새벽 2시에 장애가 났습니다. 빠르게 서비스를 복구했고, 오전 9시에 팀장이 묻습니다. "보고서 언제 나와요?" 무슨 내용을 어떻게 써야 할지 막막합니다. 그냥 "DB 문제였고 재시작으로 해결했다"고 쓰면 될까요?
장애 보고서는 다음 장애를 막기 위한 문서입니다. 잘 쓴 보고서는 팀 전체가 같은 장애를 두 번 겪지 않게 하고, 조직의 인프라 성숙도를 높입니다. 이 모듈은 장애 타임라인 재구성부터 5-Why 분석, 재발 방지 대책 수립까지 — 실제로 쓸 수 있는 보고서를 만드는 방법을 다룹니다.
- 1장애 보고서의 구성 요소(요약, 타임라인, 원인 분석, 재발 방지)를 설명할 수 있다
- 2로그 timestamp를 기준으로 장애 타임라인을 재구성할 수 있다
- 35-Why 기법으로 직접 원인에서 근본 원인까지 분석할 수 있다
- 4측정 가능한 재발 방지 대책(담당자, 기한, 완료 기준 포함)을 작성할 수 있다
- 5좋은 재발 방지 대책과 나쁜 재발 방지 대책의 차이를 구분할 수 있다
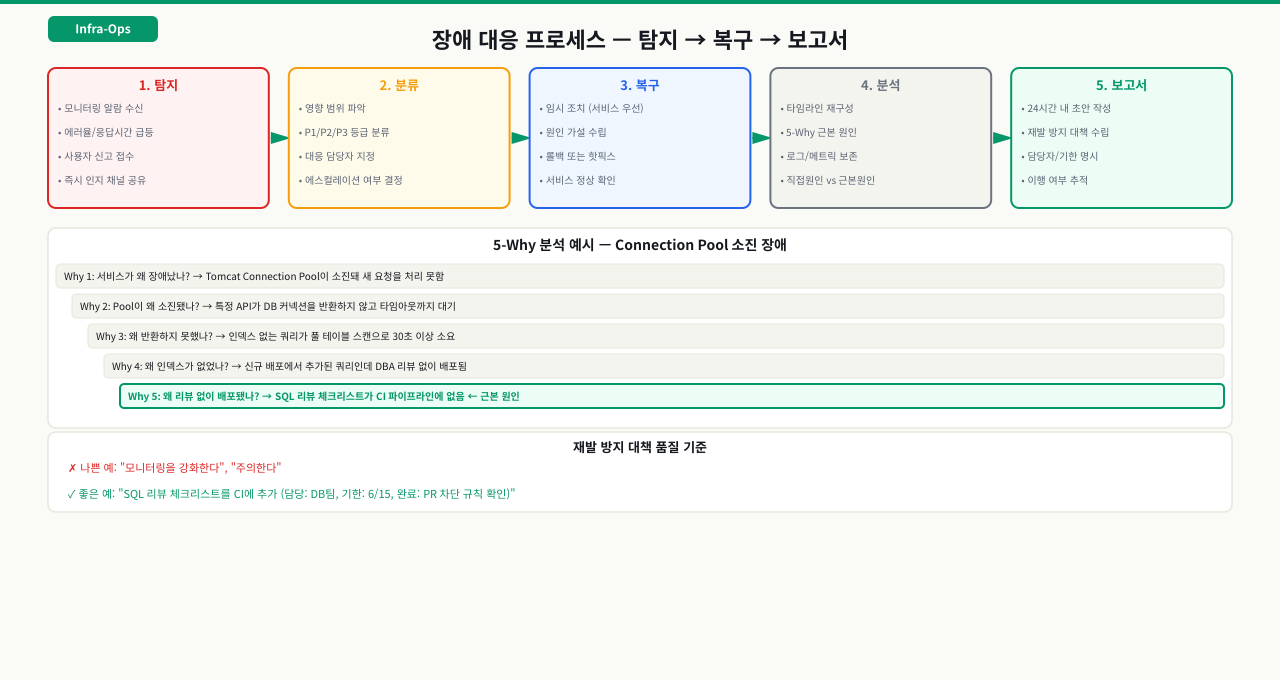
장애 보고서 구성
보고서가 다뤄야 할 핵심 항목
장애를 복구하고 나서 팀장이 "보고서 써줘"라고 합니다. 처음 쓰는 사람은 "기술적으로 무슨 일이 있었는지"만 나열하다가 마칩니다. 경영진은 "몇 명 고객이 영향받았고, 매출 손실이 얼마였으며, 다시는 일어나지 않을 것인지"를 묻습니다. 두 독자를 모두 만족시키지 못하면 좋은 보고서가 아닙니다. 구조를 알면 쓰는 시간도, 받아들이는 쪽도 훨씬 빨라집니다.
