점이 매번 재시작 직후에 정렬된다면 새 버그가 아니라 회복 패턴이 원인입니다.
해결: 문을 한 번에 열지 않습니다. 복구 인스턴스를 로드밸런서 뒤에서 단계적으로 투입하거나 워밍업 동안 게이트웨이에서 레이트리밋을 걸어 유입을 서서히 늘리고, 트래픽을 받기 전에 캐시를 예열합니다. 근본적으로는 클라이언트·게이트웨이가 지수 백오프+지터와 서킷 브레이커를 쓰도록 고쳐 재시도가 동기화되지 않게 합니다. 회복을 '재시작 한 방'이 아니라 '점진 램프업'으로 설계하는 것이 핵심입니다.
7가지 시나리오를 하나의 역량으로 묶으면:
이 모든 시나리오의 공통 패턴은 "로그를 먼저, 추측은 나중"입니다. 어떤 장애든 첫 30초는 영향도 파악과 공유, 다음 5분은 로그에서 단서 찾기입니다. 명령어를 외우는 것보다 "이런 증상이 나오면 어떤 로그를 보는가"를 연결하는 것이 더 중요합니다.
# 인프라 엔지니어의 장애 대응 첫 60초 루틴
# (어떤 장애든 이 4개 명령으로 시작)
# 1. Nginx 상태와 최근 에러
sudo systemctl status nginx && sudo tail -30 /var/log/nginx/error.log
# 2. WAS 로그 에러 패턴
sudo grep -E "ERROR|Exception|WARN" /opt/tomcat/logs/catalina.out | tail -30
# 3. 시스템 리소스
top -bn1 | head -20; free -h; df -h
# 4. DB 연결 상태
mysql -u root -p -e "SHOW STATUS LIKE 'Threads_connected';" 2>/dev/null
주니어 때 이 흐름이 몸에 배면, 시니어가 됐을 때는 여기서 파생되는 수백 가지 케이스를 자연스럽게 다룰 수 있게 됩니다. infra-ops 트랙의 마지막 종합 모듈입니다. 배운 모든 내용은 실제 장애와 운영 상황에서 연결됩니다.
명령어·단축키 빠른 참조
7가지 시나리오에서 반복해서 쓴 장애 진단·조치 명령을 실전 옵션과 함께 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
systemctl status/restart | 서비스 상태 확인·재기동 | systemctl restart tomcat (덤프 확보 후) |
tail -f … catalina.out | WAS 기동·에러 로그 실시간 | grep -E "ERROR|Exception|OutOfMemory" 조합 |
awk '{print $9}' access.log | 상태코드 분포 집계 | awk '{print $9}' access.log | sort | uniq -c | sort -rn |
curl -o /dev/null -w '%{http_code}' | 헬스체크 상태코드만 확인 | curl -o /dev/null -s -w '%{http_code}' localhost/health |
openssl s_client + x509 -noout -dates | SSL 인증서 만료일 확인 | echo | openssl s_client -connect ex.com:443 | openssl x509 -noout -dates |
certbot renew | Let's Encrypt 인증서 갱신 | certbot renew --dry-run(테스트) → certbot renew |
nginx -t && systemctl reload nginx | 설정 문법 검증 후 무중단 반영 | 인증서·프록시·WAF 예외 변경 후 |
SHOW FULL PROCESSLIST | 실행 중 쿼리·커넥션 확인 | information_schema.processlist WHERE time>60 |
KILL / KILL QUERY | 느린 쿼리·연결 강제 종료 | KILL QUERY 1234;(쿼리만) / KILL 1234;(연결) |
EXPLAIN / ALTER TABLE … ADD INDEX | 풀스캔 진단·인덱스 추가 | ALTER TABLE orders ADD INDEX idx_email (email) |
nc -zv | 외부 API 포트 연결 테스트 | nc -zv api.payment.com 443 |
curl -v --connect-timeout | HTTP 레벨 연결·차단 확인 | curl -v --connect-timeout 10 https://api.payment.com/ |
iptables -L OUTPUT -n | 아웃바운드 방화벽 규칙 확인 | iptables -L OUTPUT -n | grep 443 |
jstack / jmap | 재시작 전 스레드·힙 덤프 확보 | 증거가 지워지기 전에 먼저 실행 |
SHOW STATUS LIKE 'Threads_connected' | 커넥션 소진 임박 확인 | max_connections 대비 80%↑면 위험 |
관련 모듈로 더 깊이:
- 프로세스(ps), 포트(netstat), 리소스(top) 모니터링 실무 — 장애 1차 진단의 핵심인 프로세스·포트·리소스 점검 흐름
- HTTP 에러 코드 해석과 장애 원인 추적 — 종합 시나리오에서 원인을 좁히는 로그 분석 기법
- 타임라인 분석과 재발 방지 대책 수립 — 대응이 끝난 뒤 장애를 기록하고 재발을 막는 보고서 작성
다음 모듈에서는 infra-ops 트랙에서 익힌 서버 진단·로그 분석·네트워크 디버깅 역량을 바탕으로 Kubernetes 환경에서의 운영 방식을 다룹니다.