장애 보고서의 독자는 두 종류입니다. 기술 내용을 이해하는 엔지니어팀과, 영향 범위와 재발 방지에 관심 있는 경영진입니다. 좋은 보고서는 두 독자 모두를 만족시킵니다.
 확대
확대
장애 보고서 표준 구성:
1. 요약 (Executive Summary)
- 발생 일시와 복구 일시
- 총 장애 지속 시간
- 영향 범위 (서비스명, 영향받은 사용자 수/트랜잭션 수)
- 핵심 원인 한 줄 요약
2. 타임라인 (Timeline)
- 장애 발생부터 복구까지 시각 순서대로
- 각 시점에 누가 무엇을 했는지 명시
3. 원인 분석 (Root Cause Analysis)
- 직접 원인: 기술적으로 무슨 일이 발생했나
- 근본 원인: 왜 그 일이 가능했나 (5-Why)
4. 재발 방지 대책 (Action Items)
- 각 대책에 담당자, 기한, 완료 기준 명시
5. 교훈 (Lessons Learned)
- 팀 전체가 공유할 인사이트
타임라인 재구성
로그에서 타임라인을 뽑아내는 방법
장애 타임라인은 기억에 의존하면 안 됩니다. 로그의 timestamp가 유일한 사실입니다. 장애 복구 직후, 관련 로그를 수집하고 시각순으로 정렬하는 것이 첫 번째 작업입니다.
# Tomcat 에러 로그에서 장애 시각대 추출
grep -E "ERROR|WARN|Exception" /opt/tomcat/logs/catalina.out \
| grep "2026-05-30 14:" \
| head -30
# 예시 출력:
# 2026-05-30 14:02:31 WARN HikariPool - Connection is not available, request timed out after 30000ms
# 2026-05-30 14:02:31 ERROR DispatcherServlet - Servlet.service() for servlet threw exception
# 2026-05-30 14:03:15 ERROR HikariPool - HikariPool-1 - Connection timeout
# Nginx 액세스 로그에서 500 에러 시작 시점
grep " 500 " /var/log/nginx/access.log | grep "30/May/2026:14:" | head -5
# DB slow query 로그 확인 (MySQL 예시)
grep -A2 "Query_time" /var/log/mysql/slow.log | grep "2026-05-30 14:" | head -10
# 시스템 로그에서 관련 이벤트
journalctl -u tomcat --since "2026-05-30 14:00" --until "2026-05-30 15:00" \
| grep -E "ERROR|killed|OOM"
타임라인 작성 예시:
14:00 배포 완료 (v2.4.1 → v2.4.2)
14:02 모니터링 alert — Tomcat Connection Pool 사용률 100%
14:03 고객 신고 첫 건 — "결제 오류" (Slack #support)
14:05 온콜 엔지니어(홍길동) 접속, 로그 확인 시작
14:08 DB slow query 확인 — /api/orders GET 쿼리 5초 이상
14:12 해당 쿼리 인덱스 없음 확인 (EXPLAIN 실행)
14:15 Tomcat 재시작으로 임시 서비스 복구
14:22 인덱스 추가 배포
14:25 모니터링 정상 확인, 장애 종료
총 장애 시간: 23분 (14:02 ~ 14:25)
5-Why 분석
표면적 원인에서 근본 원인으로
보고서에 "Tomcat이 다운되었습니다"라고 쓰면, 다음 달에 같은 Tomcat이 또 다운됩니다. "왜 다운됐는가"까지 파고들지 않으면 증상만 치료하고 원인은 그대로 남습니다. 장애 재발 방지의 핵심은 표면 현상에서 멈추지 않고 운영 절차나 구조적 결함까지 도달하는 것입니다. 5-Why는 이 과정을 체계화합니다.
5-Why는 "왜?"를 반복해서 근본 원인까지 파고드는 기법입니다. 단순히 5번을 채우는 것이 목적이 아닙니다. "더 이상 왜를 물을 수 없는 곳"에서 멈추는 것이 목표입니다.
5-Why 분석 예시:
현상: 14:02부터 결제 서비스에서 500 에러 폭발
Why 1: 왜 500 에러가 났는가?
→ Tomcat Connection Pool이 고갈됐다
Why 2: 왜 Connection Pool이 고갈됐는가?
→ DB 쿼리 응답이 5분 이상 걸렸다
Why 3: 왜 DB 쿼리 응답이 5분 이상 걸렸는가?
→ /api/orders?userId=... 쿼리가 인덱스 없이 full scan을 했다
Why 4: 왜 인덱스 없는 쿼리가 배포됐는가?
→ 이번 배포에 orders 테이블에 새 컬럼이 추가됐는데 인덱스가 누락됐다
Why 5: 왜 인덱스 누락이 배포 전에 감지되지 않았는가?
→ 배포 전 SQL 리뷰 프로세스가 없었고, 개발 환경에서는 데이터가 적어 full scan이 문제되지 않았다
근본 원인: 배포 전 SQL 변경사항에 대한 리뷰 프로세스 부재
→ 재발 방지 대책: CI 파이프라인에 SQL 변경사항 리뷰 단계 추가
좋은 5-Why의 특징:
- 각 단계가 논리적 인과관계로 연결된다
- 마지막 원인이 프로세스나 설계 수준이다 (개인 실수가 아니라)
- 근본 원인을 해결하면 같은 패턴의 장애가 재발하지 않는다
피해야 할 패턴:
Why 1: 왜 장애가 났는가? → 담당자가 인덱스를 빠뜨렸다
Why 2: 왜 인덱스를 빠뜨렸는가? → 실수로
Why 3: 왜 실수를 했는가? → 주의를 안 했다
...
사람을 탓하는 방향으로 흐르면 재발 방지 대책이 "주의한다"가 됩니다. 5-Why는 시스템과 프로세스의 결함을 찾는 도구입니다.
 확대
확대
재발 방지 대책 작성
실행 가능한 대책을 만드는 기준
3개월 전 장애 보고서를 꺼내봤더니 "모니터링을 강화한다"고 적혀 있습니다. 그 사이에 같은 유형의 장애가 한 번 더 났습니다. "강화한다"는 말에는 담당자도, 기한도, 완료 기준도 없습니다. 막연한 의지 표명은 재발 방지가 되지 않습니다. 실제로 실행되고 검증될 수 있는 대책의 조건이 있습니다.
재발 방지 대책은 "무엇을, 누가, 언제까지, 어떻게 완료됐다고 판단하는가"가 명확해야 합니다.
나쁜 재발 방지 대책 예시:
1. 배포 전 더 주의한다
2. 모니터링을 강화한다
3. 인덱스를 항상 확인한다
이 세 항목은 모두 담당자가 없고, 기한이 없고, 완료 기준이 없습니다. 한 달 후 같은 장애가 나도 이 항목들이 지켜졌는지 확인할 방법이 없습니다.
좋은 재발 방지 대책 예시:
| # | 대책 | 담당 | 기한 | 완료 기준 |
|---|------|------|------|-----------|
| 1 | CI 파이프라인에 SQL 변경사항 리뷰 체크리스트 추가 | DB팀 이민준 | 6/15 | PR에 SQL 변경 시 체크리스트 없으면 머지 차단 |
| 2 | 개발 환경 DB에 운영 수준 데이터 볼륨 추가 | 인프라팀 박현우 | 6/30 | EXPLAIN 플랜에서 full scan 감지 시 경고 |
| 3 | Tomcat Connection Pool 고갈 alert 추가 | 인프라팀 박현우 | 6/10 | Pool 사용률 80% 초과 시 Slack alert 동작 확인 |
각 항목이 "완료됐다"고 판단하는 기준이 테스트 가능한 형태입니다.
실습
실제 로그 파일에서 장애 시각대의 에러와 경고를 추출합니다. timestamp, 로그 레벨, 메시지를 한 줄로 정리해 타임라인 초안을 만듭니다. 파일이 없는 실습 환경에서는 /var/log/syslog 또는 journalctl 출력으로 대체합니다.
grep -E 'ERROR|WARN|Exception' /opt/tomcat/logs/catalina.out | grep '2026-05-30 14:' | awk '{print $1, $2, $3, $NF}' | head -20- 첫 번째 ERROR 로그의 timestamp를 먼저 확인 — 모니터링 alert 시각보다 1~5분 앞서면 정상(수집 지연), 10분 이상 차이나면 alert 설정 문제
- WARN 로그가 ERROR보다 앞서 나타나면 사전 징조 — WARN과 첫 ERROR 사이 시간 간격이 5분 미만이면 빠른 악화, 30분 이상이면 점진적 악화로 원인이 다름
- 같은 Exception이 반복되면 루프 에러 가능성 — 복구 조치 후 로그에서 에러가 사라지는 시점이 없으면 근본 원인이 해소되지 않은 것, 재발 가능성 높음
DB 연결 관련 에러를 확인하고, 해당 에러를 시작점으로 5-Why 분석을 직접 작성해봅니다. 로그에서 첫 번째 에러 메시지를 가져와 "왜 이 에러가 발생했는가?"부터 시작합니다.
grep -E 'ORA-|SQLException|Connection' /opt/tomcat/logs/catalina.out | grep '2026-05-30 14:' | tail -5- 에러 유형 식별을 먼저 — Connection timeout은 네트워크/DB 방향, OutOfMemoryError는 JVM Heap 방향, NullPointerException은 코드 로직 방향으로 Why 1이 갈라진다
- 5번의 Why가 "담당자가 몰랐다"나 "실수했다"로 끝나면 재발 방지 불가 — 프로세스 결함(검토 단계 누락, 알림 미설정)이나 설계 결함(단일 장애점, 재시도 없음)으로 연결돼야 함
- Why 1이 에러 메시지에서 자연스럽게 도출되고, Why 5 답변이 "~를 자동화한다" 또는 "~단계를 절차에 추가한다" 형식으로 구체화되면 분석 완성 — 모호한 "모니터링 강화"는 재발 방지 대책이 아님
트러블슈팅
원인: 재발 방지 대책을 "빠르게 마무리해야 하는 형식"으로 접근하거나, 근본 원인 분석 없이 표면적 증상에 대한 대책만 만들 때 발생합니다. 또는 특정 팀이나 개인을 탓하지 않으려는 배려가 지나쳐 구체성이 사라지기도 합니다.
진단 체크리스트:
재발 방지 대책 품질 점검:
□ 담당자가 명시됐는가? (팀명이 아닌 특정 사람)
□ 기한이 있는가?
□ 완료 기준이 테스트 가능한가? ("확인한다" → "X 상황에서 Y가 발생하면 Z로 간주")
□ 이 대책이 실행됐다면 이번 장애를 막을 수 있었는가?
□ "주의한다", "강화한다", "노력한다" 같은 태도 표현이 없는가?
개선 예시:
나쁜 예: "모니터링을 강화한다"
좋은 예: "Tomcat Connection Pool 사용률 80% 초과 시 Slack #ops-alert으로 알람 발송
(담당: 인프라팀 박현우, 기한: 6/10, 완료 기준: 테스트 환경에서 80% 초과 시 알람 동작 확인)"
나쁜 예: "배포 전 더 주의한다"
좋은 예: "배포 PR 체크리스트에 'SQL 변경사항 EXPLAIN 결과 첨부' 항목 추가,
체크리스트 미완성 시 GitHub Actions에서 머지 차단
(담당: DB팀 이민준, 기한: 6/15)"
심화 — RCA를 한 겹 더: 5-Why의 한계와 정직한 MTTR
심화: 근본 원인은 정말 '하나'인가 — 5-Why의 구조적 한계와 다음 단계
5-Why는 강력한 출발점이지만, 그것만 신봉하면 큰 장애의 절반을 놓칩니다. 이 기법이 무엇을 못 보는지 알아야, 보고서가 '깔끔한 사슬'에 만족하고 끝나지 않습니다.
- 5-Why는 선형 사슬 하나만 만든다: 대형 장애는 대개 여러 기여 요인(contributing factors)이 겹쳐 터집니다 — 인덱스 누락 + 트래픽 급증 + 풀 고갈 알림 부재 + 롤백 지연이 동시에. Why를 한 줄로 내리면 나머지 요인이 사슬 밖으로 잘려나가, "그거 하나만 고치면 된다"는 착각을 줍니다.
- 분석자에 따라 다른 사슬이 나온다: 같은 현상도 누가 파느냐에 따라 다른 '근본 원인'에 도달합니다(주관성). 그래서 성숙한 조직은 단일 root cause 대신 여러 갈래의 causal tree나 contributing-factors 목록으로 확장합니다.
- 각 단계는 반사실(counterfactual)로 검증한다: "이 요인이 없었다면 장애가 막혔을까?"를 물어 답이 '아니오'면 그건 진짜 원인이 아니라 곁가지입니다. 이 질문으로 사슬의 각 마디가 실제 인과인지 걸러냅니다.
- '사람 실수'는 종착지가 아니라 정지 신호다: Why가 "담당자가 실수했다"에서 멈추면 시스템 개선을 통째로 놓칩니다. human error가 나오면 "왜 시스템이 그 실수를 허용·증폭했나"로 한 겹 더 내려가는 것이 blameless의 실천입니다.
- 다음 단계 — 대책을 세 축으로 나눈다: action item을 '원인 제거'뿐 아니라 '감지 개선(더 빨리 알아채기)'과 '영향 완화(터져도 덜 아프게)'로 나눠, 각 기여 요인에 매핑합니다. 원인 하나 제거로 안심하지 않는 구조입니다.
정리하면, 좋은 RCA는 '유일한 근본 원인'을 찾는 게 아니라 '겹친 요인들과 그것을 허용한 시스템'을 드러내고, 각 요인을 반사실로 검증하는 작업입니다.
상황: 장애 보고서에 발생 14:02, 복구 14:14, MTTR 12분으로 적었습니다. 그런데 고객센터에는 14:40까지 결제 실패 문의가 계속 들어왔습니다. 경영진이 "복구했다면서 왜 아직 클레임이 오느냐"고 묻습니다.
원인: '복구' 시각을 fix 배포와 헬스체크 green 순간으로 잡았지만, 실제 사용자 영향은 그 뒤로도 이어졌습니다. CDN·브라우저 캐시에 남은 에러 응답, 커넥션 풀에 적체된 대기 요청 드레인, 재시도 큐, 만료 안 된 세션 등으로 사용자 성공률은 서버가 정상이 됐다고 즉시 100%로 돌아오지 않습니다. MTTR을 '내부 시점(서버가 정상)' 기준으로만 재면 고객이 겪은 시간과 괴리가 생깁니다. 헬스체크 green과 실제 사용자 경로 성공은 서로 다른 지표입니다.
진단: 복구 판단을 서버 상태가 아니라 사용자 성공률로 다시 잡습니다.
# '기술 복구'(14:14) 이후에도 5xx가 언제까지 이어졌는지 분 단위로 확인
awk '$9 ~ /^5/ {print substr($4,14,5)}' /var/log/nginx/access.log | sort | uniq -c
# 분당 5xx 건수가 0으로 수렴하는 시각이 실제 '고객 영향 종료'
결제 성공 트랜잭션이 정상 분포로 돌아온 시각까지 함께 대조해, 헬스체크가 아니라 사용자 관점에서 언제 끝났는지 확정합니다.
해결: 타임라인에 '기술 복구(서버 정상)'와 '고객 영향 종료(에러율 정상화)' 두 시각을 분리해 기록하고, MTTR은 후자(고객 관점)로 측정합니다. 그리고 캐시 무효화·커넥션 풀 강제 드레인·재시도 큐 비우기 같은 '복구 후 잔여 영향 제거' 절차를 런북에 추가합니다. 지표를 자기 편한 시점이 아니라 고객이 실제로 겪은 시점으로 재는 것이, blameless와 함께 가는 보고서의 정직함입니다.
실제 업무에서 이 지식이 쓰이는 상황:
장애 보고서는 단순히 "어떤 일이 있었다"의 기록이 아닙니다. 잘 작성된 보고서 하나가 팀 전체의 인프라 성숙도를 높이고, 동일 패턴의 장애를 영구히 없애는 계기가 됩니다.
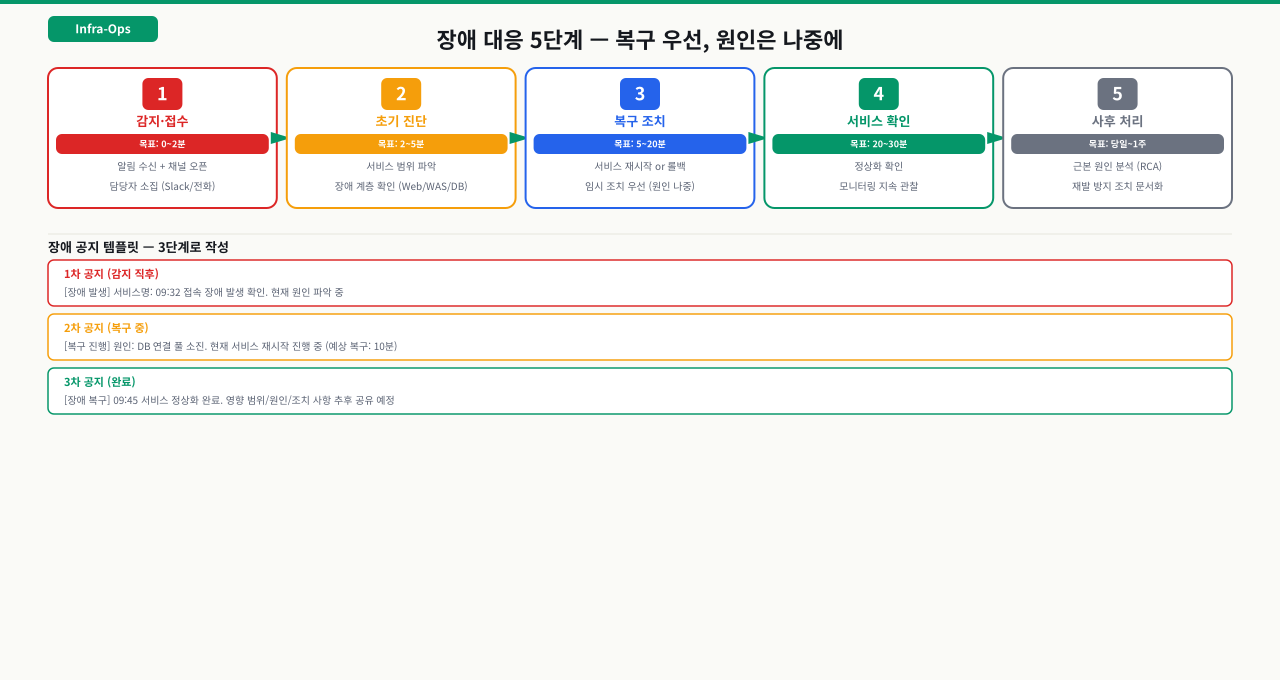
장애 보고서 작성 타임라인 권장:
장애 복구 직후 (0~1시간): 로그 수집, 타임라인 메모
복구 후 24시간 내: 초안 작성 (완벽하지 않아도 됨)
복구 후 48~72시간 내: 팀 리뷰, 5-Why 완성, 재발 방지 대책 확정
1주 후: 재발 방지 대책 이행 시작 확인
장애 보고서 템플릿 (직접 사용 가능):
## 장애 보고서 — [서비스명] [날짜]
### 요약
- 발생: YYYY-MM-DD HH:MM
- 복구: YYYY-MM-DD HH:MM
- 지속 시간: N분
- 영향: [영향받은 서비스/사용자 수/트랜잭션 수]
- 핵심 원인: [한 줄 요약]
### 타임라인
| 시각 | 행동 | 담당자 |
|------|------|--------|
| HH:MM | 현상 감지 | 시스템/모니터링 |
| HH:MM | [대응 행동] | [이름] |
| HH:MM | 서비스 복구 | [이름] |
### 원인 분석
**직접 원인:** [기술적 현상]
**5-Why 분석:**
- Why 1: [현상] → [원인]
- Why 2: [원인] → [더 깊은 원인]
- Why 3: ...
- 근본 원인: [프로세스/설계 결함]
### 재발 방지 대책
| 대책 | 담당 | 기한 | 완료 기준 |
|------|------|------|-----------|
| [구체적 행동] | [이름] | [날짜] | [테스트 가능한 기준] |
### 교훈
- [팀 전체가 공유할 인사이트]
명령어·단축키 빠른 참조
장애 타임라인을 재구성하고 MTTR·근본원인을 로그로 짚을 때 쓰는 명령을 모았습니다.
| 명령어/단축키 | 용도 | 자주 쓰는 예 |
|---|---|---|
grep -E "ERROR|WARN|Exception" | 장애 시각대 에러·경고 추출(타임라인 재료) | … catalina.out | grep "2026-05-30 14:" |
grep "2026-05-30 14:" | 특정 시간창만 필터 | 여러 로그를 같은 창으로 맞춰 대조 |
journalctl -u <svc> --since --until | 서비스 로그를 시간창으로 자르기 | journalctl -u tomcat --since "14:00" --until "15:00" |
awk '$9 ~ /^5/' | 5xx만 골라 분당 분포 | awk '$9~/^5/{print substr($4,14,5)}' access.log | sort | uniq -c |
sort | uniq -c | 분·코드별 건수 집계 | 5xx가 0으로 수렴하는 분 = 고객영향 종료 |
grep -A2 "Query_time" | slow query 로그에서 지연 쿼리 | grep -A2 Query_time /var/log/mysql/slow.log |
EXPLAIN <query> | 인덱스 없는 full scan 입증 | 근본원인(인덱스 누락) 확인 |
grep -E "ORA-|SQLException|Connection" | DB 연결·SQL 예외 추출(5-Why 시작점) | … catalina.out | tail -5 |
관련 모듈로 더 깊이:
- HTTP 에러 코드 해석과 장애 원인 추적 — 타임라인 재구성의 1차 근거가 되는 에러 로그를 읽고 원인을 짚는 법
- CPU/메모리/디스크 임계치 관리와 logrotate — 장애를 사후 보고가 아니라 임계치 알람으로 미리 잡는 재발 방지
- 계정 권한 관리, 보안 헤더, TLS 강화 실무 — 보안 사고 유형 장애의 대책을 운영 차원에서 강화하는 법
다음 모듈에서는 서버 보안 운영 실무 — 계정 권한 관리, 보안 헤더 설정, TLS 강화를 다룹니다.